Chapter 3. Pure Functions
We use functions to perform specific tasks and then combine them to build our applications. Each function is designed to do some work, given a set of inputs. When we don’t return the result of our execution but rather mutate another external (i.e., not contained within the function scope) object, we call this a side effect. Pure functions, on the other hand, are functions that have no side effects and always perform the same computation, resulting in the same output, given a set of inputs. Although most of this seems straightforward, the implementation is quite another story.
Functions performing large amounts of work are difficult to test. Generally, to allow for your code to grow over time, you need to be able to change functionality. This means the larger your function becomes, the more parameters you need in order to modify the functionality. You should break up the function into smaller functions. These smaller functions can then be pure, allowing for a better understanding of the code’s overall functionality. When a function is pure, we say that “output depends on input.”
Output Depends on Input
If we pass a set of parameters into a pure function, we will always get the same result. The return is solely dependent on the parameter list.
Don’t Closures Break Function Purity?
If we pass a closure, aren’t we then dependent on the external (closed-over) variable? This is an interesting point, so let’s think about closures and how they work. Closures work by bringing the closed-over variable into the scope of the function. Because the variable becomes part of the function as we pass it to another function, everything the receiving function needs to operate has been passed to the function locally.
Math Warning
Let’s think about the following example:
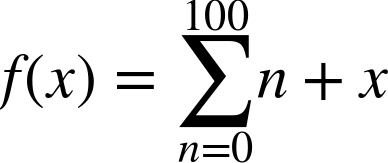
Here is the key: it does not matter what we pass in; we can always predict the output.
Back at XXY, your boss has asked you to add a function that can update a Contract record and set it to enabled. He said there was already a function that could update a Contract by setting it to disabled by a customer. Right now, Customers have only one Contract, so that makes things a little simpler for us. Let’s look at Example 3-1.
importjava.util.Calendar;publicclassContract{publicCalendarbegin_date;publicCalendarend_date;publicBooleanenabled=true;publicContract(Calendarbegin_date){this.begin_date=begin_date;this.end_date=this.begin_date.getInstance();this.end_date.setTimeInMillis(this.begin_date.getTimeInMillis());this.end_date.add(Calendar.YEAR,2);}publicstaticvoidsetContractDisabledForCustomer(Integercustomer_id){for(Customercustomer:Customer.allCustomers){if(customer.id==customer_id){customer.contract.enabled=false;}}}}
But wait—we’re using another for loop. You should remember from the previous chapter that we need to extract some of this functionality. It is likely we’ll have other times when we need to get a customer by id.
Let’s start by creating the getCustomerById method in the Customer class. We just need some basic functionality that can return the customer if it exists and return null if it doesn’t. For now, let’s check the code in Example 3-2. Inside our function is a for loop that iterates over the customer list; we don’t want this because we have already written a loop over the allCustomer list. Don’t worry: for many people this is how you would generally write it.
publicstaticCustomergetCustomerById(Integercustomer_id){for(Customercustomer:Customer.allCustomers){if(customer.id==customer_id){returncustomer;}}returnnull;}
Nullity allows us to represent the absence of a value, but using it can cause many different issues. Why is nullity considered bad? Well, if we call into getCustomerById and get back a null, what does that mean to the caller? Does that mean that we errored out? Does it mean that we were unable to find it? Think about how many places you now have to check for a null return value, and consider the amount of code necessary to make sure that the application does not crash with a NullPointerException. What other options do we have to handle our cases?
We could throw an exception if we were unable to find the Customer object. The problem with that is that we are telling the caller that we will throw an exception if there is no user, even though it’s not actually an error.
We could also return a list containing the customer, or an empty list if it doesn’t exist. This means that no matter what happens, we have a valid object that can be operated on at all times. Now, our caller can decide how she wants to handle the case in which the customer doesn’t exist. Let’s look at the code in Example 3-3.
publicstaticArrayList<Customer>getCustomerById(Integercustomer_id){ArrayList<Customer>outList=newArrayList<Customer>();for(Customercustomer:Customer.allCustomers){if(customer.id==customer_id){outList.add(customer);}}returnoutList;}
But wait a second, that for loop looks quite familiar. Our function filters or finds all of the customers given a customer_id. Remember in the preceding chapter how our method getField had a similar for loop?
Let’s not repeat ourselves; instead, let’s abstract that for loop into its own function, which we’ll call filter. It will take a function that takes a Customer and returns a Boolean. The Boolean will indicate to us whether to keep the record. Our new function is listed in Example 3-4.
publicstaticArrayList<Customer>filter(Function1<Customer,Boolean>test){ArrayList<Customer>outList=newArrayList<Customer>();for(Customercustomer:Customer.allCustomers){if(test.call(customer)){outList.add(customer);}}returnoutList;}
Now that we’ve created this function, let’s think back to the getField function in our Customer object. We can actually extract the filtering functionality and use our new filter function. So, let’s refactor this function—we’re not going to rename it, because it’s the same functionality; instead, we’re extracting the filtering logic out, as shown in Example 3-5. Now we call into Customer.filter(test) and then iterate over the return of that result.
publicstatic<B>List<B>getField(Function1<Customer,Boolean>test,Function1<Customer,B>func){ArrayList<B>outList=newArrayList<B>();for(Customercustomer:Customer.filter(test)){outList.add(func.call(customer));}returnoutList;}
We also modify our getCustomerById function to use the new filter method by passing a new test function, which takes a Customer and returns a Boolean to filter by the requested customer_id, as shown in Example 3-6.
publicstaticArrayList<Customer>getCustomerById(finalIntegercustomer_id){returnCustomer.filter(newFunction1<Customer,Boolean>(){publicBooleancall(Customercustomer){returncustomer.id==customer_id;}});}
Now let’s return to the Contract class and use our getCustomerById function. We’ll go ahead and grab our list of customers and iterate over it, setting the contract to enabled. There’s no need to check that we didn’t return null; the fact that the list will be populated with something implicitly handles the “if there are no records” issue (see Example 3-7).
Purifying Our Functions
The first function we’ll make pure is our filter function. We purify a function by making sure that it isn’t referencing anything outside of its function arguments. This means that our reference to Customer.allCustomers needs to go away, and instead we should pass it in as an argument.
As our functions become more pure, it becomes easier to troubleshoot them because all of our inputs are known. In turn, because all of our inputs are known, all possible outcomes should be derivable. If they are all derivable, we should be able to determine what caused failures in logic. Obviously, our calls to the filter function will receive Customer.allCustomers, which is listed directly below the filter function in Example 3-8.
publicstaticArrayList<Customer>filter(ArrayList<Customer>inList,Function1<Customer,Boolean>test){ArrayList<Customer>outList=newArrayList<Customer>();for(Customercustomer:inList){if(test.call(customer)){outList.add(customer);}}returnoutList;}publicstatic<B>List<B>getField(Function1<Customer,Boolean>test,Function1<Customer,B>func){ArrayList<B>outList=newArrayList<B>();for(Customercustomer:Customer.filter(Customer.allCustomers,test)){outList.add(func.call(customer));}returnoutList;}publicstaticArrayList<Customer>getCustomerById(finalIntegercustomer_id){returnCustomer.filter(Customer.allCustomers,newFunction1<Customer,Boolean>(){publicBooleancall(Customercustomer){returncustomer.id==customer_id;}});}
Let’s continue by making getCustomerById pure (see Example 3-9). This means that the method getCustomerById inside Customer.java must be updated to accept our customer list. This way, we no longer reference the Customer.allCustomers object directly.
publicstaticArrayList<Customer>getCustomerById(ArrayList<Customer>inList,finalIntegercustomer_id){returnCustomer.filter(inList,newFunction1<Customer,Boolean>(){publicBooleancall(Customercustomer){returncustomer.id==customer_id;}});}
We should also update setContractEnabledForCustomer to pass in Customer.allCustomers (see Example 3-10). At this point, we no longer need to have allCustomers passed in because this method only ever operates on the Customer.allCustomers object.
publicstaticvoidsetContractEnabledForCustomer(Integercustomer_id){for(Customercustomer:Customer.getCustomerById(Customer.allCustomers,customer_id)){customer.contract.enabled=true;}}
We need to have a method so that we can execute the customer.contract.enabled = true code for each object without needing to duplicate these loops. The first thing that we need to do is create a new interface, which we’ll call Foreach1.
Foreach1 will be an abstraction for a higher-order function which takes an A1 and has a void return type, because we really don’t care what type is being returned. In our instance, we’re not returning anything because we’re just setting contract.enabled = true. Check out the code for our Foreach1 interface in Example 3-11 and the Function1 interface in Example 3-12.
Refactoring Time
We should move the Foreach1 and Function1 interface definitions into their own Foreach1.java and Function1.java files, respectively.
publicinterfaceForeach1<A1>{publicvoidcall(A1in1);}
publicinterfaceFunction1<A1,B>{publicBcall(A1in1);}
We can then update the Customer class to have its own foreach function that will execute func for each record in the inList, as shown in Example 3-13.
publicstaticvoidforeach(ArrayList<Customer>inList,Foreach1<Customer>func){for(Customercustomer:inList){func.call(customer);}}
We can now use our foreach function. For the inList, we’re going to use a getCustomerById, which will return a list containing our Customer if it exists. For the func, we’re going to create a new Function1 that sets the Contract to enabled. You can see the code in Example 3-14.
publicstaticvoidsetContractEnabledForCustomer(Integercustomer_id){Customer.foreach(Customer.getCustomerById(Customer.allCustomers,customer_id),newForeach1<Customer>(){publicvoidcall(Customercustomer){customer.contract.enabled=true;}});}
Unfortunately, this code modifies the customer argument and sets the customer.contract.enabled field. We’ll address how we might fix this when we start looking at immutable variables.
Returning an Empty List Rather Than Null
In Example 3-14, notice that we’re able to pass the list that was returned by getCustomerById directly to foreach. This has the nice side effect that we don’t need to do null checking. The foreach takes care of “what happens if it doesn’t exist?”
Now, we can easily create a setContractDisabledForCustomer method, as shown in Example 3-15. It’s the same as Example 3-14, except for the value we’re setting on enabled (true versus false, respectively).
publicstaticvoidsetContractDisabledForCustomer(Integercustomer_id){Customer.foreach(Customer.getCustomerById(Customer.allCustomers,customer_id),newForeach1<Customer>(){publicvoidcall(Customercustomer){customer.contract.enabled=false;}});}
Can you think of how we can refactor both of the setContract*ForCustomer methods into a single function? Check out the code in Example 3-16 after you’ve tried it yourself.
publicstaticvoidsetContractForCustomer(Integercustomer_id,finalBooleanstatus){Customer.foreach(Customer.getCustomerById(Customer.allCustomers,customer_id),newForeach1<Customer>(){publicvoidcall(Customercustomer){customer.contract.enabled=status;}});}
That’s right—we can just take the enabled value as a parameter, which will then set the enabled member!
We’ve mostly purified our functions by extracting a filter function and a foreach function so that we don’t need to rewrite our iteration functionality. We also changed our functions so that we’re no longer directly accessing the Customer.allCustomer object; instead, we’re passing it to our functions each time. This ensures that our functions’ output will always be dependent on the input.
We still have a bit to do before our functions are completely pure; we need to get rid of the side effect that exists when we are changing our Contact variable.
Side Effects
Side effects are important: you can use them to persist data, display data, and even change fields on objects. Without side effects, most applications are completely useless. Here are a few examples of side effects:
- Printing to a screen
- Saving to a file/database
- Altering a field on an object
Side effects are not bad, they should just be used sparingly. They should be used only in certain situations because they go outside of the functional concepts. As we’ll see in Chapter 7, statements allow us to implement side effects.
Back at XXY your boss has come to you again and said, “Boy, it’s awesome that we can now set specific customers’ contracts as disabled, but we really need to get information about those contracts after we’ve updated them.” He essentially wants you to update setContractForCustomer to return a list of Contract objects you modified.
As stated before, assigning a field on an object passed in is technically a side effect. So, let’s modify the Contract object’s methods and return the Contract after updating the field. We’re going to create some setters that actually return the object itself after it is modified! Let’s look at the setters in Example 3-17.
publicCustomersetCustomerId(Integercustomer_id){this.id=customer_id;returnthis;}publicCustomersetName(Stringname){this.name=name;returnthis;}publicCustomersetState(Stringstate){this.state=state;returnthis;}publicCustomersetDomain(Stringdomain){this.domain=domain;returnthis;}publicCustomersetEnabled(Booleanenabled){this.enabled=enabled;returnthis;}publicCustomersetContract(Contractcontract){this.contract=contract;returnthis;}
Let’s also look at the setters that we’re creating for our Contract class in Example 3-18. Again, we set the member variable and return our instance.
publicContractsetBeginDate(Calendarbegin_date){this.begin_date=begin_date;returnthis;}publicContractsetEndDate(Calendarend_date){this.end_date=end_date;returnthis;}publicContractsetEnabled(Booleanenabled){this.enabled=enabled;returnthis;}
Whereas we’re trying to ensure that there are no functions that have side effects, we should no longer be using our foreach function. Instead, we’ll be using a map or collect function. Let’s write that really quickly so that we have it ready.
Our map function will take a list of anything and another function that will be used to transform each individual item it is passed. The code in Example 3-19 shows the new map function, which will exist inside our Customer class.
publicstatic<A1,B>List<B>map(List<A1>inList,Function1<A1,B>func){ArrayList<B>outList=newArrayList<B>();for(A1obj:inList){outList.add(func.call(obj));}returnoutList;}
Let’s remember our setContractForCustomer function; we can refactor it to return the list of Contracts that were updated, as shown in Example 3-20. Notice how much simpler writing this code is? We can then use the return to print out each Contract that was updated.
publicstaticList<Contract>setContractForCustomer(Integercustomer_id,finalBooleanstatus){returnCustomer.map(Customer.getCustomerById(Customer.allCustomers,customer_id),newFunction1<Customer,Contract>(){publicContractcall(Customercustomer){returncustomer.contract.setEnabled(status);}});}
We’re now at the point where we need to abstract our foreach, map, and filter functions so that we’re not just bound to our Customer object. Let’s bring these out into their own singleton class, which we’ll define in FunctionalConcepts.java, as shown in Example 3-21. Don’t forget to update the references to these methods.
importjava.util.ArrayList;importjava.util.List;publicclassFunctionalConcepts{privateFunctionalConcepts(){}publicstatic<A1,B>List<B>map(List<A1>inList,Function1<A1,B>func){ArrayList<B>outList=newArrayList<B>();for(A1obj:inList){outList.add(func.call(obj));}returnoutList;}publicstatic<A>voidforeach(ArrayList<A>inList,Foreach1<A>func){for(Aobj:inList){func.call(obj);}}publicstatic<A>ArrayList<A>filter(ArrayList<A>inList,Function1<A,Boolean>test){ArrayList<A>outList=newArrayList<A>();for(Aobj:inList){if(test.call(obj)){outList.add(obj);}}returnoutList;}}
Now we just need to print the Contracts that changed, as shown in Example 3-22. Notice that we are implementing setContractForCustomer followed by a foreach on our returned list. We then create our Foreach function, which does the printing for us.
FunctionalConcepts.foreach(Contract.setContractForCustomer(1,true),newForeach1<Contract>(){publicvoidcall(Contractcontract){System.out.println(contract.toString());}});
We’ve ended up with a side effect again, so what are we going to do? As I said earlier, you can’t entirely avoid side effects in your code. This being the case, we just need to wrap the side effect so that the output is always dependent on the input.
Conclusion
So far, we’ve discussed how to use higher-order functions to create more abstract functionality. I’ve also shown you how to take functions and make them pure, such that the entirety of the output is reliant on the parameter list.
It takes time and practice to really get the hang of refactoring into a functional style. My hope is that through this book you’ll gain an understanding of how to make the changes.
How do you know when to make a function pure? Really, you want to make a function pure whenever possible; it makes the function much more testable and improves understandability from a troubleshooting perspective. However, sometimes you don’t need to go to that extreme.
Let’s look at Example 3-23, in which we’ll refactor our getField method and instead of passing in the test function, we’ll pass in a prefiltered list. That is a good purification, but let’s not use the static DisabledCustomers object we created; instead, we’ll create a new Function1 with which to perform the filter.
Upon trying to purify the function, notice that we’re now creating a new Function1 object for every call to getDisabledCustomerNames. This isn’t a huge deal, but remember that we have a lot of these getDisabledCustomer* functions, which means that we’re going to duplicate a lot of these Function1 objects. In this instance, we’ve taken purity too far, and instead we should’ve just used the Customer.DisabledCustomer object instead.
publicstaticList<String>getDisabledCustomerNames(){returnCustomer.getField(FunctionalConcepts.filter(Customer.allCustomers,newFunction1<Customer,Boolean>(){publicBooleancall(Customercustomer){returncustomer.enabled==false;}}),newFunction1<Customer,String>(){publicStringcall(Customercustomer){returncustomer.name;}});}publicstatic<B>List<B>getField(List<Customer>inList,Function1<Customer,B>func){ArrayList<B>outList=newArrayList<B>();for(Customercustomer:inList){outList.add(func.call(customer));}returnoutList;}
Making the Switch to Groovy
Dynamically Typed Language
Groovy is a dynamically typed language, which means that you can create new types at runtime and the compiler won’t warn you that you are passing incompatible types. In Groovy you overcome this by writing 100% unit tests in your code to ensure that you will not pass an invalid class to a function.
Your boss has started to see how useful functional programming is; he’s been noticing how higher-order functions can reduce code duplication and sees the ease of testability that comes from having pure functions. He’s decided that if you can keep the classes as they exist right now, you can go ahead and start converting over to another language.
You decide to convert to Groovy because it’s fairly close to Java and allows people to write in Java if they are not fully comfortable with Groovy. Not only does Groovy allow us to keep the class definitions we already have, it also allows us to begin a transition to a fully functional language. As soon as we switch to Groovy, we will be able to get rid of our custom FunctionalConcepts class, as well as the Function1 and Foreach1 classes.
We will no longer need these classes, because Groovy includes helpful additions to the List interface such as findAll and collect, which are the same as filter and map, respectively. Let’s see how we are going to refactor the update contract example. We’ll begin by retrieving only the customer for the id we want, as shown in Example 3-24.
defgetCustomerById(IntegercustomerId){Customer.allCustomers.findAll({customer->customer.id==customerId})}
We now have a list of customers matching that customer_id; this list will be either empty or have one Customer in it, which, as we saw earlier in the chapter, is much safer to deal with than checking for nullity. Next, we need to take that list and update and send back the Contract, as in Example 3-25.
.collect({customer->customer.contract.enabled=falsecustomer.contract})
The last step is to print each of the contracts that we updated, as shown in Example 3-26.
Now, let’s chain all of these calls together in Example 3-27.
defsetContractForCustomer(IntegercustomerId){Customer.allCustomers.findAll({customer->customer.id==customerId}).collect({customer->customer.contract.setEnabled(false)}).each({contract->printlncontract})}
What about all of those other methods from the Customer.java file? Let’s go ahead and refactor our code into functional Groovy code. Let’s do the getDisabledCustomerNames function first (see Example 3-28).
publicstaticList<String>getDisabledCustomerNames(){Customer.allCustomers.findAll({customer->customer.enabled==false}).collect({cutomer->cutomer.name})}
Go ahead and refactor the Customer.java code into Groovy syntax. When you’re done, check out the code in Example 3-29 to see how I refactored it.
importjava.util.ArrayList;importjava.util.List;publicclassCustomer{staticpublicArrayList<Customer>allCustomers=newArrayList<Customer>();publicIntegerid=0;publicStringname="";publicStringaddress="";publicStringstate="";publicStringprimaryContact="";publicStringdomain="";publicBooleanenabled=true;publicContractcontract;publicCustomer(){}publicCustomersetCustomerId(Integercustomer_id){this.customer_id=customer_id;returnthis;}publicCustomersetName(Stringname){this.name=name;returnthis;}publicCustomersetState(Stringstate){this.state=state;returnthis;}publicCustomersetDomain(Stringdomain){this.domain=domain;returnthis;}publicCustomersetEnabled(Booleanenabled){this.enabled=enabled;returnthis;}publicCustomersetContract(Contractcontract){this.contract=contract;returnthis;}staticdefEnabledCustomer={customer->customer.enabled==true}staticdefDisabledCustomer={customer->customer.enabled==false}publicstaticList<String>getDisabledCustomerNames(){Customer.allCustomers.findAll(DisabledCustomer).collect({cutomer->cutomer.name})}publicstaticList<String>getEnabledCustomerStates(){Customer.allCustomers.findAll(EnabledCustomer).collect({cutomer->cutomer.state})}publicstaticList<String>getEnabledCustomerDomains(){Customer.allCustomers.findAll(EnabledCustomer).collect({cutomer->cutomer.domain})}publicstaticList<String>getEnabledCustomerSomeoneEmail(Stringsomeone){Customer.allCustomers.findAll(EnabledCustomer).collect({cutomer->someone+"@"+cutomer.domain})}publicstaticArrayList<Customer>getCustomerById(ArrayList<Customer>inList,finalIntegercustomer_id){inList.findAll({customer->customer.customer_id==customer_id})}}
We can now get rid of the FunctionalConcepts.java, Foreach1.java, and Function1.java files because we’re converting over to Groovy, which already have these built in.
Now that we’ve converted over, we’ll be using Groovy from here on out. As I said before, Groovy is a fantastic transition language, since it makes it possible for you to bring in more functional concepts while keeping a syntax familiar to many Java programmers. You can continue writing in Java until everyone is more comfortable writing in a fully functional language. It also means that you can keep your libraries and current code without rewriting them.