
Chapter 4
Innovative Services and Public Clouds: What Do You Really Pay For?
In a properly automated and educated world, then, machines may prove to be the true humanizing influence. It may be that machines will do the work that makes life possible and that human beings will do all the other things that make life pleasant and worthwhile.
— Isaac Asimov, Robot Visions
Now that we’ve covered some of the more mundane cloud services, including storage and compute, let’s move on to the services that really drive cloud computing today. These more innovative and advanced services include AI, serverless, analytics, data lakes, and much more. They dominate much of what the technology press (including myself) currently writes about.
Here, we don’t concentrate on the definitions of these services, which is information you can find in so many other places. Instead, we focus on how to optimize their value for the business. Most enterprises that rent advanced services from a top-tier public cloud provider only scratch the surface when it comes to their capabilities and potential benefits.
The cloud services of yesteryear were nowhere near as good as the traditional enterprise data center solutions. Those days are gone. Today’s cloud-based solutions are multiples of times better than the traditional solutions, especially solutions that the top-tier public clouds can now provide. The reason is that the lion’s share of all enterprise technology companies’ R&D budgets goes toward cloud-based products and solutions. As a result, security is much better in the cloud, even though that seems counterintuitive to many people. There are also better databases, better development platforms, and better software packages available in public clouds.
Those who chose to stay off the cloud for any number of reasons will soon (or already) leverage inferior technology in the data center because these legacy systems receive less frequent or no updates from the provider, which means they also cost more to maintain and operate. There are reasons everyone is moving to the cloud these days. It’s partly because the market evolved to give us little choice.
For our purposes, let’s assume that moving to the cloud is a foregone conclusion. Your enterprise plans to leverage basic cloud infrastructure services, such as storage and compute as table stakes. The more innovative services covered in this chapter offer additional value to your enterprise, and these cloud services could even become game changers that redefine your business.
As we pointed out in Chapter 1, “How ‘Real’ Is the Value of Cloud Computing?” different layers define the value that cloud computing can bring to an enterprise. At the bottom layer we have basic infrastructure services (see Figure 4-1). These services support the applications and data storage systems that run the business. Basic infrastructure examples can include sales order entry, inventory management, shipping, logistics, and other systems that are common to most businesses. The target benefit of cloud computing at the bottom layer is to run these systems at a reduced cost, but these are just operational efficiencies. These are not game changer services.
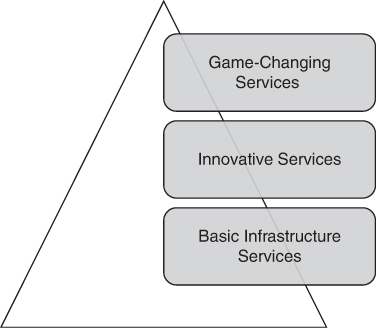
FIGURE 4-1 Cloud computing services can range from simple infrastructure services, such as those that run the business, to game-changing services, such as those that introduce innovative advantages that lead to the company becoming an industry disruptor.
Moving up a layer, we have innovative services. These services also depend on basic infrastructure services but provide true opportunities for innovation. Examples include advanced application development platforms and the ability to leverage services such as advanced data analytics, deep learning AI, massive scalability, proactive security, and anything that allows you to innovate or create unique differentiators.
Companies that leverage innovative services today include ride share companies that can leverage AI as a key differentiator to tell customers where their ride is located in near-real time, how much it will cost, and the almost exact time the ride should arrive. Ride share systems are based on simple services. By adding enhanced customer experiences using innovative cloud services, they can disrupt an existing traditional market.
For the most part, this chapter is about those innovative services. We look at what they are, what value they can bring, and how to effectively leverage them.
At the top layer, we have game-changing services. These innovative services combine to create net-new technologies and services that do not yet exist. A much earlier example of game-changing technology would be the invention of the airplane, which eventually changed how we travel long distances. These days, it could be a breakthrough in ways in which we cure diseases through genetic engineering or the ability to 3-D print construction components or entire houses. The possibilities are literally endless.
These are services and technologies that will change the way we think of things such as transportation, health care, housing, and other problems we want to solve, but we will do so in unique ways that did not exist prior to the appearance of these services and technologies.
Remember, each layer depends on the more primitive layer beneath it. Even the basic infrastructure layer where storage and compute exist needs to leverage more primitive components, such as a physical disk or a CPU, to provide the hardware services this layer needs. It’s a good reference model to define different types of cloud services and solutions that exist and how they are all interdependent and work together.
AI/ML
Artificial intelligence and machine learning (AI/ML) are old concepts with new life, thanks to cloud computing.
Back in the ’80s, AI was more of a high-tech experiment, with any AI advantages removed considering the high cost and lower technology capabilities at the time. You may remember computers playing chess, and IBM’s Watson on game shows. It was interesting technology, but the business applications were few and far between, and it was still cost prohibitive for valid applications.
AI saw little use in the ’80s, ’90s, and even the early 2000s, until something came along to change all that…the cloud. Now that we can rent the infrastructure, as well as the AI engines themselves, the cost went from a minimum investment of about $1 million to a few hundred dollars per month. Today’s AI technology is cheap, readily available, and with more advanced capabilities than in previous generations. It comes as no surprise that enterprises want to use AI in ways that will differentiate their business within the marketplace. Although you’ll hear different definitions of AI and ML, at its essence, AI is a type of technology that leverages human-like learning capabilities. AI is the broad category of computer intelligence with implementations that can include services such as ML and deep learning (see Figure 4-2). Although there are many different definitions of ML, it’s best thought of as a subcategory of AI systems that uses data to learn and find patterns. ML focuses on the pragmatic application of AI concepts that improve the value of AI for the business.
Today, most of what you see on the cloud is ML in the form of AI. ML can determine things such as a likely fraudulent transaction, in terms of patterns that may provide indicators. ML learns the patterns by learning from data specifically designed to teach the knowledge engine what certain existing patterns mean, such as data that is likely fraudulent or incorrect. It’s our job, as humans, to define and set up the learning data that will “teach” the ML engine to spot specific patterns.
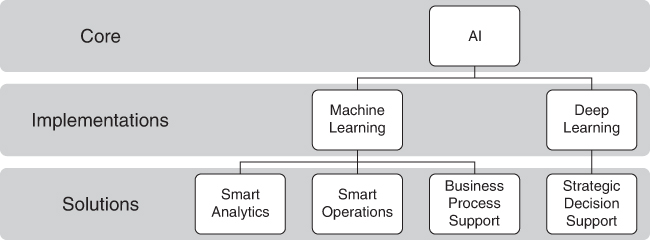
FIGURE 4-2 AI is the core concept, and machine learning and deep learning are examples of AI-related concepts or subcategories. Machine learning provides solutions related to analytics, operations, and business processing. Deep learning solutions include complex decision support and other solutions where a deeper understanding of the data is required.
Deep learning (DL) is the ability to leverage data and stimulus to find deeper meanings within data or stimulus. One can consider ML more tactically focused, meaning that we use it for more business purposes. DL can find deeper meaning within the data, sometimes finding a deeper understanding than we humans could find, such as the ability to figure out causes of some illnesses, where the problem is so complex that a single human is unable to process all of the knowledge that needs to be processed. That’s why deep learning is often called “AI without limits.”
It’s not a good idea to get too wrapped up in the semantics of AI. You’ll find that many in the world of cloud computing use AI, ML, DL, and other AI-related concepts interchangeably. While the PhD candidates may have issues with that approach, there are a lot of crossovers between the different types of technologies, which is why I just call it all “AI.” Enough said about that idiom.
Overused?
Is AI overused? Perhaps initially when cloud computing providers began to offer AI as a service. The cloud made it cheap and readily available to solutions developers. As a result, AI found its way into applications that did not require AI capabilities, and the solution ended up less valuable. It’s like putting high-end, high-cost racing brakes on a subcompact car. The car will stop just fine with stock brakes, while high-end brakes just waste money and resources.
These days we better understand the pragmatic use of AI: when it will prove worthwhile and when it will not. Business solutions that typically find the most value with cloud-based AI include
Business applications with potential patterns to find in large amounts of data. These can be new patterns from new data, or new patterns that emerge based on what an AI engine already processes and learns from data as it processes over time. The more data that gets analyzed and the more patterns the AI system identifies, the better the AI engine gets at doing its job. We see this today in our daily lives, such as our cars learning from our driving patterns to accordingly adjust braking and acceleration. Even the smart thermostats on the wall can determine better patterns of use, including adjusting temperature based on past preferences and other related patterns, such as the current weather outside.
The creation of new data and/or understandings. For example, leveraging “recommendation engines” by retailers selling online to better determine who they are interacting with and thus recommending products and services the user will likely purchase. Just based on behavior, these engines can determine your age, demographics, sexual orientation, income, location, and even the amount of education you likely had, and if you have a spouse and kids. Retailers can increase sales by using these engines, often by 20 percent or more. This “educated” means of enticing you to purchase additional products weaponizes AI.
An existing data set combined with AI’s ability to determine new meanings. It’s why AI exists in the first place. Most enterprises realize they have valuable data, but they have not figured out ways to mine its value. Data is at the heart of all AI-enabled systems but is rarely noted as such. If you understand that there are better ways to learn from your business data, as well as gather information that is not necessarily obvious, then you can grasp the value of AI and the cloud.1
1. https://www.infoworld.com/article/3662071/3-business-solutions-where-ai-is-a-good-choice.html
Overpriced?
The cost of AI dropped over 300 percent in the last 10 years, and the capabilities quadrupled (at a minimum). So why would anyone consider AI overpriced? This is more about AI’s deliverable value for your specific use cases than its cost. When you leverage AI, you don’t just leverage a single AI cloud service. There are many other resources that must be attached as well, including storage, compute, databases, and security, just to name the top four. To understand the real costs of AI, you need a holistic understanding of the AI service.
AI services are notoriously compute- and I/O-intensive; thus, they always incur additional costs. Also, training data is needed to analyze, and those data resources could cost you more than any AI service you leverage. Sometimes the cloud providers will “give away” the specific AI cloud service because they realize that billing will be higher for infrastructure resources the system requires when using AI.
However, some cloud providers offer bundled AI packages that include its infrastructure requirements. Some even provide AI cloud services at a fixed price per month for all the compute, storage, and AI usage you’ll need. The larger players rarely offer these bundles, which means you also introduce the additional expense of leveraging AI as a multicloud deployment. We get into the risks, costs, and advantages of AI later in this book.
So, when considering the cost versus value problem of leveraging AI in the cloud, you need to consider the following questions:
What potential value will an AI-enabled system bring, in terms of its direct ROI? What payback can you expect in hard dollars? For example, the ability to detect and stop most fraud by leveraging AI in the cloud would be based on the elimination of historical fraud losses.
What potential value will this AI-enabled system bring in terms of strategic ROI? For example, could you enter a new market with new innovative offerings or optimize the existing market through new processes and new understanding of the data?
What’s the all-in cost of building a system(s) using AI in the cloud? This includes costs for infrastructure, AI engine usage costs, training, and any risks that adding this technology might bring.
Answers to these questions will establish the true cost of AI, which can determine whether the cost is too high. Again, you need to consider the true all-in cost against the soft and hard values that AI can bring. For some enterprises and some use cases, this is the best bargain they will see at any cost. For others, the payback won’t be as well defined. You could pay a dollar for an entire AI system, and it would still be overpriced. Always consider the clear benefits as well as the drawback costs of unnecessary distractions.
Finding the Right Use Cases
The key to finding the right AI value is to find the right use cases. What problems can AI solve to benefit the business? Conversely, where is AI overkill with costs higher than any business benefits?
There’s a list of use case examples that the industry feels will benefit most from AI technology, cloud and not. However, it’s better to understand the typical problem patterns that are a good fit for AI. If you make a long list of application types, such as fraud detection and health-related wearables, that may or may not be a good application of AI technology within the specific requirements of a specific use case. Instead, look at what patterns you might find within your business problem, which is much more helpful than just listing types of applications where AI has been a good fit in the past. My fear is that we will end up force-fitting AI before we have a true understanding of the problem to solve, simply because others in somewhat similar situations have profitably leveraged AI. Rocky architecture ends up adding unnecessary cost and risk.
So, if you set aside application lists created by others, how do you find the right AI application for your use case? Let’s first understand why we are bothering with AI in the first place.
AI systems, especially those that leverage ML, are good at learning from large amounts of data, called training data. AI can make inferences around that data via things that humans teach the AI model (supervised learning), or they can learn on their own (unsupervised learning), or there can be some assistance from humans (semi-supervised learning), or AI can be trained through trial-and-error corrections that can be made by humans or automated processes (reinforced learning).
Reminder: I’m not going to teach you all the details behind AI and ML; there are plenty of other places to go for that knowledge. However, it helps to get an insider view of what business problems AI and ML typically solve best and how to recognize when AI technology should and should not be considered.
AI, including ML, should be leveraged only when there are things to learn, and then leverage the AI model only for business problem solutions that are a best fit for AI and ML. While the need to have a system learn from historical and ongoing data is an easy way to describe the best use case, there still needs to be a business case for leveraging this knowledge model. It’s not good enough to say that you can derive additional meaning from the data, such as spotting fraudulent transactions or diagnosing a disease. Define the business case use for that trained knowledge model to be leveraged, such as marking the likely fraudulent transactions for automated investigation and resolution that will return 2 percent of net profit to the business.
Far too often, businesses build these AI systems with no solid, stated benefit to the business at the end of the day to justify the cost of leveraging AI, cloud or not. Define, memorize, and be prepared to prove the true benefit of AI, no matter whether the application seems like a good fit or not. Most AI applications work just fine, but the additional cost is unjustified.
Business Optimization of AI
Okay, AI works, but now we need to find the problems to solve that will bring the most value to the business. What do we need to consider?
Most people who look for business applications of cloud-based AI/ML do so without picking applications or solution patterns that will optimize the value that AI/ML can bring. This is close to an epidemic, as AI costs go lower and availability rises. More and more often, enterprises apply AI to solve problems that AI is unsuited to solve. As you can see in Figure 4-3, this means that about two-thirds of the applications that leverage AI/ML are underoptimized for the business and end up costing more money and time than they should. These AI projects are often hailed as initial successes, but they become a money pit that insidiously removes value from the business over time.
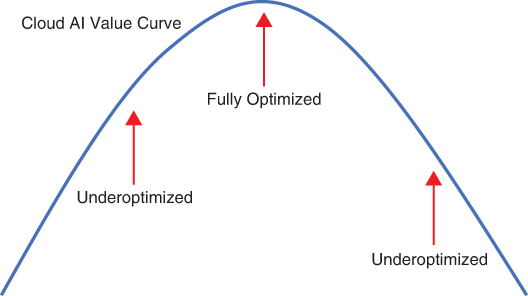
FIGURE 4-3 Cloud-based AI applications and/or solutions should leverage most capabilities of AI/ML. Applications and/or solutions that don’t leverage these capabilities are considered underoptimized or inappropriate use cases. These cases cost the business time and money.
If using AI/ML has a negative effect on value, that often means we’re not using AI/ML holistically. As you can see by Figure 4-4, it’s usually best to set up access to AI-enhanced data by leveraging both the data and the knowledge model that’s bound to the data through a holistic API. Therefore, any number of applications can leverage the “knowledge” using APIs or services, as much or as little as needed. This approach solves a few other problems as well, such as having a centralized knowledge model and data that’s consistent from application to application, which should also reduce operational and development costs because you leverage the same AI/ML services throughout the portfolio of applications.
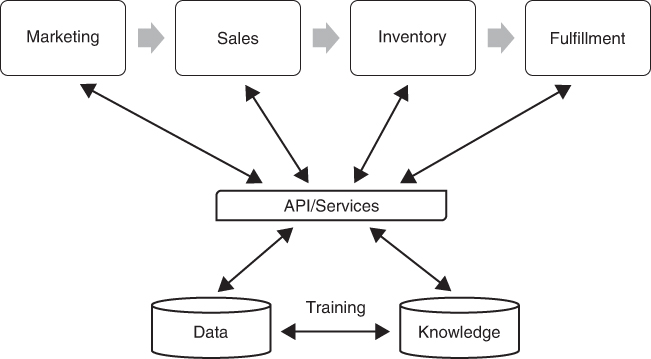
FIGURE 4-4 AI optimization means returning the maximum value back to the business to justify the use of AI technology. Most AI systems will be set up for use via multiple applications, both inside and outside of the cloud. This holistic solution can provide the best value to the business, but you must still consider your specific requirements.
Today, AI/ML is in overuse. Many believe this is a good thing, considering what the technology can do. Holistically, it often moves the business backward by leveraging applications and/or solutions that may not initially appear to be a failure, but they remove value to the business ongoing. This is the dilemma when leveraging any type of new, hyped technology, in that they are often misapplied and make things worse. The theme here is to consider the use case and its longer-term impact on the business before you jump on AI/ML.
Serverless
Serverless technology is a misnomer, in that it’s about how you deal with “servers” rather than the lack of them. The technology is called serverless because you no longer need to figure out how many server and storage resources will be required to run specific applications. The number of required resources is figured out for you, on the fly, as your applications execute.
Serverless gained in popularity because it moves allocation and provisioning decisions of virtual cloud server resources from the developer to the cloud provider. The types of serverless technology available grew from simple application execution systems to containers, databases, and anything else that makes cloud resource-sizing steps easier.
You Really Are Using Servers
When we leverage serverless systems found on major public cloud providers, we often forget that we’re leveraging actual servers and we’ll have to pay for their use. This is not much different from when we allocated the cloud server resources ourselves (such as storage and compute) and paid for the resources we leveraged. Now that automated processes make those calls for you, the question arises: Is serverless cheaper and more efficient than more traditional approaches? The dreaded answer is: It depends.
Serverless works on the assumption that rank-and-file developers are not that great at resource planning, and often over- or underallocate the number of resources needed. Overallocation means you spend too much money, underallocation means the application could fail. Both are cost inefficient, considering the outcome.
For now, let’s put aside some of the other features that serverless can bring to focus on manual versus its automatic provisioning features. When serverless is in play, the serverless system determines what the applications require, and thus allocates the precise number of resources needed for the application to execute at a particular point in time. Each provider approach to serverless is a bit different, but these functions usually operate independently, and thus the serverless system allocates resources only to execute that specific function, or a system that uses many functions. You’ll get a small report when the function executes, telling how many resources it used and how much it cost to execute that function/application. Thus, you’ll have to design for your serverless system as well, considering that these applications are more function oriented.
Many people question a serverless system’s ability to pick resources more cost-effectively than humans. There are two arguments to be made here. First, when we leverage automation, we usually have more cost-effective results than if it’s all left to people. This is the typical case when you have more dynamic applications that are difficult to predict, in terms of resources that need to be leveraged. However, there are static applications that provide easy-to-predict resource requirements, especially if the number of resources needed is not likely to change over time. With static applications, we can also leverage special discounting (such as reserved instances) to further improve costs to allocate our own resources versus relying on serverless automation.
Determining the value of leveraging serverless anything is best answered (again) by: It depends. It depends on the size and the specific behavior of the applications, dynamic versus static, for instance. So, sometimes serverless will make sense and provide the most cost optimization, sometimes not. The trick is to understand the application patterns that will lead to the best cost optimization.
Cost Versus Value
As you can see in Figure 4-5, traditional methods of allocating resources that support application execution are not based on the application needs at the time of deployment, but what the application will need. Or you can allocate enough resources to support application execution and then manually increase those resources as the scalability and capacity needs of the application organically grow.
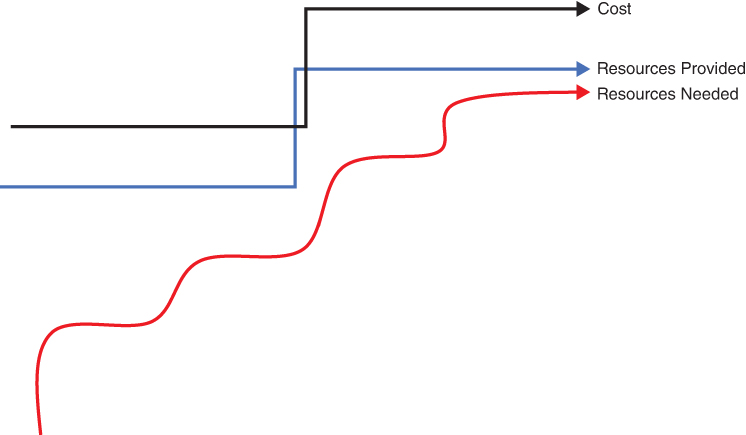
FIGURE 4-5 This graph illustrates a traditional method where humans select and allocate the number of resources needed, which means resources must be allocated ahead of need. In this example, the resources are only allocated twice—once initially and once to increase them to handle a growing application load. The capacity allocated ahead of need is largely wasted. Optimizing serverless means first understanding what you give up.
With traditional methods, you don’t look at the number of resources that an application continuously uses, but adjust those resources up or down, based on need. Thus, your resource allocations might be perfectly aligned with the current needs of the applications only once or twice a month, at the most, because traditional resource allocation for an application workload is static. Traditional allocations are never continuously adjusting to meet the needs of the application, whereas serverless is adjusting for the exact needs of the application or function.
Serverless was created to work around the fact that most developers struggle to correctly size applications to the number of required resources, and they usually don’t have unlimited time to do adjustments ongoing. Figure 4-6 depicts the serverless value of removing humans from this process, at least the value of automatic server provisioning. Again, as the needs go up, so do the number of cloud server resources leveraged, and so does the cost of those resources. The object is to align the resources needed with resources provided, as well as optimize cost. The question then becomes, Does leveraging a serverless model make us more (or less) cost efficient?
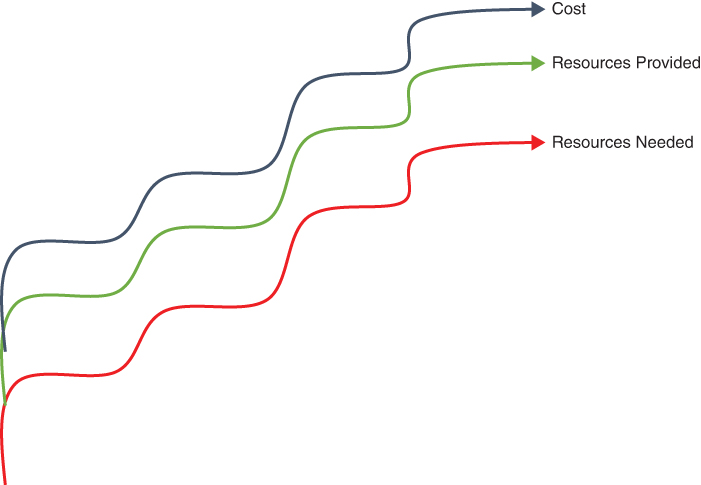
FIGURE 4-6 Serverless is a bit easier to understand. As the resources needed to run the application increase and sometimes decrease, this directly aligns with the amount of cloud resources allocated as well as what you pay for those resources.
Finding the Right Use Cases
The answer of whether or not to utilize serverless systems comes down to the use case. Applications that behave in dynamic ways also need to scale, meaning they go from using many compute and storage resources to very few, and then back to many resources again. Applications with dynamic behavior are a great fit for serverless. Serverless automation deals with the dynamic resource needs, always adjusting the number of resources up and down based on current need. Obviously, costs follow this line, as you can see in Figure 4-6, where you only pay for what the application(s) need, and you do not pay for unnecessary capacity.
Of course, not all applications are that dynamic, and they may not need to scale. In those cases, a simple equation can often define the number of required resources. In these use cases, serverless systems are usually more expensive than standard cloud resources that you manually provision and manage ongoing. Again, you could further reduce costs if you leverage discounted cloud resources, such as those purchased ahead of need. With proper planning, a nondynamic application could cost about one-third less than if you leveraged serverless resources.
Finding Business Optimization
The optimization of costs as related to need is key here. Many of those who pick serverless technology within the cloud providers do so for the wrong reasons. Often, they do not understand the requirements of their core use cases, which means they can’t properly determine if they should leverage serverless or more traditional approaches.
I suspect they’ll eventually figure out that serverless was not a cost-effective fit for a particular application because they did not consider the application’s processing and storage needs, which were not dynamic and did not need to scale. The use of static resources that could be manually allocated and remain in place would have been a much better idea. Remember, cloud providers don’t offer refunds for your poor judgment.
As we covered previously, serverless provides the best business optimization when the applications are both dynamic and consistently grow in the number of resources the applications will require going forward. For these types of applications, serverless is purpose-built to provide a more optimized solution.
DevOps/DevSecOps
Development and operations (DevOps) is also called development, security, and operations (DevSecOps). Both have revolutionized the way that we do software development, testing, deployment, and operations. For our purposes, we’ll call DevOps and DevSecOps just DevOps to make it easier to follow. We accept that there is a difference between the two, in that one also focuses on security as well as holistic development.
Figure 4-7 depicts the general idea behind DevOps, both in the cloud and out. We set up a DevOps tool pipeline that consists of design, development, integration, testing, and deployment tools that we automate as much as possible. The objective is to change the design of an application on one end and have the pipeline almost instantaneously perform automated integration, testing, and deployment tasks. For example, if we find an issue with a software system at 9:00 a.m., we could have it fixed by 10:00 a.m., including testing and deployment. We can do the same with enhancements and changes to meet the “speed of need” for the business.
DevOps leveraged with cloud generates value through its ability to provide agility, which in turn allows developers to almost instantaneously build or change application solutions to meet the exact needs of the business. Thus, automated DevOps can bring a huge amount of value to the business because it provides the soft value of business agility, which was covered in Chapter 1, something that most businesses will value, allowing them to “turn on a dime,” or expand innovation as needed by the marketplace.
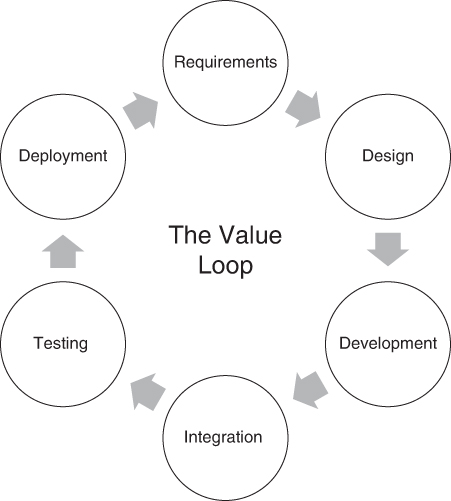
FIGURE 4-7 DevOps focuses on iteration, which means moving quickly and in parallel between one development task to another. The idea is to focus on speed, flexibility, and continuous improvement to obtain the most value.
Furthermore, DevOps can enable innovation. We can build innovative solutions at record speed that allow us to “fail fast” and drive innovation at scale. The company can quickly create game-changing innovations, such as providing an enhanced customer experience or other innovations that lead to increased business value for the company’s shareholders, which is the end goal.
DevOps is a disruptive approach to development because it removes the wall between development and operations. Both parties are now responsible for building, testing, deploying, and operating an application solution. Both work together with open communications, and it’s no longer “not my job” when it comes to ensuring the systems are fully optimized and meet the exact needs of the business.
DevOps accomplishes this state by removing much of the formality, structure, and processes that we follow with traditional software development. We no longer work down a set of tasks, where one task must be completed before the next starts. We no longer sit in a silo and wait for others to do their jobs before we can do ours. This creates a culture of teamwork, which removes many impediments to productivity and ensures that speed and agility are valued attributes. The result is the timely ability to build net new systems or alter existing systems to meet the changing needs of the business.
There are plenty of books and courses on DevOps, if you want to learn more about this concept. Here we examine the value of DevOps, including when it’s useful and when it’s not. Again, we get the insiders’ view of the true value of DevOps technology and processes.
No Cloud DevOps
Until recently, most DevOps toolchains existed outside of cloud providers. This was true even if the deployment of the applications at the end state of the process occurred in the cloud. Why? DevOps tools began as open systems that ran within data centers, prior to any need to put DevOps on public clouds.
Although cloud-based DevOps is a thing now, it’s difficult to create a cloud-only DevOps solution. The standard requirements for DevOps tooling are all over the place, and there are many tools to pick from. You may end up going from a design system on the cloud, to development on the cloud, to integration, testing, and deployment that occur in the data center. Then you could end up deploying to a public cloud provider as the end-state platform. Although most seek pure cloud DevOps toolchains, this often proves impossible, depending on the specific tools required by your use case or preferred by your staff. Thus, most DevOps in the cloud encompass hybrid, cloud, and traditional systems. At least, that’s the case at the time I’m writing this book.
All Cloud DevOps
Most public cloud providers offer a mix of their tooling along with third-party tooling that can be leveraged in the cloud, specifically on their cloud. These tools generally work fine but may not be optimized for your project’s specific needs if you prioritize “on the cloud” over “fully optimized.” As with anything I discuss here, if you prioritize the platform over the core business requirements, cloud or not, you will end up with something less than optimized.
Some-Cloud DevOps
Most DevOps is some-cloud DevOps (see Figure 4-8). This means that some of the DevOps tools within the toolchain run in the cloud, and some run on traditional systems in the data centers or even on the desktop of the developers or operators.

FIGURE 4-8 DevOps toolchains can run on public clouds or traditional systems, and they can work together when they run on both. This leads us to some-cloud DevOps, or a hybrid approach where you pick the best tooling and run it on the platform where it makes the most sense.
Of course, you may need to add more tools to the chain, or remove tools, based on your requirements. What’s important is to design your toolchain to provide a fully optimized DevOps solution and run those tools where they can provide the most value. DevOps engineers often end up with a hybrid some-cloud solution as their best DevOps solution. The core message is to find the most optimal DevOps tools for your use case, cloud or not.
Finding Business Optimization
DevOps is an easy place to find business value. It provides faster and more agile development and enables teams to work together more effectively. We’ve needed this improvement for decades. The benefits of DevOps are easy to measure; it promotes both business agility and speed, with the outcome being more innovation.
Are there any downsides? DevOps can be taken to an extreme, which can result in negative value to the business. This often happens when people leverage DevOps as a religion and put more value on moving quicky than software quality, or what the business specifically needs. These DevOps-driven shops don’t spend enough time on tools and processes to ensure the stability of their systems, and they accept unstable systems as a natural outcome of agile development. When confronted about the stability/quality issues, many will push back with the fact that they are “agile”; thus, the trade-off will be some lack of design and testing integrity. These people should be retrained or fired.
DevOps is not about moving fast to the detriment of application quality; it’s about enabling application quality to happen fast. There is a huge difference, in that one leverages automation to become a better developer who produces better tested and configured systems versus being a developer who uses Agile as an excuse to skip steps that ensure system quality and adherence to business objectives. DevOps is a great practice, great set of technologies, and a huge value to the business…if it’s done correctly. Otherwise, it can do a lot of damage that businesses typically need to hire someone else to fix.
Analytics
Analytics is the ability to understand the meaning of data and business processes, and support helpful automated processes in terms of trends, insights, and monitoring of business events so those charged with running the company can make better business decisions. Cloud computing became important in this arena because most enterprises do a poor job of managing their data and data assets, despite the emergence of concepts such as data warehouses and data marts. Many businesses continue to underutilize their data, or they lack the vision to create beneficial ways to use their data. Cloud was and is tagged as a technology that could exploit these fallow opportunities.
The trouble comes in when considering the as-is state of data in most enterprises. Most enterprise data is scattered throughout the existing thousands of databases, without a single source of truth for important entities such as customers, sales, and inventory. In many cases, CIOs kicked this mess down the road when they realized that the costs to correctly fix the problems were far more than their budgets would allow.
Much of this “asset scatter” arose when different groups built systems for different purposes, and because very few people, data, or systems within an enterprise interact or share resources. Each group picked its own development and database technology, and, in many cases, these groups just created new databases to store information that already existed.
I would assert that cloud made the asset scatter problem worse. These diverse groups can now pick and choose different application development tools and data assets because today’s cloud-based tools are far less expensive to acquire and easy to access. So, how do we retrofit good data analytics over a flawed asset scatter model?
First, undergoing a major renovation to consolidate the use of enterprise data is beyond the scope of virtually all enterprise budgets, although most enterprises need to do it. The reality is that money, staff skills, resources, and time to properly fix asset scatter issues don’t exist. Instead, we must fix this problem on the fly as we move to cloud, and then find ways to lessen the damage moving forward.
Although most of us can’t afford to eliminate asset scatter in one fell swoop, all of us should consolidate scatter patterns as we migrate systems to the cloud and never create new scatter problems. That’s the name of the game.
Connecting the Data Is Key
The first step? Understand that it’s all about leveraging existing data assets in optimized ways by adding value with new systems (such as AI) that can abstract the data we need. All of this can happen without major surgery. We can avoid remodels to the back-end databases, which is where the most money and risks come into play. Instead, we can use virtualization and abstraction to connect the data for analytics.
Figure 4-9 depicts what this connected model looks like. We deal with data, either old or new business data, that may exist in many different physical data stores, both within the cloud and out. Rather than replicate the data, we ensure that it can be efficiently read using data virtualization and abstraction to create the structure that makes the data most useful. This technology has been around for years and is often used to work around bad data designs and structures, both in and out of the cloud.
FIGURE 4-9 When we are dealing with data analytics, it’s important to understand that data unto itself is not as important as how it can teach AI systems to provide useful insights and thus deliver value to the business.
There are new concepts to consider as well, including data fabric and data mesh, just to name a few. Data fabric is an approach to data usage that employs a set of data services that provide similar capabilities for data access across endpoints. In other words, data fabric abstracts the physical data structure to consistently leverage data services, and it provides data and data analytics to give consumers a consistent array of services. Typically, data virtualization is the core mechanism behind data fabric. Although a detailed discussion of these approaches to connect with data is outside the scope of this book, if this is an issue you will or do deal with, you should look at other resources to take a deeper dive.
The requirements in Figure 4-9 mean that we must look for the business value of the data that’s recast using a more usable structure and view, as well as what the business can do with the data. Underutilized data means that it’s there to be read, but there are other, unrealized uses of the data that could add value to the business. For example, I can see that certain data is related to a single sale of a product, or even a grouping of sales, such as finding the total sales for a given period. Other insights might be more useful, such as the ability to determine who, what, where, when, and why sales trend higher or lower by relating sales data to other data sets, such as seasonal trends for specific products. Obviously, in-depth analysis of sales data is useful for sales planning and production adjustments, and even how the company markets its products to optimize sales.
Finally, AI is related to all connected data. As we covered earlier in this chapter, AI is most useful when there is data around that can be leveraged for machine learning/training that can, in turn, enable the AI system to find patterns. You could instruct the AI system to look for specific patterns, such as transactions that may indicate fraud based on attributes that you provided. Or, more valuable are patterns the AI might detect that you didn’t know existed. For example, a specific product that is marketed equally to both men and woman may have stronger sales trends around women buyers who also fit into a specific demographic, perhaps those who live in cities. These are patterns that create deeper insight into the data via data analytics.
Analytics Over and Under
Some businesses overapply analytics technology, whereas others underutilize data analytics, which is true in most use cases I see.
Overutilization of cloud-based data analytics typically occurs when someone overstates the value of analytics services, and/or it’s used for incompatible tasks. Examples include a demand for planning around a specific product or service when there is not enough data to determine any specific patterns. I recall one case where a company invested in promotional marketing campaigns based on analytics that lacked any historical data to spot true trends. Analytics based on junk data or missing data cause too many businesses to put too much stock in analytics. In these cases, you need to consider the solution holistically. Can the analytics be correct within a certain margin of error? It’s this belief in “magic data” that often gets companies into trouble. This is not the fault of the technology itself, rather the fact that the technology is being misused.
Underutilization of analytical technology is a far more common problem. The data exists; data analytics could derive information of value from that data. However, the data goes untapped. Indeed, some companies make mistake after mistake around sales and marketing trends when the information that would have saved them was an API call away. The trouble usually exists when enterprises look at the data itself rather than the potential ways to look at the data to find patterns or combine the data with other data sets to determine other meanings—for example, comparing sales data with economic data to determine how sales align with key market indicators. In some cases, you’ll find that sales go up when the market goes down. This is the case with discount stores, which traditionally see an increase in sales during an economic downturn. Other less obvious analytics would be the ability to compare demographic behaviors with sales data to determine the best ways to advertise to the people most likely to purchase a specific product or service, based on what we find in certain demographics.
AI Convergence
As we stated earlier, the concepts of AI, data, and analytics are tightly coupled within the cloud. Figure 4-10 depicts this relationship and the understanding that business value for analytics can only be created by connecting AI, business processes, and raw data.
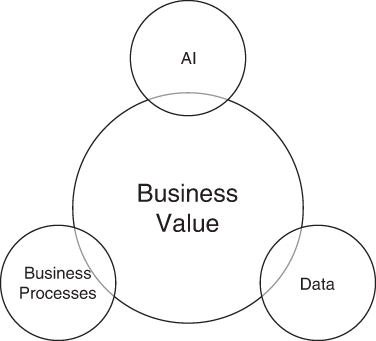
FIGURE 4-10 To find the true business value of cloud-based data analytics, we need to leverage a few key technologies that include the data itself that’s housed within a database, analyze how that data is provided to key business processes, and then determine how that data can teach key AI systems. All of this is interconnected to provide the core business value.
AI can find patterns in the data as well as learn day to day, which provides even more AI knowledge about how to use the data. No matter if this is general business analytics, or how an AIOs (Artificial Intelligence [AI] Operations) tool will deal with operational data to learn how to resolve problems over time, the fact that we’re including AI means that the analytics system can learn ongoing. It does so from the data and applies that knowledge to find deeper understandings about what the data means for the business. Often, the business learns something about its data that becomes game changing.
For instance, analytics could determine that an improved customer experience versus an improved product generates more real value. The system might forecast that certain improvements to the customer experience will return 15 times more than an equal investment in product improvements. Very few humans would connect those dots, but AI can help businesses identify and pursue opportunities to generate more business value.
Business processes are often overlooked as a consumer for analytics, but they play perhaps the most important role. Let’s say we support a core business process, such as a product sales process, and now we can embed analytics to allow this process to become more valuable for the business. For example, we add the ability to look at the sales history of a specific customer, understanding that this type of customer often closes after receiving a small discount on the price. The AI system can determine that the best target discount rate for this customer is 5 percent, and that this discount often results in an order quantity increase of three times the initial order. Building these analytics into the process, we’ll understand how much of a discount to provide to which customers for the highest chance of closing the sale right away, while still maintaining margins. This process can even be automated so that the system offers the discount without human intervention, which removes any latency caused by manually doing the discount procedure.
Finding Business Optimization
Business optimization for analytics is the ability to provide the right information at the right time and provide insights into the business that are greater than the raw data itself. Raw data unto itself is largely meaningless. If we can look at the data with a different dimensional understanding and allow external data to be compared with that data, we can determine the raw data’s higher and more valuable meaning.
So, this is about understanding the value that analytics technology can bring. We must determine how to successfully apply it so the cost of analytics implementation in the cloud returns the investment back to the business in terms of direct value understood, typically within a few short weeks. Typical cloud-based analytics systems are not that expensive. You integrate existing data with cloud-based AI engines and leverage models that were created for other purposes. Often these existing models are provided by your cloud analytics vendors that can be modified to meet your specific needs, which significantly reduces development and deployment costs. Some of the low-code and no-code solutions that are now a part of analytics can get us to a state where setting up our analytics models is just a matter of dragging and dropping objects on our screens—no programming skills required.
Edge and IoT
Edge computing is just another architectural approach where we place some of the data and processing outside of the cloud, closer to where the data is consumed, and where the processing needs to occur. Edge computing rose in popularity as those who build widely distributed systems realized it was highly inefficient to transmit data from its point of origin, say a factory robot, back to a centralized cloud-based system where it processes and then returns the information to the data source, in this case a factory robot. A “dumb terminal” type of device that requires unbroken communication with a “mainframe” or cloud system via Wi-Fi or Bluetooth is a recipe for disaster. If the Internet goes down, data processing would not occur. In some cases, the remote device or remote server could stop processing until communications were restored with the centralized storage and processing systems, often on the cloud.
As greater numbers of distributed systems emerged, we saw the rise of the Internet of Things (IoT) that opened the market to devices such as “smart” thermostats, TVs, watches, phones, and locks, with “advanced” capabilities. Those advanced capabilities are typically rudimentary when compared to full-fledged computing systems, but many of today’s smart devices surpass the capabilities of a 10- or even a 5-year old desktop computer. With more virtual assistants (Alexa, Siri, Hey Google) and appliances coming online, smart devices now account for more than half of the Wi-Fi connections in our homes.
We can define edge computing as an architecture in which varying amounts of processing and data storage exist on some device outside of the architecture’s centralized processing systems (which typically reside on a public cloud). IoT devices all leverage edge computing architecture.
Edge computing also includes sizable software and hardware systems, such as edge clouds that exist in data centers. These smaller versions of public clouds operate autonomously, away from public clouds such as AWS and Microsoft. Most edge clouds include a subset of public cloud providers’ cloud services. Public cloud providers and others offer autonomous edge cloud services to enterprises. The enterprises themselves use edge clouds when they need to keep data in sight to meet some legal requirements, or if they’re just paranoid that they will lose control of their data. Again, this is also edge computing.
So, edge computing is an architecture that applies to many things, and the term itself is so overused that it’s become a buzzword. However, edge computing is designed to put processing and data storage in a place where they can operate with the most efficiency. This means eliminating or removing latency, because the smart device is at the origin of data collection. Also, the edge system can continue to support an attached but independently operating system, such as a factory robot, even if communications with the central server become disrupted. Your watch still tells time and counts your steps. Your thermostat continues to operate manually or on its set schedule. The IoT devices continue to collect data that will automatically upload to the edge cloud when the connection reestablishes itself. So, edge computing provides the architectural advantages of reliability and performance.
Edge and the Cloud Realities
In the early days of edge computing, some people thought edge would replace cloud computing. That will never happen. If you think about it, edge computing must be on the edge of something. So, edge computing itself can’t exist without the “something” related to centralized storage and processing, which is typically found on a public cloud.
More and more edge computing services rely on public clouds to provide development, configuration, and management services. In other words, they have a symbiotic relationship, meaning that if you do edge computing, you will be working in the cloud as well…in most cases. This is a good thing, considering how complex edge computing can be, and especially when you consider the challenges around edge operations and configurations. Centralized control of the cloud makes edge computing work.
Cloud Controls the Edge
As alluded to in the preceding section, edge and cloud are tightly coupled. When you look at a list of the top 10 edge computing solution providers, the major public cloud providers appear first on that list. Public cloud providers support edge development, deployment, and edge computing operations by creating “digital twins” of the edge computing server or devices and by managing the twin of the device in the cloud. Thus, you automatically sync those changes to the deployed remote edge computing device or server.
As you can see by Figure 4-11, this structure provides many more advantages than if we managed each edge device one at a time. We create a single configuration that is automatically replicated as many times as needed, to as many devices and/or servers that the edge configuration needs to run on. This is very handy when it comes to operations, where the configurations need to be updated to fix issues or repair problems. The mechanism to roll out changes to the operating systems, databases, or other runtime utilities is in one place on the public cloud. Those changes are then replicated out to the edge computing systems, as are updates to any databases or specialized systems that may be out there.
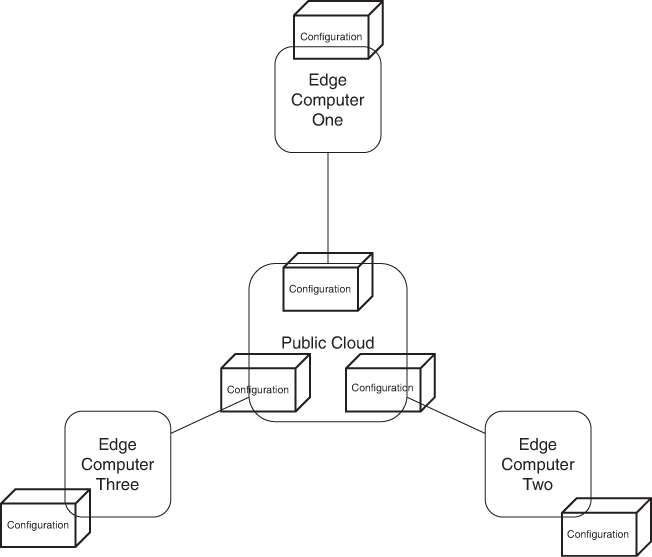
FIGURE 4-11 When looking at cloud computing and edge computing, you’ll find that cloud computing is where many edge-based software systems are developed and deployed. In many cases, a copy of the edge computing configuration is kept on the public cloud, allowing configurations to be updated or fixed when needed.
Edge Computing and IoT Realities
Edge and IoT come with their own set of challenges, and you need to figure them out before you go all-in with edge computing and IoT in general. The main challenge is one of scale. As you can see in Figure 4-12, the number of IoT devices can be significant. There can be so many devices that your ability to effectively manage them becomes more of a challenge than building the devices themselves.
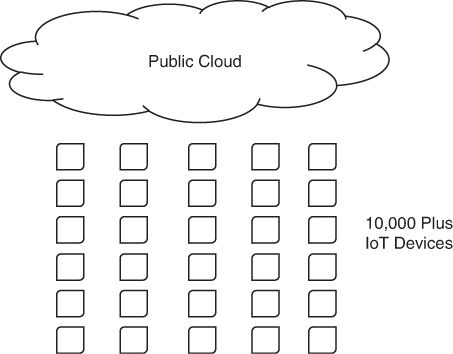
FIGURE 4-12 Public clouds are needed to manage the tens of thousands of IoT devices that might be needed to support a business. These devices must be centrally configured and managed, with scaling to support this number of devices. Scaling still presents problems for many of those moving to edge computing/IoT.
We’ve all experienced the sight of our smartphone updating its operating systems to provide fixes and new features. Even smart watches get occasional updates, as do our smart thermostats, as does the software within our vehicles. Large companies drive those updates, with the resources and ability to build specialized systems to deal with the scale of IoT devices purchased by their customers. Normal enterprises that want to leverage edge and IoT may not have access to the same capabilities. How do they efficiently and cost-effectively leverage edge and IoT when it comes to operational realities?
Let’s say you’re a small oil company that is looking to remotely manage pumping stations within South America, where the number of stations will soon number over 1,000. Because these systems need to be individually customized for the type of pump and the operations of the pump, AI is needed to monitor pump health and efficiency. AI introduces the ability to remotely fix issues and monitor the overall efficiency of the pumping systems. These fixes can be applied to an individual system, or all pumps at the same time.
The reality? This oil company has little to no chance of creating a scalable, cost-efficient edge-based application from scratch. If it wants any chance of building something usable, it’ll need to leverage an edge computing development platform provided by a public cloud provider or other third-party providers. Most companies are sized at or below the oil company example. Clearly, the ability to leverage edge building tools and platforms is a force multiplier to jump onto edge computing, and it’s the only realistic way for most enterprises to edge at scale, especially for enterprises that want to build edge-based systems for internal use.
Finding Business Optimization
When looking for business optimization of edge computing and IoT, you need to consider these realities: While many enterprises will leverage edge computing architecture, many will not. Many won’t need to. Your first step is to consider if edge computing is even needed and then to verify that a business case exists.
In my experience, many enterprises intend to leverage edge-based systems with systems that exist within data centers; those are not low-powered remote devices or computers. That’s not edge computing. Other companies try to leverage edge architecture for a variety of odd reasons, such as a desire to push processing out of the cloud to an edge-based device or server to distribute the processing load.
Edge computing is of value only when there is a need to put the gathering and processing of data close to the source of that data. If you build jet airliners, there’s a huge benefit if you put the engine processing technologies inside of the aircraft, which eliminates the need to deal with satellite communications latency or network outages to resolve problems with the engine in-flight. In that instance, edge computing is not only a smart move, but it’s really the only move.
However, the use cases for most enterprises are not as compelling as they should be for edge computing. At the very least, edge computing will increase development and operational costs threefold. There needs to be a good use case to justify that level of complexity and expense.
Emerging Technologies
In covering innovative services, we’re looking at a list that increases monthly, in terms of new service offerings that have the potential to provide more business value. The list of innovative services I reviewed in this chapter covers only the services that I feel are important to understand, as well as to put into proper perspective. My blog provides updates to developments in thinking around the uses of this technology, and I look at it through a skeptical eye rather than jump on every hype-driven bandwagon.
The advice I’m giving you here is simple. Every technology that you encounter needs to justify its existence, no matter who’s writing about it, or the purpose it’s serving for other enterprises. If there is no clear business case to use it, then it should not be used.
Call to Action
Understand any technology you want to leverage, in the cloud or out. This is not a race to determine who can build the coolest and most innovative systems the fastest; it’s a race to see who can provide innovation that results in the most value to the business.
We need to deal with all technology a bit differently than many of us do today. Technology needs to be evaluated on its usefulness and its ability to bring value to the business. Often, this is easier said than done.
I realize that many of you are often put in positions where the crowd chooses to do something in specific ways, using specific technologies that they believe are innovative and game changing. The use of AI, for example.
AI is useful for many use cases; it’s not useful for all use cases. The misapplication of AI bleeds millions of dollars from enterprises each year. The technology fails to bring any value, and it’s often misaligned to the needs of the application or system. Even more often, the mistake is never caught until after (or long after) the system is built and deployed. It becomes something that is likely considered a “success,” but is underoptimized to a point that it bleeds millions of dollars each year, and no one is the wiser. Don’t be those people.