
Chapter 11. Organizational Security
Terms you need to understand
![]() Redundant array of independent (or inexpensive) disks (RAID)
Redundant array of independent (or inexpensive) disks (RAID)
![]() Uninterruptible power supply (UPS)
Uninterruptible power supply (UPS)
Techniques you need to master
![]() Knowing the common areas of concern when planning for redundant site services
Knowing the common areas of concern when planning for redundant site services
![]() Understanding how to plan and conduct disaster exercises
Understanding how to plan and conduct disaster exercises
![]() Recognizing backup techniques and restoration processes
Recognizing backup techniques and restoration processes
Network security and system hardening provide the strongest possible levels of security against directed attacks, but organizational security must also be considered when planning an organization’s data security. This chapter examines the issues surrounding redundancy planning, disaster recovery, backup, and restoration policies.
Disaster Recovery and Redundancy Planning
For many organizations, downtime is not an option. Organizational security encompasses identifying the critical business needs and the resources associated with those needs. Critical business functions must be designed to continue operating in the event of hardware or other component failure. Critical systems such as servers and Internet availability will require redundant hardware. Redundancy planning requires that you prioritize the data and systems that need to be recovered first. Then plan backup methods, data replication, and failover systems. Make sure you have redundancy for critical systems, whether it’s as simple as a redundant array of independent (or inexpensive) disks (RAID) storage system or as complex as a complete duplicate data center.
Too many organizations realize the criticality of disaster recovery planning only after a catastrophic event (such as a hurricane, flood, or terrorist attack). However, disaster recovery is an important part of overall organization security planning, for every organization! Natural disasters and terrorist activity can bypass even the most rigorous physical security measures. Common hardware failures and even accidental deletions may require some form of recovery capability. Failure to recover from a disaster may destroy an organization.
Disaster recovery involves many aspects, including the following:
• Impact and risk assessment—To plan recovery appropriately, companies must determine the scope and criticality of its services and data. In addition, an order (a priority) of recovery must be established.
• Disaster recovery plan—A disaster recovery plan is a written document that defines how the organization will recover from a disaster and how to restore business with minimum delay. The document also explains how to evaluate risks, how data backup and restoration procedures work, and the training required for managers, administrators, and users. A detailed disaster recovery should address various processes, including backup, data security, and recovery.
• Disaster recovery policies—These policies detail responsibilities and procedures to follow during disaster recovery events, including how to contact key employees, vendors, customers, and the press. They should also include instructions for situations in which it may be necessary to bypass the normal chain of command to minimize damage or the effects of a disaster.
• Service level agreements (SLAs)—SLAs are contracts with Internet service providers (ISPs), utilities, facilities managers, and other types of suppliers that detail minimum levels of support that must be provided (including in the event of failure or disaster).
Detailed responsibilities and procedures to follow during disaster recovery events should be in place. The procedures must include contact methods. Plans must also be established in case it is necessary to bypass normal access for any reason (perhaps, for instance, to avoid potential sources of failure). Disaster recovery and redundancy require organizations to consider how best to deal with the following issues:
• Power in the event of a complete loss of city power
• Alternative locations for business operations
• Telecommunications restoration
• Internet connectivity to continue business operations
• Equipment that will be put in place for operations to continue
• Replacement software
• Data restoration
• The contact method for employees and clients
• The order in which the recovery process should proceed
• Physical security at current and alternative sites
• The estimated time to complete the steps in the disaster recovery plan and get the business back to normal
After a “disaster” or other failure situation has been evaluated, and the damage assessed, the company can begin the recovery process. A hard copy of the plan must be available (and key elements of that plan should be removable, such as a vendors list or team member phone numbers). After all, a disaster recovery plan does not do you any good if it is locked in someone’s desk drawer and that desk is in a building that has been evacuated.
Beyond backup and restoration of data, disaster recovery planning must include a detailed analysis of underlying business practices and support requirements. This is called business continuity planning. Business continuity planning is a more comprehensive approach to provide guidance so that the organization can continue making sales and collecting revenue. As with disaster recovery planning, it covers natural and man-made disasters. Business continuity planning should identify required services, such as network access and utility agreements, and arrange for automatic failover of critical services to redundant offsite systems.
Business continuity planning may address the following:
• Network connectivity—In the event that a disaster is widespread or targeted at an ISP or key routing hardware point, an organization’s continuity plan should include options for alternative network access, including dedicated administrative connections that may be required for recovery.
• Facilities—Continuity planning should include considerations for recovery in the event that existing hardware and facilities are rendered inaccessible or unrecoverable. Hardware configuration details, network requirements, and utilities agreements for alternative sites (that is, warm and cold sites) should be included in this planning consideration.
• Clustering—To provide load balancing to avoid functionality loss because of directed attacks meant to prevent valid access, continuity planning may include clustering solutions that allow multiple nodes to perform support while transparently acting as a single host to the user. High-availability clustering may also be used to ensure that automatic failover will occur in the event that hardware failure renders the primary node unable to provide normal service.
• Fault tolerance—Cross-site replication may be included for high-availability solutions requiring high levels of fault tolerance. Individual servers may also be configured to allow for the continued function of key services even in the case of hardware failure. Common fault-tolerant solutions include RAID solutions, which maintain duplicated data across multiple disks so that the loss of one disk will not cause the loss of data. Many of these solutions may also support the hot-swapping of failed drives and redundant power supplies so that replacement hardware may be installed without ever taking the server offline.
A business recovery plan, business resumption plan, and contingency plan are also considered part of business continuity planning.
The following sections describe several critical aspects of organizational security and disaster and business continuity planning.
Redundant Sites
In the beginning stages of the organizational security plan, the organization must decide how it will operate and how it will recover from any unfortunate incidents that affect its ability to conduct business. Redundancy planning encompasses the effects of both natural and man-made catastrophes. Often, these catastrophes result from unforeseen circumstances. Hot, warm, and cold sites can provide a means for recovery should an event render the original building unusable. These are discussed individually in the sections that follow.
Hot Site
A hot site is a location that is already running and available 7 days a week, 24 hours a day. These sites allow the company to continue normal business operations, usually within a minimal period of time after the loss of a facility. This type of site is similar to the original site in that it is equipped with all necessary hardware, software, network, and Internet connectivity fully installed, configured, and operational. Data is regularly backed up or replicated to the hot site so that it can be made fully operational in a minimal amount of time in the event of a disaster at the original site. The business can be resumed without significant delay. In the event of a catastrophe, all people need to do is drive to the site, log on, and begin working.
Hot sites are the most expensive to operate and are mostly found in businesses that operate in real time, for whom any downtime might mean financial ruin.
The hot site should be located far enough from the original facility to avoid the disaster striking both facilities. A good example of this is a flood. The range of a flood depends on the category and other factors as wind and the amount of rain that follows. A torrential flood can sink and wash away buildings and damage various other property, such as electrical facilities. If the hot site is within this range, the hot site is affected, too.
Warm Site
A warm site is a scaled-down version of a hot site. The site is generally configured with power, phone, and network jacks. The site may have computers and other resources, but they are not configured and ready to go. In a warm site, the data is replicated elsewhere for easy retrieval. However, you still have to do something to be able to access the data. This “something” might include setting up systems so that you can access the data or taking special equipment over to the warm site for data retrieval. It is assumed that the organization itself will configure the devices, install applications, and activate resources or that it will contract with a third party for these services. Because the warm site is generally office space or warehouse space, the site can serve multiple clients simultaneously. The time and cost for getting a warm site operational is somewhere between a hot and a cold site.
Cold Site
A cold site is the weakest of the recovery plan options but also the cheapest. These sites are merely a prearranged request to use facilities if needed. Electricity, bathrooms, and space are about the only facilities provided in a cold site contract. Therefore, the organization is responsible for providing and installing all the necessary equipment. If the organization chooses this type of facility, it will require additional time to secure equipment, install operating systems and applications, and contract services such as Internet connectivity. The same distance factors should be considered when planning a cold site as when planning a hot site.
Choosing a Recovery Site Solution
The type of recovery site an organization chooses will depend on the criticality of recovery and budget allocations. Hot sites are traditionally more expensive, but they can be used for operations and recovery testing before an actual catastrophic event occurs. Cold sites are less costly in the short term. However, equipment purchased after such an event may be more expensive or difficult to obtain.
As part of redundancy and recovery planning, an organization can contract annually with a company that offers redundancy services (for a monthly, or otherwise negotiated, service charge). When contracting services from a provider, the organization should carefully read the contract. Daily fees and other incidental fees might apply. In addition, in a large-scale incident, the facility could very well become overextended.
Utilities
When planning for redundancy, keep in mind that even though the physical building may be spared destruction in a catastrophic event, it can still suffer power loss. If power is out for several days or weeks, your business itself could be in jeopardy. The most common way to overcome this problem is to supply your own power when an emergency scenario calls for it.
Backup Power Generator
Backup power refers to a power supply that runs in the event of a primary power outage. One source of backup power is a gas-powered generator. The generator can be used for rolling blackouts, emergency blackouts, or electrical problems. Most generators can be tied in to the existing electrical grid so that if power is lost, the generator starts supplying power immediately. When selecting a generator, issues to consider include the following:
• Power output—Rated in watts or kilowatts
• Fuel source—Gasoline, diesel, propane, or natural gas
• Uptime—How long the unit will run on one tank of fuel
• How unit is started—Battery or manually with a pull-cord
• Transfer switch—Automatic or manual
Determine how big a generator you need by adding up the wattages required by devices you want turned on at one time. Gasoline-run generators are the least expensive. However, they are louder and have a shorter lifespan than diesel, propane, and natural gas generators.
Uninterruptible Power Supply
Power problems will occur in various ways. One of the most obvious is when power strips are daisy-chained. Often, daisy-chained devices do not get enough power. At the other end of the spectrum, daisy chaining of devices will occasionally trip the circuit breakers or start a fire. Be aware that power issues can quickly burn out equipment. If power is not properly conditioned, it can have devastating effects on equipment. The following list describes some of the power variations that can occur:
• Noise—Also referred to as electromagnetic interference (EMI) and radio frequency interference (RFI), noise can be caused by lightning, load switching, generators, radio transmitters, and industrial equipment.
• Spikes—These are instantaneous and dramatic increases in voltage that result from lightning strikes or when electrical loads are switched on or off. They can destroy electronic circuitry and corrupt stored data.
• Surges—These are short-term increases in voltage commonly caused by large electrical load changes and from utility power-line switching.
• Brownouts—These are short-term decreases in voltage levels that most often occur when motors are started or are triggered by faults on the utility provider’s system.
• Blackouts—These are caused by faults on the utility provider’s system and results in a complete loss of power. Rolling blackouts occur when the utility company turns off the power in a specific area.
To protect your environment from such damaging fluctuations in power, always connect your sensitive electronic equipment to power conditioners, surge protectors, and a UPS (uninterruptible power supply, which provides the best protection of all). A UPS is a power supply that sits between the wall power and the computer. In the event of power failure at the wall, the UPS takes over and powers the computer so that you can take action to not lose data (such as saving your work or shutting down your servers).
Three different types of devices are classified as UPSs:
• Standby power supply (SPS)—This is also referred to as an “offline” UPS. In this type of supply, power usually derives directly from the power line until power fails. After a power failure, a battery-powered inverter turns on to continue supplying power. Batteries are charged, as necessary, when line power is available.
• Hybrid or ferroresonant UPS systems—This device conditions power using a ferroresonant transformer. This transformer maintains a constant output voltage even with a varying input voltage and provides good protection against line noise. The transformer also maintains output on its secondary briefly when a total outage occurs.
• Continuous UPS—This is also called an “online” UPS. In this type of system, the computer is always running off of battery power, and the battery is continuously being recharged. There is no switchover time, and these supplies generally provide the best isolation from power-line problems.
You cannot eliminate all risk associated with power problems just by connecting your sensitive electronic equipment to power conditioners, surge protectors, or a UPS. However, you can certainly minimize (if not entirely prevent) the damage such problems may cause.
Redundant Equipment and Connections
The main goal of preventing and effectively dealing with any type of disruption is to ensure availability. Of course, you can use RAID, UPS equipment, and clustering to accomplish this. But neglecting single points of failure can prove disastrous. A single point of failure is any piece of equipment that can bring your operation down if it stops working.
To determine the number of single points of failure in the organization, start with a good map of everything the organization uses to operate. Pay special attention to items such as the Internet connection, routers, switches, and proprietary business equipment. After identifying the single points of failure, perform a risk analysis. In other words, compare the consequences if the device fails to the cost of redundancy. For example, if all your business is web-based, it is a good idea to have some redundancy in the event the Internet connection goes down. However, if the majority of your business is telephone-based, you might look for redundancy in the phone system as opposed to the ISP. In some cases, the ISP may supply both the Internet and the phone services. The point here is to be aware of where your organization is vulnerable and understand what the risk is, so that you can devise an appropriate backup plan.
RAID
Perhaps the biggest asset an organization has is its data. The planning of every server setup should consider how to salvage the data should a component fail. The decision about how to store and protect data will be determined by how the organization uses its data. This section examines data-redundancy options.
The most common approach to data availability and redundancy is called RAID. RAID organizes multiple disks into a large, high-performance logical disk. In other words, if you have three hard drives, you can configure them to look like one large drive. Disk arrays are created to stripe data across multiple disks and access them in parallel, which allows the following:
• Higher data transfer rates on large data accesses
• Higher I/O rates on small data accesses
• Uniform load balancing across all the disks
Large disk arrays are highly vulnerable to disk failures. To solve this problem, you can use redundancy in the form of error-correcting codes to tolerate disk failures. With this method, a redundant disk array can retain data for a much longer time than an unprotected single disk. With multiple disks and a RAID scheme, a system can stay up and running when a disk fails and during the time the replacement disk is being installed and data restored.
The two major goals when implementing disk arrays are data striping for better performance and redundancy for better reliability. There are many types of RAID. Some of the more common ones are as follows:
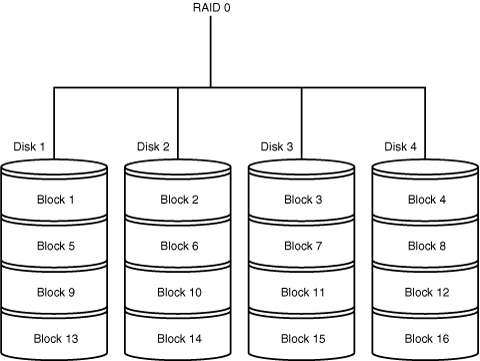
• RAID Level 0—Striped disk array without fault tolerance. RAID 0 implements a striped disk array, the data is broken into blocks, and each block is written to a separate disk drive. This requires a minimum of two disks to implement. See Figure 11.1 for an illustration.
Figure 11.1. RAID Level 0.
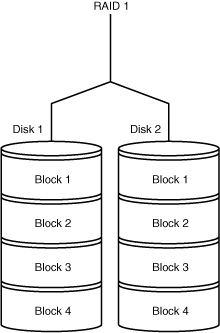
• RAID Level 1—Mirroring and duplexing. This solution, called mirroring or duplexing, requires a minimum of two disks and offers 100% redundancy because all data is written to both disks. The difference between mirroring and duplexing is the number of controllers. Mirroring uses one controller, whereas duplexing uses one controller for each disk. In RAID 1, disk usage is 50% as the other 50% is for redundancy. See Figure 11.2 for an illustration.
Figure 11.2. RAID Level 1.
• RAID Level 2—Hamming Code Error Correcting Code (ECC). In RAID 2, each bit of a data word is written to a disk. RAID 2 requires the use of extra disks to store an error-correcting code. A typical setup requires 10 data disks and 4 ECC disks. Because all modern disk drives incorporate ECC, this offers little additional protection. No commercial implementations exist today. The controller required is complex, specialized, and expensive, and the performance is not very good.
• RAID Level 3—Parallel transfer with parity. In RAID 3, the data block is striped and written on the data disks. This requires a minimum of three drives to implement. In a parallel transfer with parity, data is interleaved bit-wise over the data disks, and a single parity disk is added to tolerate any single disk failure.
• RAID Level 4—Independent data disks with shared parity disk. Entire blocks are written onto a data disk. RAID 4 requires a minimum of three drives to implement. RAID 4 is similar to RAID 3 except that data is interleaved across disks of arbitrary size rather than in bits.
• RAID Level 5—Independent data disks with distributed parity blocks. In RAID 5, each entire block of the data, and the parity is striped. RAID 5 requires a minimum of three disks. Because it writes both the data and the parity over all the disks, it has the best small read, large write performance of any redundancy disk array. See Figure 11.3 for an illustration.
Figure 11.3. RAID Level 5.

• RAID Level 6—Independent data disks with two independent parity schemes. This is an extension of RAID 5 and allows for additional fault tolerance by using two-dimensional parity. This method uses Reed-Solomon codes to protect against up to two disk failures using the bare minimum of two redundant disk arrays.
• RAID Level 10—High reliability combined with high performance. RAID 10 requires a minimum of four disks to implement. This solution is a striped array that has RAID 1 arrays. Disks are mirrored in pairs for redundancy and improved performance, and then data is striped across multiple disks for maximum performance.
There are several additional levels of RAID: 7, 50, 53, and 0+1. RAID 7 is a proprietary solution that is a registered trademark of Storage Computer Corporation. This RAID has a fully implemented, process-oriented, real-time operating system residing on an embedded array controller microprocessor. RAID 50 is more fault tolerant than RAID 5 but has twice the parity overhead and requires a minimum of six drives to implement. RAID 53 is an implementation of a striped array that has RAID 3 segment arrays. This takes a minimum of five drives, three for RAID 3 and two for striping. RAID 0+1 is a mirrored array that has RAID 0 segments. RAID 0+1 requires a minimum of four drives, two for striping and two to mirror the first striped set.
When choosing a method of redundancy, choose a level of RAID that is supported by the operating system. Not all operating systems support all versions of RAID. For example, Microsoft Windows servers support RAID levels 0, 1, and 5. In addition to hardware RAID, software RAID can be used. Software RAID can be used when the expense of additional drives is not included in the budget or if the organization is using older servers. Software RAID can provide more flexibility, but it requires more CPU cycles and power to run. Software RAID operates on a partition-by-partition basis and tends be slightly more complicated to run.
Another point to remember is that even though you set up the server for redundancy, you must still back up your data. RAID does not protect you from multiple disk failures. Regular tape backups allow you to recover from data loss that result from errors unrelated to disk failure (such as human, hardware, and software errors). We discuss the different types and methods of backups later in this chapter in the section “Backup Techniques and Practices.”
Servers
It might be necessary to set up redundant servers so that the business can still function in the event of hardware or software failure. If a single server hosts vital applications, a simple equipment failure might result in days of downtime as the problem is repaired.
To ensure availability and reliability, server redundancy is implemented. This means multiple servers are used to perform the same task. For example, if you have a web-based business with more than one server hosting your site, when one of the servers crashes, the requests can be redirected to another server. This provides a highly available website.
In today’s world, mission-critical businesses demand 100% uptime 24 hours a day 7 days a week. Availability is vital, and many businesses would not be able to function without redundancy. Redundancy can take several forms, such as automatic failover, failback, and virtualization. The most notable advantage of server redundancy, perhaps, is load balancing. In load balancing, the system load is spread over all available servers. This proves especially useful when traffic volume is high. It prevents one server from being overloaded while another sits idle.
Another way to increase availability is server clustering. A server cluster is the combination of two or more servers so that they appear as one. This clustering increases availability by ensuring that if a server is out of commission because of failure or planned downtime, another server in the cluster takes over the workload. In addition, some manufacturers provide redundant power supplies in mission-critical servers.
ISPs
Along with power and equipment loss, telephone and Internet communications may be out of service for a while when a disaster strikes. Organization must consider this factor when formulating a disaster recovery plan. Relying on a single Internet connection for critical business functions could prove disastrous to your business. With a redundant ISP, a backup ISP could be standing by in the event of an outage at the main ISP. Should this happen, traffic is switched over to the redundant ISP. The organization can continue to do business without any interruptions.
Although using multiple ISPs is mostly considered for disaster recovery purposes, it can also relieve network traffic congestion and provide network isolation for applications. As organizations become global, dealing with natural disasters will become more common. Solutions such as wireless ISPs used in conjunction with VoIP to quickly restore phone and data services are looked at more closely. Organizations may look to ISP redundancy to prevent application performance failure and supplier diversity. For example, businesses that transfer large files can use multiple ISPs to segregate voice and file transfer traffic to a specific ISP. More and more organizations are implementing technologies such as VoIP. When planning deployment, explore using different ISPs for better network traffic performance, for disaster recovery, and to ensure a quality level of service.
Connections
In disaster recovery planning, you might need to consider redundant connections between branches or sites. Internally, for total redundancy, you might need two network cards in computers connected to different switches or hubs. With redundant connections, all devices are connected to each other more than once, to create fault tolerance. A single device or cable failure will not affect the performance because the devices are connected by more than one means. This setup is more expensive because it requires more hardware and cabling. This type of topology can also be found in enterprisewide networks, with routers being connected to other routers for fault tolerance.
Service Level Agreements
In the event of a disaster, an organization might also need to restore equipment (in addition to data). One of the best ways to ensure the availability of replacement parts is through service level agreements (SLAs). These are signed contracts between the organization and the vendors with which they commonly deal. SLAs are covered in greater detail in the next chapter. SLAs can be for services such as access to the Internet, backups, restoration, and hardware maintenance. Should a disaster destroy your existing systems, the SLA can also help you guarantee the availability of computer parts or even entire computer systems.
When evaluating SLAs, the expected uptime and maximum allowed downtime on a yearly basis are considered. Uptime is based on 365 days a year, 24 hours a day. Here is an example:
|
99.999% |
53.3 minutes downtime/year |
|
99.99% |
53 minutes downtime/year |
|
99.9% |
8.7 hours downtime/year |
|
99% |
87 hours downtime/year |
Backup Techniques and Practices
Fundamental to any disaster recovery plan is the need to provide for regular backups of key information, including user file and email storage, database stores, event logs, and security principal details such as user logons, passwords, and group membership assignments. Without a regular backup process, loss of data through accidents or directed attack could severely impair business processes.
The backup procedures in use may also affect what is recovered following a disaster. Disaster recovery plans should identify the type and regularity of the backup process. The following sections cover the types of backups you can use and different backup schemes.
Backup Types
The different types of backups you can use are full, differential, incremental, and copy. A full backup is a complete backup of all data and is the most time-intensive and resource-intensive form of backup, requiring the largest amount of data storage. In the event of a total loss of data, restoration from a complete backup will be faster than other methods. A full backup copies all selected files and resets the archive bit. An archive bit is a file attribute used to track incremental changes to files for the purpose of backup. The operating system sets the archive bit any time changes occur, such as when a file is created, moved, or renamed. This method enables you to restore using just one tape. Theft poses the most risk, however, because all data is on one tape.
A differential backup includes all data that has changed since the last full backup, regardless of whether or when the last differential backup was made, because it doesn’t reset the archive bit. This form of backup is incomplete for full recovery without a valid full backup. For example, if the server dies on Thursday, two tapes are needed—the full from Friday and the differential from Wednesday. Differential backups require a variable amount of storage, depending on the regularity of normal backups and the number of changes that occur during the period between full backups. Theft of a differential tape is more risky than an incremental tape because larger chunks of sequential data may be stored on the tape the further away it is from the last full backup.
An incremental backup includes all data that has changed since the last incremental backup, and it resets the archive bit. An incremental backup is incomplete for full recovery without a valid full backup and all incremental backups since the last full backup. For example, if the server dies on Thursday, four tapes are needed—the full from Friday and the incremental tapes from Monday, Tuesday, and Wednesday. Incremental backups require the smallest amount of data storage and require the least amount of backup time, but they can take the most time during restoration. If an incremental tape is stolen, it might not be of value to the offender, but it still represents risk to the company.
A copy backup is similar to a full backup in that it copies all selected files. However, it doesn’t reset the archive bit. From a security perspective, the loss of a tape with a copy backup is the same as losing a tape with a full backup.
Schemes
When choosing a backup strategy, a company should look at the following factors:
• How often it needs to restore files—As a matter of convenience, if files are restored regularly, a full backup may be decided on because it can be done with one tape.
• How fast the data needs to be restored—If large amounts of data are backed up, the incremental backup method may work best.
• How long the data needs to be kept before being overwritten—If used in a development arena where data is constantly changing, a differential backup method may be the best choice.
After the backups are complete, they must be clearly marked or labeled so that they can be properly safeguarded. In addition to these backup strategies, organizations employ tape rotation and retention policies. The various methods of tape rotation include the following:
• Grandfather-father-son backup refers to the most common rotation scheme for rotating backup media. The basic method is to define three sets of backups. The first set, “son,” represents daily backups. A second set, “father,” is used to perform full backups. The final set of three tapes, “grandfather,” is used to perform full backups on the last day of each month.
• Tower of Hanoi is based on the mathematics of the Tower of Hanoi puzzle. This is a recursive method where every tape is associated with a disk in the puzzle, and the disk movement to a different peg corresponds with a backup to a tape.
• Ten-tape rotation is a simpler and more cost-effective method for small businesses. It provides a data history of up to two weeks. Friday backups are full backups. Monday through Thursday backups are incremental.
All tape-rotation schemes can protect your data, but each one has different cost considerations. The Tower of Hanoi is more difficult to implement and manage but costs less than the grandfather-father-son scheme.
In some instances, it might be more beneficial to copy or image a hard drive for backup purposes. For example, in a development office, where there might be large amounts of data that changes constantly, instead of spending money on a complex backup system to back up all the developers’ data, it may be less expensive and more efficient to buy another hard drive for each developer and have him back up his data that way. If the drive is imaged, it ensures that if a machine has a hard drive failure, a swift way of getting it back up and running again is available.
Another option available for backups is offsite tape storage with trusted third parties. Vendors offer a wide range of offsite tape vaulting services. These are highly secure facilities that may include secure transportation services, chain-of-custody control for tapes in transit, and environmentally controlled storage vaults.
System Restoration
Disaster recovery planning should include detailed system restoration procedures. This planning should explain any needed configuration details that may be required to restore access and network function. These may include items that can either be general or specific.
The procedure for restoring a server hardware failure, for example, is as follows:
1. Upon discovery, a first responder is to notify the on-duty IT manager. If not on the premises, the manager should be paged or reached via cell phone.
2. The IT manager assesses the damage to determine whether the machine can survive on the UPS. If it can, for how long? If it cannot, what data must be protected before the machine shuts down.
3. Because all equipment is under warranty, no cases should be opened without the consent of the proper vendor.
4. The IT manager will assign a technician to contact the vendor for instructions and a date when a replacement part can be expected.
5. A determination will be made by the IT manager as to whether the organization can survive without the machine until the replacement part is received.
6. If the machine is a vital part of the business, the IT manager must then notify the head of the department affected by the situation and give an assessment of how and when it will be remedied.
7. The IT manager will then find another machine with similar hardware to replace the damaged server.
8. The damaged machine will be shut down properly, if possible, unplugged from the network, and placed in the vendor-assigned work area.
9. The replacement machine will be configured by an assigned technician to ensure it meets the specifications listed in the IT department’s server configuration manual.
10. The most recent backup will be checked out of the tape library by the IT manager. The assigned technician will then restore the data.
11. When the technician has determined that the machine is ready to be placed online, the IT manager will evaluate it to confirm it meets the procedure specifications.
12. The IT manager puts the replacement server in place. Connectivity must be verified, and then the appropriate department head can be notified that the situation has been remedied.
Also a restoration plan should include contingency planning to recover systems and data even in the event of administration personnel loss or lack of availability. This plan should include procedures on what to do if a disgruntled employee changes an administrative password before leaving. Statistics show that more damage to a network comes from inside than outside. Therefore, any key root-level account passwords and critical procedures should be properly documented so that another equally trained individual can manage the restoration process.
Recovery planning documentation and backup media contain many details that an attacker can exploit when seeking access to an organization’s network or data. Therefore, planning documentation, backup scheduling, and backup media must include protections against unauthorized access or potential damage. The data should be protected by at least a password, and preferably encryption. When the backups are complete, they must be clearly labeled so that they can be properly safeguarded. Imagine having to perform a restore for an organization that stores its backup tapes unlabeled in a plastic bin in the server room. The rotation is supposed to be on a two-week basis. When you go to get the needed tape, you discover that the tapes are not marked, nor are they in any particular order. How much time will you spend just trying to find the proper tape? Also, is it a good practice to keep backup tapes in the same room with the servers? What happens if there is a fire?
How backup media is handled is just as important as how it is marked. You certainly don’t want to store CDs in a place where they can easily be scratched or store tapes in an area that reaches 110 degrees Fahrenheit during the day. You should ensure that you also have offsite copies of your backups where they are protected from unauthorized access as well as fire, flood, and other forms of environmental hazards that might impact the main facility. Normal backups should include all data that cannot be easily reproduced. Secure recovery services are another method of offsite storage and security that organizations may consider. In military environments, a common practice is to have removable storage media locked in a proper safe or container at the end of the day.
Exam Prep Questions
1. Which of the following levels of RAID do Windows servers support? (Choose all that apply.)
![]() A. RAID 0
A. RAID 0
![]() B. RAID 1
B. RAID 1
![]() C. RAID 2
C. RAID 2
![]() D. RAID 3
D. RAID 3
![]() E. RAID 4
E. RAID 4
![]() F. RAID 5
F. RAID 5
2. Which of the following backup strategies uses three sets of backups, such as daily, weekly, and monthly, with backup sets rotated on a daily, weekly, and monthly basis?
![]() A. Grandfather, father, son
A. Grandfather, father, son
![]() B. Tower of Hanoi
B. Tower of Hanoi
![]() C. Tower of Pisa
C. Tower of Pisa
![]() D. Grandmother, mother, daughter
D. Grandmother, mother, daughter
3. Which of the following is a type of site similar to the original site in that it has all the equipment fully configured, has up-to-date data, and can become operational with minimal delay?
![]() A. Cold site
A. Cold site
![]() B. Warm site
B. Warm site
![]() C. Hot site
C. Hot site
![]() D. Mirror site
D. Mirror site
4. Which of the following is a type of uninterruptible power supply where power usually derives directly from the power line, until the power fails?
![]() A. Hybrid power supply
A. Hybrid power supply
![]() B. Standby power supply
B. Standby power supply
![]() C. Ferroresonant power supply
C. Ferroresonant power supply
![]() D. Continuous power supply
D. Continuous power supply
5. A system restoration plan should include which of the following? (Select the two best answers)
![]() A. Backup generator procedures
A. Backup generator procedures
![]() B. Procedures for what to do if a disgruntled employee changes an administrative password before leaving
B. Procedures for what to do if a disgruntled employee changes an administrative password before leaving
![]() C. Single points of failure risks
C. Single points of failure risks
![]() D. Contingency planning to recover systems and data even in the event of administration personnel loss
D. Contingency planning to recover systems and data even in the event of administration personnel loss
6. Which of the following aspects of disaster recovery planning details how fast an ISP must have a new Frame Relay connection configured to an alternative site?
![]() A. Impact and risk assessment
A. Impact and risk assessment
![]() B. Disaster recovery plan
B. Disaster recovery plan
![]() C. Disaster recovery policies
C. Disaster recovery policies
![]() D. Service level agreement
D. Service level agreement
7. Which type of backup requires the least amount of time to restore in the event of a total loss?
![]() A. Full
A. Full
![]() B. Daily
B. Daily
![]() C. Differential
C. Differential
![]() D. Incremental
D. Incremental
8. Which of the following statements best describes a disaster recovery plan (DRP)?
![]() A. A DRP reduces the impact of a hurricane on a facility.
A. A DRP reduces the impact of a hurricane on a facility.
![]() B. A DRP is an immediate action plan used to bring a business back on line immediately after a disaster has struck.
B. A DRP is an immediate action plan used to bring a business back on line immediately after a disaster has struck.
![]() C. A DRP attempts to manage risks associated with theft of equipment.
C. A DRP attempts to manage risks associated with theft of equipment.
![]() D. A DRP plans for automatic failover of critical services to redundant offsite systems.
D. A DRP plans for automatic failover of critical services to redundant offsite systems.
9. Redundancy planning includes which of the following? (Choose the two best answers.)
![]() A. RAID
A. RAID
![]() B. UPS placement
B. UPS placement
![]() C. Backup procedures
C. Backup procedures
![]() D. Restoring data
D. Restoring data
10. Full backups are performed weekly on Sunday at 1:00 a.m., and incremental backups are done on weekdays at 1:00 a.m. If a drive failure causes a total loss of data at 8:00 a.m. on Tuesday morning, what is the minimum number of backup files that must be used to restore the lost data?
![]() A. One
A. One
![]() B. Two
B. Two
![]() C. Three
C. Three
![]() D. Four
D. Four
![]() E. Five
E. Five
Answers to Exam Prep Questions
1. A, B, F. Windows servers support striped disk arrays without fault tolerance, mirroring and duplexing, and independent data disks with distributed parity blocks. Answers C, D, and E are incorrect because some implementations of RAID are not used in Microsoft operating systems.
2. A. Grandfather-father-son backup refers to the most common rotation scheme for rotating backup media. Originally designed for tape backup, it works well for any hierarchical backup strategy. The basic method is to define three sets of backups, such as daily, weekly, and monthly. Answer B is incorrect. The Tower of Hanoi is based on the mathematics of the Tower of Hanoi puzzle, with what is essentially a recursive method. It is a “smart” way of archiving an effective number of backups and provides the ability to go back over time, but it is more complex to understand. Answer C is incorrect. The various methods of tape rotation include the grandfather, Tower of Hanoi, and 10-tape rotation schemes. Answer D is incorrect because the method does not exist.
3. C. A hot site is similar to the original site in that it has all the equipment needed for the organization to continue operations, such as hardware and furnishings. Answer A is incorrect because a cold site does not provide any equipment. Answer B is incorrect because a warm site is not similar to the original site. Answer D is incorrect because a mirror site is an exact copy of another Internet site.
4. B. In a standby power supply, power usually derives directly from the power line until power fails. After a power failure, a battery-powered inverter turns on to continue supplying power. Answer A is incorrect because a hybrid device conditions power using a ferroresonant transformer. This transformer maintains a constant output voltage even with a varying input voltage and provides good protection against line noise. Answer C is incorrect because this device conditions power using a ferroresonant transformer. This transformer maintains a constant output voltage even with a varying input voltage and provides good protection against line noise. Answer D is incorrect because in this type of system the computer is always running off of battery power, and the battery is continuously being recharged.
5. B, D. A restoration plan should include contingency planning to recover systems and data even in the event of administration personnel loss or lack of availability. This plan should include procedures that address what to do if a disgruntled employee changes an administrative password before leaving. Answers A and C are incorrect because they are part of disaster recovery planning.
6. D. Service level agreements establish the contracted requirements for service through utilities, facility management, and ISPs. Answer A is incorrect because risk assessment is used to identify areas that must be addressed in disaster recovery provisions. Answers B and C are incorrect because although the disaster recovery plan and its policies may include details of the service level agreement’s implementation, neither is the best answer in this case.
7. A. A full backup includes a copy of all data, so it may be used to directly restore all data and settings as of the time of the last backup. Answers B, C, and D are incorrect because daily, differential, and incremental backups all require a full backup and additional backup files to restore from a total loss of data.
8. B. A DRP is an immediate action plan to be implemented after a disaster. Answer A is incorrect because it describes physical disasters. Answer C is incorrect because it describes loss prevention. Answer D is incorrect because it describes a business continuity plan.
9. A, B. RAID and UPS placement are both part of redundancy planning. Answers C and D are incorrect because backup procedures and restoring data are part of disaster recovery processes.
10. C. Sunday’s full backup must be installed, followed by Monday’s incremental backup, and finally Tuesday morning’s incremental backup. This will recover all data as of 1:00 a.m. Tuesday morning. Answers A and B are incorrect because a full backup Tuesday morning would be required to allow a single-file recovery of all data, whereas a differential backup on Tuesday morning would be required so that only two backup files would be needed. Answers D and E are incorrect because no files from before the last full backup would be required.
Suggested Readings and Resources
1. Schmidt, Klaus. High Availability and Disaster Recovery: Concepts, Design, Implementation. Springer, 2006.
2. Wells, April, Charlyne Walker, Timothy Walker, and David Abarca. Disaster Recovery: Principles and Practices. Prentice Hall, 2006.
3. CERT incident reporting guidelines: http://www.cert.org/tech_tips/incident_reporting.html
4. RAID tutorial: http://www.acnc.com/raid.html
5. SANS Information Security Reading Room: http://www.sans.org/reading_room/?ref=3701