
Chapter 26
Becoming Adept at Testing
WHAT’S IN THIS CHAPTER?
- What software quality control is and how to track bugs
- What unit testing means and how to use it in practice
- What integration, system and regression testing means
A programmer has overcome a major hurdle in her career when she realizes that testing is a part of the software development process. Bugs are not an occasional occurrence. They are found in every project of significant size. A good quality-assurance (QA) team is invaluable, but the full burden of testing cannot be placed on QA alone. Your responsibility as a programmer is to write code that works and tests to prove its correctness.
A distinction is often made between white box testing, in which the tester is aware of the inner workings of the program, and black box testing, which tests the program’s functionality without concern for its implementation. Both forms of testing are important to professional-quality projects. Black box testing is the most fundamental approach because it typically models the behavior of a user. For example, a black box test can examine interface components like buttons. If the tester clicks the button and nothing happens, there is obviously a bug in the program.
Black box testing cannot cover everything. Modern programs are too large to employ a simulation of clicking every button, providing every kind of input, and performing all combinations of commands. White box testing is necessary because it is easier to ensure test coverage when tests are written at the object or subsystem level. White box tests are often easier to write and automate than black box tests. This chapter focuses on topics that would generally be considered white box testing techniques because the programmer can use these techniques during development.
This chapter begins with a high-level discussion of quality control, including some approaches to viewing and tracking bugs. A section on unit testing, one of the simplest and most useful types of testing, follows this introduction. You will read about the theory and practice of unit testing, as well as several examples of unit tests in action. Next, higher-level tests are covered, including integration tests, system tests, and regression tests. Finally, this chapter ends with a list of tips for successful testing.
Large programming projects are rarely finished when a feature-complete goal is reached. There are always bugs to find and fix, both during and after the main development phase. Understanding the shared responsibility of quality control and the life cycle of a bug is essential to performing well in a group.
Whose Responsibility Is Testing?
Software development organizations have different approaches to testing. In a small startup, there may not be a group of people whose full-time job is testing the product. Testing may be the responsibility of the individual developers, or all the employees of the company may be asked to lend a hand and try to break the product before its release. In larger organizations, a full-time quality assurance staff probably qualifies a release by testing it according to a set of criteria. Nonetheless, some aspects of testing may still be the responsibility of the developers. Even in organizations where the developers have no role in formal testing, you still need to be aware of what your responsibilities are in the larger process of quality assurance.
The Life Cycle of a Bug
All good engineering groups recognize that bugs will occur in software both before and after its release. There are many different ways to deal with these problems. Figure 26-1 shows a formal bug process, expressed as a flow chart. In this particular process, a bug is always filed by a member of the QA team. The bug reporting software sends a notification to the development manager, who sets the priority of the bug and assigns the bug to the appropriate module owner. The module owner can accept the bug or explain why the bug actually belongs in a different module or is invalid, giving the development manager the opportunity to assign it to someone else.

Once the bug has found its rightful owner, a fix is made and the developer marks the bug as “fixed.” At this point, the QA engineer verifies that the bug no longer exists and marks the bug as “closed” or reopens the bug if it is still present.
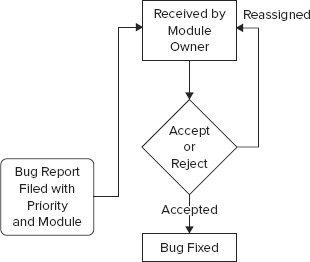
A less formal approach is shown in Figure 26-2. In this workflow, anybody can file a bug and assign an initial priority and a module. The module owner receives the bug report and can either accept it or reassign it to another engineer or module. When a correction is made, the bug is marked as “fixed.” Toward the end of the testing phase, all the implementation and QA engineers divide up the fixed bugs and verify that each bug is no longer present in the current build. The release is ready when all bugs are marked as “closed.”
Bug-Tracking Tools
There are many ways to keep track of software bugs, from informal e-mail- or spreadsheet-based schemes to expensive third-party bug-tracking software. The appropriate solution for your organization depends on the group’s size, the nature of the software, and the level of formality you wish to build around bug fixing.
There are also a number of free open-source bug-tracking solutions available. One of the more popular free tools for bug tracking is Bugzilla, written by the authors of the Mozilla web browser. As an open-source project, Bugzilla has gradually accumulated a number of useful features to the point where it now rivals expensive bug-tracking software packages. Among its many features are:
- Customizable settings for a bug, including its priority, associated component, status, and so on
- E-mail notification of new bug reports or changes to an existing report
- Tracking of dependencies between bugs and resolution of duplicate bugs
- Reporting and searching tools
- A web-based interface for filing and updating bugs
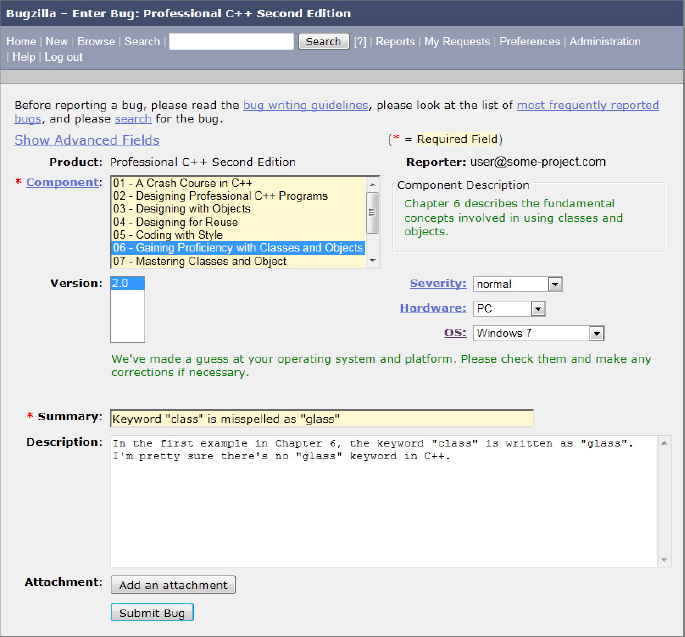
Figure 26-3 shows a bug being entered into a Bugzilla project that was set up for this book. For our purposes, each chapter was input as a Bugzilla component. The filer of the bug can specify the severity of the bug (how big of a deal it is). A summary and description are included to make it possible to search for the bug or list it in a report format.
Bug-tracking tools like Bugzilla are becoming essential components of a professional software development environment. In addition to supplying a central list of currently open bugs, bug-tracking tools provide an important archive of previous bugs and their fixes. A support engineer, for instance, might use Bugzilla to search for a problem similar to one reported by a customer. If a fix was made, the support person will be able to tell the customer which version they need to update to or how to work around the problem.
The only way to find bugs is through testing. One of the most important types of tests from a developer’s point of view is the unit test. Unit tests are pieces of code that exercise specific functionality of a class or subsystem. These are the finest-grained tests that you could possibly write. Ideally, one or more unit tests should exist for every low-level task that your code can perform. For example, imagine that you are writing a math library that can perform addition and multiplication. Your suite of unit tests might contain the following tests:
- Basic test of addition
- Test addition of large numbers
- Test addition of negative numbers
- Test addition of zero to a number
- Test the commutative property of addition
- Basic test of multiplication
- Test multiplication of large numbers
- Test multiplication of negative numbers
- Test multiplication with zero
- Test the commutative property of multiplication
Well-written unit tests protect you in many ways. First, they prove that a piece of functionality actually works. Until you have some code that actually makes use of your class, its behavior is a major unknown. Second, they provide a first alert when a recently introduced change breaks something. This specific usage, called a regression test, is covered later in this chapter. Third, when used as part of the development process, they force the developer to fix problems from the start. If you are prevented from checking in your code with failed unit tests, you’re forced to address problems right away. Fourth, unit tests let you try out code before other code is in place. When you first started programming, you could write a whole program and then run it for the first time. Professional programs are too big for that approach, so you need to be able to test components in isolation. Last, but certainly not least, they provide an example of usage.
Almost as a side effect, unit tests make great reference code for other programmers. If a co-worker wants to know how to perform matrix multiplication by using your math library, you can point her to the appropriate test.
Approaches to Unit Testing
It’s hard to go wrong with unit tests, unless you don’t write them or write them poorly. In general, the more tests you have, the more coverage you have. The more coverage you have, the less likely it is for bugs to fall through the cracks and for you to have to tell your boss, or worse, your customer, “Oh, we never tested that.”
There are several methodologies for writing unit tests most effectively. The Extreme Programming methodology, explained in Chapter 23, instructs its followers to write unit tests before writing code. In theory, writing tests first helps you solidify the requirements for the component and provide a metric that can be used to determine when it is done.
Writing tests first can be tricky and requires diligence on the part of the programmer. For some programmers, it simply doesn’t mesh well with their coding style. A less rigid approach is to design the tests before coding, but implement them later in the process. This way, the programmer is still forced to understand the requirements of the module but doesn’t have to write code that makes use of nonexistent classes.
In some groups, the author of a particular subsystem doesn’t write the unit tests for that subsystem. The theory is that if you write the tests for your own code, you might subconsciously work around problems that you know about, or only cover certain cases that you know your code handles well. In addition, it’s sometimes difficult to get excited about finding bugs in code you just wrote, so you might only put in a half-hearted effort. In practice, having one developer write unit tests for another developer’s code requires a lot of extra overhead and coordination. When such coordination is accomplished, however, this approach helps guarantee more-effective tests.
Another way to ensure that unit tests are actually testing the right parts of the code is to write them so that they maximize code coverage. You can use a code coverage tool, such as gcov, that will tell you what percentage of public methods are called by unit tests. In theory, a properly tested class has unit tests for all of its public methods.
The Unit Testing Process
The process of providing unit tests for your code begins before the code is written. Even if you do not subscribe to the methodology of writing unit tests before you write code, you should take the time to consider what sorts of tests you will provide. This way, you can break the task up into well-defined chunks, each of which has its own test-validated criteria. For example, if your task is to write a database access class, you might first write the functionality that inserts data into the database. Once that is fully tested with a suite of unit tests, you can continue to write the code to support updates, deletes, and selects, testing each piece as you go.
The following list of steps is a suggested approach for designing and implementing unit tests. As with any programming methodology, the best process is the one that yields the best results. We suggest that you experiment with different ways of using unit tests to discover what works best for you.
Define the Granularity of Your Tests
Before you start designing the individual tests, you need to do a reality check. Given the requirements of your component, its complexity, and the amount of time available, what level of unit testing can you provide? In an ideal world, you would write more tests than code to thoroughly validate the functionality of a program (though if it were truly an ideal world, we probably wouldn’t need tests because everything would work). In reality, you are probably already crunched for time, and your initial task is to maximize the effectiveness of unit tests given the constraints placed upon you.
The granularity of tests refers to their scope. As the following table illustrates, you can unit test a database class with just a few test functions, or you can go nuts and really ensure that everything works as it should.
| LARGE-GRAINED TESTS | MEDIUM-GRAINED TESTS | FINE-GRAINED TESTS |
| testConnection() testInsert() testUpdate() testDelete() testSelect() |
[all of the large-grained tests] testConnectionDropped() testInsertBadData() testInsertStrings() testInsertIntegers() testUpdateStrings() testUpdateIntegers() testDeleteNonexistentRow() testSelectComplicated() testSelectMalformed() |
[all large- and medium-grained tests] testConnectionThroughHTTP() testConnectionLocal() testConnectionErrorBadHost() testConnectionErrorServerBusy() testInsertWideCharacters() testInsertLargeData() testInsertMalformed() testUpdateWideCharacters() testUpdateLargeData() testUpdateMalformed() testDeleteWithoutPermissions() testDeleteThenUpdate() testSelectNested() testSelectWideCharacters() testSelectLargeData() |
As you can see, each successive column brings in more-specific tests. As you move from large-grained tests to more finely grained tests, you start to consider error conditions, different input data sets, and different modes of operation.
Of course, the decision you make initially when choosing the granularity of your tests is not set in stone. Perhaps the database class is just being written as a proof-of-concept and might not even be used. A few simple tests may be adequate now, and you can always add more later. Or perhaps the use cases change at a later date. The database class might not initially have been written with international characters in mind. Once such features are added, they should be tested with specific targeted unit tests.
If you plan to revisit or refine the tests at a later date, you should make every effort to actually do so. Consider the unit tests to be part of the actual implementation. When you make a modification, don’t just modify the tests so that they continue to work, write new tests and re-evaluate the existing ones.
Unit tests are part of the subsystem that they are testing. As you enhance and refine the subsystem, enhance and refine the tests.
Brainstorm the Individual Tests
Over time, you will gain an intuition for which aspects of a piece of code should turn into a unit test. Certain methods or inputs just feel like they should be tested. This intuition is gained through trial and error and by looking at unit tests that other people in your group have written. It should be pretty easy to pick out which programmers are the best unit testers. Their tests tend to be organized and frequently modified.
Until unit test creation becomes second nature, approach the task of figuring out which tests to write by brainstorming. To get some ideas flowing, consider the following questions:
1. What are the things that this piece of code was written to do?
2. What are the typical ways each method would be called?
3. What preconditions of the methods could be violated by the caller?
4. How could each method be misused?
5. What kinds of data are you expecting as input?
6. What kinds of data are you not expecting as input?
7. What are the edge cases or exceptional conditions?
You don’t need to write formal answers to those questions (unless your manager is a particularly fervent devotee of this book or of certain testing methodologies), but they should help you generate some ideas for unit tests. The table of tests for the database class contained test functions, each of which arose from one of these questions.
Once you have generated ideas for some of the tests you would like to use, consider how you might organize them into categories, and the breakdown of tests will fall into place. In the database class example, the tests could be split into the following categories:
- Basic tests
- Error tests
- Localization tests
- Bad input tests
- Complicated tests
Splitting your tests into categories makes them easier to identify and augment. It might also make it easier to realize which aspects of the code are well tested and which could use a few more unit tests.
It’s easy to write a massive number of simple tests, but don’t forget about the more complicated cases!
Create Sample Data and Results
The most common trap to fall into when writing unit tests is to match the test to the behavior of the code instead of using the test to validate the code. If you write a unit test that performs a database select for a piece of data that is definitely in the database, and the test fails, is it a problem with the code or a problem with the test? It’s often easier to assume that the code is right and to modify the test to match. This approach is usually wrong.
To avoid this pitfall, you should understand the inputs to the test and the expected output before you try it out. This is sometimes easier said than done. For example, say you wrote some code to encrypt an arbitrary block of text using a particular key. A reasonable unit test would take a fixed string of text and pass it in to the encryption module. Then, it would examine the result to see if it was correctly encrypted.
When you go to write such a test, it is tempting to try out the behavior with the encryption module first and see the result. If it looks reasonable, you might write a test to look for that value. Doing so really doesn’t prove anything, however. You haven’t actually tested the code — you’ve just written a test that guarantees it will continue to return that same value. Often times, writing the test requires some real work — you would need to encrypt the text independently of your encryption module to get an accurate result.
Decide on the correct output for your test before you ever run the test.
Write the Tests
The exact code behind a test will vary depending on what type of test framework you have in place. One framework, cppunit, is discussed later in this chapter. Independent of the actual implementation, however, the following guidelines will help ensure effective tests:
- Make sure that you’re testing only one thing in each test. That way, if a test fails, it will point to a specific piece of functionality.
- Be specific inside the test. Did the test fail because an exception was thrown or because the wrong value was returned?
- Use logging extensively inside of test code. If the test fails some day, you will have some insight into what happened.
- Avoid tests that depend on earlier tests or are otherwise interrelated. Tests should be as atomic and isolated as possible.
- If the test requires the use of other subsystems, consider writing stub versions of those subsystems that simulate the modules’ behavior so that changes in loosely related code don’t cause the test to fail.
- Ask your code reviewers to look at your unit tests as well. When you do a code review, tell the other engineer where you think additional tests could be added.
As you will see later in this chapter, unit tests are usually very small and simple pieces of code. In most cases, writing a single unit test will take only a few minutes, making them one of the most productive uses of your time.
Run the Tests
When you’re done writing a test, you should run it right away before the anticipation of the results becomes too much to bear. The joy of a screen full of passing unit tests shouldn’t be minimized. For most programmers, this is the easiest way to see quantitative data that declare your code useful and correct.
Even if you adopt the methodology of writing tests before writing code, you should still run the tests immediately after they are written. This way, you can prove to yourself that the tests fail initially. Once the code is in place, you have tangible data that shows that it accomplished what it was supposed to accomplish.
It’s unlikely that every test you write will have the expected result the first time. In theory, if you are writing tests before writing code, all of your tests should fail. If one passes, either the code magically appeared or there is a problem with a test. If the code is done and tests still fail (some would say that if the tests fail, the code is actually not done), there are two possibilities. The code could be wrong or the test could be wrong.
Unit Testing in Action
Now that you’ve read about unit testing in theory, it’s time to actually write some tests. The following example draws on the object pool example from Chapter 24. As a brief recap, the object pool is a class that can be used to avoid excessive object creation. By keeping track of already created objects, the pool acts as a broker between code that needs a certain type of object and such objects that already exist.
The public interface for the ObjectPool class is as follows. Note that comments have been removed for brevity; consult Chapter 24 for details on the ObjectPool class:
template <typename T>
class ObjectPool
{
public:
ObjectPool(size_t chunkSize = kDefaultChunkSize)
throw(std::invalid_argument, std::bad_alloc);
shared_ptr<T> acquireObject();
void releaseObject(shared_ptr<T> obj);
// [Private/Protected methods and data omitted.]
};
Code snippet from ObjectPoolTestObjectPool.h
If the notion of an object pool is new to you, you may wish to peruse Chapter 24 before continuing with this example.
Introducing cppunit
cppunit is an open-source unit testing framework for C++ that is based on a Java package called junit. The framework is fairly lightweight (in a good way), and it is very easy to get started. The advantage of using a framework such as cppunit is that it allows the developer to focus on writing tests instead of dealing with setting up tests, building logic around tests, and gathering results. cppunit includes a number of helpful utilities for test developers, and automatic output in various formats. The full breadth of features is not covered here. We suggest you read up on cppunit at http://cppunit.sourceforge.net.
The most common way of using cppunit is to subclass the CppUnit::TestFixture class (note that CppUnit is the namespace and TestFixture is the class). A fixture is a logical group of tests. A TestFixture subclass can override the setUp() method to perform any tasks that need to happen prior to the tests running, as well as the tearDown() method, which can be used to clean up after the tests have run. A fixture can also maintain state with member variables. A skeleton implementation of ObjectPoolTest, a class for testing the ObjectPool class, is shown here:
#include <cppunit/TestFixture.h>
class ObjectPoolTest : public CppUnit::TestFixture
{
public:
void setUp();
void tearDown();
};
Code snippet from ObjectPoolTestObjectPoolTest.h
Because the tests for ObjectPool are relatively simple and isolated, empty definitions will suffice for setUp() and tearDown(). The beginning stage of the source file is shown here:
#include "ObjectPoolTest.h"
void ObjectPoolTest::setUp() { }
void ObjectPoolTest::tearDown() { }
Code snippet from ObjectPoolTestObjectPoolTest.cpp
That’s all the initial code we need to start developing unit tests.
Writing the First Test
Since this may be your first exposure to cppunit, or to unit tests at large, the first test will be a very simple one. It tests whether 0 <1.
An individual unit test in cppunit is just a method of the fixture class. To create a simple test, add its declaration to the ObjectPoolTest.h file:
#include <cppunit/TestFixture.h>
class ObjectPoolTest : public CppUnit::TestFixture
{
public:
void setUp();
void tearDown();
void testSimple(); // Our first test!
};
Code snippet from ObjectPoolTestObjectPoolTest.h
The test definition uses the CPPUNIT_ASSERT macro to perform the actual test. CPPUNIT_ASSERT, like other assert macros you may have used, surrounds an expression that should be true. Chapter 27 explains asserts in more detail. In this case, the test claims that 0 is less than 1, so it surrounds the statement 0 < 1 in a CPPUNIT_ASSERT macro call. This macro is defined in the <cppunit/TestAssert.h> file:
#include "ObjectPoolTest.h" #include <cppunit/TestAssert.h> void ObjectPoolTest::setUp() { } void ObjectPoolTest::tearDown() { } void ObjectPoolTest::testSimple() { CPPUNIT_ASSERT(0 < 1); }
Code snippet from ObjectPoolTestObjectPoolTest.cpp
That’s it. Of course, most of your unit tests will do something a bit more interesting than a simple assert. As you will see, the common pattern is to perform some sort of calculation and assert that the result is the value you expected. With cppunit, you don’t even need to worry about exceptions — the framework will catch and report them as necessary.
Building a Suite of Tests
There are a few more steps before the simple test can be run. cppunit runs a group of tests as a suite. A suite tells cppunit which tests to run, as opposed to a fixture, which groups tests together logically. The common pattern is to give your fixture class a static method that builds a suite containing all of its tests. In the updated versions of ObjectPoolTest.h and ObjectPoolTest.cpp, the suite() method is used for this purpose:
#include <cppunit/TestFixture.h> #include <cppunit/TestSuite.h> #include <cppunit/Test.h> class ObjectPoolTest : public CppUnit::TestFixture { public: void setUp(); void tearDown(); void testSimple(); // Our first test! static CppUnit::Test* suite(); };
Code snippet from ObjectPoolTestObjectPoolTest.h
#include "ObjectPoolTest.h" #include <cppunit/TestAssert.h> #include <cppunit/TestCaller.h> void ObjectPoolTest::setUp() { } void ObjectPoolTest::tearDown() { } void ObjectPoolTest::testSimple() { CPPUNIT_ASSERT(0 < 1); } CppUnit::Test* ObjectPoolTest::suite() { CppUnit::TestSuite* suiteOfTests = new CppUnit::TestSuite("ObjectPoolTest"); suiteOfTests->addTest(new CppUnit::TestCaller<ObjectPoolTest>( "testSimple", &ObjectPoolTest::testSimple)); return suiteOfTests; // Note that Test is a superclass of TestSuite }
Code snippet from ObjectPoolTestObjectPoolTest.cpp
The template syntax for creating a TestCaller is a bit dense, but just about every single test you write will follow this exact pattern, so you can ignore the implementation of TestSuite and TestCaller for the most part.
To actually run the suite of tests and see the results, you will need a test runner. cppunit is a flexible framework. It contains several different runners that operate in different environments, such as the MFC Runner, which is designed to run within a program written with the Microsoft Foundation Classes. For a text-based environment, you should use the Text Runner, which is defined in the CppUnit::TextUi namespace.
The code to run the suite of tests defined by the ObjectPoolTest fixture follows. It creates a runner, adds the tests returned by the suite() method, and calls run().
#include "ObjectPoolTest.h"
#include <cppunit/ui/text/TestRunner.h>
int main()
{
CppUnit::TextUi::TestRunner runner;
runner.addTest(ObjectPoolTest::suite());
runner.run();
return 0;
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
To compile and run these unit tests, you will need to download, build, and install cppunit. Please consult the cppunit documentation on their website for installation instructions specific to your platform. After cppunit is installed, the code can be built. For example, on Linux, this can be done as follows:
> export LD_LIBRARY_PATH=/usr/local/lib
> g++ -I/usr/local/include/cppunit -L/usr/local/lib -lcppunit
-ldl -std=C++0x *.cpp
See Bonus Chapter 2 on the website (www.wrox.com) for more information on the -std=c++0x flag.
This command is for a default cppunit installation on Linux using the GCC compiler. If you are working on another platform or with another compiler, please consult the cppunit website for instructions. After the code is compiled, linked, and run, you should see output similar to the following:
OK (1 tests)
If you modify the code to assert that 1 < 0, the test will fail; cppunit will report the failure as follows:
!!!FAILURES!!! Test Results: Run: 1 Failures: 1 Errors: 0 1) test: testSimple (F) line: 21 ObjectPoolTest.cpp assertion failed - Expression: 1 < 0
Note that by using the CPPUNIT_ASSERT macro, the framework was able to pinpoint the exact line on which the test failed — a useful piece of information for debugging.
Adding the Real Tests
Now that the framework is all set up and a simple test is working, it’s time to turn your attention to the ObjectPool class and write some code that actually tests it. All of the following tests will be added to ObjectPoolTest.h and ObjectPoolTest.cpp, just like the earlier simple test.
Before you can write the tests, you’ll need a helper object to use with the ObjectPool class. The ObjectPool creates chunks of objects of a certain type and hands them out to the caller as requested. Some of the tests will need to check if a retrieved object is the same as a previously retrieved object. One way to do this is to create a pool of serial objects — objects that have a monotonically increasing serial number. The following code defines such a class:
#include <cstddef> // For size_t
class Serial
{
public:
Serial();
size_t getSerialNumber() const;
protected:
static size_t sNextSerial;
size_t mSerialNumber;
};
Code snippet from ObjectPoolTestSerial.h
#include "Serial.h"
Serial::Serial()
{
mSerialNumber = sNextSerial++; // A new object gets the next serial number.
}
size_t Serial::getSerialNumber() const
{
return mSerialNumber;
}
size_t Serial::sNextSerial = 0; // The first serial number is 0.
Code snippet from ObjectPoolTestSerial.cpp
On to the tests! As an initial sanity check, you might want a test that creates an object pool. If any exceptions are thrown during creation, cppunit will report an error:
void ObjectPoolTest::testCreation()
{
ObjectPool<Serial> myPool;
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
The next test is a negative test because it is doing something that should fail. In this case, the test tries to create an object pool with an invalid chunk size of 0. The object pool constructor should throw an exception. Normally, cppunit would catch the exception and report an error. However, since that is the desired behavior, the test catches the exception explicitly and sets a flag. The final step of the test is to assert that the flag was set. Thus, if the constructor does not throw an exception, the test will fail:
void ObjectPoolTest::testInvalidChunkSize()
{
bool caughtException = false;
try {
ObjectPool<Serial> myPool(0);
} catch (const invalid_argument& ex) {
caughtException = true; // OK. We were expecting an exception.
}
CPPUNIT_ASSERT(caughtException);
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
testAcquire() tests a specific piece of public functionality — the ability of the ObjectPool to give out an object. In this case, there is not much to assert. To prove validity of the resulting Serial reference, the test asserts that its serial number is greater than or equal to zero:
void ObjectPoolTest::testAcquire()
{
ObjectPool<Serial> myPool;
shared_ptr<Serial> serial = myPool.acquireObject();
CPPUNIT_ASSERT(serial->getSerialNumber() >= 0);
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
The next test is a bit more interesting. The ObjectPool should not give out the same Serial object twice (unless it is explicitly released). This test checks the exclusivity property of the ObjectPool by creating a pool with a fixed chunk size and retrieving exactly that many objects. If the pool is properly dishing out unique objects, none of their serial numbers should match. Note that this test only covers objects created as part of a single chunk. A similar test for multiple chunks would be an excellent idea.
void ObjectPoolTest::testExclusivity()
{
const size_t poolSize = 5;
ObjectPool<Serial> myPool(poolSize);
set<size_t> seenSerials;
for (size_t i = 0; i < poolSize; i++) {
shared_ptr<Serial> nextSerial = myPool.acquireObject();
// Assert that this number hasn't been seen before.
CPPUNIT_ASSERT(seenSerials.find(nextSerial->getSerialNumber()) ==
seenSerials.end());
// Add this number to the set.
seenSerials.insert(nextSerial->getSerialNumber());
}
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
This implementation uses the set container from the STL. Consult Chapter 12 for details if you are unfamiliar with this container.
The final test (for now) checks the release functionality. Once an object is released, the ObjectPool can give it out again. The pool shouldn’t create additional chunks until it has recycled all released objects. This test first retrieves a Serial from the pool and records its serial number. Then, the object is immediately released back into the pool. Next, objects are retrieved from the pool until either the original object is recycled (identified by its serial number) or the chunk has been used up. If the code gets all the way through the chunk without seeing the recycled object, the test fails.
void ObjectPoolTest::testRelease()
{
const size_t poolSize = 5;
ObjectPool<Serial> myPool(poolSize);
shared_ptr<Serial> originalSerial = myPool.acquireObject();
size_t originalSerialNumber = originalSerial->getSerialNumber();
// Return the original object to the pool.
myPool.releaseObject(originalSerial);
// Now make sure that the original object is recycled before
// a new chunk is created.
bool wasRecycled = false;
for (size_t i = 0; i < poolSize; i++) {
shared_ptr<Serial> nextSerial = myPool.acquireObject();
if (nextSerial->getSerialNumber() == originalSerialNumber) {
wasRecycled = true;
break;
}
}
CPPUNIT_ASSERT(wasRecycled);
}
Code snippet from ObjectPoolTestObjectPoolTest.cpp
Once these tests are added to the suite, you should be able to run them, and they should all pass. Of course, if one or more tests fails, you are presented with the quintessential issue in unit tests — is it the test or the code that is broken?
Basking in the Glorious Light of Unit Test Results
The tests in the previous section should have given you a good idea of how to get started writing actual professional-quality tests for real code. It’s just the tip of the iceberg though. The previous examples should help you think of additional tests that you could write for the ObjectPool class. For example, none of the tests deal with allocation of multiple chunks — there should definitely be coverage of that functionality. There also weren’t complex tests that acquired and released the same object multiple times.
There is no end to the number of unit tests you could write for a given piece of code, and that’s the best thing about unit tests. If you find yourself wondering how your code might react to a certain situation, that’s a unit test. If a particular aspect of your subsystem seems to be presenting problems, increase unit test coverage of that particular area. Even if you simply want to put yourself in the client’s shoes to see what it’s like to work with your class, writing unit tests is a great way to get a different perspective.
While unit tests are the best first line of defense against bugs, they are only part of the larger testing process. Higher-level tests focus on how pieces of the product work together, as opposed to the relatively narrow focus of unit tests. In a way, higher-level tests are more challenging to write because it’s less clear what tests need to be written. Yet, you cannot really claim that the program works until you have tested how its pieces work together.
Integration Tests
An integration test covers areas where components meet. Unlike a unit test, which generally acts on the level of a single class, an integration test usually involves two or more classes. Integration tests excel at testing interactions between two components, often written by two different programmers. In fact, the process of writing an integration test often reveals important incongruities in designs.
Sample Integration Tests
Since there are no hard-and-fast rules to determine what integration tests you should write, some examples might help you get a sense of when integration tests are useful. The following scenarios depict cases where an integration test is appropriate, but they do not cover every possible case. Just as with unit tests, over time you will refine your intuition for useful integration tests.
An XML-Based File Serializer
Suppose that your project includes a persistence layer that is used to save certain types of objects to disk and to read them back in. The hip way to serialize data is to use the XML format, so a logical breakdown of components might include an XML conversion layer sitting on top of a custom file API. Both of these components can be thoroughly unit tested. The XML layer would have unit tests that ensure that different types of objects are correctly converted to XML and populated from XML. The file API would have tests that read, write, update, and delete files on disk.
When these modules start to work together, integration tests are appropriate. At the very least, you should have an integration test that saves an object to disk through the XML layer, then reads it back in and does a comparison to the original. Because the test covers both modules, it is a basic integration test.
Readers and Writers to a Shared Resource
Imagine a program that contains a data space shared by different components. For example, a stock-trading program might have a queue of buy-and-sell requests. Components related to receiving stock transaction requests would add orders to the queue, and components related to performing stock trades would take data off the queue. You could unit test the heck out of the queue class, but until it is tested with the actual components that will be using it, you really don’t know if any of your assumptions are wrong.
A good integration test would use the stock request components and the stock trade components as clients of the queue class. You would write some sample orders and make sure that they successfully entered and exited the queue through the client components.
Wrapper around a Third-Party Library
Integration tests do not always need to occur at integration points in your own code. Many times, integration tests are written to test the interaction between your code and a third-party library.
For example, you may be using a database connection library to talk to a relational database system. Perhaps you built an object-oriented wrapper around the library that adds support for connection caching or provides a friendlier interface. This is a very important integration point to test because, even though the wrapper probably provides a more useful interface to the database, it introduces possible misuse of the original library.
In other words, writing a wrapper is a good thing, but writing a wrapper that introduces bugs is going to be a disaster.
Methods of Integration Testing
When it comes to actually writing integration tests, there is often a fine line between integration and unit tests. If a unit test is modified so that it touches another component, is it suddenly an integration test? In a way, the answer is moot because a good test is a good test regardless of the type of test. We recommend that you use the concepts of integration and unit testing as two approaches to testing, but avoid getting caught up in labeling the category of every single test.
In terms of implementation, integration tests are often written by using a unit testing framework, further blurring their distinction. As it turns out, unit testing frameworks provide an easy way to write a yes/no test and produce useful results. Whether the test is looking at a single unit of functionality or the intersection of two components hardly makes a difference from the framework’s point of view.
However, for performance and organizational reasons, you may wish to attempt to separate unit tests from integration tests. For example, your group may decide that everybody must run integration tests before checking in new code, but be a bit more lax on running unrelated unit tests. Separating the two types of tests also increases the value of results. If a test failure occurs within the XML class tests, it will be clear that it’s a bug in that class, not in the interaction between that class and the file API.
System Tests
System tests operate at an even higher level than integration tests. These tests examine the program as a whole. System tests often make use of a virtual user that simulates a human being working with the program. Of course, the virtual user must be programmed with a script of actions to perform. Other system tests rely on scripts or a fixed set of inputs and expected outputs.
Much like unit and integration tests, an individual system test performs a specific test and expects a specific result. It is not uncommon to use system tests to make sure that different features work in combination with one another.
In theory, a fully system-tested program would contain a test for every permutation of every feature. This approach quickly grows unwieldy, but you should still make an effort to test many features in combination. For example, a graphics program could have a system test that imports an image, rotates it, performs a blur filter, converts it to black and white, and then saves it. The test would compare the saved image to a file that contains the expected result.
Unfortunately, few specific rules can be stated about system tests because they are highly dependent on the actual application. For applications that process files with no user interaction, system tests can be written much like unit and integration tests. For graphical programs, a virtual user approach may be best. For server applications, you might need to build stub clients that simulate network traffic. The important part is that you are actually testing real use of the program, not just a piece of it.
Regression Tests
Regression testing is more of a testing concept than a specific type of test. The idea is that once a feature works, developers tend to put it aside and assume that it will continue to work. Unfortunately, new features and other code changes often conspire to break previously working functionality.
Regression tests are often put in place as a sanity check for features that are, more or less, complete and working. If the regression test is well written, it will cease to pass when a change is introduced that breaks the feature.
If your company has an army of quality-assurance testers, regression testing may take the form of manual testing. The tester acts as a user would and goes through a series of steps, gradually testing every feature that worked in the previous release. This approach is thorough and accurate if carefully performed, but not particularly scalable.
At the other extreme, you could build a completely automated system that performs each function as a virtual user. This would be a scripting challenge, though several commercial and noncommercial packages exist to ease the scripting of various types of applications.
A middle ground is known as smoke testing. Some tests will only test the subset of the most important features that should work. The idea is that if something is broken, it should show up right away. If smoke tests pass, they could be followed by more rigorous manual or automated testing. The term smoke testing was introduced a long time ago, in electronics. After a circuit was built, with different components like vacuum tubes, resistors, etc., the question was, “Is it assembled correctly?” A solution was to “plug it in, turn it on, and see if smoke comes out.” If smoke came out, the design might be wrong, or the assembly might be wrong. By seeing what part went up in smoke, the error could be determined.
Some bugs are like the dream where you show up for school in your underwear — they are both terrifying and recurring. Recurring bugs are frustrating and a poor use of engineering resources. Even if, for some reason, you decide not to write a suite of regression tests, you should still write regression tests for bugs that you fix.
By writing a test for a bug fix, you both prove that the bug is fixed and set up an alert that is triggered if the bug ever comes back (for example, if your change is rolled back or otherwise undone or if two branches are not merged correctly into the main development branch). When a regression test of a previously fixed bug fails, it should be easy to fix because the regression test can refer to the original bug number and describe how it was fixed the first time.
As a software engineer, your role in testing may range anywhere from basic unit testing responsibility to complete management of an automated test system. Because testing roles and styles vary so much, we have assembled several tips from our experiences that may help you in various testing situations:
- Spend some time designing your automated test system. A system that runs constantly throughout the day will detect failures quickly. A system that sends emails to engineers automatically, or sits in the middle of the room loudly playing show tunes when a failure occurs, will result in increased visibility of problems.
- Don’t forget about stress testing. Even though a full suite of unit tests passes for your database access class, it could still fall down when used by several dozen threads simultaneously. You should test your product under the most extreme conditions it could face in the real world.
- Test on a variety of platforms or a platform that closely mirrors the customer’s system. One method of testing on multiple operating systems is to use a virtual machine environment that allows you to run several different operating systems on the same machine.
- Some tests can be written to intentionally inject faults in a system. For example, you could write a test that deletes a file while it is being read, or simulates a network outage during a network operation.
- Bugs and tests are closely related. Bug fixes should be proven by writing regression tests. The comment with a test should refer to the original bug number.
- Don’t remove tests that are failing. When a co-worker is slaving over a bug and finds out you removed tests, he will come looking for you.
The most important tip we can give you is to remember that testing is a part of software development. If you agree with that and accept it before you start coding, it won’t be quite as unexpected when the feature is finished, but there is still more work to do to prove that it works.
This chapter has covered the basic information that all professional programmers should know about testing. Unit testing in particular is the easiest and most effective way to increase the quality of your own code. Higher-level tests provide coverage of use cases, synchronicity between modules, and protection against regressions. No matter what your role is with regard to testing, you should now be able to confidently design, create, and review tests at various levels.
Now that you know how to find bugs, it’s time to learn how to fix them. To that end, Chapter 27 covers techniques and strategies for effective debugging.