
As explained in Chapter 2, Data Pipelines and Modeling, most complex machine learning problems can be reduced to optimization as our final goal is to optimize the whole process where the machine is involved as an intermediary or the complete solution. The metric can be explicit, such as error rate, or more indirect, such as Monthly Active Users (MAU), but the effectiveness of an algorithm is finally judged by how it improves some metrics and processes in our lives. Sometimes, the goals may consist of multiple subgoals, or other metrics such as maintainability and stability might eventually be considered, but essentially, we need to either maximize or minimize a continuous metric in one or other way.
For the rigor of the flow, let's show how the linear regression can be formulated as an optimization problem. The classical linear regression needs to optimize the cumulative ![]() error rate:
error rate:

Here, ![]() is the estimate given by a model, which, in the case of linear regression, is as follows:
is the estimate given by a model, which, in the case of linear regression, is as follows:
(Other potential loss functions have been enumerated in Chapter 3, Working with Spark and MLlib). As the ![]() metric is a differentiable convex function of a, b, the extreme value can be found by equating the derivative of the cumulative error rate to
metric is a differentiable convex function of a, b, the extreme value can be found by equating the derivative of the cumulative error rate to 0:

Computing the derivatives is straightforward in this case and leads to the following equation:
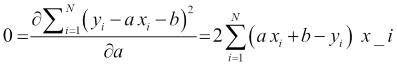

This can be solved to give:

Here, avg() denotes the average overall input records. Note that if avg(x)=0 the preceding equation is reduced to the following:

So, we can quickly compute the linear regression coefficients using basic Scala operators (we can always make avg(x) to be zero by performing a ![]() ):
):
akozlov@Alexanders-MacBook-Pro$ scala Welcome to Scala version 2.11.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_40). Type in expressions to have them evaluated. Type :help for more information. scala> import scala.util.Random import scala.util.Random scala> val x = -5 to 5 x: scala.collection.immutable.Range.Inclusive = Range(-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5) scala> val y = x.map(_ * 2 + 4 + Random.nextGaussian) y: scala.collection.immutable.IndexedSeq[Double] = Vector(-4.317116812989753, -4.4056031270948015, -2.0376543660274713, 0.0184679796245639, 1.8356532746253016, 3.2322795591658644, 6.821999810895798, 7.7977904139852035, 10.288549406814154, 12.424126535332453, 13.611442206874917) scala> val a = (x, y).zipped.map(_ * _).sum / x.map(x => x * x).sum a: Double = 1.9498665133868092 scala> val b = y.sum / y.size b: Double = 4.115448625564203
Didn't I inform you previously that Scala is a very concise language? We just did linear regression with five lines of code, three of which were just data-generation statements.
Although there are libraries written in Scala for performing (multivariate) linear regression, such as Breeze (https://github.com/scalanlp/breeze), which provides a more extensive functionality, it is nice to be able to use pure Scala functionality to get some simple statistical results.
Let's look at the problem of Mr. Galton, where he found that the regression line always has the slope of less than one, which implies that we should always regress to some predefined mean. I will generate the same points as earlier, but they will be distributed along the horizontal line with some predefined noise. Then, I will rotate the line by 45 degrees by doing a linear rotation transformation in the xy-space. Intuitively, it should be clear that if anything, y is strongly correlated with x and absent, the y noise should be nothing else but x:
[akozlov@Alexanders-MacBook-Pro]$ scala Welcome to Scala version 2.11.7 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_40). Type in expressions to have them evaluated. Type :help for more information. scala> import scala.util.Random.nextGaussian import scala.util.Random.nextGaussian scala> val x0 = Vector.fill(201)(100 * nextGaussian) x0: scala.collection.immutable.IndexedSeq[Double] = Vector(168.28831870102465, -40.56031270948016, -3.7654366027471324, 1.84679796245639, -16.43467253746984, -76.77204408341358, 82.19998108957988, -20.22095860147962, 28.854940681415442, 42.41265353324536, -38.85577931250823, -17.320873680820082, 64.19368427702135, -8.173507833084892, -198.6064655461397, 40.73700995880357, 32.36849515282444, 0.07758364225363915, -101.74032407199553, 34.789280276495646, 46.29624756866302, 35.54024768650289, 24.7867839701828, -11.931948933554782, 72.12437623460166, 30.51440227306552, -80.20756177356768, 134.2380548346385, 96.14401034937691, -205.48142161773896, -73.48186022765427, 2.7861465340245215, 39.49041527572774, 12.262899592863906, -118.30408039749234, -62.727048950163855, -40.58557796128219, -23.42... scala> val y0 = Vector.fill(201)(30 * nextGaussian) y0: scala.collection.immutable.IndexedSeq[Double] = Vector(-51.675658534203876, 20.230770706186128, 32.47396891906855, -29.35028743620815, 26.7392929946199, 49.85681312583139, 24.226102932450917, 31.19021547086266, 26.169544117916704, -4.51435617676279, 5.6334117227063985, -59.641661744341775, -48.83082934374863, 29.655750956280304, 26.000847703123497, -17.43319605936741, 0.8354318740518344, 11.44787080976254, -26.26312164695179, 88.63863939038357, 45.795968719043785, 88.12442528090506, -29.829048945601635, -1.0417034396751037, -27.119245702417494, -14.055969115249258, 6.120344305721601, 6.102779172838027, -6.342516875566529, 0.06774080659895702, 46.364626315486014, -38.473161588561, -43.25262339890197, 19.77322736359687, -33.78364440355726, -29.085765762613683, 22.87698648100551, 30.53... scala> val x1 = (x0, y0).zipped.map((a,b) => 0.5 * (a + b) ) x1: scala.collection.immutable.IndexedSeq[Double] = Vector(58.30633008341039, -10.164771001647015, 14.354266158160707, -13.75174473687588, 5.152310228575029, -13.457615478791094, 53.213042011015396, 5.484628434691521, 27.51224239966607, 18.949148678241286, -16.611183794900917, -38.48126771258093, 7.681427466636357, 10.741121561597705, -86.3028089215081, 11.651906949718079, 16.601963513438136, 5.7627272260080895, -64.00172285947366, 61.71395983343961, 46.0461081438534, 61.83233648370397, -2.5211324877094174, -6.486826186614943, 22.50256526609208, 8.229216578908131, -37.04360873392304, 70.17041700373827, 44.90074673690519, -102.70684040557, -13.558616956084126, -17.843507527268237, -1.8811040615871129, 16.01806347823039, -76.0438624005248, -45.90640735638877, -8.85429574013834, 3.55536787... scala> val y1 = (x0, y0).zipped.map((a,b) => 0.5 * (a - b) ) y1: scala.collection.immutable.IndexedSeq[Double] = Vector(109.98198861761426, -30.395541707833143, -18.11970276090784, 15.598542699332269, -21.58698276604487, -63.31442860462248, 28.986939078564482, -25.70558703617114, 1.3426982817493691, 23.463504855004075, -22.244595517607316, 21.160394031760845, 56.51225681038499, -18.9146293946826, -112.3036566246316, 29.08510300908549, 15.7665316393863, -5.68514358375445, -37.73860121252187, -26.924679556943964, 0.2501394248096176, -26.292088797201085, 27.30791645789222, -5.445122746939839, 49.62181096850958, 22.28518569415739, -43.16395303964464, 64.06763783090022, 51.24326361247172, -102.77458121216895, -59.92324327157014, 20.62965406129276, 41.37151933731485, -3.755163885366482, -42.26021799696754, -16.820641593775086, -31.73128222114385, -26.9... scala> val a = (x1, y1).zipped.map(_ * _).sum / x1.map(x => x * x).sum a: Double = 0.8119662470457414
The slope is only 0.81! Note that if one runs PCA on the x1 and y1 data, the first principal component is correctly along the diagonal.
For completeness, I am giving a plot of (x1, y1) zipped here:

Figure 05-4. The regression curve slope of a seemingly perfectly correlated dataset is less than one. This has to do with the metric the regression problem optimizes (y-distance).
I will leave it to the reader to find the reason why the slope is less than one, but it has to do with the specific question the regression problem is supposed to answer and the metric it optimizes.