
Chapter 11. Troubleshooting Procedures and Best Practices
Even the most well-designed and maintained networks will fail at some point. Such a failure might be as dramatic as a failed server taking down the entire network or as routine as a single computer system being unable to print. Regardless of the problem you face, as a network administrator, you will spend a sizable portion of your time troubleshooting problems with the network, the devices connected to it, and the people who use it. In each case, the approach to the problem is as important as the troubleshooting process. Although some steps are common to the troubleshooting process, few problems you face will be alike because so many variables are involved.
As you see in this chapter, troubleshooting is about more than just fixing a problem: It includes isolating the problem and taking the appropriate actions to prevent it from happening again. The ability to effectively troubleshoot network-related problems goes beyond technical knowledge and includes the ability to think creatively to get to the root of a problem. In addition, strong communication skills can turn a difficult and seemingly impossible troubleshooting task into an easy one. Although the role of the network administrator can be a cellular one, you will be surprised at just how much interaction you’ll have with users and how important this element of your role will be.
This chapter provides a comprehensive look into the many facets that make up an effective troubleshooting strategy. In addition, it examines specific skills and techniques you can use to quickly isolate a network-related problem. It also examines scenarios in which these troubleshooting skills come into play.
Note: Who Says?
Ask 10 network administrators about troubleshooting best practices, and you will no doubt get 15 different answers. There is no universally accepted definition or procedural acceptance of troubleshooting best practices. With this in mind, the information provided in this chapter specifies troubleshooting best practices identified by CompTIA. Whether these are the best practices in real-world application is a matter of debate. However, there is no debate that these are the best practices that will be on the exam.
Foundation Topics: The Art of Troubleshooting
There is no magic or innate ability that makes a good network troubleshooter. You will hear tales of people who have a gift for troubleshooting, but those who can troubleshoot well aren’t necessarily gifted. Instead, good troubleshooters have a special combination of skills. The ability to competently and confidently troubleshoot networks comes from experience, a defined methodology, and sometimes just plain luck.
One of the factors that makes troubleshooting such a difficult task is the large number of variables that can come into play. Although it is difficult to preemptively list all the factors you have to consider while troubleshooting networks, this chapter lists a few to help you start thinking in the right direction. When you are troubleshooting, thinking in the right direction is half the battle. Considering that most network administrators spend the majority of their troubleshooting time working on the devices connected to the network rather than on the network infrastructure, it is worth looking at some of the factors that can affect troubleshooting of devices connected to the network. First, let’s look at the difference between troubleshooting a server and troubleshooting a workstation system.
Troubleshooting Servers and Workstations
One often overlooked but important distinction in troubleshooting networks is the difference between troubleshooting a server computer and troubleshooting a workstation system. Although the fundamental troubleshooting principles of isolation and problem determination are often the same in different networks, the steps taken for problem resolution are often different from one network to another. Make no mistake: When you troubleshoot a server system, the stakes are much higher than with workstation troubleshooting, and therefore it’s considerably more stressful. Let’s take a look at a few of the most important distinctions between workstation and server troubleshooting:
• Pressure—It is difficult to capture in words the pressure you feel when troubleshooting a downed server. Troubleshooting a single workstation with one anxious user is stressful enough, and when tens, hundreds, or even thousands of users are waiting for you to solve the problem, the pressure can be enough to unhinge even the most seasoned administrator.
• Planning—Troubleshooting a single workstation often requires little planning. If work needs to be done on a workstation, it can often be done during a lunch break, after work, or even during the day. If work needs to be done on a server, particularly one that is heavily accessed, you might need to wait days, weeks, or even months before you have a good time to take down the server so that you can work on it and fix the problem.
• Time—For many organizations, every minute a server is unavailable is measured as much in dollars as it is in time. Servers are often relied on to provide 24-hour network service, and anything less is often considered unacceptable. Although it might be necessary to take a server down at some point for troubleshooting, you will be expected to account for every minute that it is down.
• Problem determination—Many people who have had to troubleshoot workstation systems know that finding the problem often involves a little trial and error. (Swap out the RAM; if that doesn’t work, replace the power supply, and so on.) Effective server troubleshooting involves little trial and error—if any at all. Before the server is powered down, the administrator is expected to have a good idea of the problem.
• Expertise—Today, many people feel comfortable taking the case off their personal computers to add memory, replace a fan, or just have a quick peek. Although it is based on the same technologies as PC hardware, server hardware is more complex, and those who manage and maintain servers are expected to have an advanced level of hardware and software knowledge, often reinforced by training and certifications.
These are just a few of the differences in the troubleshooting practices and considerations between servers and workstations. As this chapter discusses troubleshooting, the focus is mainly on the server side of troubleshooting. This helps explain why some of the troubleshooting procedures might seem rigid and unnecessary on a workstation level.
Tip: Workstations and Servers
The Network+ exam does not require you to identify any specific differences between workstation and server troubleshooting, but it does require background knowledge of general troubleshooting procedures and the factors that influence how to approach a network problem.
General Troubleshooting Considerations
Knowing the differences between procedures and approaches for troubleshooting servers and for troubleshooting workstations is valuable, but a seemingly endless number of other considerations exist. Each of these other factors can significantly affect the way you approach a problem on the network. The following list contains some of the obvious and perhaps not so obvious factors that come into play when troubleshooting a network:
• Time—The time of day can play a huge role in the troubleshooting process. For instance, you are likely to respond differently to a network problem at 10 a.m., during high network use, than at 8 p.m., when the network is not being utilized as much. The response to network troubleshooting during high-use periods is often geared toward a Band-Aid solution, just getting things up and running as soon as possible. Finding the exact cause of the problem and developing a permanent fix generally occurs when there is more time.
• Network size—The strategies and processes used to troubleshoot small networks of 10 to 100 computer systems can be different from those used to troubleshoot networks consisting of thousands of computers.
• Support—Some network administrators find themselves working alone, as a single IT professional working for a company. In such cases, the only available sources might include telephone, Internet, or manufacturer support. Other network administrators are part of a large IT department. In that type of environment, the troubleshooting process generally includes a hierarchical consultation process.
• Knowledge of the network—It would be advantageous if uniformity existed in the installation of all networks, but that isn’t the case. You could be working on a network with ring or star topology. Before you start troubleshooting a network, you need to become familiarize with its layout and design. The troubleshooting strategies you employ will be affected by your knowledge of the network.
• Technologies used—Imagine being called in to troubleshoot a wide area network (WAN) that includes multiple Linux servers, a handful of NetWare servers, an old Windows NT 4.0 server, and multiple Macintosh workstations. Your knowledge of these technologies will dictate how, if at all, you are going to troubleshoot the network. There is no shame in walking away from a problem you are unfamiliar with. Good network administrators always recognize their knowledge boundaries.
These are just a few of the factors that will affect your ability to troubleshoot a network. There are countless others.
Troubleshooting Methods and Procedures
At some point in your networking career, you will be called on to troubleshoot network-related problems. Correctly and swiftly identifying these problems is not done by accident; rather, effective troubleshooting requires attention to some specific steps and procedures. Although some organizations have documented troubleshooting procedures for their IT staff members, many do not. Whether you use these exact steps in your job is debatable, but the general principles remain the same. The CompTIA Network+ exam objectives list the troubleshooting steps as follows:
Step 1. Information gathering—identify symptoms and problems.
![]()
Step 2. Identify the affected areas of the network.
Step 3. Determine if anything has changed.
Step 4. Establish the most probable cause.
Step 5. Determine if escalation is necessary.
Step 6. Create an action plan and solution identifying potential effects.
Step 7. Implement and test the solution.
Step 8. Identify the results and effects of the solution.
Step 9. Document the solution and the entire process.
The following sections examine each area of the troubleshooting process.
Step 1: Information Gathering—Identify Symptoms and Problems
Troubleshooting a network can be difficult at the best of times, but trying to do it with limited information makes it that much harder. Trying to troubleshoot a network without all the information can, and often will, cause you to troubleshoot the wrong problem. Without the correct information, you could literally replace a toner cartridge when someone just used the wrong password.
With this in mind, the first step in the troubleshooting process is to establish exactly what the symptoms of the problem are. This stage of the troubleshooting process is all about information gathering. To get this information, you need knowledge of the operating system used, good communication skills, and a little patience. It is important to get as much information as possible about the problem before you charge out the door with that toner cartridge under your arm. You can glean information from three key sources: the computer (in the form of logs and error messages), the computer user experiencing the problem, and your own observation. These sources are examined in the following sections.
Information from the Computer
If you know where to look and what to look for, a computer can help reveal where a problem lies. Many operating systems provide error messages when a problem is encountered. A Linux system, for example, might present a Segmentation Fault error message, which often indicates a memory-related error. Windows, on the other hand, might display an Illegal Operation error message to indicate a possible memory or application failure. Both of these system error messages can be cross-referenced with the operating system’s website information to identify the root of the problem. The information provided in these error messages can at times be cryptic, so finding the solution might be tricky.
In addition to the system-generated error messages, network operating can be configured to generate log files after a hardware or software failure. An administrator can then view these log files to see when the failure occurred and what was being done when the crash occurred. Windows 2000/2003/2008/XP/Vista displays error messages in the Event Viewer; Linux stores many of its system log files in the /var/log directory; and NetWare creates a file called abend.log, which contains detailed information about the state of the system at the time of the crash. When you start the troubleshooting process, make sure that you are familiar enough with the operating system used to determine whether it is trying to give you a message.
Tip: Error Message Storage
For the Network+ exam, you might need to know that the troubleshooting process requires you to read system-generated log errors.
Information from the User
Your communication skills will be most needed when you gather information from end users. Getting accurate information from a computer user or anyone with limited technical knowledge can be difficult. Having a limited understanding of computers and technical terminology can make it difficult for a nontechnical person to relay the true symptoms of a problem. However, users can convey what they are trying to do and what is not working. When you interview an end user, you will likely want the following information:
• Error frequency—If it is a repeating problem, ask for the frequency of the problem. Does the problem occur at regular intervals or sporadically? Does it happen daily, weekly, or monthly?
• Applications in use—You will definitely want to know what applications were in use at the time of the failure. Only the end user will know this information.
• Past problems—Ask whether this error has been a problem in the past. If it has and it was addressed, you might already have your fix.
• User modifications—A new screensaver, game, or other such programs have ways of ending up on users’ systems. Although many of these applications can be installed successfully, sometimes they create problems. When you try to isolate the problem, ask the user whether any new software additions have been made to the system.
• Error messages—Network administrators cannot be at all the computers on a network all the time. Therefore, they are likely to miss an error message when it is displayed onscreen. The end user might tell you what error message appeared.
Note: Installation Policies
Many organizations have strict policies about what can and cannot be installed on computer systems. These policies are not in place to exercise the administrator’s control but rather to prevent as many crashes and failures as possible. Today many harmless-looking freeware and trial programs have Trojan horse or spyware attached. When executed they can cause considerable problems on a system.
Observation Techniques
Finding a problem often involves nothing more than using your eyes, ears, and nose to locate the problem. For instance, if you troubleshoot a workstation system and you see a smoke cloud wafting from the back of the system, looking for error messages might not be necessary. If you walk into a server room and hear the CPU fan grinding, you are unlikely to need to review the server logs to find the problem.
Observation techniques often come into play when you troubleshoot connectivity errors. For instance, looking for an unplugged cable and confirming that the light-emitting diode (LED) on the network interface card (NIC) is lit requires observation on your part. Keeping an eye as well as a nose out for potential problems is part of the network administrator’s role and can help in identifying a situation before it becomes a problem.
Tip: Observation Techniques
For the Network+ exam, remember that observation techniques play a large role in the preemptive troubleshooting process, which can result in finding a small problem before it becomes a large one.
Effective Questioning Techniques
Regardless of the method you use to gather information about a problem, you need answers to some important questions. When approaching a problem, consider the following questions:
• Is only one computer affected, or has the entire network gone down?
• Is the problem happening all the time, or is it intermittent?
• Does the problem happen during specific times, or does it happen all the time?
• Has this problem occurred in the past?
• Has any network equipment been moved recently?
• Have any new applications been installed on the network?
• Has anyone else tried to correct the problem; if so, what has that person tried?
• Is there any documentation that relates to the problem or to the applications or devices associated with the problem?
By answering these questions, as well as others, you can gain a better idea of exactly what the problem is.
Step 2: Identify the Affected Areas of the Network
Some computer problems are isolated to a single user in a single location; others affect several thousand users spanning multiple locations. Establishing the affected area is an important part of the troubleshooting process, and it often dictates the strategies you use in resolving the problem.
Tip: Be Thorough
On the Network+ exam, you might be provided with either a description of a scenario or a description augmented by a network diagram. In either case, you should read the description of the problem carefully, step by step. In most cases, the correct answer is fairly logical, and the wrong answers can be identified easily.
Problems that affect many users are often connectivity issues that disable access for many users. Such problems can often be isolated to wiring closets, network devices, and server rooms. The troubleshooting process for problems isolated to a single user often begins and ends at that user’s workstation. The trail might indeed lead you to the wiring closet or server, but it is not likely that the troubleshooting process would begin there. Understanding who is affected by a problem can provide the first clues about where the problem exists.
As a practical example, assume that you are troubleshooting a client connectivity problem whereby a Windows client is unable to access the network. You can try to ping the server from that system, and, if it fails, ping the same server from one or two more client systems. If all tested client systems cannot ping the server, the troubleshooting procedure will not focus on the clients but more toward something common to all three, such as the DHCP server or network switch.
Step 3: Determine if Anything Has Changed
Whether a problem exists with a workstation’s access to a database or an entire network, keep in mind that they were working at some point. Although many claim that the “computer just stopped working,” it is unlikely. Far more likely is that changes to the system or the network caused the problem. As much as users try to convince you that computers do otherwise, computer systems do not reconfigure themselves. Therefore, establishing what was done to a system can lead you in the right direction to isolate and troubleshoot a problem.
Changes can occur on the network, server, or workstation. Each of these is discussed in the following sections.
Tip: Obvious Solutions
In the Network+ exam, avoid discounting a possible answer because it seems too easy. Many of the troubleshooting questions are based on possible real-world scenarios, many of which do have easy or obvious solutions.
Changes to the Network
Most of today’s networks are dynamic and continually growing to accommodate new users and new applications. Unfortunately, these network changes, although intended to increase network functionality, may inadvertently cause additional problems. For instance, a new computer system added to a network might be installed with a duplicate computer name or IP address, which would prevent another computer that has the same name or address from accessing the network. Other changes that can create problems on the network include adding or removing a hub or switch, changing the network’s routing information, or adding or removing a server. Almost every change that the network administrator makes to the network can potentially have an undesirable impact elsewhere on the network. For this reason, all changes made to the network should be fully documented and fully thought out.
Note: Faulty Hardware
Although recent changes to systems or networks account for many network problems, some problems do happen out of the blue. Faulty hardware is a good example.
Changes to the Server
Part of a network administrator’s job involves some tinkering with the server. Although this might be unavoidable, it can sometimes lead to several unintentional problems. Even the most mundane of all server tasks can have a negative impact on the network. The following are some common server-related tasks that can cause problems:
• Changes to user accounts—For the most part, changes to accounts do not cause any problems, but sometimes they do. If after making changes to user accounts, a user or several users cannot log on to the network or access a database, the problem is likely related to the changes made to the accounts.
• Changes to permissions—Data is protected by permissions that dictate who can and cannot access the data on the drives. Permissions are an important part of system security, but changes to permissions can inadvertently prevent users from accessing specific files.
• Patches and updates—Part of the work involved in administering networks is to monitor new patches and updates for the network operating system and install them as needed. It is not uncommon for an upgrade or a fix to an operating system to cause problems on the network.
• New applications—From time to time, new applications and programs—such as productivity software, firewall software, or even virus software—have to be installed on the server. When any kind of new software is added to the server, it might cause problems on the network. Knowing what has recently been installed can help you isolate a problem.
• Hardware changes—Either because of failure or expansion, hardware on the server might have to be changed. Changes to the hardware configuration on the server can cause connectivity problems.
Changes to the Workstation
The changes made to the systems on the network are not always under the control of the network administrator. Often, the end user performs configuration changes and some software installations. Such changes can be particularly frustrating to troubleshoot, and many users are unaware that the changes they make can cause problems. When looking for changes to a workstation system, consider the following:
• Network settings—One of the configuration hotspots for workstation computer systems are the network settings. If a workstation cannot access the network, it is a good idea to confirm that the network settings have not been changed.
• Printer settings—Many printing problems can be isolated to changes in the printer configuration. Some client systems, such as Linux, are more adept at controlling administrative configuration screens than others; for example, Windows leaves such screens open to anyone who wants to change the configuration. When printing problems are isolated to a single system, changes in the configuration could be the cause.
• New software—Many users love to download and install nifty screensavers or perhaps the latest 3D adventure games on their work computers. The addition of extra software can cause the system to fail. Confirm with the end user that new software has not been added to the system recently.
Note: Duplicate IP Addresses
Consider a system that could previously log on to the network but now receives an error message, stating that it cannot log on because of a duplicate IP address. A duplicate IP address means that two systems on the network are attempting to connect to the network using the same IP address. As you know, there can be only one. This often happens when a new system has been added to a network where Dynamic Host Configuration Protocol (DHCP) is not used.
Step 4: Establish the Most Probable Cause
There can be many different causes for a single problem on a network, but with appropriate information gathering, it is possible to eliminate many of them. When looking for a probable cause, it is often best to look at the easiest solution first and then work from there. Even in the most complex of network designs, the easiest solution is often the right one. For example, if a single user cannot log on to a network, it is best to confirm network settings before replacing the NIC. Remember, though, that at this point you are trying to determine only the most probable cause, and your first guess might be incorrect. It might take a few tries to determine the correct cause of the problem.
Step 5: Determine if Escalation Is Necessary
Sometimes the problems we encounter fall outside the scope of our knowledge. Few organizations expect their administrators to know everything, but organizations do expect administrators to fix any problem, and to do this, additional help is often needed.
Note: Finding Solutions
System administration is often as much about knowing whom and what to refer to in order to get information about a problem as it is about actually fixing the problem.
Technical escalation procedures do not follow a specific set of rules; rather, the procedures to follow vary from organization to organization and situation to situation. Your organization might have an informal arrangement or a formal one requiring documented steps and procedures to be carried out. Whatever the approach, there are general practices that you should follow for appropriate escalation.
Unless otherwise specified by the organization, the general rule is to start with the closest help first and work out from there. If you work in an organization that has an IT team, talk with others in your team; every IT professional has had different experiences, and someone else might know the issue at hand. If you are still struggling with the problem, it is common practice to notify a supervisor or head administrator, especially if the problem is a threat to the server’s data or can bring down the server.
Suppose that you are the server administrator who notices a problem with a hard disk in a RAID 1 array on a Linux server. You know how to replace drives in a failed RAID 1 configuration, but you have no experience working with software RAID on a Linux server. This situation would most certainly require an escalation of the problem. The job of server administrator in this situation is to notice the failed RAID 1 drive and to recruit the appropriate help to repair the RAID failure within Linux.
Note: Passing the Buck
When you’re confronted with a problem, it is yours until it has been solved or until it has been passed to someone else. Of course, the passing on of an issue requires that both parties be aware that it has been passed on.
Step 6: Create an Action Plan and Solution Identifying Potential Effects
After identifying a cause, but before implementing a solution, develop a plan for the solution. This is particularly a concern for server systems in which taking the server offline is a difficult and undesirable prospect. After identifying the cause of a problem on the server, it is absolutely necessary to plan for the solution. The plan must include details around when the server or network should be taken offline and for how long, what support services are in place, and who will be involved in correcting the problem.
Planning is an important part of the whole troubleshooting process and can involve formal or informal written procedures. Those who do not have experience troubleshooting servers might be wondering about all the formality, but this attention to detail ensures the least amount of network or server downtime and the maximum data availability.
As far as workstation troubleshooting is concerned, rarely is a formal planning procedure required, and this makes the process easier. Planning for workstation troubleshooting typically involves arranging a convenient time with end users to implement a solution.
Step 7: Implement and Test the Solution
With the plan in place, you should be ready to implement a solution—that is, apply the patch, replace the hardware, plug in a cable, or implement some other solution. Ideally, your first solution would fix the problem, although unfortunately this is not always the case. If your first solution does not fix the problem, you need to retrace your steps and start again.
It is important that you attempt only one solution at a time. Trying several solutions at once can make it unclear which one actually corrected the problem.
Tip: Rollback Plans
A common and mandatory step that you must take when working on servers and some mission-critical workstations is to develop a rollback plan. The purpose of a rollback plan is to provide a method to get back to where you were before attempting the fix. Troubleshooting should not make the problem worse. Have an escape plan!
After the corrective change has been made to the server, network, or workstation, it is necessary to test the results. Never assume. This is where you find out whether you were right and the remedy you applied actually worked. Don’t forget that first impressions can be deceiving, and a fix that seems to work on first inspection might not have corrected the problem.
The testing process is not always as easy as it sounds. If you test a connectivity problem, it is not difficult to ascertain whether your solution was successful. However, changes made to an application or to databases are typically much more difficult to test. It might be necessary to have people who are familiar with the database or application run the tests with you in attendance. For example, suppose that you troubleshoot an accounting program installed in a client/server configuration. Network clients access the accounting program and the associated data from the server. Recently, all network accountants receive only outdated data when using the application. You, being a network administrator and not an accountant, may have never used the program and therefore cannot determine the outdated data from current data. Perhaps you don’t even know how to load the data in the application. How can you possibly determine whether you have corrected the problem? Even from this simple example, we can see that the process of testing results may require the involvement of others, including end users, managers, other members of the IT team, support professionals associated with third-party applications, and so on.
Note: Avoiding False Starts
When you complete a fix, test it as thoroughly as you can before informing users of the fix. Users would generally rather wait for a real fix than have two or three false starts.
In an ideal world, you want to fully test a solution to see whether it indeed corrects the problem. However, you might not know whether you were successful until all users have logged back on, the application has been used, or the database has been queried. As a network administrator, you will be expected to take the testing process as far as you realistically can, even though you might not simulate certain system conditions or loads. The true test is in a real-world application.
Tip: Virus Activity
Keep in mind when troubleshooting a network or systems on a network that the problem might be virus-related. Viruses can cause a variety of problems that often disguise themselves as other problems. Part of your troubleshooting toolkit should include a virus repair disk with the latest virus definitions. Indicators that you might have a virus include increased error messages and missing and corrupt files.
Step 8: Identify the Results and Effects of the Solution
Sometimes, you apply a fix that corrects one problem but creates another. Many such circumstances are difficult to predict, but not always. For example, you might add a new network application, but the application requires more bandwidth than your current network infrastructure can support. The result would be that overall network performance is compromised.
Everything done to one part of the network can negatively affect another area of the network. Actions such as adding clients, replacing hubs or switches, and adding applications can all have unforeseen results. It is difficult to always know how the changes you make to a network are going to affect the network’s functioning. The safest thing to do is assume that the changes you make are going to affect the network in some way and realize that you just have to figure out how. This is where you might need to think outside the box and try to predict possible outcomes.
Step 9: Document the Solution and the Entire Process
Although it is often neglected in the troubleshooting process, documentation is as important as any of the other troubleshooting procedures. Documenting a solution involves keeping a record of all the steps taken during the fix—not necessarily just the solution.
For the documentation to be of use to other network administrators in the future, it must include several key pieces of information. When documenting a procedure, include the following information:
• Date—When was the solution implemented? It is important to know the date because if problems occur after your changes, knowing the date of your fix makes it easier to determine whether your changes caused the problems.
• Why—Although it is obvious when a problem is fixed while it is done, a few weeks later, it might become less clear why that solution was needed. Documenting why the fix was made is important because if the same problem appears on another system, you can use this information to reduce time finding the solution.
• What—The successful fix should be detailed, along with information about any changes to the configuration of the system or network that were made to achieve the fix. Additional information should include version numbers for software patches or firmware, as appropriate.
• Results—Many administrators choose to include information on both successes and failures. The documentation of failures can prevent you from going down the same road twice, and the documentation of successful solutions can reduce the time it takes to get a system or network up and running.
• Who—It might be that information is left out of the documentation, or someone simply wants to ask a few questions about a solution. In both cases, if the name of the person who made a fix is in the documentation, the person can easily be tracked down. This is more of a concern in environments in which there are a number of IT staff, or if system repairs are performed by contractors instead of company employees.
Tip: Log Books
Many organizations require that a log book be kept in the server room. This log book should maintain a record of everything that has been done on the network. In addition, many organizations require that administrators keep a log book of all repairs and upgrades made to networks and workstations.
Troubleshooting the Network
You will no doubt troubleshoot wiring and infrastructure problems less frequently than you troubleshoot client connectivity problems—and thankfully so. Wiring- and infrastructure-related problems can be difficult to trace, and sometimes a costly solution is needed to remedy the situation. When troubleshooting these problems, a methodical approach is likely to pay off.
Wiring problems are related to the cable used in a network. For the purposes of the Network+ exam, infrastructure problems are classified as those related to network devices such as hubs, switches, and routers.
Troubleshooting Wiring
Troubleshooting wiring involves knowing what wiring your network uses and where it is used. As mentioned in Chapter 2, “Media and Connectors,” the cable used has certain limitations in terms of both speed and distance. It might be that the network problems are the result of trying to use a cable in an environment or a way for which it was not designed. For example, you might find that a network connects two workstations 130 meters apart with Category 5 UTP cabling, which is specified for distances up to 100 meters, so exceeding the maximum cable length could be a potential cause of the problem.
Tip: Cable Distances
Look at cable distances carefully. When you run cables along walls, across ceilings, and along baseboards, the distances can add up quickly. For this reason, carefully consider the placement of the wiring closet and ensure that you can reach all extents of your network while staying within the specified maximum cable distances.
Determining the type of cable used by a network is often as easy as reading the cable. The cable should be stamped with its type—whether it is, for example, UTP Category 5, RG-58, or something else. As you work with the various cable types used to create networks, you get to the point where you can easily identify them. However, be careful when identifying cable types because some cable types are almost indistinguishable. After you determine the cable used, you can compare the characteristics and limitations of that cable against how it is used on the network.
Tip: Cable Types
The type of cable used in a network is important and should be included in the network documentation.
Where the Cable Is Used
Imagine that you have been called in to track down a problem with a network. After some time, you discover that clients connect to the network via standard UTP cable run down an elevator shaft. Recall from Chapter 2 that UTP has poor resistance to electromagnetic interference (EMI), and therefore UTP and the electrical equipment associated with elevators react to each other like oil and water. The same can be said of cables that run close to fluorescent light fittings. Such problems might seem far-fetched, but you would be surprised at how many environments you will work in that have random or erratic problems that users have lived with for a long time and nothing has been done.
Note: Risers
In many buildings, risers are used for running cables between floors. A riser is a column that runs from the bottom of the building to the top. Risers are used for running all kinds of cables, including electrical and network cables.
Part of troubleshooting wiring problems is to identify where the cable is run to isolate whether the problem is a result of crosstalk or EMI. Be aware of problems associated with interference and the distance limitations of the cable used.
Tip: Test Cable
Never assume that the cable you use is good until you test it and confirm that it is good. Sometimes cables break, and bad media can cause network problems.
If you find a problem with a network’s cable, you can do various things to correct it. For cables that exceed the maximum distance, you can use a repeater to regenerate the signal, try to reroute the cable over a more economical route, or even replace the type of cable with one that has greater resistance to attenuation. The method you choose often depends on the network’s design and your budget.
For cable affected by EMI or other interference, consider replacing the cable with one that is more resistant to such interference or rerouting the cable away from the source of the interference. If you do reroute cable, pay attention to the maximum distance, and make sure that as you cure one problem you don’t create another.
Wiring Issues
Depending on where the cable is used and the type of cable, you might encounter some specific cable-related problems. This section describes some problems you might encounter and their solutions.
Crosstalk
Whether its coaxial cable, or UTP, copper-based cabling is susceptible to crosstalk. Crosstalk happens when the signal from one cable gets mixed up with the signal in another cable. This can happen when cables run too closely together. Some cables use shielding to help reduce the impact of crosstalk. If shielded cable is not used, cables should not be run directly near each other.
Near-End Crosstalk (NEXT)
NEXT refers to interference between adjacent wire pairs within the twisted-pair cable at the near-end of the link (the end closest to the origin of the data signal). NEXT occurs when an outgoing data transmission leaks over to an incoming transmission. In effect, the incoming transmission overhears the signal sent by a transmitting station at the near end of the link. The result is that a portion of the outgoing signal is coupled back into the received signal.
Far-End Crosstalk (FEXT)
FEXT occurs when a receiving station overhears a data signal sent by a transmitting station at the other end of a transmission line. FEXT identifies the interference of a signal through a wire pair to an adjacent pair at the farthest end from the interfering source (the end where the signal is received).
Electromagnetic interference (EMI)
Electromagnetic interference (EMI) can reduce signal strength or corrupt it altogether. EMI occurs when cables are run too close to everyday office fixtures such as computer CRT monitors, fluorescent lighting fixtures, elevators, microwaves, and anything else that creates an electromagnetic field. Again, the solution is to carefully run cables away from such devices. If they have to be run through EMI areas, shielded cabling or fiber cabling needs to be used.
Attenuation
All media has recommended lengths that the cable can be run. This is because data signals weaken as they travel farther from the point of origin. If the signal travels far enough, it can weaken so much that it becomes unusable. The weakening of data signals as they traverse the media is referred to as attenuation. All copper-based cable is particularity susceptible to attenuation. When cable lengths have to be run farther than the recommended lengths, signal regenerators can boost the signal as it travels. If you work on a network with intermittent problems and notice that cable lengths run too far, attenuation can be the problem. To see cable lengths, refer to Chapter 6, “Ethernet Networking Standards.”
Open Impedance Mismatch (Echo)
Any network segment can consist of a single continuous section of cable or be constructed from multiple cable sections attached through switches and other hardware. If multiple cable sections are used, it can result in impedance mismatches caused by slight differences in the impedance of each cable section. Impedance refers to the total opposition a circuit or device offers to the flow of a signal, measured in ohms. All media, such as twisted-pair cable, has characteristic impedance. Impedance characteristics for twisted-pair cable include 100, 120, and 150 ohms. UTP typically has an impedance of 100 ohms, and STP has an impedance of 150 ohms. Mixing these two wires in the same cable link can result in an impedance mismatch, which can cause the link to fail. To help prevent impedance mismatch, use cable rated with the same impedance rating.
Shorts
Electrical shorts can occur in any type of cable that has electrical current flowing through it. Shorts occur when the electrical current travels along a different path than what is intended. This can often happen if a network cable is not made correctly and wires are touching each other, improperly grounded, or touching metal. This is another reason to be careful when attaching your own RJ-45 connectors to twisted-pair cable. Sometimes, network cables can become damaged, bent, or mishandled, and shorts can occur. Several networking tools test for shorts, as discussed in Chapter 13, “Network Management Tools and Documentation Procedures.” Copper-based media that carries electrical current is susceptible to shorts; wireless and fiber optic cable are not.
Managing Collisions
Collisions occur on a network when two or more networked devices transmit data at the same time. The result is that the data collides, becomes corrupted, and needs to be re-sent. If these collisions keep occurring, the network slows down and can eventually impact network users. Media Access Control (MAC) techniques can help prevent collisions from occurring. Two commonly used MAC methods include Collision Sense Multiple Access/Collision Detection, or CSMA/CD, used with wired Ethernet networks and Collision Sense Multiple Access/Collision Avoidance, or CSMA/CA, used with 802.11 wireless networks.
The more devices that connect to an Ethernet network, the more likely it is that collisions will occur on the network. In other words, the more devices you add to an Ethernet network, the slower, exponentially, the network will become. This decreasing of performance has driven improvements in the structure of how Ethernet networks. Improvements include the substitution of older hubs with new, high-performance Ethernet switches and the reduction of broadcast-intensive applications.
Collisions can mostly be avoided by using switches instead of hubs. Switches enable for the segmentation of Ethernet networks into smaller collision domain. Whereas the use of a hub creates a large single collision domain, each port on a switch represents a separate collision domain. The switch can provide full-duplex communication to the node/nodes connected to that port. In a switched network, systems do not need to use collision detection and can just transmit without hesitation. How a switch functions is covered in Chapter 3, “Networking Components and Devices.”
Tip: Switched Network
For the Network+ exam, remember that a switch reduces the need for a contention-based network environment because the switch ports break down the network into smaller collision domains. The smaller the collision domain, the fewer collisions that occur.
Troubleshooting Infrastructure Hardware
If you are looking for a challenge, troubleshooting hardware infrastructure problems is for you. It is often not an easy task and usually involves many processes, including baselining and performance monitoring. Both baselines and monitoring are covered in detail in Chapter 13. One of the keys to identifying the failure of a hardware network device is to know what devices are used on a particular network and what each device is designed to do. Some of the common hardware components used in a network infrastructure are shown in Table 11.1.
![]()
Table 11.1 Common Network Hardware Components, Their Function and Troubleshooting Strategies

For more information on network hardware devices and their function, refer to Chapter 3.
Configuring and Troubleshooting Client Connectivity
Connecting clients to an existing network is a common task for network administrators. Connecting a client system requires establishing the physical connection, defining network protocols, assigning permissions, and accessing server services and resources. This section explores the requirements to connect a client PC to a network.
Verifying Client TCP/IP Configurations
Configuring a client for TCP/IP can be relatively complex, or it can be simple. Any complexity involved is related to the possible need to configure TCP/IP manually. The simplicity is related to the fact that TCP/IP configuration can occur automatically via DHCP or through APIPA. This section looks at some of the basic information required to make a system function on a network, using TCP/IP. At the least, a system needs an IP address and a subnet mask. The default gateway, DNS server, and WINS server are all optional, but network functionality is limited without them. The following list briefly explains the IP-related settings used to connect to a TCP/IP network:
• IP address—Each system must be assigned a unique IP address so that it can communicate on the network. Clients on a LAN will have a private IP address and matching subnet mask. Table 11.2 shows the private IP ranges. If a system has the wrong IP or subnet mask, that client system cannot communicate on the network. If the client system has an IP address in the 169.254.0.0 range, the system is not connected to a DHCP server and not getting on the network. Refer to Chapter 5, “TCP/IP Addressing and Routing,” for information on APIPA and automatic IPv4 assignments.
![]()
Table 11.2 Private Address Ranges

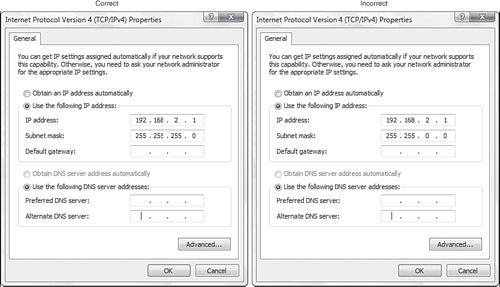
• Subnet mask—Enables the system to determine what portion of the IP address represents the network address and what portion represents the node address. Refer to Table 11.2 to see the right subnet mask associated with each private IP range. To be part of the network, each client system needs to have the correct subnet mask, and the subnet mask must use the matching one used with the rest of the network. Figure 11.1 shows a correct IP configuration and an incorrect IP configuration on a Windows Vista system.
![]()
Figure 11.1 A correct and an incorrect IP client configuration.
• Default gateway—Enables internal systems to communicate with systems on a remote network. In home use, the gateway would likely be the DSL or cable modem that acts as a router. In a business environment the gateway is the device that routes traffic from the workstation to the outside network. This network device will have an IP address assigned to it, and the client configuration must use this address as the default gateway. If not, the system cannot be routed outside the local network.
• DNS server addresses—Enable dynamic hostname resolution to be performed. It is common practice to have two DNS server addresses defined so that if one server becomes unavailable, the other can be used. The client system must be configured with the IP address of the local DNS server. If a client system has the wrong DNS address listed, hostname resolution will not be possible. Figure 11.2 shows the IP configuration for connection to a private network.
![]()
Figure 11.2 The Internet Protocol (TCP/IPv4) Properties dialog box on a Windows Vista system.

Note: TCP/IP Connection Requirements
At a minimum, an IP address and a subnet mask are required to connect to a TCP/IP network. With just this minimum configuration, connectivity is limited to the local segment, and DNS resolution is not possible.
When manually configuring a system to use TCP/IP, all information needs to be entered into the respective dialog boxes carefully. Entering a duplicate IP address might prevent the client system from logging on to the network; the wrong gateway will prevent the system from accessing remote networks, and so on. To view the IP settings of a client system, many utilities are used, including the ipconfig command for Windows systems and the ifconfig for Linux and UNIX systems.
When troubleshooting a system, ensure that the IP address, default gateway, subnet mask, and DNS are correctly set. This information can be assigned using DHCP and should not have any errors; however, in networks where DHCP is not used and settings are inputted manually, these settings must be verified.
Setting Port Speeds and Duplex
When configuring a client for the network, you need to be aware of two more settings: port speeds and duplex settings. Adjust these two settings in Windows in the Network Properties area of the Windows operating system. Figure 11.3 shows the port speed and duplex settings of a Windows Vista system.
![]()
Figure 11.3 The Advanced tab on the properties of a NIC found in Windows Device Manager.
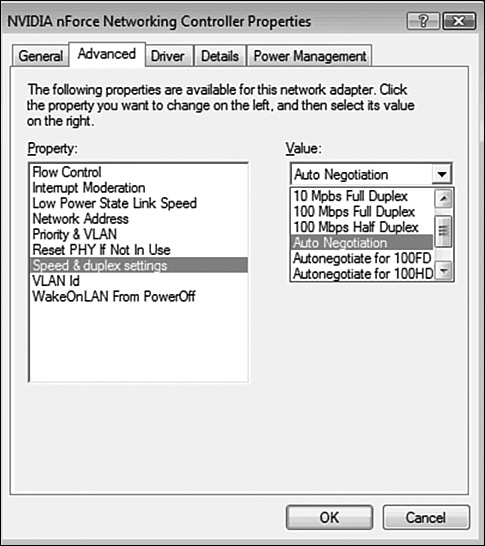
Figure 11.3 shows several settings for port speed and duplex setting. These settings can be set to autoconfiguration to detect the setting used by the network. It can also be set to one of the other settings to match the network configuration—for example, 100Mbps and half duplex. If you work with a client system that cannot log on to a network, it might be necessary to ensure that the duplex setting and port speeds are correctly set for the network. You can find more information on duplex settings in Chapter 2.
Troubleshooting Incorrect VLANs
As mentioned in Chapter 1, “Introduction to Computer Networking,” VLANs provide a method of segmenting and organizing the network. Computer systems can be located anywhere on the network but communicate as if they are on the same segment. For example, VLANs can be segmented according to an organization’s departments, such as sales, finance, and secretaries. It can be segmented according to usage, security permissions, and more.
The ability to segment the network provides clear advantages, such as increased security because devices can communicate only with other systems in the VLAN. Users can see only the systems in their VLAN segment. It can help control broadcast traffic and makes moving end systems around the network easier.
Problems can arise when users are moved or otherwise connected to the wrong VLAN. Administrators need to ensure that the user system is plugged into the correct VLAN port. For example, suppose a network uses port-based VLANs, assigning ports 1 through 8 to marketing, ports 9 through 18 to sales, and so on. Plugging a sales client into port 6 would make that sales client part of the marketing network. It sounds simple, but if documentation is not up to date and you walk into a new network, this can be tricky to identify.
One of the keys to preventing VLAN assignment errors is to clearly document the VLAN arrangement. Should systems be moved, it is important to know how to reconnect them and forward them to the correct VLAN port.
Another consideration to keep in mind is that membership to a VLAN can be assigned both statically and dynamically. In static VLAN assignment, the switch ports are assigned to a specific VLAN, and new systems added will be assigned to the VLAN associated with that particular port. For example, plug a new system into port 8 and the user becomes part of the administrator’s network. Make sure you have the right port assigned to users.
Dynamic VLAN assignment requires specific software to control VLAN distribution. Using a VLAN server, administrators can dynamically assign VLAN membership based on such criteria as MAC address or a username password combination. As a system tries to access the network, it queries the VLAN server database to ask for VLAN membership information. The server responds and logs the system onto the appropriate VLAN network. When configured correctly, dynamic assignment reduces human error associated with static VLAN assignment.
Identifying Issues That Might Need Escalation
Earlier in this chapter we discussed the procedures that must be followed when issue escalation is required. Although any number of issues might need escalation, the CompTIA Network+ objectives list specific scenarios in which escalation might be necessary. Each of these issues will not always require escalation; an administrator with an Internet connection and a little determination can track these down. Nevertheless, we quickly identify each of the issues listed in the CompTIA objectives:
• Switching loop—On an Ethernet network, only a single active path can exist between devices on a network. When multiple active paths are available, switching loops can occur. Switching loops are simply the result of having more than one path between two switches in a network. The Spanning Tree Protocol (STP) is designed to prevent these loops from occurring. If the packet in the loop is a broadcast message, the loop can create a full broadcast storm. Broadcast storms are discussed in this section. Switching loops occur at the data link (Layer 2) of the OSI model.
• Routing loop—As the name suggests, a routing loop occurs when data packets continue to be routed in an endless circle. In a proper operation, a router forwards packets according to the information presented in the routing table. If the routing table is correct, the packet takes the optimal path from the source to the destination. It is not common, but if the information in the routing table is incorrect through a manual misconfiguration or a faulty router route detection, routing loops can form. A routing loop is a path through the internetwork for a network ID that loops back onto itself. Routing loops are detectable because they can quickly bog down a network, and some packets are not received by the destination system.
• Route problems—Route problems typically occur when routing tables contain information that does not reflect the correct topology of the internetwork. Out-of-date or incorrect routing tables mean that packets cannot be correctly routed through the network, and route problems occur. Verify the routing table to ensure that it is correct. Sometimes static routes are entered and cause problems when the network topology is changed.
• Proxy ARP—The ARP protocol is used to resolve IP addresses to MAC addresses. This is important because on a network, devices find each other using the IP address, but communication between devices requires the MAC address. In a proxy ARP configuration, one system or network device answers ARP requests for another system. It is a proxy ARP because one network system is proxying for another’s ARP communications.
• Broadcast storms—A broadcast address is an IP address that you can use to target all systems on a subnet or network instead of single hosts. In other words, a broadcast message goes to everyone on the network. A broadcast storm occurs when a network is overwhelmed with constant broadcast or multicast traffic. Broadcast storms can eventually lead to a complete loss of network connectivity because the network is bogged down with the broadcast storm. As with other network problems, you might suspect a broadcast storm when network response times are poor and people complain of a slow network. These broadcast storms can be caused by faulty hardware, such as a NIC that continually sends out data, switching loops, or even faulty applications running on the network. Baselines work well for identifying broadcast storms.
Troubleshooting Wireless Issues
Because wireless signals travel through the atmosphere, they are subjected to all sorts of elements that can block wireless signals. This includes storms, the number of walls between the sending and receiving devices, ceilings, mirrors, and so on. Just how weakened the signal becomes depends on the building material used, RF interference, the power of the wireless signal, and how far the signal must travel. Every element that a wireless signal must pass through or around weakens the signal, reducing the distance it can travel.
Environmental factors are not the only things to consider when working with wireless networks. This section reviews two key areas to focus on when troubleshooting wireless networks: wireless signals and wireless configurations.
Note: Signal Strength
Wireless signals degrade depending on the construction material used. Signals passing through concrete and steel are particularly weakened.
Troubleshooting Wireless Signals
If you troubleshoot a wireless connection that has a particularly weak signal and one that won’t reach its destination, you can troubleshoot a signal by checking the following:
• Antenna type—As mentioned in Chapter 7, “Wireless Networking,” a wireless antenna can be either omnidirectional or directional. Omnidirectional antennas are great in an environment in which there is a clear line of path between the senders and receivers. With omnidirectional antennas, the wireless signal disperses in a 360-degree pattern to all points.
If environmental obstacles exist, a directional wireless antenna might be a better choice. The directional antenna concentrates the signal power in a specific direction and enables you to use less power for a greater distance than an omnidirectional antenna. Omnidirectional antennas are well suited inside office buildings to accommodate numerous users.
• Antenna placement—Many home-use APs have a built-in antenna that is adequate to reach all areas of a home. Network APs can use an external wireless antenna, and placing it correctly is an important consideration. In general, the AP and the antenna should be located as near to each other as possible. The farther the signal has to travel over cabling from the antenna to the AP, the more signal degradation (RF attenuation) there is. Directional antennas connecting locations in a point-to-point configuration should be placed in a clear line of site between each other. Often the outdoor antennas are placed high to prevent the signal being blocked by physical objects. Indoor antennas should be kept away from large metal objects such as filing cabinets and devices that can cause RF interference.
• Boost signal—If all else fails, it is possible to purchase devices, such as wireless repeaters, that can amplify the wireless signal. The device takes the signal and amplifies it so that it has greater strength and can travel farther distances. Amplifiers increase the range that the client system can be placed from the AP.
• Bleed—Because wireless signals travel through the atmosphere, they are not bound by the same physical limitations of wired media. The dispersed nature of wireless communication can lead to problems. For example, although everyone in an office might be within range of a wireless signal, the signal is not restricted to that office, and someone outside might also use the signal. Wireless signals that travel where administrators might not want is known as bleed. Some APs and antennas enable administrators to restrict the range a wireless signal transmits by reducing the strength of the wireless signal output. Bleed makes wireless security measures essential. To prevent people from using a signal, encryption and other methods are used. So, a user might see the wireless signal but not use the wireless network without the proper security clearance.
• Distance—Wireless signals degrade as they travel from their point of origin. While troubleshooting wireless signals, you might need to relocate the AP closer to client systems or add wireless routers to increase the wireless transmission range. Administrators often use wireless signal testers to ensure transmission ranges are adequate before implementing the wireless network.
Tip: Relocation
When troubleshooting wireless signals, it is often necessary to relocate the AP to a more favorable location. This is important to know both for the Network+ exam and for real-world application.
To successfully manage the wireless signals, you need to know the wireless standard that you are using. The standards used today specify range distances, RF ranges, and speeds. It might be that the wireless standard cannot do what you need. More information on all wireless standards is in Chapter 7.
Troubleshooting Wireless Configurations
You can use a number of settings and configurations when working with wireless clients and APs. Some of the more common areas to check when troubleshooting wireless configurations include the following:
• Incorrect encryption—The wireless network security features are set on the wireless router or AP. This includes the wireless encryption methods that will be used—for instance, WEP or WPA. When encryption is enabled on the AP, the client must be configured to use the encryption and know the encryption key to be authenticated to the AP. When troubleshooting a connectivity problem between an AP and a wireless client, a common problem is that the encryption security settings do not match.
• SSID/ESSID mismatch—Whether your wireless network uses infrastructure mode or ad-hoc mode, an SSID/ESSID is required. The SSID/ESSID is a configurable client identification that enables clients to communicate to a particular base station. Only client systems configured with the same SSID as the AP can communicate with it. SSIDs provide a simple password arrangement between base stations and clients. The ESSID/SSID might be broadcast from the AP and visible to all receiving devices in the area, or it might be configured not to broadcast. Not broadcasting the SSID name adds another level of security because people cannot see the SSID name when browsing for wireless networks in the area. The ESSID/SSID would need to be obtained from the network administrator.
• Overlapping channels—When troubleshooting a wireless network, be aware that overlapping channels can disrupt the wireless communications. For example, in many environments, APs are inadvertently placed close together—perhaps two access points in separate offices located next door to each other or between floors. Signal disruption will result if a channel overlap occurs between the access points. You would typically change the channel of a wireless device only if there is a channel overlap with another device. If a channel must be changed, it must be changed to another nonoverlapping channel.
• Standard mismatch—The 802.11 standards commonly used today include 802.11a/b and g, with n as the new standard. When configuring client systems, be sure they are configured to use the same or compatible wireless standard; 802.11a is not compatible with b, g, or n, but b and g are compatible.
Note: More Wireless Troubleshooting
When preparing for the Network+ exam, be sure to cross-reference the wireless information in this chapter with Chapter 7.
Summary
Troubleshooting networks is an activity with which network administrators become very familiar. Successful troubleshooting does not happen by accident; rather, the troubleshooting process follows some defined procedures. These procedures include the following:
Step 1. Information gathering—identify symptoms and problems.
Step 2. Identify the affected areas of the network.
Step 3. Determine if anything has changed.
Step 4. Establish the most probable cause.
Step 5. Determine if escalation is necessary.
Step 6. Create an action plan and solution identifying potential effects.
Step 7. Implement and test the solution.
Step 8. Identify the results and effects of the solution.
Step 9. Document the solution and the entire process.
At times, you might troubleshoot wiring and infrastructure problems. Although they are less common than other troubleshooting areas, wiring and network devices should be considered a possible causes of a problem. Tracking down infrastructure problems often requires using documentation and network maps or taking baselines to compare network performance.
Consider several areas when troubleshooting a wireless network. Many problems are related to poor signal strength, low transmission rates, and limited distances. When troubleshooting wireless connectivity, it is important to verify both the signal strength and the AP and wireless client configuration.
Exam Preparation Tasks: Review All the Key Topics
![]()
Review the most important topics in the chapter, noted with the Key Topics icon in the outer margin of the page. Table 11.3 lists a reference of these key topics and the page numbers on which each is found.
Table 11.3 Key Topics for Chapter 11
Define Key Terms
Define the following key terms from this chapter, and check your answers in the Glossary.
• Crosstalk
• Attenuation
• Collisions
• Open impedance mismatch
• Interference
• Port speed
• Port duplex mismatch
• VLAN
• DNS
• Encryption
• Wireless channel
• SSID
• ESSID mismatch
• 802.11 a/b/g/n
Apply Your Knowledge
Exercise 11.1 Using the Microsoft Support Website to Track Error Codes
As a network administrator, you have the task of installing and configuring a new Windows Vista computer system. However, each time you try to install the new operating system, the process is halted with the following error message:
Stop: 0x000000A5 To install the Windows Vista system, you need to find the solution to the problem.
Estimated time: 10 minutes
1. Go to http://support.microsoft.com.
2. Type Stop: 0x000000A5 in the bing search bar.
3. Select the bing button to continue.
4. One result will be displayed; scroll through the document links.
5. Scroll down the page until you see Stop: 0x000000A5. In this case, you notice that the reason the installation failed is that the computer BIOS is incompatible with the Advanced Configuration and Power Interface (ACPI) standard supported in Windows Vista.
Review Questions
You can find answers to the review questions in Appendix A, “Answers to Review Questions.”
1. Considering the following figure, which of the following statements is true?
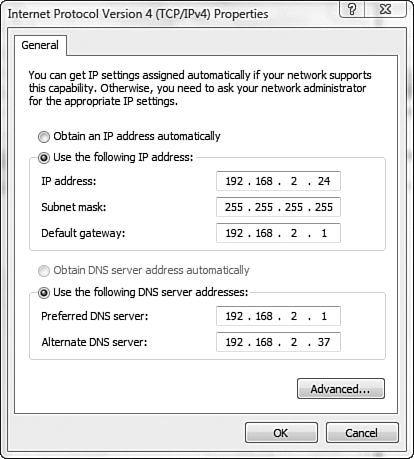
a. The system cannot access the local network.
b. The system cannot access remote networks.
c. The system cannot have hostname resolution.
d. The system has the wrong subnet mask.
2. Using the following configuration screen, which of the following is true?
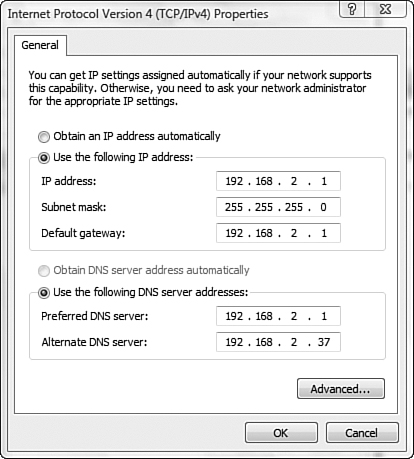
a. The system cannot access the local network.
b. The system cannot access remote networks.
c. The system cannot have hostname resolution.
d. The system has the wrong subnet mask.
3. Which of the following best describes the function of the default gateway?
a. Converts hostnames to IP address
b. Converts IP addresses to hostnames
c. Enables systems to communicate with systems on a remote network
d. Enables systems to communicate with routers
4. Which of the following bits of IP information are mandatory to join the network? (Select two answers.)
a. Subnet mask
b. IP address
c. DNS address
d. Default gateway
5. You are wiring a new network. Because of space limitations, you need to run several cables close to each other. After the setup you find that the signals from each cable are overlapping. Which of the following terms describe what is happening?
a. Attenuation
b. Cross talk
c. Near crosstalk
d. EMI
6. Which of the following should you consider when troubleshooting wiring problems? (Choose all best answers.)
a. The distance between devices
b. Interference
c. Atmospheric conditions
d. Connectors
7. You get numerous calls from users who cannot access an application. Upon investigation, you find that the application has crashed. You restart the application, and it appears to run okay. What is the next step in the troubleshooting process?
a. Email the users and let them know that they can use the application again.
b. Test the application to ensure that it operates correctly.
c. Document the problem and the solution.
d. Reload the application executables from the CD and restart it.
8. A user calls to inform you that she is having a problem accessing her email. What is the next step in the troubleshooting process?
a. Document the problem.
b. Make sure that the user’s email address is valid.
c. Discuss the problem with the user.
d. Visit the user’s desk to reload the email client software.
9. You successfully fix a problem with a server, test the application, and let the users back on the system. What is the next step in the troubleshooting process?
a. Document the problem.
b. Restart the server.
c. Document the problem and the solution.
d. Clear the error logs of any reference to the problem.
10. You are called in to troubleshoot a problem with the NIC on a server that has been running well for some time. The server reports a resource conflict. What would be the next step in the troubleshooting process?
a. Change the NIC.
b. Consult the documentation to determine whether there have been any changes to the server configuration.
c. Download and install the latest drivers for the NIC.
d. Reload the protocol drivers for the NIC and set them to use a different set of resources.
11. Which of the following can cause switching loops?
a. Sporadic sending of broadcast messages
b. Continual sending of broadcast messages
c. An Ethernet network in which multiple active paths are available for data to travel.
d. An Ethernet network in which only a single active path is available for data to travel.
12. You are troubleshooting an infrastructure problem and suspect the problem might be the network media. Which of the following must be considered when troubleshooting network media? (Choose two answers.)
a. Where the media is used
b. Media frequency output/input ratio
c. Media type
d. Media voltage
13. You have been called into a network to troubleshoot a cabling error. You have traced the problem to lengths of cable that have been run too far. Which of the following describes the weakening of data signals as they travel down a given media?
a. Near crosstalk
b. EMI
c. Attenuation
d. Crosstalk
14. You troubleshoot an intermittent connectivity issue. You suspect the problem might be a form of crosstalk known as NEXT. Which of the following is a symptom of NEXT?
a. Packets cannot be decrypted.
b. Packets cannot be encrypted.
c. Interference exists between wire pairs at the near end of the link.
d. Interference exists between wire pairs at the far end of the link.
15. You work with several homemade network cables. Which of the following is caused by poorly made cables?
a. Near End crosstalk
b. Signal degradation
c. EMI
d. Attenuation
16. A client on your network has had no problem accessing the wireless network, but recently the client moved to a new office in the same building. Since the move, she has been experiencing intermittent connectivity problems. Which of the following is most likely the cause of the problem? (Select the two best answers.)
a. The SSID on the client and the AP are different.
b. The client WEP settings need to be set to auto detect.
c. The signal is partially blocked by physical objects.
d. The client system has moved too far away from the access point.
17. You have been called in to troubleshoot a problem with a specific application on a server system. The client cannot provide any information about the problem except that the application is not accessible. Which of the following troubleshooting steps should you perform first?
a. Consult the documentation for the server.
b. Consult the application error log on the server.
c. Reboot the server.
d. Reload the application from the original CD.
18. Which of the following is not a concern when troubleshooting connectivity between an AP and a wireless client?
a. Ensuring both use the same encryption
b. Ensuring the AP and client are configured not to combine 802.11b/g and n
c. Ensuring that the same SSID is used
d. Ensuring that the client system is within range of the AP
19. You have been called in to troubleshoot an intermittent network problem. You suspect that cabling is a problem. You review the documentation and find out that a segment of Category 5e cable runs through the ceiling. Which of the following would you guess would be the problem?
a. Crosstalk
b. Near crosstalk
c. Attenuation
d. EMI
20. A user is having problems logging on to the server. Each time she tries, she receives a Server Not Found message. After asking a few questions, you deduce that the problem is isolated to this single system. Which of the following are possible explanations to the problem? (Choose the two best answers.)
a. The protocol configuration on the workstation is incorrect.
b. A hub might have failed.
c. The cable has become disconnected from the user’s workstation.
d. The server is down.