
As we noted in chapter 1, for many people who deal with electronic media, “audience research” means nothing more than “ratings research.” While that view is certainly not held by everyone in the business, it is true that no other form of audience measurement so dominates the industry. For this reason, our focus in the next two chapters is on the analysis and interpretation of ratings information.
Once audience data are collected, edited, and reported, it is up to the analyst to interpret their meaning. Fortunately, there is no need to reinvent the wheel every time you are tasked with analyzing this kind of audience data; researchers in the media industries and in academia have already developed many useful analytical strategies. Learning these techniques has two important advantages. First, they have been tested, and their strengths and limitations are well known. Second, standardization of analytical techniques has many benefits. Comparisons of one sort or another play an important part in ratings analysis. If everyone calculated the cost of reaching the audience differently, for example, meaningful comparisons would be difficult or impossible to make, thus limiting the utility of the analysis. This has become a major concern for programmers and advertisers who want to compare the cost of media across different platforms. Standardization can help us build a systematic body of knowledge about audiences and their role in the operation of electronic media. If one study can be directly related to the next, progress and/or dead ends can be more readily identified.
In chapter 4, we defined gross and cumulative measurements. Following this distinction, we have organized analytical techniques into two chapters—those that deal with gross measures and those that deal with cumulative measures. We recognize that this distinction is not always obvious. Analyses of one sort are often coupled with the other; and there can be strict mathematical relationships between the two. However, this scheme of organization can help the reader manage a potentially bewildering assortment of ways to manipulate the data.
Within each chapter, we go from the least complicated analytical techniques to the most complicated. Unfortunately, as we make this progression, our language becomes increasingly complex and arcane, but we try to keep the technical jargon to a minimum. The majority of analytical techniques described require only an understanding of simple arithmetic. Some, however, involve the use of multivariate statistics.
We begin by reviewing metrics that are commonly used in broadcasting. Many of these measures date back to the early days of radio. Gross measures can be thought of as snapshots of the audience taken at a point in time. Included in this category are the measures themselves (e.g., ratings and shares), any subsequent manipulations of those measures (e.g., totaling GRPs), or analyses of the measures using additional data (e.g., calculating the cost to reach 1 percent of the audience, the “cost per point” or CPP). Excluded from this category are audience measurements that require tracking individual audience members over time.
Throughout the book, we have made frequent use of terms like ratings and share. Although basic definitions of these terms were provided in chapter 4, they ignored a good many nuances that an analyst should know. In fact, it is important to recognize that these measures are themselves a kind of first-order data analysis. Ratings, shares, and gross audience projections are all the result of mathematical operations being applied to the database.
Projected audiences are the most basic gross measurements of the audience. In this context, “projection” means going from the sample to an estimate of what is happening in the population. It should not be confused with predicting future audiences. These projections are estimates of absolute audience size, intended to answer the question, “How many people watched or listened?” Audience projections can be made for specific programs, specific stations, or for all those using a medium at any point in time. Projections can be made for households, persons, or various subsets of the audience (e.g., the number of men aged 18–49 who watched the news). Most of the numbers in a ratings report are simply estimates of absolute audience size, whether for program content or for commercial content.
Projections are made from samples. The most straightforward method of projection is to determine the proportion of the sample using a program, station, or medium and then multiply that by the size of the population. For example, if we wanted to know how many households watched Program Z, we would look at the sample, note that 20 percent watched Z, and multiply that by the estimated number of television households in the market, say 100,000. The projected number of households equipped with television (TVHH) watching Program Z would therefore be 20,000. That proportion is, of course, a rating. Hence, projected audiences can be derived by the following equation:
Rating (%) × Population = Projected Audience
For many years, this was the approach Nielsen used with its metered samples. It assumed that the in-tab sample, without further adjustments, adequately represented the population. Today, as Nielsen folds local peoplemeters (LPM) into its national sample to boost sample size, it weights respondents accordingly—a methodological fix that has been standard operating procedure in audience measurement for years. As we have noted, it is common to weight the responses of underrepresented groups more heavily than others; the specific variables used to weight the sample and the way these weights are combined vary from market to market. The end result is that the weighted responses of households or individuals are combined to project audience size. Unlike the simple procedure described previously, here projected audiences must be determined before ratings. In fact, if sample weighting or balancing is used, audience projections are actually used to calculate a rating, not vice versa.
Audience projections, used in the context of advertising, will sometimes be added to produce a number called gross audience or gross impressions. This is a summation of program or station audiences across different points in time. Those points in time are usually defined by an advertiser’s schedule of spots. Table 5.1 is a simple example of how gross impressions, for women aged 18 to 49, would be determined for a commercial message that aired at four different times.
Gross impressions are just like GRPs, except they are expressed as a whole number rather than percentage points. They provide a rough estimate of total audience exposure to a particular message or campaign. They do not take frequency of exposure or audience duplication into account. As a result, 10,000 gross impressions might mean that 10,000 people saw a message once or that 1,000 people saw it 10 times
TABLE 5.1
Determining Gross Impressions
| Spot Availability | Audience of Women Aged 18 to 49 |
Monday, 10 A.M. |
2,500 |
Wednesday, 11 A.M. |
2,000 |
Thursday, 4 P.M. |
3,500 |
Friday, 9 P.M. |
1,500 |
| Total (gross impressions) | 9,500 |
Ratings are the most familiar of all gross measures of the audience. Unlike projected audience, they express the size of the audience as a percentage of the total population, rather than a whole number. The simplest calculation for a rating, therefore, is to divide a station or program audience by the total potential audience. In practice, the “%” is understood, so a program with 20 percent of the audience is said to have a rating of 20.
The potential audience on which a rating is based can vary. Household ratings for the broadcast networks are based on all U.S. TVHH. But ratings can also be based on people, or different categories of people. Local market reports include station ratings for different market areas, like DMA and Metro. Some national cable and satellite networks might base their ratings not on all TVHH, or even all cable households, but only on those homes that can receive a network’s programming. Although there is a rationale for doing that, such variation can affect our interpretation of the data. A ratings analyst should, therefore, be aware of the potential audience on which a rating is based.
In addition to ratings, it is frequently useful to summarize the total number of people using the medium at any point in time. When households are the units of analysis, this summary is called households using television, or HUT level for short. HUT levels are typically expressed as a percentage of the total number of television households in a market. As with ratings, though, it is possible to express them in absolute terms. If individuals are being counted, persons using television, or PUT, is the appropriate term. In radio, the analogous term is persons using radio (PUR).
There are several different kinds of ratings calculations. Their definitional equations are summarized in Table 5.2 (actual computations are much more complex). To simplify the wording in the table, everything is described in terms of television, with television households (TVHH) as the unit of analysis. Radio ratings, and television ratings using persons as the unit of analysis, would be just the same, except they would use slightly different terminology (e.g., PUT vs. HUT).
Also summarized in Table 5.2 are calculations for GRPs and HUT levels. These are analogous to gross impressions and HUTs, respectively. They carry essentially the same information as those projections of audience size, but they are expressed as percentages instead of whole numbers. They are also subject to the same interpretive limitations as their counterparts. Reporting HUT or PUT as percentages means they are a kind of rating. To avoid confusion, we will refer to them as such. In practice, however, these percentages are usually called HUTs or PUTs, without appending the word “rating.”
Share, the third major gross measurement, expresses audience size as a percentage of those using the medium at a point in time. The basic equation for determining audience share among television households is:
![]()
TABLE 5.2
Ratings Computationsa

a The precise method for computing a rating depends on whether the responses of sample members are differentially weighted. When they are, program audiences must be projected and then divided by the total estimated population. When the responses of sample members are not weighted, or have equal weights, proportions within the sample itself determine the ratings and subsequent audience projections.
b In this computation, the number of minutes each TVHH spends watching a program is totaled across all TVHH. This is divided by the total possible number of minutes that could have been watched, as determined by multiplying program duration in minutes by total TVHH. AA can also be reported for specific quarter hours within the program, in which case the denominator is 15 × total TVHH.
The calculation of person shares is exactly the same, except persons and PUT levels are in the numerator and denominator, respectively. In either case, the rating and share of a given program or station have the same number in the numerator. The difference is in the denominator. As we noted in chapter 4, HUT or PUT levels are always less than the total potential audience, so a program’s share will always be larger than its rating.
Like ratings, audience shares can be determined for various subsets of the total audience. Unlike ratings, however, shares are of somewhat limited value in buying and selling audiences. Although shares indicate performance relative to the competition, they do not convey information about actual size of the audience, and that is what advertisers are most often interested in. The only way that a share can reveal information about total audience size is when it is related to its associated HUT level, as follows:
Program share × HUT = projected program audience
or
Program share × HUT rating = program rating
Audience shares can also be calculated over periods of time longer than program lengths. In local rating books, for example, audience shares are often reported for entire dayparts. When long-term average share calculations are made, the preferred method is to derive the average quarter-hour (AQH) share from the AQH rating within the same daypart. The following equation summarizes how such a daypart share might be calculated with television data:
![]()
Unlike AQH ratings, it is not appropriate to calculate AQH shares by adding a station’s audience share in each quarter hour and dividing by the number of quarter hours. That is because each audience share has a different denominator, and it would distort the average to give them equal weight.
Defining audience size in these ways presents some interesting problems, many of which occur when households are the unit of analysis. Suppose that a household is watching two different programs on different sets. To which station should that home be attributed? Standard practice in the ratings business is to credit the household to the audiences of both stations. In other words, it counts in the calculation of each station’s household rating and share. However, it will only be allowed to count once in the calculation of HUT levels. This means that the sum of all program ratings can exceed the HUT rating, and the sum of all program shares can exceed 100. This was an insignificant problem in the early days of television because most homes had only one television. In the United States, for example, close to 85 percent of all television households have more than one television set, and Nielsen estimates the national average is three sets per household.
Because households are typically collections of two or more people, household ratings tend to be higher than person ratings. Imagine, for example, that some market has 100 homes, with four people living in each. Suppose that one person in each household was watching Station Z. That would mean that Station Z had a TVHH rating of 100 and a person rating of 25. Some programs, like “family shows,” do better at attracting groups of viewers, whereas others garner more solitary viewing. It is, therefore, worth keeping an eye on discrepancies between household and person ratings, because differences between the two can be substantial.
Even when people are the unit of analysis, aberrations in audience size can occur. Most ratings services require that a person be in a program or quarter-hour audience for at least 5 minutes to be counted. That means it is quite possible for a person to be in two programs in a quarter hour or to show up in several program audiences of longer duration. This creates a problem analogous to multiple set use at the household level. In the olden days, when person ratings could only be made with diaries and people had to get up to change the channel, it was not much of a problem. Today, with peoplemeters tracking a population that has remote control devices and dozens of channels from which to choose, the potential for viewers to show up in more than one program audience is considerably greater.
As if this were not complicated enough, technology is now drawing into question the very act of viewing itself. Nielsen used to credit people who taped a program with their VCR to the program audience and simply note the size of the VCR contribution. In effect, to tape a program was to watch it. Of course, many taped programs were never watched, but the total amount of taping was so limited that no one was particularly concerned. With the introduction of DVRs, however, the definition of viewing became problematic. DVR users can time-shift within a program on a near-live basis or stockpile content for later viewing. Nielsen will segregate all time-shifted viewing, even if a viewer pauses for a few seconds; any recorded material that is actually played within a 7-day period can be added back into the audience, producing a “live plus” rating. While syndicators have used ratings compiled from multiple airings for years, this type of system is still relatively new to networks. Obviously it has the potential to alter our understanding of overnights and even fundamental concepts like ratings, HUTs, and shares.
The most common way to extend the data reported in a typical ratings “book” (the term is still used even though most information is now digital) is to introduce information on the cost of reaching the audience. Cost calculations are an important tool for those who must buy and sell media audiences. There are two such calculations in wide use, and both are based on manipulations of gross audience measurements.
Cost per thousand (CPM), as the name implies, tells you how much it costs to reach 1,000 members of a target audience. It is a yardstick that can be used to compare stations or networks with different audiences and different rate structures. The standard formula for computing CPMs is:
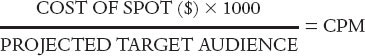
The projected target audience is expressed as a whole number. It could simply be the number of households delivered by the spot in question, or it could also be men aged 18 to 49, working women, teens aged 12 to 17, and so on. CPMs can be calculated for whatever audience is most relevant to the advertiser, as long as the ratings data can be calculated to project that audience. Occasionally, when a large number of spots are running, it is more convenient to compute the average CPM for the schedule in the following way:

CPMs are the most widely used measure of the advertising media’s cost efficiency. They can be calculated to gauge relative costs within a medium or used to make comparisons across different media. In print, for example, the cost of a black-and-white page or a newspaper’s line rate is divided by its circulation or the number of readers it delivers. Comparisons within a medium are generally easier to interpret than intermedia comparisons. As long as target audiences are defined in the same way, CPMs do a good job of revealing which spot is more cost efficient. There is less agreement on what is the magazine equivalent of a 30-second spot.
The electronic media have a unique form of cost calculation called cost per point (CPP). Like CPM, it is a yardstick for making cost-efficiency comparisons, except here the unit of measurement is not thousands of audience members but ratings points. CPP is computed as follows:

An alternative method for calculating CPP can be used when a large number of spots are being run and an average CPP is of more interest than the efficiency of any one commercial. This is sometimes called the cost per gross ratings point (CPGRP), and it is calculated as follows:

As you know by now, there are different kinds of ratings. In network television, C3 ratings are used to calculate the cost and efficiency of an advertising buy because they more accurately express the size of the audience at the moment a commercial is run. For ratings based on diary data in local markets, a quarter-hour rating is used. Television market reports also estimate station break ratings by averaging quarter hours before and after the break. This procedure gives buyers an estimate for the time closest to when a spot actually runs.
CPP measures are part of the everyday language of people who specialize in broadcast advertising. Stations’ representatives, and the media buyers with whom they deal, often conduct their negotiations on a CPP basis. This measure of cost efficiency has the additional advantage of relating directly to GRPs, which are commonly used to define the size of an advertising campaign. CPPs, however, have two limiting characteristics that affect their use and interpretation.
First, they are simply less precise than CPMs. Ratings points are rarely carried beyond one decimal place. They must, therefore, be rounded. Rounding off network audiences in this way can add or subtract tens of thousands of people from the audience, causing an unnecessary reduction in the accuracy of cost calculations. Second, ratings are based on different potential audiences. We would expect the CPP in New York to be more than it is in Louisville because each point represents many more people. But how many more? CPMs are calculated on the same base—1,000 households or persons—so they can be used for intermarket comparisons. Even within a market, problems can crop up when using CPP. Radio stations whose signals may cover only part of a market should be especially alert to CPP buying criteria. It is quite possible, for example, that one station delivers most of its audience within the metropolitan area, whereas another has an audience of equal size located mostly outside the metropolis. If CPPs in the market are based on metropolitan ratings, the second station could be at an unfair and unnecessary disadvantage.
With more and more media being delivered over the Web and other digital networks, the foregoing review of broadcast-based metrics might seem a bit quaint. The Web, after all, is a vast, interactive, nonlinear medium that enables new forms of media use. Those behaviors are measured with servers or very large panels of metered computers, with a level of “granularity” that would have been unimaginable in the early days of radio. But, in many ways, broadcasting has established precedents that the Web is bound to follow. This happens for two interrelated reasons.
First, the Web is a victim of its own success. There is so much data that analysts parse in so many ways that the industry is awash in metrics. The result has been what the Interactive Advertising Bureau (IAB, 2011) called “a cacophony of competing and contradictory measurement systems.” Not only are there a great many possible metrics to choose from, but even fairly common measures are defined and calculated in different ways. This happens, in part, because user-centric panels and servers record somewhat different kinds of information that affect the production of metrics. But even server-centric data alone are managed in idiosyncratic ways. Web analytics are typically done using computerized tools that access server data. Unfortunately, as Avinash Kaushik, an expert in the field noted, “each tool seems to have its own sweet way of reporting these numbers. They also tend to compute those numbers differently” (2010, p. 37). There are too many metrics with too little standardization. The result can be confusion about what the numbers mean and disagreement about which of them to use.
Second, remember that audience measurement always happens within an institutional context. The major players are the media themselves, who are trying to attract and sell audiences, and the advertisers who are trying to reach them. The system works best when there are straightforward, universally understood metrics that can function as the currency used to transact business. Broadcast-based metrics have done that. They guide the allocation of billions in ad spending around the world. They summarize the most relevant kinds of audience behaviors (audience size, composition, and loyalty). Media planners are, in turn, used to working with them. As other media arise, broadcast-based metrics offer a ready-made, if imperfect, template that can be extended to newcomers. Making “apples to apples” comparisons across media is increasingly critical as advertisers decide how to allocate their resources among platforms. Promoting that kind of standardization has been an important motivation for the IAB (2011), which hopes to “develop digital metrics and advertising currency that facilitate cross-platform measurement and evaluation of media.” These forces will result in a standardization of Web metrics and, we suspect, one that favors measures that relate directly to existing broadcast-based metrics. We review only the most common Web-based metrics next.
Hits were among the first measures to indicate website popularity. A hit occurs each time a file is requested from a web server. The problem is that even a single web page might contain dozens of files, each one of which would be counted as a hit. As a result, most analysts now regard hits as largely meaningless. In fact, many joke the acronym “HITS” stands for “How Idiots Track Success.”
A more useful gross measure is page views. Most websites allow users to visit specific pages. One common way to judge the popularity of a page is to count the number of times that it has been viewed. An analogous term is simply views. YouTube counts and reports the number of times each video has been watched. In neither case do you have any idea whether the count results from a few people viewing repeatedly, or many people viewing once. Nonetheless, views can function as a kind of currency. For that reason, YouTube goes to some lengths to authenticate the accuracy of its view counts.
There are many actions that can be counted in this way. Clicks occur when users follow a link from one page to another. Advertisers will often count the number of clicks an ad generates. Many voting schemes, where users indicate their likes and dislikes, allow people to vote multiple times. The same can true for measures of engagement that are built on counting “tweets.” In all these instances, you have a gross measure of something but no idea how many people are actually responsible.
Visits constitute yet another way to measure popularity. Web users typically have a session on a website in which they look at many pages. Each session is regarded as a visit. If they stop looking at pages or do not take any action for a period of time (e.g., 30 minutes), the visit ends. If they return later, it is regarded as another visit. You can use the number of visits as a measure of how much traffic a website gets, but it does not tell you how many different visitors there were. The “unique visitors” count is a cumulative measure that we discuss in the following chapter.
Impressions are a widely used Web metric. In today’s Web, ad servers often deliver display ads to multiple websites. These can appear as banner ads or some graphic element that might link you back to the advertiser. People do not always click on these ads, but they might see them. It is common to count and report the number of served impressions, which can be thought of as opportunities to see the ad. As we noted in chapter 3, many advertisers are not happy about counting served impressions, because those ads are not always placed on the page where users can see them. So there is a move in the industry to pare down the count to just “viewable impressions.”
Impressions, viewable or not, are just like the gross impressions used in broadcast-based metrics. They provide a measure of the overall weight of an ad campaign, without really telling you anything about reach and frequency. And just like their broadcast counterparts, they are routinely combined with information on costs to create a hybrid measure called cost per impression. These are generally reported in the form on CPMs. That is, they tell you how much it costs to achieve a thousand impressions. The use of CPMs across media platforms allows marketers to make judgments about the cost-effectiveness of different advertising vehicles.
Comparing gross measures is, in fact, the most common form of ratings analysis. There are an endless number of comparisons that can be made. Some might show the superiority of one station over another, the relative cost efficiency of different advertising media, or the success of one program format as opposed to another. There are certainly more of these than we can catalog in this chapter. We can, however, provide illustrative examples of comparisons that may be useful in buying or selling time and programs, or simply reaching a better understanding of the electronic media and their audiences.
One area of comparison deals with the size and composition of the available audience. You know from chapter 4 that the nature of the available audience is a powerful determinant of station or program audiences. Therefore, an analyst might want to begin by taking a closer look at who is watching or listening at different times. This kind of analysis could certainly be of interest to a programmer who must be cognizant of the ebb and flow of different audience segments when deciding what programs to run. It might also be of value to an advertiser or media buyer who wants to know when a certain kind of audience is most available. The most straightforward method of comparison is to graph the size of various audience segments at different hours throughout the day.
As we noted earlier, the single most important factor affecting the size of broadcast audiences is when people are available to listen. Work hours, school, commuting, and meal times, as well as seasons of the year, are the strongest influences on when people are available and potentially interested in using mass media. There are no regular surveys that provide detailed information on such availabilities, but several older studies can be reconstructed to give a rough idea of the availability of men, women, teens, and children throughout the day (Figure 5.1A).
Holidays, special events, and coverage of especially important news stories can certainly alter these patterns of availability, but as a rule they translate rather directly into the patterns of media use depicted in Figure 5.1B. The instances when a single program, or big event, has influenced a rise in HUTs are relatively rare. The most famous such occasions were the assassination of President Kennedy, men landing on the moon, the verdict in the O. J. Simpson trial, the events of 9/11, and the inauguration of Barak Obama, the first African American U.S. president.
With few exceptions, though, the best indicators of how many people will use media at any given time are existing reports of total audience size. Any new program or network that plans to find an audience among those who are not already listening or viewing is very unlikely to be successful. New programs, formats, and program services, for the most part, divide the existing potential and available audiences into smaller pieces of the pie rather than cause new viewers to tune in. The most obvious evidence of this is the decline in national broadcast network share due to the increasing number of cable and DBS competitors.
Thus, to plot when various audience segments are using a medium in a market is a valuable starting point for the audience analyst. Radio market reports have a section of day-part audience estimates with people using radio (PUR) levels, as well as different station audiences. Television reports typically estimate audiences by the quarter hour or the half hour.

FIGURE 5.1. Hypothetical Audience Availabilities and Typical Patterns of Radio and Television Use
Advertisers, of course, must eventually commit to buying time on specific stations or networks. To do so, they need to determine the most effective way to reach their target audience. This relatively simple requirement can trigger a torrent of ratings comparisons. From the time buyer’s perspective, the comparisons should be responsive to the advertiser’s need to reach a certain kind of audience in a cost-efficient manner. From the seller’s perspective, the comparisons should also show his or her audiences in the best possible light. Although these two objectives are not mutually exclusive, they can cause audience analysts to look at ratings data in different ways.
The simplest form of ratings analysis is to compare station or program audiences in terms of their size. This can be determined by ranking each program, station, or network by its average rating and, in effect, declaring a winner. One need only glance at the trade press to get a sense of how important it is to be “Number 1” by some measure. Of course, not everyone can be Number 1. Further, buying time on the top-rated station may not be the most effective way to spend an advertising budget. Comparisons of audience size are typically qualified by some consideration of audience composition.
The relevant definition of audience composition is usually determined by an advertiser. If the advertiser has a primary audience of women aged 18 to 24, it would make sense for the analyst to rank programs by ratings among women aged 18 to 24 rather than by total audience size. In all probability, this would produce a different rank ordering of programs and perhaps even a different Number 1 program. For radio stations, which often specialize in a certain demographic, ranking within audience subsets can allow several stations to claim they are Number 1.
At this point, we should emphasize a problem in ratings analysis about which researchers are quite sensitive. Analysis or comparison of audience subsets reduces the actual sample size on which those comparisons are based. Casual users can easily ignore or forget this because published ratings seem so authoritative once they are published and downloaded to a desktop computer. But remember that ratings estimates are subject to sampling error, and the amount of error increases as the sample size decreases. That means, for instance, that the difference between being Number 1 and Number 2 among men aged 18 to 24 might be a chance occurrence rather than a real difference. A researcher in this case would say the difference was not statistically significant. The same phenomenon produces what people in the industry call bounce, which is defined as a change in station ratings from one book to the next that is a result of a sampling error rather than any real change in the station’s audience size. An analyst should never be impressed by small differences, especially those based on small samples.
Having so cautioned, we must also point out that comparisons are sometimes made using statistics other than sheer audience size. Ratings data can be adjusted in a way that highlights audience composition and then ranked. This may produce very different rank orderings. There are two common techniques used to make these adjustments.
Indexing is a common way to make comparisons across scores. An index number simply expresses an individual score, like a rating or CPM, relative to some standard or base value. The basic formula for creating index numbers is as follows:
![]()
Usually the base value is fixed at a point in time to give the analyst an indication of how some variable is changing. Current CPMs, for instance, are often indexed to their levels in an earlier year. Base values have been determined in other ways as well. Suppose a program has a high rating among women aged 18 to 24 but a low rating overall. An index number could be created by using the overall rating as a base value. That would make the target audience rating look strong by comparison. CPM indices are also created by comparing individual market CPMs to an average CPM across markets (see Poltrack, 1983).
Thus far, we have defined target audiences only in terms of two demographic variables: age and gender. These are the segmentation variables most commonly used to specify an advertiser’s audience objectives. Age and gender, of course, may not be the most relevant descriptors of an advertiser’s target market. Income, buying habits, lifestyle, and a host of other variables might be of critical importance to someone buying advertising time. Target audiences defined in those terms make effective sales tools. Unfortunately, this kind of specialized information is not reported in ratings books.
As we discussed in chapter 1, ratings services are capable of producing customized ratings reports. The widespread use of personal computers and Internet access to databases has made this sort of customization increasingly common. As a consequence, it is now possible to describe audiences in ways that are not reported in the syndicated ratings report.
For example, ratings services keep track of the zip code in which each member of the sample lives. Zip code information is valued because knowing where a person lives can reveal a great deal about that individual. Inferences can be made about household incomes, occupations, ethnicity, education levels, lifestyles, and so on. As long as sample sizes are sufficiently large, these inferences will be reasonably accurate on average. Several companies offer research that combines geography with demographic/psychographic characteristics. Nielsen acquired Claritas, a market leader in this type of analysis, and now offers its own product called NielsenPRIZM. The use of this information means that audiences can be defined and compared in a virtually unlimited number of ways.
Of course, these audience comparisons alone will not necessarily convince an advertiser to buy time. As with any product for sale, no matter how useful or nicely packaged, the question usually comes down to how much it costs. In this context, CPM and CPP comparisons are critical. Such comparisons might be designed to illuminate the efficiency of buying one program, station, or daypart as opposed to another. Table 5.3 compares CPMs for network and spot television across several dayparts. Note that gaining access to 1,000 homes during daytime is relatively inexpensive, while the same unit costs several times more during prime time. CPM levels for cable networks are generally lower.
Programmers use rating and share comparisons as well. Consider, for example, how they might use zip codes to segment and compare audiences. A radio station might compare its ratings across zip code areas within a market to determine whether ratings are highest in areas with the highest concentration of likely listeners. If a station places a strong signal over an area with the kind of population that should like its format but has few listeners, special promotions might be called for. One station that uses this kind of analysis placed outdoor advertising and conducted a series of remote broadcasts in the areas where it was underperforming.
TABLE 5.3
Cost-per-thousand for Network and Spot TV 30-Second Units (2011–2012)

aSince there is no upfront for spot, these estimates are more akin to network TV scatter CPMs.
Source: National TV ACES, a service of Media Dynamics, Inc. (national data only). Spot data are Media Dynamics, Inc. estimates. Used by permission, Media Dynamics, Inc.
Radio programmers may also find it useful to represent the audience for each station in the market on a special demographic map. This can be done by creating a two-dimensional grid, with the vertical axis expressing, for example, the percentage of males in each station’s audience and the horizontal axis expressing the median age of the audience. Once these values are known, each station can be located on the grid. The station audiences could also be averaged to map formats rather than individual stations. Local radio market reports contain the information needed to determine these values, although a few preliminary calculations are necessary.
The most difficult calculation is determining the median age of each station’s audience. The median is a descriptive statistic, much like an arithmetic average. Technically, it is the point at which half the cases in a distribution are higher and half are lower. If, for example, 50 percent of a station’s audience is younger than 36 and 50 percent are older, then 36 is the median age.
To determine the median age of a station’s audience, you must know the audience size of individual age categories reported by the ratings service. Table 5.4 contains these data for a single station in a single daypart, as well as the estimated numbers of men and women who are listening. The station has 43,200 listeners in an AQH. Because radio books report audiences in hundreds, it is more convenient to record that as 432 in the table. The number of listeners aged 65 and older must be inferred from the difference between the total audience aged 12 and older and the sum of all other categories (i.e., 432 − 408 = 24).
TABLE 5.4
Calculating Median Age and Gender of Station Audience
| Age Group | Male (in 00’s) | Female (in 00’s) | Group Frequency (in 00’s) | Cumulative Frequency (in 00’s) |
12–17 |
? |
? |
23 |
23 |
18–24 |
29 |
50 |
79 |
102 |
25–34 |
63 |
41 |
104 |
206 |
35–44 |
43 |
60 |
103 |
309 |
45–54 |
35 |
27 |
62 |
371 |
55–64 |
20 |
17 |
37 |
408 |
65+ |
8 |
16 |
24 |
432 |
Total 12+ |
? |
? |
432 |
|
Total 18+ |
198 |
211 |
409 |
|
| Percent M-Fa | 48% | 52% |
a Because radio market reports do not ordinarily report the gender of persons 12 to 17, the male to female breakdown for a station’s audience must be determined on the basis of those 18 and older. In this case, there are 409(00) persons 18+ in the audience.
The median can now be located in the following way. First, figure out the cumulative frequency. This is shown in the column on the far right-hand side of the table. Second, divide the total size of the audience in half. In this case, it is 216 (i.e., 432/2 = 216). Third, look at the cumulative distribution and find the age category in which the 216th case falls. We know that 206 people are 34.5 or younger, and that there are 103 people in the next oldest group. Therefore, the 216th case must be between 34.5 and 44.5. Fourth, locate the 216th case by interpolating within that age group. To do that, assume that the ages of the 103 people in that group are evenly distributed. To locate the median, we must move 10 cases deep into the next age group. Stated differently, we need to go 10/103 of the way into a 10-year span. That translates into .97 years (i.e., 10/103 × 10 = 0.97). Add that to the lower limit of the category and, bingo, the median age is 35.47 (i.e., 34.5 + 0.97 = 35.47).
This procedure sounds more burdensome than it really is. Once you get the hang of it, it can be done with relative ease. It is simply a way to reduce a great deal of information about the age of the station’s audience into a single number. Similarly, the gender of the audience is reduced to a single number by using the male/female breakdowns in each category. In the example just given, 48 percent of the audience was male. These two numbers could become coordinates that allow us to plot a point on a two-dimensional grid. Figure 5.2 shows how stations with different formats would look on a demographic map of radio stations.
Figure 5.2 is a fairly typical array of formats and the audiences associated with each one. As you can see, formats can vary widely in terms of the type of listener they attract. Both an album rock station and a contemporary hits station will tend to have young listeners, but they typically appeal differently to young men and women. A classical station tends to attract older listeners. Music syndicators often package radio formats designed to appeal to very specific demographics, and the pronounced differences in audience composition explain how different stations can be Number 1 with different categories of listeners.
This kind of demographic mapping can be used by programmers in a number of ways. For example, it can help identify “holes” in the market by drawing attention to underserved segments of the population. It can also offer a different way to look at the positioning of stations in a market, and how they do or do not compete for the same type of listeners. By creating maps for different dayparts, the programmer can look for shifts in audience composition.
A number of cautions in the interpretation of the map should, however, be kept in mind. First, it tells the analyst nothing about the size of the potential audiences involved. There may be a hole in the market because there are relatively few people of a particular type. Some markets, for example, have very old populations; others do not. Similarly, the map reports no information on the size of the station’s actual audience, only its composition. Second, the analyst should remember that different types of listeners may be more valuable to advertisers, and hence constitute a more desirable audience. This could be attributable to their demographic composition, or the fact that many listen exclusively to their favorite station. Third, just because two or more stations occupy the same space on the map, it does not mean that they will share an audience. A country and Western station and a public radio station will often fall side-by-side on a map, but typically they have very little crossover audience. The tendency of listeners to move back and forth between stations can be more accurately studied by using the audience duplication section of the ratings book. We discuss such cumulative measurements later. Finally, remember that age and gender are not the only factors that might be related to station preferences. The map could look quite different if ethnicity or education were among the dimensions. Just such a map can be constructed when other demographic variables, such as education and income, are available.

FIGURE 5.2. Demographic Map of Radio Stations
Median age can also be a useful way to differentiate among television program sources. Table 5.5 shows a comparison of broadcast and cable networks on the median age of their audiences. Aside from the CW, which attracts a younger audience, the median age of broadcast network viewers is rising. Cable networks show an even wider range of median ages. MTV’s is 23, while USA network’s median age is 52. As you might expect, news networks occupy the other end of the spectrum. The FOX News prime time audience is 61.2, and CNN’s is over 65.
TABLE 5.5
Median Age of Network Audiences 2011–2012
| CBS | 56 |
ABC |
52 |
NBC |
49 |
Fox |
46 |
CW |
37 |
USA |
52 |
LIFETIME |
50 |
AMC |
50 |
HISTORY |
49 |
TNT |
49 |
Syfy |
47 |
A&E |
46 |
WE |
46 |
Food |
46 |
DISC |
43 |
TLC |
43 |
Bravo |
42 |
TBS |
39 |
FX |
38 |
E! |
34 |
ABC Family |
27 |
| MTV | 23 |
Data are from John Consoli, “A Random Sampling of Cable Networks’ Median Age Audiences” in Broadcasting & Cable August 28, 2012. (Analysis of NielsenData) http://www.broadcastingcable.com/article/488919-A_Random_Sampling_of_Cable_Networks_Median_Age_Audiences.php
The median age of networks can mask significant variation in programs, so it is also useful to look at averages for program types. According to Media Dynamics (2012, p. 211), the audience for primetime animated sitcoms has a median age of 31.4, much lower than the average of networks as a whole. Similarly, the median age for late night comedy/variety programs and for cable sports channels is a comparatively low 41.9. At the other end of the spectrum are early evening newscasts and syndicated game shows, which tend to skew much older (average ages of 60.8 and 61.1, respectively).
Ratings comparisons are also made longitudinally, over several points in time. In fact, most local market ratings reports will include data from previous sweeps under the heading of ratings trends. There could be any number of reasons for looking at audience trends. A radio programmer might want to determine how a format change had altered the composition of the station’s audience, perhaps producing a series of maps like the one in Figure 5.2. A financial analyst might want to examine the ratings history of a particular media property. A policymaker or economist might want to study patterns of audience diversion to assess the competitive positions of old and new media.
Modern metering devices also permit what might be called a “micro-longitudinal” study of audiences. Instead of comparing gross measures over a period of weeks or months, the analyst can assess audience behavior on a second-by-second basis. DVRs, like those sold by TiVo Inc., or set-top boxes (STBs) could become the functional equivalent of household meters—capturing a group of television sets playing moment to moment.
Figure 5.3 is a report of how households with Set-top Boxes (STBs) watched Super Bowl XLVI (2012) on an aggregate, anonymous basis. The horizontal axis displays the time of the broadcast; the vertical axis represents an audience index, which compares viewing at a given point in time with the average audience over the course of the game. An index of 1.0 means the audience during that 30-second time period was the same as the average audience. If the index is higher than 1.0, the time period audience was higher than average; and if it is less than 1.0, the audience at that time was lower than average. Note that the index values on the left are scaled differently than the values on the right—the left axis represents live viewing, and the right represents time-shifted viewing.

FIGURE 5.3. NFL Real-time Audience Size
© Rentrak Corporation 2012—Content in this chart is produced and/or compiled by Rentrak Corporation and its TV Essentials data collection and analytical service, and is covered by provisions of the Copyright Act.
This graph can be used to gauge audience interest in various parts of the Super Bowl broadcast. For example, the live audience grew steadily throughout the game but dipped slightly during commercials and during one segment of the halftime show. The viewers who time-shifted and watched the game any time during the next 3 days had more interest in the last segment of the half-time show than they did at any other point in the game. They zapped through the commercials they found boring and watched the ones they liked. This DVR audience shows much more variability in their viewing pattern.
Aside from offering a footnote to popular culture, such micro-longitudinal studies of program audiences can be of value to advertisers and programmers alike. The former can assess the attention-grabbing power of their commercials or, conversely, the rate at which DVR users are skipping the ads altogether. The latter can look at the same information the way they use “program analyzer” data—identifying those parts of the show that people want to skip or see again and again.
As you can surely tell by now, there are any number of ways to manipulate and compare estimates of audience size and composition. In fact, because the major ratings services now produce electronic ratings books that are read by a computer, the time involved in sorting and ranking ratings data can be drastically reduced. Both Arbitron and Nielsen sell software packages that will manipulate their data in a variety of ways. Some private vendors have also produced software that can turn ratings data into bar graphs, pie charts, and so on.
Although most of these developments are a boon to ratings analysts, a number of cautions should be exercised in either producing or consuming all the comparative statistics. Do not let the computational power or colorful graphics of these programs blind you to what you are actually dealing with. Remember that all gross measures of the audience are simply estimates based on sample information. Keep the following points in mind:
• Be alert to the size of the sample used to create a rating or make an audience projection. One consequence of zeroing in on a narrowly defined target audience is that the actual number of people on which estimates are based becomes quite small. That will increase the sampling error surrounding the audience estimates. A national peoplemeter sample might be big enough to break out the audience into narrow subsets. It does not follow that local market samples, which are smaller, can provide similar target estimates of equal accuracy.
• Techniques like indexing and calculating target efficiency can have you taking percentages of percentages, which tend to obscure the original values on which they are based. For example, comparing a 1.4 rating to a 0.7 rating produces the same index number (i.e., 200) as comparing a 14.0 to a 7.0. Sampling error, however, will be much larger relative to the smaller ratings. This means you should have less confidence in the first index value because even slight variations in its component parts could cause it to fluctuate wildly. The fact that the second index number is more reliable is not readily apparent with this sort of data reduction.
• Keep it simple. The ability to manipulate numbers in a multitude of ways does not necessarily mean that it is a good idea. This is true for two reasons. First, the more twists and turns there are in the analysis, the more likely you are to lose sight of what you are actually doing to the data. In other words, you are more likely to make a conceptual or computational error. Second, even if your work is flawless, more complex manipulations are harder to explain to the consumers of your research. You may understand how some special index was created, but that does not mean that a media buyer will have the time or inclination to sit through the explanation.
Most people schooled in quantitative research and theory are familiar with the concepts of prediction and explanation. In fact, the major reason for developing social scientific theory is to allow us to explain and/or predict the events we observe in the social world around us. In the context of ratings research, we can use the theories of audience behavior we explored in chapter 4 to help explain and predict gross measures of audience size and composition. Although prediction and explanation are certainly of interest to social theorists, they are not mere academic exercises. Indeed, predicting audience ratings is one of the principal activities of industry users.
It is important to remember that all ratings data are historical. They describe something that has already happened. It is equally important to remember that the buying and selling of audiences are always conducted in anticipation of future events. Although it is certainly useful to know which program had the largest audience last week, what really determines the allocation of advertising dollars is an expectation of who will have the largest audience next week or next season. Hence, ratings analysts who are involved in sales and advertising often spend a considerable portion of their time trying to predict ratings.
In the parlance of the industry, the job of predicting ratings is sometimes called pre-buy analysis (not to be confused with the pre-buy analyses done by financial planners and programmers when they evaluate a program acquisition). The buyer and seller of advertising time must each estimate the audience that will be delivered by a specific media schedule. The standard method of prediction is a two-stage process.
In the first stage, the analyst estimates the size of the total audience, as reflected in HUT or PUT levels, at the time a spot is to air. This is largely a matter of understanding audience availability. You will recall from our discussion in chapter 4 that total audience size is generally quite predictable. It varies by hour of the day, day of the week, and week of the year. It can also be affected by extremes in the weather (e.g., snowstorms, heatwaves, etc.), although these are obviously harder to know far in advance.
The simplest way to predict the total audience level for a future point in time is to assume it will be the same as it was exactly 1 year ago. This takes hourly, daily, and seasonal variations into account. A somewhat more involved procedure is to look at HUT/PUT over a period of months or years. By doing so, the analyst may identify long-term trends, or aberrations, in audience levels that would affect his or her judgment about future HUT levels. For instance, a 4-year average of HUT levels for a given hour, day, or month might produce a more stable estimate of future HUTs than would looking only at last year, which could have been atypical. In fact, to determine audience levels during months that are not measured, HUT levels should be interpolated by averaging data from sweeps before and after the month in question.
In the second stage, the analyst must project the share of audience that the station or program will achieve. Here, the simplest approach is to assume that an audience share will be the same as it was during the last measurement period. Of course, a number of factors can affect audience shares, and an analyst must take these into account. Programming changes can have a dramatic effect on audience shares. In radio, rival stations may have changed formats, making them more or less appealing to some segment of the market. In television, a competing station might be counterprogramming more effectively than in the past. Less dramatic, long-term trends might also be at work. Perhaps cable penetration has caused gradual erosion in audience shares that is likely to continue in the near future. Just as in estimating HUT levels, making comparisons across several measurement periods might reveal subtle shifts that would otherwise go unnoticed.
Once total audience levels and specific audience shares have been estimated, predicting an audience rating is simple. Multiply the HUT level you expect by the projected audience share, and you have a predicted rating. This formula is summarized as follows:
Estimated HUT × projected share (%) = predicted rating
In effect, it simply codifies the conventional wisdom expressed in Paul Klein’s (1971) theory of the “least objectionable program.” That is, exposure is best thought of as a two-stage process in which an already available audience decides which station or program to watch. The procedure to predict ratings for specific demographic subsets of the audience is the same, except that you must estimate the appropriate PUT level (e.g., men aged 18–49) and determine the program’s likely share among that audience subset. In either case, there are now a number of computer programs marketed by the ratings companies and independent vendors that perform such pre-buy analyses.
Although these formulas and computer programs are useful, remember that predicting audience ratings is not an exact science. It involves experience, intuition, and an understanding of the factors that affect audience size. Unfortunately, we can only offer help in the last category. Our advice would be to consider the model of audience behavior in chapter 4. Systematically work your way through the structural and individual-level factors that are likely to affect audience size, and begin to test them against your own experience. Sometimes that will lead you to make modifications that just seem to work.
The DVR and the introduction of C3 ratings have affected the audience-prediction calculus. Now buyers and sellers have to take into account not only the differences between program and commercial viewership but also whether a recorded program will actually be played back within 3 days. Some programs like popular dramas have a high rate of time-shifted viewing, which adds to the C3 rating; others, such as live events, do not gain as much additional viewership over time.
One of the most difficult and high-stakes occasions for predicting ratings occurs during the upfront market in network television. Major advertising agencies and network sales executives must try to anticipate how the fall lineups will perform. This is especially tricky because new programs have no track record to depend on. At least one major agency has found, through experience, that it can predict network ratings more accurately if it bases those predictions not on total HUT levels but on network-only HUT levels. In other words, the first stage in the process is to estimate the total number of viewers who will watch broadcast network television. Why this results in better predictions is not entirely clear.
TABLE 5.6
Sweeps Used for Post-Buy Analysisa
| February | January-February-March |
May |
April-May-June |
July |
July-August-September |
| November | October-November-December |
aThis schedule for post-buy analysis assumes the market is measured four times a year. Additional sweeps in January, March, and October would, if available, be used for post-by analysis in January, March, April and September-October, respectively.
Armed with share projections and predicted ratings for various segments of the audience, buyers and sellers negotiate a contract. Sellers are inclined to be optimistic about their ratings prospects, whereas buyers tend to be more conservative. In fact, the ratings projections that each brings to the table may be colored by the need to stake out a negotiating position. Eventually a deal is struck. Because most spot buys involve a schedule of several spots, the sum total of audience to be delivered is usually expressed in GRPs.
After a schedule of spots has run, both buyers and sellers want to know how well they did. Just as programmers and financial managers evaluate program buys, salespeople and buyers evaluate ratings predictions through a post-buy analysis. In markets that are continuously measured, it is possible to know exactly how well programs performed when a spot aired. Most local markets, however, are only surveyed during certain months. Consequently, precise data on ratings performance may not be available. Table 5.6 identifies the sweeps that are traditionally used for post-buy analysis in different months. The point is to use the best available data for evaluative purposes.
With the schedule of spots in one hand and the actual ratings in the other, the schedule is “re-rated.” For example, it may be that the original contract anticipated 200 GRPs, but the actual audience delivered totaled 210 GRPs. If that is true, the media buyer did better than expected. Of course, the opposite could have occurred, resulting in an audience deficiency. In upfront deals, networks have traditionally made up such deficiencies by running extra spots. More often, however, it is simply the media buyer’s bad luck.
Questions are often raised about how accurate ratings predictions are, or should be. The standard practice in the industry has been to view delivered audience levels within ±10 percent of the predicted levels as acceptable. There are three sources of error that can cause such discrepancies—forecasting error, strategic error, and sampling error. Forecasting errors are usually the first that come to mind. Included are errors of judgment and prediction. For example, the analyst might not have properly gauged a trend in HUT levels or foreseen the success of some programming strategy. Strategic errors are those errors deliberately introduced into the process at the time of contractual negotiations. A researcher might, for instance, honestly believe that a particular program will deliver a 5 rating while the person selling the program believes that it could be sold at 6 if a projection justified that number. To make a more profitable deal, the projection is knowingly distorted.
Sampling error can also affect the accuracy of ratings predictions, and should serve to remind us once again that these numbers are simply estimates based on sample information. As we saw in chapter 3, any rating is associated with a certain amount of sampling error. The larger the sample on which the rating is based, the lower is the associated error. In addition, the error surrounding small ratings tends to be rather large relative to the size of the rating itself. The same logic can be applied to a schedule of spots as expressed in GRPs. In the mid-1980s, Arbitron conducted an extensive study of the error (Jaffe, 1985) in GRP estimates. The principal conclusions were as follows:
• GRPs based on larger effective sample bases (ESB) had smaller standard errors. In effect, this means that GRPs based on large audience segments (e.g., men aged 18 and older) are more stable than those based on smaller segments (e.g., men aged 18–34). It also means that larger markets, which tend to have larger samples, will generally have less error than small markets.
• The higher the pairwise correlation between programs in the schedule, the higher the standard error. In other words, when there is a high level of audience duplication between spots in the schedule, there is a higher probability of error. This happens because high duplication implies that the same people tend to be represented in each program rating, thereby reducing the scope of the sample on which GRPs are based.
• For a given GRP level, a schedule with relatively few highly rated spots was less prone to error than a schedule with many low-rated spots.
• All things being equal, the larger the schedule in terms of GRPs, the larger the size of absolute standard error, but the smaller the size of relative standard error.
A more recent study by Nielsen (2005) reached similar conclusions. As a practical matter, all this means that a post-buy analysis is more likely to find results within the ±10 percent criterion if GRPs are based on relatively large segments of the market and programs or stations with relatively high ratings. A match of pre-buy predictions to post-buy ratings is less likely if GRPs are based on small ratings among small audience segments, even if forecasting and strategic error are nonexistent. As increased competition fragments radio and television audiences, and as advertisers try to target increasingly precise market segments, this problem of sampling error is likely to cause more postbuy results to fall outside the 10 percent range. For a thoughtful discussion of buying and selling predicted audiences, see Napoli (2003).
The method for predicting ratings we have described thus far is fairly straightforward, requires relatively little in the way of statistical manipulations, and depends heavily on intuition and expert judgment. There have, however, been a number of efforts to model program ratings in the form of mathematical equations. With either approach, the underlying theory of audience behavior is much the same. In attempts to model the ratings, however, many expert judgments are replaced by empirically determined, quantitative relationships.
Gensch and Shaman (1980) and Barnett, Chang, Fink, and Richards (1991) developed various models that accurately estimate the number of viewers of network television at any point in time. Consistent with our earlier discussions, they discovered that total audience size was not dependent on available program content but rather was a function of time of day and seasonality. Once the size of the available audience was predicted, the second stage in the process, determining each program’s share of audience, was modeled independently. This is analogous to the standard method of prediction in the industry. For an excellent review of the state of the art in forecasting television ratings, see Danaher, Dagger, and Smith (2011).
A number of writers have developed integrated models of viewer choice, considering factors such as lead-in effects, counterprogramming, a program’s rating history, program type, and even the demographic characteristics of cast members (e.g., Cooper, 1993; Danaher & Mawhinney, 2001; Shachar & Emerson, 2000; Rust, Kamakura, & Alpert, 1992; Weber, 2003; Webster & Phalen, 1997). In addition to these general predictive models, more specialized studies have also been done. Researchers have used correlational studies of gross audience measurements to assess the success of different programming strategies (e.g., Lin, 1995; McDowell & Dick, 2003; Tiedge & Ksobiech, 1986, 1987), to determine the cancellation threshold of network programs (Adams, 1993; Atkin & Litman, 1986), to assess the impact of media ownership on ratings performance (Parkman, 1982), and to examine the role of ratings in the evolution of television program content (McDonald & Schechter, 1988). In our judgment, these sorts of analyses represent a fertile area for further study. They are very helpful for historical and methodological insights.
Balnaves, M., O’Regan, T., & Goldsmith, B. (2011). Rating the audience: The business of media. New York: Bloomsbury Publishing Plc.
Buzzard, K. (2012). Tracking the audience: The ratings industry from analog to digital. New York: Routledge.
Danaher, P. J., Dagger, T. S., & Smith, M. S. (2011). Forecasting television ratings. International Journal of Forecasting, 27(4), 1215–1240. doi:10.1016/j.ijforecast.2010.08.002
Katz, H. E. (2010). The media handbook: A complete guide to advertising media selection, planning, research and buying (4th ed.). New York: Routledge.
Kaushik, A. (2010). Web analytics 2.0: The art on online accountability & science of customer centricity. Indianapolis, IN: Wiley.
Media Dynamics. (2012). TV dimensions. Nutley, NJ: Author.
Napoli, P. M. (2003). Audience economics: Media institutions and the audience marketplace. New York: Columbia University Press.
Rust, R. T. (1986). Advertising media models: A practical guide. Lexington, MA: Lexington Books.
Sissors, J. Z., & Baron, R. B. (2010). Advertising media planning (7th ed.). New York: McGraw-Hill.
Webster, J. G., & Phalen, P. F. (1997). The mass audience: Rediscovering the dominant model. Mahwah, NJ: Lawrence Erlbaum Associates.