
19
Divide and Conquer
In this chapter, the Divide and Conquer strategy is detailed and demonstrated over the problems of finding the max/min element in a list, merge sort and matrix multiplication.
19.1. Introduction
Divide and Conquer is a popular algorithm design strategy that has been widely used over a variety of problem classes. As the name indicates, the strategy solves a problem by dividing it repeatedly into smaller sub-problems, until the smaller sub-problems can be individually and easily solved. The strategy then backtracks, combining the solutions of the smaller sub-problems phase by phase on its return, until the solution to the original problem is automatically constructed, thereby conquering the problem. Needless to say, Divide and Conquer has been a time-tested political strategy too!
The fact that the strategy repeatedly moves onward to “divide” the problem and backtracks to “conquer” its solution, is suggestive of the application of recursion. Thus, Divide and Conquer-based solutions to problems are ideally implemented as recursive procedures or programs (see section 2.7 of Chapter 2, Volume 1, for a discussion on recursion and analysis of recursive procedures).
19.2. Principle and abstraction
Figure 19.1(a) illustrates the principle of Divide and Conquer, where a problem whose data set size is n, is repeatedly divided into smaller sub-problems each of which are solved independently, before the principle backtracks to combine the solutions of the sub-problems, to finally arrive at the solution to the original problem.
Figure 19.1(b) illustrates the abstraction of the Divide and Conquer method. The function SMALL(r,t) determines if the size of the sub-problem whose data set size is given by (r,t), is small enough to be solved independently and directly using the function B(r,t). Note that the if condition functions as the base case of the recursive procedure. DIVIDE(r,t) divides the problem into two sub-problems of smaller sizes and the function COMBINE() combines the solutions of the two sub-problems. The repeated division of the problem is handled recursively, by calling DIVIDEandCONQUER() over the sub-problems.

Figure 19.1 The principle and abstraction of the Divide and Conquer method. a) principle and b) abstraction. For a color version of this figure, see www.iste.co.uk/pai/algorithms3.zip
The application of the Divide and Conquer method for the solution of problems is detailed in the ensuing sections.
19.3. Finding maximum and minimum
Finding the maximum and minimum elements in a list, termed the max-min problem for ease of reference, is a simple problem. While there are different methods available to solve this problem, we use this problem only to demonstrate how Divide and Conquer works to obtain its solution.
Procedure MAXMIN()(Algorithm 19.1) illustrates the pseudo-code for the Divide and Conquer-based solution to the max-min problem. The procedure begins with the original dataset D and recursively divides the dataset D into two subsets D1 and D2, that comprise half the elements of D. To undertake this, the recursive procedure is called twice, one as MAXMIN(D1) and the other as MAXMIN(D2).

Algorithm 19.1 Pseudo-code for the Divide and Conquer-based solution to the Max-Min problem
The base cases of the recursive procedure are invoked when the divided dataset comprises just two elements {a, b} at which point, the max and min elements are computed by a mere comparison of the elements, or when the divided dataset comprises a single element {a} at which point, both the max and min elements are set to {a} and returned to their respective calling procedures. When recursion terminates, (MAX1, MIN1) and (MAX2, MIN2) store the max and min elements of D1 and D2, respectively.
One last comparison between the max elements and the min elements returns the final maximum and minimum element of the given dataset, at which point recursion terminates successfully.
Illustrative problem 19.1 demonstrates the working of procedure MAXMIN() over a problem instance.
19.3.1. Time complexity analysis
Since procedure MAXMIN() is a recursive procedure, to obtain the time complexity of the procedure, the recurrence relation needs to be framed first. Since there are two recursive calls in the procedure, for an input size n, the time complexity T(n) expressed in terms of the element comparisons made over the data set is given by the following recurrence relation:

The base case (n = 1), does not entail any element comparisons, hence T(n) = 0, whereas, the base case (n = 2) entails only one comparison between a and b to determine the max and min elements and therefore T(n) = 1. For (n > 2), the two recursive calls incur a time complexity of ![]() with two more comparisons undertaken last, to determine the final maximum and minimum element of the data set.
with two more comparisons undertaken last, to determine the final maximum and minimum element of the data set.
Solving equation [19.1] assuming that n = 2k for some k, yields,
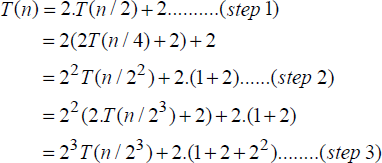
In the ith step,

Since n = 2k, in the step when i = (k-1),

Thus, the time complexity of the Divide and Conquer-based max/min element finding problem is O(n).
19.4. Merge sort
The merge sort algorithm which makes use of the principle of merge to order a data set was discussed in section 17.5. Algorithm 17.5 illustrates the recursive merge sort algorithm (procedure MERGE_SORT). The merge sort algorithm employs a Divide and Conquer approach to sort the elements.
Thus, the original list is divided into two sub-lists and the recursive MERGE_SORT procedure is invoked over the two sub-lists after which the two sorted sub-lists are merged one last time using procedure MERGE (Algorithm 17.4 in section 17.5), yielding the sorted list.
19.4.1. Time complexity analysis
The recurrence relation for the time complexity of procedure MERGE_SORT is given by,
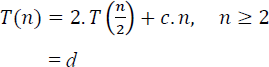
where c and d are constants. Illustrative problem 17.5, shows the solution of the recurrence relation, yielding a time complexity of O(n.log2 n).
19.5. Matrix multiplication
The multiplication of two square matrices A, B of order n, is given by,

where 
Known as the “high school” method, this way of multiplying two square matrices involves three for loops, two to keep the indices i, j of Cij running and the third running over index k, to sum up the product (aik. bkj). With all the three loops ranging from 1 to n, where n is the size of the square matrices, the time complexity of the iterative algorithm is bound to be O(n3).
Now, what if a Divide and Conquer-based approach was adopted to undertake this “high school” method of computing the product of two square matrices? Would it result in a better time complexity? Let us explore.
19.5.1. Divide and Conquer-based approach to “high school” method of matrix multiplication
A Divide and Conquer-based approach could involve dividing the square matrices A and B into four quadrants A11, A12, A21, A22 and B11, B12, B21, B22 respectively, as shown in Figure 19.2 and recursively undertaking the division of each of the quadrants into four other “miniature” quadrants and so on, until each of the quadrants is just left with a 2 ×2 matrix. At this stage, the base case of the recursive procedure merely does the usual “high school” method of matrix multiplication and returns the results, which eventually results in the recursive procedure returning the product of the two matrices as (C)n X n.

Figure 19.2 Division of square matrices into four quadrants of size 
The governing recurrence relations of the Divide and Conquer-based algorithm are as follows:

where Aij, Bij and Cij denote sub-matrices of order ![]() and aij, bij and cij denote matrix elements. Aij.Bjk in general denotes the recursive matrix multiplication of the sub-matrices of
and aij, bij and cij denote matrix elements. Aij.Bjk in general denotes the recursive matrix multiplication of the sub-matrices of ![]() until the base case is triggered at n = 2, at which stage the matrix multiplication of two matrices of order 2 × 2 is undertaken as illustrated in equation [19.2].
until the base case is triggered at n = 2, at which stage the matrix multiplication of two matrices of order 2 × 2 is undertaken as illustrated in equation [19.2].
19.5.1.1. Time complexity analysis
The time complexity of the Divide and Conquer-based “high school” method of matrix multiplication in terms of the basic operations, i.e. the matrix additions and multiplications that were carried out during recursion, are obtained as follows.
Let T(n) denote the time complexity of multiplying two square matrices of order n. The recursive algorithm calls for eight matrix multiplications and four matrix additions of sub-matrices of order ![]() , during each call. When n = 2, it reduces to eight element multiplications and four element additions. The recurrence relation is therefore given by,
, during each call. When n = 2, it reduces to eight element multiplications and four element additions. The recurrence relation is therefore given by,

Since the addition of two square matrices of order n has a time complexity of O(n2), c.n2 in equation [19.3] denotes the upper bound for the four matrix additions called for, by the recursive algorithm.
Solving equation [19.3] assuming that n = 2k for some k, yields,

In the ith step,

Since n = 2k, in the step when i = (k-1),
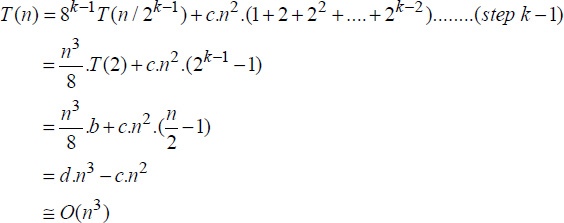
Thus, despite the Divide and Conquer-based approach, the “high school” method of matrix multiplication does not yield a performance better than its traditional method of element multiplications and additions, which also yielded O(n3) time complexity.
19.5.2. Strassen’s matrix multiplication algorithm
Strassen’s matrix multiplication algorithm devised by Volker Strassen is a faster matrix multiplication method when compared to the traditional method. It works best over large matrices, though not as much as other competing methods.
Adopting a Divide and Conquer-based approach, the algorithm recursively divides the matrices A and B into four quadrants as shown in Figure 19.2, and proceeds to compute the intermediary matrices P, Q, R, S, T, U and V, to obtain the final matrix C.

Strassen’s method recursively works on equation [19.4] until the base case of n = 2 is reached. At this stage, as discussed with regard to equation [19.2], the computations become element additions, subtractions and multiplications.
An observation of equation [19.4] reveals that the algorithm uses seven matrix multiplications and 18 matrix additions/subtractions. Thus, the method seems to have saved on one matrix multiplication when compared to the traditional method but in the process has jacked up the matrix additions/subtractions to a whopping eighteen! Will it ensure good performance? Let’s explore its time complexity.
19.5.2.1. Time complexity analysis
Following a similar description of T(n) in equation [19.3], the recurrence relation for Strassen’s method is as follows:

c.n2 in the equation denotes the upper bound for the eighteen matrix additions/subtractions called for, by the recursive algorithm.
Solving equation [19.5] using the usual steps and assuming that n = 2k for some k, yields,
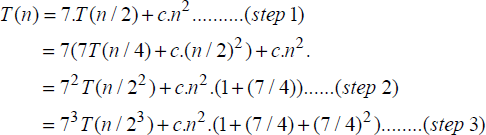
In the ith step,

Since n = 2k, in the step when i = (k-1),

Thus, the Divide and Conquer-based on Strassen’s method for matrix multiplication reports a time complexity of O(n2.81), which is a better performance especially for large matrices, when compared to the time complexity of O(n3) reported by the “high school” method.
Summary
- Divide and Conquer is an efficient method for algorithm design and works by dividing the problem into sub-problems and solving them when they are small enough, only to combine their results to yield the final solution to the problem.
- Divide and Conquer is a recursive method.
- Max-Min element finding, Merge Sort and Matrix Multiplication are examples of Divide and Conquer-based algorithms.
19.6. Illustrative problems
Review questions
- Why do Divide and Conquer-based algorithms inherently advocate recursion during their implementation?
- Justify the Divide and Conquer approach adopted in quick sort, merge sort and binary search algorithms. Comment on the “Divide” strategies used by them.
- Show that
 comparisons are required to find the minimum and maximum elements of a list L with n elements.
comparisons are required to find the minimum and maximum elements of a list L with n elements. - Demonstrate the Divide and Conquer-based bit number multiplication methods discussed in illustrative problems 19.4 and 19.5 on the following two-bit numbers:
v: 0101 w: 1000
- What is the time complexity of multiplying two n-bit numbers using the traditional method?
Programming assignments
- Implement the Divide and Conquer-based “high school” method to multiply two square matrices AnXn, BnXn.
- Implement Strassen’s method of matrix multiplication over two square matrices.
- Implement the Divide and Conquer-based algorithm to find the minimum and maximum elements in a list L of n elements.