
Chapter 3. Creating Small Tools: Do one thing and do it well

Every operating system includes small tools.
Small tools written in C perform specialized small tasks, such as reading and writing files, or filtering data. If you want to perform more complex tasks, you can even link several tools together. But how are these small tools built? In this chapter, you’ll look at the building blocks of creating small tools. You’ll learn how to control command-line options, how to manage streams of information, and redirection, getting tooled up in no time.
Small tools can solve big problems
A small tool is a C program that does one task and does it well. It might display the contents of a file on the screen or list the processes running on the computer. Or it might display the first 10 lines of a file or send it to the printer. Most operating systems come with a whole set of small tools that you can run from the command prompt or the terminal. Sometimes, when you have a big problem to solve, you can break it down into a series of small problems, and then write small tools for each of them.
A small tool does one task and does it well.

If one small part of your program needs to convert data from one format to another, that’s the perfect kind of task for a small tool.
Hey, who hasn’t taken a code printout on a long ride only to find that it soon becomes...unreadable? Sure, we all have. But with a little thought, you should be able to piece together the original version of some code.
This program can read comma-separated data from the command line and then display it in JSON format. See if you can figure out what the missing code is.
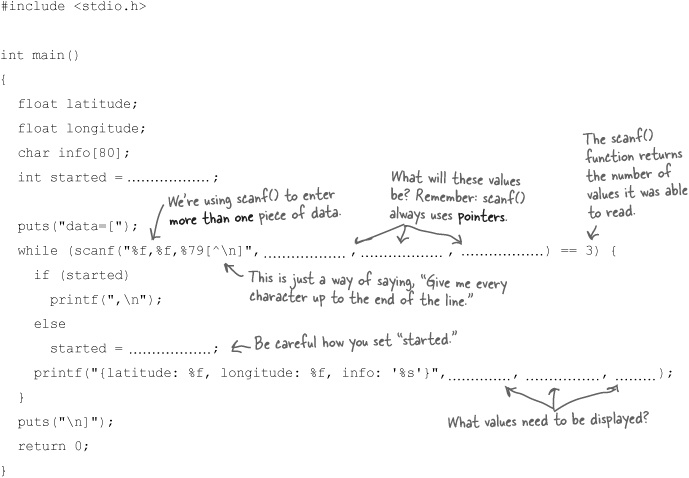
Hey, who hasn’t taken a code printout on a long ride only to find that it soon becomes...unreadable? Sure, we all have. But with a little thought, you should have been able to piece together the original version of some code.
This program can read comma-separated data from the command line and then display it in JSON format. You were to figure out what the missing code is.

So what happens when you compile and run this code? What will it do?

The program lets you enter GPS data at the keyboard and then it displays the JSON-formatted data on the screen. Problem is, the input and the output are all mixed up together. Also, there’s a lot of data. If you are writing a small tool, you don’t want to type in the data; you want to get large amounts of data by reading a file.
Also, how is the JSON data going to be used? Surely it can’t be much use on the screen?
So is the program running OK? Is it doing the right thing? Do you need to change the code?

Here’s how the program should work
Take the GPS from the bike and download the data.
It creates a file called gpsdata.csv with one line of data for every location.
The geo2json tool needs to read the contents of the gpsdata.csv line by line...
...and then write that data in JSON format into a file called output.json.
The web page that contains the map application reads the output.json file.
It displays all of the locations on the map.

But you’re not using files...
The problem is, instead of reading and writing files, your program is currently reading data from the keyboard and writing it to the display.

But that isn’t good enough. The user won’t want to type in all of the data if it’s already stored in a file somewhere. And if the data in JSON format is just displayed on the screen, there’s no way the map within the web page will be able to read it.
You need to make the program work with files. But how do you do that? If you want to use files instead of the keyboard and the display, what code will you have to change? Will you have to change any code at all?
Brain Power
Is there a way of making our program use files without changing code? Without even recompiling it?
Geek Bits
Tools that read data line by line, process it, and write it out again are called filters. If you have a Unix machine, or you’ve installed Cygwin on Windows, you already have a few filter tools installed.
head: This tool displays the first few lines of a file.
tail: This filter displays the lines at the end of a file.
sed: The stream editor lets you do things like search and replace text.
You’ll see later how to combine filters together to form filter chains.
You can use redirection
You’re using scanf()
and printf() to read from the
keyboard and write to the display. But the truth is, they don’t talk
directly to the keyboard and display. Instead, they
use the Standard Input and Standard
Output. The Standard Input and
Standard Output are created by the operating system
when the program runs.
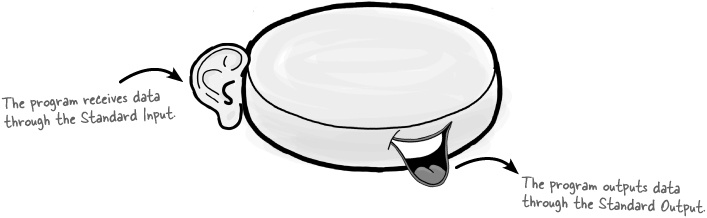
The operating system controls how data gets into and out of the Standard Input and Output. If you run a program from the command prompt or terminal, the operating system will send all of the keystrokes from the keyboard into the Standard Input. If the operating system reads any data from the Standard Output, by default it will send that data to the display.
The scanf() and printf() functions don’t know, or care, where
the data comes from or goes to. They just read and write Standard Input
and the Standard Output.
Now this might sound like it’s kind of complicated. After all, why not just have your program talk directly to the keyboard and screen? Wouldn’t that be simpler?
Well, there’s a very good reason why operating systems communicate with programs using the Standard Input and the Standard Output:
You can redirect the Standard Input and Standard Output so that they read and write data somewhere else, such as to and from files.
You can redirect the Standard Input with <...
Instead of entering data at the keyboard, you can use the
< operator to read the data from a
file.

The < operator tells the
operating system that the Standard Input of the program should be
connected to the gpsdata.csv file instead of the
keyboard. So you can send the program data from a file. Now you just
need to redirect its output.
...and redirect the Standard Output with >
To redirect the Standard Output to a file, you need to use
the > operator:
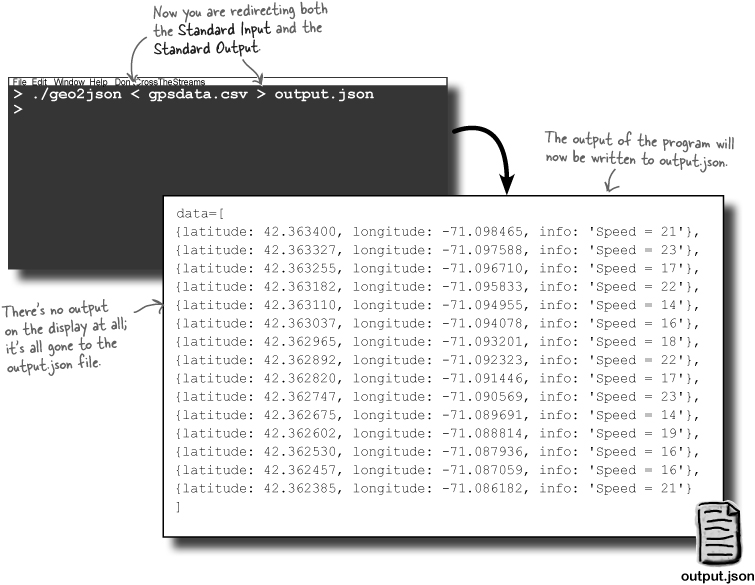
Because you’ve redirected the Standard Output, you don’t see any data appearing on the screen at all. But the program has now created a file called output.json.
The output.json file is the one you needed to create for the mapping application. Let’s see if it works.
Now it’s time to see if the new data file you’ve created can be used to plot the location data on a map. You’ll take a copy of the web page containing the mapping program and put it into the same folder as the output.json file. Then you need to open the web page in a browser:

The map works.
The map inside the web page is able to read the data from the output file.
Do this!
Download the web page from https://github.com/dogriffiths/HeadFirstC. |


But there’s a problem with some of the data...
Your program seems to be able to read GPS data and format it correctly for the mapping application. But after a few days, a problem creeps in.

So what happened here? The problem is that there was some bad data in the GPS data file:

But the geo2json program
doesn’t do any checking of the data it reads; it just reformats the
numbers and sends them to the output.
That should be easy to fix. You need to validate the data.
You need to add some code to the geo2json program that will check for bad
latitude and longitude values. You don’t need anything fancy. If a
latitude or longitude falls outside the expected numeric, just display
an error message and exit the program with an error status of
2:

You needed to add some code to the geo2json program to check for bad latitude
and longitude values. If a latitude or longitude falls outside the
expected numeric, just display an error message and exit the program
with an error status of 2:

OK, so you now have the code in place to check that the latitude and longitude are in range. But will it be enough to make our program cope with bad data? Let’s see.
Compile the code and then run the bad data through the program:

Hmmm...that’s odd. You added the error-checking code, but when you run the program, nothing appears to be different. But now no points appear on the map at all. What gives?
Brain Power
Study the code. What do you think happened? Is the code doing what you asked it to? Why weren’t there any error messages? Why did the mapping program think that the entire output.json file was corrupt?
The mapping program is complaining about the output.json file, so let’s open it up and see what’s inside:

Once you open the file, you can see exactly what happened. The program saw that there was a problem with some of the data, and it exited right away. It didn’t process any more data and it did output an error message. Problem is, because you were redirecting the Standard Output into the output.json, that meant you were also redirecting the error message. So the program ended silently, and you never saw what the problem was.
Now, you could have checked the exit status of the program, but you really want to be able to see the error messages.
But how can you still display error messages if you are redirecting the output?
Geek Bits
If your program finds a problem in the data, it exits with a status of 2. But how can you check that error status after the program has finished? Well, it depends on what operating system you’re using. If you’re running on a Mac, Linux, some other kind of Unix machine, or if you’re using Cygwin on a Windows machine, you can display the error status like this:

If you’re using the Command Prompt in Windows, then it’s a little different:

Both commands do the same thing: they display the number returned by the program when it finished.

Introducing the Standard Error
The Standard Output is the default way of outputting data from a program. But what if something exceptional happens, like an error? You’ll probably want to deal with things like error messages a little differently from the usual output.
That’s why the Standard Error was invented. The Standard Error is a second output that was created for sending error messages.
Human beings generally have two ears and one mouth, but processes are wired a little differently. Every process has one ear (the Standard Input) and two mouths (the Standard Output and the Standard Error).
Human
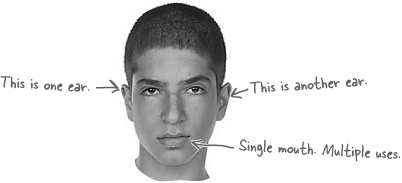
Process

Let’s see how the operating system sets these up.
By default, the Standard Error is sent to the display
Remember how when a new process is created, the operating system points the Standard Input at the keyboard and the Standard Output at the screen? Well, the operating system creates the Standard Error at the same time and, like the Standard Output, the Standard Error is sent to the display by default.

That means that if someone redirects the Standard Input and Standard Output so they use files, the Standard Error will continue to send data to the display.

And that’s really cool, because it means that even if the Standard Output is redirected somewhere else, by default, any messages sent down the Standard Error will still be visible on the screen.
So you can fix the problem of our hidden error messages by simply displaying them on the Standard Error.
But how do you do that?
fprintf() prints to a data stream
You’ve already seen that the printf() function sends data to the Standard
Output. What you didn’t know is that the printf() function is just a version of a more
general function called fprintf():

The fprintf() function allows
you to choose where you want to send text to. You can tell fprintf() to send text to stdout (the
Standard Output) or stderr (the Standard Error).
Let’s update the code to use fprintf()
With just a couple of small changes, you can get our error messages printing on the Standard Error.

That means that the code should now work in exactly the same way, except the error messages should appear on the Standard Error instead of the Standard Output.
Let’s run the code and see.
If you recompile the program and then run the corrupted GPS data through it again, this happens.

That’s excellent. This time, even though you are redirecting the Standard Output into the output.json file, the error message is still visible on the screen.
The Standard Error was created with exactly this in mind: to
separate the error messages from the usual output. But remember:
stderr and stdout are both just output streams. And
there’s nothing to prevent you from using them for anything.
Let’s try out your newfound Standard Input and Standard Error skills.
We have reason to believe that the following program has been used in the transmission of secret messages:

We have intercepted a file called secret.txt and a scrap of paper with instructions:

Your mission is to decode the two secret messages. Write your answers below.
Message 1 | Message 2 |
_____________________ | _____________________ |
_____________________ | _____________________ |
_____________________ | _____________________ |
_____________________ | _____________________ |
_____________________ | _____________________ |
_____________________ | _____________________ |
_____________________ | _____________________ |
We have reason to believe that the following program has been used in the transmission of secret messages:
#include <stdio.h>
int main()
{
char word[10];
int i = 0;
while (scanf("%9s", word) == 1) {
i = i + 1;
if (i % 2)
fprintf(stdout, "%s
", word);
else
fprintf(stderr, "%s
", word);
}
return 0;
}We have intercepted a file called secret.txt and a scrap of paper with instructions:

Your mission was to decode the two secret messages.

Small tools are flexible
One of the great things about small tools is their flexibility. If you write a program that does one thing really well, chances are you will be able to use it in lots of contexts. If you create a program that can search for text inside a file, say, then chances are you’re going to find that program useful in more than one place.
For example, think about your geo2json tool. You created it to help display
cycling data, right? But there’s no reason you can’t use it for some
other purpose...like investigating...the...
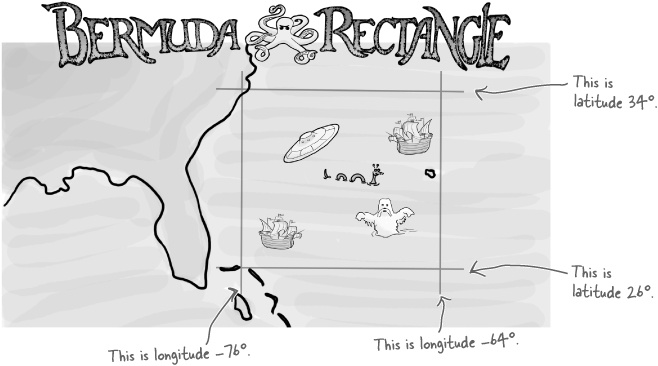
To see how flexible our tool is, let’s use it for a completely different problem. Instead of just displaying data on a map, let’s try to use it for something a little more complex. Say you want to read in a whole set of GPS data like before, but instead of just displaying everything, let’s just display the information that falls inside the Bermuda Rectangle.
That means you will display only data that matches these conditions:
((latitude > 26) && (latitude < 34)) ((longitude > -76) && (longitude < -64))
So where do you need to begin?
Don’t change the geo2json tool
Our geo2json tool
displays all of the data it’s given. So what should we do? Should we
modify geo2json
so that it exports data and also
checks the data?
Well, we could, but remember, a small tool:
does one job and does it well
You don’t really want to modify the geo2json tool, because you want it to do just
one task. If you make the program do something more complex, you’ll
cause problems for your users who expect the tool to keep working in
exactly the same way.

So if you don’t want to change the geo2json tool, what should you do?
A different task needs a different tool
If you want to skip over the data that falls outside the Bermuda Rectangle, you should build a separate tool that does just that.
So, you’ll have two tools: a
new bermuda tool that filters out data
that is outside the Bermuda Rectangle, and then your original geo2json tool that will convert the remaining
data for the map.
This is how you’ll connect the programs together:

By splitting the problem down into two tasks, you will be able to
leave your geo2json untouched. That
will mean that its current users will still be able to use it. The
question is:
How will you connect your two tools together?
Connect your input and output with a pipe
You’ve already seen how to use redirection to connect the
Standard Input and the Standard
Output of a program file. But now you’ll connect the
Standard Output of the bermuda
tool to the Standard Input of the
geo2json, like this:
The | symbol is a pipe that connects the Standard Output of one process to the Standard Input of another process.
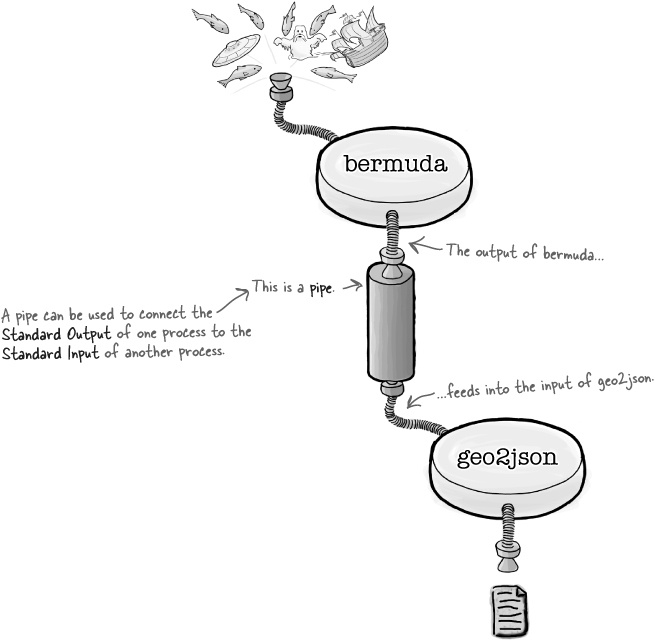
That way, whenever the bermuda
tool sees a piece of data inside the Bermuda Rectangle, it will send the
data to its Standard Output. The pipe will send that data from the
Standard Output of the bermuda tool
to Standard Input of the geo2json
tool.
The operating system will handle the details of exactly how the pipe will do this. All you have to do to get things running is issue a command like this:

So now it’s time to build the bermuda tool.
The bermuda tool
The bermuda tool will work in a
very similar way to the geo2json
tool: it will read through a set of GPS data, line by line, and then
send data to the Standard Output.
But there will be two big differences. First, it won’t send
every piece of data to the Standard Output, just
the lines that are inside the Bermuda Rectangle. The second difference
is that the bermuda tool will always
output data in the same CSV format used to store GPS data.
This is what the pseudocode for the tool looks like:

Let’s turn the pseudocode into C.
Your goal is to complete the
code for the bermuda program. Take
code snippets from the pool and place them into the blank lines below.
You won’t need to use all the snippets of code in the pool.
#include <stdio.h>
int main()
{
float latitude;
float longitude;
char info[80];
while (scanf("%f,%f,%79[^
]",_________, _________, _________) == 3)
if ((_________ >_________) _________ (_________ <_________))
if ((_________ >_________) _________ (_________ <_________))
printf("%f,%f,%s
",_________, _________, _________);
return 0;
}Note: each thing from the pool can be used only once!

Your goal was to complete the
code for the bermuda program by
taking code snippets from the pool and placing them into the blank
lines below.

Note: each thing from the pool can be used only once!
Now that you’ve completed the bermuda tool, it’s time to use it with the
geo2json tool and see if you can
map any weird occurrences inside the Bermuda Rectangle.
Once you’ve compiled both of the tools, you can fire up a console and then run the two programs together like this:

By connecting the two programs together with a pipe, you can treat these two separate programs as if they were a single program, so you can redirect the Standard Input and Standard Output like you did before.

Excellent: the program works!
Do this!
You can download the spooky.csv file at https://github.com/dogriffiths/HeadFirstC. |
But what if you want to output to more than one file?
We’ve looked at how to read data from one file and write to another file using redirection, but what if the program needs to do something a little more complex, like send data to more than one file?
Imagine you need to create another tool that will read a set of data from a file, and then split it into other files.
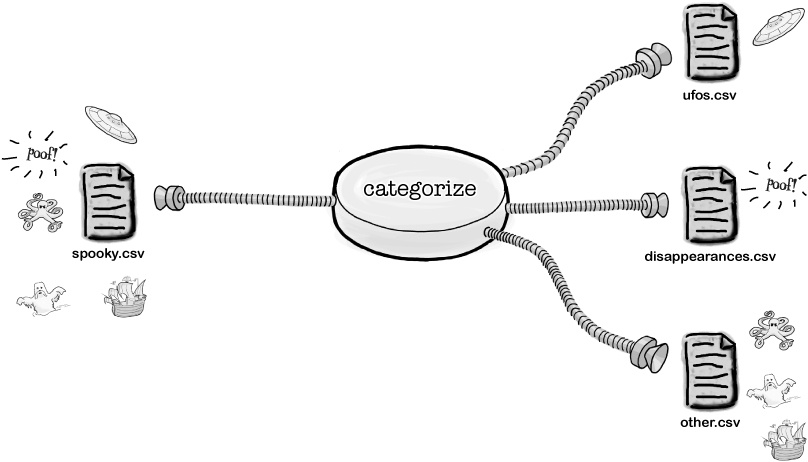
So what’s the problem? You can’t write to files, right? Trouble is, with redirection you can write to only two files at most, one from the Standard Output and one from the Standard Error. So what do you do?
Roll your own data streams
When a program runs, the operating system gives it three file data streams: the Standard Input, the Standard Output, and the Standard Error. But sometimes you need to create other data streams on the fly.

The good news is that the operating system doesn’t limit you to the ones you are dealt when the program starts. You can roll your own as the program runs.
Each data stream is represented by a pointer to a file, and you
can create a new data stream using the fopen() function:

The fopen() function takes
two parameters: a
filename and a mode. The mode
can be w to write to a file, r to read
from a file, or a to append data to the
end of a file.
Once you’ve created a data stream, you can print to it using
fprintf(), just like before. But
what if you need to read from a file? Well, there’s also an fscanf()
function to help you do that too:
The mode is:
“w” = write,
“r” = read, or
“a” = append.
fprintf(out_file, "Don't wear %s with %s", "red", "green"); fscanf(in_file, "%79[^ ] ", sentence);
Finally, when you’re finished with a data stream, you need to close it. The truth is that all data streams are automatically closed when the program ends, but it’s still a good idea to always close the data stream yourself:
fclose(in_file); fclose(out_file);
Let’s try this out now.
This is the code for a program to read all of the data from a GPS file and then write the data into one of three other files. You were to fill in the blanks.

The program runs, but...
If you compile and run the program with:

the program will read the spooky.csv file and split up the data, line by line, into three other files— ufos.csv, disappearances.csv, and other.csv.
That’s great, but what if a user wanted to split up the data differently? What if he wanted to search for different words or write to different files? Could he do that without needing to recompile the program each time?
There’s more to main()
The thing is, any program you write will need to give the
user the ability to change the way it works. If it’s a GUI program, you
will probably need to give it preferences. And if it’s a command-line
program, like our categorize tool, it
will need to give the user the ability to pass it command-line arguments:

Like any array in C, you need some way of knowing how long the
array is. That’s why the main()
function has two parameters. The argc
value is a count of the number of elements in the array.
Command-line arguments really give your program a lot more flexibility, and it’s worth thinking about which things you want your users to tweak at runtime. It will make your program a lot more valuable to them.
OK, let’s see how you can add a little flexibility to the categorize program.
Watch it!
The first argument contains the name of the program as it was run by the user.
That means that the first proper command-line argument is
argv[1].
This is a modified version of the categorize program that can read the
keywords to search for and the files to use from the command line. See
if you can fit the correct magnets into the correct slots.
The program runs using:


This is a modified version of the categorize program that can read the
keywords to search for and the files to use from the command line. You
were to fit the correct magnets into the correct slots.
The program runs using:

OK, let’s try out the new version of the code. You’ll need a test data file called spooky.csv.

Now you’ll need to run the categorize program with a few command-line
arguments saying what text to look for and what filenames to
use:

When the program runs, the following files are produced:


Safety Check
Although at Head First Labs we never make mistakes
(cough), it’s important in real-world programs to check for problems
when you open a file for reading or writing. Fortunately, if there’s a
problem opening a data stream, the fopen() function will return the value 0.
That means if you want to check for errors, you should change code
like:
FILE *in = fopen("i_dont_exist.txt", "r");to this:
FILE *in;
if (!(in = fopen("dont_exist.txt", "r"))) {
fprintf(stderr, "Can't open the file.
");
return 1;
}Overheard at the Head First Pizzeria

Chances are, any program you write is going to need options. If you create a chat program, it’s going to need preferences. If you write a game, the user will want to change the shape of the blood spots. And if you’re writing a command-line tool, you are probably going to need to add command-line options.
Command-line options are the little switches you often see with command-line tools:

Let the library do the work for you
Many programs use command-line options, so there’s a
special library function you can use to make dealing with them a little
easier. It’s called getopt(), and each time you call
it, it returns the next option it finds on the command line.
Let’s see how it works. Imagine you have a program that can take a set of different options:

This program needs one option that will take a value ( -e = engines) and another that is simply
on or off ( -a = awesomeness). You can handle these
options by calling getopt() in a loop
like this:

Inside the loop, you have a switch statement to handle each of the valid
options. The string ae: tells the getopt() function that a and e are
valid options. The e is followed by a
colon to tell getopt() that the
-e needs to be followed by an extra
argument. getopt() will point to that
argument with the optarg variable.
When the loop finishes, you tweak the argv and argc variables to skip past all of the options
and get to the main command-line arguments. That will make your argv array look like this:
The Polite Guide to Standards
The unistd.h header is not actually part of the standard C library. Instead, it gives your programs access to some of the POSIX libraries. POSIX was an attempt to create a common set of functions for use across all popular operating systems.
Watch it!
After processing the arguments, the 0th argument will no longer be the program name.
argv[0] will
instead point to the first command-line argument that follows the
options.
Looks like someone’s been taking a bite out of the pizza code.
See if you can replace the pizza slices and rebuild the order_pizza program.



Looks like someone’s been taking a bite out of the pizza code.
You were to replace the pizza slices and rebuild the order_pizza program.


Now you can try out the pizza-order program:

It works!
Well, you’ve learned a lot in this chapter. You got deep into the Standard Input, Standard Output, and Standard Error. You learned how to talk to files using redirection and your own custom data streams. Finally, you learned how to deal with command-line arguments and options.
A lot of C programmers spend their time creating small tools, and most of the small tools you see in operating systems like Linux are written in C. If you’re careful in how you design them, and if you make sure that you design tools that do one thing and do that one thing well, you’re well on course to becoming a kick-ass C coder.
Your C Toolbox
You’ve got Chapter 3 under your belt, and now you’ve added small tools to your toolbox. For a complete list of tooltips in the book, see Appendix B.
