
![]()
SQL Server 2012 continues the standard for XML integration included with the SQL Server 2008 release. SQL Server 2012 XML still offers tight integration with T-SQL through the xml data type, support for the World Wide Web Consortium (W3C) XQuery and XML Schema recommendations.
SQL Server 2012’s tight XML integration and the xml data type provide streamlined methods of performing several XML-related tasks that used to require clunky code to interface with COM objects and other tools external to the SQL Server engine. This chapter discusses the xml data type and the XML tools built into T-SQL to take advantage of this functionality.
Legacy XML
T-SQL support for XML was introduced with the release of SQL Server 2000 via the FOR XML clause of the SELECT statement, the OPENXML rowset provider, and the sp_xml_preparedocument and sp_xml_removedocument system SPs. In this section, we’ll discuss the legacy OPENXML, sp_xml_preparedocument, and sp_xml_removedocument functionality. Though these tools still exist in SQL Server 2012 and can be used for backward-compatibility scripts, they are awkward and kludgy to use.
OPENXML
OPENXML is a legacy XML function that provides a rowset view of XML data. The process of converting XML data to relational form is known as shredding.OPENXML is technically a rowset provider, which means its contents can be queried and accessed like a table. The legacy SQL Server XML functionality requires the sp_xml_preparedocument and sp_xml_removedocument system SPs to parse text into an XML document and clean up afterward. These procedures are used in conjunction with the OPENXML function to move XML data from its textual representation into a parsed internal representation of an XML document, and from there into a tabular format.
This method is rather clunky compared to the newer methods first introduced by SQL Server 2005, but you might need it if you’re writing code that needs to be backward compatible. The OPENXML method has certain disadvantages based on its heritage, some of which are listed here:
- OPENXML relies on COM to invoke the Microsoft XML Core Services Library (MSXML) to perform XML manipulation and shredding.
- When it is invoked, MSXML assigns one-eighth of SQL Server’s total memory to the task of parsing and manipulating XML data.
- If you fail to call spxmlremovedocument after preparing an XML document with the spxmlpreparedocument procedure, it won’t be removed from memory until the SQL Server service is restarted.
![]() Tip We strongly recommend using xml data type methods like nodes(), value(), and query() to shred your XML data instead of using OPENXML. We’ll discuss these xml data type methods later in this chapter, in the section titled “The XML Data Type Methods.”
Tip We strongly recommend using xml data type methods like nodes(), value(), and query() to shred your XML data instead of using OPENXML. We’ll discuss these xml data type methods later in this chapter, in the section titled “The XML Data Type Methods.”
The sample query in Listing 11-1 is a simple demonstration of using OPENXML to shred XML data. The partial results of this query are shown in Figure 11-1.
Listing 11-1. Simple OPENXML Query
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max) = N' < Customers>
<Customer CustomerID = "1234" ContactName = "Larry" CompanyName = "APress">
<Orders>
<Order CustomerID = "1234" OrderDate = "2006-04-25T13:22:18"/>
<Order CustomerID = "1234" OrderDate = "2006-05-10T12:35:49"/>
</Orders>
</Customer>
<Customer CustomerID = "4567" ContactName = "Bill" CompanyName = "Microsoft">
<Orders>
<Order CustomerID = "4567" OrderDate = "2006-03-12T18:32:39"/>
<Order CustomerID = "4567" OrderDate = "2006-05-11T17:56:12"/>
</Orders>
</Customer>
</Customers > ';
EXECUTE sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
SELECT
Id,
ParentId,
NodeType,
LocalName,
Prefix,
NameSpaceUri,
DataType,
Prev,
[Text]
FROM OPENXML(@docHandle, N'/Customers/Customer'),
EXECUTE sp_xml_removedocument @docHandle;
GO
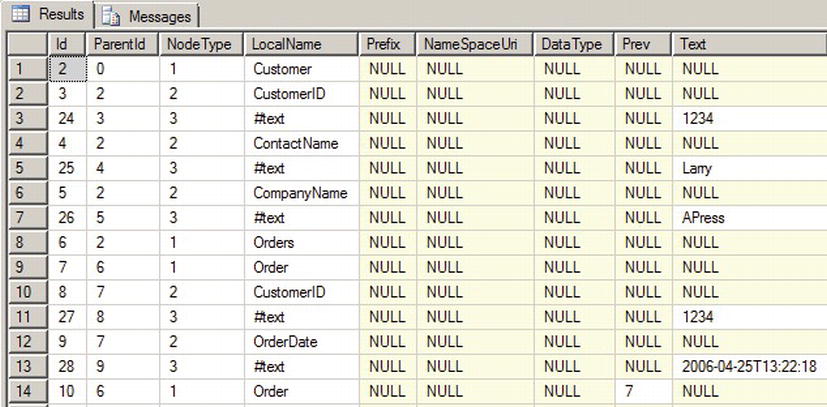
Figure 11-1. Results of the OPENXML Query
The first step in using OPENXML is to call the sp_xml_preparedocument SP to convert an XML-formatted string into an XML document:
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max) = N' < Customers>
<Customer CustomerID = "1234" ContactName = "Larry" CompanyName = "APress">
<Orders>
<Order CustomerID = "1234" OrderDate = "2006-04-25T13:22:18"/>
<Order CustomerID = "1234" OrderDate = "2006-05-10T12:35:49"/>
</Orders>
</Customer>
<Customer CustomerID = "4567" ContactName = "Bill" CompanyName = "Microsoft">
<Orders>
<Order CustomerID = "4567" OrderDate = "2006-03-12T18:32:39"/>
<Order CustomerID = "4567" OrderDate = "2006-05-11T17:56:12"/>
</Orders>
</Customer>
</Customers > ';
EXECUTE sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
The sp_xml_preparedocument procedure invokes MSXML to parse your XML document into an internal Document Object Model (DOM) tree representation of the nodes. The sp_xml_preparedocument procedure accepts up to three parameters, as follows:
- The first parameter, called hdoc, is an output parameter that returns an int handle to the XML document created by the SP.
- The second parameter is the original XML document. This parameter is known as xmltext and can be a char, nchar, varchar, nvarchar, text, ntext, or xml data type. If NULL is passed in or the xmltext parameter is omitted, an empty XML document is created. The default for this parameter is NULL.
- A third optional parameter, xpathnamespaces, specifies the namespace declarations used in OPENXML XPath expressions. Like xmltext, the xpath_namespaces parameter can be a char, nchar, varchar, nvarchar, text, ntext, or xml data type. The default xpath_namespaces value is < root xmlns:mp = "urn:schemas-microsoft-com: xml-metaprop" > .
The OPENXML rowset provider shreds the internal DOM representation of the XML document into relational format. The result of the rowset provider can be queried like a table or view, as shown following:
SELECT
Id,
ParentId,
NodeType,
LocalName,
Prefix,
NameSpaceUri,
DataType,
Prev,
[Text]
FROM OPENXML(@docHandle, N'/Customers/Customer'),
The OPENXML rowset provider accepts up to three parameters:
- The first parameter, hdoc, is the int document handle returned by the call to the sp_xml_preparedocument procedure.
- The second parameter, known as rowpattern, is an nvarchar XPath query pattern that determines which nodes of the XML document are returned as rows.
- The third parameter is an optional flags parameter. This tinyint value specifies the type of mapping to be used between the XML data and the relational rowset. If specified, flags can be a combination of the values listed in Table 11-1.
Table 11-1 . OPENXML Flags Parameter Options
| Value | Name | Description |
|---|---|---|
| 0 | DEFAULT | A flags value of 0 tells OPENXML to default to attribute-centric mapping. This is the default value if the flags parameter is not specified. |
| 1 | XML_ATTRIBUTES | A flags value of 1 indicates that OPENXML should use attribute-centric mapping. |
| 2 | XML_ELEMENTS | A flags value of 2 indicates that OPENXML should use element-centric mapping. |
| 3 | XML_ATTRIBUTES | XML_ELEMENTS | Combining the XML_ATTRIBUTES flag value with the XML_ELEMENTS flag value (logical OR) indicates that attribute-centric mapping should be applied first, and element-centric mapping should be applied to all columns not yet dealt with. |
| 8 | A flags value of 8 indicates that the consumed data should not be copied to the overflow property @mp:xmltext. This value can be combined (logical OR) with any of the other flags values. |
The internal XML document generated by sp_xml_preparedocument is cached and will continue to take up SQL Server memory until it is explicitly removed with the sp_xml_removedocument procedure. The sp_xml_removedocument procedure accepts a single parameter, the int document handle initially generated by sp_xml_preparedocument:
EXECUTE sp_xml_removedocument @docHandle;
![]() Caution Always call sp_xml_removedocument to free up memory used by XML documents created with sp_xml_createdocument. Any XML documents created with sp_xml_createdocument remain in memory until sp_xml_removedocument is called or the SQL Server service is restarted. Microsoft advises that not freeing up memory with sp_xml_removedocument could cause your server to run out of memory.
Caution Always call sp_xml_removedocument to free up memory used by XML documents created with sp_xml_createdocument. Any XML documents created with sp_xml_createdocument remain in memory until sp_xml_removedocument is called or the SQL Server service is restarted. Microsoft advises that not freeing up memory with sp_xml_removedocument could cause your server to run out of memory.
OPENXML Result Formats
The sample in Listing 11-1 returns a table in edge table format, which is the default OPENXML rowset format. According to BOL, “Edge tables represent the fine-grained XML document structure . . . in a single table” (http://msdn2.microsoft.com/en-us/library/ ms186918(SQL.11).aspx). The columns returned by the edge table format are shown in Table 11-2.
Table 11-2. Edge Table Format
| Column Name | Data Type | Description |
|---|---|---|
| id | bigint | The unique ID of the document node. The root element ID is 0. |
| parentid | bigint | The identifier of the parent of the node. If the node is a top-level node, the parentid is NULL. |
| nodetype | int | The column that indicates the type of the node. It can be 1 for an element node, 2 for an attribute node, or 3 for a text node. |
| localname | nvarchar | The local name of the element or attribute, or NULL if the DOM object does not have a name. |
| prefix | nvarchar | The namespace prefix of the node. |
| namespaceuri | nvarchar | The namespace URI of the node, or NULL if there’s no namespace. |
| datatype | nvarchar | The data type of the element or attribute row, which is inferred from the inline DTD or inline schema. |
| prev | bigint | The XML ID of the previous sibling element, or NULL if there is no direct previous sibling. |
| text | ntext | The attribute value or element content. |
OPENXML supports an optional WITH clause to specify a user-defined format for the returned rowset. The WITH clause lets you specify the name of an existing table or a schema declaration to define the rowset format. By adding a WITH clause to the OPENXML query in Listing 11-1, you can specify an explicit schema for the resulting rowset. This technique is demonstrated in Listing 11-2, with results shown in Figure 11-2. The differences between Listings 11-2 and 11-1 are shown in bold.
Listing 11-2. OPENXML and WITH Clause, Explicit Schema
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max) = N' < Customers>
<Customer CustomerID = "1234" ContactName = "Larry" CompanyName = "APress">
<Orders>
<Order CustomerID = "1234" OrderDate = "2006-04-25T13:22:18"/>
<Order CustomerID = "1234" OrderDate = "2006-05-10T12:35:49"/>
</Orders>
</Customer>
<Customer CustomerID = "4567" ContactName = "Bill" CompanyName = "Microsoft">
<Orders>
<Order CustomerID = "4567" OrderDate = "2006-03-12T18:32:39"/>
<Order CustomerID = "4567" OrderDate = "2006-05-11T17:56:12"/>
</Orders>
</Customer>
</Customers > ';
EXECUTE sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
SELECT
CustomerID,
CustomerName,
CompanyName,
OrderDate
FROM OPENXML(@docHandle, N'/Customers/Customer/Orders/Order')
WITH
(
CustomerID nchar(4) N'../../@CustomerID',
CustomerName nvarchar(50) N'../../@ContactName',
CompanyName nvarchar(50) N'../../@CompanyName',
OrderDate datetime
);
EXECUTE sp_xml_removedocument @docHandle;
GO
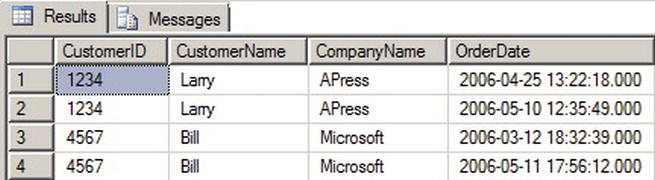
Figure 11-2. Results of OPENXML with an Explicit Schema Declaration
The OPENXML WITH clause can also use the schema from an existing table to format the relational result set. This is demonstrated in Listing 11-3. The differences between Listing 11-3 and 11-2 are shown in bold.
Listing 11-3. OPENXML with WITH Clause, Existing Table Schema
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max) = N' < Customers>
<Customer CustomerID = "1234" ContactName = "Larry" CompanyName = "APress">
<Orders>
<Order CustomerID = "1234" OrderDate = "2006-04-25T13:22:18"/>
<Order CustomerID = "1234" OrderDate = "2006-05-10T12:35:49"/>
</Orders>
</Customer>
<Customer CustomerID = "4567" ContactName = "Bill" CompanyName = "Microsoft">
<Orders>
<Order CustomerID = "4567" OrderDate = "2006-03-12T18:32:39"/>
<Order CustomerID = "4567" OrderDate = "2006-05-11T17:56:12"/>
</Orders>
</Customer>
</Customers > ';
EXECUTE sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
CREATE TABLE #CustomerInfo
(
CustomerID nchar(4) NOT NULL,
ContactName nvarchar(50) NOT NULL,
CompanyName nvarchar(50) NOT NULL
);
CREATE TABLE #OrderInfo
(
CustomerID nchar(4) NOT NULL,
OrderDate datetime NOT NULL
);
INSERT INTO #CustomerInfo
(
CustomerID,
ContactName,
CompanyName
)
SELECT
CustomerID,
ContactName,
CompanyName
FROM OPENXML(@docHandle, N'/Customers/Customer')
WITH #CustomerInfo;
INSERT INTO #OrderInfo
(
CustomerID,
OrderDate
)
SELECT
CustomerID,
OrderDate
FROM OPENXML(@docHandle, N'//Order')
WITH #OrderInfo;
SELECT
c.CustomerID,
c.ContactName,
c.CompanyName,
o.OrderDate
FROM #CustomerInfo c
INNER JOIN #OrderInfo o
ON c.CustomerID = o.CustomerID;
DROP TABLE #OrderInfo;
DROP TABLE #CustomerInfo;
EXECUTE sp_xml_removedocument @docHandle;
GO
The WITH clause used by each OPENXML query in Listing 11-3 specifies a table name. OPENXML uses the table’s schema to define the relational format of the result returned.
FOR XML Clause
SQL Server 2000 introduced the FOR XML clause for use with the SELECT statement to efficiently convert relational data to XML format. The FOR XML clause is highly flexible and provides a wide range of options that give you fine-grained control over your XML result.
The FOR XML clause appears at the end of the SELECT statement and can specify one of five different modes and several mode-specific options. The first FOR XML mode is RAW mode, which returns data in XML format with each row represented as a node with attributes representing the columns. FOR XML RAW is useful for ad hoc FOR XML queries while debugging and testing. The FOR XML RAW clause allows you to specify the element name for each row returned in parentheses immediately following the RAW keyword (if you leave it off, the default name, row, is used). The query in Listing 11-4 demonstrates FOR XML RAW, with results shown in Figure 11-3.
Listing 11-4. Sample FOR XML RAW Query
USE AdventureWorks2012;
GO
SELECT
ProductID,
Name,
ProductNumber
FROM Production.Product
WHERE ProductID IN (770, 903)
FOR XML RAW;

Figure 11-3. Results of the FOR XML RAW Query
The FOR XML clause modes support several additional options to control the resulting output. The options supported by all FOR XML modes are shown in Figure 11-4.

Figure 11-4. FOR XML Clause Options
The options supported by FOR XML RAW mode include the following:
- The TYPE option specifies that the result should be returned as an xml data type instance. This is particularly useful when you use FOR XML in nested subqueries. By default, without the TYPE option, all FOR XML modes return XML data as a character string.
- The ROOT option adds a single top-level root element to the XML result. Using the ROOT option guarantees a well-formed XML (single root element) result.
- The ELEMENTS option specifies that column data should be returned as subelements instead of attributes in the XML result. The ELEMENTS option can have the following additional options:
- XSINIL specifies that columns with SQL nulls are included in the result with an xsi:nil attribute set to true.
- ABSENT specifies that no elements are created for SQL nulls. ABSENT is the default action for handling nulls.
- The BINARY BASE64 option specifies that binary data returned by the query should be represented in Base64-encoded form in the XML result. If your result contains any binary data, the BINARY BASE64 option is required.
- XMLSCHEMA returns an inline XML schema definition (the W3C XML Schema Recommendation is available at www.w3.org/XML/Schema).
- XMLDATA appends an XML-Data Reduced (XDR) schema to the beginning of your XML result. This option is deprecated and should not be used for future development. If you currently use this option, Microsoft recommends changing your code to use the XMLSCHEMA option instead.
As we discuss the other FOR XML modes, we will point out the options supported by each.
For a query against a single table, the AUTO keyword retrieves data in a format similar to RAW mode, but the XML node name is the name of the table and not the generic label row. For queries that join multiple tables, however, each XML element is named for the tables from which the SELECT list columns are retrieved. The order of the column names in the SELECT list determine the XML element nesting in the result. The FOR XML AUTO clause is called similarly to the FOR XML RAW clause, as shown in Listing 11-5. The results are shown in Figure 11-5.
Listing 11-5. FOR XML AUTO Query on a Single Table
USE AdventureWorks2012;
GO
SELECT
ProductID,
Name,
ProductNumber
FROM Production.Product
WHERE ProductID IN (770, 903)
FOR XML AUTO;
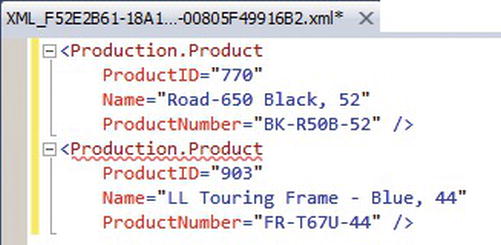
Figure 11-5. Results of the FOR XML AUTO Single-table Query
Listing 11-6 demonstrates using FOR XML AUTO in a SELECT query that joins two tables. The results are shown in Figure 11-6.
Listing 11-6. FOR XML AUTO Query with a Join
SELECT
Product.ProductID,
Product.Name,
Product.ProductNumber,
Inventory.Quantity
FROM Production.Product Product
INNER JOIN Production.ProductInventory Inventory
ON Product.ProductID = Inventory.ProductID
WHERE Product.ProductID IN (770, 3)
FOR XML AUTO;

Figure 11-6. Results of the FOR XML AUTO Query with a Join
The FOR XML AUTO statement can be further refined by adding the ELEMENTS option. Just as with the FOR XML RAW clause, the ELEMENTS option transforms the XML column attributes into subelements, as demonstrated in Listing 11-7, with results shown in Figure 11-7.
Listing 11-7. FOR XML AUTO Query with ELEMENTS Option
SELECT
ProductID,
Name,
ProductNumber
FROM Production.Product
WHERE ProductID = 770
FOR XML AUTO, ELEMENTS;
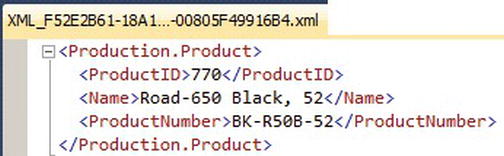
Figure 11-7. Results of the FOR XML AUTO Query with the ELEMENTS Option
The FOR XML AUTO clause can accept almost all of the same options as the FOR XML RAW clause. The only option that you can use with FOR XML RAW that’s not available to FOR XML AUTO is the user-defined ElementName option, since AUTO mode generates row names based on the names of tables in the query.
FOR XML EXPLICIT
The FOR XML EXPLICIT clause is flexible but complex. This clause allows you to specify the exact hierarchy of XML elements and attributes in your XML result. This structure is specified in the SELECT statement itself using a special ElementName!TagNumber!AttributeName!Directive notation.
![]() Tip The FOR XML PATH clause, described in the next section, also allows you to explicitly define your XML result structure. The FOR XML PATH clause accepts XPath-style syntax to define the structure and node names, however, and is much easier to use than FOR XML EXPLICIT. As a general recommendation, we would advise using FOR XML PATH instead of FOR XML EXPLICIT for new development and converting old FOR XML EXPLICIT queries to FOR XML PATH when possible.
Tip The FOR XML PATH clause, described in the next section, also allows you to explicitly define your XML result structure. The FOR XML PATH clause accepts XPath-style syntax to define the structure and node names, however, and is much easier to use than FOR XML EXPLICIT. As a general recommendation, we would advise using FOR XML PATH instead of FOR XML EXPLICIT for new development and converting old FOR XML EXPLICIT queries to FOR XML PATH when possible.
In order to get FOR XML EXPLICIT to convert your relational data to XML format, there’s a strict requirement on the results of the SELECT query—it must return data in universal table format that includes a Tag column defining the level of the current tag and a Parent column with the parent level for the current tag. The remaining columns in the query are the actual data columns. Listing 11-8 demonstrates a FOR XML EXPLICIT query that returns information about a product, including all of its inventory quantities, as a nested XML result. The results are shown in Figure 11-8.
Listing 11-8. FOR XML EXPLICIT Query
SELECT
1 AS Tag,
NULL AS Parent,
ProductID AS [Products!1!ProductID!element],
Name AS [Products!1!ProductName],
ProductNumber AS [Products!1!ProductNumber],
NULL AS [Products!2!Quantity]
FROM Production.Product
WHERE ProductID IN (770, 3)
UNION ALL
SELECT
2 AS Tag,
1 AS Parent,
NULL,
NULL,
NULL,
Quantity
FROM Production.ProductInventory
WHERE ProductID IN (770, 3)
FOR XML EXPLICIT;

Figure 11-8. Results of the FOR XML EXPLICIT Query
The FOR XML EXPLICIT query in Listing 11-8 defines the top-level elements with Tag = 1 and Parent = NULL. The next level is defined with Tag = 2 and Parent = 1, referencing back to the top level. Additional levels can be added by using the UNION keyword with additional queries that increment the Tag and Parent references for each additional level.
Each column of the query must be named with the ElementName!TagNumber!AttributeName!Directive format that we mentioned previously. As specified by this format, ElementName is the name of the XML element, in this case Products.TagNumber is the level of the element, which is 1 for top-level elements. AttributeName is the name of the attribute if you want the data in the column to be returned as an XML attribute. If you want the item to be returned as an XML element, use AttributeName to specify the name of the attribute, and set the Directive value to element. The Directive values that can be specified include the following:
- The hide directive value, which is useful when you want to retrieve values for sorting purposes but do not want the specified node included in the resulting XML.
- The element directive value, which generates an XML element instead of an attribute.
- The elementxsinil directive value, which generates an element for SQL null column values.
- The xml directive value, which generates an element instead of an attribute, but does not encode entity values.
- The cdata directive value, which wraps the data in a CDATA section and does not encode entities.
- The xmltext directive value, which wraps the column content in a single tag integrated with the document.
- The id, idref, and idrefs directive values, which allow you to create internal document links.
The additional options that the FOR XML EXPLICIT clause supports are BINARY BASE64, TYPE, ROOT, and XMLDATA. These options operate the same as they do in the FOR XML RAW and FOR XML AUTO clauses.
FOR XML PATH
The FOR XML PATH clause was first introduced in SQL Server 2005. It provides another way to convert relational data to XML format with a specific structure, but is much easier to use than the FOR XML EXPLICIT clause. Like FOR XML EXPLICIT, the FOR XML PATH clause makes you define the structure of the XML result. But the FOR XML PATH clause allows you to use a subset of the well-documented and much more intuitive XPath syntax to define your XML structure.
The FOR XML PATH clause uses column names to define the structure, as with FOR XML EXPLICIT. In keeping with the XML standard, column names in the SELECT statement with a FOR XML PATH clause are case sensitive. For instance, a column named Inventory is different from a column named INVENTORY. Any columns that do not have names are inlined, with their content inserted as XML content for xml data type columns or as a text node for other data types. This is useful for including the results of nameless computed columns or scalar subqueries in your XML result.
FOR XML PATH uses XPath-style path expressions to define the structure and names of nodes in the XML result. Because path expressions can contain special characters like the forward slash (/) and at sign (@), you will usually want to use quoted column aliases as shown in Listing 11-9. The results of this sample FOR XML PATH query are shown in Figure 11-9.
Listing 11-9. FOR XML PATH Query
SELECT
p.ProductID AS "Product/@ID",
p.Name AS "Product/Name",
p.ProductNumber AS "Product/Number",
i.Quantity AS "Product/Quantity"
FROM Production.Product p
INNER JOIN Production.ProductInventory i
ON p.ProductID = i.ProductID
WHERE p.ProductID = 770
FOR XML PATH;
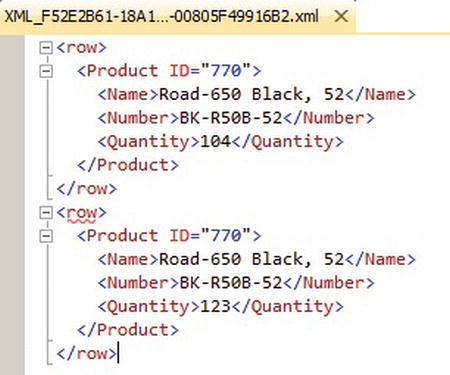
Figure 11-9. Results of the FOR XML PATH Query
The FOR XML PATH clause imposes some rules on column naming, since the column names define not only the names of the XML nodes generated, but also the structure of the XML result. You can also use XPath node tests in your FOR XML PATH clauses. These rules and node tests are summarized in Table 11-3.
Table 11-3. FOR XML PATH Column-naming Conventions
| Column Name | Result |
|---|---|
| text() | The string value of the column is added as a text node. |
| comment() | The string value of the column is added as an XML comment. |
| node() | The string value of the column is inserted inline under the current element. |
| * | This is the same as node(). |
| data() | The string value of the column is inserted as an atomic value. Spaces are inserted between atomic values in the resulting XML. |
| processing-instruction(name) | The string value of the column is inserted as an XML-processing instruction named name. |
| @name | The string value of the column is inserted as an attribute of the current element. |
| Name | The string value of the column is inserted as a subelement of the current element. |
| elem/name | The string value of the column is inserted as a subelement of the specified element hierarchy, under the element specified by elem. |
| elem/@name | The string value of the column is inserted as an attribute of the last element in the specified hierarchy, under the element specified by elem. |
The FOR XML PATH clause supports the BINARY BASE64, TYPE, ROOT, and ELEMENTS options, and the user-defined ElementName options. The additional FOR XML PATH options operate the same as they do for the FOR XML AUTO and FOR XML RAW clauses.
The xml Data Type
SQL Server’s legacy XML functionality can be cumbersome and clunky to use at times. Fortunately, SQL Server 2012 provides much tighter XML integration with its xml data type. The xml data type can be used anywhere that other SQL Server data types are used, including variable declarations, column declarations, SP parameters, and UDF parameters and return types. The T-SQL xml data type provides built-in methods that allow you to query and modify XML nodes. When you declare instances of the xml data type, you can create them as untyped (which is the default), or you can associate them with XML schemas to create typed xml instances. This section discusses both typed and untyped xml in T-SQL.
The xml data type can hold complete XML documents or XML fragments. An XML document must follow all the rules for well-formed XML, including the following:
- Well-formed XML must have at least one element.
- Every well-formed XML document has a single top-level, or root, element.
- Well-formed XML requires properly nested elements (tags cannot overlap).
- All tags must be properly closed in a well-formed XML document.
- Attribute values must be quoted in a well-formed XML document.
- Special characters in element content must be properly entitized, or converted to XML entities such as & for the ampersand character.
An XML fragment must conform to all the rules for well-formed XML, except that it may have more than one top-level element. The stored internal representation of an XML document or fragment stored in an xml variable or column maxes out at around 2.1 GB of storage.
Untyped xml
Untyped xml variables and columns are created by following them with the keyword xml in the declaration, as shown in Listing 11-10.
Listing 11-10. Untyped xml Variable and Column Declarations
DECLARE @x XML;
CREATE TABLE XmlPurchaseOrders
(
PoNum int NOT NULL PRIMARY KEY,
XmlPurchaseOrder xml );
Populating an xml variable or column with an XML document or fragment requires a simple assignment statement. You can implicitly or explicitly convert char, varchar, nchar, nvarchar, varbinary, text, and ntext data to xml. There are some rules to consider when converting from these types to xml:
- The XML parser always treats nvarchar, nchar, and nvarchar(max) data as a two-byte Unicode-encoded XML document or fragment.
- SQL Server treats char, varchar, and nvarchar(max) data as a single-byte-encoded XML document or fragment. The code page of the source string, variable, or column is used for encoding by default.
- The content of varbinary data is passed directly to the XML parser, which accepts it as a stream. If the varbinary XML data is Unicode encoded, the byte-order mark/encoding information must be included in the varbinary data. If no byte-order mark/encoding information is included, the default of UTF-8 is used.
![]() Note The binary data type can also be implicitly or explicitly converted to xml, but it must be the exact length of the data it contains. The extra padding applied to binary variables and columns when the data they contain is too short can cause errors in the XML-parsing process. Use the varbinary data type when you need to convert binary data to XML.
Note The binary data type can also be implicitly or explicitly converted to xml, but it must be the exact length of the data it contains. The extra padding applied to binary variables and columns when the data they contain is too short can cause errors in the XML-parsing process. Use the varbinary data type when you need to convert binary data to XML.
Listing 11-11 demonstrates implicit conversion from nvarchar to the xml data type. The CAST or CONVERT functions can be used when an explicit conversion is needed.
Listing 11-11. Populating an Untyped xml Variable
DECLARE @x xml = N' < ?xml version = "1.0" ?>
<Address>
<Latitude > 47.642737</Latitude>
<Longitude > −122.130395</Longitude>
<Street > ONE MICROSOFT WAY</Street>
<City > REDMOND</City>
<State > WA</State>
<Zip > 98052</Zip>
<Country > US</Country>
</Address > ';
SELECT @x;
Typed xml
To create a typed xml variable or column in SQL Server 2012, you must first create an XML schema collection with the CREATE XML SCHEMA COLLECTION statement. The CREATE XML SCHEMA COLLECTION statement allows you to specify a SQL Server name for your schema collection and an XML schema to add. Listing 11-12 shows how to create an XML schema collection.
Listing 11-12. Creating a Typed xml Variable
CREATE XML SCHEMA COLLECTION AddressSchemaCollection
AS N'<?xml version="1.0" encoding="utf-16" ?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="Address">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="Latitude" type="xsd:decimal" />
<xsd:element name="Longitude" type="xsd:decimal" />
<xsd:element name="Street" type="xsd:string" />
<xsd:element name="City" type="xsd:string" />
<xsd:element name="State" type="xsd:string" />
<xsd:element name="Zip" type="xsd:string" />
<xsd:element name="Country" type="xsd:string" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>';
GO
DECLARE @x XML (CONTENT AddressSchemaCollection);
SELECT @x = N'<?xml version="1.0" ?>
<Address>
<Latitude>47.642737</Latitude>
<Longitude>-122.130395</Longitude>
<Street>ONE MICROSOFT WAY</Street>
<City>REDMOND</City>
<State>WA</State>
<Zip>98052</Zip>
<Country>US</Country>
</Address>';
SELECT @x;
DROP XML SCHEMA COLLECTION AddressSchemaCollection;
GO
The first step in creating a typed xml instance is to create an XML schema collection, as we did in Listing 11-12:
CREATE XML SCHEMA COLLECTION AddressSchemaCollection
AS N' < ?xml version = "1.0" encoding = "utf-16" ?>
<xsd:schema xmlns:xsd = "http://www.w3.org/2001/XMLSchema">
<xsd:element name = "Address">
<xsd:complexType>
<xsd:sequence>
<xsd:element name = "Latitude" type = "xsd:decimal" />
<xsd:element name = "Longitude" type = "xsd:decimal" />
<xsd:element name = "Street" type = "xsd:string" />
<xsd:element name = "City" type = "xsd:string" />
<xsd:element name = "State" type = "xsd:string" />
<xsd:element name = "Zip" type = "xsd:string" />
<xsd:element name = "Country" type = "xsd:string" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema > ';
![]() Tip The World Wide Web Consortium (W3C) maintains the standards related to XML schemas. The official XML Schema recommendations are available at www.w3.org/TR/xmlschema-1/ and www.w3.0rg/TR/xmlschema-2/. These W3C recommendations are an excellent starting point for creating your own XML schemas.
Tip The World Wide Web Consortium (W3C) maintains the standards related to XML schemas. The official XML Schema recommendations are available at www.w3.org/TR/xmlschema-1/ and www.w3.0rg/TR/xmlschema-2/. These W3C recommendations are an excellent starting point for creating your own XML schemas.
The next step is to declare the variable as xml type, but with an XML schema collection specification included:
DECLARE @x XML (CONTENT AddressSchemaCollection);
In the example, we used the CONTENT keyword before the schema collection name in the xml variable declaration. SQL Server offers two keywords, DOCUMENT and CONTENT, that represent facets you can use to constrain typed xml instances. Using the DOCUMENT facet in your typed xml variable or column declaration constrains your typed XML data so that it must contain only one top-level root element. The CONTENT facet allows zero or more top-level elements. CONTENT is the default if neither is specified explicitly.
The next step in the example is the assignment of XML content to the typed xml variable. During the assignment, SQL Server validates the XML content against the XML schema collection.
SELECT @x = N' < ?xml version = "1.0" ?>
<Address>
<Latitude > 47.642737</Latitude>
<Longitude > −122.130395</Longitude>
<Street > ONE MICROSOFT WAY</Street>
<City > REDMOND</City>
<State > WA</State>
<Zip > 98052</Zip>
<Country > US</Country>
</Address > ';
SELECT @x;
The DROP XML SCHEMA COLLECTION statement in the listing removes the XML schema collection from SQL Server.
DROP XML SCHEMA COLLECTION AddressSchemaCollection;
You can also add new XML schemas and XML schema components to XML schema collections with the ALTER XML SCHEMA COLLECTION statement.
The xml data type has several methods for querying and modifying xml data. The built-in xml data type methods are summarized in Table 11-4.
Table 11-4. xml Data Type Methods
| Method | Result |
|---|---|
| query(xquery) | Performs an XQuery query against an xml instance. The result returned is an untyped xml instance. |
| value(xquery, sql_type) | Performs an XQuery query against an xml instance and returns a scalar value of the specified SQL Server data type. |
| exist(xquery) | Performs an XQuery query against an xml instance and returns one of the following bit values: 1 if the xquery expression returns a nonempty result, 0 if the xquery expression returns an empty result, NULL if the xml instance is NULL |
| modify(xml_dml) | Performs an XML Data Modification Language (XML DML) statement to modify an xml instance. |
| nodes(xquery) as table_name(column_name) | Performs an XQuery query against an xml instance and returns matching nodes as an SQL result set. The table_name and column_name specify aliases for the virtual table and column to hold the nodes returned. These aliases are mandatory for the nodes() method. |
This section introduces each of these xml data type methods.
The xml data type query() method accepts an XQuery query string as its only parameter. This method returns all nodes matching the XQuery as a single untyped xml instance. Conveniently enough, Microsoft provides sample typed xml data in the Resume column of the HumanResources.JobCandidate table. Though all of its xml is well formed with a single root element, the Resume column is faceted with the default of CONTENT.
Listing 11-13 shows how to use the query() method to retrieve names from the resumes in the HumanResources.JobCandidate table.
Listing 11-13. Using the Query Method on the HumanResources.JobCandidate Resume XML
SELECT Resume.query(N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
/ns:Resume/ns:Name') AS [NameXML]
FROM HumanResources.JobCandidate;
The first thing to notice is the namespace declaration inside the XQuery query via the declare namespace statement. This is done because the Resume column’s xml data declares a namespace. In fact, the namespace declaration used in the XQuery is exactly the same as the declaration used in the xml data. The declaration section of the XQuery looks like this:
declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
The actual query portion of the XQuery query is a simple path expression:
/ns:Resume/ns:Name
A sample of the results of Listing 11-13 are shown in Figure 11-10 (reformatted for easy reading).

Figure 11-10. Retrieving Job Candidate Names with the Query Method (Partial Results)
![]() Tip SQL Server 2012 implements a subset of the W3C XQuery recommendation. Chapter 12 discusses SQL Server’s XPath and XQuery implementations in detail. If you’re just getting started with XQuery, additional resources include the W3C recommendation available at http://www.w3.org/standards/techs/xquery#w3c_all/, and on BOL at http://msdn.microsoft.com/en-us/library/ms189075.aspx.
Tip SQL Server 2012 implements a subset of the W3C XQuery recommendation. Chapter 12 discusses SQL Server’s XPath and XQuery implementations in detail. If you’re just getting started with XQuery, additional resources include the W3C recommendation available at http://www.w3.org/standards/techs/xquery#w3c_all/, and on BOL at http://msdn.microsoft.com/en-us/library/ms189075.aspx.
The xml data type’s value() method performs an XQuery query against an xml instance and returns a scalar result. The scalar result of value() is automatically cast to the T-SQL data type specified in the call to value(). The sample code in Listing 11-14 uses the value() method to retrieve all last names from AdventureWorks job applicant resumes. The results are shown in Figure 11-11.
Listing 11-14. xml Data Type Value Method Sample
SELECT Resume.value (N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
(/ns:Resume/ns:Name/ns:Name.Last)[1]',
'nvarchar(100)') AS [LastName]
FROM HumanResources.JobCandidate;

Figure 11-11. Using the Value Method to Retrieve Job Candidate Last Names
Like the query() method described previously, the value() method sample XQuery query begins by declaring a namespace:
declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
The actual query portion of the XQuery query is a simple path expression:
(/ns:Resume/ns:Name/ns:Name.Last)[1]
Because value() returns a scalar value, the query is enclosed in parentheses with an XQuery numeric predicate [1] following it to force the return of a singleton atomic value. The second parameter passed into value() is the T-SQL data type that value() will cast the result to, in this case nvarchar. The value() method cannot cast its result to a SQL CLR user-defined type or an xml, image, text, ntext, or sql_variant data type.
The xml data type provides the exist() method for determining if an XML node exists in an xml instance, or if an existing XML node value meets a specific set of criteria. The example in Listing 11-15 uses the exist() method in a query to return all AdventureWorks job candidates that reported a bachelor’s degree level of education. The results are shown in Figure 11-12.
Listing 11-15. xml Data Type Exist Method Example
SELECT Resume.value (N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
(/ns:Resume/ns:Name/ns:Name.Last) [1]',
'nvarchar(100)') AS [BachelorsCandidate]
FROM HumanResources.JobCandidate
WHERE Resume.exist (N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
/ns:Resume/ns:Education/ns:Edu.Level [ . = "Bachelor" ]') = 1;

Figure 11-12. Using the Exist Method to Retrieve Bachelor’s Degree Job Candidates
The first part of the query borrows from the value() method example in Listing 11-13 to retrieve matching job candidate names:
SELECT Resume.value (N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
(/ns:Resume/ns:Name/ns:Name.Last) [1]',
'nvarchar(100)') AS [BachelorsCandidate] FROM HumanResources.JobCandidate
The exist() method in the WHERE clause specifies the xml match criteria. Like the previous sample queries, the exist() method XQuery query begins by declaring a namespace:
declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
The query itself compares the Edu.Level node text to the string Bachelor:
/ns:Resume/ns:Education/ns:Edu.Level [ . = "Bachelor" ]
If there is a match, the query returns a result and the exist() method returns 1. If there is no match, there will be no nodes returned by the XQuery query, and the exist() method will return 0. If the xml is NULL, exist() returns NULL. The query limits the results to only matching resumes by returning only those where exist() returns 1.
The nodes() method of the xml data type retrieves XML content in relational format—a process known as shredding. The nodes() method returns a rowset composed of the xml nodes that match a given XQuery expression. Listing 11-16 retrieves product names and IDs for those products with the word Alloy in the Material node of their CatalogDescription column. The table queried is Production.ProductModel. Notice that the CROSS APPLY operator is used to perform the nodes() method on all rows of the Production.ProductModel table.
Listing 11-16. xml Data Type Nodes Example
SELECT
ProductModelID,
Name,
Specs.query('.') AS Result
FROM Production.ProductModel
CROSS APPLY CatalogDescription.nodes('declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
/ns:ProductDescription/ns:Specifications/Material/text()
[ contains ( . , "Alloy" ) ]')
AS NodeTable(Specs);
The first part of the SELECT query retrieves the product model ID, the product name, and the results of the nodes() method via the query() method:
SELECT
ProductModelId,
Name,
Specs.query('.') AS Result
FROM Production.ProductModel
One restriction of the nodes() method is that the relational results generated cannot be retrieved directly. They can only be accessed via the exist(), nodes(), query(), and value() methods of the xml data type, or checked with the IS NULL and IS NOT NULL operators.
The CROSS APPLY operator is used with the nodes() method to generate the final result set. The XQuery query used in the nodes() method begins by declaring a namespace:
CROSS APPLY CatalogDescription.nodes('declare namespace ns = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
The query portion is a path expression that retrieves XML nodes in which a Material node’s text contains the word Alloy:
/ns:ProductDescription/ns:Specifications/Material/text() [ contains ( . , "Alloy" ) ]')
Notice that the nodes() method requires you to provide aliases for both the virtual table returned and the column that will contain the result rows. In this instance, we chose to alias the virtual table with the name NodeTable and the column with the name Specs.
AS NodeTable(Specs);
The xml data type modify() method can be used to modify the content of an xml variable or column. The modify() method allows you to insert, delete, or update xml content. The main restrictions on the modify() method is that it must be used in a variable SET statement or in the SET clause of an UPDATE statement. The example in Listing 11-17 demonstrates the modify() method on an untyped xml variable. The results are shown in Figure 11-13.
![]() Tip Although the SELECT and SET statements are similar in their functionality when applied to variables, the modify() method of the xml data type will not work in SELECT statements—even SELECT statements that assign values to variables. Use the SET statement as demonstrated in Listing 11-17 to use the modify() method on an xml variable.
Tip Although the SELECT and SET statements are similar in their functionality when applied to variables, the modify() method of the xml data type will not work in SELECT statements—even SELECT statements that assign values to variables. Use the SET statement as demonstrated in Listing 11-17 to use the modify() method on an xml variable.
Listing 11-17. xml Data Type Modify Method Example
DECLARE @x xml = N' < ?xml version = "1.0" ?>
<Address>
<Street > l MICROSOFT WAY</Street>
<City > REDMOND</City>
<State > WA</State>
<Zip > 98052</Zip>
<Country > US</Country>
<Website>http://www.microsoft.com</Website>
</Address > ';
SELECT @x;
SET @x.modify ('insert
(
<CompanyName > Microsoft Corporation</CompanyName>,
<Url>http://msdn.microsoft.com</Url>,
<UrlDescription > Microsoft Developer Network</UrlDescription>
)
into (/Address)[1] '),
SET @x.modify('replace value of
(/Address/Street/text())[1]
with "ONE MICROSOFT WAY"
'),
SET @x.modify('
delete /Address/Website
'),
SELECT @x;

Figure 11-13. Before-and-after Results of the Modify Method
The sample begins by creating an xml variable and assigning XML content to it:
DECLARE @x xml = N' < ?xml version = "1.0" ? > <Address>
<Street > l MICROSOFT WAY</Street>
<City > REDMOND</City>
<State > WA</State>
<Zip > 98052</Zip>
<Country > US</Country>
<Website>http://www.microsoft.com</Website> </Address > ';
SELECT @x;
The XML DML insert statement inserts three new nodes into the xml variable, right below the top-level Address node:
SET @x.modify ('insert
(
<CompanyName > Microsoft Corporation</CompanyName > J
<Url>http://msdn.microsoft.com</Url>,
<UrlDescription > Microsoft Developer's Network</UrlDescription>
)
into (/Address)[1] '),
The replace value of statement specified in the next modify() method updates the content of the Street node with the street address our good friends at Microsoft prefer: ONE MICROSOFT WAY, instead of 1 MICROSOFT WAY.
SET @x.modify('replace value of (/Address/Street/text())[l]
with "ONE MICROSOFT WAY"
'),
Finally, the XML DML method delete statement is used to remove the old <Website> tag from the xml variable’s content:
SET @x.modifyC
delete /Address/Website
'),
SELECT @x;
SQL Server provides XML indexes to increase the efficiency of querying xml data type columns. XML indexes come in two flavors:
- Primary XML index: An XML column can have a single primary XML index declared on it. The primary XML index is different from the standard relational indexes most of us are used to. Rather, it is a persisted preshredded representation of your XML data. Basically, the XML data stored in a column with a primary XML index is converted to relational form and stored in the database. By persisting an xml data type column in relational form, you eliminate the implicit shredding that occurs with every query or manipulation of your XML data. In order to create a primary XML index on a table’s xml column, a clustered index must be in place on the primary key columns for the table.
- Secondary XML index: Secondary XML indexes can also be created on a table’s xml column. Secondary XML indexes are nonclustered relational indexes created on primary XML indexes. In order to create secondary XML indexes on an xml column, a primary XML index must already exist on that column. You can declare any of three different types of secondary XML index on your primary XML indexes:
- The PATH index is a secondary XML index optimized for XPath and XQuery path expressions that rely heavily on path and node values. The PATH index creates an index on path and node values on the columns of the primary XML index. The path and node values are used as key columns for efficient path seek operations.
- The VALUE index is optimized for queries by value where the path is not necessarily known. This type of index is the inverse of the PATH index, with the primary XML index node values indexed before the node paths.
- The PROPERTY index is optimized for queries that retrieve data from other columns of a table based on the value of nodes or paths in the xml data type column. This type of secondary index is created on the primary key of the base table, node paths, and node values of the primary XML index.
Consider the example XQuery FLWOR (for, let, where, order by, return) expression in Listing 11-18 that retrieves the last, first, and middle names of all job applicants in the HumanResources.JobCandidate table with an education level of Bachelor. The results of this query are shown in Figure 11-14.
Listing 11-18. Retrieving Job Candidates with Bachelor’s Degrees
SELECT Resume.query('declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/Resume";
for $m in /ns:Resume
where $m/ns:Education/ns:Edu.Level[. = "Bachelor" ]
return < Name>
{
data(($m/ns:Name/ns:Name.Last)[1]),
data(($m/ns:Name/ns:Name.First)[1]),
data(($m/ns:Name/ns:Name.Middle)[1])
} </Name > ')
FROM HumanResources.JobCandidate;
GO
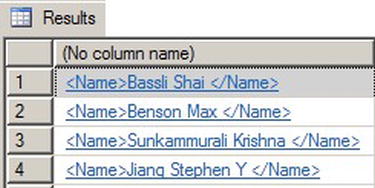
Figure 11-14. Retrieving Candidate Names with a FLWOR Expression
We’ll describe FLWOR expressions in greater detail, with examples, in Chapter 12. For the purposes of this discussion, however, the results are not as important as what’s going on under the hood. This FLWOR expression is returning the last, first, and middle names of all candidates for which the Edu.Level node contains the value Bachelor. As shown in Figure 11-15, the execution cost of this query is 41.2849. Although the subtree cost is an arbitrary number, it represents the total cost in relationship to the batch. In this case the number is large enough in relationship to the batch to warrant investigation.

Figure 11-15. The Execution Cost of the Query
By far the most expensive part of this query is contained in a step called Table Valued Function[XML Reader with XPath Filter]. This is the main operator SQL Server uses to shred XML data on the fly whenever you query XML data. In this query plan, it is invoked two times at a cost of 13.052 each, and three more times at a cost of 4.89054 each, accounting for over 98 percent of the query plan cost (see Figure 11-16).

Figure 11-16. Table Valued Function [XML Reader with XPath Filter] Cost
Adding XML indexes to this column of the HumanResources.JobCandidate table significantly improves XQuery query performance by eliminating on-the-fly XML shredding. Listing 11-19 adds a primary and secondary XML index to the Resume column.
Listing 11-19. Adding XML Indexes to the Resume Column
CREATE PRIMARY XML INDEX PXML_JobCandidate
ON HumanResources.JobCandidate (Resume);
GO
CREATE XML INDEX IXML_Education
ON HumanResources.JobCandidate (Resume)
USING XML INDEX PXML_JobCandidate
FOR PATH;
GO
With the primary and secondary XML indexes in place, the query execution cost drops significantly from 41.2849 to 0.278555, as shown in Figure 11-17.
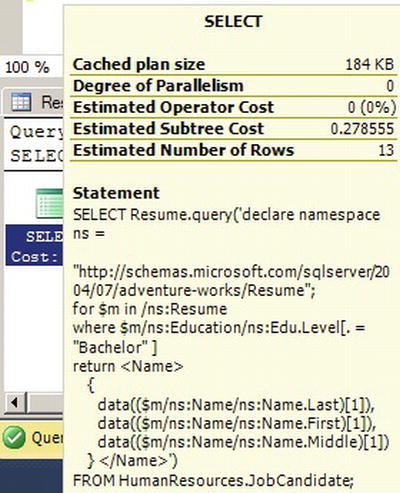
Figure 11-17. The Query Execution Cost with XML Indexes
The greater efficiency is brought about by the XML Reader with XPath Filter step being replaced with efficient index seek operators on both clustered and nonclustered indexes. The primary XML index eliminates the need to shred XML data at query time and the secondary XML index provides additional performance enhancement by providing a nonclustered index that can be used to efficiently fulfill the FLWOR expression where clause.
The CREATE PRIMARY XML INDEX statement in the example creates a primary XML index on the Resume column of the HumanResources.JobCandidate table. The primary XML index provides a significant performance increase by itself, since it eliminates on-the-fly XML shredding at query time.
CREATE PRIMARY XML INDEX PXML_JobCandidate ON HumanResources.JobCandidate (Resume);
The primary XML index is a prerequisite for creating the secondary XML index that will provide additional performance enhancement for XQuery queries that specify both a path and a predicate based on node content. The CREATE XML INDEX statement in the example creates the secondary XML PATH index.
CREATE XML INDEX IXML_Education ON HumanResources.JobCandidate (Resume) USING XML INDEX PXML_JobCandidate FOR PATH;
The USING XML INDEX clause of the CREATE XML INDEX statement specifies the name of the primary XML index on which to build the secondary XML index. The FOR clause determines the type of secondary XML index that will be created. You can specify a VALUE, PATH, or PROPERTY type as described previously.
The optional WITH clause of both of the XML index creation statements allows you to specify a variety of XML index creation options, as shown in Table 11-5.
Table 11-5. XML Index Creation Options
| Option | Description |
|---|---|
| PAD_INDEX | This option specifies whether index padding is on or off. The default is OFF. |
| FILLFACTOR | This option indicates how full the leaf level index pages should be made during XML index creation or rebuild. Values of 0 and 100 are equivalent. The FILLFACTOR option is used in conjunction with the PAD_INDEX option. |
| SORT_IN_TEMPDB | This option specifies that intermediate sort results should be stored in tempdb. By default, SORT_IN_TEMPDB is set to OFF and intermediate sort results are stored in the local database. |
| STATISTICS_NORECOMPUTE | This option indicates whether distribution statistics are automatically recomputed. The default is OFF. |
| DROP_EXISTING | This option specifies that the preexisting XML index of the same name should be dropped before creating the index. The default is OFF. |
| ALLOW_ROW_LOCKS | This option allows SQL Server to use row locks when accessing the XML index. The default is ON. |
| ALLOW_PAGE_LOCKS | This option allows SQL Server to use page locks when accessing the XML index. The default is ON. |
| MAXDOP | This option determines the maximum degree of parallelism SQL Server can use during the XML index creation operation. MAXDOP can be one of the following values: 0: Uses up to the maximum number of processors available. 1: Uses only one processor; no parallel processing. 2 through 64: Restricts the number of processors used for parallel processing to the number specified or less. |
XSL Transformations
One of the powerful features available to SQL Server 2012 is its ability to execute .NET Framework-based code via the SQL Common Language Runtime (SQL CLR). You can use standard .NET Framework classes to access XML-based functionality that is not supported directly within T-SQL. One useful feature that can be accessed via CLR Integration is the W3C Extensible Stylesheet Language Transformations (XSLT). As defined by the W3C, XSLT is a language designed for the sole purpose of “transforming XML documents into other XML documents.” SQL Server 2012 provides access to XSL transformations via a combination of the built-in xml data type and the .NET Framework XslCompiledTransform class.
![]() Tip The XSLT 1.0 standard is available at www.w3.org/TR/xslt.
Tip The XSLT 1.0 standard is available at www.w3.org/TR/xslt.
You can access XSLT from SQL Server to perform server-side transformations of your relational data into other XML formats. I’ve chosen to use XHTML as the output format for this example, although some would argue that generating XHTML output is best done away from SQL Server, in the middle tier or presentation layer. Arguments can also be made for performing XSL transformations close to the data, for efficiency reasons. I’d like to put those arguments aside for the moment, and focus on the main purpose of this example, demonstrating that additional XML functionality is available to SQL Server via SQL CLR. Listing 11-20 demonstrates the first step in the process of performing server-side XSL transformations using FOR XML to convert relational data to an xml variable.
Listing 11-20. Using FOR XML to Convert Relational Data to Populate an xml Variable
DECLARE @xml xml =
(
SELECT
p.ProductNumber AS "@Id",
p.Name AS "Name",
p.Color AS "Color",
p.ListPrice AS "ListPrice",
p.SizeUnitMeasureCode AS "Size/@UOM",
p.Size AS "Size",
p.WeightUnitMeasureCode AS "Weight/@UOM",
p.Weight AS "Weight",
(
SELECT COALESCE(SUM(i.Quantity), 0)
FROM Production.ProductInventory i
WHERE i.ProductID = p.ProductID
) AS "QuantityOnHand"
FROM Production.Product p
WHERE p.FinishedGoodsFlag = 1
ORDER BY p.Name
FOR XML PATH ('Product'),
ROOT ('Products')
);
SELECT @xml;
The resulting xml document looks like Figure 11-18.

Figure 11-18. Partial Results of the FOR XML Product Query
The next step is to create the XSLT style sheet to specify the transformation and assign it to an xml data type variable. Listing 11-21 demonstrates a simple XSLT style sheet to convert XML data to HTML.
Listing 11-21. XSLT Style Sheet to Convert Data to HTML
DECLARE @xslt xml = N' < ?xml version = "1.0" encoding = "utf-16"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/Products">
<html>
<head>
<title > AdventureWorks Product Listing Report</title>
<style type = "text/css">
tr.row-heading {
background-color: 000099;
color: ffffff;
font-family: tahoma, arial, helvetica, sans-serif;
font-size: 12px;
}
tr.row-light {
background-color: ffffff;
font-family: tahoma, arial, helvetica, sans-serif;
font-size: 12px;
}
tr.row-dark {
background-color: 00ffff;
font-family: tahoma, arial, helvetica, sans-serif;
font-size: 12px;
}
td.col-right {
text-align: right;
}
</style>
</head>
<body>
<table>
<tr class = "row-heading">
<th > ID</th>
<th > Product Name</th>
<th > On Hand</th>
<th > List Price</th>
<th > Color</th>
<th > Size</th>
<th > Weight</th>
</tr>
<xsl:for-each select = "Product">
<xsl:element name = "tr">
<xsl:choose>
<xsl:when test = "position() mod 2 = 0">
<xsl:attribute name = "class" > row-light</xsl:attribute>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name = "class" > row-dark</xsl:attribute>
</xsl:otherwise>
</xsl:choose>
<td > <xsl:value-of select = "@Id"/></td>
<td > <xsl:value-of select = "Name"/></td>
<td class = "col-right">
<xsl:value-of select = "QuantityOnHand"/>
</td>
<td class = "col-right" > <xsl:value-of select = "ListPrice"/></td>
<td > <xsl:value-of select = "Color"/></td>
<td class = "col-right"> <xsl:value-of select = "Size"/>
<xsl:value-of select = "Size/@UOM"/>
</td>
<td class = "col-right">
<xsl:value-of select = "Weight"/>
<xsl:value-of select = "Weight/@UOM"/>
</td>
</xsl:element>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet > ';
![]() Tip We won’t dive into the details of XSLT style sheet creation in this book, but information can be found at the official W3C XSLT 1.0 standard site, at http://www.w3.org/TR/xslt20/. The book Pro SQL Server 2008 XML (Apress, 2008) also offers a detailed discussion of XSLT on SQL Server.
Tip We won’t dive into the details of XSLT style sheet creation in this book, but information can be found at the official W3C XSLT 1.0 standard site, at http://www.w3.org/TR/xslt20/. The book Pro SQL Server 2008 XML (Apress, 2008) also offers a detailed discussion of XSLT on SQL Server.
The final step is to create an SQL CLR SP that accepts the raw XML data and the XSLT style sheet, performs the XSL transformation, and writes the results to an HTML file. The SQL CLR SP code is shown in Listing 11-22.
Listing 11-22. SQL CLR SP for XSL Transformations
using System.Data.SqlTypes;
using System.Xml;
using System.Xml.Xsl;
namespace Apress.Samples
{
public partial class XSLT
{
[Microsoft.SqlServer.Server.SqlProcedure]
public static void XmlToHtml
(
SqlXml RawXml,
SqlXml XslStyleSheet,
SqlString OutputPage
)
{
// Create and load the XslCompiledTransform object
XslCompiledTransform xslt = new XslCompiledTransform();
XmlDocument xmldoc1 = new XmlDocument();
xmldocl.LoadXml(XslStyleSheet.Value);
xslt.Load(xmldoc1);
// Create and load the Raw XML document
XmlDocument xml = new XmlDocument();
xml.LoadXml(RawXml.Value);
// Create the XmlTextWriter for output to HTML document
XmlTextWriter htmlout = new XmlTextWriter
(
OutputPage.Value,
System.Text.Encoding.Unicode
);
// Perform the transformation
xslt.Transform
(
xml,
htmlout
);
// Close the XmlTextWriter
htmlout.Close(); }
}
};
SQL CLR SECURITY SETTINGS
There are a few administrative details you need to take care of before you deploy SQL CLR code to SQL Server. The first thing to do is set the database to trustworthy mode with the ALTER DATABASE statement, as shown following:
ALTER DATABASE AdventureWorks2012 SET TRUSTWORTHY ON;
A better alternative to setting your database to trustworthy mode is to sign your assemblies with a certificate. While signing SQL CLR assemblies is beyond the scope of this book, authors Robin Dewson and Julian Skinner cover this topic in their book Pro SQL Server 2005 Assemblies (Apress, 2005). The book covers SQL 2005 but the topics are still relevant and applicable to SQL Server 2012.
For the example in Listing 11-22, which accesses the local file system, you also need to set the CLR assembly permission level to External. You can do this through Visual Studio, as shown in the following illustration, or you can use WITH PERMISSION_SET clause of the CREATE ASSEMBLY or ALTER ASSEMBLY statements in T-SQL.
For SQL CLR code that doesn’t require access to external resources or unmanaged code, a permission level of Safe is adequate. For SQL CLR assemblies that need access to external resources like hard drives or network resources, External permissions are the minimum required. Unsafe permissions are required for assemblies that access unsafe or unmanaged code. Always assign the minimum required permissions when deploying SQL CLR assemblies to SQL Server.
Finally, make sure the SQL Server service account has permissions to any required external resources. For this example, the service account needs permissions to write to the c:Documents and Settings All UsersDocuments directory.
After you have deployed the SQL CLR assembly to SQL Server and set the appropriate permissions, you can call the XmlToHtml procedure to perform the XSL transformation, as shown in Listing 11-23. The resulting HTML file is shown in Figure 11-19.
Listing 11-23. Performing a SQL CLR XSL Transformation
EXECUTE XmlToHtml @xml,
gxslt,
'c:Documents and SettingsXAll UsersDocumentsadventureworks-inventory.html';

Figure 11-19. Results of the XML-to-HTML Transformation
Summary
In this chapter, we discussed SQL Server 2012’s integrated XML functionality. We began with a discussion of legacy XML functionality carried forward, and in some cases improved upon, from the days of SQL Server 2005. This legacy functionality includes the flexible FOR XML clause and the OPENXML rowset provider.
We then discussed the powerful xml data type and its many methods:
- The query() method allows you to retrieve XML nodes using XQuery queries.
- The value() method lets you retrieve singleton atomic values using XQuery path expressions to locate nodes.
- The exist() method determines whether a specific node exists in your XML data.
- The modify() method allows you to use XML DML to modify your XML data directly.
- The nodes() method makes shredding XML data simple.
We also presented SQL Server’s primary and secondary XML indexes, which are designed to optimize XML query performance. Finally, we touched on SQL Server’s SQL CLR integration and demonstrated how to use it to access .NET Framework XML functionality not directly available through the T-SQL language.
In the next chapter, we will continue the discussion of SQL Server XML by introducing XPath and XQuery support, including a more detailed discussion of the options, functions, operators, and expressions available for querying and manipulating XML on SQL Server.
EXERCISES
- [Choose all that apply] SQL Server’s FOR XML clause supports which of the following modes:
- a. FOR XML RAW
- b. FOR XML PATH
- c. FOR XML AUTO
- d. FOR XML EXPLICIT
- e. FOR XML RECURSIVE
- [Fill in the blank] By default, the OPENXML rowset provider returns data in ____________ table format.
- [True/False] The xml data type query() method returns its results as an untyped xml data type instance.
- [Choose one] A SQL Server primary XML index performs which of the following functions:
- a. It creates a nonclustered index on your xml data type column or variable.
- b. It creates a clustered index on your xml data type column or variable.
- c. It stores your xml data type columns in a preshredded relational format.
- d. It stores your xml data type columns using an inverse index format.
- [True/False] When you perform XQuery queries against an xml data type column with no primary XML index defined on it, SQL Server automatically shreds your XML data to relational format.
- [True/False] You can access additional XML functionality on SQL Server through the .NET Framework via SQL Server’s SQL CLR integration.