
Chapter 14: Machine Learning Integration
Machine learning (ML) is one of the cornerstones of today’s computing for any software-related company. ML models are capable of making predictions or deductions based on past experience, provided as training data. This enables a wide variety of applications with large benefits to any organization.
Because it relies on training data, ML is closely tied to data mining, data processing, and, in general, any kind of extract, transform, load (ETL) process. Training data must be properly cleaned, formatted, and classified before it can be fed to a model – a process that greatly affects the effectiveness of the model itself. Because of this, services such as AWS Glue offer ML-specific features and integrations, catered to making ML easier and more effective to use.
Training data preparation is not the only relationship ML has with ETL processes – it can also be used to enhance and provide new transformations within the processes themselves, enabling new capabilities that were not possible before. ML models can be used, for instance, to automatically detect duplicate data or to tag columns in datasets based on specific properties.
In this chapter, we will cover the following topics:
- Glue ML transformations
- SageMaker integration
- Developing ML pipelines with Glue
By the end of this chapter, you will understand how ML transformations work with Glue, how to combine Glue and SageMaker effectively to power all your ML needs, and how to deploy an ML pipeline in the AWS cloud using Glue.
Technical requirements
For this chapter, the only requirement is that you have access to this book’s GitHub repository page (https://github.com/PacktPublishing/Serverless-ETL-and-Analytics-with-AWS-Glue).
Glue ML transformations
As mentioned previously, ML is not just an entity that reads the output data from ETL processes, but also one that powers its transformations. ML models enable a wide variety of operations that were not possible before due to computer intelligence limitations.
Because of this, Glue started to offer ML powered-operations with specific purposes under the ML transforms feature. As the name suggests, ML transforms are specific kinds of Glue transforms that are powered by ML models but must be trained and prepared before they can be used. Once they are ready, they can be called from your ETL job’s code, just like other Glue transforms.
At the time of writing, Glue has only released one ML transform, FindMatches, which will automatically find duplicated records within a dataset. Even though this seems like a simple task (most ETL engines could provide this by simply comparing records and checking if they are equal, or if they share a primary key), ML allows for duplicate detection, even in scenarios where records don’t have the same identifier or primary key, or when all the fields are not the same.
The FindMatches operation enables use cases that were not possible or considerably harder before, such as fraud detection (where a user may have created a duplicate account while trying to avoid a ban) or finding duplicates in a product catalog (where two entries may have different capitalization or spelling but refer to the same product).
As mentioned earlier, ML transforms must be trained, which means you will need sample training data, but the transformation must be fine-tuned to the specifics of your dataset and use case. ML transforms also abstract most of the logic that goes into training an ML model, enabling data engineers to take advantage of ML without necessarily being experts on it.
In this section, we’ll go through the life cycle of an ML transform. We’ll learn how to create one, train it, and use it in ETL jobs.
Creating an ML transform
Before the training stage, an ML transform must be created and configured according to the desired results. To create an ML transform, you must provide the following:
- Job configuration parameters: Just like with ETL jobs, the transform will need an IAM role, resource configuration, and security configurations.
- Source dataset parameters: The dataset to be read, plus the column within it to be used as a primary key.
- ML tuning parameters: As with other ML models, the transformation can be configured to favor precise or non-strict results, where the non-strict configuration would give more results but also a larger number of false positives. A Glue ML transform also allows the user to decide between spending extra resources to make the transform more accurate or saving costs by having fewer results at the cost of less accuracy.
Once these have been set, the transform is created and is set to the Needs training state. Transforms in this state cannot be used in ETL jobs, as they are required to go through the model training process first.
Training an ML transform
ML transforms follow a supervised learning mechanism called labeling. Within ML, data labeling is a mechanism by which a human actor provides context to a dataset so that a machine can learn and understand it. For instance, when creating an image object recognition ML model, a human could take a set of pictures and label them based on the object shown in them (for example, “car”, “bicycle”, or “orange”). This labeling can be as simple or as complex as required, and with it, the ML model can understand the context of what it is trying to recognize based on the labels.
The same mechanism applies here. When training an ML transform, Glue will take a sample of the records of the specified input dataset and provide it in a pre-formatted CSV file in an S3 path of the user’s choice. The user can then download the file, inspect the records, and label them accordingly by filling out the label column in the CSV file. For instance, let’s say we have the following sample records:
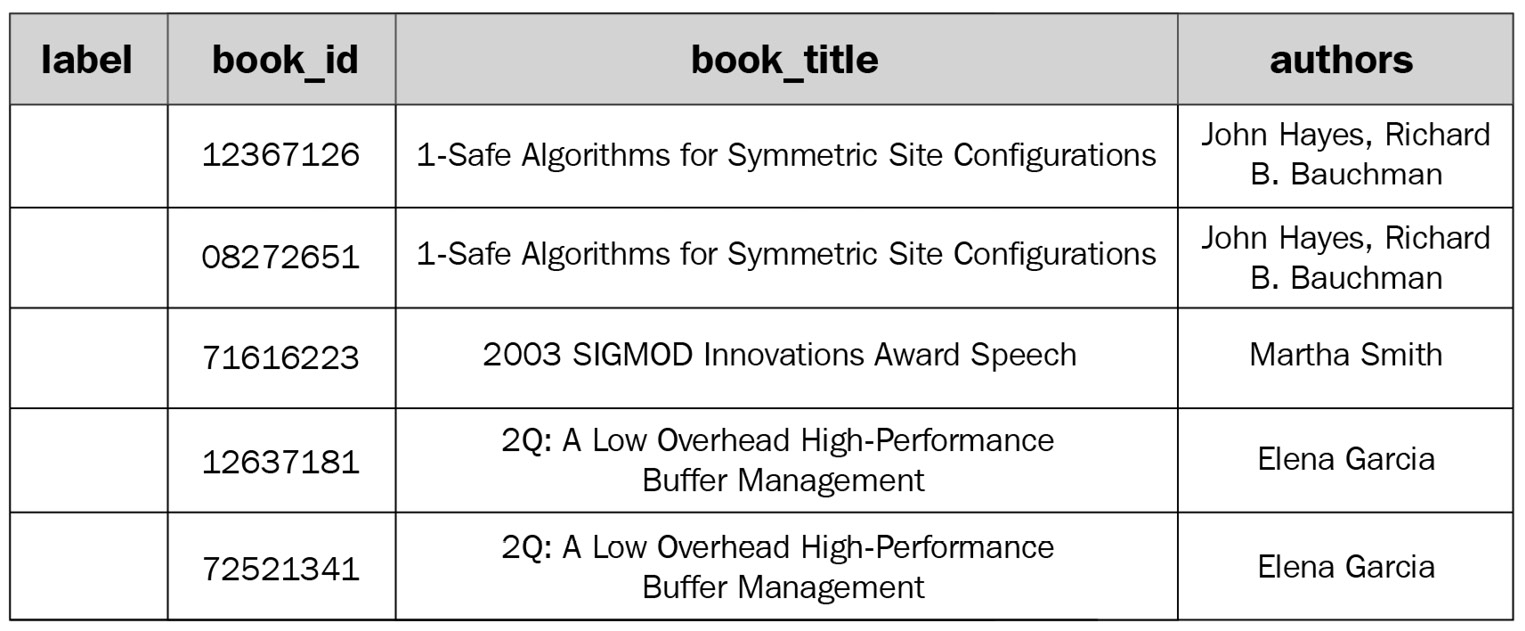
Figure 14.1 – Sample records with an empty label column
The labeling should look like this, considering we are trying to identify duplicated records:

Figure 14.2 – Sample records with a filled label column
As you can see, the labeling process consists of setting the same label identifier for records that refer to the same book, even if the records are slightly different in terms of title or authors. This process is quite literally teaching the ML model how different records refer to the same entity.
There are several considerations regarding how this works:
- The value of the label column can be anything (a number, a letter, or a word), so long as it is consistent and the same for equal rows.
- The file will also contain a second column called labeling_set_id. This column identifies different groups of rows with their own, separate labeling. Label values can be repeated across different labeling sets without causing a match.
- The file you upload to S3 for Glue to take as labels must be a UTF-8-encoded CSV file, the columns of which must be the same as the source dataset’s, plus the label and labeling_set_id columns.
Once the labeling file is ready, it can be uploaded to S3 and provided to Glue so that it can train the transform’s model. Upon being uploaded, Glue can perform two calculations:
- Transform quality estimation: This is an estimation of how good the transform is at doing its job, as specified by several percentage values.
- Column importance: This calculation determines how relevant the columns in the dataset are to the success of the transform. Irrelevant columns can be omitted and the transform would still be able to find matches.
The labeling process is repeatable and can be done an unlimited number of times. If the results of the quality estimation process (or the results of your ETL jobs that rely on the ML transform) are not good enough, the labeling process can be repeated to improve the accuracy of the model through human curation.
Using an ML transform
Once the transform has been trained at least once, it will change status to Ready for use. A transformation in this state can be used within ETL jobs. The FindMatches ML transform can be used in two modes: regular and incremental. Let’s start by looking at a regular invocation:
findmatches_result = FindMatches.apply(
frame = my_dynamic_frame,
transformId = "tfm-d03f274ad2f0136dacc5bcb54deced1eea54371a", transformation_ctx = "findmatches")
As you can see, the transform simply needs the DynamicFrame to apply the transformation to, as well as the ID of the trained transformation. The result of this operation (findmatches_result) will be a DynamicFrame with the same schema as the input one, but with two added columns:
- match_id: If the ML model considers two rows are the same, they will have the same value for this column – for instance, two matching rows may have a match_id value of 2, whereas a different pair of matching rows may have a value of 3.
- match_confidence_score: This represents a number between 0 and 1 that estimates the quality of the decision made by the model.
Using these two columns, a pipeline could automatically cull duplicated records, provided that the confidence score is high enough, for example.
Using FindMatches in this way lets users detect duplicates in a dataset. However, it can cause challenges. If new records were to come in and had to be matched against the previous ones, they would have to be added to the already-existing table, and the transform would have to be executed against the entire dataset. This approach is doable but will increase the execution time and resource consumption as the dataset becomes larger. Because of this, Glue provides an incremental way of using a transform:
findincrementalmatches_result = FindIncrementalMatches.apply(
existingFrame = my_dynamic_frame,
incrementalFrame = my_incremental_data,
transformId = "tfm-d03f274ad2f0136dacc5bcb54deced1eea54371a", computeMatchConfidenceScores = true,
transformation_ctx = "findincrementalmatches")
When using FindIncrementalMatches, several parameters must be provided:
- existingFrame: This represents the already existing and cleaned dataset.
- incrementalFrame: This represents the batch of new records that must be matched against the already-existing ones.
- transformId: This is the ID of the trained transformation.
- computeMatchConfidenceScores: A Boolean value that determines whether the match_confidence_score column should be generated or not.
Using FindIncrementalMatches allows for faster, easier, and less resource-intensive match detection and should always be used for incremental setups.
Running ML training tasks and ML ETL jobs
Training an ML model and using ML-based transformations is a resource-intensive task that often requires additional memory. Because of this, it is always recommended to use larger EC2 instance types, or in the case of Glue resources, worker types. When training an ML transformation or running an ML-based ETL job, we recommend always using the G.2X worker type unless you know the task is simple and small in advance.
SageMaker integration
Amazon SageMaker is AWS’s primary service for ML development. It provides a set of tools and features that lets users handle all the stages of the ML development pipeline, from data collection and preparation to model deployment and hosting.
Just like any other ML tool, SageMaker relies on the concept of model training to get models up to the accuracy level expected from them. And as we mentioned previously, training ML models usually requires large amounts of data to be prepared and processed. Because of this, SageMaker offers native integration with Apache Spark (https://docs.aws.amazon.com/sagemaker/latest/dg/apache-spark.html), which provides model-training capabilities using an AWS-tailored version of Spark.
One of the most important features SageMaker offers is serverless notebooks (https://docs.aws.amazon.com/sagemaker/latest/dg/nbi.html). A notebook instance is a serverless EC2 instance that runs Jupyter (https://jupyter.org), a web-based code execution service that lets users run code and visualize results interactively through the concept of notebooks. Code running in notebooks can be written in a variety of languages and use as many external libraries and frameworks as necessary, including Apache Spark. That said, the code within the notebook is usually executed locally unless a framework provides the capabilities to do otherwise.
To execute SageMaker features using Apache Spark jobs in a proper cluster environment, SageMaker offers AWS Glue integration. This allows users to execute Spark code written in a SageMaker notebook in a Glue Development Endpoint rather than locally within the notebook instance – which is always recommended to take advantage of Spark’s concurrent execution model.
Glue-integrated SageMaker notebooks have the following limitations and considerations:
- They can only be launched from the Glue web console.
- The Development Endpoint they attach to must be launched in a VPC.
- Just like with ETL jobs, the security group attached must contain a self-referencing inbound rule that allows all traffic. This ensures that communication between the notebook and the endpoint, as well as between all the nodes of the endpoint, is possible.
Once a notebook has been launched, the Sparkmagic kernel can be used to run code within the Development Endpoint. Even though this feature was originally designed to run the SageMaker Spark library, you can also use it to interactively run and debug your regular ETL job code in a notebook easily.
In the next section, we’ll discuss ways to orchestrate the elements we discussed previously into a pipeline using Glue and SageMaker.
Developing ML pipelines with Glue
The combination of SageMaker’s model-hosting features and libraries, plus Glue’s data preparation and orchestration features, allow you to create complex and highly-configurable ML pipelines. In this architecture, each service is responsible for different roles:
- Glue handles data handling and orchestration. Data handling includes extraction, processing, preparation, and storage. Orchestration refers to the overall execution of the pipeline itself.
- SageMaker handles all ML-related tasks such as model creation, training, and hosting.
Several components are critical to this, as follows:
- Glue workflows are the main form of orchestration in Glue. Workflows allow users to define graph-based chains of crawlers, ETL jobs, and triggers, and to see their execution visually in the web console.
- Python Shell jobs are a sub-class of Glue ETL jobs that are designed to run plain Python scripts instead of PySpark ones. They are similar to AWS Lambda functions but come with fewer restrictions since they don’t have a time or memory limit. Python Shell jobs are typically used to automate tasks in an ETL pipeline using the AWS SDK or to run any code that does not need the capabilities of Spark in a cheaper, faster-to-launch environment.
- SageMaker Model hosting allows users to create an ML model and host it in the AWS cloud. Users don’t have to worry about managing hardware or infrastructure to hold the model, and SageMaker provides tools to train and access the model in different ways.
A Glue-based ML pipeline would consist of a workflow where the following steps take place:
- Data extraction: A Spark-based Glue ETL job obtains data from a source and stores it in intermediate, temporary storage, such as S3.
- Data preparation: A second Spark-based Glue ETL job takes the output of Step 1 and prepares the dataset for ML usage using ETL transformations.
- Model creation and training: Using the AWS SDK, a Glue Python Shell job creates an ML model hosted in SageMaker and starts a SageMaker training job using the dataset that was created in Step 2. Once the model has been trained, a SageMaker inference endpoint is created to let other applications use the model.
Interaction with the workflow (starting it and notifying its completion) can be handled with Amazon SQS queues and messaging (https://aws.amazon.com/sqs/).
Parts of the pipeline could be replaced by other services if Glue’s capabilities are not enough, although orchestration would have to be handled with a different feature since Glue workflows only orchestrate Glue resources. The following are some examples:
- The data extraction phase could be handled by any other ETL service in AWS, such as Amazon EMR, AWS Batch, or AWS Data Exchange.
- The data preparation phase could potentially be handled better by AWS Glue DataBrew, a service specifically designed for visual data preparation. Alternatively, you could also use Amazon EMR or AWS Batch.
- Pipeline orchestration can be handled by AWS Step Functions, CloudWatch events, or even Lambda functions.
With this, we’ve discussed everything about ML data pipelines using Glue.
Summary
In this chapter, we discussed all aspects of ML within AWS Glue. We talked about Glue ML transforms, what they are, how they are trained, and how they can be used. We also discussed AWS SageMaker and how it can integrate with Glue resources to accelerate the execution of ML code in notebooks. Finally, we analyzed reference architectures and services for ML pipelines using AWS Glue and SageMaker.
These concepts should have given you a complete overview of how Glue can be used for ML purposes, and how Glue can fit into your ML architecture in the AWS cloud. In the next chapter, we will talk about the data lake architecture and designing use cases for real-world scenarios.