
A fair amount of speculation surrounding Ajax applications concerns the availability of web services. Web services make it possible for developers to request data from sites outside of their direct control (usually), getting a feed of data in response, though sometimes a web service can be completely internal to an organization and be used as a data transportation device as well. Web services is a much talked-about buzzword floating around the web development community, and it is important to have a good handle on what web services are before moving on to using them.
According to the World Wide Web Consortium (W3C), a web service is “a software system designed to support interoperable machine to machine interaction over a network.” What you will see most often on the Web is an API that may be accessed over the Internet and executed on a remote system. Many different types of systems could be defined as web services, but for the purposes of this book I will define web service as a service that uses XML to communicate information between two systems: one that dispenses information and one that requests that information. Figure 17-1 shows a basic diagram of how a web service can be constructed.

Web services are architected in different ways, and though they may vary in how they do their jobs, in the end they all get the job done. Because of the differences in web service architectures, applications must be designed with a specific type of web service in mind in order to utilize it effectively. The most common web service architectures are:
Remote Procedure Call (RPC)
Service-Oriented Architecture (SOA)
Representational State Transfer (REST)
A Remote Procedure Call (RPC) architecture enables an application to start the process of an external procedure while being remote to the system that holds it. In simpler terms, a developer writes code that will call a procedure that could be executed either within the same application or in a remote environment. The developer does not care about the details of this remote action, only the interface it begins to execute and the results of that execution.
The general concept of RPC dates back to the 1970s, when it was described in RFC 707 (http://tools.ietf.org/html/rfc707). Not until the early 1980s, however, were the first implementations of RPC created. Microsoft used its version of RPC (MSRPC) as the basis for DCOM.
RPC fits the classic client/server paradigm for distributed computing. An RPC begins on the client by sending a request to a known remote server so that a specific procedure will be executed, with the client supplying parameters to do so. The code is then executed on the server, and a response is generated and returned back to the client. Here the original application continues to run as though the entire interaction is happening in a local environment. Figure 17-2 shows what this architecture looks like.
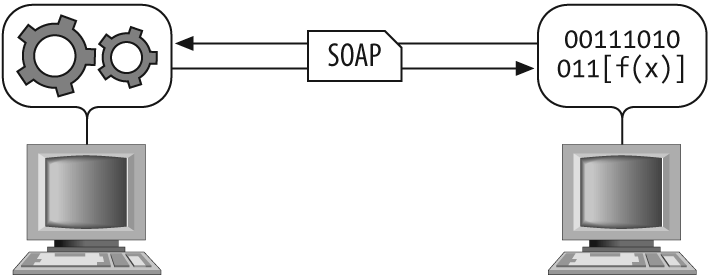
A couple of popular variations on RPC exist in languages such as Java and Microsoft .NET. Java uses the Java Remote Method Invocation (Java RMI) to provide functionality similar to a standard RPC, whereas Microsoft has .NET Remoting to implement RPC for distributed systems in a Windows environment. XML-RPC provides a basic set of tools for creating cross-platform RPC calls, using HTTP as a foundation.
Tip
You can find a lot more on using XML-RPC based web services (and a broader discussion of RPC) in Programming Web Services with XML-RPC by Edd Dumbill et al. (O’Reilly).
An alternative to RPC is to implement a web service with Service-Oriented Architecture (SOA) concepts, where applications are built with loosely coupled services. These services communicate using a formal definition (typically WSDL, discussed shortly) that is independent of the application’s program language and the operating system in which it resides. The individual services are accessed without any knowledge of their underlying resource dependencies.
SOA has many definitions, and groups such as the Organization for the Advancement of Structured Information Standards (OASIS; http://www.oasis-open.org/home/index.php) and the Open Group (http://www.opengroup.org/) have created formal definitions that can be applied to both technology and business. SOA adoption is thought to help the response time for changing market conditions, something that saves money in businesses. It also promotes reuse among components, a concept that is not new in programming circles. No matter what the belief, definition, or benefits, SOA has the following qualities:
It is modular, interoperable, reusable, and component-based.
It is standards-compliant.
It has identifiable services, providing deliverables, with monitoring and tracking.
Combining SOA techniques with web services basically gives us the web services protocol stack, a collection of network protocols that are used to define and implement how web services interact with one another.
SOA implementations rely on several standards to implement web services. These include XML, HTTP/HTTPS, SOAP, WSDL, and UDDI. A system does not have to have all of these standards to be considered an SOA, however.
By following standards when using and creating web services, a developer can ensure that the services will work as expected, without having to understand anything about those services. I discuss XML in detail in Appendix A. A thorough discussion of HTTP/HTTPS is outside the scope of this book; however, a good source of information is HTTP: The Definitive Guide by David Gourley and Brian Totty (O’Reilly). The standards that we will discuss here, at least in enough detail to understand their roles in web services, are SOAP, WSDL, and UDDI.
SOAP, now an empty acronym, used to be the Simple Object Access Protocol, and sometimes is expanded as Service-Oriented Access Protocol. SOAP is an XML-based protocol for passing information back and forth over a network. Defined using XML, SOAP is a very flexible protocol that does not rely on a single language to produce or use it. This flexibility, in turn, allows programs written in different languages on different operating systems to still communicate effectively. A typical example, especially with web services, is a web application written in ASP.NET on a Windows 2003 Server communicating with a web service written in Perl on an Ubuntu Linux server.
SOAP is a relatively simple and straightforward protocol that has been developed as a W3C recommendation. The latest version, the SOAP Version 1.2 Recommendation from June 24, 2003, is divided into parts, the starting point being the “SOAP Version 1.2 Part 0: Primer (Second Edition),” located at http://www.w3.org/TR/soap12-part0/.
Certain elements are required to make up a proper SOAP document:
An envelope
A body
In addition, there are optional elements:
A header
A fault
All of these elements are declared in the default namespace for SOAP, while the data types and element encoding are contained in their own namespace.
When creating a new SOAP document, you must remember the following syntax rules to ensure that the document is structured properly:
A SOAP message must be an XML encoded document.
A DTD reference must not be included in a SOAP document.
XML processing instructions must not be included in a SOAP document.
The SOAP
Envelopenamespace must be used in the document.The SOAP
Encodingnamespace must be used in the document.
Following these syntax rules, the basic skeleton for SOAP looks like this:
<?xml version="1.0" encoding="utf-8"?>
<soap:Envelope xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Header>
<!-- Header information -->
</soap:Header>
<soap:Body>
<!-- Body Information -->
</soap:Body>
</soap:Envelope>Example 17-1 shows what a request may look like using Amazon Web Services (AWS) to get details regarding this book. The Amazon Standard Item Number (ASIN) is how Amazon tracks every item that it sells. In the case of books, the ASIN is the same as the book’s ISBN.
Example 17-1. A SOAP request using AWS
<?xml version="1.0" encoding="utf-8" ?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<SOAP-ENV:Body>
<namesp1:AsinSearchRequest xmlns:namesp1="urn:PI/DevCentral/SoapService">
<AsinSearchRequest xsi:type="m:AsinRequest">
<asin>0596528388</asin>
<page>1</page>
<mode>books</mode>
<tag>associate tag</tag>
<type>lite</type>
<dev-tag>developer token</dev-tag>
<format>xml</format>
<version>1.0</version>
</AsinSearchRequest>
</namesp1:AsinSearchRequest>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>Refer to Appendix C for more information on AWS and how to use it.
Once Amazon receives this request, its service will process it and return an XML response to the client. In this request, the response is an XML document specific to Amazon’s products, as was requested in the SOAP request. Many times, a SOAP request will be answered with a SOAP response because there is no choice for a response format. It is important to know what you will be receiving from the web service when you make a request!
Web Services Description Language (WSDL) is an XML-based protocol used to describe web services, what public methods are available to them, and where the service is located. There is a W3C Note for WSDL, called “Web Services Description Language (WSDL) 1.1” and first made available in March 2001 (you can find it at http://www.w3.org/TR/wsdl). In July 2002, a Working Draft of WSDL 1.2 was released. Though technically not a W3C Recommendation, WSDL is pretty much the universally accepted protocol for describing web services.
Six major elements are included in a WSDL document:
The data types that the web service uses
The messages that the web service uses
The operations that the web service performs
The communication protocols that the web service uses
The individual binding addresses
The aggregate of a set of related ports
A WSDL document may contain other elements, and it can group together definitions of several web services into one WSDL document. Take a look at the W3C Note for more information on these elements. The structure of the document, according to the W3C Note, looks like this:
<wsdl:definitions name="nmtoken"? targetNamespace="uri"?>
<import namespace="uri" location="uri"/>*
<wsdl:documentation .... /> ?
<wsdl:types> ?
<wsdl:documentation .... />?
<xsd:schema .... />*
<-- extensibility element --> *
</wsdl:types>
<wsdl:message name="nmtoken"> *
<wsdl:documentation .... />?
<part name="nmtoken" element="qname"? type="qname"?/> *
</wsdl:message>
<wsdl:portType name="nmtoken">*
<wsdl:documentation .... />?
<wsdl:operation name="nmtoken">*
<wsdl:documentation .... /> ?
<wsdl:input name="nmtoken"? message="qname">?
<wsdl:documentation .... /> ?
</wsdl:input>
<wsdl:output name="nmtoken"? message="qname">?
<wsdl:documentation .... /> ?
</wsdl:output>
<wsdl:fault name="nmtoken" message="qname"> *
<wsdl:documentation .... /> ?
</wsdl:fault>
</wsdl:operation>
</wsdl:portType>
<wsdl:binding name="nmtoken" type="qname">*
<wsdl:documentation .... />?
<-- extensibility element --> *
<wsdl:operation name="nmtoken">*
<wsdl:documentation .... /> ?
<-- extensibility element --> *
<wsdl:input> ?
<wsdl:documentation .... /> ?
<-- extensibility element -->
</wsdl:input>
<wsdl:output> ?
<wsdl:documentation .... /> ?
<-- extensibility element --> *
</wsdl:output>
<wsdl:fault name="nmtoken"> *
<wsdl:documentation .... /> ?
<-- extensibility element --> *
</wsdl:fault>
</wsdl:operation>
</wsdl:binding>
<wsdl:service name="nmtoken"> *
<wsdl:documentation .... />?
<wsdl:port name="nmtoken" binding="qname"> *
<wsdl:documentation .... /> ?
<-- extensibility element -->
</wsdl:port>
<-- extensibility element -->
</wsdl:service>
<-- extensibility element --> *
</wsdl:definitions>This may not mean a whole lot to anyone that does not enjoy reading through the entire specification for a piece of technology. Therefore, here is a brief explanation of the different parts:
typesThe
typeselement uses XML Schema syntax to define the data types that the web service will use.messagesThe
messageselement defines the individual data elements of a web service function. The message normally consists of one, and possibly more, parts that define what the web service can be passed.port typesThe
port typeselement has the important job of describing a web service, from the methods it has exposed to any messaging that is involved.bindingsThe
bindingselement details the messages and protocols that will be used for each port of the web service.portsThe
portselement defines the individual bindings of the web service, specifying address information.servicesThe
serviceselement groups a set of individual ports together in the web service.
Example 17-1 showed the portions of the AWS WSDL document, and Example 17-2 is the portion of the document that pertains to our SOAP request in Example 17-1.
Example 17-2. The AWS WSDL document (portions of it, at least)
<wsdl:definitions xmlns:typens="http://soap.amazon.com"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns="http://schemas.xmlsoap.org/wsdl/"
targetNamespace="http://soap.amazon.com" name="AmazonSearch">
<wsdl:types>
<xsd:schema xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://soap.amazon.com">
<xsd:complexType name="ProductLineArray">
<xsd:complexContent>
<xsd:restriction base="soapenc:Array">
<xsd:attribute ref="soapenc:arrayType"
wsdl:arrayType="typens:ProductLine[]"/>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
<xsd:complexType name="ProductLine">
<xsd:all>
<xsd:element name="Mode" type="xsd:string" minOccurs="0"/>
<xsd:element name="ProductInfo" type="typens:ProductInfo"
minOccurs="0"/>
</xsd:all>
</xsd:complexType>
<xsd:complexType name="ProductInfo">
<xsd:all>
<xsd:element name="TotalResults" type="xsd:string"
minOccurs="0"/>
<xsd:element name="TotalPages" type="xsd:string"
minOccurs="0"/>
<xsd:element name="ListName" type="xsd:string"
minOccurs="0"/>
<xsd:element name="Details" type="typens:DetailsArray"
minOccurs="0"/>
</xsd:all>
</xsd:complexType>
<xsd:complexType name="DetailsArray">
<xsd:complexContent>
<xsd:restriction base="soapenc:Array">
<xsd:attribute ref="soapenc:arrayType"
wsdl:arrayType="typens:Details[]"/>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
<xsd:complexType name="Details">
<xsd:all>
<xsd:element name="Url" type="xsd:string" minOccurs="0"/>
<xsd:element name="Asin" type="xsd:string" minOccurs="0"/>
<xsd:element name="ProductName" type="xsd:string"
minOccurs="0"/>
<xsd:element name="Catalog" type="xsd:string"
minOccurs="0"/>
<!-- Edited for length -->
<xsd:element name="Authors" type="typens:AuthorArray"
minOccurs="0"/>
<xsd:element name="ListPrice" type="xsd:string"
minOccurs="0"/>
<xsd:element name="OurPrice" type="xsd:string"
minOccurs="0"/>
<xsd:element name="UsedPrice" type="xsd:string"
minOccurs="0"/>
<xsd:element name="NumberOfPages" type="xsd:string"
minOccurs="0"/>
</xsd:all>
</xsd:complexType>
<xsd:complexType name="AuthorArray">
<xsd:complexContent>
<xsd:restriction base="soapenc:Array">
<xsd:attribute ref="soapenc:arrayType"
wsdl:arrayType="xsd:string[]"/>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
<xsd:complexType name="AsinRequest">
<xsd:all>
<xsd:element name="asin" type="xsd:string"/>
<xsd:element name="tag" type="xsd:string"/>
<xsd:element name="type" type="xsd:string"/>
<xsd:element name="devtag" type="xsd:string"/>
<xsd:element name="offer" type="xsd:string"
minOccurs="0"/>
<xsd:element name="offerpage" type="xsd:string"
minOccurs="0"/>
<xsd:element name="locale" type="xsd:string"
minOccurs="0"/>
</xsd:all>
</xsd:complexType>
</xsd:schema>
</wsdl:types>
<message name="AsinSearchRequest">
<part name="AsinSearchRequest" type="typens:AsinRequest"/>
</message>
<message name="AsinSearchResponse">
<part name="return" type="typens:ProductInfo"/>
</message>
<portType name="AmazonSearchPort">
<operation name="AsinSearchRequest">
<input message="typens:AsinSearchRequest"/>
<output message="typens:AsinSearchResponse"/>
</operation>
</portType>
<binding name="AmazonSearchBinding" type="typens:AmazonSearchPort">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="AsinSearchRequest">
<soap:operation soapAction="http://soap.amazon.com"/>
<input>
<soap:body use="encoded"
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://soap.amazon.com"/>
</input>
<output>
<soap:body use="encoded"
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://soap.amazon.com"/>
</output>
</operation>
</binding>
<service name="AmazonSearchService">
<port name="AmazonSearchPort" binding="typens:AmazonSearchBinding">
<soap:address location="http://soap.amazon.com/onca/soap2"/>
</port>
</service>
</wsdl:definitions>This document defines everything about AWS in terms of the ASIN search; it contains definitions for all of the other search capabilities that Amazon provides, but I included only the relevant parts in the example.
Universal Discovery, Description, and Integration (UDDI) was announced in 2000 as the joint work of Microsoft, IBM, and Ariba. Since its inception, the number of companies that are UDDI sponsors, contributors, liaisons, representatives, and so on has increased enormously, though UDDI is not used as frequently as SOAP or WSDL. To see a list of these companies, visit http://www.oasis-open.org/about/index.php.
UDDI provides a directory of web services that is searchable by client. There are two main parts to UDDI: the specification for how to hold all of the information, and the implementation of the specification. In 2001, Microsoft and IBM launched the first two publicly available UDDI registries. The registries allowed everyone interested to search for web services as well as register a new web service to be made searchable, though public UDDI directories never really took off.
UDDI directories are not limited to web services, and can contain services based on a number of protocols and technologies such as telephone, FTP, email, CORBA, SOAP, and Java RMI.
Tip
Understanding Web Services: XML, WSDL, SOAP, and UDDI by Eric Newcomer (Addison-Wesley Professional) is a good source of information on using web services and how they are created in an SOA environment.
Representational State Transfer (REST) is a method of transporting media primarily over the World Wide Web, though it is not restricted to this. It is designed for any hypermedia system—the Web is just the largest. The term REST comes from Roy Fielding’s 2000 doctoral dissertation about the Web. The term defines architectural principles on transfer over systems, but it is loosely tied to transferring data over HTTP without the use of an additional messaging layer, such as SOAP.
The key components for a RESTful design are as follows:
The state and functionality of an application are separated into different resources.
Every resource shares a consistent method for the transfer of state between resources.
Every resource is addressable using hypermedia syntax.
It is a protocol that is stateless, cacheable, client/server-based, and layered.
The World Wide Web is a perfect example of a RESTful
implementation, as it can be made to conform to the REST principles.
HTML has implicit support for hyperlinks built into the language.
HTTP has a consistent method (GET, POST,
PUT, and DELETE) to
access resources from URIs, methods, status codes, and headers. HTTP
is stateless (unless cookies are utilized), has the ability to
control caching, utilizes the notion of a client and a server, and
is layered so that no layer can know anything about another except
for its immediate conversation (connection).
For REST applications, the resource that defines its interface is constrained so that fewer types are defined on the network and more resources are defined. You can think of the interface as verbs, and the content types and resource identifiers as nouns. REST defines the nouns to be unconstrained so that clients do not need knowledge of the whole resource. Figure 17-3 shows the REST triangle of nouns, verbs, and content types.

The architecture we use for the applications we build ultimately depends on the web services with which the architecture will interact. When we know that the only interface to a web service is through SOAP, it might naturally be easier to define the architecture of the application to follow SOA. On the other hand, if the web service is RESTful in nature, building the application to follow REST would more likely be in order. Even more likely, one component of an application will be built one way and another component a different way. The application on the whole takes whatever architectural style is needed for the project (client/server, Model-View-Controller [MVC], etc.), while the components follow their own models to be as efficient as possible.
We’ve covered the basics, and now you know everything you need to get started using web services. It was the norm awhile ago to call a web service from a server script; the script would collect the data from the service, do its thing, and then send a new page to the client. It worked, at least as far as the user was concerned, as any other page on the Web did, so there was no way for him to know a web service was involved with this process.
Just like everything else, though, Ajax brings about new and fresh ways to look at existing technologies. Data gathered from a web service can now be placed on a page without an entire page reload, as you already know. The “wow” can be put into using web services, and they have a real place in web applications (and in particular, Ajax applications) today.
For the most part, any client request for a web service is
handled in one of two ways. Requests are made using a hidden
<iframe> or <frame> element to handle the
sending and receiving, and then the data is collected from the
frames. Or, a call is made to a server script that handles the
sending and receiving, and the client gets the data from the
server-side script’s response.
Why is this? Simply because of the (necessary) limitations placed on JavaScript with respect to calling pages on different domains. This is our sandbox, which we have seen before in this book. The two methods are simply ways of handling any restrictions a client may have.
There are exceptions, of course—in this case, the exception comes when the web services being contacted reside on the same domain as the page being called.
Up to this point, almost all of our examples of client requests to the server have fit a RESTful-like pattern. Unless there is some huge need for a different method, passing parameters to the server to define action and state is an easy way to implement a web service request. What we need to worry about is getting the data from a web service not located on our domain. The same domain communication will look the same, the server handles all of the requests to other servers, or it is the web service—either way, the request will look the same. Example 17-3 shows what the request will generally look like for all calls for a web service.
Example 17-3. The client request for a web service
/*
* Example 17-3. The client request for a web service.
*/
new Ajax.Request('amazon.php', {
method: 'get',
parameters: { asin: '0596528388' },
onSuccess: distributeResults
});Once the server sends back the data—in a format that the client will be expecting, no matter where it is from—it will parse and display the results in whatever manner is necessary. I believe I have covered this enough that I can leave it to your imagination as to what to do. For reference and to get some ideas, look over the chapters in Part II.
Say that five times fast! Seriously, using PHP to access web services is fairly simple. The one detail that is necessary to address is whether the web service interfaces with SOAP or REST. This will determine what our server script will look like.
Think of this server-side script as an intermediary between the client and the web service. The client does not have to speak the web service’s language, and in turn the web service does not have to speak the client’s language. Our server script will handle all of the details. The advantage to this is that the intermediary takes care of all the parsing details instead of the client, which should offer some speed improvements.
PHP has a built-in class extension to the language to handle SOAP. Example 17-4 shows how this works.
Example 17-4. A SOAP request to AWS using PHP
<?php
/**
* Example 17-4. A SOAP request to AWS using PHP.
*
* This example shows how to create a SOAP request using PHP's SOAP extension to
* an AWS method.
*/
/* Create a new instance of the SOAP client class */
$client = new SoapClient('http://soap.amazon.com/schemas2/AmazonWebServices.wsdl'),
/* Create the parameters that should be passed */
$params = Array(
'asin' => mysql_real_escape_string($_REQUEST['asin']),
'type' => 'lite',
'tag' => '[associates id]',
'devtag' => '[developer token]'
) ;
/* Call the AWS method */
$result = $client->ASINSearchRequest($params);
?>SOAP functions are capable of returning one or multiple values. When there is only one value, the return value of the method will be a simple variable type. If multiple values are returned, however, the method will return an associative array of named output parameters.
Example 17-4 calls the
ASINSearchRequest( ) method that
is available with AWS. Other methods are also available, and each
provides different search capabilities should the developer need
them. Table 17-1 lists all of the
methods available with AWS.
Table 17-1. Methods available with AWS
Method | Description |
|---|---|
| Performs an Amazon product code search and returns detailed information on the product. |
| Performs a node search and returns a list of catalog items attached to the node. |
| Performs a keyword search and returns the resulting products. |
| Performs an advanced search and returns the resulting products. |
| Performs a search for products listed by third-party sellers and returns the resulting products. |
| Performs a search for items similar to a particular product code and returns the resulting products. |
The following is an example of what the SOAP request will return:
Array ( [Details] => Array ( [0] => Array ( [Url] => http://www.amazon.com/gp/product/0596528388%3ftag=[associates id]%26link_code=xm2%26camp=2025%26dev-t=[developer token][Asin] => 0596528388 [ProductName] => Ajax: The Definitive Guide [Catalog] => Book [Authors] => Array ( [0] => Anthony T. Holdener III ) [ReleaseDate] => 15 January, 2008 [Manufacturer] => O'Reilly Media [ImageUrlSmall] => http://images.amazon.com/images/P/0596528388.01.THUMBZZZ.jpg [ImageUrlMedium] => http://images.amazon.com/images/P/0596528388.01.MZZZZZZZ.jpg [ImageUrlLarge] => http://images.amazon.com/images/P/0596528388.01.LZZZZZZZ.jpg [ListPrice] => $49.99 [OurPrice] => $32.99 [UsedPrice] => $24.50 [Availability] => Usually ships within 24 hours ) )
Then there is the REST way of handling things. Fortunately for us, AWS supports both SOAP and REST, so if I do not like the SOAP way of using the web service, I can use the REST methods. First, an XML Link must be created to pass to the AWS service. The structure of the XML Link is:
http://xml.amazon.com/onca/xml3?t=[associates id]&dev-t=[developer token]&[Search Type]=[Search Term]&mode=books&sort=[Sort]&offer=All&type=[Type]& page=[Page Number]&f=xml
Table 17-2 lists the parameters needed in the XML Link for it to be complete as far as AWS is concerned. Another cool thing Amazon has available for use with its web services is the ability to create the XML Link using its XML Scratch Pad, found at http://www.amazon.com/gp/browse.html/?node=3427431.
Table 17-2. Available XML Link options
Description | |
|---|---|
Search type | The type of search to perform:
|
Search term | This is dependent on
the search type, and should correspond to it. For example,
an |
Sort | The sort to be used on the search:
|
Type | The type of search results to display:
|
Page number | The page number of the search results to jump to. |
The data from a request of this nature will be an XML document with the following structure:
<Details url="http://www.amazon.com/gp/product/0596528388%3ftag=[associates id]%26link_code=xm2%26camp=2025%26dev-t=[developer token]"> <Asin>0596528388</Asin> <ProductName>Ajax: The Definitive Guide</ProductName> <Catalog>Book</Catalog> <Authors> <Author>Anthony T. Holdener III</Author> </Authors> <ReleaseDate>1 January, 2008</ReleaseDate> <Manufacturer>O'Reilly Media</Manufacturer> <ImageUrlSmall> http://images.amazon.com/images/P/0596528388.01.THUMBZZZ.jpg </ImageUrlSmall> <ImageUrlMedium> http://images.amazon.com/images/P/0596528388.01.MZZZZZZZ.jpg </ImageUrlMedium> <ImageUrlLarge> http://images.amazon.com/images/P/0596528388.01.LZZZZZZZ.jpg </ImageUrlLarge> <ListPrice>$49.99</ListPrice> <OurPrice>$31.49</OurPrice> <Availability>Usually ships in 24 hours</Availability> <UsedPrice>$24.50</UsedPrice> </Details>
We’ve seen how to parse returned XML using PHP before, and Example 17-5 shows this.
Example 17-5. A REST request to AWS using PHP
<?php
/**
* Example 17-5. A REST request to AWS using PHP.
*
* This example shows how to create a REST request using PHP to an AWS method.
*/
$assoc_id = '[associate id]';
$dev_token = '[developer token]';
$xml_link = sprintf('http://xml.amazon.com/onca/xml3?t=%s&dev-t=%s&AsinSearch=
%s&mode=books&type=lite&f=xml',
$assoc_id,
$dev_token,
urlencode($_REQUEST['asin'])
);
$results = file_get_contents($xml_link);
?>Once the server has captured the data, whether the request was from SOAP or REST, it should be formatted in such a way that the client can parse it quickly. Using Example 17-5 as the model for getting the data from the server, all we must do is modify the last part to create an XML document the client will use. Example 17-6 shows what this looks like.
Example 17-6. Gathering the AWS response and formatting it for the client
<?php
/**
* Example 17-6. Gathering the AWS response and formatting it for the client.
*
* This example shows how to create a REST request using PHP to an AWS method,
* and how to parse and format the results.
*/
$assoc_id = '[associate id]';
$dev_token = '[developer token]';
$xml_link = sprintf('http://xml.amazon.com/onca/xml3?t=%s&dev-t=%s'
.'&AsinSearch=%s&mode=books&type=lite&f=xml',
$assoc_id,
$dev_token,
urlencode($_REQUEST['asin'])
);
$results = file_get_contents($xml_link);
$xml = new SimpleXMLElement($results);
/* Was there a problem with the search query? */
if ($xml->faultstring) {
$response = '<response code="500">'.$xml->faultstring.'</response>';
} else {
$response = '<response code="200">';
$response .= '<title>';
$response .= '<name>'.$xml->details[0]->ProductName.'</name>';
$response .= '<author>';
$authors = '';
/* Loop through authors and concatenate any names */
foreach ($xml->details[0]->authors->author as $author) {
/* Should a comma be added? */
if (strlen($authors))
$authors .= ', ';
$authors .= $author;
}
$response .= $authors.'</author>';
$response .= '<date>'.date('F j, Y',
strottime($xml->details[0]->ReleaseDate)).'</date>';
$response .= '<publisher>'.$xml->details[0]->Manufacturer.'</publisher>';
$response .= '<img_src>'.$xml->details[0]->ImageUrlSmall.'</img_src>';
$response .= '<availability>'.$xml->details[0]->Availability.'</availability>';
$response .= '<list_price>'.$xml->details[0]->ListPrice.'</list_price>';
$response .= '<amazon_price>'.$xml->details[0]->OurPrice.'</amazon_price>';
$response .= '</title>';
$response .= '</response>';
}
/*
* Change the header to text/xml so that the client can use the return string
* as XML
*/
header('Content-Type: text/xml'),
/* Give the client the XML */
print($response);
?>We have the data formatted the way we want the server to get it, and it should look something like this:
<response code="200">
<title>
<name>Ajax: The Definitive Guide</name>
<author>Anthony T. Holdener III</author>
<date>January 1, 2008</date>
<publisher>O'Reilly Media</publisher>
<img_src>
http://images.amazon.com/images/P/0596528388.01.THUMBZZZ.jpg
</img_src>
<availability>Usually ships in 24 hours</availability>
<list_price>$49.99</list_price>
<amazon_price>$31.49</amazon_price>
</title>
</response>Notice that the <response> element has a code attribute attached to it. I am using
HTTP status codes to show the status of the request, because passing
these codes to the client will help it determine what to show the
user. Table 17-3 shows
possible codes that could be passed to the client.
Table 17-3. Possible status codes for the results
Code | Status | Description |
|---|---|---|
200 | OK | The request was successful. |
204 | No Content | The request was successful but there was no content with the response. |
400 | Bad Request | The request had bad formatting in it, causing it to fail. |
404 | Not Found | The web service being requested cannot be found. |
408 | Request Timeout | The request to the service failed in the time allowed by the server. |
500 | Internal Server Error | The server had a problem either getting data or parsing the results. |
503 | Service Unavailable | The web service had a temporary overload and could not process the request. |
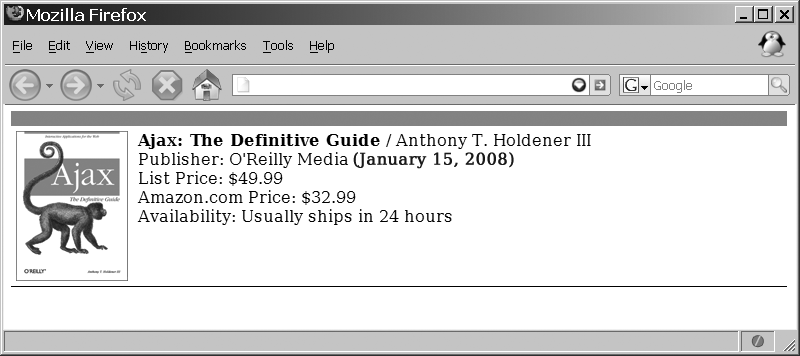
Now that the data has been sent to the client, it can be parsed easily and the results can be displayed to the user. Figure 17-4 gives an example of how the client could format the data.
Another way to access data is through a web feed. Web feeds are also XML-based documents that are structured with either RSS or Atom. You may remember these protocols from Chapter 1 when I was discussing syndication. Feeds are generated in a number of ways, and are not as “flashy” as web services because they are static in nature.
One way you can make a feed is by writing a script that visits pages and scrapes data from them. Web scraping is not the noblest way to get data, and it could break laws if you take copyrighted material from a site and use it on yours without proper authorization. Laws vary by state and country, but I recommend avoiding this practice and using more readily available information through syndicated feeds.
Using a syndicated web feed to gather information is a good way to create your own web services to use on your site. Feeds can be pulled down by your server script and then disseminated to clients when the information is requested. This is a good solution for quickly collecting headlines and descriptions from a source that might not provide web services to grab information. The only big disadvantage to using syndicated resources is that you are at the mercy of the provider. Whatever content the provider wishes to place in a feed is what you will get; there is no choice on the developer’s part.
What is good about feeds, however, is that you can find feed aggregators to do some of the work for you. Aggregators basically gather feeds from content providers and aggregate them in a number of ways to make it easier to get data for your application. A good example of this is Google Reader, found at http://www.google.com/reader. This application takes feeds from different sources (in real time) and allows subscribers to customize their choices. Using feeds, you keep your application completely up-to-date.
Tip
What Are Syndication Feeds, by Shelley Powers (O’Reilly), is a good primer on feeds and how to use them.
There is nothing new about syndication, RSS, or Atom unless you create a new web service that aggregates feeds and sends them to the client. This creates a service that distributes the information you want without you having to be the keeper of the data (and dealing with all of the hassle that goes along with that).
For example, consider this feed from Yahoo! Weather (http://weather.yahooapis.com/forecastrss?p=62221):
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<rss version="2.0" xmlns:yweather="http://xml.weather.yahoo.com/ns/rss/1.0"
xmlns:geo="http://www.w3.org/2003/01/geo/wgs84_pos#">
<channel>
<title>Yahoo! Weather - Belleville, IL</title>
<link>
http://us.rd.yahoo.com/dailynews/rss/weather/Belleville_ _IL/*
http://weather.yahoo.com/forecast/62221_f.html
</link>
<description>Yahoo! Weather for Belleville, IL</description>
<language>en-us</language>
<lastBuildDate>Tue, 13 Mar 2007 11:55 am CDT</lastBuildDate>
<ttl>60</ttl>
<yweather:location city="Belleville" region="IL" country="US" />
<yweather:units temperature="F" distance="mi" pressure="in" speed="mph" />
<yweather:wind chill="77" direction="210" speed="14" />
<yweather:atmosphere humidity="50" visibility="1609"
pressure="30.07" rising="2" />
<yweather:astronomy sunrise="7:15 am" sunset="7:05 pm" />
<image>
<title>Yahoo! Weather</title>
<width>142</width>
<height>18</height>
<link>http://weather.yahoo.com/</link>
<url>http://l.yimg.com/us.yimg.com/i/us/nws/th/main_142b.gif</url>
</image>
<item>
<title>Conditions for Belleville, IL at 11:55 am CDT</title>
<geo:lat>38.5</geo:lat>
<geo:long>-90</geo:long>
<link>
http://us.rd.yahoo.com/dailynews/rss/weather/Belleville_ _IL/*
http://weather.yahoo.com/forecast/62221_f.html
</link>
<pubDate>Tue, 13 Mar 2007 11:55 am CDT</pubDate>
<yweather:condition text="Fair" code="34" temp="77"
date="Tue, 13 Mar 2007 11:55 am CDT" />
<description>
<![CDATA[
<img src="http://l.yimg.com/us.yimg.com/i/us/we/52/34.gif" /><br />
<b>Current Conditions:</b><br />
Fair, 77 F<BR /><BR />
<b>Forecast:</b><BR />
Tue - Partly Cloudy. High: 81 Low: 58<br />
Wed - Partly Cloudy. High: 76 Low: 55<br />
<br />
<a href="http://us.rd.yahoo.com/dailynews/rss/weather/
Belleville_ _IL/*http://weather.yahoo.com/forecast/62221_f.html">
Full Forecast at Yahoo! Weather
</a><BR/>
(provided by The Weather Channel)<br/>
]]>
</description>
<yweather:forecast day="Tue" date="13 Mar 2007" low="58" high="81"
text="Partly Cloudy" code="30" />
<yweather:forecast day="Wed" date="14 Mar 2007" low="55" high="76"
text="Partly Cloudy" code="30" />
<guid isPermaLink="false">62221_2007_03_13_11_55_CDT</guid>
</item>
</channel>
</rss>Warning
Be careful when elements in an RSS or Atom feed contain namespace prefixes. These elements are harder to traverse, and usually an XPath solution works best.
A little bit of PHP code can turn this feed into a REST web service without any trouble. Example 17-7 shows how to do this.
Example 17-7. Using feeds to distribute information with PHP
<?php
/**
* Example 17-7. Using feeds to distribute information with PHP.
*
* This example shows how to take an RSS feed and strip out the information
* desired by the application, giving only a minimal amount of data to the
* client.
*/
/* Get the RSS feed from Yahoo! for my zip code */
$results = file_get_contents('http://weather.yahooapis.com/forecastrss?p=62221'),
$xml = new SimpleXMLElement($results);
/* Create the XML for the client */
$response = '<response code="200">';
$response .= '<weather>';
/* Create the prefix context for the XPath query */
$xml->registerXPathNamespace('y', 'http://xml.weather.yahoo.com/ns/rss/1.0'),
/* Gather the temperature data */
$temp = $xml->xpath('//y:condition'),
/* Fill in information for the client */
$response .= '<temp>'.$temp[0]['text'].', '.$temp[0]['temp'].' °F</temp>';
$response .= '<img>'.$xml->channel->image->url.'</img>';
$response .= '<link>'.$xml->channel->image->link.'</link>';
$response .= '</weather>';
$response .= '</response>';
/*
* Change the header to text/xml so that the client can use the return string
* as XML
*/
header('Content-Type: text/xml'),
/* Give the client the XML */
print($response);
?>You could easily change this code to point to several different sources, aggregate that information, and then send it out for the client to display. The whole point of this is so that an Ajax call can be made—say, every 15 minutes—to update the application with the latest information. Figure 17-5 gives an example of this.

It is all well and good to collect information from different sources using RSS feeds, but how do you know you are getting what you expect? Feed validation services are available to check the validity of a feed so that you can be more certain that your application will work with it. A good idea is to periodically check a feed’s validity to ensure that your aggregation service is working. Better yet, write an application that does the feed validation for you automatically.
There are a number of feed validators to choose from; here are a few to get you started:
- Feed Validator (http://feedvalidator.org/)
This validator is extremely versatile and can check RSS 0.90, 0.91, 0.92, 0.93, 0.94, 1.0, and 2.0 feeds as well as Atom feeds. This validator is the creation of Sam Ruby and Mark Pilgrim.
- W3C Validator (http://validator.w3.org/feed/)
This is the W3C validator for checking the validity of RSS and Atom feeds. It works in the same manner as the W3C HTML/XHTML and CSS validators.
- Redland RSS 1.0 Validator (http://librdf.org/rss/)
This validator from Dave Beckett validates and formats results for display.
- Experimental Online RSS 1.0 Validator (http://www.ldodds.com/rss_validator/1.0/validator.html)
This is a prototype validator based on a Schematron schema for validating RSS 1.0. This validator is by Leigh Dodds.
- RSS Validator (http://rss.scripting.com/)
This is a feed validation service that tests the validity of RSS 0.9x feeds.
Chances are good that there’s a web service capable of handling whatever a developer needs. When you find a web service that you want to use, hopefully an API will be available for you to reference. These APIs are invaluable when you’re interacting with web services—unless you truly enjoy reading through a bunch of WSDL documents (if they even exist).
The API is the easiest means by which a developer can create a way to interact with an existing service as it was intended. This not only creates the opportunity for cleaner code, but it will also reduce the amount of time needed to create the methods of interaction. In the next chapter, we will focus exclusively on web service APIs, where to find them, and how to use them.