
Appendix A. Leftovers: The top ten things (we didn’t cover)

Even after all that, there’s still a bit more.
There are just a few more things we think you need to know. We wouldn’t feel right about ignoring them, even though they need only a brief mention, and we really wanted to give you a book you’d be able to lift without extensive training at the local gym. So before you put the book down, read through these tidbits.
#1. Operators
We’ve used a few operators in this book, like the basic
arithmetic operators +, -,
*, and /, but there are many other operators
available in C that can make your life easier.
Increments and decrements
An increment and a decrement increase and decrease a number by 1. That’s a very common operation in C code, particularly if you have a loop that increments a counter. The C language gives you four simple expressions that simplify increments and decrements:

Each of these expressions will change the value of i. The position of the ++ and --
say whether or not to return the original value of i or its new value. For example:
The ternary operator
What if you want one value if some condition is true, and a different value if it’s false?
if (x == 1) return 2; else return 3;
C has a ternary operator that allows you to compress this code right down to the following:

Bit twiddling
C can be used for low-level programming, and it has a set of operators that let you calculate a new series of bits:
Operator | Description |
| The value of |
| AND the bits of |
| OR the bits of |
| XOR the bits of |
| Shift bits to the left (increase) |
| Shift bits to the right (decrease) |
The << operator can be
used as a quick way of multiplying an integer by 2. But be careful
that numbers don’t overflow.
Commas to separate expressions
You’ve seen for loops that
perform code at the end of each loop:
But what if you want to perform more than one operation at the end of a loop? You can use the comma operator:
The comma operator exists because there are times when you don’t want to separate expressions with semicolons.
#2. Preprocessor directives
You use a preprocessor directive every time you compile a program that includes a header file:
The preprocessor scans through your C source file and generates a
modified version that will be compiled. In the case of the #include directive, the preprocessing inserts
the contents of the stdio.h file. Directives always
appear at the start of a line, and they always begin with the hash (
#) character. The next most common
directive after #include is #define:
#define DAYS_OF_THE_WEEK 7 ... printf("There are %i days of the week ", DAYS_OF_THE_WEEK);
The #define directive creates a
macro. The preprocessor will scan through the C
source and replace the macro name with the macro’s value. Macros aren’t
variables because they can never change at runtime. Macros are replaced
before the program even compiles. You can even
create macros that work a little like functions:

The preprocessor will replace ADD_ONE(3) with ((3)
+ 1) before the program is compiled.

#3. The static keyword
Imagine you want to create a function that works like a counter. You could write it like this:

What’s the problem with this code? It uses a global variable
called count. Any other function can
change the value of count because
it’s in the global scope. If you start to write large programs, you need
to be careful that you don’t have too many global variables because they
can lead to buggy code. Fortunately, C lets you create a
global variable that is available only inside the
local scope of a function:

The static keyword will store
the variable inside the global area of memory, but the compiler will
throw an error if some other function tries to access the count variable.
static can also make things private
You can also use the static
keyword outside of functions. static in this case means “only code in this
.c file can use this.” For example:

The static keyword controls the scope of something. It will
prevent your data and functions from being accessed in ways that they
weren’t designed to be.
#4. How big stuff is
You’ve seen that the sizeof operator can tell you how much memory a
piece of data will occupy. But what if you want to know what range of values it will hold? For example, if
you know that an int occupies 4 bytes
on your machine, what’s the largest positive number you can store in it?
Or the largest negative number? You could, theoretically, work that out
based on the number of bytes it uses, but that can be tricky.
Instead, you can use the macros defined in the limits.h header. Want to know what the
largest long value you can use is?
It’s given by the LONG_MAX macro. How
about the most negative short? Use
SHRT_MIN. Here’s an example program
that shows the ranges for ints and
shorts:
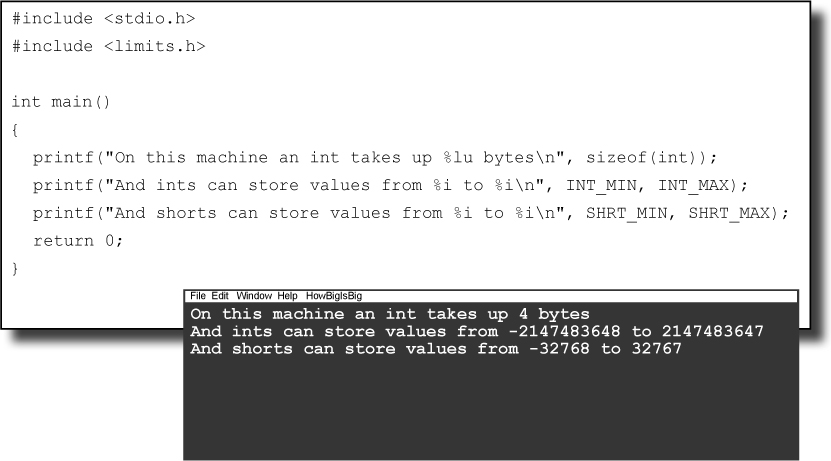
The macro names come from the data types: INT ( int),
SHRT ( short), LONG ( long), CHAR
( char), FLT ( float), DBL
( double). Then, you either add
_MAX (most positive) or _MIN (most negative). You can optionally add
the prefix U ( unsigned), S ( signed), or L ( long)
if you are interested in a more specific data type.
#5. Automated testing
It’s always important to test your code, and life becomes a lot simpler if you automate the tests. Automated tests are now used by virtually all developers, and there are many, many testing frameworks used by C programmers. One that’s popular at Head First Labs is called AceUnit:
http://aceunit.sourceforge.net/
AceUnit is very similar to the xUnit frameworks in other languages (like nUnit and jUnit).
If you’re writing a command-line tool and you have a Unix-style
command shell, then another great tool is called shunit2.
http://code.google.com/p/shunit2/
shunit2 lets you create shell
scripts that test scripts and commands.
#6. More on gcc
You’ve used the GNU Compiler
Collection ( gcc)
throughout this book, but you’ve only scratched the surface of what this
compiler can do for you. gcc is like
a Swiss Army knife. It has an immense number of features that give you a
tremendous amount of control over the code it produces.

Optimization
gcc can do a huge amount to
improve the performance of your code. If it sees that you’re assigning
the same value to a variable every time a loop runs, it can move that
assignment outside the loop. If you have a small function that is used
only in a few places, it can convert that function into a piece of
inline code and insert it into the right places
in your program.
It can do lots of optimizations, but most of them are switched off by default. Why? Because optimizations take time for the compiler to perform, and while you’re developing code you normally want your compiles to be fast. Once your code is ready for release, you might want to switch on more optimization. There are four levels of optimization:
Flag | Description |
| If you add a |
| For even more optimizations and a
slower compile, choose |
| For yet more
optimizations, choose |
| The maximum amount of optimization
is done with |
Warnings
Warnings are displayed if the code is technically valid
but does something suspicious, like assign a value to a variable of
the wrong type. You can increase the number of warning checks with
-Wall:
gcc fred.c
-Wall -o fredThe -Wall option means “All
warnings,” but for historic reasons is doesn’t
actually display all of the warnings. For that,
you should also include -Wextra:
gcc fred.c -Wall
-Wextra -o fredAlso, if you want to have really strict
compilation, you can make the compile fail if there are any warnings
at all with -Werror:
-Werror is useful if several
people are working on the same code because it will help maintain code
quality.
For more gcc options,
see:
#7. More on make
make is an incredibly
powerful tool for building C applications, but you’ve only had a very
simple introduction to it in this book. For more details on the amazing
things you can do with make, see
Robert Mecklenburg’s Managing Projects with GNU
Make:
http://shop.oreilly.com/product/9780596006105.do
For now, here are just a few of its features.
Variables
Variables are a great way of shortening your makefiles. For
example, if you have a standard set of command-line options you want
to pass to gcc, you can define them
with a variable:
CFLAGS = -Wall -Wextra -v fred: fred.c gcc fred.c $(CFLAGS) -o fred
You define a variable using the equals sign ( =) and then read its value with $(...).
Using %, ^, and @
Most of the time, a lot of your compile commands are going to look pretty similar:
fred: fred.c gcc fred.c -Wall -o fred
In which case, you might want to use the % symbol to write a more general
target/recipe:

This looks a little weird because of all the symbols. If you
want to make a file called fred, this rule tells
make to look for a file called
fred.c. Then, the recipe will run a gcc command to create the target fred (given by the special symbol $@) using the given dependency (given by
$@).
Implicit rules
The make tool knows
quite a lot about C compilation, and it can use implicit
rules to build files without you telling it exactly how.
For example, if you have a file called fred.c,
you can compile it without a
makefile by typing:

That’s because make comes
with a bunch of built-in recipes. For more on make, see:
#8. Development tools
If you’re writing C code, you probably care a lot about performance and stability. And if you’re using the GNU Compiler Collection to compile your code, you’ll probably want to take a look at some of the other GNU tools that are available.
gdb
The GNU Project Debugger ( gdb) lets you study your compiled program
while it’s running. This is invaluable if you’re trying to chase down
some pesky bug. gdb can be used
from the command line or using an integrated development
environment like Xcode or
Guile.
http://sourceware.org/gdb/download/onlinedocs/gdb/index.html
gprof
If your code isn’t as fast as you’d hoped, it might be worth
profiling it. The GNU
Profiler ( gprof) will
tell you which parts of your program are the slowest so that you can
tune the code in the most appropriate way. gprof lets you compile a modified version of
your program that will dump a performance report when it’s finished.
Then the gprof command-line tool
will let you analyze the performance report to track down the slow
parts of your code.
gcov
Another profiling tool is GNU Coverage (
gcov). But while gprof is normally used to check the
performance of your code, gcov is
used to check which parts of your code did or didn’t run. This is
important if you’re writing automated tests, because you’ll want to be
sure that your tests are running all of the code you’re expecting them
to.
#9. Creating GUIs
You haven’t created any graphical user interface (GUI) programs in any of the main chapters of this book. In the labs, you used the Allegro and OpenCV libraries to write a couple of programs that were able to display very simple windows. But GUIs are usually written in very different ways on each operating system.
Linux — GTK
Linux has a number of libraries that are used to create GUI applications, and one of the most popular is the GIMP toolkit (GTK+):
GTK+ is available on Windows and the Mac, as well as Linux, although it’s mostly used for Linux apps.
Windows
Windows has very advanced GUI libraries built-in. Windows programming is a really specialized area, and you will probably need to spend some time learning the details of the Windows application programming interfaces (APIs) before you can easily build GUI applications. An increasing number of Windows applications are written in languages based on C, such as C# and C++. For an online introduction to Windows programming, see:
The Mac — Carbon
The Macintosh uses a GUI system called Aqua. You can create GUI programs in C on the Mac using a set of libraries called Carbon. But the more modern way of programming the Mac is using the Cocoa libraries, which are programmed using another C-derived language called Objective-C. Now that you’ve reached the end of this book, you’re in a very good position to learn Objective-C. Here at Head First Labs, we love the books and courses on Mac programming available at the Big Nerd Ranch:
#10. Reference material
Here’s a list of some popular books and websites on C programming.
Brian W. Kernighan and Dennis M. Ritchie, The C Programming Language (Prentice Hall; ISBN 978-0-131-10362-7)
This is the book that defined the original C programming language, and almost every C programmer on Earth has a copy.
Samuel P. Harbison and Guy L. Steele Jr., C: A Reference Manual (Prentice Hall; ISBN 978-0-130-89592-9)
This is an excellent C reference book that you will want by your side as you code.
Peter van der Linden, Expert C Programming (Prentice Hall; ISBN 978-0-131-77429-2)
For more advanced programming, see Peter van der Linden’s excellent book.
Steve Oualline, Practical C Programming (O’Reilly; ISBN 978-1-565-92306-5)
This book outlines the practical details of C development.
Websites
For standards information, see:
http://pubs.opengroup.org/onlinepubs/9699919799/
For additional C coding tutorials, see:
For general reference information, see:
http://www.cprogrammingreference.com/
For a general C programming tutorial, see: