
Launching Parallel Tasks
It was really difficult to develop applications capable of taking full advantage of multicore microprocessors working with .NET Framework versions prior to .NET Framework 4. It was necessary to launch, control, manage, and synchronize multiple threads using complex structures prepared for some concurrency but not tuned for the modern multicore age.
.NET Framework 4 introduced the new Task Parallel Library (TPL), and .NET Framework 4.5 expanded its capabilities. The TPL was born in the multicore age and is prepared to work with a new lightweight concurrency model. The TPL provides a lightweight framework that enables developers to work with the following parallelism scenarios, implementing task-based designs instead of working with heavyweight and complex threads:
- Data parallelism—There is a lot of data and it is necessary to perform the same operations for each piece—for example, encrypting 100 Unicode strings using the Advanced Encryption Standard (AES) algorithm with a 256-bits key.
- Task parallelism—There are many different operations that can run concurrently, taking advantage of parallelism—for example, generating hash codes for files, encrypting Unicode strings, and creating thumbnail representations of images.
- Pipelining—A mix of task and data parallelism. It is the most complex scenario because it always requires the coordination between multiple concurrent specialized tasks—for example, encrypting 100 Unicode strings using the AES algorithm with a 256-bits key and then generating a hash code for each encrypted string. This pipeline could be implemented running two concurrent tasks, the encryption and the hash code generation. Each encrypted Unicode string would enter into a queue in order to be processed by the hash code generation algorithm.
The easiest way to understand how to work with parallel tasks is by using them. Thus, you can take your first step to creating parallelized code with the methods offered by the System.Threading.Tasks.Parallel static class.
System.Threading.Tasks.Parallel Class
The most important namespace for TPL is System.Threading.Tasks. It offers access to classes, structures, and enumerations introduced in .NET Framework 4, including the System.Threading.Tasks.Parallel static class. Therefore, it is a good idea to import this namespace whenever you want to work with TPL:
Imports System.Threading.Tasks
This way, you will avoid large references. For example, instead of writing System.Threading.Tasks.Parallel.Invoke, you will be able to write Parallel.Invoke. In order to simplify the code, I will assume the aforementioned import is used in all the code snippets. However, remember that you can download the sample code for each code snippet and listing.
The main class is Task, representing an asynchronous and potentially concurrent operation. However, it is not necessary to work directly with instances of Task in order to create parallel code. Sometimes, the best option is to create parallel loops or regions, especially when the code seems to be appropriate for a sequential loop. In these cases, instead of working with the lower-level Task instances, it is possible to work with the methods offered by the Parallel static class (System.Threading.Tasks.Parallel):
- Parallel.For—Offers a load-balanced, potentially parallel execution of a fixed number of independent For loop iterations
- Parallel.ForEach—Offers a load-balanced, potentially parallel execution of a fixed number of independent For Each loop iterations
- Parallel.Invoke—Offers the potentially parallel execution of the provided independent actions
These methods are very useful when refactoring existing code to take advantage of potential parallelism. However, it is very important to understand that it is not as simple as replacing a For statement with Parallel.For. Many techniques to refactor existing loops are covered in detail later in this chapter.
Parallel.Invoke
One of the easiest ways to try to run many methods in parallel is by using the new Invoke method provided by the Parallel class. For example, suppose that you have the following four independent subroutines that perform a format conversion, and you are sure it is safe to run them concurrently:
You can use the following line in order to launch these subroutines, taking advantage of potential parallelism:
Parallel.Invoke(
AddressOf ConvertEllipses,
AddressOf ConvertRectangles,
AddressOf ConvertLines,
AddressOf ConvertText)
In this case, each AddressOf operator creates a function delegate that points to each subroutine. The definition of the Invoke method receives an array of Action (System.Action()) to execute in parallel.
The following code produces the same results using single-line lambda expression syntax for the subroutines to run. Instead of using the aforementioned AddressOf operator, it adds Sub() before each method name.
Parallel.Invoke(
Sub() ConvertEllipses(),
Sub() ConvertRectangles(),
Sub() ConvertLines(),
Sub() ConvertText())
The multiline lambda expression syntax makes it easier to understand the code that runs the four subroutines. The following code uses that syntax to produce the same result (code file: Snippet01.sln):
Parallel.Invoke(Sub()
ConvertEllipses()
' Do something else adding more lines
End Sub,
Sub()
ConvertRectangles()
' Do something else adding more lines
End Sub,
Sub()
ConvertLines()
' Do something else adding more lines
End Sub,
Sub()
ConvertText()
' Do something else adding more lines
End Sub)
Lack of Execution Order
The following explanations apply to any of the previously shown code examples. The Parallel.Invoke method will not return until each of the four subroutines shown earlier has completed. However, completion could occur even with exceptions.
The method will try to start the four subroutines concurrently, taking advantage of the multiple logical cores, also known as hardware threads, offered by one or more physical microprocessors. However, their actual parallel execution depends on many factors. In this case, there are four subroutines. This means that Parallel.Invoke needs at least four logical cores available to be able to run the four methods concurrently.
In addition, having four logical cores doesn't guarantee that the four subroutines are going to start at the same time. The underlying scheduling logic could delay the initial execution of some of the provided subroutines because one or more cores could be too busy. It is indeed very difficult to make accurate predictions about the execution order because the underlying logic will try to create the most appropriate execution plan according to the available resources at runtime.
Figure 19.1 shows three of the possible concurrent execution scenarios that could take place according to different hardware configurations or diverse workloads. It is very important to keep in mind that the same code doesn't require a fixed time to run. Therefore, sometimes, the ConvertText method could take more time than the ConvertLines method, even using the same hardware configuration and input data stream.
Figure 19.1 Three possible parallel executions of four methods launched with Parallel.Invoke

The top diagram represents an almost ideal situation: the four subroutines running in parallel. It is very important to consider the necessary time to schedule the concurrent tasks, which adds an initial overhead to the overall time.
The middle diagram shows a scenario with just two concurrent lanes and four subroutines to run. On one lane, once ConvertEllipses finishes, ConvertRectangles starts. On the other lane, once ConvertLines finishes, ConvertText starts. Parallel.Invoke takes more time than the previous scenario to run all the subroutines.
The bottom diagram shows another scenario with three concurrent lanes. However, it takes almost the same time as the middle scenario, because in this case the ConvertLines subroutine takes more time to run. Thus, Parallel.Invoke takes almost the same time as the previous scenario to run all the subroutines even using one additional parallel lane.
Advantages and Disadvantages
The key advantage of using Parallel.Invoke is its simplicity; you can run many subroutines in parallel without having to worry about tasks or threads. However, it isn't suitable for all the situations in which it is possible to take advantage of parallel execution. Parallel.Invoke has many trade-offs, including the following:
- If you use it to launch subroutines that need very different times to run, it will need the longest time to return control. This could mean that many logical cores stay idle for long periods of time. Therefore, it is very important to measure the results of using this method—that is, the speed gain achieved and the logical core usage.
- If you use it to launch delegates with different running times, it will need the longest time to return.
- It imposes a limit on the parallel scalability, because it calls a fixed number of delegates. In the previous example, if you run it in a computer with 16 logical cores, it will launch only four subroutines in parallel. Therefore, 12 logical cores could remain idle.
- Each call to this method adds an overhead before running the potentially parallel subroutines.
- Like any parallelized code, the existence of interdependencies or uncontrolled interaction between the different subroutines could lead to concurrency bugs that are difficult to detect and unexpected side effects. However, this trade-off applies to any concurrent code; it isn't a problem limited to using Parallel.Invoke.
- As there are no guarantees made about the order in which the subroutines are executed, it isn't suitable for running complex algorithms that require a specific execution plan of concurrent methods.
- Because exceptions could be thrown by any of the delegates launched with different parallel execution plans, the code to catch and handle these exceptions is more complex than the traditional sequential exception handling code.
Parallelism and Concurrency
The previously explained example provides a good transition to the differences between parallelism and concurrency, because they aren't the same thing, as shown in Figure 19.2.
Figure 19.2 Possible scenarios for the execution of four methods in 1, 4, and 2 cores
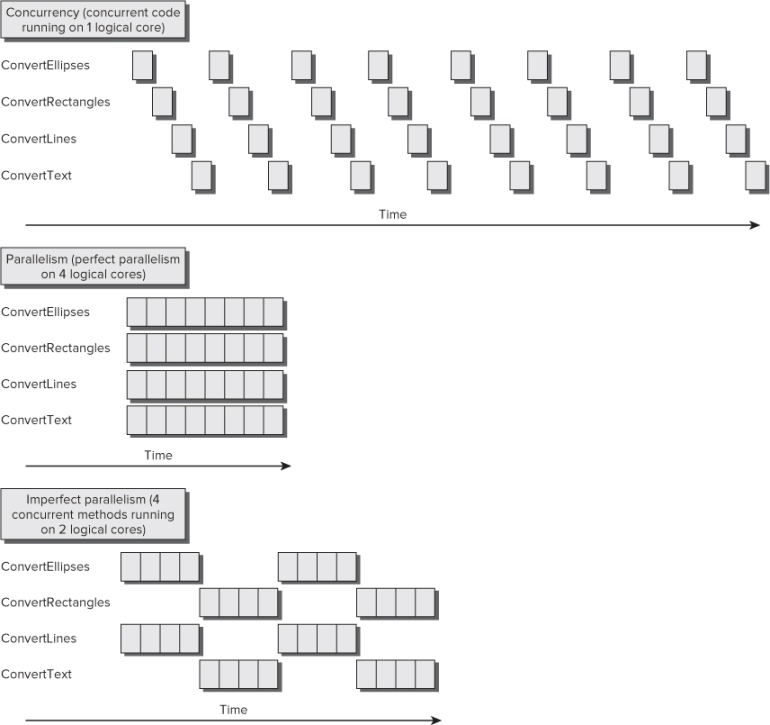
Concurrency means that different parts of code can start, run, and complete in overlapping time periods. Concurrency can happen even on computers with a single logical core. When many parts of code run concurrently on a computer with a single logical core, time-slicing mechanisms and fast context switches can offer the impression of parallel execution. However, on this hardware, it requires more time to run many parts of code concurrently than to run a single part of code alone, because the concurrent code is competing for hardware resources (refer to Figure 19.2). You can think of concurrency as many cars sharing a single lane. This is why concurrency is also defined as a form of virtual parallelism, but it isn't real parallelism.
Parallelism means that different parts of code can actually run simultaneously, i.e., at the same time, taking advantage of real parallel processing capabilities found in the underlying hardware. Parallelism isn't possible on computers with a single logical core. You need at least two logical cores in order to run parallel code. When many parts of code run in parallel on a computer with multiple logical cores, time-slicing mechanisms and context switches also occur because typically many other parts of code are trying to use processor time. However, when real parallelism occurs, you can achieve speed gains because many parts of code running in parallel can reduce the overall necessary time to complete certain algorithms. The diagram shown in Figure 19.2 offers two possible parallelism scenarios: