
Chapter 10. Interprocess Communication: It’s good to talk

Creating processes is just half the story.
What if you want to control the process once it’s running? What if you want to send it data? Or read its output? Interprocess communication lets processes work together to get the job done. We’ll show you how to multiply the power of your code by letting it talk to other programs on your system.
Redirecting input and output
When you run programs from the command line, you can
redirect the Standard Output to a file using the > operator:

The Standard Output is one of the three default data streams. A data stream is exactly what it sounds like: a stream of data that goes into, or comes out of, a process. There are data streams for the Standard Input, Output, and Error, and there are also data streams for other things, like files or network connections. When you redirect the output of a process, you change where the data is sent. So, instead of the Standard Output sending data to the screen, you can make it send the data to a file.
Redirection is really useful on the command line, but is there a way of making a process redirect itself?
A look inside a typical process
Every process will contain the program it’s running, as well as space for stack and heap data. But it will also need somewhere to record where data streams like the Standard Output are connected. Each data stream is represented by a file descriptor, which, under the surface, is just a number. The process keeps everything straight by storing the file descriptors and their data streams in a descriptor table.
A file descriptor is a number that represents a data stream.

The descriptor table has one column for each of the file descriptor numbers. Even though these are called file descriptors, they might not be connected to an actual file on the hard disk. Against every file descriptor, the table records the associated data stream. That data stream might be a connection to the keyboard or screen, a file pointer, or a connection to the network.
The first three slots in the table are always the same. Slot 0 is the Standard Input, slot 1 is the Standard Output, and slot 2 is the Standard Error. The other slots in the table are either empty or connected to data streams that the process has opened. For example, every time your code opens a file for reading or writing, another slot is filled in the descriptor table.
When the process is created, the Standard Input is connected to the keyboard, and the Standard Output and Error are connected to the screen. And they will stay connected that way until something redirects them somewhere else.
File descriptors don’t necessarily refer to files.
Redirection just replaces data streams
The Standard Input, Output, and Error are always fixed in the same places in the descriptor table. But the data streams they point to can change.

That means if you want to redirect the Standard Output, you just need to switch the data stream against descriptor 1 in the table.
All of the functions, like printf(), that send data to the Standard
Output will first look in the descriptor table to see where descriptor 1
is pointing. They will then write data out to the correct data
stream.
Processes can redirect themselves
Every time you’ve used redirection so far, it’s been from the
command line using the > and
< operators. But processes can
do their own redirection by rewiring the descriptor table.
Geek Bits
So, that’s why it’s 2> ...
You can redirect the Standard Output and Standard Error on the command line using the > and 2> operators:
./myprog > output.txt 2> errors.log
Now you can see why the Standard Error is redirected with 2>. The 2 refers to the number of the Standard Error in the descriptor table. On most operating systems, you can use 1> as an alternative way of redirecting the Standard Output, and on Unix-based systems you can even redirect the Standard Error to the same place as the Standard Output like this:

fileno() tells you the descriptor
Every time you open a file, the operating system registers a new item in the descriptor table. Let’s say you open a file with something like this:
FILE *my_file = fopen("guitar.mp3", "r");The operating system will open the guitar.mp3 file and return a pointer to it, but it will also skim through the descriptor table until it finds an empty slot and register the new file there.
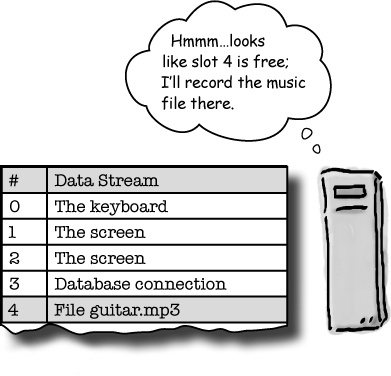
But once you’ve got a file pointer, how do you find it in the
descriptor table? The answer is by calling the
fileno() function.
fileno() is one of the few
system functions that doesn’t return –1 if it fails. As long as you pass
fileno() the pointer to an open file,
it should always return the descriptor number.
dup2() duplicates data streams
Opening a file will fill a slot in the descriptor table, but
what if you want to change the data stream
already registered against a descriptor? What if you want to change
file descriptor 3 to point to a different data stream? You can do it
with the dup2() function. dup2() duplicates a data stream from one
slot to another. So, if you have a file pointer to
guitar.mp3 plugged in to file descriptor 4, the
following code will connect it to file descriptor 3 as well.
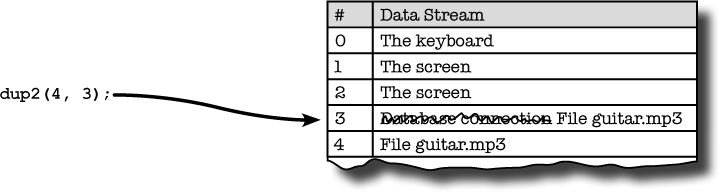
There’s still just one guitar.mp3 file, and
there’s still just one data stream connected to it. But the data
stream (the FILE*) is now
registered with file descriptors 3 and 4.
Now that you know how to find and change things in the descriptor table, you should be able to redirect the Standard Output of a process to point to a file.
Do you find that you’re writing duplicate error-handling code every time you make a system call? Then fear no more! Using our patented method, we’ll show you how to make the most out of your error code without writing the same thing over and over.

Look at these two troublesome pieces of code:

Is there some way of removing the duplicated code block? Why, yes, there is! By creating a simple fire-and-forget error() function, you’ll make your duplicated code a thing of the past.
What’s that, you say? How do you handle that troublesome return statement? After all, you can’t move that into a function, can you?
There’s no need! The exit() system call is the fastest way to stop your program in its tracks. No more worrying about returning to main(); just call exit(), and your program’s history!
This is how it works. First, remove all of your error code into a separate function called error() and replace that tricky return with a call to exit().

Now you can replace that troublesome error-checking code with something much simpler:
pid_t pid = fork();
if (pid == -1) {
error("Can't fork process");
}
if (execle(...) == -1) {
error("Can't run script");
}Warning: offer limited to one exit() call per program execution. Do not operate exit() if you have a fear of sudden program termination.
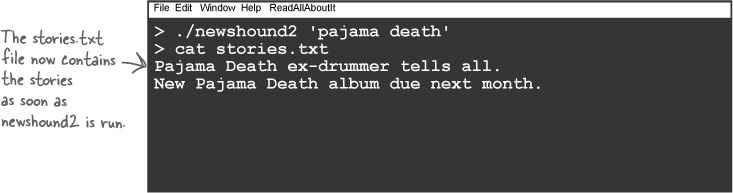
This is a program that saves the output of the
rssgossip.py script into a file called
stories.txt. It’s similar to the newshound program, except it searches
through a single RSS feed only. Using what you’ve learned about the
descriptor table, see if you can find the missing line of code that
will redirect the Standard Output
of the child process to the stories.txt
file.

This is a program that saves the output of the
rssgossip.py script into a file called
stories.txt. It’s similar to the newshound program, except it searches
through a single RSS feed only. Using what you’ve learned about the
descriptor table, you were to find the missing line of code that
will redirect the Standard Output
of the child process to the stories.txt
file.

Did you get the right answer? The program will change the descriptor table in the child script to look like this:
That means that when the rssgossip.py script sends data to the Standard Output, it should appear in the stories.txt file.
# | Data Stream |
0 | The keyboard |
1 | File stories.txt |
2 | The screen |
3 | File stories.txt |
This is what happens when the program is compiled and run:

What happened?
When the program opened the stories.txt
file with fopen(), the operating
system registered the file f in
the descriptor table. fileno(f)
was the descriptor number it used. The dup2() function set the Standard Output
descriptor (1) to point to the same file.


Sometimes you need to wait...
The newshound2 program
fires off a separate process to run the
rssgossip.py script. But once that child process
gets created, it’s independent of its
parent. You could run the newshound2
program and still have an empty stories.txt, just
because the rssgossip.py isn’t finished yet. That
means the operating system has to give you some way of waiting for the child process to
complete.
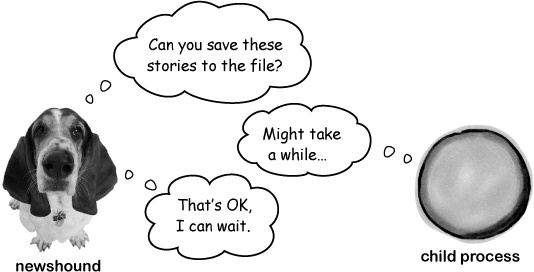
The waitpid() function
The waitpid() function won’t return
until the child process dies. That means you can add a little code to
your program so that it won’t exit until the
rssgossip.py script has stopped running:

waitpid() takes
three parameters:

pid
This is the process ID that the parent process was given when it
forked the child.pid_status
This will store exit information about the process.
waitpid()will update it, so it needs to be a pointer.options
There are several options you can pass to
waitpid(), and typingman waitpidwill give you more info. If you set the options to0, the function waits until the process finishes.
What’s the status?
When the waitpid() function
has finished waiting, it stores a value in pid_status that tells you how the process
did. To find the exit status of the child
process, you’ll have to pass the pid_status value through a macro called
WEXITSTATUS():

Why do you need the macro? Because the pid_status contains several pieces of
information, and only the first 8 bits represent the exit status.
The macro tells you the value of just those 8 bits.
Now, when you run the newshound2 program, it checks that the
rssgossip.py script finishes before newshound2 itself ends:
Adding a waitpid() to the
program was easy to do and it made the program more reliable.
Before, you couldn’t be sure that the subprocess had finished
writing, and that meant there was no way you could use the newshound2 program as a proper tool. You
couldn’t use it in scripts and you couldn’t create a GUI frontend
for it.
Redirecting input and output, and making processes wait for each other, are all simple forms of interprocess communication. When processes are able to cooperate—by sharing data or by waiting for each other—they become much more powerful.

Stay in touch with your child
You’ve seen how to run a separate process using exec() and fork(), and you know how to redirect the
output of a child process into a file. But what if you want to listen to
a child process directly? Is that possible? Rather than waiting for a
child process to send all of its data into a file and then reading the
file afterward, is there some way to start a process running and read
the data it generates in real
time?
Reading story links from rssgossip
As an example, there’s an option on the rssgossip.py script that allows you to display the URLs for any stories that it finds:

Now, you could run the script and save its output to a file, but that would be slow. It would be much better if the parent and child process could talk to each other while the child process is still running.
Connect your processes with pipes
You’ve already used something that makes live connections between processes: pipes.

Pipes are used on the command line to connect the output of one process with the input of another process. In the example here,
you’re running the rssgossip.py script manually and
then passing its output through a command called grep. The
grep command finds all the lines
containing http.
Piped commands are parents and children
Whenever you pipe commands together on the
command line, you are actually connecting them together as parent and
child processes. So, in the above example, the grep command is the parent of the
rssgossip.py script.
The command line creates the parent process.
The parent process forks the rssgossip.py script in a child process.
The parent connects the output of the child with the input of the parent using a pipe.
The parent process execs the grep command.



Pipes are used a lot on the command line to allow users to connect processes together. But what if you’re just using C code? How do you connect a pipe to your child process so that you can read its output as soon as it’s generated?
Case study: opening stories in a browser
Let’s say you want to run the rssgossip.py script and then open the stories it finds in a web browser. Your program will run in the parent process and rssgossip.py will run in the child. You need to create a pipe that connects the output of rssgossip.py to the input of your program.
But how do you create a pipe?
pipe() opens two data streams
Because the child is going to send data to the parent, you need
a pipe that’s connected to the Standard Output of the child and the
Standard Input of the parent. You’ll create the pipe using the
pipe() function. Remember how we
said that every time you open a data stream to something like a file,
it gets added to the descriptor table? Well, that’s exactly what the
pipe() functions does: it creates
two connected streams and adds them to the table. Whatever is written
into one stream can be read from the other.


When pipe() creates the two
lines in the descriptor table, it will store their file descriptors in
a two-element array:

The pipe() command creates a
pipe and tells you two descriptors: fd[1] is the descriptor that writes to the pipe, and fd[0] is the descriptor that reads from the pipe. Once you’ve got the
descriptors, you’ll need to use them in the parent and child
processes.
fd[1] writes to the pipe; fd[0] reads from it.
In the child
In the child process, you need to close the fd[0] end of the pipe and then change the
child process’s Standard Output to point to the same stream as
descriptor fd[1].

That means that everything the child sends to the Standard Output will be written to the pipe.
In the parent
In the parent process, you need to close the fd[1] end of the pipe (because you won’t be
writing to it) and then redirect the parent process’s Standard Input to
read its data from the same place as descriptor fd[0]:

Everything that the child writes to the pipe will be read through the Standard Input of the parent process.
Opening a web page in a browser
Your program will need to open up a web page using the machine’s browser. That’s kind of hard to do, because different operating systems have different ways of talking to programs like web browsers.
Fortunately, the out-of-work actors have hacked together some code
that will open web pages on most systems. It looks like they were in a
rush to go do something else, so they’ve put together something pretty
simple using system():


Ready-Bake Code

The code runs three separate commands to open a URL: that’s one command each for the Mac, Windows, and Linux. Two of the commands will always fail, but as long as the third command works, that’ll be fine.
Go Off Piste
Think you can write better code than the out-of-work actors?
Then why not rewrite the code to use fork() and exec() for your favorite operating
system?
It looks like most of the program is already written. All you
need to do is complete the code that connects the
parent and child processes
to a pipe. To save space, the #include lines and the error() and open_url() functions have been removed.
Remember, in this program the child is going to
talk to the parent, so make sure that pipe’s
connected the right way!

It looks like most of the program is already written. You were
to complete the code that connects the parent and
child processes to a pipe. To save space, the
#include lines and the error() and open_url() functions have been
removed.

When you compile and run the code, this happens:

That’s great. It worked.
The news_opener program ran
the rssgossip.py in a separate process and told
it to display URLs for each story it found. All of the output of the
screen was redirected through a pipe that was connected to the news_opener parent process. That meant the
news_opener process could search
for any URLs and then open them in the browser.
Pipes are a great way of connecting processes together. Now, you have the ability to not only run processes and control their environments, but you also have a way of capturing their output. That opens up a huge amount of functionality to you. Your C code can now use and control any program that you can use from the command line.
Go Off Piste
Now that you know how to control rssgossip.py, why not try controlling some of these programs? You can get all of them for Unix-style machines or any Windows machine using Cygwin:
curl/wget
These programs let you talk to web servers. If you call them from C code, you can write programs that can talk to the Web.
mail/mutt
These programs let you send email from the command line. If they’re on your machine, it means your C programs can send mail too.
convert
This command can convert one image format to another image format. Why not create a C program that outputs SVG charts in text format, and then use the convert command to create PNG images from them?
The death of a process
You’ve seen how processes are created, how their environments are configured, and even how processes talk to each other. But what about how processes die? For example, if your program is reading data from the keyboard and the user hits Ctrl-C, the program stops running.
How does that happen? You can tell from the output that the
program never got as far as running the second printf(), so the Ctrl-C didn’t just stop the
fgets() command. Instead, the whole
program just stopped in its tracks. Did the operating system just unload
the program? Did the fgets() function
call exit()? What happened?

The O/S controls your program with signals
The magic all happens in the operating system. When you call the
fgets() function, the operating
system reads the data from the keyboard, and when it sees the user hit
Ctrl-C, sends an interrupt signal to the program.
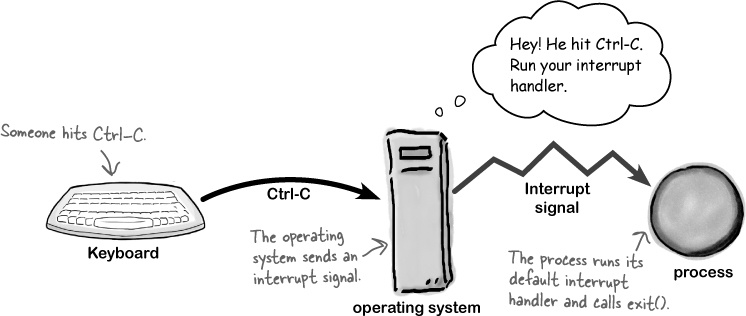
A signal is just a short message: a single integer value. When
the signal arrives, the process has to stop whatever it’s doing and go
deal with the signal. The process looks at a table of signal
mappings that link each signal with a function called the
signal handler. The default signal
handler for the interrupt signal just calls the exit() function.
So, why doesn’t the operating system just kill the program? Because the signal table lets you run your own code when your process receives a signal.

Catching signals and running your own code
Sometimes you’ll want to run your own code if someone
interrupts your program. For example, if your process has files or
network connections open, it might want to close things down and tidy up
before exiting. But how do you tell the computer to run your code when
it sends you a signal? You can do it with
sigactions.
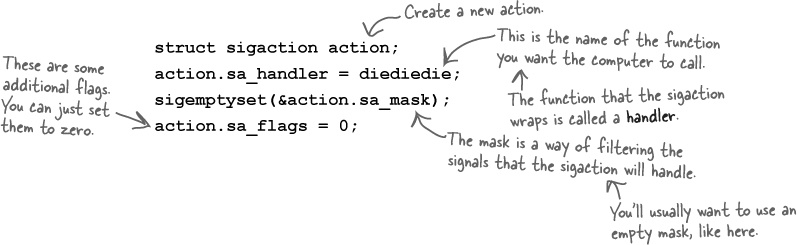
A sigaction is a function wrapper
A sigaction is a struct that contains a pointer to a
function. sigactions are used to
tell the operating system which function it should call when a signal
is sent to a process. So, if you have a function called diediedie() that you want the operating
system to call if someone sends an interrupt
signal to your process, you’ll need to wrap the diediedie() function up as a sigaction.
This is how you create a sigaction:
The function wrapped by a sigaction is called the handler, because it will be used to deal with
(or handle) a signal that’s sent to it. If you
want to create a handler, it will need to be written in a certain
way.
All handlers take signal arguments
Signals are just integer values, and if you create a custom
handler function, it will need to accept an int argument, like this:

Because the handler is passed the number of the signal, you can reuse the same handler for several signals. Or, you can have a separate handler for each signal. How you choose to program it is up to you.
Handlers are intended to be short, fast pieces of code. They should do just enough to deal with the signal that’s been received.
Watch it!
Be careful when writing to Standard Output and Error in handler functions.
Even though the example code you’ll use will display text on the Standard Output, be careful about doing that in more complex programs. Signals can arrive because something bad has happened to the program. That might mean that Standard Output isn’t available, so be careful.
sigactions are registered with sigaction()
Once you’ve create a sigaction, you’ll need to tell the operating
system about it. You do that with the sigaction() function:
sigaction(signal_no, &new_action, &old_action);sigaction() takes three
parameters:
The signal number.
The integer value of the signal you want to handle. Usually, you’ll pass one of the standard signal symbols, like
SIGINTorSIGQUIT.The new action.
This is the address of the new
sigactionyou want to register.The old action.
If you pass a pointer to another
sigaction, it will be filled with details of the current handler that you’re about to replace. If you don’t care about the existing signal handler, you can set this toNULL.
The sigaction() function will
return –1 if it fails and will also set the errno variable. To keep the code short, some
of the code you’ll see in this book will skip checking for errors, but
you should always check for
errors in your own code.
Ready-Bake Code
This is a function that will make it a little easier to register functions as signal handlers:

This function will allow you to set a signal handler by calling
catch_signal() with a signal number
and a function name:
catch_signal(SIGINT, diedieie)Rewriting the code to use a signal handler
You now have all the code to make your program do something if someone hits the Ctrl-C key:

The program will ask for the user’s name and then wait for her to
type. But if instead of typing her name, the user just hits the Ctrl-C
key, the operating system will automatically send the process an
interrupt signal ( SIGINT). That interrupt signal will be handled
by the sigaction that was registered
in the catch_signal() function. The
sigaction contains a pointer to the
diediedie() function. This will then
be called, and the program will display a message and exit().


Use kill to send signals
If you’ve written some signal-handling code, how do you
test it? Fortunately, on Unix-style systems, there’s a command called
kill. It’s called kill because it’s normally used to kill off
processes, but in fact, kill just
sends a signal to a process. By default, the command sends a SIGTERM signal to the process, but you can use
it to send any signal you like.
To try it out, open two terminals. In one
terminal, you can run your program. Then, in the second terminal, you
can send signals to your program with the kill command:
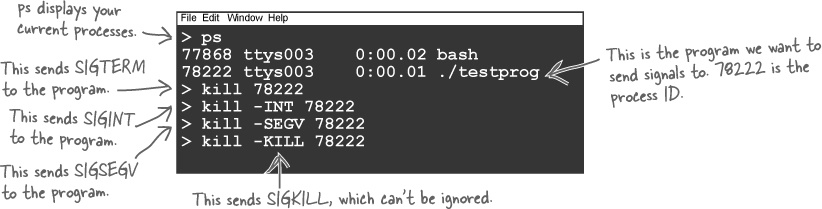
Each of these kill commands
will send signals to the process and run whatever handler the process
has configured. The exception is the SIGKILL signal. The SIGKILL signal can’t be caught by code, and it
can’t be ignored. That means if you have a bug in your code and it is
ignoring every signal, you can always
stop the process with kill
-KILL.
kill -KILL <pid> will always kill your program.
Send signals with raise()
Sometimes you might want a process to send a signal to itself,
which you can do with the raise()
command.
raise(SIGTERM);Normally, the raise() command
is used inside your own custom signal handlers. It means your code can
receive a signal for something minor and then choose to raise a more
serious signal.
This is called signal escalation.
Sending your code a wake-up call
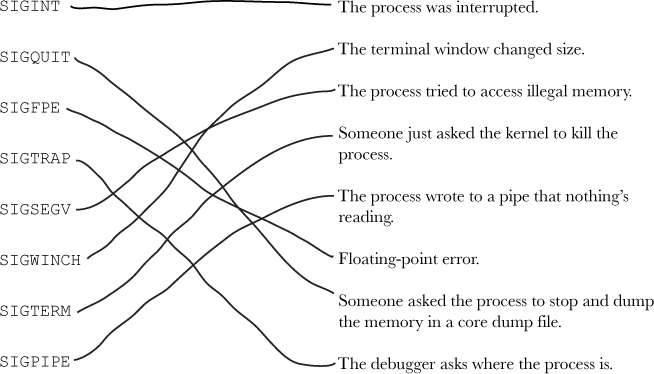
The operating system sends signals to a process when something has happened that the process needs to know about. It might be that the user has tried to interrupt the process, or someone has tried to kill it, or even that the process has tried to do something it shouldn’t have, like trying to access a restricted piece of memory.
But signals are not just used when things go wrong. Sometimes a
process might actually want to generate its own signals. One example of
that is the alarm signal, SIGALRM.
The alarm signal is usually created by the process’s interval timer. The interval timer is like an
alarm clock: you set it for some time in the future, and in the meantime
your program can go and do something else:
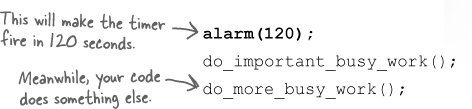

But even though your program is busy doing other things, the timer is still running in the background. That means that when the 120 seconds are up...
...the timer fires a SIGALRM signal
When a process receives a signal, it stops doing everything else and handles the signal. But what does a process do with an alarm signal by default? It stops the process. It’s really unlikely that you would ever want a timer to kill your program for you, so most of the time you will set the handler to do something else:

Alarm signals let you multitask. If you need to run a particular job every few seconds, or if you want to limit the amount of time you spend doing a job, then alarm signals are a great way of getting a program to interrupt itself.
Watch it!
Don’t use alarm() and sleep() at the same time.
The sleep() function puts your
program to sleep for a few seconds, but it works by using the same
interval timer as the alarm() function, so if you try
to use the two functions at the same time, they will interfere with
each other.
You’ve seen how to set custom signal handlers, but
what if you want to restore the default signal handler? Fortunately,
the signal.h header has a special symbol
SIG_DFL, which means handle it the default way.
catch_signal(SIGTERM, SIG_DFL);
Also, there’s another symbol,
SIG_IGN, that tells
the process to completely ignore
a signal.
catch_signal(SIGINT, SIG_IGN);
But you should be very careful before you choose to ignore a signal. Signals are an important way of controlling—and stopping—processes. If you ignore them, your program will be harder to stop.
This is the source code for a program that tests the user’s math skills. It asks the user to work the answer to a simple multiplication problem and keeps track of how many answers he got right. The program will keep running forever, unless:
The user presses Ctrl-C, or
The user takes more than five seconds to answer the question.
When the program ends, it will display the final score and set the exit status to 0.


This is the source code for a program that tests the user’s math skills. It asks the user to work the answer to a simple multiplication problem and keeps track of how many answers he got right. The program will keep running forever, unless:
The user presses Ctrl-C, or
The user takes more than five seconds to answer the question.
When the program ends, it will display the final score and set the exit status to 0.


To see if the program works, you need to run it a couple of times.
Test 1: hit Ctrl-C
The first time, you’ll answer a few questions and then hit Ctrl-C.
Ctrl-C sends the process an interrupt signal ( SIGINT) that makes the program display the
final score and then exit().

Test 2: wait five seconds
The second time, instead of hitting Ctrl-C, wait for at least five seconds on one of the answers and see what happens.
The alarm signal ( SIGALRM)
fires. The program was waiting for the user to enter an answer, but
because he took so long, the timer signal was sent; the process
immediately switches to the times_up() handler function. The handler
displays the “TIME’S UP!” message and then escalates the signal to a
SIGINT that causes the program to
display the final score.

Signals are a little complex, but incredibly useful. They allow your programs to end gracefully, and the interval timer can help you deal with tasks that are taking too long.
Your C Toolbox
You’ve got Chapter 10 under your belt, and now you’ve added interprocess communication to your toolbox. For a complete list of tooltips in the book, see Appendix B.
