
Chapter 16. The PyMailCGI Server
“Things to Do When Visiting Chicago”
This chapter is the fifth in our survey of Python Internet programming, and it continues Chapter 15’s discussion. There, we explored the fundamentals of server-side Common Gateway Interface (CGI) scripting in Python. Armed with that knowledge, this chapter moves on to a larger case study that underscores advanced CGI and server-side web scripting topics.
This chapter presents PyMailCGI—a “webmail” website for reading and sending email that illustrates security concepts, hidden form fields, URL generation, and more. Because this system is similar in spirit to the PyMailGUI program we studied in Chapter 14, this example also serves as a comparison of the web and nonweb application models. This case study is founded on basic CGI scripting, but it implements a complete website that does something more useful than Chapter 15’s examples.
As usual in this book, this chapter splits its focus between application-level details and Python programming concepts. For instance, because this is a fairly large case study, it illustrates system design concepts that are important in actual projects. It also says more about CGI scripts in general: PyMailCGI expands on the notions of state retention and security concerns and encryption.
The system presented here is neither particularly flashy nor feature rich as websites go (in fact, the initial cut of PyMailCGI was thrown together during a layover at Chicago’s O’Hare airport). Alas, you will find neither dancing bears nor blinking lights at this site. On the other hand, it was written to serve a real purpose, speaks more to us about CGI scripting, and hints at just how far Python server-side programs can take us. As outlined at the start of this part of the book, there are higher-level frameworks, systems, and tools that build upon ideas we will apply here. For now, let’s have some fun with Python on the Web.
The PyMailCGI Website
In Chapter 14, we built a program called PyMailGUI that implements a complete Python+tkinter email client GUI (if you didn’t read that chapter, you may want to take a quick glance at it now). Here, we’re going to do something of the same, but on the Web: the system presented in this section, PyMailCGI, is a collection of CGI scripts that implement a simple web-based interface for sending and reading email in any browser. In effect, it is a webmail system—though not as powerful as what may be available from your Internet Service Provider (ISP), its scriptability gives you control over its operation and future evolution.
Our goal in studying this system is partly to learn a few more CGI tricks, partly to learn a bit about designing larger Python systems in general, and partly to underscore the trade-offs between systems implemented for the Web (the PyMailCGI server) and systems written to run locally (the PyMailGUI client). This chapter hints at some of these trade-offs along the way and returns to explore them in more depth after the presentation of this system.
Implementation Overview
At the top level, PyMailCGI allows users to view incoming email with the Post Office Protocol (POP) interface and to send new mail by Simple Mail Transfer Protocol (SMTP). Users also have the option of replying to, forwarding, or deleting an incoming email while viewing it. As implemented, anyone can send email from a PyMailCGI site, but to view your email, you generally have to install PyMailCGI on your own computer or web server account, with your own mail server information (due to security concerns described later).
Viewing and sending email sounds simple enough, and we’ve already coded this a few times in this book. But the required interaction involves a number of distinct web pages, each requiring a CGI script or HTML file of its own. In fact, PyMailCGI is a fairly linear system—in the most complex user interaction scenario, there are six states (and hence six web pages) from start to finish. Because each page is usually generated by a distinct file in the CGI world, that also implies six source files.
Technically, PyMailCGI could also be described as a state machine, though very little state is transferred from state to state. Scripts pass user and message information to the next script in hidden form fields and query parameters, but there are no client-side cookies or server-side databases in the current version. Still, along the way we’ll encounter situations where more advanced state retention tools could be an advantage.
To help keep track of how all of PyMailCGI’s source files fit into the overall system, I jotted down the file in Example 16-1 before starting any real programming. It informally sketches the user’s flow through the system and the files invoked along the way. You can certainly use more formal notations to describe the flow of control and information through states such as web pages (e.g., dataflow diagrams), but for this simple example, this file gets the job done.
file or script creates
-------------- -------
[pymailcgi.html] Root window
=> [onRootViewLink.py] Pop password window
=> [onViewPswdSubmit.py] List window (loads all pop mail)
=> [onViewListLink.py] View Window + pick=del|reply|fwd (fetch)
=> [onViewPageAction.py] Edit window, or delete+confirm (del)
=> [onEditPageSend.py] Confirmation (sends smtp mail)
=> back to root
=> [onRootSendLink.py] Edit Window
=> [onEditPageSend.py] Confirmation (sends smtp mail)
=> back to rootThis file simply lists all the source files in the system,
using => and indentation to
denote the scripts they trigger.
For instance, links on the pymailcgi.html root page invoke onRootViewLink.py and
onRootSendLink.py, both executable scripts. The
script onRootViewLink.py generates a password
page, whose Submit button in turn triggers
onViewPswdSubmit.py, and so on. Notice that
both the view and the send actions can wind up triggering onEditPageSend.py to send a new mail; view
operations get there after the user chooses to reply to or forward
an incoming mail.
In a system such as this, CGI scripts make little sense in isolation, so it’s a good idea to keep the overall page flow in mind; refer to this file if you get lost. For additional context, Figure 16-1 shows the overall contents of this site, viewed as directory listings under Cygwin on Windows in a shell window.

When you install this site, all the files you see here are uploaded to a PyMailCgi subdirectory of your web directory on your server’s machine. Besides the page-flow HTML and CGI script files invoked by user interaction, PyMailCGI uses a handful of utility modules:
commonhtml.pyProvides a library of HTML tools
externs.pyIsolates access to modules imported from other places
loadmail.pyEncapsulates mailbox fetches for future expansion
secret.pyImplements configurable password encryption
PyMailCGI also reuses parts of the mailtools module
package and mailconfig.py
module we wrote in Chapter 13. The former of these is
accessible to imports from the
PP4E package root, and the latter is
largely copied by a local version in the PyMailCgi directory so that it can
differ between PyMailGUI and PyMailCGI. The externs.py module is intended to hide
these modules’ actual locations, in case the install structure varies on some
machines.
In fact, this system again demonstrates the powers of
code reuse in a practical way. In this edition,
it gets a great deal of logic for free from the new mailtools package of Chapter 13—message loading, sending,
deleting, parsing, composing, decoding and encoding, and
attachments—even though that package’s modules were originally
developed for the PyMailGUI program. When it came time to update
PyMailCGI later, tools for handling complex things such as
attachments and message text searches were already in place. See
Chapter 13 for mailtools source code.
As usual, PyMailCGI also uses a variety of standard library
modules: smtplib,
poplib, email.*, cgi, urllib.*, and the like. Thanks to the
reuse of both custom and standard library code, this system achieves
much in a minimal amount of code. All told, PyMailCGI consists of
just 846 lines of new code, including whitespace, comments, and the
top-level HTML file (see file linecounts.xls in this system’s source
directory for details; the prior edition’s version claimed to be
some 835 new lines).
This compares favorably to the size of the PyMailGUI client-side “desktop” program in Chapter 14, but most of this difference owes to the vastly more limited functionality in PyMailCGI—there are no local save files, no transfer thread overlap, no message caching, no inbox synchronization tests or recovery, no multiple-message selections, no raw mail text views, and so on. Moreover, as the next section describes, PyMailCGI’s Unicode policies are substantially more limited in this release, and although arbitrary attachments can be viewed, sending binary and some text attachments is not supported in the current version because of a Python 3.1 issue.
In other words, PyMailCGI is really something of a prototype, designed to illustrate web scripting and system design concepts in this book, and serve as a springboard for future work. As is, it’s nowhere near as far along the software evolutionary scale as PyMailGUI. Still, we’ll see that PyMailCGI’s code factoring and reuse of existing modules allow it to implement much in a surprisingly small amount of code.
New in This Fourth Edition (Version 3.0)
In this fourth edition, PyMailCGI has been ported to run under Python 3.X. In
addition, this version inherits and employs a variety of new
features from the mailtools
module, including mail header decoding and encoding, main mail text
encoding, the ability to limit mail headers fetched, and more.
Notably, there is new support for Unicode and Internationalized
character sets as follows:
For display, both a mail’s main text and its headers are decoded prior to viewing, per email, MIME, and Unicode standards; text is decoded per mail headers and headers are decoded per their content.
For sends, a mail’s main text, text attachments, and headers are all encoded per the same standards, using UTF-8 as the default encoding if required.
For replies and forwards, headers copied into the quoted message text are also decoded for display.
Note that this version relies upon web browsers’ ability to display arbitrary kinds of Unicode text. It does not emit any sort of “meta” tag to declare encodings in the HTML reply pages generated for mail view and composition. For instance, a properly formed HTML document can often declare its encoding this way:
<HTML><HEAD> <META http-equiv=Content-Type content="text/html; charset=windows-1251"> </HEAD>
Such headers are omitted here. This is in part due to the fact that the mail might have arbitrary and even mixed types of text among is message and headers, which might also clash with encoding in the HTML of the reply itself. Consider a mail index list page that displays headers of multiple mails; because each mail’s Subject and From might be encoding in a different character set (one Russian, one Chinese, and so on), a single encoding declaration won’t suffice (though UTF-8’s generality can often come to the rescue). Resolving such mixed character set cases is left to the browser, which may ultimately require assistance from the user in the form of encoding choices. Such displays work in PyMailGUI because we pass decoded Unicode text to the tkinter Text widget, which handles arbitrary Unicode code points well. In PyMailCGI, we’re largely finessing this issue to keep this example short.
Moreover, both text and binary attachments of fetched mails
are simply saved in binary form and opened by filename in browsers
when their links are clicked, relying again on browsers to do the
right thing. Text attachments for sends are also subject to the CGI
upload limitations described in the note just ahead. Beyond all
this, Python 3.1 appears to have an issue printing some types of
Unicode text to the standard output stream in the CGI context, which
necessitates a workaround in the main utilities module here that
opens stdout in binary mode and
writes text as encoded bytes (see the code for more details).
This Unicode/i18n support is substantially less rich than that in PyMailGUI. However, given that we can’t prompt for encodings here, and given that this book is running short on time and space in general, improving this for cases and browsers where it might matter is left as a suggested exercise.
For more on specific 3.0 fourth-edition changes made, see the comments marked with “3.0” in the program code files listed ahead. In addition, all the features added for the prior edition are still here, as described in the next section.
New in the Prior Edition (Version 2.0)
In the third edition, PyMailCGI was upgraded to use the new
mailtools module package of Chapter 13, employ the PyCrypto package for
passwords if it is installed, support viewing and sending message
attachments, and run more efficiently. All these are inherited by
version 3.0 as well.
We’ll meet these new features along the way, but the last two
of these merit a few words up front. Attachments are supported in a
simplistic but usable fashion and use existing mailtools package code for much of their
operation:
For viewing attachments, message parts are split off the message and saved in local files on the server. Message view pages are then augmented with hyperlinks pointing to the temporary files; when clicked, they open in whatever way your web browser opens the selected part’s file type.
For sending attachments, we use the HTML upload techniques presented near the end of Chapter 15. Mail edit pages now have file-upload controls, to allow a maximum of three attachments. Selected files are uploaded to the server by the browser with the rest of the page as usual, saved in temporary files on the server, and added to the outgoing mail from the local files on the server by
mailtools. As described in the note in the preceding section, sent attachments can only be compatibly encoded text in version 3.0, not binary, though this includes encodable HTML files.
Both schemes would fail for multiple simultaneous users, but since PyMailCGI’s configuration file scheme (described later in this chapter) already limits it to a single username, this is a reasonable constraint. The links to temporary files generated for attachment viewing also apply only to the last message selected, but this works if the page flow is followed normally. Improving this for a multiuser scenario, as well as adding additional features such as PyMailGUI’s local file save and open options, are left as exercises.
For efficiency, this version of PyMailCGI also avoids repeated
exhaustive mail downloads. In the prior version, the full text of
all messages in an inbox was downloaded every time you visited the
list page and every time you selected a single message to view. In
this version, the list page downloads only the header text portion
of each message, and only a single message’s full text is downloaded
when one is selected for viewing. In addition, the headers fetch
limits added to mailtools in the
fourth edition of this book are applied automatically to limit
download time (earlier mails outside the set’s size are
ignored).
Even so, the list page’s headers-only download can be slow if you have many messages in your inbox (and as I confessed in Chapter 14, I have thousands in one of mine). A better solution would somehow cache mails to limit reloads, at least for the duration of a browser session. For example, we might load headers of only newly arrived messages, and cache headers of mails already fetched, as done in the PyMailGUI client of Chapter 14.
Due to the lack of state retention in CGI scripts, though, this would likely require some sort of server-side database. We might, for instance, store already fetched message headers under a generated key that identifies the session (e.g., with process number and time) and pass that key between pages as a cookie, hidden form field, or URL query parameter. Each page would use the key to fetch cached mail stored directly on the web server, instead of loading it from the email server again. Presumably, loading from a local cache file would be faster than loading from a network connection to the mail server.
This would make for an interesting exercise, too, if you wish to extend this system on your own, but it would also result in more pages than this chapter has to spend (frankly, I ran out of time for this project and real estate in this chapter long before I ran out of potential enhancements).
Presentation Overview
Much of the “action” in PyMailCGI is encapsulated in shared
utility modules, especially one called commonhtml.py. As you’ll see in a moment,
the CGI scripts that implement user interaction don’t do much by
themselves because of this. This architecture was chosen
deliberately, to make scripts simple, avoid code redundancy, and
implement a common look-and-feel in shared code. But it means you
must jump between files to understand how the whole system
works.
To make this example easier to digest, we’re going to explore its code in two chunks: page scripts first, and then the utility modules. First, we’ll study screenshots of the major web pages served up by the system and the HTML files and top-level Python CGI scripts used to generate them. We begin by following a send mail interaction, and then trace how existing email is read and then processed. Most implementation details will be presented in these sections, but be sure to flip ahead to the utility modules listed later to understand what the scripts are really doing.
I should also point out that this is a fairly complex system, and I won’t describe it in exhaustive detail; as for PyMailGUI and Chapter 14, be sure to read the source code along the way for details not made explicit in the narrative. All of the system’s source code appears in this chapter, as well as in the book’s examples distribution package, and we will study its key concepts here. But as usual with case studies in this book, I assume that you can read Python code by now and that you will consult the example’s source code for more details. Because Python’s syntax is so close to “executable pseudocode,” systems are sometimes better described in Python than in English once you have the overall design in mind.
Running This Chapter’s Examples
The HTML pages and CGI scripts of PyMailCGI can be installed on any
web server to which you have access. To keep things simple for this
book, though, we’re going to use the same policy as in Chapter 15—we’ll be running the Python-coded
webserver.py script from Example 16-1 locally, on the same
machine as the web browser client. As we learned at the start of the
prior chapter, that means we’ll be using the server domain name
“localhost” (or the equivalent IP address, “127.0.0.1”) to access
this system’s pages in our browser, as well as in the urllib.request
module.
Start this server script on your own machine to test-drive the program. Ultimately, this system must generally contact a mail server over the Internet to fetch or send messages, but the web page server will be running locally on your computer.
One minor twist here: PyMailCGI’s code is located in a directory of its own, one level down from the webserver.py script. Because of that, we’ll start the web server here with an explicit directory and port number in the command line used to launch it:
C:...PP4EInternetWeb> webserver.py PyMailCgi 8000Type this sort of command into a command prompt window on Windows or into your system shell prompt on Unix-like platforms. When run this way, the server will listen for URL requests on machine “localhost” and socket port number 8000. It will serve up pages from the PyMailCgi subdirectory one level below the script’s location, and it will run CGI scripts located in the PyMailCgicgi-bin directory below that. This works because the script changes its current working directory to the one you name when it starts up.
Subtle point: because we specify a unique port number on the command line this way, it’s OK if you simultaneously run another instance of the script to serve up the prior chapter’s examples one directory up; that server instance will accept connections on port 80, and our new instance will handle requests on port 8000. In fact, you can contact either server from the same browser by specifying the desired server’s port number. If you have two instances of the server running in the two different chapters’ directories, to access pages and scripts of the prior chapter, use a URL of this form:
http://localhost/languages.html http://localhost/cgi-bin/languages.py?language=All
And to run this chapter’s pages and scripts, simply use URLs of this form:
http://localhost:8000/pymailcgi.html http://localhost:8000/cgi-bin/onRootSendLink.py
You’ll see that the HTTP and CGI log messages appear in the window of the server you’re contacting. For more background on why this works as it does, see the introduction to network socket addresses in Chapter 12 and the discussion of URLs in Chapter 15.
If you do install this example’s code on a different server, simply replace the “localhost:8000/cgi-bin” part of the URLs we’ll use here with your server’s name, port, and path details. In practice, a system such as PyMailCGI would be much more useful if it were installed on a remote server, to allow mail processing from any web client.[66]
As with PyMailGUI, you’ll have to edit the mailconfig.py module’s settings to use
this system to read your own email. As provided, the email server
information is not useful for reading email of your own; more on
this in a moment.
The Root Page
Let’s start off by implementing a main page for this example. The file shown in Example 16-2 is primarily used to publish links to the Send and View functions’ pages. It is coded as a static HTML file, because there is nothing to generate on the fly here.
<HTML>
<TITLE>PyMailCGI Main Page</TITLE>
<BODY>
<H1 align=center>PyMailCGI</H1>
<H2 align=center>A POP/SMTP Web Email Interface</H2>
<P align=center><I>Version 3.0 June 2010 (2.0 January 2006)</I></P>
<table>
<tr><td><hr>
<h2>Actions</h2>
<P>
<UL>
<LI><a href="cgi-bin/onRootViewLink.py">View, Reply, Forward, Delete POP mail</a>
<LI><a href="cgi-bin/onRootSendLink.py">Send a new email message by SMTP</a>
</UL></P>
<tr><td><hr>
<h2>Overview</h2>
<P>
<A href="http://rmi.net/~lutz/about-pp.html">
<IMG src="ppsmall.gif" align=left
alt="[Book Cover]" border=1 hspace=10></A>
This site implements a simple web-browser interface to POP/SMTP email
accounts. Anyone can send email with this interface, but for security
reasons, you cannot view email unless you install the scripts with your
own email account information, in your own server account directory.
PyMailCgi is implemented as a number of Python-coded CGI scripts that run on
a server machine (not your local computer), and generate HTML to interact
with the client/browser. See the book <I>Programming Python, 4th Edition</I>
for more details.</P>
<tr><td><hr>
<h2>Notes</h2>
<P>Caveats: PyMailCgi 1.0 was initially written during a 2-hour layover at
Chicago's O'Hare airport. This release is not nearly as fast or complete
as PyMailGUI (e.g., each click requires an Internet transaction, there
is no save operation or multithreading, and there is no caching of email
headers or already-viewed messages). On the other hand, PyMailCgi runs on
any web browser, whether you have Python (and Tk) installed on your machine
or not.
<P>Also note that if you use these scripts to read your own email, PyMailCgi
does not guarantee security for your account password. See the notes in the
View action page as well as the book for more information on security policies.
<p><I><U>New in Version 2</U></I>: PyMailCGI now supports viewing and sending
Email attachments for a single user, and avoids some of the prior version's
exhaustive mail downloads. It only fetches message headers for the list page,
and only downloads the full text of the single message selected for viewing.
<p><I><U>New in Version 3</U></I>: PyMailCGI now runs on Python 3.X (only),
and employs many of the new features of the mailtools package: decoding and
encoding of Internationalized headers, decoding of main mail text, and so on.
Due to a regression in Python 3.1's cgi and email support, version 3.0 does
not support sending of binary or incompatibly-encoded text attachments, though
attachments on fetched mails can always be viewed (see Chapter 15 and 16).
<p>Also see:
<UL>
<li>The <I>PyMailGUI</I> program in the Internet directory, which
implements a more complete client-side Python+Tk email GUI
<li>The <I>pymail.py</I> program in the Email directory, which
provides a simple console command-line email interface
<li>The Python imaplib module which supports the IMAP email protocol
instead of POP
</UL></P>
</table><hr>
<A href="http://www.python.org">
<IMG SRC="PythonPoweredSmall.gif" ALIGN=left
ALT="[Python Logo]" border=0 hspace=15></A>
<A href="http://rmi.net/~lutz/about-pp.html">[Book]</a>
<A href="http://www.oreilly.com">[O'Reilly]</a>
</BODY></HTML>The file pymailcgi.html is the system’s root page and lives in a PyMailCgi subdirectory which is dedicated to this application and helps keep its files separate from other examples. To access this system, start your locally running web server as described in the preceding section and then point your browser to the following URL (or do the right thing for whatever other web server you may be using):
http://localhost:8000/pymailcgi.html
If you do, the server will ship back a page such as that captured in Figure 16-2, shown rendered in the Google Chrome web browser client on Windows 7. I’m using Chrome instead of Internet Explorer throughout this chapter for variety, and because it tends to yield a concise page which shows more details legibly. Open this in your own browser to see it live—this system is as portable as the Web, HTML, and Python-coded CGI scripts.
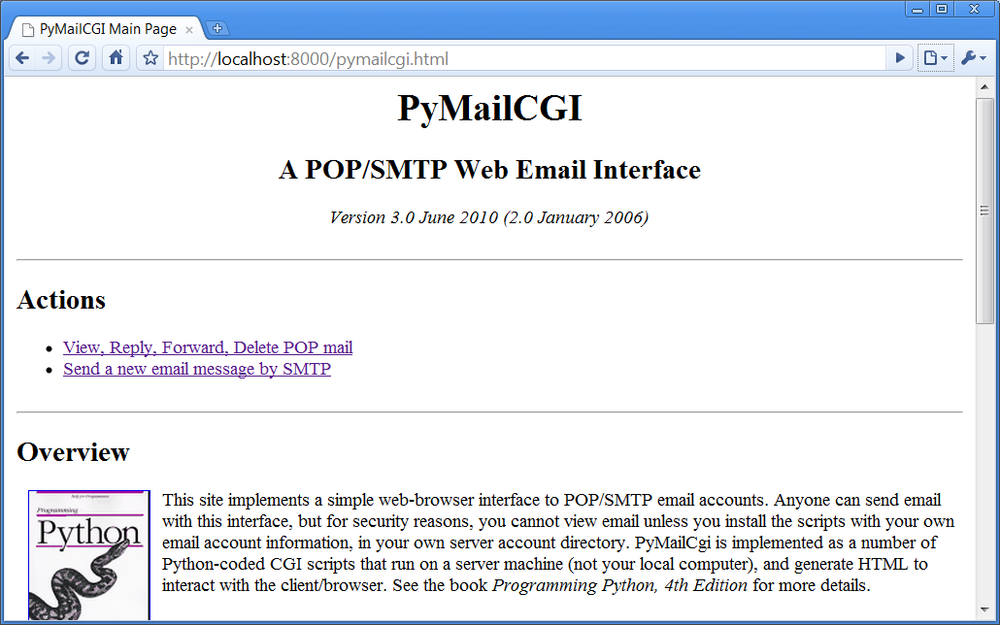
Configuring PyMailCGI
Now, before you click on the “View…” link in Figure 16-2 expecting to read your own email, I should point out that by default, PyMailCGI allows anybody to send email from this page with the Send link (as we learned earlier, there are no passwords in SMTP). It does not, however, allow arbitrary users on the Web to read their email accounts without either typing an explicit and unsafe URL or doing a bit of installation and configuration.
This is on purpose, and it has to do with security constraints; as we’ll see later, PyMailCGI is written such that it never associates your email username and password together without encryption. This isn’t an issue if your web server is running locally, of course, but this policy is in place in case you ever run this system remotely across the Web.
By default, then, this page is set up to read the email account shown in this book—address [email protected]—and requires that account’s POP password to do so. Since you probably can’t guess the password (and wouldn’t find its email all that interesting if you could!), PyMailCGI is not incredibly useful as shipped. To use it to read your email instead, you’ll want to change its mailconfig.py mail configuration file to reflect your mail account’s details. We’ll see this file later; for now, the examples here will use the book’s POP email account; it works the same way, regardless of which account it accesses.
Sending Mail by SMTP
PyMailCGI supports two main functions, as links on the root page: composing and sending new mail to others, and viewing incoming mail. The View function leads to pages that let users read, reply to, forward, and delete existing email. Since the Send function is the simplest, let’s start with its pages and scripts first.
The Message Composition Page
The root page Send function steps users through two other pages: one to edit a message and one to confirm delivery. When you click on the Send link on the main page in Figure 16-2, the Python CGI script in Example 16-3 runs on the web server.
#!/usr/bin/python
"""
################################################################################
On 'send' click in main root window: display composition page
################################################################################
"""
import commonhtml
from externs import mailconfig
commonhtml.editpage(kind='Write', headers={'From': mailconfig.myaddress})No, this file wasn’t truncated; there’s not much to see in
this script because all the action has been encapsulated in the
commonhtml and externs modules. All that we can tell here
is that the script calls something named editpage to generate a reply, passing in
something called myaddress for
its “From” header.
That’s by design—by hiding details in shared utility modules we make top-level scripts such as this much easier to read and write, avoid code redundancy, and achieve a common look-and-feel to all our pages. There are no inputs to this script either; when run, it produces a page for composing a new message, as shown in Figure 16-3.

Most of the composition page is self-explanatory—fill in
headers and the main text of the message (a “From” header and
standard signature line are initialized from settings in the
mailconfig module, discussed
further ahead). The Choose File buttons open file selector dialogs,
for picking an attachment. This page’s interface looks very
different from the PyMailGUI client program in Chapter 14, but it is functionally very
similar. Also notice the top and bottom of this page—for reasons
explained in the next section, they are going to look the same in
all the pages of our system.
The Send Mail Script
As usual, the HTML of the edit page in Figure 16-3 names its handler script. When we click its Send button, Example 16-4 runs on the server to process our inputs and send the mail message.
#!/usr/bin/python
"""
################################################################################
On submit in edit window: finish a write, reply, or forward;
in 2.0+, we reuse the send tools in mailtools to construct and send the message,
instead of older manual string scheme; we also inherit attachment structure
composition and MIME encoding for sent mails from that module;
3.0: CGI uploads fail in the py3.1 cgi module for binary and incompatibly-encoded
text, so we simply use the platform default here (cgi's parser does no better);
3.0: use simple Unicode encoding rules for main text and attachments too;
################################################################################
"""
import cgi, sys, commonhtml, os
from externs import mailtools
savedir = 'partsupload'
if not os.path.exists(savedir):
os.mkdir(savedir)
def saveAttachments(form, maxattach=3, savedir=savedir):
"""
save uploaded attachment files in local files on server from
which mailtools will add to mail; the 3.1 FieldStorage parser
and other parts of cgi module can fail for many upload types,
so we don't try very hard to handle Unicode encodings here;
"""
partnames = []
for i in range(1, maxattach+1):
fieldname = 'attach%d' % i
if fieldname in form and form[fieldname].filename:
fileinfo = form[fieldname] # sent and filled?
filedata = fileinfo.value # read into string
filename = fileinfo.filename # client's pathname
if '' in filename:
basename = filename.split('')[-1] # try DOS clients
elif '/' in filename:
basename = filename.split('/')[-1] # try Unix clients
else:
basename = filename # assume dir stripped
pathname = os.path.join(savedir, basename)
if isinstance(filedata, str): # 3.0: rb needs bytes
filedata = filedata.encode() # 3.0: use encoding?
savefile = open(pathname, 'wb')
savefile.write(filedata) # or a with statement
savefile.close() # but EIBTI still
os.chmod(pathname, 0o666) # need for some srvrs
partnames.append(pathname) # list of local paths
return partnames # gets type from name
#commonhtml.dumpstatepage(0)
form = cgi.FieldStorage() # parse form input data
attaches = saveAttachments(form) # cgi.print_form(form) to see
# server name from module or get-style URL
smtpservername = commonhtml.getstandardsmtpfields(form)
# parms assumed to be in form or URL here
from commonhtml import getfield # fetch value attributes
From = getfield(form, 'From') # empty fields may not be sent
To = getfield(form, 'To')
Cc = getfield(form, 'Cc')
Subj = getfield(form, 'Subject')
text = getfield(form, 'text')
if Cc == '?': Cc = ''
# 3.0: headers encoded per utf8 within mailtools if non-ascii
parser = mailtools.MailParser()
Tos = parser.splitAddresses(To) # multiple recip lists: ',' sept
Ccs = (Cc and parser.splitAddresses(Cc)) or ''
extraHdrs = [('Cc', Ccs), ('X-Mailer', 'PyMailCGI 3.0')]
# 3.0: resolve main text and text attachment encodings; default=ascii in mailtools
bodyencoding = 'ascii'
try:
text.encode(bodyencoding) # try ascii first (or latin-1?)
except (UnicodeError, LookupError): # else use tuf8 as fallback (or config?)
bodyencoding = 'utf-8' # tbd: this is more limited than PyMailGUI
# 3.0: use utf8 for all attachments; we can't ask here
attachencodings = ['utf-8'] * len(attaches) # ignored for non-text parts
# encode and send
sender = mailtools.SilentMailSender(smtpservername)
try:
sender.sendMessage(From, Tos, Subj, extraHdrs, text, attaches,
bodytextEncoding=bodyencoding,
attachesEncodings=attachencodings)
except:
commonhtml.errorpage('Send mail error')
else:
commonhtml.confirmationpage('Send mail')This script gets mail header and text input information from
the edit page’s form (or from query parameters in an explicit URL)
and sends the message off using Python’s standard smtplib module, courtesy of the mailtools package. We studied mailtools in Chapter 13, so I won’t say much more about
it now. Note, though, that because we are reusing its send call,
sent mail is automatically saved in a sentmail.txt file on the server; there
are no tools for viewing this in PyMailCGI itself, but it serves as
a log.
New in version 2.0, the saveAttachments function grabs any part
files sent from the browser and stores them in temporary local files
on the server from which they will be added to the mail when sent.
We covered CGI upload in detail at the end of Chapter 15; see that discussion for more on
how the code here works (as well as its limitations in Python 3.1
and this edition—we’re attaching simple text here to accommodate).
The business of attaching the files to the mail itself is automatic
in mailtools.
A utility in commonhtml
ultimately fetches the name of the SMTP server to receive the
message from either the mailconfig module or the script’s inputs
(in a form field or URL query parameter). If all goes well, we’re
presented with a generated confirmation page, as captured in Figure 16-4.
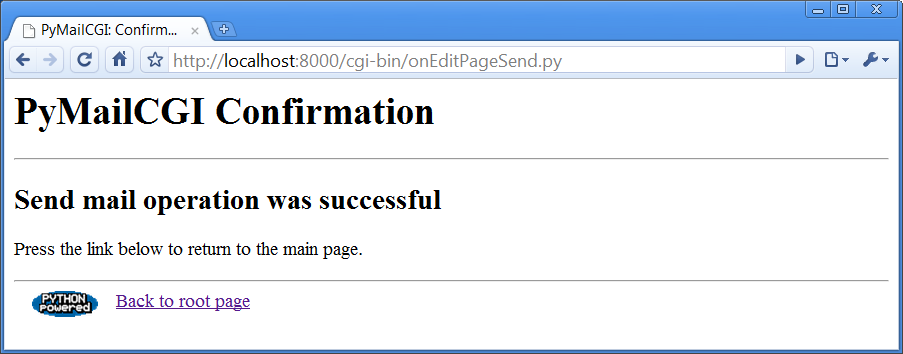
Open file sentmail.txt in PyMailCGI’s source directory if you want to see what the resulting mail’s raw text looks like when sent (or fetch the message in an email client with a raw text view, such as PyMailGUI). In this version, each attachment part is MIME encoded per Base64 with UTF-8 Unicode encoding in the multipart message, but the main text part is sent as simple ASCII if it works as such.
As we’ll see, this send mail script is also used to deliver reply and forward messages for incoming POP mail. The user interface for those operations is slightly different for composing new email from scratch, but as in PyMailGUI, the submission handler logic has been factored into the same, shared code—replies and forwards are really just mail send operations with quoted text and preset header fields.
Notice that there are no usernames or passwords to be found
here; as we saw in Chapter 13, SMTP
usually requires only a server that listens on the SMTP port, not a
user account or password. As we also saw in that chapter, SMTP send
operations that fail either raise a Python exception (e.g., if the
server host can’t be reached) or return a dictionary of failed
recipients; our mailtools package
modules insulate us from these details by always raising an
exception in either case.
Error Pages
If there is a problem during mail delivery, we get an error page
such as the one shown in Figure 16-5. This page reflects a failed
recipient and includes a stack trace generated by the standard
library’s traceback
module. On errors Python detects, the Python error message and extra
details would be displayed.

It’s also worth pointing out that the commonhtml module encapsulates the
generation of both the confirmation and the error pages so that all
such pages look the same in PyMailCGI no matter where and when they
are produced. Logic that generates the mail edit page in commonhtml is reused by the reply and
forward actions, too (but with different mail headers).
Common Look-and-Feel
In fact, commonhtml makes
all pages look similar—it also provides common page
header (top) and footer
(bottom) generation functions, which are used everywhere in the
system. You may have already noticed that all the pages so far
follow the same pattern: they start with a title and horizontal
rule, have something unique in the middle, and end with another
rule, followed by a Python icon and link at the bottom. This
common look-and-feel is the product of shared
code in commonhtml; it generates
everything but the middle section for every page in the system
(except the root page, a static HTML file).
Most important, if we ever change the header and footer format
functions in the commonhtml module, all our page’s headers
and footers will automatically be updated. If you are interested in
seeing how this encapsulated logic works right now, flip ahead to
Example 16-14. We’ll
explore its code after we study the rest of the mail site’s
pages.
Using the Send Mail Script Outside a Browser
I initially wrote the send script to be used only within PyMailCGI using
values typed into the mail edit form. But as we’ve seen, inputs can
be sent in either form fields or URL query parameters. Because the
send mail script checks for inputs in CGI inputs before importing
from the mailconfig module,
it’s also possible to call this script outside the edit page to send
email—for instance, explicitly typing a URL of this nature into your
browser’s address field (but all on one line and with no intervening
spaces):
http://localhost:8000/cgi-bin/
onEditPageSend.py?site=smtp.rmi.net&
[email protected]&
[email protected]&
Subject=test+url&
text=Hello+Mark;this+is+Markwill indeed send an email message as specified by the input
parameters at the end. That URL string is a lot to type into a
browser’s address field, of course, but it might be useful if
generated automatically by another script. As we saw in Chapters
13 and 15,
the module urllib.request
can then be used to submit such a URL string to the
server from within a Python program. Example 16-5 shows one way to
automate this.
"""
####################################################################
Send email by building a URL like this from inputs:
http://servername/pathname/
onEditPageSend.py?site=smtp.rmi.net&
[email protected]&
[email protected]&
Subject=test+url&
text=Hello+Mark;this+is+Mark
####################################################################
"""
from urllib.request import urlopen
from urllib.parse import quote_plus
url = 'http://localhost:8000/cgi-bin/onEditPageSend.py'
url += '?site=%s' % quote_plus(input('Site>'))
url += '&From=%s' % quote_plus(input('From>'))
url += '&To=%s' % quote_plus(input('To >'))
url += '&Subject=%s' % quote_plus(input('Subj>'))
url += '&text=%s' % quote_plus(input('text>')) # or input loop
print('Reply html:')
print(urlopen(url).read().decode()) # confirmation or error page HTMLRunning this script from the system command line is yet another way to send an email message—this time, by contacting our CGI script on a web server machine to do all the work. The script sendurl.py runs on any machine with Python and sockets, lets us input mail parameters interactively, and invokes another Python script that lives on a possibly remote machine. It prints HTML returned by our CGI script:
C:...PP4EInternetWebPyMailCgi>sendurl.pySite>smtpout.secureserver.netFrom>[email protected]To >[email protected]Subj>testing sendurl.pytext>But sir, it's only wafer-thin...Reply html: <html><head><title>PyMailCGI: Confirmation page (PP4E)</title></head> <body bgcolor="#FFFFFF"><h1>PyMailCGI Confirmation</h1><hr> <h2>Send mail operation was successful</h2> <p>Press the link below to return to the main page.</p> </p><hr><a href="http://www.python.org"> <img src="../PythonPoweredSmall.gif" align=left alt="[Python Logo]" border=0 hspace=15></a> <a href="../pymailcgi.html">Back to root page</a> </body></html>
The HTML reply printed by this script would normally be
rendered into a new web page if caught by a browser. Such cryptic
output might be less than ideal, but you could easily search the
reply string for its components to determine the result (e.g., using
the string find method or an
in membership test to look for
“successful”), parse out its components with Python’s standard
html.parse or re modules (covered in Chapter 19),
and so on. The resulting mail message—viewed, for variety, with
Chapter 14’s PyMailGUI program—shows
up in this book’s email account as seen in Figure 16-6
(it’s a single text-part message).

Of course, there are other, less remote ways to send email
from a client machine. For instance, the Python smtplib module (used by mailtools) itself depends only upon the
client and SMTP server connections being operational, whereas this
script also depends on the web server machine and CGI script
(requests go from client to web server to CGI script to SMTP
server). Because our CGI script supports general URLs, though, it
can do more than a mailto: HTML
tag and can be invoked with urllib.request outside the context of a
running web browser. For instance, as discussed in Chapter 15, scripts like
sendurl.py can be used to invoke and
test server-side programs.
Reading POP Email
So far, we’ve stepped through the path the system follows to send new mail. Let’s now see what happens when we try to view incoming POP mail.
The POP Password Page
If you flip back to the main page in Figure 16-2, you’ll see a View link; pressing it triggers the script in Example 16-6 to run on the server.
#!/usr/bin/python
"""
################################################################################
On view link click on main/root HTML page: make POP password input page;
this could almost be an HTML file because there are likely no input params yet,
but I wanted to use standard header/footer functions and display the site/user
names which must be fetched; on submission, does not send the user along with
password here, and only ever sends both as URL params or hidden fields after the
password has been encrypted by a user-uploadable encryption module;
################################################################################
"""
# page template
pswdhtml = """
<form method=post action=%sonViewPswdSubmit.py>
<p>
Please enter POP account password below, for user "%s" and site "%s".
<p><input name=pswd type=password>
<input type=submit value="Submit"></form></p>
<hr><p><i>Security note</i>: The password you enter above will be transmitted
over the Internet to the server machine, but is not displayed, is never
transmitted in combination with a username unless it is encrypted or obfuscated,
and is never stored anywhere: not on the server (it is only passed along as hidden
fields in subsequent pages), and not on the client (no cookies are generated).
This is still not guaranteed to be totally safe; use your browser's back button
to back out of PyMailCgi at any time.</p>
"""
# generate the password input page
import commonhtml # usual parms case:
user, pswd, site = commonhtml.getstandardpopfields({}) # from module here,
commonhtml.pageheader(kind='POP password input') # from html|url later
print(pswdhtml % (commonhtml.urlroot, user, site))
commonhtml.pagefooter()This script is almost all embedded HTML: the triple-quoted
pswdhtml string is printed, with
string formatting to insert values, in a single step. But because we
need to fetch the username and server name to display on the
generated page, this is coded as an executable script, not as a
static HTML file. The module commonhtml either loads usernames and
server names from script inputs (e.g., appended as query parameters
to the script’s URL) or imports them from the mailconfig file; either way, we don’t want
to hardcode them into this script or its HTML, so a simple HTML file
won’t do. Again, in the CGI world, we embed HTML code in Python code
and fill in its values this way (in server-side templating tools
such as PSP the effect is similar, but Python code is embedded in
HTML code instead and run to produce values).
Since this is a script, we can also use the commonhtml page header and footer routines
to render the generated reply page with a common look-and-feel, as
shown in Figure 16-7.

At this page, the user is expected to enter the password for
the POP email account of the user and server displayed. Notice that
the actual password isn’t displayed; the input field’s HTML
specifies type=password, which
works just like a normal text field, but shows typed input as stars.
(See also the pymail program in Chapter 13 for doing this at a console and
PyMailGUI in Chapter 14 for doing this
in a tkinter GUI.)
The Mail Selection List Page
After you fill out the last page’s password field and press its Submit button, the password is shipped off to the script shown in Example 16-7.
#!/usr/bin/python
"""
################################################################################
On submit in POP password input window: make mail list view page;
in 2.0+ we only fetch mail headers here, and fetch 1 full message later upon
request; we still fetch all headers each time the index page is made: caching
Messages would require a server-side(?) database and session key, or other;
3.0: decode headers for list display, though printer and browser must handle;
################################################################################
"""
import cgi
import loadmail, commonhtml
from externs import mailtools
from secret import encode # user-defined encoder module
MaxHdr = 35 # max length of email hdrs in list
# only pswd comes from page here, rest usually in module
formdata = cgi.FieldStorage()
mailuser, mailpswd, mailsite = commonhtml.getstandardpopfields(formdata)
parser = mailtools.MailParser()
try:
newmails = loadmail.loadmailhdrs(mailsite, mailuser, mailpswd)
mailnum = 1
maillist = [] # or use enumerate()
for mail in newmails: # list of hdr text
msginfo = []
hdrs = parser.parseHeaders(mail) # email.message.Message
addrhdrs = ('From', 'To', 'Cc', 'Bcc') # decode names only
for key in ('Subject', 'From', 'Date'):
rawhdr = hdrs.get(key, '?')
if key not in addrhdrs:
dechdr = parser.decodeHeader(rawhdr) # 3.0: decode for display
else: # encoded on sends
dechdr = parser.decodeAddrHeader(rawhdr) # email names only
msginfo.append(dechdr[:MaxHdr])
msginfo = ' | '.join(msginfo)
maillist.append((msginfo, commonhtml.urlroot + 'onViewListLink.py',
{'mnum': mailnum,
'user': mailuser, # data params
'pswd': encode(mailpswd), # pass in URL
'site': mailsite})) # not inputs
mailnum += 1
commonhtml.listpage(maillist, 'mail selection list')
except:
commonhtml.errorpage('Error loading mail index')This script’s main purpose is to generate a selection list page for the user’s email account, using the password typed into the prior page (or passed in a URL). As usual with encapsulation, most of the details are hidden in other files:
loadmail.loadmailhdrsReuses the
mailtoolsmodule package from Chapter 13 to fetch email with the POP protocol; we need a message count and mail headers here to display an index list. In this version, the software fetches only mail header text to save time, not full mail messages (provided your server supports theTOPcommand of the POP interface, and most do—if not, seemailconfigto disable this).commonhtml.listpageGenerates HTML to display a passed-in list of tuples
(text,URL,parameter-dictionary) as a list of hyperlinks in the reply page; parameter values show up as query parameters at the end of URLs in the response.
The maillist list built
here is used to create the body of the next page—a clickable email
message selection list. Each generated hyperlink in the list page
references a constructed URL that contains enough information for
the next script to fetch and display a particular email message. As
we learned in the preceding chapter, this is a simple kind of state
retention between pages and scripts.
If all goes well, the mail selection list page HTML generated
by this script is rendered as in Figure 16-8. If your inbox
is as large as some of mine, you’ll probably need to scroll down to
see the end of this page. This page follows the common look-and-feel
for all PyMailCGI pages, thanks to commonhtml.

If the script can’t access your email account (e.g., because
you typed the wrong password), its try statement handler instead produces a
commonly formatted error page. Figure 16-9 shows one that gives the
Python exception and details as part of the reply after a
Python-raised exception is caught; as usual, the exception details
are fetched from sys.exc_info,
and Python’s traceback
module is used to generate a stack trace.

Passing State Information in URL Link Parameters
The central mechanism at work in Example 16-7 is the generation of URLs that embed message numbers and mail account information. Clicking on any of the View links in the selection list triggers another script, which uses information in the link’s URL parameters to fetch and display the selected email. As mentioned in Chapter 15, because the list’s links are programmed to “know” how to load a particular message, they effectively remember what to do next. Figure 16-10 shows part of the HTML generated by this script (use your web browser View Source option to see this for yourself—I did a Save As and then opened the result which invoked Internet Explorer’s source viewer on my laptop).

Did you get all the details in Figure 16-10? You may not be able to read generated HTML like this, but your browser can. For the sake of readers afflicted with human-parsing limitations, here is what one of those link lines looks like, reformatted with line breaks and spaces to make it easier to understand:
<tr><th><a href="onViewListLink.py?
pswd=wtGmpsjeb7359&
mnum=5&
user=PP4E%40learning-python.com&
site=pop.secureserver.net">View</a>
<td>Among our weapons are these | [email protected] | Fri, 07 May 2010 20:32...PyMailCGI generates relative minimal URLs (server and pathname
values come from the prior page, unless set in commonhtml). Clicking on the word
View in the hyperlink rendered from this HTML
code triggers the onViewListLink
script as usual, passing it all the parameters embedded at the end
of the URL: the POP username, the POP message number of the message
associated with this link, and the POP password and site
information. These values will be available in the object returned
by cgi.FieldStorage in the next script run. Note that the mnum POP message number parameter differs
in each link because each opens a different message when clicked and
that the text after <td>
comes from message headers extracted by the mailtools package, using the email package.
The commonhtml module
escapes all of the link parameters with the urllib.parse module, not cgi.escape, because they are part of a
URL. This can matter in the pswd
password parameter—its value might be encrypted and arbitrary bytes,
but urllib.parse additionally escapes nonsafe characters in the
encrypted string per URL convention (it translates to %xx character sequences). It’s OK if the
encryptor yields odd—even nonprintable—characters because URL
encoding makes them legible for transmission. When the password
reaches the next script, cgi.FieldStorage undoes URL escape
sequences, leaving the encrypted password string without % escapes.
It’s instructive to see how commonhtml builds up the stateful link
parameters. Earlier, we learned how to use the urllib.parse.quote_plus call to escape a
string for inclusion in URLs:
>>>import urllib.parse>>>urllib.parse.quote_plus("There's bugger all down here on Earth")'There%27s+bugger+all+down+here+on+Earth'
The module commonhtml,
though, calls the higher-level urllib.parse.urlencode function,
which translates a dictionary of
name:value pairs into a complete URL
query parameter string, ready to add after a ? marker in a URL. For instance, here is
urlencode in action at
the interactive prompt:
>>>parmdict = {'user': 'Brian',...'pswd': '#!/spam',...'text': 'Say no more, squire!'}>>>urllib.parse.urlencode(parmdict)'text=Say+no+more%2C+squire%21&pswd=%23%21%2Fspam&user=Brian' >>>"%s?%s" % ("http://scriptname.py", urllib.parse.urlencode(parmdict))'http://scriptname.py?text=Say+no+more%2C+squire%21&pswd=%23%21%2Fspam&user=Brian'
Internally, urlencode
passes each name and value in the dictionary to the built-in
str function (to make sure they
are strings), and then runs each one through urllib.parse.quote_plus as they are added
to the result. The CGI script builds up a list of similar
dictionaries and passes it to commonhtml to be formatted into a
selection list page.[67]
In broader terms, generating URLs with parameters like this is one way to pass state information to the next script (along with cookies, hidden form input fields, and server databases, discussed in Chapter 15). Without such state information, users would have to reenter the username, password, and site name on every page they visit along the way.
Incidentally, the list generated by this script is not radically different in functionality from what we built in the PyMailGUI program in Chapter 14, though the two differ cosmetically. Figure 16-11 shows this strictly client-side GUI’s view on the same email list displayed in Figure 16-8.

It’s important to keep in mind that PyMailGUI uses the tkinter GUI library to build up a user interface instead of sending HTML to a browser. It also runs entirely on the client and talks directly to email servers, downloading mail from the POP server to the client machine over sockets on demand. Because it retains memory for the duration of the session, PyMailGUI can easily minimize mail server access. After the initial header load, it needs to load only newly arrived email headers on subsequent load requests. Moreover, it can update its email index in-memory on deletions instead of reloading anew from the server, and it has enough state to perform safe deletions of messages that check for server inbox matches. PyMailGUI also remembers emails you’ve already viewed—they need not be reloaded again while the program runs.
In contrast, PyMailCGI runs on the web server machine and simply displays mail text on the client’s browser—mail is downloaded from the POP server machine to the web server, where CGI scripts are run. Due to the autonomous nature of CGI scripts, PyMailCGI by itself has no automatic memory that spans pages and may need to reload headers and already viewed messages during a single session. These architecture differences have some important ramifications, which we’ll discuss later in this chapter.
Security Protocols
In onViewPswdSubmit’s
source code (Example 16-7), notice that
password inputs are passed to an encode function as they are added to the
parameters dictionary; this causes them to show up encrypted or
otherwise obfuscated in hyperlinked URLs. They are also URL encoded
for transmission (with % escapes
if needed) and are later decoded and decrypted within other scripts
as needed to access the POP account. The password encryption step,
encode, is at the heart of
PyMailCGI’s security policy.
In Python today, the standard library’s ssl module supports Secure Sockets Layer (SSL) with its socket wrapper call, if the required library
is built into your Python. SSL automatically encrypts transmitted
data to make it safe to pass over the Net. Unfortunately, for
reasons we’ll discuss when we reach the secret.py module later in this chapter
(see Example 16-13), this
wasn’t a universal solution for PyMailCGI’s password data. In short,
the Python-coded web server we’re using doesn’t directly support its
end of a secure HTTP encrypted dialog, HTTPS. Because of that, an
alternative scheme was devised to minimize the chance that email
account information could be stolen off the Net in transit.
Here’s how it works. When this script is invoked by the
password input page’s form, it gets only one input parameter: the
password typed into the form. The username is imported from a
mailconfig module installed on
the server; it is not transmitted together with the unencrypted
password because such a combination could be harmful if
intercepted.
To pass the POP username and password to the next page as
state information, this script adds them to the end of the mail
selection list URLs, but only after the password has been encrypted
or obfuscated by secret.encode—a
function in a module that lives on the server and may vary in every
location that PyMailCGI is installed. In fact, PyMailCGI was written to not have to
know about the password encryptor at all; because the encoder is a
separate module, you can provide any flavor you like. Unless you
also publish your encoder module, the encoded password shipped with
the username won’t mean much if seen.
The upshot is that normally PyMailCGI never sends or receives both username and password values together in a single transaction, unless the password is encrypted or obfuscated with an encryptor of your choice. This limits its utility somewhat (since only a single account username can be installed on the server), but the alternative of popping up two pages—one for password entry and one for username—seems even less friendly. In general, if you want to read your mail with the system as coded, you have to install its files on your server, edit its mailconfig.py to reflect your account details, and change its secret.py encoder and decoder as desired.
Reading mail with direct URLs
One exception: since any CGI script can be invoked with parameters in an
explicit URL instead of form field values, and since commonhtml tries to fetch inputs from
the form object before importing them from mailconfig, it is possible for any
person to use this script if installed at an accessible address to
check his or her mail without installing and configuring a copy of
PyMailCGI of their own. For example, a URL such as the following
typed into your browser’s address field or submitted with tools
such as urllib.request (but
without the line break used to make it fit here):
http://localhost:8000/cgi-bin/ onViewPswdSubmit.py?user=lutz&pswd=guess&site=pop.earthlink.net
will actually load email into a selection list page such as that in Figure 16-8, using whatever user, password, and mail site names are appended to the URL. From the selection list, you may then view, reply, forward, and delete email.
Notice that at this point in the interaction, the password
you send in a URL of this form is not
encrypted. Later scripts expect that the password inputs will be
sent encrypted, though, which makes it more difficult to use them
with explicit URLs (you would need to match the encrypted or
obfuscated form produced by the secret module on the server). Passwords
are encoded as they are added to links in the reply page’s
selection list, and they remain encoded in URLs and hidden form
fields thereafter.
Warning
But you shouldn’t use a URL like this, unless you don’t care about exposing your email password. Sending your unencrypted mail user ID and password strings across the Net in a URL such as this is unsafe and open to interception. In fact, it’s like giving away your email—anyone who intercepts this URL or views it in a server logfile will have complete access to your email account. It is made even more treacherous by the fact that this URL format appears in a book that will be distributed all around the world.
If you care about security and want to use PyMailCGI on a
remote server, install it on your server and configure mailconfig and secret. That should at least guarantee
that both your user and password information will never be
transmitted unencrypted in a single transaction. This scheme
still may not be foolproof, so be careful out there. Without
secure HTTP and sockets, the Internet is a “use at your own
risk” medium.
The Message View Page
Back to our page flow; at this point, we are still viewing the message selection list in Figure 16-8. When we click on one of its generated hyperlinks, the stateful URL invokes the script in Example 16-8 on the server, sending the selected message number and mail account information (user, password, and site) as parameters on the end of the script’s URL.
#!/usr/bin/python
"""
################################################################################
On user click of message link in main selection list: make mail view page;
cgi.FieldStorage undoes any urllib.parse escapes in link's input parameters
(%xx and '+' for spaces already undone); in 2.0+ we only fetch 1 mail here, not
the entire list again; in 2.0+ we also find mail's main text part intelligently
instead of blindly displaying full text (with any attachments), and we generate
links to attachment files saved on the server; saved attachment files only work
for 1 user and 1 message; most 2.0 enhancements inherited from mailtools pkg;
3.0: mailtools decodes the message's full-text bytes prior to email parsing;
3.0: for display, mailtools decodes main text, commonhtml decodes message hdrs;
################################################################################
"""
import cgi
import commonhtml, secret
from externs import mailtools
#commonhtml.dumpstatepage(0)
def saveAttachments(message, parser, savedir='partsdownload'):
"""
save fetched email's parts to files on
server to be viewed in user's web browser
"""
import os
if not os.path.exists(savedir): # in CGI script's cwd on server
os.mkdir(savedir) # will open per your browser
for filename in os.listdir(savedir): # clean up last message: temp!
dirpath = os.path.join(savedir, filename)
os.remove(dirpath)
typesAndNames = parser.saveParts(savedir, message)
filenames = [fname for (ctype, fname) in typesAndNames]
for filename in filenames:
os.chmod(filename, 0o666) # some srvrs may need read/write
return filenames
form = cgi.FieldStorage()
user, pswd, site = commonhtml.getstandardpopfields(form)
pswd = secret.decode(pswd)
try:
msgnum = form['mnum'].value # from URL link
parser = mailtools.MailParser()
fetcher = mailtools.SilentMailFetcher(site, user, pswd)
fulltext = fetcher.downloadMessage(int(msgnum)) # don't eval!
message = parser.parseMessage(fulltext) # email pkg Message
parts = saveAttachments(message, parser) # for URL links
mtype, content = parser.findMainText(message) # first txt part
commonhtml.viewpage(msgnum, message, content, form, parts) # encoded pswd
except:
commonhtml.errorpage('Error loading message')Again, much of the work here happens in the commonhtml module, listed later in this
section (see Example 16-14). This script adds
logic to decode the input password (using the configurable secret encryption module) and extract the
selected mail’s headers and text using the mailtools module
package from Chapter 13 again. The
full text of the selected message is ultimately fetched, parsed, and
decoded by mailtools, using the
standard library’s poplib module and
email package. Although we’ll
have to refetch this message if viewed again, version 2.0 and later
do not grab all mails to get just the one selected.[68]
Also new in version 2.0, the saveAttachments function in this script
splits off the parts of a fetched message and stores them in a
directory on the web server machine. This was discussed earlier in
this chapter—the view page is then augmented with URL links that
point at the saved part files. Your web browser will open them
according to their filenames and content. All the work of part
extraction, decoding, and naming is inherited from mailtools. Part files are kept
temporarily; they are deleted when the next message is fetched. They
are also currently stored in a single directory and so apply to only
a single user.
If the message can be loaded and parsed successfully, the
result page, shown in Figure 16-12, allows
us to view, but not edit, the mail’s text. The function commonhtml.viewpage generates a
“read-only” HTML option for all the text widgets in this page. If
you look closely, you’ll notice that this is the mail we sent to
ourselves in Figure 16-3 and which
showed up at the end of the list in Figure 16-8.

View pages like this have a pull-down action selection list near the bottom; if you want to do more, use this list to pick an action (Reply, Forward, or Delete) and click on the Next button to proceed to the next screen. If you’re just in a browsing frame of mind, click the “Back to root page” link at the bottom to return to the main page, or use your browser’s Back button to return to the selection list page.
As mentioned, Figure 16-12 displays the mail we sent earlier in this chapter, being viewed after being fetched. Notice its “Parts:” links—when clicked, they trigger URLs that open the temporary part files on the server, according to your browser’s rules for the file type. For instance, clicking on the “.txt” file will likely open it in either the browser or a text editor. In other mails, clicking on “.jpg” files may open an image viewer, “.pdf” may open Adobe Reader, and so on. Figure 16-13 shows the result of clicking the “.py” attachment part of Figure 16-12’s message in Chrome.

Passing State Information in HTML Hidden Input Fields
What you don’t see on the view page in Figure 16-12 is just as important as what you do
see. We need to defer to Example 16-14 for coding details,
but something new is going on here. The original message number, as
well as the POP user and (still encoded) password information sent
to this script as part of the stateful link’s URL, wind up being
copied into the HTML used to create this view page, as the values of
hidden input fields in the form. The hidden field generation code in
commonhtml looks like
this:
print('<form method=post action="%s/onViewPageAction.py">' % urlroot)
print('<input type=hidden name=mnum value="%s">' % msgnum)
print('<input type=hidden name=user value="%s">' % user) # from page|url
print('<input type=hidden name=site value="%s">' % site) # for deletes
print('<input type=hidden name=pswd value="%s">' % pswd) # pswd encodedAs we’ve learned, much like parameters in generated hyperlink URLs, hidden fields in a page’s HTML allow us to embed state information inside this web page itself. Unless you view that page’s source, you can’t see this state information because hidden fields are never displayed. But when this form’s Submit button is clicked, hidden field values are automatically transmitted to the next script along with the visible fields on the form.
Figure 16-14 shows part of the source code generated for another message’s view page; the hidden input fields used to pass selected mail state information are embedded near the top.

The net effect is that hidden input fields in HTML, just like parameters at the end of generated URLs, act like temporary storage areas and retain state between pages and user interaction steps. Both are the Web’s simplest equivalent to programming language variables. They come in handy anytime your application needs to remember something between pages.
Hidden fields are especially useful if you cannot invoke the next script from a generated URL hyperlink with parameters. For instance, the next action in our script is a form submit button (Next), not a hyperlink, so hidden fields are used to pass state. As before, without these hidden fields, users would need to reenter POP account details somewhere on the view page if they were needed by the next script (in our example, they are required if the next action is Delete).
Escaping Mail Text and Passwords in HTML
Notice that everything you see on the message view page’s HTML in
Figure 16-14 is
escaped with cgi.escape. Header
fields and the text of the mail itself might contain characters that
are special to HTML and must be translated as usual. For instance,
because some mailers allow you to send messages in HTML format, it’s
possible that an email’s text could contain a </textarea> tag, which might throw
the reply page hopelessly out of sync if not escaped.
One subtlety here: HTML escapes are important only when text is sent to the browser initially by the CGI script. If that text is later sent out again to another script (e.g., by sending a reply mail), the text will be back in its original, nonescaped format when received again on the server. The browser parses out escape codes and does not put them back again when uploading form data, so we don’t need to undo escapes later. For example, here is part of the escaped text area sent to a browser during a Reply transaction (use your browser’s View Source option to see this live):
<tr><th align=right>Text: <td><textarea name=text cols=80 rows=10 readonly> more stuff --Mark Lutz (http://rmi.net/~lutz) [PyMailCgi 2.0] > -----Original Message----- > From: [email protected] > To: [email protected] > Date: Tue May 2 18:28:41 2000 > > <table><textarea> > </textarea></table> > --Mark Lutz (http://rmi.net/~lutz) [PyMailCgi 2.0] > > > > -----Original Message-----
After this reply is delivered, its text looks as it did before escapes (and exactly as it appeared to the user in the message edit web page):
more stuff --Mark Lutz (http://rmi.net/~lutz) [PyMailCgi 2.0] > -----Original Message----- > From: [email protected] > To: [email protected] > Date: Tue May 2 18:28:41 2000 > > <table><textarea> > </textarea></table> > --Mark Lutz (http://rmi.net/~lutz) [PyMailCgi 2.0] > > > > -----Original Message-----
Beyond the normal text, the password gets special HTML escapes treatment as well. Though not shown in our examples, the hidden password field of the generated HTML screenshot (Figure 16-14) can look downright bizarre when encryption is applied. It turns out that the POP password is still encrypted when placed in hidden fields of the HTML. For security, they have to be. Values of a page’s hidden fields can be seen with a browser’s View Source option, and it’s not impossible that the text of this page could be saved to a file or intercepted off the Net.
The password is no longer URL encoded when put in the hidden
field, however, even though it was when it appeared as a query
parameter at the end of a stateful URL in the mail list page.
Depending on your encryption module, the password might now contain
nonprintable characters when generated as a hidden field value here;
the browser doesn’t care, as long as the field is run
through cgi.escape like
everything else added to the HTML reply stream. The commonhtml module is careful to route all
text and headers through cgi.escape as the view page is
constructed.
As a comparison, Figure 16-15 shows what the mail message captured in Figure 16-12 looks like when viewed in PyMailGUI, the client-side “desktop” tkinter-based email tool from Chapter 14. In that program, message parts are listed with the Parts button and are extracted, saved, and opened with the Split button; we also get quick-access buttons to parts and attachments just below the message headers. The net effect is similar from an end user’s perspective.

In terms of implementation, though, the model is very different. PyMailGUI doesn’t need to care about things such as passing state in URLs or hidden fields (it saves state in Python in-process variables and memory), and there’s no notion of escaping HTML and URL strings (there are no browsers, and no network transmission steps once mail is downloaded). It also doesn’t have to rely on temporary server file links to give access to message parts—the message is retained in memory attached to a window object and lives on between interactions. On the other hand, PyMailGUI does require Python to be installed on the client, but we’ll return to that in a few pages.
Processing Fetched Mail
At this point in our PyMailCGI web interaction, we are viewing an email message (Figure 16-12) that was chosen from the selection list page. On the message view page, selecting an action from the pull-down list and clicking the Next button invokes the script in Example 16-9 on the server to perform a reply, forward, or delete operation for the selected message viewed.
#!/usr/bin/python
"""
################################################################################
On submit in mail view window: action selected=(fwd, reply, delete);
in 2.0+, we reuse the mailtools delete logic originally coded for PyMailGUI;
################################################################################
"""
import cgi, commonhtml, secret
from externs import mailtools, mailconfig
from commonhtml import getfield
def quotetext(form):
"""
note that headers come from the prior page's form here,
not from parsing the mail message again; that means that
commonhtml.viewpage must pass along date as a hidden field
"""
parser = mailtools.MailParser()
addrhdrs = ('From', 'To', 'Cc', 'Bcc') # decode name only
quoted = '
-----Original Message-----
'
for hdr in ('From', 'To', 'Date'):
rawhdr = getfield(form, hdr)
if hdr not in addrhdrs:
dechdr = parser.decodeHeader(rawhdr) # 3.0: decode for display
else: # encoded on sends
dechdr = parser.decodeAddrHeader(rawhdr) # email names only
quoted += '%s: %s
' % (hdr, dechdr)
quoted += '
' + getfield(form, 'text')
quoted = '
' + quoted.replace('
', '
> ')
return quoted
form = cgi.FieldStorage() # parse form or URL data
user, pswd, site = commonhtml.getstandardpopfields(form)
pswd = secret.decode(pswd)
try:
if form['action'].value == 'Reply':
headers = {'From': mailconfig.myaddress, # 3.0: commonhtml decodes
'To': getfield(form, 'From'),
'Cc': mailconfig.myaddress,
'Subject': 'Re: ' + getfield(form, 'Subject')}
commonhtml.editpage('Reply', headers, quotetext(form))
elif form['action'].value == 'Forward':
headers = {'From': mailconfig.myaddress, # 3.0: commonhtml decodes
'To': '',
'Cc': mailconfig.myaddress,
'Subject': 'Fwd: ' + getfield(form, 'Subject')}
commonhtml.editpage('Forward', headers, quotetext(form))
elif form['action'].value == 'Delete': # mnum field is required here
msgnum = int(form['mnum'].value) # but not eval(): may be code
fetcher = mailtools.SilentMailFetcher(site, user, pswd)
fetcher.deleteMessages([msgnum])
commonhtml.confirmationpage('Delete')
else:
assert False, 'Invalid view action requested'
except:
commonhtml.errorpage('Cannot process view action')This script receives all information about the selected message as form input field data (some hidden and possibly encrypted, some not) along with the selected action’s name. The next step in the interaction depends upon the action selected:
- Reply and Forward actions
Generate a message edit page with the original message’s lines automatically quoted with a leading
>.- Delete actions
Trigger immediate deletion of the email being viewed, using a tool imported from the
mailtoolsmodule package from Chapter 13.
All these actions use data passed in from the prior page’s form, but only the Delete action cares about the POP username and password and must decode the password received (it arrives here from hidden form input fields generated in the prior page’s HTML).
Reply and Forward
If you select Reply as the next action, the message edit page in Figure 16-16 is generated by the script. Text on this page is editable, and pressing this page’s Send button again triggers the send mail script we saw in Example 16-4. If all goes well, we’ll receive the same confirmation page we got earlier when writing new mail from scratch (Figure 16-4).

Forward operations are virtually the same, except for a few
email header differences. All of this busy-ness comes “for free,”
because Reply and Forward pages are generated by calling commonhtml.editpage, the same utility used
to create a new mail composition page. Here, we simply pass
preformatted header line strings to the utility (e.g., replies add
“Re:” to the subject text). We applied the same sort of reuse trick
in PyMailGUI, but in a different context. In PyMailCGI, one script
handles three pages; in PyMailGUI, one superclass and callback
method handles three buttons, but the architecture is similar in
spirit.
Delete
Selecting the Delete action on a message view page and pressing Next
will cause the onViewPageAction
script to immediately delete the message being viewed. Deletions are
performed by calling a reusable delete utility function coded in
Chapter 13’s mailtools package. In a prior version, the
call to the utility was wrapped in a commonhtml.runsilent call that prevents
print call statements in the
utility from showing up in the HTML reply stream (they are just
status messages, not HTML code). In this version, we get the same
capability from the “Silent” classes in mailtools. Figure 16-17 shows a Delete
operation in action.
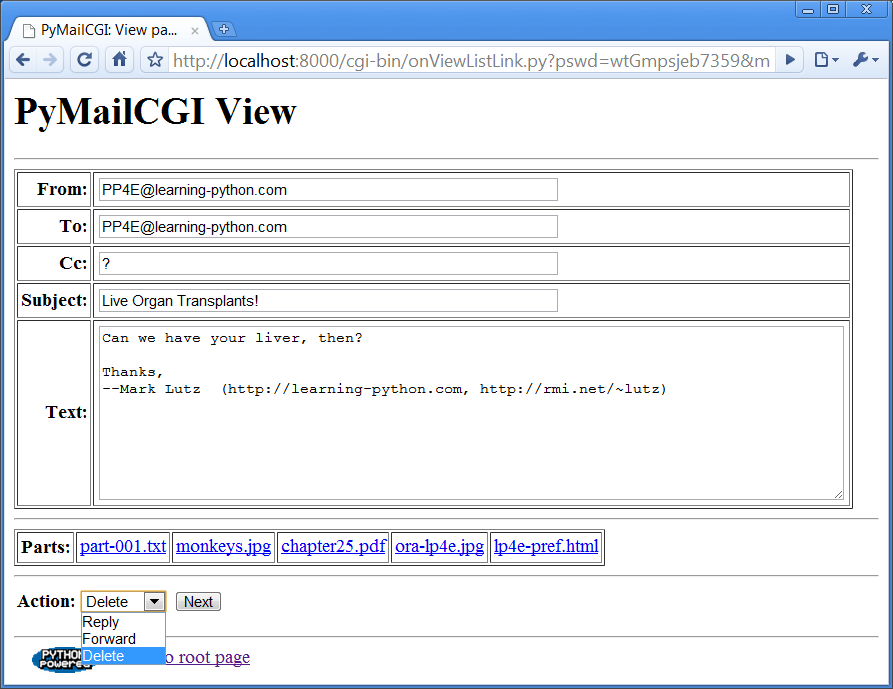
By the way, notice the varied type of attachment parts on the mail’s page in Figure 16-17. In version 3.0 we can send only text attachments due to the Python 3.1 CGI uploads parsing regression described earlier, but we can still view arbitrary attachment types in fetched mails received from other senders. This includes images and PDFs. Such attachments open according to your browser’s conventions; Figure 16-18 shows how Chrome handles a click on the monkeys.jpg link at the bottom of the PyMailCGI page in Figure 16-17—it’s the same image we sent by FTP in Chapter 13 and via PyMailGUI in Chapter 14, but here it has been extracted by a PyMailCGI CGI script and is being returned by a locally running web server.

Back to our pending deletion. As mentioned, Delete is the only action that uses the POP account information (user, password, and site) that was passed in from hidden fields on the prior message view page. By contrast, the Reply and Forward actions format an edit page, which ultimately sends a message to the SMTP server; no POP information is needed or passed.
But at this point in the interaction, the POP password has racked up more than a few frequent flyer miles. In fact, it may have crossed phone lines, satellite links, and continents on its journey from machine to machine. Let’s trace through the voyage:
Input (client): The password starts life by being typed into the login page on the client (or being embedded in an explicit URL), unencrypted. If typed into the input form in a web browser, each character is displayed as a star (
*).Fetch index (client to CGI server to POP server): It is next passed from the client to the CGI script on the server, which sends it on to your POP server in order to load a mail index. The client sends only the password, unencrypted.
List page URLs (CGI server to client): To direct the next script’s behavior, the password is embedded in the mail selection list web page itself as hyperlink URL query parameters, encrypted (or otherwise obfuscated) and URL encoded.
Fetch message (client to CGI server to POP server): When an email is selected from the list, the password is sent to the next script named within the link’s URL; the CGI script decodes it and passes it on to the POP server to fetch the selected message.
View page fields (CGI server to client): To direct the next script’s behavior, the password is embedded in the view page itself as HTML hidden input fields, encrypted or obfuscated, and HTML escaped.
Delete message (client to CGI server to POP server): Finally, the password is again passed from client to CGI server, this time as hidden form field values; the CGI script decodes it and passes it to the POP server to delete.
Along the way, scripts have passed the password between pages
as both a URL query parameter and an HTML hidden input field; either
way, they have always passed its encrypted or obfuscated string and
have never passed an unencoded password and username together in any
transaction. Upon a Delete request, the password must be decoded
here using the secret module
before passing it to the POP server. If the script can access the
POP server again and delete the selected message, another
confirmation page appears, as shown in Figure 16-19 (there is currently no
verification for the delete, so be careful).

One subtlety for replies and forwards: the onViewPageAction mail action script builds
up a >-quoted representation
of the original message, with original “From:”, “To:”, and “Date:”
header lines prepended to the mail’s original text. Notice, though,
that the original message’s headers are fetched from the CGI form
input, not by reparsing the original mail (the mail is not readily
available at this point). In other words, the script gets mail
header values from the form input fields of the view page. Because
there is no “Date” field on the view page, the original message’s
date is also passed along to the action script as a hidden input
field to avoid reloading the message. Try tracing through the code
in this chapter’s listings ahead to see whether you can follow dates
from page to page.
Deletions and POP Message Numbers
Note that you probably should click the “Back to root page” link in Figure 16-19 after a successful deletion—don’t use your browser’s Back button to return to the message selection list at this point because the delete has changed the relative numbers of some messages in the list. The PyMailGUI client program worked around this problem by automatically updating its in-memory message cache and refreshing the index list on deletions, but PyMailCGI doesn’t currently have a way to mark older pages as obsolete.
If your browser reruns server-side scripts as you press your Back button, you’ll regenerate and hence refresh the list anyhow. If your browser displays cached pages as you go back, though, you might see the deleted message still present in the list. Worse, clicking on a view link in an old selection list page may not bring up the message you think it should, if it appears in the list after a message that was deleted.
This is a property of POP email in general, which we have discussed before in this book: incoming mail simply adds to the mail list with higher message numbers, but deletions remove mail from arbitrary locations in the list and hence change message numbers for all mail following the ones deleted.
Inbox synchronization error potential
As we saw in Chapter 14, even the PyMailGUI client has the potential to get some message numbers wrong if mail is deleted by another program while the GUI is open—in a second PyMailGUI instance, for example, or in a simultaneously running PyMailCGI server session. This can also occur if the email server automatically deletes a message after the mail list has been loaded—for instance, moving it from inbox to undeliverable on errors.
This is why PyMailGUI went out of its way to detect server
inbox synchronization errors on loads and deletes, using mailtools package utilities. Its
deletions, for instance, match saved email headers with those for
the corresponding message number in the server’s inbox, to ensure
accuracy. A similar test is performed on loads. On mismatches, the
mail index is automatically reloaded and updated. Unfortunately,
without additional state information, PyMailCGI cannot detect such
errors: it has no email list to compare against when messages are
viewed or deleted, only the message number in a link or hidden
form field.
In the worst case, PyMailCGI cannot guarantee that deletes
remove the intended mail—it’s unlikely but not
impossible that a mail earlier in the list may have been deleted
between the time message numbers were fetched and a mail is
deleted at the server. Without extra state information on the
server, PyMailCGI cannot use the safe deletion or synchronization
error checks in the mailtools
modules to check whether subject message numbers are still
valid.
To guarantee safe deletes, PyMailCGI would require state retention, which maps message numbers passed in pages to saved mail headers fetched when the numbers were last determined, or a broader policy, which sidesteps the issue completely. The next three sections outline suggested improvements and potential exercises.
Alternative: Passing header text in hidden input fields (PyMailCGI_2.1)
Perhaps the simplest way to guarantee accurate deletions is to embed the displayed message’s full header text in the message view page itself, as hidden form fields, using the following scheme:
onViewListLink.pyEmbed the header text in hidden form fields, escaped per HTML conventions with
cgi.escape(with itsquoteargument set toTrueto translate any nested quotes in the header text).onViewPageAction.pyRetrieve the embedded header text from the form’s input fields, and pass it along to the safe deletion call in
mailtoolsfor header matching.
This would be a small code change, but it might require an extra headers fetch in the first of these scripts (it currently loads the full mail text), and it would require building a phony list to represent all mails’ headers (we would have headers for and delete only one mail here). Alternatively, the header text could be extracted from the fetched full mail text, by splitting on the blank line that separates headers and message body text.
Moreover, this would increase the size of the data transmitted both from client and server—mail header text is commonly greater than 1 KB in size, and it may be larger. This is a small amount of extra data in modern terms, but it’s possible that this may run up against size limitations in some client or server systems.
And really, this scheme is incomplete. It addresses only deletion accuracy and does nothing about other synchronization errors in general. For example, the system still may fetch and display the wrong message from a message list page, after deletions of mails earlier in the inbox performed elsewhere. In fact, this technique guarantees only that the message displayed in a view window will be the one deleted for that view window’s delete action. It does not ensure that the mail displayed or deleted in the view window corresponds to the selection made by the user in the mail index list.
More specifically, because this scheme embeds headers in the HTML of view windows, its header matching on deletion is useful only if messages earlier in the inbox are deleted elsewhere after a mail has already been opened for viewing. If the inbox is changed elsewhere before a mail is opened in a view window, the wrong mail may be fetched from the index page. In that event, this scheme avoids deleting a mail other than the one displayed in a view window, but it assumes the user will catch the mistake and avoid deleting if the wrong mail is loaded from the index page. Though such cases are rare, this behavior is less than user friendly.
Even though it is incomplete, this change does at least avoid deleting the wrong email if the server’s inbox changes while a message is being viewed—the mail displayed will be the only one deleted. A working but tentative implementation of this scheme is implemented in the following directory of the book’s examples distribution:
PP4EInternetWebdevPyMailCGI_2.1
When developed, it worked under the Firefox web browser and it requires just more than 10 lines of code changes among three source files, listed here (search for “#EXPERIMENTAL” to find the changes made in the source files yourself):
# onViewListLink.py . . . hdrstext = fulltext.split(' ')[0] # use blank line commonhtml.viewpage( # encodes passwd msgnum, message, content, form, hdrstext, parts) # commonhtml.py . . . def viewpage(msgnum, headers, text, form, hdrstext, parts=[]): . . . # delete needs hdrs text for inbox sync tests: can be multi-K large hdrstext = cgi.escape(hdrstext, quote=True) # escape '"' too print('<input type=hidden name=Hdrstext value="%s">' % hdrstext) # onViewPageAction.py . . . fetcher = mailtools.SilentMailFetcher(site, user, pswd) #fetcher.deleteMessages([msgnum]) hdrstext = getfield(form, 'Hdrstext') + ' ' hdrstext = hdrstext.replace(' ', ' ') # get from top dummyhdrslist = [None] * msgnum # only one msg hdr dummyhdrslist[msgnum-1] = hdrstext # in hidden field fetcher.deleteMessagesSafely([msgnum], dummyhdrslist) # exc on sync err commonhtml.confirmationpage('Delete')
To run this version locally, run the webserver script from Example 15-1 (in Chapter 15) with the dev subdirectory name, and a unique port
number if you want to run both the original and the experimental
versions. For instance:
C:...PP4EInternetWeb>webserver.py devPyMailCGI_2.1 9000command linehttp://localhost:9000/pymailcgi.htmlweb browser URL
Although this version works on browsers tested, it is considered tentative (and was not used for this chapter, and not updated for Python 3.X in this edition) because it is an incomplete solution. In those rare cases where the server’s inbox changes in ways that invalidate message numbers after server fetches, this version avoids inaccurate deletions, but index lists may still become out of sync. Messages fetches may still be inaccurate, and addressing this likely entails more sophisticated state retention options.
Note that in most cases, the message-id header would be sufficient
for matching against mails to be deleted in the inbox, and it
might be all that is required to pass from page to page. However,
because this field is optional and can be forged to have any
value, this might not always be a reliable way to identify matched
messages; full header matching is necessary to be robust. See the
discussion of mailtools in
Chapter 13 for more details.
Alternative: Server-side files for headers
The main limitation of the prior section’s technique is that it addressed only deletions of already fetched emails. To catch other kinds of inbox synchronization errors, we would have to also record headers fetched when the index list page was constructed.
Since the index list page uses URL query parameters to record state, adding large header texts as an additional parameter on the URLs is not likely a viable option. In principle, the header text of all mails in the list could be embedded in the index page as a single hidden field, but this might add prohibitive size and transmission overheads.
As a perhaps more complete approach, each time the mail
index list page is generated in onViewPswdSubmit.py, fetched headers of
all messages could be saved in a flat file on the server, with a
generated unique name (possibly from time, process ID, and
username). That file’s name could be passed along with message
numbers in pages as an extra hidden field or query
parameter.
On deletions, the header’s filename could be used by
onViewPageAction.py to load the
saved headers from the flat file, to be passed to the safe delete
call in mailtools. On fetches,
the header file could also be used for general synchronization
tests to avoid loading and displaying the wrong mail. Some sort of
aging scheme would be required to delete the header save files
eventually (the index page script might clean up old files), and
we might also have to consider multiuser issues.
This scheme essentially uses server-side files to emulate PyMailGUI’s in-process memory, though it is complicated by the fact that users may back up in their browser—deleting from view pages fetched with earlier list pages, attempting to refetch from an earlier list page and so on. In general, it may be necessary to analyze all possible forward and backward flows through pages (it is essentially a state machine). Header save files might also be used to detect synchronization errors on fetches and may be removed on deletions to effectively disable actions in prior page states, though header matching may suffice to ensure deletion accuracy.
Alternative: Delete on load
As a final alternative, mail clients could delete all email off the server as soon as it is downloaded, such that deletions wouldn’t impact POP identifiers (Microsoft Outlook may use this scheme by default, for instance). However, this requires additional mechanisms for storing deleted email persistently for later access, and it means you can view fetched mail only on the machine to which it was downloaded. Since both PyMailGUI and PyMailCGI are intended to be used on a variety of machines, mail is kept on the POP server by default.
Warning
Because of the current lack of inbox synchronization error checks in PyMailCGI, you should not delete mails with it in an important account, unless you employ one of the solution schemes described or you use other tools to save mails to be deleted before deletion. Adding state retention to ensure general inbox synchronization may make an interesting exercise, but would also add more code than we have space for here, especially if generalized for multiple simultaneous site users.
Utility Modules
This section presents the source code of the utility modules imported and used by the page scripts shown earlier. As installed, all of these modules live in the same directory as the CGI scripts, to make imports simple—they are found in the current working directory. There aren’t any new screenshots to see here because these are utilities, not CGI scripts. Moreover, these modules aren’t all that useful to study in isolation and are included here primarily to be referenced as you go through the CGI scripts’ code listed previously. See earlier in this chapter for additional details not repeated here.
External Components and Configuration
When running PyMailCGI out of its own directory in the book examples distribution tree, it relies on a number of external modules that are potentially located elsewhere. Because all of these are accessible from the PP4E package root, they can be imported with dotted-path names as usual, relative to the root. In case this setup ever changes, though, the module in Example 16-10 encapsulates the location of all external dependencies; if they ever move, this is the only file that must be changed.
""" isolate all imports of modules that live outside of the PyMailCgi directory, so that their location must only be changed here if moved; we reuse the mailconfig settings that were used for pymailgui2 in ch13; PP4E/'s container must be on sys.path to use the last import here; """ import sys #sys.path.insert(0, r'C:UsersmarkStuffBooks4EPP4EdevExamples') sys.path.insert(0, r'........') # relative to script dir import mailconfig # local version from PP4E.Internet.Email import mailtools # mailtools package
This module simply preimports all external names needed by
PyMailCGI into its own namespace. See Chapter 13 for more on the mailtools package modules’ source code
imported and reused here; as for PyMailGUI, much of the magic behind
PyMailCGI is actually implemented in mailtools.
This version of PyMailCGI has its own local copy of the
mailconfig module we coded in
Chapter 13 and expanded in Chapter 14, but it simply loads all
attributes from the version we wrote in Chapter 13 to avoid redundancy, and
customizes as desired; the local version is listed in Example 16-11.
""" user configuration settings for various email programs (PyMailCGI version); email scripts get their server names and other email config options from this module: change me to reflect your machine names, sig, and preferences; """ from PP4E.Internet.Email.mailconfig import * # reuse ch13 configs fetchlimit = 50 # 4E: maximum number headers/emails to fetch on loads (dflt=25)
POP Mail Interface
Our next utility module, the loadmail file
in Example 16-12, depends
on external files and encapsulates access to mail on the remote POP
server machine. It currently exports one function, loadmailhdrs, which returns a list of the
header text (only) of all mail in the specified POP account; callers
are unaware of whether this mail is fetched over the Net, lives in
memory, or is loaded from a persistent storage medium on the CGI
server machine. That is by design—because loadmail changes won’t impact its clients,
it is mostly a hook for future expansion.
"""
mail list loader; future--change me to save mail list between CGI script runs,
to avoid reloading all mail each time; this won't impact clients that use the
interfaces here if done well; for now, to keep this simple, reloads all mail
for each list page; 2.0+: we now only load message headers (via TOP), not full
msg, but still fetch all hdrs for each index list--in-memory caches don't work
in a stateless CGI script, and require a real (likely server-side) database;
"""
from commonhtml import runsilent # suppress prints (no verbose flag)
from externs import mailtools # shared with PyMailGUI
# load all mail from number 1 up
# this may trigger an exception
import sys
def progress(*args): # not used
sys.stderr.write(str(args) + '
')
def loadmailhdrs(mailserver, mailuser, mailpswd):
fetcher = mailtools.SilentMailFetcher(mailserver, mailuser, mailpswd)
hdrs, sizes, full = fetcher.downloadAllHeaders() # get list of hdr text
return hdrsThis module is not much to look at—just an interface and calls
to other modules. The mailtools.SilentMailFetcher class (reused
here from Chapter 13) uses the
Python poplib module to
fetch mail over sockets. The silent class prevents mailtools print call statements from going
to the HTML reply stream (although any exceptions are allowed to
propagate there normally).
In this version, loadmail
loads just the header text portions of all incoming email to
generate the selection list page. However, it still reloads headers
every time you refetch the selection list page. As mentioned
earlier, this scheme is better than the prior version, but it can
still be slow if you have lots of email sitting on your server.
Server-side database techniques, combined with a scheme for
invalidating message lists on deletions and new receipts, might
alleviate some of this bottleneck. Because the interface exported by
loadmail would likely not need to
change to introduce a caching mechanism, clients of this module
would likely still work unchanged.
POP Password Encryption
We discussed PyMailCGI’s security protocols in the abstract earlier in this chapter. Here, we look at their concrete implementation. PyMailCGI passes user and password state information from page to page using hidden form fields and URL query parameters embedded in HTML reply pages. We studied these techniques in the prior chapter. Such data is transmitted as simple text over network sockets—within the HTML reply stream from the server, and as parameters in the request from the client. As such, it is subject to security issues.
This isn’t a concern if you are running a local web server on your machine, as all our examples do. The data is being shipped back and forth between two programs running on your computer, and it is not accessible to the outside world. If you want to install PyMailCGI on a remote web server machine, though, this can be an issue. Because this data is sensitive, we’d ideally like some way to hide it in transit and prevent it from being viewed in server logs. The policies used to address this have varied across this book’s lifespan, as options have come and gone:
The second edition of this book developed a custom encryption module using the standard library’s
rotorencryption module. This module was used to encrypt data inserted into the server’s reply stream, and then to later decrypt it when it was returned as a parameter from the client. Unfortunately, in Python 2.4 and later, therotormodule is no longer available in the standard library; it was withdrawn due to security concerns. This seems a somewhat extreme measure (rotorwas adequate for simpler applications), butrotoris no longer a usable solution in recent releases.The third edition of this book extended the model of the second, by adding support for encrypting passwords with the third-party and open source PyCrypto system. Regrettably, this system is available for Python 2.X but still not for 3.X as I write these words for the fourth edition in mid-2010 (though some progress on a 3.X port has been made). Moreover, the Python web server classes used by the locally running server deployed for this book still does not support HTTPS in Python 3.1—the ultimate solution to web security, which I’ll say more about in a moment.
Because of all the foregoing, this fourth edition has legacy support for both
rotorand PyCrypto if they are installed, but falls back on a simplistic password obfuscator which may be different at each PyMailCGI installation. Since this release is something of a prototype in general, further refinement of this model, including support for HTTPS under more robust web servers, is left as exercise.
In general, there are a variety of approaches to encrypting information transferred back and forth between client and server. Unfortunately again, none is easily implemented for this chapter’s example, none is universally applicable, and most involve tools or techniques that are well beyond the scope and size constraints of this text. To sample some of the available options, though, the sections that follow contain a brief rundown of some of the common techniques in this domain.
Manual data encryption: rotor (defunct)
In principle, CGI scripts can manually encrypt any sensitive
data they insert into reply streams, as PyMailCGI did in this
book’s second edition. With the removal of the rotor module,
though, Python 2.4’s standard library has no encryption tools for
this task. Moreover, using the original rotor module’s code is not advisable
from a maintenance perspective and would not be straightforward,
since it was coded in the C language (it’s not a simple matter of
copying a .py file from a prior release).
Unless you are using an older version of Python, rotor is not a real option.
Mostly for historical interest and comparison today, this module was used as follows. It was based on an Enigma-style encryption scheme: we make a new rotor object with a key (and optionally, a rotor count) and call methods to encrypt and decrypt:
>>>import rotor>>>r = rotor.newrotor('pymailcgi')# (key, [,numrotors]) >>>r.encrypt('abc123')# may return nonprintable chars ' 323an�21224' >>>x = r.encrypt('spam123')# result is same len as input >>>x'* _344�11pY' >>>len(x)7 >>>r.decrypt(x)'spam123'
Notice that the same rotor object can encrypt multiple
strings, that the result may contain nonprintable characters
(printed as ascii escape codes
when displayed), and that the result is always the same length as
the original string. Most important, a string encrypted with
rotor can be decrypted in a
different process (e.g., in a later CGI script) if we re-create
the rotor object:
>>>import rotor>>>r = rotor.newrotor('pymailcgi')# can be decrypted in new process >>>r.decrypt('* _344�11pY')# use "ascii" escapes for two chars 'spam123'
Our secret module by
default simply used rotor to
encrypt and did no additional encoding of its own. It relies on
URL encoding when the password is embedded in a URL parameter and
on HTML escaping when the password is embedded in hidden form
fields. For URLs, the following sorts of calls occur:
>>>from secret import encode, decode>>>x = encode('abc$#<>&+')# CGI scripts do this >>>x' 323a�16317326�23�163' >>>import urllib.parse# urlencode does this >>>y = urllib.parse.quote_plus(x)>>>y'+%d3a%0e%cf%d6%13%0e3' >>>a = urllib.parse.unquote_plus(y)# cgi.FieldStorage does this >>>a' 323a�16317326�23�163' >>>decode(a)# CGI scripts do this 'abc$#<>&+'
Although rotor itself is
not a widely viable option today, these same techniques can be
used with other encryption schemes.
Manual data encryption: PyCrypto
A variety of encryption tools are available in the third-party public domain, including the popular Python Cryptography Toolkit, also known as PyCrypto. This package adds built-in modules for private and public key algorithms such as AES, DES, IDEA, and RSA encryption, provides a Python module for reading and decrypting PGP files, and much more. Here is an example of using AES encryption, run after installing PyCrypto on my machine with a Windows self-installer:
>>>from Crypto.Cipher import AES# AES.block_size is 16 >>>mykey = 'pymailcgi'.ljust(16, '-')# key must be 16, 24, or 32 bytes >>>mykey'pymailcgi-------' >>> >>>password = 'Already got one.'# length must be multiple of 16 >>>aesobj1 = AES.new(mykey, AES.MODE_ECB)>>>cyphertext = aesobj1.encrypt(password)>>>cyphertext'xfezx95xb7x07_"xd4xb6xe3rx07g~X]' >>> >>>aesobj2 = AES.new(mykey, AES.MODE_ECB)>>>aesobj2.decrypt(cyphertext)'Already got one.'
This interface is similar to that of the original rotor module, but it uses better
encryption algorithms. AES is a popular private key encryption
algorithm. It requires a fixed length key and a data string to
have a length that is a multiple of 16 bytes.
Unfortunately, this is not part of standard Python, may be subject to U.S. (and other countries’) export controls in binary form at this writing, and is too large and complex a topic for us to address in this text. This makes it less than universally applicable; at the least, shipping its binary installer with this book’s examples package may require legal expertise. And since data encryption is a core requirement of PyMailCGI, this seems too strong an external dependency.
The real showstopper for this book’s fourth edition, though, is that PyCrypto is a 2.X-only system not yet available for Python 3.X today; this makes it unusable with the examples in this book. Still, if you are able to install and learn PyCrypto, this can be a powerful solution. For more details, search for PyCrypto on the Web.
HTTPS: Secure HTTP transmissions
Provided you are using a server that supports secure HTTP, you can simply write HTML and delegate the encryption to the web server and browser. As long as both ends of the transmission support this protocol, it is probably the ultimate encrypting solution for web security. In fact, it is used by most e-commerce sites on the Web today.
Secure HTTP (HTTPS) is designated in URLs by using the protocol name
https:// rather than http://. Under HTTPS, data is still sent
with the usual HTTP protocol, but it is encrypted with the SSL
secure sockets layer. HTTPS is supported by most web browsers and
can be configured in most web servers, including Apache and the
webserver.py script that
we are running locally in this chapter. If SSL support is compiled
into your Python, Python sockets support it with ssl module socket wrappers, and the
client-side module urllib.request we met in Chapter 13 supports HTTPS.
Unfortunately, enabling secure HTTP in a web server requires more configuration and background knowledge than we can cover here, and it may require installing tools outside the standard Python release. If you want to explore this issue further, search the Web for resources on setting up a Python-coded HTTPS server that supports SSL secure communications. As one possible lead, see the third-party M2Crypto package’s OpenSSL wrapper support for password encryption, HTTPS in urllib, and more; this could be a viable alternative to manual encryption, but it is not yet available for Python 3.X at this writing.
Also see the Web for more details on HTTPS in general. It is not impossible that some of the HTTPS extensions for Python’s standard web server classes may make their way into the Python standard library in the future, but they have not in recent years, perhaps reflecting the classes’ intended roles—they provide limited functionality for use in locally running servers oriented toward testing, not deployment.
Secure cookies
It’s possible to replace the form fields and query parameter PyMailCGI currently generates with client-side cookies marked as secure. Such cookies are automatically encrypted when sent. Unfortunately again, marking a cookie as secure simply means that it can be transmitted only if the communications channel with the host is secure. It does not provide any additional encryption. Because of this, this option really just begs the question; it still requires an HTTPS server.
The secret.py module
As you can probably tell, web security is a larger topic
than we have time to address here. Because of that, the secret.py module in Example 16-13 finesses the
issue, by trying a variety of approaches in turn:
If you are able to fetch and install the third-party PyCrypto system described earlier, the module will use that package’s AES tools to manually encrypt password data when transmitted together with a username.
If not, it will try
rotornext, if you’re able to find and install the original rotor module in the version of Python that you’re using.And finally, it falls back on a very simplistic default character code shuffling obfuscation scheme, which you can replace with one of your own if you install this program on the Internet at large.
See Example 16-13
for more details; it uses function definitions nested in if statements to generate the selected
encryption scheme’s functions at run time.
"""
###############################################################################
PyMailCGI encodes the POP password whenever it is sent to/from client over
the Net with a username, as hidden text fields or explicit URL params; uses
encode/decode functions in this module to encrypt the pswd--upload your own
version of this module to use a different encryption mechanism or key; pymail
doesn't save the password on the server, and doesn't echo pswd as typed,
but this isn't 100% safe--this module file itself might be vulnerable;
HTTPS may be better and simpler but Python web server classes don't support;
###############################################################################
"""
import sys, time
dayofweek = time.localtime(time.time())[6] # for custom schemes
forceReadablePassword = False
###############################################################################
# string encoding schemes
###############################################################################
if not forceReadablePassword:
###########################################################
# don't do anything by default: the urllib.parse.quote
# or cgi.escape calls in commonhtml.py will escape the
# password as needed to embed in URL or HTML; the
# cgi module undoes escapes automatically for us;
###########################################################
def stringify(old): return old
def unstringify(old): return old
else:
###########################################################
# convert encoded string to/from a string of digit chars,
# to avoid problems with some special/nonprintable chars,
# but still leave the result semi-readable (but encrypted);
# some browsers had problems with escaped ampersands, etc.;
###########################################################
separator = '-'
def stringify(old):
new = ''
for char in old:
ascii = str(ord(char))
new = new + separator + ascii # '-ascii-ascii-ascii'
return new
def unstringify(old):
new = ''
for ascii in old.split(separator)[1:]:
new = new + chr(int(ascii))
return new
###############################################################################
# encryption schemes: try PyCrypto, then rotor, then simple/custom scheme
###############################################################################
useCrypto = useRotor = True
try:
import Crypto
except:
useCrypto = False
try:
import rotor
except:
useRotor = False
if useCrypto:
#######################################################
# use third-party pycrypto package's AES algorithm
# assumes pswd has no '�' on the right: used to pad
# change the private key here if you install this
#######################################################
sys.stderr.write('using PyCrypto
')
from Crypto.Cipher import AES
mykey = 'pymailcgi3'.ljust(16, '-') # key must be 16, 24, or 32 bytes
def do_encode(pswd):
over = len(pswd) % 16
if over: pswd += '�' * (16-over) # pad: len must be multiple of 16
aesobj = AES.new(mykey, AES.MODE_ECB)
return aesobj.encrypt(pswd)
def do_decode(pswd):
aesobj = AES.new(mykey, AES.MODE_ECB)
pswd = aesobj.decrypt(pswd)
return pswd.rstrip('�')
elif useRotor:
#######################################################
# use the standard lib's rotor module to encode pswd
# this does a better job of encryption than code above
# unfortunately, it is no longer available in Py 2.4+
#######################################################
sys.stderr.write('using rotor
')
import rotor
mykey = 'pymailcgi3'
def do_encode(pswd):
robj = rotor.newrotor(mykey) # use enigma encryption
return robj.encrypt(pswd)
def do_decode(pswd):
robj = rotor.newrotor(mykey)
return robj.decrypt(pswd)
else:
#######################################################
# use our own custom scheme as a last resort
# shuffle characters in some reversible fashion
# caveat: very simple -- replace with one of your own
#######################################################
sys.stderr.write('using simple
')
adder = 1
def do_encode(pswd):
pswd = 'vs' + pswd + '48'
res = ''
for char in pswd:
res += chr(ord(char) + adder) # inc each ASCII code
return str(res)
def do_decode(pswd):
pswd = pswd[2:-2]
res = ''
for char in pswd:
res += chr(ord(char) - adder)
return res
###############################################################################
# top-level entry points
###############################################################################
def encode(pswd):
return stringify(do_encode(pswd)) # encrypt plus string encode
def decode(pswd):
return do_decode(unstringify(pswd))In addition to encryption, this module also implements an encoding method for already encrypted strings, which transforms them to and from printable characters. By default, the encoding functions do nothing, and the system relies on straight URL or HTML encoding of the encrypted string. An optional encoding scheme translates the encrypted string to a string of ASCII code digits separated by dashes. Either encoding method makes nonprintable characters in the encrypted string printable.
To illustrate, let’s test this module’s tools interactively.
For this test, we set forceReadablePassword to True. The top-level entry points encode
and decode into printable characters (for illustration purposes,
this test reflects a Python 2.X installation where PyCrypto is
installed):
>>>from secret import *using PyCrypto >>>data = encode('spam@123+')>>>data'-47-248-2-170-107-242-175-18-227-249-53-130-14-140-163-107' >>>decode(data)'spam@123+'
But there are actually two steps to this—encryption and printable encoding:
>>>raw = do_encode('spam@123+')>>>raw'/xf8x02xaakxf2xafx12xe3xf95x82x0ex8cxa3k' >>>text = stringify(raw)>>>text'-47-248-2-170-107-242-175-18-227-249-53-130-14-140-163-107' >>>len(raw), len(text)(16, 58)
Here’s what the encoding looks like without the extra printable encoding:
>>>raw = do_encode('spam@123+')>>>raw'/xf8x02xaakxf2xafx12xe3xf95x82x0ex8cxa3k' >>>do_decode(raw)'spam@123+'
Rolling your own encryptor
As is, PyMailCGI avoids ever passing the POP account
username and password across the Net together in a single
transaction, unless the password is encrypted or obfuscated
according to the module secret.py on the server. This module can
be different everywhere PyMailCGI is installed, and it can be
uploaded anew in the future—encrypted passwords aren’t persistent
and live only for the duration of one mail-processing interaction
session. Provided you don’t publish your encryption code or its
private keys, your data will be as secure as the custom encryption
module you provide on your own server.
If you wish to use this system on the general Internet, you’ll want to tailor this code. Ideally, you’ll install PyCrypto and change the private key string. Barring that, replace Example 16-13 with a custom encryption coding scheme of your own or deploy one of the general techniques mentioned earlier, such as an HTTPS-capable web server. In any event, this software makes no guarantees; the security of your password is ultimately up to you to ensure.
For additional information on security tools and techniques, search the Web and consult books geared exclusively toward web programming techniques. As this system is a prototype at large, security is just one of a handful of limitations which would have to be more fully addressed in a robust production-grade version.
Note
Because the encryption schemes used by PyMailCGI are
reversible, it is possible to reconstruct my email account’s
password if you happen to see its encrypted form in a
screenshot, unless the private key listed in secret.py was different when the tests
shown were run. To sidestep this issue, the email account used
in all of this book’s examples is temporary and will be deleted
by the time you read these words. Please use an email account of
your own to test-drive the system.
Common Utilities Module
Finally, the file commonhtml.py in Example 16-14 is the Grand Central Station of this application—its code is used and reused by just about every other file in the system. Most of it is self-explanatory, and we’ve already met most of its core idea earlier, in conjunction with the CGI scripts that use it.
I haven’t talked about its debugging
support, though. Notice that this module assigns sys.stderr to sys.stdout, in an attempt to force the
text of Python error messages to show up in the client’s browser
(remember, uncaught exceptions print details to sys.stderr). That works sometimes in PyMailCGI, but not always—the
error text shows up in a web page only if a page_header call has already printed a
response preamble. If you want to see all error messages, make sure
you call page_header (or print
Content-type: lines manually)
before any other processing.
This module also defines functions that dump raw CGI
environment information to the browser (dumpstatepage), and that wrap calls to
functions that print status messages so that their output isn’t
added to the HTML stream (runsilent). A version 3.0 addition also
attempts to work around the fact that built-in print calls can fail
in Python 3.1 for some types of Unicode text (e.g., non-ASCII
character sets in Internationalized headers), by forcing binary mode
and bytes for the output stream (print).
I’ll leave the discovery of any remaining magic in the code in Example 16-14 up to you, the reader. You are hereby admonished to go forth and read, refer, and reuse.
#!/usr/bin/python
"""
##################################################################################
generate standard page header, list, and footer HTML; isolates HTML generation
related details in this file; text printed here goes over a socket to the client,
to create parts of a new web page in the web browser; uses one print per line,
instead of string blocks; uses urllib to escape params in URL links auto from a
dict, but cgi.escape to put them in HTML hidden fields; some tools here may be
useful outside pymailcgi; could also return the HTML generated here instead of
printing it, so it could be included in other pages; could also structure as a
single CGI script that gets and tests a next action name as a hidden form field;
caveat: this system works, but was largely written during a two-hour layover at
the Chicago O'Hare airport: there is much room for improvement and optimization;
##################################################################################
"""
import cgi, urllib.parse, sys, os
# 3.0: Python 3.1 has issues printing some decoded str as text to stdout
import builtins
bstdout = open(sys.stdout.fileno(), 'wb')
def print(*args, end='
'):
try:
builtins.print(*args, end=end)
sys.stdout.flush()
except:
for arg in args:
bstdout.write(str(arg).encode('utf-8'))
if end: bstdout.write(end.encode('utf-8'))
bstdout.flush()
sys.stderr = sys.stdout # show error messages in browser
from externs import mailconfig # from a package somewhere on server
from externs import mailtools # need parser for header decoding
parser = mailtools.MailParser() # one per process in this module
# my cgi address root
#urlroot = 'http://starship.python.net/~lutz/PyMailCgi/'
#urlroot = 'http://localhost:8000/cgi-bin/'
urlroot = '' # use minimal, relative paths
def pageheader(app='PyMailCGI', color='#FFFFFF', kind='main', info=''):
print('Content-type: text/html
')
print('<html><head><title>%s: %s page (PP4E)</title></head>' % (app, kind))
print('<body bgcolor="%s"><h1>%s %s</h1><hr>' % (color, app, (info or kind)))
def pagefooter(root='pymailcgi.html'):
print('</p><hr><a href="http://www.python.org">')
print('<img src="../PythonPoweredSmall.gif" ')
print('align=left alt="[Python Logo]" border=0 hspace=15></a>')
print('<a href="../%s">Back to root page</a>' % root)
print('</body></html>')
def formatlink(cgiurl, parmdict):
"""
make "%url?key=val&key=val" query link from a dictionary;
escapes str() of all key and val with %xx, changes ' ' to +
note that URL escapes are different from HTML (cgi.escape)
"""
parmtext = urllib.parse.urlencode(parmdict) # calls parse.quote_plus
return '%s?%s' % (cgiurl, parmtext) # urllib does all the work
def pagelistsimple(linklist): # show simple ordered list
print('<ol>')
for (text, cgiurl, parmdict) in linklist:
link = formatlink(cgiurl, parmdict)
text = cgi.escape(text)
print('<li><a href="%s">
%s</a>' % (link, text))
print('</ol>')
def pagelisttable(linklist): # show list in a table
print('<p><table border>') # escape text to be safe
for (text, cgiurl, parmdict) in linklist:
link = formatlink(cgiurl, parmdict)
text = cgi.escape(text)
print('<tr><th><a href="%s">View</a><td>
%s' % (link, text))
print('</table>')
def listpage(linkslist, kind='selection list'):
pageheader(kind=kind)
pagelisttable(linkslist) # [('text', 'cgiurl', {'parm':'value'})]
pagefooter()
def messagearea(headers, text, extra=''): # extra for readonly
addrhdrs = ('From', 'To', 'Cc', 'Bcc') # decode names only
print('<table border cellpadding=3>')
for hdr in ('From', 'To', 'Cc', 'Subject'):
rawhdr = headers.get(hdr, '?')
if hdr not in addrhdrs:
dechdr = parser.decodeHeader(rawhdr) # 3.0: decode for display
else: # encoded on sends
dechdr = parser.decodeAddrHeader(rawhdr) # email names only
val = cgi.escape(dechdr, quote=1)
print('<tr><th align=right>%s:' % hdr)
print(' <td><input type=text ')
print(' name=%s value="%s" %s size=60>' % (hdr, val, extra))
print('<tr><th align=right>Text:')
print('<td><textarea name=text cols=80 rows=10 %s>' % extra)
print('%s
</textarea></table>' % (cgi.escape(text) or '?')) # if has </>s
def viewattachmentlinks(partnames):
"""
create hyperlinks to locally saved part/attachment files
when clicked, user's web browser will handle opening
assumes just one user, only valid while viewing 1 msg
"""
print('<hr><table border cellpadding=3><tr><th>Parts:')
for filename in partnames:
basename = os.path.basename(filename)
filename = filename.replace('', '/') # Windows hack
print('<td><a href=../%s>%s</a>' % (filename, basename))
print('</table><hr>')
def viewpage(msgnum, headers, text, form, parts=[]):
"""
on View + select (generated link click)
very subtle thing: at this point, pswd was URL encoded in the
link, and then unencoded by CGI input parser; it's being embedded
in HTML here, so we use cgi.escape; this usually sends nonprintable
chars in the hidden field's HTML, but works on ie and ns anyhow:
in url: ?user=lutz&mnum=3&pswd=%8cg%c2P%1e%f0%5b%c5J%1c%f3&...
in html: <input type=hidden name=pswd value="...nonprintables..">
could urllib.parse.quote html field here too, but must urllib.parse.unquote
in next script (which precludes passing the inputs in a URL instead
of the form); can also fall back on numeric string fmt in secret.py
"""
pageheader(kind='View')
user, pswd, site = list(map(cgi.escape, getstandardpopfields(form)))
print('<form method=post action="%sonViewPageAction.py">' % urlroot)
print('<input type=hidden name=mnum value="%s">' % msgnum)
print('<input type=hidden name=user value="%s">' % user) # from page|url
print('<input type=hidden name=site value="%s">' % site) # for deletes
print('<input type=hidden name=pswd value="%s">' % pswd) # pswd encoded
messagearea(headers, text, 'readonly')
if parts: viewattachmentlinks(parts)
# onViewPageAction.quotetext needs date passed in page
print('<input type=hidden name=Date value="%s">' % headers.get('Date','?'))
print('<table><tr><th align=right>Action:')
print('<td><select name=action>')
print(' <option>Reply<option>Forward<option>Delete</select>')
print('<input type=submit value="Next">')
print('</table></form>') # no 'reset' needed here
pagefooter()
def sendattachmentwidgets(maxattach=3):
print('<p><b>Attach:</b><br>')
for i in range(1, maxattach+1):
print('<input size=80 type=file name=attach%d><br>' % i)
print('</p>')
def editpage(kind, headers={}, text=''):
# on Send, View+select+Reply, View+select+Fwd
pageheader(kind=kind)
print('<p><form enctype="multipart/form-data" method=post', end=' ')
print('action="%sonEditPageSend.py">' % urlroot)
if mailconfig.mysignature:
text = '
%s
%s' % (mailconfig.mysignature, text)
messagearea(headers, text)
sendattachmentwidgets()
print('<input type=submit value="Send">')
print('<input type=reset value="Reset">')
print('</form>')
pagefooter()
def errorpage(message, stacktrace=True):
pageheader(kind='Error') # was sys.exc_type/exc_value
exc_type, exc_value, exc_tb = sys.exc_info()
print('<h2>Error Description</h2><p>', message)
print('<h2>Python Exception</h2><p>', cgi.escape(str(exc_type)))
print('<h2>Exception details</h2><p>', cgi.escape(str(exc_value)))
if stacktrace:
print('<h2>Exception traceback</h2><p><pre>')
import traceback
traceback.print_tb(exc_tb, None, sys.stdout)
print('</pre>')
pagefooter()
def confirmationpage(kind):
pageheader(kind='Confirmation')
print('<h2>%s operation was successful</h2>' % kind)
print('<p>Press the link below to return to the main page.</p>')
pagefooter()
def getfield(form, field, default=''):
# emulate dictionary get method
return (field in form and form[field].value) or default
def getstandardpopfields(form):
"""
fields can arrive missing or '' or with a real value
hardcoded in a URL; default to mailconfig settings
"""
return (getfield(form, 'user', mailconfig.popusername),
getfield(form, 'pswd', '?'),
getfield(form, 'site', mailconfig.popservername))
def getstandardsmtpfields(form):
return getfield(form, 'site', mailconfig.smtpservername)
def runsilent(func, args):
"""
run a function without writing stdout
ex: suppress print's in imported tools
else they go to the client/browser
"""
class Silent:
def write(self, line): pass
save_stdout = sys.stdout
sys.stdout = Silent() # send print to dummy object
try: # which has a write method
result = func(*args) # try to return func result
finally: # but always restore stdout
sys.stdout = save_stdout
return result
def dumpstatepage(exhaustive=0):
"""
for debugging: call me at top of a CGI to
generate a new page with CGI state details
"""
if exhaustive:
cgi.test() # show page with form, environ, etc.
else:
pageheader(kind='state dump')
form = cgi.FieldStorage() # show just form fields names/values
cgi.print_form(form)
pagefooter()
sys.exit()
def selftest(showastable=False): # make phony web page
links = [ # [(text, url, {parms})]
('text1', urlroot + 'page1.cgi', {'a':1}),
('text2', urlroot + 'page1.cgi', {'a':2, 'b':'3'}),
('text3', urlroot + 'page2.cgi', {'x':'a b', 'y':'a<b&c', 'z':'?'}),
('te<>4', urlroot + 'page2.cgi', {'<x>':'', 'y':'<a>', 'z':None})]
pageheader(kind='View')
if showastable:
pagelisttable(links)
else:
pagelistsimple(links)
pagefooter()
if __name__ == '__main__': # when run, not imported
selftest(len(sys.argv) > 1) # HTML goes to stdoutWeb Scripting Trade-Offs
As shown in this chapter, PyMailCGI is still something of a system in the making, but it does work as advertised: when it is installed on a remote server machine, by pointing a browser at the main page’s URL, I can check and send email from anywhere I happen to be, as long as I can find a machine with a web browser (and can live with the limitations of a prototype). In fact, any machine and browser will do: Python doesn’t have to be installed anew, and I don’t need POP or SMTP access on the client machine itself. That’s not the case with the PyMailGUI client-side program we wrote in Chapter 14. This property is especially useful at sites that allow web access but restrict more direct protocols such as POP email.
But before we all jump on the collective Internet bandwagon and utterly abandon traditional desktop APIs such as tkinter, a few words of larger context may be in order in conclusion.
PyMailCGI Versus PyMailGUI
Besides illustrating larger CGI applications in general, the PyMailGUI and PyMailCGI examples were chosen for this book on purpose to underscore some of the trade-offs you run into when building applications to run on the Web. PyMailGUI and PyMailCGI do roughly the same things but are radically different in implementation:
- PyMailGUI
This is a traditional “desktop” user-interface program: it runs entirely on the local machine, calls out to an in-process GUI API library to implement interfaces, and talks to the Internet through sockets only when it has to (e.g., to load or send email on demand). User requests are routed immediately to callback handler method functions running locally and in-process, with shared variables and memory that automatically retain state between requests. As mentioned, because its memory is retained between events, PyMailGUI can cache messages in memory—it loads email headers and selected mails only once, fetches only newly arrived message headers on future loads, and has enough information to perform general inbox synchronization checks. On deletions, PyMailGUI can simply refresh its memory cache of loaded headers without having to reload from the server. Moreover, because PyMailGUI runs as a single process on the local machine, it can leverage tools such as multithreading to allow mail transfers to overlap in time (you can send while a load is in progress), and it can more easily support extra functionality such as local mail file saves and opens.
- PyMailCGI
Like all CGI systems, PyMailCGI consists of scripts that reside and run on a server machine and generate HTML to interact with a user’s web browser on the client machine. It runs only in the context of a web browser or other HTML-aware client, and it handles user requests by running CGI scripts on the web server. Without manually managed state retention techniques such as a server-side database system, there is no equivalent to the persistent memory of PyMailGUI—each request handler runs autonomously, with no memory except that which is explicitly passed along by prior states as hidden form fields, URL query parameters, and so on. Because of that, PyMailCGI currently must reload all email headers whenever it needs to display the selection list, naively reloads messages already fetched earlier in the session, and cannot perform general inbox synchronization tests. This can be improved by more advanced state-retention schemes such as cookies and server-side databases, but none is as straightforward as the persistent in-process memory of PyMailGUI.
The Web Versus the Desktop
Of course, these systems’ specific functionality isn’t exactly the same—PyMailCGI is roughly a functional subset of PyMailGUI—but they are close enough to capture common trade-offs. On a basic level, both of these systems use the Python POP and SMTP modules to fetch and send email through sockets. The implementation alternatives they represent, though, have some critical ramifications that you should consider when evaluating the prospect of delivering systems on the Web:
- Performance costs
Networks are slower than CPUs. As implemented, PyMailCGI isn’t nearly as fast or as complete as PyMailGUI. In PyMailCGI, every time the user clicks a Submit button, the request goes across the network (it’s routed to another program on the same machine for “localhost,” but this setup is for testing, not deployment). More specifically, every user request incurs a network transfer overhead, every callback handler may take the form of a newly spawned process or thread on most servers, parameters come in as text strings that must be parsed out, and the lack of state information on the server between pages means that either mail needs to be reloaded often or state retention options must be employed which are slower and more complex than shared process memory.
In contrast, user clicks in PyMailGUI trigger in-process function calls rather than network traffic and program executions, and state is easily saved as Python in-process variables. Even with an ultra-fast Internet connection, a server-side CGI system is slower than a client-side program. To be fair, some tkinter operations are sent to the underlying Tcl library as strings, too, which must be parsed. This may change in time, but the contrast here is with CGI scripts versus GUI libraries in general. Function calls will probably always beat network transfers.
Some of these bottlenecks may be designed away at the cost of extra program complexity. For instance, some web servers use threads and process pools to minimize process creation for CGI scripts. Moreover, as we’ve seen, some state information can be manually passed along from page to page in hidden form fields, generated URL parameters, and client-side cookies, and state can be saved between pages in a concurrently accessible database to minimize mail reloads. But there’s no getting past the fact that routing events and data over a network to scripts is slower than calling a Python function directly. Not every application must care, but some do.
- Complexity costs
HTML isn’t pretty. Because PyMailCGI must generate HTML to interact with the user in a web browser, it is also more complex (or at least, less readable) than PyMailGUI. In some sense, CGI scripts embed HTML code in Python; templating systems such as PSP often take the opposite approach. Either way, because the end result of this is a mixture of two very different languages, creating an interface with HTML in a CGI script can be much less straightforward than making calls to a GUI API such as tkinter.
Witness, for example, all the care we’ve taken to escape HTML and URLs in this chapter’s examples; such constraints are grounded in the nature of HTML. Furthermore, changing the system to retain loaded-mail list state in a database between pages would introduce further complexities to the CGI-based solution (and, most likely, yet another language such as SQL, even if it only appears near the bottom of the software stack). And secure HTTP would eliminate the manual encryption complexity but would introduce new server configuration complexity.
- Functionality limitations
HTML can say only so much. HTML is a portable way to specify simple pages and forms, but it is poor to useless when it comes to describing more complex user interfaces. Because CGI scripts create user interfaces by writing HTML back to a browser, they are highly limited in terms of user-interface constructs. For example, consider implementing an image-processing and animation program as CGI scripts: HTML doesn’t easily apply once we leave the domain of fill-out forms and simple interactions.
It is possible to generate graphics in CGI scripts. They may be created and stored in temporary files on the server, with per-session filenames referenced in image tags in the generated HTML reply. For browsers that support the notion, graphic images may also be in-lined in HTML image tags, encoded in Base64 format or similar. Either technique is substantially more complex than using an image in the tkinter GUI library, though. Moreover, responsive animation and drawing applications are beyond the scope of a protocol such as CGI, which requires a network transaction per interaction. The interactive drawing and animation scripts we wrote at the end of Chapter 9, for example, could not be implemented as normal server-side scripts.
This is precisely the limitation that Java applets were designed to address—programs that are stored on a server but are pulled down to run on a client on demand and are given access to a full-featured GUI API for creating richer user interfaces. Nevertheless, strictly server-side programs are inherently limited by the constraints of HTML.
Beyond HTML’s limitations, client-side programs such as PyMailGUI also have access to tools such as multithreading which are difficult to emulate in a CGI-based application (threads spawned by a CGI script cannot outlive the CGI script itself, or augment its reply once sent). Persistent process models for web applications such as FastCGI may provide options here, but the picture is not as clear-cut as on the client.
Although web developers make noble efforts at emulating client-side capabilities—see the discussion of RIAs and HTML 5 ahead—such efforts add additional complexity, can stretch the server-side programming model nearly to its breaking point, and account for much of the plethora of divergent web techniques.
- Portability benefits
All you need is a browser on clients. On the upside, because PyMailCGI runs over the Web, it can be run on any machine with a web browser, whether that machine has Python and tkinter installed or not. That is, Python needs to be installed on only one computer—the web server machine where the scripts actually live and run. In fact, this is probably the most compelling benefit to the web application model. As long as you know that the users of your system have an Internet browser, installation is simple. You still need Python on the server, but that’s easier to guarantee.
Python and tkinter, you will recall, are very portable, too—they run on all major window systems (X11, Windows, Mac)—but to run a client-side Python/tkinter program such as PyMailGUI, you need Python and tkinter on the client machine itself. Not so with an application built as CGI scripts: it will work on Macintosh, Linux, Windows, and any other machine that can somehow render HTML web pages. In this sense, HTML becomes a sort of portable GUI API language in web scripts, interpreted by your web browser, which is itself a kind of generalized GUI for rendering GUIs. You don’t even need the source code or bytecode for the CGI scripts themselves—they run on a remote server that exists somewhere else on the Net, not on the machine running the browser.
- Execution requirements
But you do need a browser. That is, the very nature of web-enabled systems can render them useless in some environments. Despite the pervasiveness of the Internet, many applications still run in settings that don’t have web browsers or Internet access. Consider, for instance, embedded systems, real-time systems, and secure government applications. While an intranet (a local network without external connections) can sometimes make web applications feasible in some such environments, I have worked at more than one company whose client sites had no web browsers to speak of. On the other hand, such clients may be more open to installing systems like Python on local machines, as opposed to supporting an internal or external network.
- Administration requirements
You really need a server, too. You can’t write CGI-based systems at all without access to a web server. Further, keeping programs on a centralized server creates some fairly critical administrative overheads. Simply put, in a pure client/server architecture, clients are simpler, but the server becomes a critical path resource and a potential performance bottleneck. If the centralized server goes down, you, your employees, and your customers may be knocked out of commission. Moreover, if enough clients use a shared server at the same time, the speed costs of web-based systems become even more pronounced. In production systems, advanced techniques such as load balancing and fail-over servers help, but they add new requirements.
In fact, one could make the argument that moving toward a web server architecture is akin to stepping backward in time—to the time of centralized mainframes and dumb terminals. Some would include the emerging cloud computing model in this analysis, arguably in part a throwback to older computing models. Whichever way we step, offloading and distributing processing to client machines at least partially avoids this processing bottleneck.
Other Approaches
So what’s the best way to build applications for the Internet—as client-side programs that talk to the Net or as server-side programs that live and breathe on the Net? Naturally, there is no one answer to that question, since it depends upon each application’s unique constraints. Moreover, there are more possible answers to it than have been disclosed so far. Although the client and server programming models do imply trade-offs, many of the common web and CGI drawbacks already have common proposed solutions. For example:
- Client-side solutions
Client- and server-side programs can be mixed in many ways. For instance, applet programs live on a server but are downloaded to and run as client-side programs with access to rich GUI libraries.
Other technologies, such as embedding JavaScript or Python directly in HTML code, also support client-side execution and richer GUI possibilities. Such scripts live in HTML on the server but run on the client when downloaded and access browser components through an exposed object model to customize pages.
The Dynamic HTML (DHTML) extensions provide yet another client-side scripting option for changing web pages after they have been constructed. And the newly emerging AJAX model offers additional ways to add interactivity and responsiveness to web pages, and is at the heart of the RIA model noted ahead. All of these client-side technologies add extra complexities all their own, but they ease some of the limitations imposed by straight HTML.
- State retention solutions
We discussed general state retention options in detail in the prior chapter, and we will study full-scale database systems for Python in Chapter 17. Some web application servers (e.g., Zope) naturally support state retention between pages by providing concurrently accessible object databases. Some of these systems have an explicit underlying database component (e.g., Oracle and MySQL); others may use flat files or Python persistent shelves with appropriate locking. In addition, object relational mappers (ORMs) such as SQLObject allow relational databases to be processed as Python classes.
Scripts can also pass state information around in hidden form fields and generated URL parameters, as done in PyMailCGI, or they can store it on the client machine itself using the standard cookie protocol. As we learned in Chapter 15, cookies are strings of information that are stored on the client upon request from the server, and that are transferred back to the server when a page is revisited (data is sent back and forth in HTTP header lines). Cookies are more complex than program variables and are somewhat controversial and optional, but they can offload some simple state retention tasks.
Alternative models such as FastCGI and
mod_pythonoffer additional persistence options—where supported, FastCGI applications may retain context in long-lived processes, andmod_pythonprovides session data within Apache.- HTML generation solutions
Third-party extensions can also take some of the complexity out of embedding HTML in Python CGI scripts, albeit at some cost to execution speed. For instance, the HTMLgen system and its relatives let programs build pages as trees of Python objects that “know” how to produce HTML. Other frameworks prove an object-based interface to reply-stream generation (e.g., a reply object with methods). When a system like this is employed, Python scripts deal only with objects, not with the syntax of HTML itself.
For instance, systems such as PHP, Python Server Pages (PSP), Zope’s DTML and ZPT, and Active Server Pages provide server-side templating languages, which allow scripting language code to be embedded in HTML and executed on the server, to dynamically generate or determine part of the HTML that is sent back to a client in response to requests. The net result can cleanly insulate Python code from the complexity of HTML code and promote the separation of display format and business logic, but may add complexities of its own due to the mixture of different languages.
- Generalized user interface development
To cover both bases, some systems attempt to separate logic from display so much as to make the choice almost irrelevant—by completely encapsulating display details, a single program can, in principle, render its user interface as either a traditional GUI or an HTML-based web page. Due to the vastly different architectures, though, this ideal is difficult to achieve well and does not address larger disparities between the client and server platforms. Issues such as state retention and network interfaces are much more significant than generation of windows and controls, and may impact code more.
Other systems may try to achieve similar goals by abstracting the display representation—a common XML representation, for instance, might lend itself to both a GUI and an HTML rendering. Again, though, this addresses only the rendering of the display, not the fundamental architectural differences of client- and server-side approaches.
- Emerging technologies: RIAs and HTML 5
Finally, higher-level approaches such as the RIA (Rich Internet Application) toolkits introduced in Chapters 7 and 12 can offer additional functionality that HTML lacks and can approach the utility on GUI toolkits. On the other hand, they can also complicate the web development story even further, and add yet additional languages to the mix. Though this can vary, the net result is often something of a Web-hosted Tower of Babel, whose development might require simultaneously programming in Python, HTML, SQL, JavaScript, a server-side templating language, an object-relational mapping API, and more, and even nested and embedded combinations of these. The resulting software stack can be more complex than Python and a GUI toolkit.
Moreover, RIAs today inherit the inherent speed degradation of network-based systems in general; although AJAX can add interactivity to web pages, it still implies network access instead of in-process function calls. Ironically, much like desktop applications, RIAs may also still require installation of a browser plug-in on the client to be used at all. The emerging HTML 5 standard may address the plug-in constraint and ease the complexity somewhat, but it brings along with it a grab bag of new complexities all its own which we won’t describe here.
Clearly, Internet technology does come with some compromises, and it is still evolving rapidly. It is nevertheless an appropriate delivery context for many, though not all, applications. As with every design choice, you must be the judge. While delivering systems on the Web may have some costs in terms of performance, functionality, and complexity, it is likely that the significance of those overheads will continue to diminish with time. See the start of Chapter 12 for more on some systems that promise such change, and watch the Web for the ever-changing Internet story to unfold.
[66] One downside to running a local webserver.py script that I noticed during development for this chapter is that on platforms where CGI scripts are run in the same process as the server, you’ll need to stop and restart the server every time you change an imported module. Otherwise, a subsequent import in a CGI script will have no effect: the module has already been imported in the process. This is not an issue on Windows today or on other platforms that run the CGI as a separate, new process. The server’s classes’ implementation varies over time, but if changes to your CGI scripts have no effect, your platform may fall into this category: try stopping and restarting the locally running web server.
[67] Technically, again, you should generally escape & separators in generated URL
links by running the URL through cgi.escape, if any parameter’s name
could be the same as that of an HTML character escape code
(e.g., &=high). See
Chapter 15 for more details; they
aren’t escaped here because there are no clashes between URL and
HTML.
[68] Notice that the message number arrives as a string and
must be converted to an integer in order to be used to fetch the
message. But we’re careful not to convert with eval here, since this is a string
passed over the Net and could have arrived embedded at the end
of an arbitrary URL (remember that earlier warning?).