
Chapter 13: Introducing H2O AI Cloud
In the previous sections of this book, we explored in great detail how to build accurate and trustworthy machine learning (ML) models on massive data volumes using H2O technology, and how to deploy these models for scoring on a diversity of enterprise systems. In doing so, we became familiar with the technologies of H2O Core (H2O-3 and H2O Sparkling Water) and its distributed in-memory architecture to perform model building steps in a horizontally scalable way, using familiar IDEs and languages. We got to know H2O Enterprise Steam as a tool for data scientists to easily provision H2O environments and for administrators to manage users. We learned the technical nature of the H2O MOJO, the ready-to-deploy scoring artifact generated and exported from built models, and we learned a great diversity of patterns for scoring MOJOs on diverse target systems, whether real-time, batch, or streaming. We also learned how enterprise stakeholders beyond data scientists view and interact with H2O at scale technology.
In this chapter, we will expand our knowledge by learning that H2O offers a larger end-to-end ML platform called H2O AI Cloud that includes multiple specialized model building engines, an MLOps platform to deploy and monitor models, a feature store to share features for model building and scoring, and a technology layer often not considered in the context of ML platforms – a low-code SDK to easily build AI applications on top of rest of the platform and an App Store to host them.
Importantly, we will see that the technologies and skills we have learned up until now are actually a subset of the larger H2O AI Cloud.
In this chapter, we're going to cover the following main topics:
- An H2O AI Cloud overview
- An H2O AI Cloud component breakdown
- H2O AI Cloud architecture
Technical requirements
You can sign up for a 90-day trial to the H2O AI Cloud by visiting https://h2o.ai/freetrial. This will allow you to use the components of the platform with your own data or with trial data supplied by H2O.
We will see that part of the H2O AI Cloud is the ability of data scientists to build AI applications using an open source low-code SDK called H2O Wave. You can start building your own H2O Wave AI applications on your local machine by visiting here: https://wave.h2o.ai/docs/installation.
An H2O AI Cloud overview
The H2O AI Cloud is an end-to-end ML platform designed to enable teams to seamlessly work through building models, trusting models, and deploying, monitoring, and governing models. In addition, the H2O AI Cloud includes an AI application development and hosting layer to allow various personas to interact with all steps in an ML life cycle – from applications expressing sophisticated visualizations to user interactions and workflows. The application SDK allows data scientists and ML engineers (and traditional software developers) to quickly prototype, finalize, and publish AI applications in a purpose-built way. For example, applications can be built for business users to view dashboards of customer churn predictions with analytics on reason codes and then respond to high churn candidates. Data scientists, on the other hand, can use an AI application to interactively validate model predictions against subsequent ground truth and track analytics around that. Alternatively, data scientists and ML engineers can use an AI application to automate retraining pipelines by orchestrating data drift alerts with model retraining and redeployment while tracking analytics and auditing.
This simplified ML life cycle with an AI application layer is shown in the following diagram, and the H2O AI Cloud is organized around these layers:
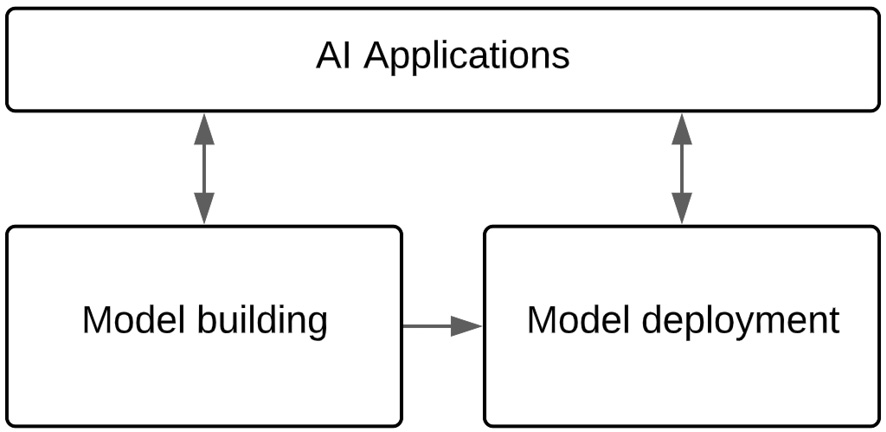
Figure 13.1 – A simplified ML life cycle with an AI app layer
H2O has built a modular, flexible, and fully capable end-to-end ML platform around this representation. The following diagram delineates the components of the H2O AI Cloud mapped to this life cycle:

Figure 13.2 – An H2O hybrid cloud end-to-end ML platform (the H2O at scale components shown in gray)
Before diving into each component and its capabilities, let's first get a high-level understanding:
- Model building: There are four separate and specialized model building engines and a tool for data scientists to self-service provision their environments and for administrators to manage and govern users. Each model building engine generates a ready-to-deploy scoring artifact for models that are built.
- Model deployment: An MLOps component is used to deploy, monitor, manage, and govern models.
- Feature store: A feature store is available to reuse features both across teams during model building and across models during scoring.
- AI applications: A low-code SDK is available to rapidly build, prototype, and then publish AI applications. The SDK includes widgets and templates to build sophisticated and interactive visualizations and workflows. Data scientists and ML engineers build the application in a familiar code-based way, focusing mostly on organizing and feeding data to templates and widgets while ignoring the complexities of web applications.
- AI App Store: AI applications are developed locally and then published to an AI App Store component for consumption by business, data science, and other enterprise stakeholders. Clinicians in healthcare, for example, may use an application to prevent patients from being discharged from the hospital prematurely, while business analysts use a different part of the application to understand how frequent this is predicted to happen and why.
- UI and API access to components: Users can interact with H2O AI components interactively from both the UI and through APIs. Component APIs allow programmatic and automated approaches to interacting with the platform and stitching components together in unique ways.
In the next section, we will understand each H2O AI Cloud component more fully. Before doing so, however, let's introduce ourselves to the components with a table overview to get our bearings:
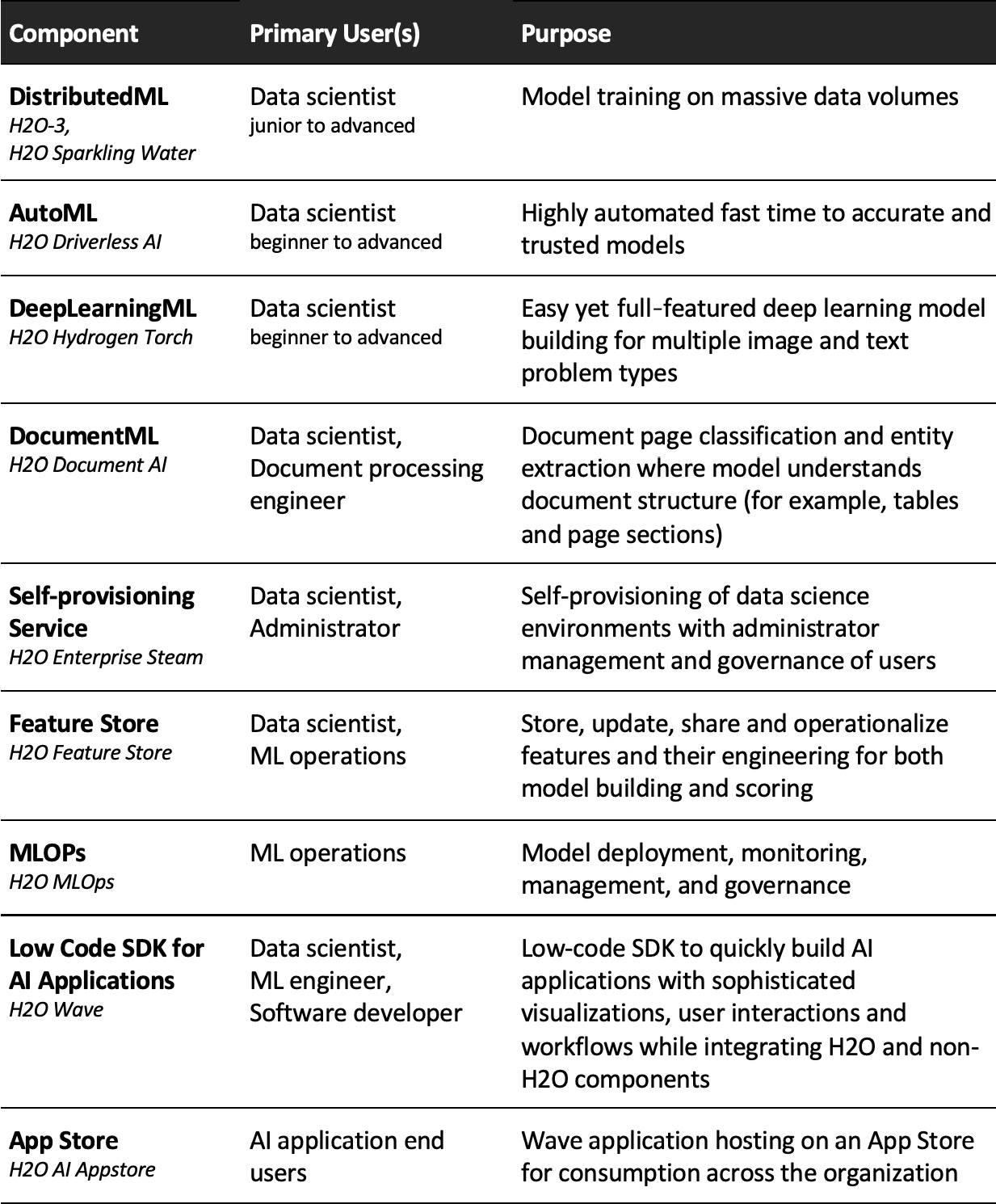
Figure 13.3 – A table summarizing H2O AI Cloud components
Finally, we need to relate H2O AI Cloud components to the focus of this book, which we will do in the following note.
How the Focus of This Book Relates to H2O AI Cloud
The focus of this book has been ML at scale with H2O, which alternatively has been called H2O at scale. We have focused on building ML models against massive datasets and deploying models to a diversity of enterprise scoring environments.
From a component standpoint, the focus has been on H2O Core (H2O-3 and H2O Sparkling Water), H2O Enterprise Steam, and the H2O MOJO. These components can be deployed either as (a) separate from H2O AI Cloud, or (b) as members of H2O AI Cloud, as shown in Figure 13.2. See Chapter 12, The Enterprise Architect and Security Views, for an elaboration of this point.
Now that we understand the fundamentals of H2O AI Cloud, its components, and how they relate to the focus of this book, let's expand our view and ML capabilities by elaborating further on each component.
H2O AI Cloud component breakdown
Let's take a deeper dive into each of the components.
DistributedML (H2O-3 and H2O Sparkling Water)
DistributedML has been the focus of model building for this book, where it is called H2O Core to represent either H2O-3 or Sparkling Water in that context. Fundamentally, you use H2O Core to build models on massive datasets.
For the purposes of this chapter, the main features and capabilities are presented in the upcoming subsection For more details, see Chapter 2, Platform Components and Key Concepts, to review the distributed in-memory architecture that enables model building on a massive scale. See Chapter 4, H2O Model Building at Scale – Capability Articulation, to review its main capabilities in greater detail.
Key features and capabilities
The key features and capabilities of H2O Core (H2O-3 and Sparkling Water) are as follows:
- Model building on massive data volumes: H2O Core has an architecture that partitions and distributes data into memory across multiple servers. Model building computation is done in parallel against this architecture, thus achieving scaling needs for massive datasets. The larger the dataset, the more horizontally scaled the architecture will be.
- Familiar data science experience: Data scientists build H2O models using familiar IDEs and languages (for example, Python in Jupyter notebooks) to express the H2O model building API. The API hides the complexities of the H2O scalable architecture from the user. To a data scientist, the experience fundamentally is that of writing code against data frames.
- Flexible data ingest: H2O Core has connectors to access diverse data sources and data formats. Data is transferred directly from source to H2O Core-distributed memory.
- Scalable data manipulation: Data is manipulated in the distributed architecture and thus is done at scale. The H2O API makes data manipulation steps concise. Sparkling Water specifically allows data manipulation using Spark APIs (for example, Spark SQL) and the conversion of Spark DataFrames to H2OFrames in the same coding workflow.
- State-of-the-art algorithms: H2O Core implements state-of-the-art ML algorithms for supervised and unsupervised problems, including, for example, XGBoost, a Gradient Boosting Machine (GBM), Generalized Linear Model (GLM), and Cox Proportional-Hazards (CoxPH), to name a few. These algorithms are run on the distributed architecture to scale to massive datasets.
- AutoML: H2O can build models using an AutoML framework that explores algorithm and hyperparameter space to build a leaderboard of best models. The AutoML framework is controllable through numerous settings.
- Explainability and auto-documentation: H2O Core implements extensive explainability capabilities and can generate auto-documentation to thoroughly describe model building and explain the resulting models.
- MOJO: Models built on H2O Core generate a ready-to-deploy and low-latency scoring artifact called a MOJO that can be flexibly deployed to diverse target environments. This was discussed in great detail in Chapter 9, Production Scoring and the H2O MOJO.
Let's move on to H2O AI Cloud's next model building engine.
H2O AutoML (H2O Driverless AI)
H2O Driverless AI is a highly automated AutoML tool built in part by Kaggle Grandmaster data scientists to incorporate data science best practices and AI heuristics to find highly accurate models in short amounts of time. Some of its key capabilities are rich explainability features, a genetic algorithm to iterate to the best model, and exhaustive feature engineering and selection to derive and use new features. Let's investigate these key features and capabilities.
Key features and capabilities
The H2O Driverless AI key features and capabilities are as follows:
- Problem types: H2O Driverless AI builds both supervised and unsupervised models:
- Supervised learning: For supervised learning on tabular data, H2O Driverless AI addresses regression, binary and multiclass classification, and time-series forecasting problems. For supervised learning on images, Driverless AI addresses image classification, and for natural language processing (NLP), it addresses text classification and context tagging problems.
- Unsupervised learning: For unsupervised learning, Driverless AI tackles anomaly detection, clustering, and dimensionality reduction problems.
- GPU support: Driverless AI can leverage GPUs for image and NLP problems, which run TensorFlow and PyTorch algorithms.
- Genetic algorithm: Driverless AI uses a proprietary genetic algorithm to iterate across dozens of models, each of which varies in its algorithm (for example, XGBoost, Generalized Linear Model, and LightGBM), its exploration of hyperparameter space, and its exploration of feature engineering space. The best models are promoted to the next iteration and new model variations are introduced during each iteration. This continues until it cannot find a better model based on the settings that users make.
- Feature engineering: During the genetic algorithm, Driverless AI applies dozens of transformers in exhaustive ways to engineer new features from those in the original dataset and determine which ones to include in the final model. These transformers are categorized as follows:
- Numeric: These are mathematical operations among two or more original features – for example, subtracting two features or clustering multiple features for the dataset and measuring the distance to a specific cluster for each observation.
- Categorical: These are transformations of category labels to numbers – for example, taking the average or frequency of the target variable for each category and assigning it to the category represented for each observation.
- Time and date: These are transformations of time and date fields to alternative time and date representations – for example, converting the date to the day of the week.
- Time series: These transformations derive new features useful for time-series problems – for example, using a lag time for a feature value.
- Text: These transformations convert strings to alternative representations – for example, using pre-trained Bidirectional Encoder Representations from Transformers (BERT) models to generate new language representations.
- Bring your own recipes: In addition to access to extensive expert settings, data scientists can control the automated ML process by importing their own code, which H2O calls recipes. These custom recipes can take the following form – scorer (your own performance metric used to optimize models in the genetic algorithm), feature engineering (your own engineered feature), or algorithm (your choice of ML algorithm to supplement familiar Driverless AI out-of-the-box algorithms).
- Interpretability (Explainability): Users can interact with diverse and full-featured interpretability techniques to explain the resulting models. These techniques can be applied at the global (entire model) or local (individual record) levels. These techniques include surrogate and actual model techniques, including K-Lime and Shapley, Decision Tree, Disparate Impact Analysis, Sensitivity Analysis, and Partial Dependence Plots. There are also explainers for time-series and NLP problems specifically.
- Auto-documentation: Each final model generated by the genetic algorithm creates extensively standardized (typically over 60 pages) auto-documentation that describes in great detail experiment overview, data overview, methodology, validation strategy, model tuning, feature transformations and evolution, a final model, and explainability. The document is in paragraph, tabular, and graphic form.
- MOJO: Each final model generated by the genetic algorithm creates a ready-to-deploy and low-latency MOJO that is flexibly deployed to diverse target environments. This is a similar technology to that discussed in Chapter 9, Production Scoring and the H2O MOJO, for H2O at scale (H2O-3 and Sparkling Water).
Important Note
The MOJO for Driverless AI performs the feature engineering for features derived during the automated model building process.
Let's now move on to the DeepLearningML engine.
DeepLearningML (H2O Hydrogen Torch)
H2O Hydrogen Torch is a UI-based deep learning engine that empowers data scientists of all skill levels (and perhaps analysts for some use cases) to easily build state-of-the-art computer vision and NLP models. The key features and capabilities are as follows.
Key features and capabilities
The H2O Hydrogen Torch features and capabilities are as follows:
- Problem types: Currently, Hydrogen Torch addresses six computer vision (CV) and five NLP problem types, described briefly as follows:
- Image classification (CV): Images are classified into one or more sets of classes – for example, an image is classified as car versus truck.
- Image regression (CV): A continuous value is predicted from an image – for example, the steering angle from a self-driving car image is positive 20 degrees from the center line.
- Object detection (CV): An object (or objects) is classified from an image and its position coordinates are identified as a bounding box – for example, multiple cars are identified, each with a rectangle defined around it.
- Semantic segmentation (CV): An object (or objects) is classified as well as its exact shape, defined by pixel positions – for example, the exact outline of a person or all people in an image.
- Instance segmentation (CV): This is the same as semantic segmentation, but when multiple objects of the same class are identified in instance segmentation, they are treated separately, whereas in semantic segmentation, they are treated as one object.
- Image metric learning (CV): Predicts the similarity between images – for example, for a picture of a retail product, it will find the likelihood that a new picture is the same product.
- Text classification (NLP): Classifies text (document, page, and snippet) into a class – for example, classifying the sentiment or intent of text.
- Text regression (NLP): Predicts a continuous value from text – for example, prediction of a person's salary from a resume.
- Text sequence to sequence (NLP): Converts text sequences in one context to text sequences in another context – for example, converting a document into a summary.
- Text token classification (NLP): Classifies each word in a text to a label – for example, identifying the United Nations as an organization (an example of Named Entity Recognition (NER)) or identifying a word as a noun or verb (example of Part-of-Speech (POS) tagging).
- Text metric learning (NLP): Predicts the similarity between two sets of text – for example, identifying duplicate information or similar documents.
- Ease of building deep learning models: Hydrogen Torch is a no-code approach to building deep learning models. The user interacts with a UI that has extensive controls on hyperparameter tuning and a rich interface to quickly iterate, understand, and evaluate model outcomes. Models can be exported for deployment to Python or H2O MLOps environments.
- Modes for user skill set: The Hydrogen Torch training UI adapts to the user skill level by exposing fewer or more model building settings, according to whether the user is a novice, skilled, an expert, or a master.
Now, let's move on to a model building engine that focuses on documents.
DocumentML (H2O Document AI)
Documents typically represent a vast untapped data source for enterprises to apply ML techniques to automate processing steps, and thus save large amounts of time and money compared to manual processing. H2O's Document AI engine learns from documents to accomplish this automation.
Document AI goes beyond simple Optical Character Recognition (OCR) and NLP by learning to recognize information structures of documents such as tables, forms, logos, and sections. The Document AI model is trained to extract text entities from documents using these capabilities. Documents can thus be processed to extract specific information from medical lab results, financial statements, loan applications, and so on. This output can then drive analytics and workflows from these documents, which become increasingly more valuable as the volume of document processing grows. Document AI can also classify an entire document to further automation of document processing pipelines.
Key features and capabilities
Let's breakdown these capabilities further:
- Document ingest: Ingests documents such as PDFs, images, Word, HTML, CSV files, text files, emails, and others.
- Preprocessing: Document AI uses OCR and NLP capabilities to perform multiple preprocessing steps, such as handling embedded text (for example, PDF metadata) and logos, and orientating, deskewing, and cropping pages.
- Apply document labels: Users access a UI to apply labels to document text. Models will be trained to recognize these labeled entities. For example, on a medical lab document, the user applies labels to the patient name, the lab name, the lab address, the test name, the test result value, the test result unit, the test result normal range, and so on.
- Train models: Document AI trains against a labeled document set. It learns to associate text with labels in the larger context of the structure of the document – for example, lab results are reported from rows in a table. Note that models are trained against a known document set and afterward will be able to pull information from documents they have never seen before. For example, each lab produces its own report (its own design, the styling of tables, number of pages, the position of the patient name in the document, and so on). Even though the model is trained on a small set of lab reports (typically 100 or so), it can then pull information from documents sent from a lab it has not been trained on.
- Post-processing: Document AI allows users to customize and standardize how results are outputted. For example, users can define an output JSON structure with date output formats standardized.
- Model deployment: Models can be exported and deployed to H2O MLOps or a Python environment of your choice.
Now that we have explored the four specialized model building engines on H2O AI Cloud, let's see how features for those engines can be shared and operationalized.
A self-provisioning service (H2O Enterprise Steam)
H2O Enterprise Steam allows users to self-provision model building environments and administrators to govern users and their resource consumption. As with H2O Core and the scoring artifact it generates called the MOJO, Enterprise Steam is considered a key component of H2O ML at scale and was introduced in Chapter 2, Platform Components and Key Concepts, and then explored in detail in Chapter 11, The Administrator and Operations View.
Note that in that context, Enterprise Steam was used to self-provision and manage H2O Core environments only, but in the context of the H2O AI Cloud, it is used to manage all H2O model building engines. Let's review its key capabilities.
Key features and capabilities
The key capabilities of H2O Enterprise Steam are listed briefly as follows:
- Easy self-provisioning of H2O model building environments: Data scientists can define, launch, and manage their H2O model building environments from the Enterprise Steam UI or API. Note that, currently, this is true for DistributedML (H2O Core) and AutoML (Driverless AI) environments. Hydrogen Torch and Document AI environments currently are launched as applications, but they are road-mapped to consolidate into the Enterprise Steam self-provisioning framework.
- Administrator management and governance of users: Administrators manage users and define the amount of resources (CPU and memory) they can use when provisioning environments, including how long those environments sit idle before spinning down.
Let's move on now to the Feature Store component.
Feature Store (H2O AI Feature Store)
H2O AI Feature Store is a system to organize, govern, share, and operationalize predictive ML features across the enterprise in both the model building and live scoring contexts. This saves significant time for data scientists to discover features and for both data scientists and ML engineers to transform raw data into these features. Let's explore the capabilities further.
Key features and capabilities
Here are some key features of the H2O AI Feature Store:
- Versatile feature publishing and search workflow: Data scientists and engineers engineer feature pipelines using pre-built integrations into Snowflake, Databricks, H2O Sparkling Water, and other technologies. The resulting features are outputted to the H2O AI Feature Store with over 40 metadata attributes associated with the feature. This cataloging of features and their attributes allows other data scientists to search for relevant features and for the Feature Store's built-in AI to recommend features.
- Scalable and timely feature consumption: Each feature in the Feature Store has a defined duration until it is refreshed. Features can be stored offline for training and batch scoring or stored online for low-latency real-time scoring.
- Automatic feature drift and bias detection: Features are automatically checked for data drift and users are alerted when drift is detected. This can be essential in deciding to retrain models with more recent data. Features are also automatically checked for bias and alert users when bias is detected. This can be essential in retraining models to remove bias.
- Access management and governance: H2O AI Feature Store integrates with the enterprise identity provider to authenticate users and authorize access to features. Features and their metadata are versioned for regulatory compliance and to backtest models against ground truth.
H2O AI Cloud has a fully capable model operations component. Let's learn more about that next.
MLOps (H2O MLOps)
H2O MLOps is a platform to deploy, manage, monitor, and govern models. These can be either models generated from any of the H2O model building engines (DistributedML, AutoML, DeepLearningML, or DocumentML) or models from non-H2O software (for example, scikit-learn or MLflow). Note that H2O MLOps workflows can be completed using the UI or API, with the latter essential for integrating into continuous integration and continuous deployment (CI/CD) workflows. Major capabilities are elaborated as follows.
Key features and capabilities
Here are the key features of H2O MLOps:
- Model deployment: Easy deployment of H2O and non-H2O models. Scoring is available as a REST endpoint for both real-time and batch scoring. Models are deployed as either a single model (simple deployment), champion/challenger (compare a new model to current model where the only current model is live), or an A/B test (multiple live models with live data are routed among them in configured proportions). Models are deployed to defined environments, typically development and production, but you may add more.
- Model monitoring: Models are monitored for health, scoring latency, data drift, fairness (bias) degradation, and performance degradation. Alerts are presented on the monitoring dashboard and sent to configured recipients. Alerts can be used to trigger model retraining and deployment.
- Model management: Models can be compared and evaluated, promoted to a registry, and then deployed. Models are associated with extensive metadata, allowing traceability to model building details and evaluation against other models. Models in the registry (and subsequent deployment) are versioned. Deployed models can be rolled back to previous versions.
- Model governance: The versioning and traceability achieved through model management create a lineage of model history. Users have role-based access with actions that are audited. Administrators have a dedicated dashboard to provide visibility across all users, models, and audit logs. These capabilities combine a result in an overall governance process that minimizes model risk and facilitates regulatory compliance.
We started this chapter by recognizing an application layer that integrates the rest of the H2O AI Cloud platform. Let's learn more about that.
Low-code SDK for AI applications (H2O Wave)
H2O Wave is an open source and low-code Python SDK to build real-time AI applications with sophisticated visualizations. Low code is achieved by abstracting the complexities of web application coding away from the application developer while exposing higher-level UI components as templates, themes, and widgets. Data scientists and ML engineers are intended as developers (as well as software developers themselves).
Examples of H2O Wave applications have been built by H2O data scientists as capability demonstrators. These can be found on the H2O AI Cloud 90-day evaluation site at https://h2o.ai/freetrial. Additional examples are on the H2O public GitHub repository at https://github.com/h2oai/wave-apps.
How Do I Try Building Wave Applications?
Instructions to download the Wave server and SDK to build your own applications can be found at https://wave.h2o.ai/docs/installation.
Key features and capabilities
The following are the key features and capabilities of H2O Wave:
- Low-code SDK: Data scientists and ML engineers focus on specifying templates and widgets and feeding data into them to create sophisticated visualizations, dashboards, and workflows. The complexities of web application code are abstracted away from the developer.
- Extensive native data connectors: You have access to over 160 connectors to data sources and sinks from the SDK.
- Native H2O APIs: The SDK includes H2O APIs that integrate other H2O AI Cloud components. This enables data scientists and ML engineers to integrate aspects of the ML life cycle as a backend to the application visualizations and workflows.
- Use any Python package: Applications are isolated as containers, thus allowing any Python package to be used by the application – for example, NumPy and pandas for data manipulation and Bokeh and Matplotlib for data visualizations, to name just a few.
- Integrate non-H2O technology: When Python packages in your application represent public APIs such as the Twitter API, AWS service APIs, or your own private Python APIs, Wave applications can integrate non-H2O technology into its visualizations and workflows. Wave applications can thus be built as single panes of glass across multiple technologies.
- Publish to H2O App Store: Wave applications are developed locally and then published to the H2O AI Cloud App Store for enterprise consumption.
Let's now take a look at the H2O App Store.
App Store (H2O AI App Store)
The H2O AI App Store hosts your H2O Wave applications in your H2O AI Cloud instance. H2O Wave applications are hosted in a searchable and role-based way. Users logged in to the App Store see only the applications they are allowed to use and can find them by custom-defined categories or by search. Wave application developers publish to the App Store, and administrators manage the App Store.
Application consumers thus access and use Wave applications through the App Store, though data scientists and ML engineer developers may prototype with consumers locally before publishing to the App Store.
Let's now get a high-level understanding of the H2O AI Cloud architecture.
H2O AI Cloud architecture
We will not dive deep into H2O AI Cloud Architecture but will review three important architecture points:
- Components are modular and open: The platform's modular architecture allows enterprises or groups to use the components they need and to hide and ignore the ones they do not. H2O AI Cloud is also open – its components can coexist and interact with the larger enterprise ecosystem, including non-H2O AI/ML components. The MLOps component, for example, can host non-H2O models, such as scikit-learn models, and the AI application Wave SDK can integrate non-H2O APIs with its own.
- Cloud-native architecture: H2O AI Cloud is built on a modern Kubernetes architecture that achieves efficient resource consumption among cloud servers. In addition, H2O workloads on the AI Cloud are ephemeral – they spin up when needed, spin down when not in use, and retain state when spinning up again. The H2O AI Cloud also leverages the cloud service providers' managed services – for example, using the cloud-managed Kubernetes service and maintaining state in a managed PostgreSQL database.
- Flexible deployment: H2O AI Cloud can be deployed in an enterprise's cloud, on-premises, or in a hybrid environment. Alternatively, it can be consumed as a managed service where H2O hosts and manages the enterprise's H2O AI Cloud platform in H2O's cloud environment.
These architecture points combined with the capabilities of each component mean that enterprises can fit the H2O AI Cloud to their specific environment, use case needs, and stage of their AI transformation journey.
Let's summarize what we've learned in this chapter.
Summary
In this chapter, we expanded our view beyond H2O ML at scale, which has been the focus of this book to this point. We did this by introducing H2O's end-to-end ML platform called H2O AI Cloud. This platform has a broad set of components in the model building and model deployment steps of the ML life cycle and introduces a lesser-considered layer to this flow – easy-to-build AI applications and an App Store to serve them. We learned that H2O AI Cloud has four specialized engines for building ML models – DistributedML, AutoML, DeepLearningML, and DocumentML. We learned that MLOps has a full capability set around deploying, monitoring, managing, and governing models for scoring. We also learned that a Feature Store is available to centralize and reuse features for model building and model scoring.
Importantly, we learned that the focus of this book, building ML models on massive datasets and deploying to enterprise systems for scoring (what we have called H2O at scale), uses technology (H2O Core, H2O Enterprise Steam, and H2O MOJO) that is actually a subset of the larger H2O AI Cloud platform.
We made the point thatH2O at scale technology can be deployed separately from H2O AI Cloud or as a part of the larger platform. In the next chapter, we are going to see additional capabilities that H2O at scale takes on by being a member of the H2O AI Cloud.