Chapter 5. Recursion
Immutable variables have an obvious flaw: we cannot change them. This means that it’s more difficult to do things like changing a single element of a list, or implementing an if statement that sets a variable. Also, let’s think about immutability in terms of applications. How can our applications run if data is never allowed to change? This is where we must use recursion.
Math Warning
Let’s check out an example of a recursive function in mathematics. We can see that we have an end case: if x is less than or equal to 0. And we have the execution to do for every other case—this is our summation.
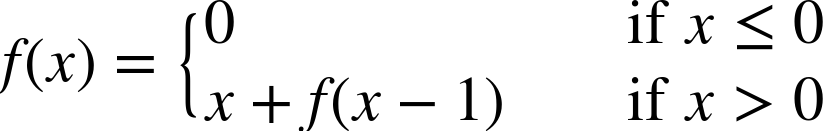
Here we are just summing up each number that we pass in, but what if we used our first-class functions? Let’s see what we could do.

Although it doesn’t seem like much has changed, what we’ve effectively done is create the summation operation.

Many people are afraid of recursion, mainly because they never learned how to write recursive functions effectively. People also assume that iterative algorithms are inherently better than recursive algorithms. Recursive algorithms are much simpler because they deal only with the input values. If we were to use a normal for loop in an iterative process, the algorithm would have to worry about the list as a whole. Example 5-1 shows a simple summation in a for loop.
deff(x){intsummation=0for(inti=1;i<=x;i++){summation=summation+i}returnsummation}printlnf(10)
Let’s rewrite this summation as a recursive function in Example 5-2.
deff(x){if(x<=0){return0}else{returnx+f(x-1)}}printlnf(10)
As in this case, a recursive algorithm is often much simpler to design, and I hope this chapter teaches you how to think recursively as you look at algorithms and puts you more at ease writing recursion.
As most software developers know, there is a limit on how deep recursion can go, or how many times a function can call into itself. Most of the time, this is bound by memory (remember, you’re creating a new frame on the stack each time you make a function call), and in other languages there are limits in the compiler or interpreter. We’ll discuss ways to get around this limitation, though unfortunately not for all languages.
An Introduction to Recursion
Let’s think about another simple example to replicate the Filter function. We’ll be writing this function in Groovy. Let’s begin with a normal iterative loop style.
Note
You’ll notice that I annotated the generic typing; although that’s not required in Groovy, I don’t want anyone to get lost.
def<T>List<T>Filter(List<T>list,Closurecls){ArrayList<T>out=newArrayList<T>()for(Tobj:list){if(cls(obj)){out.add(obj)}}returnout}
As you can see, we create a mutable out list and then go through each element in our input list, adding it to our out list if cls(obj) returns true. As the final statement, we return out. Let’s try to convert this iteration into recursion.
The first step is to check if the input list is empty; if it is, we’ll return an empty list, as shown in Example 5-3. So far, we’ve protected ourselves from the end case, the most important part of a recursive function. This should always be your first step in writing a recursive function; if you miss this, you will end up with an infinite loop.
def<T>List<T>Filter(List<T>list,Closurecls){if(list.isEmpty()){return[]}}
Lists, Heads, and Tails, Oh My!
There are generally two main parts of a list that everyone should understand: the head and the tail. Let’s take, for example, a list of numbers from 1 to 5. The head is the element 1, whereas the tail is a list containing 2 through 5:
| 1 | 2 | 3 | 4 | 5 | ^ ^^^^^^^^^^^^^ | | head tail
After our if statement, we’ll do our actual processing. We check when we pass list.head() to cls if that returns true. If it does, we’ll create a new list containing the head; otherwise, we’ll use an empty list (see Example 5-4).
def<T>List<T>Filter(List<T>list,Closurecls){if(list.isEmpty()){return[]}List<T>out=cls(list.head())?[list.head()]:[]}
At this point, we know whether the current object belongs in our output list. But what about the rest of our list? That’s easy: we’ll just call back into Filter with the tail() of the list. We’ll concatenate the returned list from Filter to our out list by using the + operator. Check out the code in Example 5-5.
def<T>List<T>Filter(List<T>list,Closurecls){if(list.isEmpty()){return[]}List<T>out=cls(list.head())?[list.head()]:[]returnout+Filter(list.tail(),cls)}
But we can simplify this more. Let’s complete the following steps and check out Example 5-6 once we’re done:
-
Add an
elsestatement to ourifstructure; this cleans up the implicitelsethat existed. -
Get rid of the extraneous
outvariable by replacing it with theternarystatement.
def<T>List<T>Filter(List<T>list,Closurecls){if(list.isEmpty()){return[]}else{return(cls(list.head())?[list.head()]:[])+Filter(list.tail(),cls)}}
Nullity Is a Scary Thing
You’ll notice that there was no check for list being null. This is actually intentional, because dealing with nullity is bad design. What would passing null to this function mean? Would it mean that your upstream function failed and you failed to handle it? If so, why should this function ignore nullity?
In my experience, null is a very dangerous construct that should be avoided at all costs. We’ll see some alternatives to error handling later, but for now just know that we’ll always pass around full objects.
The thing to notice about this algorithm is that in no instance is an object actually modified. Our objects are created and destroyed but are never mutated. Remember, immutability is an important part of functional programming.
Recursion
Sometimes the general filter- and map-style functions aren’t going to help you. Instead, you will need to perform some operation to reduce the data from a set into a single piece of output.
XXY has been growing, and your boss has asked that you get a count of all enabled customers that have no enabled contacts. This is important because every customer should have at least one enabled contact. You start to write a simple function, falling back into an imperative style using iteration, as shown in Example 5-7.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers){inttotal=0for(Customercustomer:customers){if(customer.enabled){if(customer.contacts.find({contact->contact.enabled})==null){total=total+1}}}returntotal}
Uh oh! Notice that we have a mutable variable. There is actually another solution using function chaining instead of recursion, as shown in Example 5-8.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers){returncustomers.findAll({customer->returncustomer.enabled}).findAll({customer->return(customer.contacts.find({contact->contact.enabled})==null)}).size()}
The problem here is that we’re inherently traversing our list twice. Instead, let’s go ahead and make this a single traversal by combining our findAll logic, as shown in Example 5-9.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers){returncustomers.findAll({customer->returncustomer.enabled&&(customer.contacts.find({contact->contact.enabled})==null)}).size()}
Of course, this is not a recursive function and relies on us creating a new list just to get the size() of the list. If this list were a couple thousand customers long, we’d be wasting time creating a new list that we’re just going to throw away. Now, if we were going to just get the list and operate on that, it would be a different story, but here we’re just concerned about the count.
Let’s see how we can do this in a much less wasteful way. We’re going to reduce over our list of customers into a count (see Example 5-10).
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers){if(customers.isEmpty()){return0}else{intaddition=(customers.head().enabled&&(customers.head().contacts.find({contact->contact.enabled})==null))?1:0returnaddition+countEnabledCustomersWithNoEnabledContacts(customers.tail())}}
Wow, there appears to be quite a bit going on here. There is, but what’s amazing is that it’s very simple logic and the overall statement is also really simple. Let’s decompose this function. The first thing we’ll do is define our end case, as shown in Example 5-11.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers){if(customers.isEmpty()){return0}else{
The next thing to do is define our logic if the customer is enabled and has no enabled contacts, which is shown in Example 5-12. We do this by saying, “if our logic is true, then we will add 1; otherwise, we add 0.”
intaddition=(customers.head().enabled&&(customers.head().contacts.find({contact->contact.enabled})==null))?1:0
Finally, we return our addition to our recursive call, as shown in Example 5-13.
returnaddition+countEnabledCustomersWithNoEnabledContacts(customers.tail())}}
The logic really isn’t that bad. When we start looking at statements in Chapter 7, you will find that you really don’t need to use the ternary operator. But for the time being, we’ll proceed with the tools we have right now.
As I’ve said before, you can end up with some really bad issues if you have to recurse thousands of times. The main issue with recursing this many times is that you eventually run out of space on the stack. Remember, each function call pushes information back onto the stack. But, of course, there are instances for which we need to iterate thousands of times while keeping track of some state. This is where tail recursion comes in!
Tail Recursion
Tail recursion is very close to recursion, the difference being that there are no outstanding calls when you recurse. If you no longer need to keep the stack so that you can unwind the recursive calls, you no longer have an expanding stack.
Tail recursion happens when the last call of the function is the tail call and there are no outstanding operations to be done within the function when the return occurs. This is generally a compiler optimization, except in Groovy, which we will see shortly, for which you must use trampolining.
Let’s look at our Filter example and see if we can convert this into a tail-recursive call. So, we know that in a tail call, the function cannot have outstanding processing when we go into a recurse. In Example 5-14, we’ll add our end case and end parameter to return at the end.
def<T>List<T>Filter(List<T>list,List<T>output,Closurecls){if(list.isEmpty()){returnoutput
In our else statement, you’ll notice that now we’re appending to the output list instead of prepending to it (see Example 5-15). This is because we’re building the list as we traverse it rather than as we unwind the stack.
}else{returnFilter(list.tail(),cls(list.head())?output+list.head():output,cls)}}
Let’s put this all together and see what it looks like in Example 5-16.
Refactoring Our countEnabledCustomersWithNoEnabledContacts Function
Your boss has come back saying that the countEnabledCustomersWithNoEnabledContacts function you wrote needs to handle a couple hundred thousand customers. You’ve known from the beginning that the function you wrote would fail if you go too deep into the recursion. But, there is a way to fix our recursive call, so let’s do so.
Let’s begin with the end case again. In Example 5-17, we know that our last step should be returning the sum. We will then add sum as a parameter to our function to be returned in the end case.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers,intsum){if(customers.isEmpty()){returnsum}else{
Again, we have the same logic to determine whether we’re adding anything (see Example 5-18.
intaddition=(customers.head().enabled&&(customers.head().contacts.find({contact->contact.enabled})==null))?1:0
Finally, we recurse into our function, adding the addition to our sum, which we then pass forward, as in Example 5-19. This passing forward, and the fact that we have nothing waiting on the return of that function, is what makes this function tail-recursive. As soon as we hit the end case, the value returned from the end case will be the same value that is returned from the entrance into the recursive call itself.
returncountEnabledCustomersWithNoEnabledContacts(customers.tail(),sum+addition)}}
As you can see, we’re still not mutating any objects, and we’re compiling our summation as we recurse instead of having to unwind all of our function calls. Let’s see this all put together in Example 5-20.
publicstaticintcountEnabledCustomersWithNoEnabledContacts(List<Customer>customers,intsum){if(customers.isEmpty()){returnsum}else{intaddition=(customers.head().enabled&&(customers.head().contacts.find({contact->contact.enabled})==null))?1:0returncountEnabledCustomersWithNoEnabledContacts(customers.tail(),sum+addition)}}
Awesome! Now we have a tail-recursive call. Unfortunately, Groovy does not actually do a tail-recursive optimization. But we have one small trick up our sleeves. We need to turn this into a lambda and use the trampoline() call on it. Our code in Example 5-21 shows this refactor.
So how does trampolining work? It’s pretty simple: the trampoline() call causes the function to be wrapped in a TrampolineClosure. When we execute the TrampolineClosure—for example, calling countEnabledCustomersWithNoEnabledContacts(Customer.allCustomers, 0)—it will then execute the function itself. If the execution returns a TrampolineClosure, it will run the new TrampolineClosure function. It will continue to do this until it gets something back that is not a TrampolineClosure.
defcountEnabledCustomersWithNoEnabledContacts=nullcountEnabledCustomersWithNoEnabledContacts={List<Customer>customers,intsum->if(customers.isEmpty()){returnsum}else{intaddition=(customers.head().enabled&&(customers.head().contacts.find({contact->contact.enabled})==null))?1:0returncountEnabledCustomersWithNoEnabledContacts.trampoline(customers.tail(),sum+addition)}}.trampoline()
Conclusion
In this chapter, we created a new function called countEnabledCustomersWithNoEnabledContacts as a general recursive function, and then refactored it into a tail-recursive function call. Notice that the logic is much simpler than using an entire if structure. Instead, we can just look at the first element from our list, the head, and determine whether we want to count it.
Many people shy away from recursion because of depth concerns and a perceived “performance issue.” That is valid when you start looking at extremely large lists and how many function calls are actually being done. But let’s look at our email example from Chapter 4.
Let’s assume that we have five threads and a list of n size, and we are going to synchronize access to the list (allowing mutable objects). Let’s assume that one of those threads needs to update something in the list, meaning that it’s locking the list and giving a runtime of O(n). That’s not too bad, but what about the other four threads? They are now blocked for O(n) and will eventually have their own runtime of O(n). This brings the runtime to O(2n).
Now, let’s look at this same example but instead using immutability and recursion. Let’s assume that our update thread has a runtime of O(n), and our other threads also have their own runtime of O(n). Notice, though, that the other threads do not need to wait for writing to finish before they are able to access that list. This brings the runtime to O(n). Let’s remember that in time complexity O(2n) can be simplified to O(n), which means that both an iterative and a recursive runtime should be fairly similar when we’re looking at concurrent processing.
Tail recursion solves our depth issues, but we have some challenges with syntax. As we saw with Groovy, we had to define a variable and then call .trampoline() on the closure that we were assigning to the variable. We can then use the trampoline() function call in order to return a function to execute.
Introducing Scala
Let’s revisit our countEnabledCustomersWithNoEnabledContacts method, but this time let’s look at it in Scala (shown in Example 5-22) and see how it’s different. As we’ll see in the next few chapters, languages like Scala are more expressive, making recursion much more readable and understandable.
defcountEnabledCustomersWithNoEnabledContacts(customers:List[Customer],sum:Int):Int={if(customers.isEmpty){returnsum}else{valaddition:Int=if(customers.head().enabled&&(customers.head().contacts.count(contact=>contact.enabled))>0){1}else{0}returncountEnabledCustomersWithNoEnabledContacts(customers.tail,sum+addition)}}
Scala Syntax
There are a few things to note here about the Scala syntax in Example 5-22:
-
Functions are denoted using the
defkeyword. -
Types are always listed after the definition and are separated with the
:operator. -
The
isEmptymethod call does not require us to use an empty set of parentheses (because we treat it more like a member than a method). -
Instead of using the ternary operator, we can use a full
ifstatement to achieve the same effect.
The biggest difference is that we no longer have to call trampoline(); instead, we just make our recursive call. As a double check, we can actually include the @tailrec annotation on the method, which forces the compiler to make sure this method is tail-recursive.
The other difference is that we have the if statement, which has a 1 or a 0 inside the if/else structure setting the addition variable. This is equivalent to the ternary operator.
In the coming chapters, we’ll see more examples of this, specifically when we start talking about statements.