
12
Recommendation Engines
The best recommendation I can have is my own talents, and the fruits of my own labors, and what others will not do for me, I will try and do for myself.
—18–19th-century scientist John James Audubon
Recommendation engines harness the power of available data on user preferences and item details to offer tailored suggestions. At their core, these engines aim to identify commonalities among various items and understand the dynamics of user-item interactions. Rather than just focusing on products, recommendation systems cast a wider net, considering any type of item – be it a song, a news article, or a product – and tailoring their suggestions accordingly.
This chapter starts by presenting the basics of recommendation engines. Then, it discusses various types of recommendation engines. In the subsequent sections of this chapter, we’ll explore the inner workings of recommendation systems. These systems are adept at suggesting tailored items or products to users, but they’re not without their challenges. We’ll discuss both their strengths and the limitations they present. Finally, we will learn to use recommendation engines to solve a real-world problem.
In this chapter, we’ll cover:
- An overview of recommendation engines
- Different categories of recommendation systems
- Recognizing the constraints of recommendation approaches
- Areas of practical application
- A practical example
By the end of this chapter, you should be able to understand how to use recommendation engines to suggest various items based on some preference criteria.
Let’s start by looking into the background concepts of recommendation engines.
Introducing recommendation systems
Recommendation systems are powerful tools, initially crafted by researchers but now widely adopted in commercial settings, that predict items a user might find appealing. Their ability to deliver personalized item suggestions makes them an invaluable asset, especially in the digital shopping landscape.
When used in e-commerce applications, recommendation engines use sophisticated algorithms to improve the shopping experience for shoppers, allowing service providers to customize products according to the preferences of the users.
A classic example of the significance of these systems is the Netflix Prize challenge in 2009. Netflix, aiming to refine its recommendation algorithm, offered a whopping $1 million prize for any team that could enhance its current recommendation system, Cinematch, by 10%. This challenge saw participation from researchers globally, with BellKor’s Pragmatic Chaos team emerging as the winner. Their achievement underlines the essential role and potential of recommendation systems in the commercial domain. More about this fascinating challenge can be explored in this chapter.
Types of recommendation engines
We can broadly classify recommendation engines into three main categories:
- Content-based recommendation engines: They focus on item attributes, matching the features of one product to another.
- Collaborative filtering engines: They predict preferences based on user behaviors.
- Hybrid recommendation engines: A blend of both worlds, these engines integrate the strengths of content-based and collaborative filtering methods to refine their suggestions.
Having established the categories, let’s start by diving into the details of these three types of recommendation engines one by one:
Content-based recommendation engines
Content-based recommendation engines operate on a straightforward principle: they recommend items that are like ones the user has previously engaged with. The crux of these systems lies in accurately measuring the likeness between items.
To illustrate, imagine the scenario depicted in Figure 12.1:
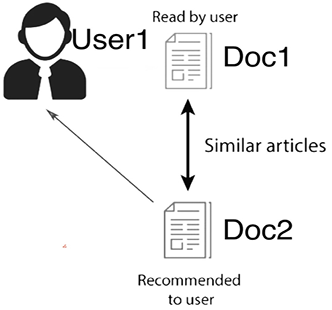
Figure 12.1: Content-based recommendation system
Let’s say that User1 has read Doc1. Due to the similarities between the documents, we could then recommend Doc2 to User1.
This method would only be effective if we could identify and quantify these similarities. Thus, identifying similarities between items is pivotal for recommendations. Let’s delve into how to quantify these similarities.
Determining similarities in unstructured documents
One way of determining the similarities between different documents is by using the co-occurrence matrix, which works on the premise that items frequently bought together likely share similarities or belong to complementary categories.
For instance, someone buying a razor might also need shaving gel. Let’s decode this with data from four users’ buying habits:
|
Razor |
Apple |
Shaving cream |
Bike |
Hummus | |
|
Mike |
1 |
1 |
1 |
0 |
1 |
|
Taylor |
1 |
0 |
1 |
1 |
1 |
|
Elena |
0 |
0 |
0 |
1 |
0 |
|
Amine |
1 |
0 |
1 |
0 |
0 |
To construct the co-occurrence matrix, follow these steps:
- Initialize an NxN matrix, where N is the number of items. This matrix will store the co-occurrence counts.
- For each user in the user-item matrix, update the co-occurrence matrix by incrementing the cell values for pairs of items that the user has interacted with.
- The final matrix showcases the associations between items based on user interactions.
The occurrence matrix of the above table will be as follows:
|
Razor |
Apple |
Shaving cream |
Bike |
Hummus | |
|
Razor |
- |
1 |
3 |
1 |
2 |
|
Apple |
1 |
- |
1 |
0 |
1 |
|
Shaving cream |
3 |
1 |
- |
1 |
2 |
|
Bike |
1 |
0 |
1 |
- |
1 |
|
Hummus |
2 |
1 |
2 |
1 |
- |
This matrix, in essence, showcases the likelihood of two items being bought together. It’s a valuable tool for recommendation.
Collaborative filtering recommendation engines
The recommendations from collaborative filtering are based on the analysis of the historical buying patterns of users. The basic assumption is that if two users show interest in mostly the same items, we can classify both users as similar. In other words, we can assume the following:
- If the overlap in the buying history of two users exceeds a threshold, we can classify them as similar users.
- Looking at the history of similar users, the items that do not overlap in the buying history become the basis of future recommendations through collaborative filtering.
For example, let’s look at a specific example. We have two users, User1 and User2, as shown in the following diagram:
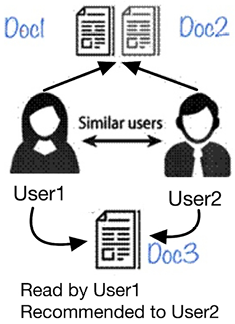
Figure 12.2: Collaborative filtering recommendation engine
Note the following:
- Both User1 and User2 have shown interest in exactly the same documents, Doc1 and Doc2.
- Based on their similar historical patterns, we can classify both of them as similar users.
- If User1 now reads Doc3, then we can suggest Doc3 to User2 as well.
This strategy of suggesting items to users based on their history will not always work. Let us look into the issues related to collaborative filtering in more detail.
Issues related to collaborative filtering
There are three potential issues related to collaborative filtering:
- Inaccuracies due to a limited sample size
- A vulnerability to isolated analysis
- Over-reliance on history
Let us look into the limitations in more detail.
Inaccuracies due to a limited sample size
The accuracy and efficacy of a collaborative filtering system also hinge on the sample size. For instance, if only three documents are analyzed, the potential for accurate recommendations is limited.
However, if a system has data on hundreds or thousands of documents and interactions, its predictive capabilities become significantly more reliable. It’s akin to the difference between making predictions based on a handful of data points versus having a comprehensive dataset to draw insights from.
Even when equipped with vast amounts of data, collaborative filtering isn’t foolproof. The reason is that it relies purely on the historical interactions between users and items, without accounting for any external factors.
Vulnerable to isolated analysis
Collaborative filtering zeroes in on patterns formed by user behaviors and their interactions with items. This means it often misses out on external influences that might dictate a user’s choice. For instance, a user might opt for a particular book not because of personal interest but because of academic needs or a friend’s recommendation. The collaborative filtering model won’t recognize these nuances.
Over-reliance on history
Because the system hinges on historical data, it can sometimes end up reinforcing stereotypes or not catching up with a user’s evolving tastes. Imagine if a user once had a phase where they loved sci-fi movies but has since transitioned to enjoying romantic films. If they watched numerous sci-fi movies in the past, the system might still primarily recommend them, missing out on their current preferences.
In essence, while collaborative filtering is powerful, especially with more data, it’s essential to understand its inherent limitations stemming from its isolated method of operation.
Next, let’s look at hybrid recommendation engines.
Hybrid recommendation engines
So far, we have discussed content-based and collaborative-filtering-based recommendation engines. Both types of recommendation engines can be combined to create a hybrid recommendation engine. To do so, we follow these steps:
- Generate a similarity matrix of the items.
- Generate preference matrices of the users.
- Generate recommendations.
Let’s look into these steps one by one.
Generating a similarity matrix of the items
In hybrid recommendations, we start by creating a similarity matrix of items using content-based recommendations. This can be done by using the co-occurrence matrix or any distance measure to quantify the similarities between items.
Let’s assume that we currently have five items. Using content-based recommendations, we generate a matrix that captures the similarities between items, as shown in Figure 12.3:
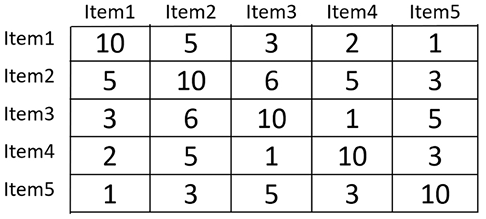
Figure 12.3: Similarity matrix
Let’s see how we can combine this similarity matrix with a preference matrix to generate recommendations.
Generating reference vectors of the users
Based on the history of each of the users of the system, we will produce a preference vector that captures those users’ interests.
Let’s assume that we want to generate recommendations for an online store named KentStreetOnline, which sells 100 unique items. KentStreetOnline is popular and has 1 million active subscribers. It is important to note that we need to generate only one similarity matrix with dimensions of 100 by 100. We also need to generate a preference vector for each of the users; this means that we need to generate 1 million preference vectors for each of the 1 million users.
Each entry of the performance vector represents a preference for an item. The value of the first row means that the preference weight for Item 1 is 4. The preference score isn’t a direct reflection of purchase counts. Instead, it’s a weighted metric, potentially considering factors like browsing history, past purchases, item ratings, and more.
A score of 4 could represent a combination of interest and past interactions with Item 1, suggesting a strong likelihood that the user would appreciate that item.
This is graphically shown in Figure 12.4:
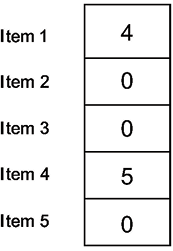
Figure 12.4: User preference matrix
Now, let’s look into how we can generate recommendations based on the similarity matrix, S, and the user preference matrix, U.
Generating recommendations
To make recommendations, we can multiply the matrices. Users are more likely to be interested in an item that co-occurs frequently with an item that they gave a high rating to:
Matrix[S] × Matrix[U] = Matrix[R]
This calculation is shown graphically in Figure 12.5:
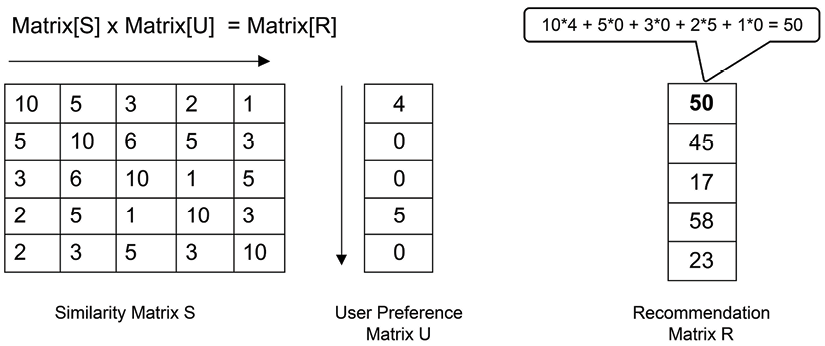
Figure 12.5: Generation of a recommendation matrix
A separate resultant matrix is generated for each of the users. The numbers in the recommendation matrix, Matrix[R], quantify the predicted interest of a user in each of the items. For example, in the resultant matrix, the fourth item has the highest number, 58. So this item is highly recommended for this particular user.
Evolving the recommendation system
Recommendation systems aren’t static; they thrive on constant refinement. How does this evolution occur? By juxtaposing the recommended items (predictions) with the user’s actual choices. By analyzing discrepancies, the system identifies areas to improve. Over time, by recalibrating based on user feedback and observed behaviors, the system enhances its recommendation accuracy, ensuring users always receive the most relevant suggestions.
Now, let’s look into the limitations of different recommendation systems.
Understanding the limitations of recommendation systems
Recommendation engines use predictive algorithms to suggest recommendations to a bunch of users. It is a powerful technology, but we should be aware of its limitations. Let’s look into the various limitations of recommendation systems.
The cold start problem
At the core of collaborative filtering lies a crucial dependency: historical user data. Without a track record of user preferences, generating accurate suggestions becomes a challenge. For a new entrant into the system, the absence of data means our algorithms largely operate on assumptive grounds, which can lead to imprecise recommendations. Similarly, in content-based recommendation systems, fresh items might lack comprehensive details, making the suggestion process less reliable. This data dependency – the need for established user and item data to produce sound recommendations – is what’s termed the cold start problem.
There are several strategies to counterbalance the cold start challenge:
- Hybrid systems: Merging collaborative and content-based filtering can offset the limitations of one system using the strengths of the other.
- Knowledge-based recommendations: If historical data is scant, leaning on explicit knowledge about users and items can help bridge the gap.
- Onboarding questionnaires: For new users, a brief questionnaire about preferences can seed the system with initial data, guiding early recommendations.
Understanding and countering these challenges ensures that recommendation systems remain an effective and reliable tool in user engagement strategies.
Metadata requirements
While content-based recommendation systems can function without metadata, incorporating such details can enhance their precision. It’s important to note that metadata isn’t confined to just textual descriptions. In our multifaceted digital ecosystem, items span various media types like images, audio, or movies. For such media, the “content” can be derived from their inherent properties. For instance, image-based metadata might be pulled from visual patterns; audio metadata from elements like waveforms or spectral features; and for movies, aspects like genre, cast, or scene structure can be considered.
Integrating these diverse content dimensions allows recommendation systems to be more adaptable, offering refined suggestions across a wide range of items.
The data sparsity problem
Across an enormous number of items, a user will have rated only a few items, resulting in a very sparse user/item rating matrix.
Amazon has around a billion users and a billion items. Amazon’s recommendation engine is said to have the sparsest data for any recommendation engine in the world.
To tackle such sparsity, various techniques are deployed. Matrix factorization methods, for example, can predict potential ratings in these sparse areas, providing a more complete user-item interaction landscape. Additionally, hybrid recommendation systems, which combine elements of content-based and collaborative filtering, can generate meaningful recommendations even when user-item interactions are limited. By integrating these and other approaches, recommendation systems can effectively navigate and mitigate the challenges posed by sparse datasets.
The double-edged sword of social influence in recommendation systems
Recommendation systems can be significantly influenced by social dynamics. Indeed, our social circles often have a marked impact on our preferences and choices. For instance, friends tend to make similar purchases and rate products or services in similar ways.
On the positive side, leveraging social connections can boost recommendation relevance. If a system observes that individuals within a particular social group enjoyed a certain movie or product, it might make sense to recommend that same item to other members of the group. This could lead to increased user satisfaction and, potentially, higher conversion rates.
However, there’s a downside. Relying too heavily on social influence can introduce bias into the recommendations. It might inadvertently create echo chambers where users are only exposed to items their immediate social circle appreciate, limiting diversity and potentially missing out on products or services that could be more individually suited. Furthermore, this could lead to a self-reinforcing feedback loop, where the same items keep getting recommended, overshadowing other potentially valuable items.
Thus, while social influence is a powerful tool in shaping user preferences, it’s essential for recommendation systems to balance it with individual user behavior and broader trends to ensure a diverse and personalized user experience.
Areas of practical applications
Recommendation systems play a pivotal role in our daily digital interactions. To truly understand their significance, let’s delve into their applications across various industries.
Based on the comprehensive details provided about Netflix’s use of data science and its recommendation system, let’s look at the restructured statement addressing the points mentioned.
Netflix’s mastery of data-driven recommendations
Netflix, a leader in streaming, has harnessed data analytics to fine-tune content recommendations, with 800 engineers in Silicon Valley advancing this effort. Their emphasis on data-driven strategies is evident in the Netflix Prize challenge. The winning team, BellKor’s Pragmatic Chaos, used 107 diverse algorithms, from matrix factorization to restricted Boltzman machines, investing 2,000 hours in its development.
The results were a significant 10.06% improvement in their “Cinematch” system. This translated to more streaming hours, fewer subscription cancellations, and substantial savings for Netflix. Interestingly, recommendations now influence about 75% of what users watch. Töscher et al. (2009) highlighted a curious “one-day effect” suggesting shared accounts or user mood variations.
While the challenge showcased Netflix’s commitment to data, it also hinted at the potential of ensemble techniques in striking a balance between recommendation diversity and accuracy.
Today, elements of the winning model remain core to Netflix’s recommendation engine, but with ever-evolving technology, there’s potential for further refinements, like integrating reinforcement algorithms and improved A/B testing.
Here’s the source for the Netflix statistic: https://towardsdatascience.com/netflix-recommender-system-a-big-data-case-study-19cfa6d56ff5.
The evolution of Amazon’s recommendation system
In the early 2000s, Amazon transformed its recommendation engine by shifting from user-based collaborative filtering to item-to-item collaborative filtering, as detailed in a seminal 2003 paper by Linden, Smith, and York. The strategy switched from recommending products based on similar users to suggesting products linked to individual product purchases.
The essence of this “relatedness” was deciphered from observed customer purchasing patterns. If Harry Potter book buyers often bought a Harry Potter bookmark, the items were considered related. Yet, the initial system had flaws. For high-volume buyers, the recommendations weren’t as refined, leading Smith and his team to make necessary algorithmic tweaks.
Fast-forward a few years – during a 2019 re:MARS conference, Amazon highlighted its significant advancements in movie recommendations for Prime Video customers, achieving a twofold improvement.
The technique utilized for this was inspired by a matrix completion problem. This method involves representing Prime Video customers and movies in a grid and predicting the probability of a customer watching a particular movie. Amazon then applied deep neural networks to this matrix problem, leading to more accurate and personalized movie recommendations.
The future holds even more potential. With continued research and advancements, the Amazon team aims to further refine and revolutionize their recommendation algorithms, always striving to enhance the customer experience.
You can find the Amazon statistic here: https://www.amazon.science/the-history-of-amazons-recommendation-algorithm.
Now, let’s try to use a recommendation engine to solve a real-world problem.
Practical example – creating a recommendation engine
Let’s build a recommendation engine that can recommend movies to a bunch of users. We will use data put together by the GroupLens Research group at the University of Minnesota.
1. Setting up the framework
Our first task is to ensure we have the right tools for the job. In the world of Python, this means importing necessary libraries:
import pandas as pd
import numpy as np
2. Data loading: ingesting reviews and titles
Now, let’s import the df_reviews and df_movie_titles datasets:
df_reviews = pd.read_csv('https://storage.googleapis.com/neurals/data/data/reviews.csv')
df_reviews.head()
The reviews.csv dataset encompasses a rich collection of user reviews. Each entry features a user’s ID, a movie ID they’ve reviewed, their rating, and a timestamp of when the review was made.
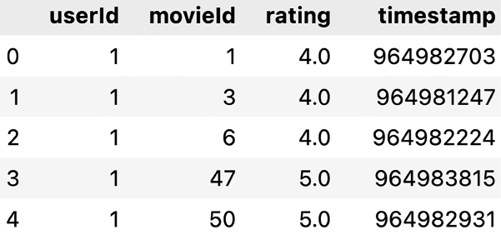
Figure 12.6: Contents of the reviews.csv dataset
The movies.csv dataset is a compilation of movie titles and their details. Each record usually contains a unique movie ID, the movie’s title, and its associated genre or genres.
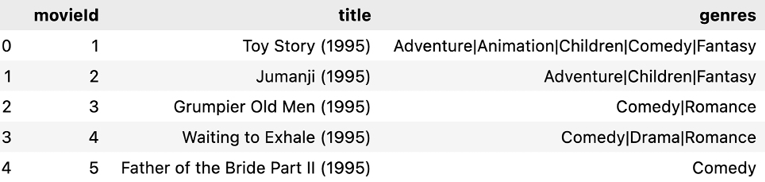
Figure 12.7: Contents of the movies.csv dataset
3. Merging data: crafting a comprehensive view
For a holistic perspective, we need to merge these datasets. The 'movieId' serves as our bridge between them:
df = pd.merge(df_reviews, df_movie_titles, on='movieId')
df.head()
The merged datasets should contain the following information:

Figure 12.8: Merged movie data
Here’s a brief on each column:
userId: A unique identifier for each user.movieId: A unique identifier for each movie.rating: Represents the rating assigned by a user to a movie, ranging from 1 to 5.timestamp: Denotes when a particular movie was rated.title: The movie’s title.genres: The genre(s) associated with the movie.
4. Descriptive analysis: gleaning insights from ratings
Let’s dive into the heart of our data: the ratings. A good starting point is to compute the average rating for each movie. Alongside, understanding the number of users who rated a movie can provide insights into its popularity:
df_ratings = pd.DataFrame(df.groupby('title')['rating'].mean())
df_ratings['number_of_ratings'] = df.groupby('title')['rating'].count()
df_ratings.head()
The mean rating for each movie should be the following:
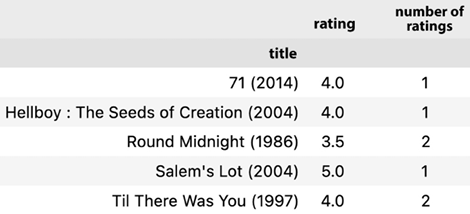
Figure 12.9: Calculating the mean rating
With these aggregated metrics, we can discern popular movies with high average ratings, potential blockbusters with numerous ratings, or hidden gems that might have fewer reviews but high averages.
This foundation will pave the way for the subsequent steps, where we’ll delve into building the actual recommendation engine. As we progress, our understanding of user preferences will refine, enabling us to suggest movies that resonate with individual tastes.
5. Structuring for recommendations: crafting the matrix
The next logical step is to convert our dataset into a structure optimized for recommendations. Visualize this structure as a matrix:
- Rows represent our users (indexed by
userId) - Columns signify movie titles
- Cells within the matrix are populated with ratings, revealing what a user thought of a specific movie
The pivot_table function in Pandas is a versatile tool that helps reshape or pivot data in a DataFrame to provide a summarized view. The function essentially creates a new derived table out of the original one:
movie_matrix = df.pivot_table(index='userId', columns='title', values='rating')
Note that the preceding code will generate a very sparse matrix.
6. Putting the engine to test: recommending movies
Let’s see our engine in action. Suppose a user has just watched Avatar (2009). How can we find other movies they might enjoy?
Our first task is to isolate all users who’ve rated Avatar (2009):
avatar_ratings = movie_matrix['Avatar (2009)']
avatar_ratings = avatar_ratings.dropna()
print("
Ratings for 'Avatar (2009)':")
print(avatar_ratings.head())
userId
10 2.5
15 3.0
18 4.0
21 4.0
22 3.5
Name: Avatar (2009), dtype: float64
From the preceding code, note the following:
- userId: This represents the unique identifier for each user in our dataset. The
userIdlist contains10,15,18,21, and22– the first five users in our data snapshot who have rated Avatar (2009). - Ratings: The numbers adjacent to each
userId(2.5,3.0,4.0,4.0, and3.5) represent the ratings these users assigned to Avatar (2009). The ratings range between1and5, where a higher value indicates a more favorable opinion about the movie. For example, User 10 rated Avatar (2009) a2.5, suggesting they found the movie average or perhaps slightly below their expectations, and User 22 rated it a3.5, expressing a slightly above-average appreciation for the movie.
Let’s build a recommendation engine that can recommend movies to a bunch of users.
Finding movies correlating with Avatar (2009)
By determining how other movies correlate in rating patterns with Avatar (2009), we can suggest movies that might appeal to fans of Avatar.
To present our findings neatly:
similar_to_Avatar=movie_matrix.corrwith(Avatar_user_rating)
corr_Avatar = pd.DataFrame(similar_to_Avatar, columns=['correlation'])
corr_Avatar.dropna(inplace=True)
corr_Avatar = corr_Avatar.join(df_ratings['number_of_ratings'])
corr_Avatar.head()
correlation number_of_ratings
title
'burbs, The (1989) 0.353553 17
(500) Days of Summer (2009) 0.131120 42
*batteries not included (1987) 0.785714 7
10 Things I Hate About You (1999) 0.265637 54
10,000 BC (2008) -0.075431 Understanding correlation
A higher correlation (close to 1) means a movie’s rating pattern is similar to Avatar (2009). A negative value indicates the opposite.
However, it’s crucial to approach the recommendations with caution. For instance, *batteries not included (1987) emerged as a top recommendation for Avatar (2009) fans, which might not seem accurate. This could be due to the limitations of relying solely on user ratings without considering other factors, like genres or movie themes. Adjustments and refinements would be needed for a more precise recommendation system.
The resulting table showcases movies that correlate in terms of user rating behavior with Avatar. The table produced at the end of our analysis lists movies in terms of their correlation to Avatar based on user ratings. But what does this mean in simpler terms?
Correlation, in this context, refers to a statistical measure that explains how one set of data moves in relation to another set of data. Specifically, we used the Pearson correlation coefficient, which ranges from -1 to 1:
- 1: Perfect positive correlation. This means if Avatar received a high rating from a user, the other movie also received a high rating from the same user.
- -1: Perfect negative correlation. If Avatar got a high rating from a user, the other movie got a low rating from the same user.
- 0: No correlation. The ratings of Avatar and the other movie are independent of each other.
In our movie recommendation context, movies with a higher positive correlation value (closer to 1) to Avatar are deemed to be more suitable recommendations for users who liked Avatar. This is because these movies have shown a pattern of receiving ratings similar to Avatar from the users.
By inspecting the table, you can identify which movies have a rating behavior akin to Avatar and, thus, can be potential recommendations for its fans.
This means that we can use these movies as recommendations for the user.
Evaluating the model
Testing and evaluation are critical. One way to evaluate our model is by using methods like train-test split, where a portion of data is set aside for testing. The model’s recommendations for the test set are then compared to actual user ratings. Metrics like Mean Absolute Error (MAE) or Root Mean Square Error (RMSE) can quantify the differences.
Retraining over time: incorporating user feedback
User preferences evolve. Retraining the recommendation model periodically with fresh data ensures its recommendations remain relevant. Incorporating a feedback loop where users can rate or review recommendations further refines the model’s accuracy.
Summary
In this chapter, we learned about recommendation engines. We studied the selection of the right recommendation engine based on the problem that we are trying to solve. We also looked into how we can prepare data for recommendation engines to create a similarity matrix. We also learned how recommendation engines can be used to solve practical problems, such as suggesting movies to users based on their past patterns.
In the next chapter, we will focus on the algorithms that are used to understand and process data.
Learn more on Discord
To join the Discord community for this book – where you can share feedback, ask questions to the author, and learn about new releases – follow the QR code below:
