
This chapter presents the concept of reinforcement learning, which is widely used in gaming and robotics. The second part of this chapter is dedicated to learning classifier systems, which combine reinforcement learning techniques with evolutionary computing introduced in the previous chapter. Learning classifiers are an interesting breed of algorithms that are not commonly included in literature dedicated to machine learning. I highly recommend that you to read the seminal book on reinforcement learning by R. Sutton and A. Barto [11:1] if you are interested to know about the origin, purpose, and scientific foundation of reinforcement learning.
In this chapter, you will learn the following topics:
- Basic concepts behind reinforcement learning
- A detailed implementation of the Q-learning algorithm
- A simple approach to manage and balance an investment portfolio using reinforcement learning
- An introduction to learning classifier systems
- A simple implementation of extended learning classifiers
The section on learning classifier systems (LCS) is mainly informative and does not include a test case.
The need of an alternative to traditional learning techniques arose with the design of the first autonomous systems.
Autonomous systems are semi-independent systems that perform tasks with a high degree of autonomy. Autonomous systems touch every facet of our life, from robots and self-driving cars to drones. Autonomous devices react to the environment in which they operate. The reaction or action requires the knowledge of not only the current state of the environment but also the previous state(s).
Autonomous systems have specific characteristics that challenge traditional methodologies of machine learning, as listed here:
- Autonomous systems have poorly defined domain knowledge because of the sheer number of possible combinations of states.
- Traditional nonsequential supervised learning is not a practical option because of the following:
- Training consumes significant computational resources, which are not always available on small autonomous devices
- Some learning algorithms are not suitable for real-time prediction
- The models do not capture the sequential nature of the data feed
- Sequential data models such as hidden Markov models require training sets to compute the emission and state transition matrices (as explained in The hidden Markov model section in Chapter 7, Sequential Data Models), which are not always available. However, a reinforcement learning algorithm benefits from a hidden Markov model if some of the states are unknown. These algorithms are known as behavioral hidden Markov models [11:2].
- Genetic algorithms are an option if the search space can be constrained heuristically. However, genetic algorithms have unpredictable response time, which makes them impractical for real-time processing.
Reinforcement learning is an algorithmic approach to understanding and ultimately automating goal-based decision making. Reinforcement learning is also known as control learning. It differs from both supervised and unsupervised learning techniques from the knowledge acquisition standpoint: autonomous, automated systems, or devices learn from direct and real-time interaction with their environment. There are numerous practical applications of reinforcement learning from robotics, navigation agents, drones, adaptive process control, game playing, and online learning, to scheduling and routing problems.
Reinforcement learning introduces new terminologies as listed here, which are quite different from that of older machine learning techniques:
- Environment: This is any system that has states and mechanisms to transition between states. For example, the environment for a robot is the landscape or facility it operates.
- Agent: This is an automated system that interacts with the environment.
- State: The state of the environment or system is the set of variables or features that fully describe the environment.
- Goal or absorbing state or terminal state: This is the state that provides a higher discounted cumulative reward than any other state. A high cumulative reward prevents the best policy from being dependent on the initial state during training.
- Action: This defines the transition between states. The agent is responsible for performing or at least recommending an action. Upon execution of the action, the agent collects a reward (or punishment) from the environment.
- Policy: This defines the action to be selected and executed for any state of the environment.
- Best policy: This is the policy generated through training. It defines the model in Q-learning and is constantly updated with any new episode.
- Reward: This quantifies the positive or negative interaction of the agent with the environment. Rewards are essentially the training set for the learning engine.
- Episode: This defines the number of steps necessary to reach the goal state from an initial state. Episodes are also known as trials.
- Horizon: This is the number of future steps or actions used in the maximization of the reward. The horizon can be infinite, in which case the future rewards are discounted in order for the value of the policy to converge.
The key component in reinforcement learning is a decision-making agent that reacts to its environment by selecting and executing the best course of actions and being rewarded or penalized for it [11:3]. You can visualize these agents as robots navigating through an unfamiliar terrain or a maze. Robots use reinforcement learning as part of their reasoning process after all. The following diagram gives the overview architecture of the reinforcement learning agent:

The four state transitions of reinforcement learning
The agent collects the state of the environment, selects, and then executes the most appropriate action. The environment responds to the action by changing its state and rewarding or punishing the agent for the action.
The four steps of an episode or learning cycle are as follows:
- The learning agent retrieves or is notified of a new state of the environment.
- The agent evaluates and selects the action that may provide the highest reward.
- The agent executes the action.
- The agent collects the reward or penalty and applies it to calibrate the learning algorithm.
The action of the agent modifies the state of the system, which in turn notifies the agent of the new operational condition. Although not every action will trigger a change in the state of the environment, the agent collects the reward or penalty nevertheless. At its core, the agent has to design and execute a sequence of actions to reach its goal. This sequence of actions is modeled using the ubiquitous Markov decision process (refer to the Markov decision processes section in Chapter 7, Sequential Data Models).
A good metaphor for such a scenario is the rollback of the action. However, not all environments support such a dummy action, and the agent may have to run Monte-Carlo simulations to try out an action.
Reinforcement learning is particularly suited to problems for which long-term rewards can be balanced against short-term rewards. A policy enforces the trade-off between short-term and long-term rewards. It guides the behavior of the agent by mapping the state of the environment to its actions. Each policy is evaluated through a variable known as the value of a policy.
Intuitively, the value of a policy is the sum of all the rewards collected as a result of the sequence of actions taken by the agent. In practice, an action over the policy farther in the future obviously has a lesser impact than the next action from a state St to a state St+1. In other words, the impact of future actions on the current state has to be discounted by a factor, known as the discount coefficient for future rewards < 1.
Note
Transition and rewards matrices
The transition and emission matrices have been introduced in the The hidden Markov model section in Chapter 7, Sequential Data Models.
The optimum policy π* is the agent's sequence of actions that maximizes the future reward discounted to the current time.
The following table introduces the mathematical notation of each component of reinforcement learning:
|
Notation |
Description |
|---|---|
|
S = {si} |
These are the states of the environment |
|
A = {ai} |
These are the actions on the environment |
|
Πt = p(at | st) |
This is the policy (or strategy) of the agent |
|
Vπ(st) |
This is the value of the policy at a state |
|
pt =p(st+1 | st,at) |
These are the state transition probabilities from the state st to the state st+1 |
|
rt= p(rt+1 | st,st+1,at) |
This is the reward of an action at for a state st |
|
Rt |
This is the expected discounted long-term return |
|
γ |
This is the coefficient to discount the future rewards |
The purpose is to compute the maximum expected reward Rt from any starting state sk as the sum of all discounted rewards to reach the current state st. The value Vπ of a policy π at the state st is the maximum expected reward Rt given the state st.

The problem of finding the optimal policies is indeed a nonlinear optimization problem whose solution is iterative (dynamic programming). The expression of the value function Vπ of a policy π can be formulated using the Markovian state transition probabilities pt.

V*(st) is the optimal value of the state st across all the policies. The equations are known as the Bellman optimality equations.
Note
The curse of dimensionality
The number of states for a high-dimension problem (large-feature vector) becomes quickly unsolvable. A workaround is to approximate the value function and reduce the number of states by sampling. The application test case introduces a very simple approximation function.
If the environment model, state, action, and rewards, as well as transition between states, are completely defined, the reinforcement learning technique is known as model-based learning. In this case, there is no need to explore a new sequence of actions or state transitions. Model-based learning is similar to playing a board game in which all combinations of steps that are necessary to win are completely known.
However, most practical applications using sequential data do not have a complete, definitive model. Learning techniques that do not depend on a fully defined and available model are known as model-free techniques. These techniques require exploration to find the best policy for any given state. The remaining sections in this chapter deal with model-free learning techniques, and more specifically, the temporal difference algorithm.
Temporal difference is a model-free learning technique that samples the environment. It is a commonly used approach to solve the Bellman equations iteratively. The absence of a model requires a discovery or exploration of the environment. The simplest form of exploration is to use the value of the next state and the reward defined from the action to update the value of the current state, as described in the following diagram:

An illustration of the temporal difference algorithm
The iterative feedback loop used to adjust the value action on the state plays a role similar to the backpropagation of errors in artificial neural networks or minimization of the loss function in supervised learning. The adjustment algorithm has to:
- Discount the estimate value of the next state using the discount rate γ
- Strike a balance between the impact of the current state and the next state on updating the value at time t using the learning rate α
The iterative formulation of the first Bellman equation predicts Vπ(st), the value function of state st from the value function of the next state st+1. The difference between the predicted value and the actual value is known as the temporal difference error abbreviated as δt.
An alternative to evaluating a policy using the value of the state Vπ(st) is to use the value of taking an action on a state st known as the value of action (or action-value) Qπ(st, at).
There are two methods to implement the temporal difference algorithm:
- On-policy: This is the value for the next best action that uses the policy
- Off-policy: This is the value for the next best action that does not use the policy
Let's consider the temporal difference algorithm using an off-policy method and its most commonly used implementation: Q-learning.
Q-learning is a model-free learning technique using an off-policy method. It optimizes the action-selection policy by learning an action-value function. Like any machine learning technique that relies on convex optimization, the Q-learning algorithm iterates through actions and states using the quality function, as described in the following mathematical formulation.
The algorithm predicts and discounts the optimum value of action max{Qt} for the current state st and action at on the environment to transition to the state st+1.
Similar to genetic algorithms that reuse the population of chromosomes in the previous reproduction cycle to produce offspring, the Q-learning technique strikes a balance between the new value of the quality function Qt+1 and the old value Qt using the learning rate α. Q-learning applies temporal difference techniques to the Bellman equation for an off-policy methodology.
- A value 1 for the learning rate α discards the previous state, while a value 0 discards learning
- A value 1 for the discount rate γ uses long-term rewards only, while a value 0 uses the short-term reward only
Q-learning estimates the cumulative reward discounted for future actions.
Let's apply our hard-earned knowledge of reinforcement learning to management and optimization of a portfolio of exchange-traded funds.
Let's implement the Q-learning algorithm in Scala.
The key components of the implementation of the Q-learning algorithm are defined as follows:
- The
QLearningclass implements training and prediction methods. It defines a data transformation of theETransformtype using an explicit configuration of theQLConfigtype. - The
QLSpaceclass has two components: a sequence of states of theQLStatetype and the identifieridof one or more goal states within the sequence. - A state,
QLState, contains a sequence ofQLActioninstances used in its transition to another state and a reference to the object orinstancefor which the state is to be evaluated and predicted. - An indexed state,
QLIndexedState, indexes a state in the search toward the goal state. - An optional
constraintfunction that limits the scope of the search for the next most rewarding action from the current state. - The model of the
QLModeltype is generated through training. It contains the best policy and the accuracy for a model.
The following diagram shows the key components of the Q-learning algorithm:

The UML components diagram of the Q-learning algorithm
The QLAction class specifies the transition of one state with a from identifier to another state with the to identifier, as shown here:
class QLAction(val from: Int, val to: Int)
Actions have a Q value (or action-value), a reward, and a probability. The implementation defines these three values in three separate matrices: Q for the action values, R for rewards, and P for probabilities, in order to stay consistent with the mathematical formulation.
A state of the QLState type is fully defined by its identifier, id, the list of actions to transition to some other states, and a prop property of the parameterized type, as shown in the following code:
class QLState[T](val id: Int, val actions: List[QLAction] = List.empty, val instance: T])
The state might not have any actions. This is usually the case of the goal or absorbing state. In this case, the list is empty. The parameterized instance is a reference to the object for which the state is computed.
The next step consists of creating the graph or search space.
The search space is the container responsible for any sequence of states. The QLSpace class takes the following parameters:
- The sequence of all the possible
states - The ID of one or several states that have been selected as
goals
The QLSpace class is implemented as follows:
class QLSpace[T](states: Seq[QLState[T]], goals: Array[Int]) { val statesMap = states.map(st =>(st.id, st)) //1 val goalStates = new HashSet[Int]() ++ goals //2 def maxQ(state: QLState[T], policy: QLPolicy): Double //3 def init(state0: Int) //4 def nextStates(st: QLState[T]): Seq[QLState[T]] //5 … }
The constructor of the QLSpace class generates a map, statesMap. It retrieves the state using its id value (line 1) and the array of goals, goalStates (line 2). Furthermore, the maxQ method computes the maximum action-value, maxQ, for a state given a policy (line 3). The implementation of the maxQ method is described in the next section.
The init method selects an initial state for training episodes (line 4). The state is randomly selected if the state0 argument is invalid:
def init(state0: Int): QLState[T] =
if(state0 < 0) {
val seed = System.currentTimeMillis+Random.nextLong
states((new Random(seed)).nextInt(states.size-1))
}
else states(state0)Finally, the nextStates method retrieves the list of states resulting from the execution of all the actions associated with the st state (line 5).
The QLSpace search space is actually created by the apply factory method defined in the QLSpace companion object, as shown here:
def apply[T](goals: Array[Int], instances: Seq[T], constraints: Option[Int =>List[Int]): QLSpace[T] ={ //6 val r = Range(n, instances.size) val states = instances.zipWithIndex.map{ case(x, n) => { val validStates = constraints.map( _(n)).getOrElse(r) val actions = validStates.view .map(new QLAction(n, _)).filter(n != _.to) //7 QLState[T](n, actions, x) }} new QLSpace[T](states, goals) }
The apply method creates a list of states using the instances set, the goals, and the constraints constraining function as inputs (line 6). Each state creates its list of actions. The actions are generated from this state to any other states (line 7).
The search space of states is illustrated in the following diagram:
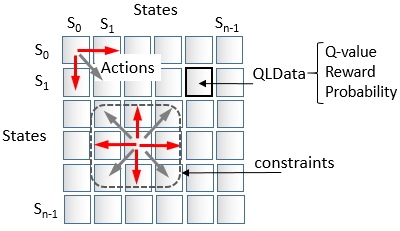
The state transition matrix with QLData (Q-value, reward, and probability)
The constraints function limits the scope of the actions that can be triggered from any given state, as illustrated in the preceding diagram.
Each action has an action-value, a reward, and a potentially probability. The probability variable is introduced to simply model the hindrance or adverse condition for an action to be executed. If the action does not have any external constraint, the probability is 1. If the action is not allowed, the probability is 0.
Note
Dissociating a policy from states
The action and states are the edges and vertices of the search space or search graph. The policy defined by the action-values, rewards, and probabilities is completely dissociated from the graph. The Q-learning algorithm initializes the reward matrix and updates the action-value matrix independently of the structure of the graph.
The QLData class is a container for three values: reward, probability, and a value variable for the Q-value, as shown here:
class QLData(val reward: Double, val probability: Double) { var value: Double = 0.0 def estimate: Double = value*probability }
Note
Reward and punishment
The probability in the QLData class represents the hindrance or difficulty to reach one state from another state. Nothing prevents you from using the probability as a negative reward or punishment. However, its proper definition is to create a soft constraint of a state transition for a small subset of a state. For most applications, the overwhelming majority of state transitions have a probability of 1.0, and therefore, rely on the reward to guide the search toward the goal.
The estimate method adjusts the Q-value, value, with the probability to reflect any external condition that can impede the action.
Note
Mutable data
You might wonder why the QLData class defines a value as a variable instead of a value as recommended by the best Scala coding practices [11:4]. The reason being that an instance of an immutable class can be created for each action or state transition that requires you to update the value variable.
The training of the Q-learning model entails iterating across several episodes, each episode being defined as a multiple iteration. For instance, the training of a model with 400 states for 10 episodes of 100 iterations can potentially create 160 million instances of QLData. Although not quite elegant, mutability reduces the load on the JVM garbage collector.
Next, let's create a simple schema or class, QLInput, to initialize the reward and probability associated with each action as follows:
class QLInput(val from: Int, val to: Int, val reward: Double, val probability: Double = 1.0)
The first two arguments are the identifiers for the from source state and the to target state for this specific action. The last two arguments are the reward, collected at the completion of the action, and its probability. There is no need to provide an entire matrix. Actions have a reward of 1 and a probability of 1 by default. You only need to create an input for actions that have either a higher reward or a lower probability.
The number of states and a sequence of input define the policy of the QLPolicy type. It is merely a data container, as shown here:
class QLPolicy(input: Seq[QLInput]) { val numStates = Math.sqrt(input.size).toInt //8 val qlData = input.map(qlIn => new QLData(qlIn.reward, qlIn.prob)) //9 def setQ(from: Int, to: Int, value: Double): Unit = qlData(from*numStates + to).value = value //10 def Q(from: Int, to: Int): Double = qlData(from*numStates + to).value //11 def EQ(from: Int, to: Int): Double = qlData(from*numStates + to).estimate //12 def R(from: Int, to: Int): Double = qlData(from*numStates + to).reward //13 def P(from: Int, to: Int): Double = qlData(from*numStates + to).probability //14 }
The number of states, numStates, is the square root of the number of elements of the initial input matrix, input (line 8). The constructor initializes the qlData matrix of the QLData type with the input data, reward, and probability (line 9). The QLPolicy class defines the shortcut methods to update (line 10) and retrieve (line 11) the value, the estimate (line 12), the reward (line 13), and the probability (line 14).
The QLearning class encapsulates the Q-learning algorithm, and more specifically, the action-value updating equation. It is a data transformation of the ETransform type with an explicit configuration of the QLConfig type (line 16) (refer to the Monadic data transformation section in Chapter 2, Hello World!):
class QLearning[T](conf: QLConfig, qlSpace: QLSpace[T], qlPolicy: QLPolicy) //15 extends ETransform[QLConfig](conf) { //16 type U = QLState[T] //17 type V = QLState[T] //18 val model: Option[QLModel] = train //19 def train: Option[QLModel] def nextState(iSt: QLIndexedState[T]): QLIndexedState[T] override def |> : PartialFunction[U, Try[V]] … }
The constructor takes the following parameters (line 15):
config: This is the configuration of the algorithmqlSpace: This is the search spaceqlPolicy: This is the policy
The model is generated or trained during the instantiation of the class (refer to the Design template for classifier section in the Appendix A, Basic Concepts) (line 19). The Q-learning algorithm is implemented as an explicit data transformation; therefore, the U type of the input element and the V type of the output element to the |> predictor are initialized as QLState (lines 17 and 18).
The configuration of the Q-learning algorithm, QLConfig, specifies the learning rate, alpha, the discount rate, gamma, the maximum number of states (or length) of an episode, episodeLength, the number of episodes (or epochs) used in training, numEpisodes, and the minimum coverage, minCoverage, required to select the best policy as follows:
case class QLConfig(val alpha: Double, val gamma: Double, val episodeLength: Int, val numEpisodes: Int, val minCoverage: Double) extends Config
The QLearning class has two constructors defined in its companion object that initializes the policy either from an input matrix of states or from a function that compute the reward and probabilities:
- The client code specifies the
inputfunction to initialize the state of the Q-learning algorithm from the input data - The client code specifies the functions to generate the
rewardandprobabilityfor each action or state transition
The first constructor for the QLearning class passes the initialization of states => Seq[QLInput], the sequence of references of instances associated with the states, and the constraints scope constraining function as an argument, besides the configuration and the goals (line 20):
def apply[T](config: QLConfig, //20 goals: Array[Int], input: => Seq[QLInput], instances: Seq[T], constraints: Option[Int =>List[Int]] =None): QLearning[T]={ new QLearning[T](config, QLSpace[T](goals, instances, constraints), new QLPolicy(input)) }
The second constructor passes the input data, xt (line 21), the reward function (line 22), and the probability function (line 23) as well as the sequence of references of instances associated with the states and the constraints scope constraining function as arguments:
def apply[T](config: QLConfig, goals: Array[Int], xt: DblVector, //21 reward: (Double, Double) => Double, //22 probability: (Double, Double) => Double, //23 instances: Seq[T]. constraints: Option[Int =>List[Int]] =None): QLearning[T] ={ val r = Range(0, xt.size) val input = new ArrayBuffer[QLInput] //24 r.foreach(i => r.foreach(j => input.append(QLInput(i, j, reward(xt(i), xt(j)), probability(xt(i), xt(j)))) ) ) new QLearning[T](config, QLSpace[T](goals, instances, constraints), new QLPolicy(input)) }
The reward and probability matrices are used to initialize the input state (line 24).
Let's take a look at the computation of the best policy during training. First, we need to define a QLModel model class with the bestPolicy optimum policy (or path) and its coverage as parameters:
class QLModel(val bestPolicy: QLPolicy, val coverage: Double) extends Model
The creation of model consists of executing multiple episodes to extract the best policy. The training is executed in the train method: Each episode starts with a randomly selected state, as shown in the following code:
def train: Option[QLModel] = Try { val completions = Range(0, config.numEpisodes) .map(epoch => if(train(-1)) 1 else 0).sum //25 completions.toDouble/config.numEpisodes //26 } .map( coverage => { if(coverage > config.minCoverage) Some(new QLModel(qlPolicy, coverage)) //27 else None }).get
The train method iterates through the generation of the best policy starting from a randomly selected state config.numEpisodes times (line 25). The state coverage is calculated as the percentage of times the search ends with the goal state (line 26). The training succeeds only if the coverage exceeds a threshold value, config.minAccuracy, specified in the configuration.
Note
The quality of the model
The implementation uses the accuracy to measure the quality of the model or best policy. The F1 measure (refer to the Assessing a model section in Chapter 2, Hello World!), is not appropriate because there are no false positives.
The train(state0: Int) method does the heavy lifting at each episode (or epoch). It triggers the search by selecting either the state0 initial state or a r random generator with a new seed, if state0 is < 0, as shown in the following code:
case class QLIndexedState[T](val state: QLState[T],
val iter: Int)The QLIndexedState utility class keeps track of the state at a specific iteration, iter, within an episode or epoch:
def train(state0: Int): Boolean = { @tailrec def search(iSt: QLIndexedState[T]): QLIndexedState[T] val finalState = search( QLIndexedState(qlSpace.init(state0), 0) ) if( finalState.index == -1) false //28 else qlSpace.isGoal(finalState.state) //29 }
The implementation of search for the goal state(s) from a state0 predefined or random is a textbook implementation of the Scala tail recursion. Either the recursive search ends if there are no more states to consider (line 28) or the goal state is reached (line 29).
Tail recursion is a very effective construct to apply an operation to every item of a collection [11:5]. It optimizes the management of the function stack frame during the recursion. The annotation triggers a validation of the condition necessary for the compiler to optimize the function calls, as shown here:
@tailrec def search(iSt: QLIndexedState[T]): QLIndexedState[T] = { val states = qlSpace.nextStates(iSt.state) //30 if( states.isEmpty || iSt.iter >= config.episodeLength) //31 QLIndexedState(iSt.state, -1) else { val state = states.maxBy(s => qlPolicy.R(iSt.state.id, s.id)) //32 if( qlSpace.isGoal(state) ) QLIndexedState(state, iSt.iter) //33 else { val fromId = iSt.state.id val r = qlPolicy.R(fromId, state.id) val q = qlPolicy.Q(fromId, state.id) //34 val nq = q + config.alpha*(r + config.gamma * qlSpace.maxQ(state, qlPolicy)-q) //35 qlPolicy.setQ(fromId, state.id, nq) //36 search(QLIndexedState(state, iSt.iter+1)) } } }
Let's dive into the implementation for the Q action-value updating equation. The search method implements the M5 mathematical expression for each recursion.
The recursion uses the QLIndexedState utility class (state, iteration number in the episode) as an argument. First, the recursion invokes the nextStates method of QLSpace (line 30) to retrieve all the states associated with the st current state through its actions, as shown here:
def nextStates(st: QLState[T]): Seq[QLState[T]] =
if( st.actions.isEmpty )
Seq.empty[QLState[T]]
else
st.actions.map(ac => statesMap.get(ac.to) )The search completes and returns the current state if the length of the episode (maximum number of states visited) is reached or the goal is reached or there is no further state to transition to (line 31). Otherwise, the recursion computes the state to which the transition generates the higher reward R from the current policy (line 32). The recursion returns the state with the highest reward if it is one of the goal states (line 33). The method retrieves the current q action-value (line 34) and r reward matrices from the policy, and then applies the equation to update the action-value (line 35). The method updates the action-value Q with the new value nq (line 36).
The action-value updating equation requires the computation of the maximum action-value associated with the current state, which is performed by the maxQ method of the QLSpace class:
def maxQ(state: QLState[T], policy: QLPolicy): Double = { val best = states.filter( _ != state) //37 .maxBy(st => policy.EQ(state.id, st.id)) //38 policy.EQ(state.id, best.id) }
The maxQ method filters out the current state (line 37) and then extracts the best state, which maximizes the policy (line 38).
Note
Reachable goal
The algorithm does not require the goal state to be reached for every episode. After all, there is no guarantee that the goal will be reached from any randomly selected state. It is a constraint on the algorithm to follow a positive gradient of the rewards when transitioning between states within an episode. The goal of the training is to compute the best possible policy or sequence of states from any given initial state. You are responsible for validating the model or best policy extracted from the training set, independent from the fact that the goal state is reached for every episode.
A commercial application may require multiple types of validation mechanisms regarding the states transition, reward, probability, and Q-value matrices.
One critical validation is to verify that the user-defined constraints function does not create a dead end in the search or training of Q-learning. The constraints function establishes the list of states that can be accessed from a given state through actions. If the constraints are too tight, some of the possible search paths may not reach the goal state. Here is a simple validation of the constraints function:
def validateConstraints(numStates: Int, constraints: Int => List[Int]): Boolean = Range(0, numStates).exists( constraints(_).isEmpty )
The last functionality of the QLearning class is the prediction using the model created during training. The |> method predicts the optimum state transition (or action) from a given state, state0:
override def |> : PartialFunction[U, Try[V]] = { case state0: U if(isModel) => Try { if(state0.isGoal) state0 //39 else nextState(QLIndexedState[T](state0, 0)).state) //40 } }
The |> data transformation returns itself if the state0 input state is the goal (line 39) or computes the best outcome, nextState, (line 40) using another tail recursion, as follows:
@tailrec def nextState(iSt: QLIndexedState[T]): QLIndexedState[T] = { val states = qlSpace.nextStates(iSt.state) //41 if( states.isEmpty || iSt.iter >=config.episodeLength) iSt //42 else { val fromId = iSt.state.id val qState = states.maxBy(s => //43 model.map(_.bestPolicy.R(fromId, s.id)).getOrElse(-1.0)) nextState(QLIndexedState[T](qState, iSt.iter+1)) //44 } }
The nextState method executes the following sequence of invocations:
- Retrieve the eligible states that can be transitioned to from the current state,
iSt.state(line41). - Return the states if there are no more states or if the method does not converge within the maximum number of allowed iterations,
config.episodeLength(line42). - Extracts the state,
qState, with the most rewarding policy (line43). - Increment the
iSt.iteriteration counter (line44).
Note
The exit condition
The prediction ends when no more states are available or the maximum number of iterations within the episode is exceeded. You can define a more sophisticated exit condition. The challenge is that there is no explicit error or loss variable/function that can be used except the temporal difference error.
The |> prediction method returns either the best possible state or None if the model cannot be created during training.
The Q-learning algorithm is used in many financial and market trading applications [11:6]. Let's consider the problem of computing the best strategy to trade certain types of options given some market conditions and trading data.
The Chicago Board Options Exchange (CBOE) offers an excellent online tutorial on options [11:7]. An option is a contract that gives the buyer the right but not the obligation to buy or sell an underlying asset at a specific price on or before a certain date (refer to the Options trading section under Finances 101 in the Appendix A, Basic Concepts.) There are several option pricing models, the Black-Scholes stochastic partial differential equations being the most recognized [11:8].
The purpose of the exercise is to predict the price of an option on a security for N days in the future according to the current set of observed features derived from the time to expiration, price of the security, and volatility. Let's focus on the call options of a given security, IBM. The following chart plots the daily price of the IBM stock and its derivative call option for May 2014 with a strike price of $190:

The IBM stock and Call $190 May 2014 pricing in May-Oct 2013
The price of an option depends on the following parameters:
- Time to expiration of the option (time decay)
- The price of the underlying security
- The volatility of returns of the underlying asset
The pricing model usually does not take into account the variation in trading volume of the underlying security. Therefore, it would be quite interesting to include it in our model. Let's define the state of an option using the following four normalized features:
- Time decay (
timeToExp): This is the time to expiration once normalized over [0, 1]. - Relative volatility (
volatility): This is the relative variation of the price of the underlying security within a trading session. It is different from the more complex volatility of returns defined in the Black-Scholes model, for example. - Volatility relative to volume (
vltyByVol): This is the relative volatility of the price of the security adjusted for its trading volume. - Relative difference between the current price and strike price (
priceToStrike): This measures the ratio of the difference between price and strike price to the strike price.
The following graph shows the four normalized features for the IBM option strategy:

Normalized relative stock price volatility, volatility relative to trading volume, and price relative to strike price for the IBM stock
The implementation of the option trading strategy using Q-learning consists of the following steps:
- Describing the property of an option
- Defining the function approximation
- Specifying the constraints on the state transition
Let's select N = 2 as the number of days in the future for our prediction. Any longer-term prediction is quite unreliable because it falls outside the constraint of the discrete Markov model. Therefore, the price of the option two days in the future is the value of the reward—profit or loss.
The OptionProperty class encapsulates the four attributes of an option (line 45) as follows:
class OptionProperty(timeToExp: Double, volatility: Double, vltyByVol: Double, priceToStrike: Double) { //45 val toArray = Array[Double]( timeToExp, volatility, vltyByVol, priceToStrike ) }
The OptionModel class is a container and a factory for the properties of the option. It creates the list of propsList option properties by accessing the data source of the four features introduced earlier. It takes the following parameters:
- The symbol of the security.
- The strike price for the
strikePriceoption. - The source of data,
src. - The minimum time decay or time to expiration,
minTDecay. Out-of-the-money options expire worthless and in-the-money options have very different price behavior as they get closer to the expiration date (refer to the Options trading section in the Appendix A, Basic Concepts). Therefore, the lastminTDecaytrading sessions prior to the expiration date are not used in the training of the model. - The number of steps (or buckets),
nSteps. It is used in approximating the values of each feature. For instance, an approximation of four steps creates four buckets [0, 25], [25, 50], [50, 75], and [75, 100].
The implementation of the OptionModel class is as follows:
class OptionModel(symbol: String, strikePrice: Double, src: DataSource, minExpT: Int, nSteps: Int) { val propsList = (for { price <- src.get(adjClose) volatility <- src.get(volatility) nVolatility <- normalize(volatility) vltyByVol <- src.get(volatilityByVol) nVltyByVol <- normalize(vltyByVol) priceToStrike <- normalize(price.map(p => (1.0 - strikePrice/p))) } yield { nVolatility.zipWithIndex./:(List[OptionProperty]()){ //46 case(xs, (v,n)) => { val normDecay = (n + minExpT).toDouble/ (price.size + minExpT) //47 new OptionProperty(normDecay, v, nVltyByVol(n), priceToStrike(n)) :: xs } }.drop(2).reverse //48 }) .getOrElse(List.empty[OptionProperty].) def quantize(o: DblArray): Map[Array[Int], Double] }
The factory uses the zipWithIndex Scala method to represent the index of the trading sessions (line 46). All feature values are normalized over the interval [0, 1], including the time decay (or time to expiration) of the normDecay option (line 47). The instantiation of the OptionModel class generates a list of OptionProperty elements if the constructor succeeds (line 48), an empty list otherwise.
The four properties of the option are continuous values, normalized as a probability [0, 1]. The states in the Q-learning algorithm are discrete and require a quantization or categorization known as a function approximation; although a function approximation scheme can be quite elaborate [11:9]. Let's settle for a simple linear categorization, as illustrated in the following diagram:

Quantization of the state of a traded option
The function approximation defines the number of states. In this example, a function approximation that converts a normalized value into three intervals or buckets generates 34 = 81 states or potentially 38-34 = 6480 actions! The maximum number of states for l buckets function approximation and n features is ln with a maximum number of l2n-ln actions.
Note
Quantization or function approximation guidelines
The design of the function to approximate the state of options has to address the following two conflicting requirements:
- Accuracy demands a fine-grained approximation
- Limited computation resources restrict the number of states, and therefore, level of approximation
The quantize method of the OptionModel class converts the normalized value of each option property of features into an array of bucket indices. It returns a map of profit and loss for each bucket keyed on the array of bucket indices, as shown in the following code:
def quantize(o: DblArray): Map[Array[Int], Double] = { val mapper = new mutable.HashMap[Int, Array[Int]] //49 val _acc = new NumericAccumulator[Int] //50 val acc = propsList.view.map( _.toArray) .map( toArrayInt( _ )) //51 .map(ar => { val enc = encode(ar) //52 mapper.put(enc, ar) enc }).zip(o) ./:(_acc){ case (acc, (t,y)) => { //53 acc += (t, y) acc }} acc.map {case (k, (v,w)) => (k, v/w) } //54 .map {case( k,v) => (mapper(k), v) }.toMap }
The method creates a mapper instance to index the array of buckets (line 49). An acc accumulator of the NumericAccumulator type extends Map[Int, (Int, Double)] and computes the tuple (number of occurrences of features on each buckets and the sum of increase or decrease of the option price) (line 50). The toArrayInt method converts the value of each option property (timeToExp, volatility, and so on) into the index of the appropriate bucket (line 51). The array of indices is then encoded (line 52) to generate the id or index of a state. The method updates the accumulator with the number of occurrences and the total profit and loss for a trading session for the option (line 53). It finally computes the reward on each action by averaging the profit and loss on each bucket (line 54).
A view is used in the generation of the list of OptionProperty to avoid unnecessary object creation.
The source code for the toArrayInt and encode methods and NumericAccumulator is documented and available online.
The final piece of the puzzle is the code that configures and executes the Q-learning algorithm on one or several options on a security, IBM:
val STOCK_PRICES = "resources/data/chap11/IBM.csv" val OPTION_PRICES = "resources/data/chap11/IBM_O.csv" val QUANTIZER = 4 val src = DataSource(STOCK_PRICES, false, false, 1) //55 val model = for { option <- Try(createOptionModel(src)) //56 oPrices <- DataSource(OPTION_PRICES, false).extract //57 _model <- createModel(option, oPrices) //58 } yield _model
The preceding implementation creates the Q-learning model with the following steps:
- Extract the historical prices for the IBM stock by instantiating a data source,
src(line55). - Create an
optionmodel (line56). - Extract the historical prices
oPricesfor option call $190 May 2014 (line57). - Create the model,
_model, with agoalStrpredefined goal (line58).
The code is as follows:
val STRIKE_PRICE = 190.0
val MIN_TIME_EXPIRATION = 6
def createOptionModel(src: DataSource): OptionModel =
new OptionModel("IBM", STRIKE_PRICE, src,
MIN_TIME_EXPIRATION, QUANTIZER)Let's take a look at the createModel method that takes the option pricing model, option, and the historical prices for oPrice options as arguments:
val LEARNING_RATE = 0.2 val DISCOUNT_RATE = 0.7 val MAX_EPISODE_LEN = 128 val NUM_EPISODES = 80 def createModel(option: OptionModel, oPrices: DblArray, alpha: Double, gamma: Double): Try[QLModel] = Try { val qPriceMap = option.quantize(oPrices) //59 val numStates = qPriceMap.size val qPrice = qPriceMap.values.toVector //60 val profit= zipWithShift(qPrice,1).map{case(x,y) => y -x}//61 val maxProfitIndex = profit.zipWithIndex.maxBy(_._1)._2 //62 val reward = (x: Double, y: Double) => Math.exp(30.0*(y – x)) //63 val probability = (x: Double, y: Double) => if(y < 0.3*x) 0.0 else 1.0 //64 if( !validateConstraints(profit.size, neighbors)) //65 throw new IllegalStateException(" ... ") val config = QLConfig(alpha, gamma, MAX_EPISODE_LEN, NUM_EPISODES) //66 val instances = qPriceMap.keySet.toSeq.drop(1) QLearning[Array[Int]](config, Array[Int](maxProfitIndex), profit, reward, probability, instances, Some(neighbors)).getModel //67 }
The method quantizes the option prices map, oPrices (line 59), extracts the historical option prices, qPrice (line 60), computes the profit as the difference in the price of the option between two consecutive trading sessions (line 61), and computes the index, maxProfitIndex, of the trading session with the highest profile (line 62). The state with the maxProfitIndex index is selected as the goal.
The input matrix is automatically generated using the reward and probability functions. The reward function rewards the state transition proportionally to the profit (line 63). The probability function punishes the state transition for which the loss y – x is greater than 0.3*x by setting the probability value to 0 (line 64).
The validateConstraints method of the QLearning companion object validates the neighbors constraints function, as described in the The validation section (line 65).
The last two steps consists of creating a configuration, config, for the Q-learning algorithm (line 66) and training the model by instantiating the QLearning class with the appropriate parameters, including the neighbors method that defines the neighboring states for any given state (line 67). The neighbors method is described in the documented source code available online.
Note
The anti-goal state
The goal state is the state with the highest assigned reward. It is a heuristic to reward a strategy for a good performance. However, it is conceivable and possible to define an anti-goal state with the highest assigned penalty or the lowest assigned reward to guide the search away from some condition.
Besides the function approximation, the size of the training set has an impact on the number of states. A well-distributed or large training set provides at least one value for each bucket created by the approximation. In this case, the training set is quite small and only 34 out of 81 buckets have actual values. As result, the number of states is 34. The initialization of the Q-learning model generates the following reward matrix:

The reward matrix for the option-pricing Q-learning strategy
The graph visualizes the distribution of the rewards computed from the profit and loss of the option. The xy plane represents the actions between states. The states' IDs are listed on x and y axes. The z axis measures the actual value of the reward associated with each action.
The reward reflects the fluctuation in the price of the option. The price of an option has a higher volatility than the price of the underlying security.
The xy reward matrix R is rather highly distributed. Therefore, we select a small value for the learning rate 0.2 to reduce the impact of the previous state on the new state. The value for the discount rate 0.7 accommodates the fact that the number of states is limited. There is no reason to compute the future discounted reward using a long sequence of states. The training of the policies generates the following action-value matrix Q of 34 states by 34 states after the first episode:

The Q action-value matrix for the first episode (epoch)
The distribution of the action-values between states at the end of the first episode reflects the distribution of the reward across state-to-state action. The first episode consists of a sequence of nine states from an initial randomly selected state to the goal state. The action-value map is compared to the map generated after 20 episodes in the following graph:

The Q Action-Value matrix for the last episode (epoch)
The action-value map at the end of the last episode shows some clear patterns. Most of the rewarding actions transition from a large number of states (X axis) to a smaller number of states (Y axis). The chart illustrates the following issues with the small training sample:
- The small size of the training set forces us to use an approximate representation of each feature. The purpose is to increase the odds that most buckets have, that is, at least one data point.
- However, a loose function approximation or quantization tends to group quite different states into the same bucket.
- The bucket with a very low number can potentially mischaracterize one property or feature of a state.
The next test is to display the profile of the log of the Q-value (QLData.value) as the recursive search (or training) progress for different episodes or epochs. The test uses a learning rate α = 0.1 and a discount rate γ = 0.9.

The profile of the log (Q-Value) for different epochs during Q-learning training
The preceding chart illustrates the fact that the Q-value for each profile is independent of the order of the epochs during training. However, the length of the profile (or number of iterations to reach the goal state) depends on the initial state, which is selected randomly, in this example.
The last test consists of evaluating the impact of the learning rate and discount rate on the coverage of the training:

Training coverage versus learning rate and discount rate
The coverage (percentage of an episode or epoch for which the goal state is reached) decreases as the learning rate increases. The result confirms the general rule of using learning rate < 0.2. The similar test to evaluate the impact of the discount rate on the coverage is inconclusive.
Reinforcement learning algorithms are ideal for the following problems:
- Online learning
- The training data is small or nonexistent
- A model is nonexistent or poorly defined
- Computation resources are limited
However, these techniques perform poorly in the following cases:
- The search space (number of possible actions) is large because the maintenance of the states, action graph, and rewards matrix becomes challenging
- The execution is not always predictable in terms of scalability and performance