
Chapter 10
Here’s the Future of Cloud Computing from an Insider’s Perspective…Be Prepared
If you don’t think about the future, you cannot have one.
—John Galsworthy
In the preceding chapter, we looked at where cloud computing is today and what your next moves should be. This chapter is a continuation of that conversation that will look much deeper into the future. I don’t have a crystal ball, but I have made a pretty good living by placing bets on certain technology patterns that may emerge, and then they did emerge. That doesn’t mean I’m clairvoyant or have a uniquely special talent, or that I’m always right. Accurate predictions require good guesswork backed by data, research, and past experiences.
The upside is that I’m right so much of the time that I’ve been hailed as a genius by some in the industry. Even if I’m right about most of cloud’s future, I doubt many people will notice or care. The technology world tends to have ADHD. We move so fast that we never really notice who was right and who got things wrong…unless they were spectacularly wrong. The best way to play this game around all the evolutions of technology is to pay attention and listen to your gut. We usually have a sense of emerging patterns and can feel and understand how these evolutions of technology are likely to play out over time. When you have a sense of the patterns, it’s relatively easy to figure out what technology innovations will be needed, and thus what we’re likely to be talking about in the tech press in 5, 10, or even 20 years in the future. All without validation from the $20,000 per month analyst firms that aren’t always on track.
You’ll find that some of the predictions in this book are more obvious than others, such as in the next section where I talk about the growth of complex data architectures and deployments. Although those are easy to predict, it’s not so easy to predict what they mean to enterprises and technology providers. That’s another level of predictions, but they address the information you’ll find most useful to yourself, your business, and/or the technology you’re building or planning to build.
As an insider, I do my best in this chapter to provide you with what will likely happen in the future, as well as why it will happen, and what that means for technology users and builders. The “why” and “what that means” are often the most valuable part of the conversation, but they usually get left out of the end-of-the-year predictions from technology articles. Instead, they let you know things like, “Cloud security will continue to be important,” which is a cop-out unto itself. Those types of generalized statements rarely get backed up with any assertions as to what specific changes we’ll see around that prediction. In this forward-looking chapter of the book, I do my best to fill in those blanks.
Continued Rise of Complex Cloud Deployments
Okay, I hear you barking, “Dave really went out on a limb for this obvious prediction that cloud computing will become more complex.” Stay with me. We’ve already covered multicloud in its current and evolving state in this book. The likelihood that its evolution will continue is close to 100 percent. However, I’m going to take things a bit further and talk about what will most likely come next after complexity settles into our everyday reality. After that, I’ll take us forward from now until about 20 years from now.
There are three main things that make hybrid and multicloud deployments harder to secure:
The first is visibility. Specifically, when you mix public and private cloud with on-premises infrastructure, you need not only visibility but also deep visibility to manage the complexity and make sure that gaps don’t develop. If you can’t see it, you can’t secure it.
The second thing to think about in these types of environments is insecure data transmission. Data that flows between public and private clouds or from on-premises or in a co-location, or co-lo, can be vulnerable to attack. We’re seeing organizations turn to tools that encrypt data both in flight and at rest.
The third thing that keeps some customers up at night, particularly if their data is globally dispersed, is the idea of falling out of compliance. The stakes for that are high from both a reputation and financial perspective. We’re seeing teams look at compliance at the start of their hybrid deployment and plan through a lens of compliance.
Figure 10-1 depicts our move from “Single-Cloud Deployments” into “Cross-Cloud Services” (also known as Supercloud/Metacloud Services). We covered this move earlier in the book. The only thing I would add here is that we’re just beginning our journey to cross-cloud services. Most of you will be operating single-cloud and multicloud deployments until well after this book hits the streets. Cross-cloud services will continue to evolve in the meantime, and I’m sure they will be the focus of my day-to-day activities for at least the next five years. The future “Cross-Cloud Services” journey is depicted in Figure 10-1. “Cross-Cloud Platform” and “Ubiquitous Deployment” are what I believe will be the next evolutions of cloud technology. Let me tell you why.

FIGURE 10-1 The progression of cloud computing clearly moves from single-cloud deployments to multicloud, where we are now, and then to more common cross-cloud services (supercloud/metacloud,), and then to ubiquitous cloud deployments and services. This is when cloud services and application services may exist anywhere, and auto migrate to the platform that provides the best cost efficiency.
Keep in mind that a cross-cloud architecture is a combination of software and services that will be delivered to give organizations freedom and control of private and public clouds. We do this by designing above the physical public cloud providers, thus removing the limitations of those physical cloud deployments from the cross-cloud architecture.
Let’s define what a cross-cloud platform is and how it will likely evolve from cross-cloud services. First, no two enterprises are the same. Each will have different requirements for security, governance, FinOps, compliance, and application and data, and different technology to fulfill those requirements. Most cross-cloud services that reside in a supercloud/metacloud are not predefined platforms, but layers of technology that need to be custom fit for each enterprise. There are no turnkey solutions, and each cross-cloud layer will be a bespoke layer of technologies that will vary from enterprise to enterprise.
Any custom fit technology gets us back to the two words enterprises hate to hear, “It depends.” In the case of every supercloud/metacloud, it does depend, and that’s why you’ll need very skilled architects to define the technology stacks that make up cross-cloud services.
As cross-cloud platforms begin to emerge, the technology industry will adapt to new market demands. Ubiquitous sets of cross-cloud services can be configured in many ways to deal with many different types of requirements. Rather than look at each set of clouds as a new problem that needs a customized solution, we’ll leverage a single platform (supercloud/metacloud) that can provide everything the enterprise needs for security, operations, AI, data, data integration, and so forth. It will be one-stop shopping for all the services you need to exist above and between cloud providers.
If cross-cloud platforms work as planned, which they should, most enterprises will move in this direction even if they already have some custom cross-cloud solutions in place. They’ll make this move for the same reasons we began the move to the cloud: We want to make the technology stack somebody else’s problem. By moving to a cross-cloud platform, we do just that.
Of course, the development of supercloud/metacloud architectures and the services that work on them will take a staggering amount of provider-supplied capital, much like cloud computing providers had to invest and spend millions of dollars at the onset of cloud computing. The larger cloud computing providers will likely offer the first commercial-grade cross-cloud platforms and end up owning that market as well. Only major players will have the resources required to build a new technology and develop its market from the ground up, and then be capable of funding the years of investments that need to be made. Here we go again.
The next phase following cross-cloud supercloud/metacloud platforms comes along further into the future. Ubiquitous deployments will install autonomous services onto a distributed array of technologies that we’re authorized to use. We won’t deploy them to a specific platform, but to a technology pool in general. This pool will include public clouds, edge computing, and on-site systems. Anything you own that is connected to a network, can store data, and has a processor can be a candidate to run these ubiquitous and fully autonomous services.
The kicker here is that these services, once developed and/or deployed, can exist by finding the best platform to run on, or even divide themselves so they can run on many platforms at the same time. The objective will be for these services to operate with the most efficiency, and thus use the least number of resources and money. They will be intelligent and have awareness of every other service around them, including hosting platforms, and will bring along security, governance, operations, and other services needed to provide the best operational efficiency.
The reason a ubiquitous service deployment is so attractive is around its underlying simplicity. We’ll no longer build centralized systems for security, operations, FinOps, and so on, as we did with the previous two evolutions. Instead, all those services will be contained within the ubiquitous deployment and thus exist wherever the service exists, all aware of each other, all working together in a distributed configuration. Everything will be self-contained and thus require very little human intervention (if any) and be intelligent, self-aware, and completely automated.
We’re working toward this end during today’s growth of multicloud technology and in what we’ll see developed for the next 10 years. During this time, we’ll also master the successful use of containers. In many respects, today’s containers are the prototypes for ubiquitous deployments. We’ll see containers evolve in this direction and eventually subsume traditional infrastructure tooling to provide something more flexible and scalable. Ubiquitous deployments will combine containerized applications and data, which will add much improved functionality to those containers to build a full operational stack. Ubiquitous deployments are on the horizon, but commonplace use is still many years into the future. I can’t wait to see if I live that long!
Refocus on Cross-Cloud Systems
This is my predicted progression of cloud computing: The focus will be on multicloud in the short term and will turn next toward cross-cloud platforms (supercloud/metacloud). As cross-cloud platforms become a more repeatable pattern, the longer-term focus will progress toward ubiquitous systems (as seen in Figure 10-1).
In this section we look at the specifics of this future, including its effects on security, operations, the rise of observability, governance, FinOps, and data federation. Because we covered these topics in other chapters in other contexts, here we focus more on the forward-looking topics, both near and long term. As cloud computing users, you’ll get a sense of where things are going to ensure that you make the right investments in time, resources, and technology. IT success requires good insights and vision to support both long- and short-term planning. Cloud computing is no different.
You’ll notice that we leave the cloud word alone for this section, opting instead for platform. Of course, a platform can be a cloud, but here we also include platforms that comprise the future core of cloud computing (that is, edge computing and traditional/legacy systems). The future will see the continued rise of technology stacks that are born and live on cloud-based platforms, but also include non-cloud platforms in that mix as well. We can’t just evolve security solutions and supporting technology that only solve problems for public cloud providers. We must also provide a valuable holistic technology solution for the enterprise. The goal will be to extend these ideas and solutions to other platforms using the same cross-platform services to secure, govern, and operate those systems, thus increasing the value of what we discuss in this section of the chapter. In other words, the future of cloud computing is not all about cloud computing, and that’s for a good reason.
Cross-Platform Security
The future focus on cross-cloud security means that we need to examine the current state as well as what’s next. We begin by discussing the basic changes that are happening now and finish up with a more far-reaching outlook. Given the importance of security, it needs to shift and evolve to protect us moving forward. Let’s get started.
Right now, security is becoming more complex to make it easier to leverage. How can that be? Security is moving from single monoethnic systems designed for use on a specific platform (such as a single public cloud provider) to systems that work with a mixture of systems and databases. These new systems comprise many pieces that must be encompassed by a larger security net. Moreover, most of these larger security nets will be custom configured for the specific business and its current technology solutions to deal with the problems and requirements at hand. Security will become this “whole of its parts” security net rather than a single security brand or a single set of tools.
This cross-platform security net encompasses several tiers of security. The native security features on platforms below the cross-platform security layer could include hundreds of things that focus on security for just that public cloud platform. This is where most of the heavy lifting occurs such as encryption, authentication, role-based security, or whatever else you need to deal with on those specific platforms. Those of you who worked with security systems throughout the years will understand the differences between security on legacy systems (that is, mainframes), security on edge-based platforms, and even those on more modern on-premises systems (that is, traditional Intel-based servers that still crowd data centers). Each has its own way to deal with security that is specific to that platform or native security layer.
Figure 10-2 depicts the concept of a cross-platform security manager, which is the key to all cross-cloud operations. This high-level platform can coordinate between all the native security layers on their own terms. The cross-platform security manager provides an orchestrated and automated system with holistic security, meaning security across all platforms.

FIGURE 10-2 Cross-platform security is the next generation of cloud security. It focuses on a cross-platform security layer (cloud and not) that can address each component by identity, and then track each identity in a directory service. From here, the cross-platform security manager can use the features of its own system, or leverage cloud-native and legacy-native features without forcing the security administrator to learn about native features and operations. This approach provides more simplicity and less complexity.
As you can see in Figure 10-2, the cross-platform security manager covers each brand’s native security system. These individual security systems are very different and highly heterogeneous because they support different models, approaches, and mechanisms. We don’t want to deal with branded security on a case-by-case basis, so it’s best to leverage abstraction and automation that use simplistic approaches and mechanisms to deal with this very complex security tier.
Cross-platform security is not a new concept. We’ve been aiming for this ability because security needed to exist across more than a single computing system. It’s why a single security technology brand typically provides our security systems, but we don’t have systems that work together in tightly coupled ways. There is centralized command and control, but it works by using loosely coupled distributed security mechanisms that deal with their platforms using best-of-breed approaches and technology.
The fundamental difference is that we will not deal with security on each platform using each platform’s terms, which would require the use of different tools, technologies, skills, and approaches. Instead, we will deal with security holistically and the same. A cross-platform security manager abstracts each native security system into sets of common services that can be orchestrated and automated, but we don’t deal with the trade-off of having to leverage least common denominator approaches, where we would force all system security to fit a single set of mechanisms that ultimately downgrade the solution from the native best-of-breed mechanisms that each platform provides.
Today, most breaches are caused by human mistakes, such as unauthorized access or simple misconfigurations. Security is better with a cross-platform security approach because we will remove humans from the process and instead focus on repeatable higher-level processes that are consistently carried out within each native security mechanism. Although we’re a few years away from the widespread availability of cross-platform security systems that work, we’re slowly moving toward these types of approaches with the rise of identity and access management (IAM) systems that authorize identities such as humans, machines, data, and processes based on their known identities and credentials. Although some cross-platform identity management security systems do exist, this is mostly deployed intra-platform, and each cloud provider has its own identity management approach and technology.
Cross-Platform Operations
The outlook for cross-platform operations is much the same as security. Rather than focus on a single platform’s operations processes, approaches, and technology, we will instead focus at a level higher on several operations managers that can abstract and automate platform-native operations systems. Typically, if you do it right, this layer exists logically above all cloud providers as well as above legacy, edge, and so on. Physically, cross-platform operations may exist anywhere, and typically run on a public cloud provider or even on-premises. It really does not matter to the value we want to obtain.
The idea with cloud operations, and operations in general, is to remove as much redundancy and complexity as possible. That means doing things in the middle of the platforms, cloud and non-cloud, rather than within each platform. Some of this is possible using emerging tools such as artificial intelligence operations (AIOps), which can monitor and manage many services on many platforms at the same time, cloud and non-cloud. However, they can’t do it all. Right now, you’ll end up with a collection of tools and technology that can logically exist over the platforms. They deal with operational functions such as performance management and operations, applications management and operations, data management and operations, FinOps, and other things that need to be monitored and managed ongoing.
The future of cross-platform operations is clear:
Core operational services will be combined in a logical layer that exists above all the cloud and non-cloud platforms. (Getting the trends here?) Again, this cross-cloud platform will have physical components that run on any type and number of platforms, cloud and non-cloud, but logically speaking they sit above the platforms to provide core operational services to all platforms.
Ubiquitous services will run in any number of host platforms. They will provide automated deployment and redeployment based on the needs of the applications, and they will have the ability to provide more value to the business by running on one platform over another, or many platforms at the same time (that is, federated applications, as covered in earlier chapters).
Automated services will proactively deal with operational issues, primarily by using the concept of observability (covered next). This means that things get fixed before they become issues.
Cross-Platform Observability
Observability is a concept being kicked around today that will evolve around the use of cross-platform services. It’s about the future of cloud computing, and computing in general. A large portion of this chapter talks about observability because it is key to taking your cloud computing game to the next level. My goal is to provide you with insights and information you simply don’t have access to right now.
At its core, observability allows us to monitor internal states of systems. Observability uses externally exhibited characteristics that can predict the future behavior of monitored systems using data analysis and other technologies. Core to the observability concept is the ability to find insights that are unapparent by just looking at the monitored data.
Observability is often associated with operations, certainly with AIOps tools. However, observability is a concept with much wider applications. Observability can enhance security, governance, and any aspect of computing where there is an advantage to seeing beyond the more obvious states of systems, data, applications, and so forth. This is about taking the understanding game to the next level. Later in this chapter, we cover some of the more interesting applications for observability that will probably affect the decisions you make about systems in the short and long term.
Back to general trends, future cross-cloud observability will move the enterprise to a state where core business systems in and out of the cloud are operated in a way that solves issues before they become issues. Proactive maintenance and operations will lead to much higher uptime that approaches zero outages and lowers operational costs. The inflection point of complexity and heterogeneity no longer impacts the business. Thus, no complexity wall and no tipping point, as we discussed in earlier chapters.
Proactive observability helps predict issues before they become issues. A proactive enterprise can deploy very complex systems without impacting the ROI value of those systems. If used correctly, observability allows enterprises to leverage best-of-breed technology and its resulting complexity with little or no impact on the business.
Figure 10-3 represents the major components of observability as related to IT operations, cloud and non-cloud.

FIGURE 10-3 Observability for general operations, security, and other aspects of cloud operations can gain insights from an enormous amount of gathered data. This is different from monitoring, which just reveals the current state of things. Observability tells you what is happening and what will happen, and it can even trigger automated mechanisms that fix problems before they cause outages or other negative events.
Let’s explore each component of observability and why it’s important to the future of cloud computing:
Trending: What patterns occur over time, and what do they mean for future behavior? For example, if performance trends downward, that indicates likely I/O problems that arise from organic database growth. This is based on historical and current data, and then the observability system uses this information as training data for an AI system such as AIOps.
Analyses: What does the data mean, and what insights can we draw from it? Observability provides the ability to analyze data, using AI, to interpret that data and determine insights. This core feature of observability sets it apart from just monitoring the data. Observability analysis can be very deep and complex, such as determining AI system training requirements based on an analysis of system outages. Or it can be rudimentary, such as determining that a drop in network traffic means there is a 67 percent probability that an I/O error exists in a core storage system.
Insights: What can we understand from the data, or what do we need to understand from the data? Observability finds meaning in data that’s not readily understood or apparent. For example, observability can find correlations between a rise in sales revenue and a drop in overall system performance. This doesn’t make sense on the surface. A decrease in system performance usually has a negative impact on customer access and sales order entry. However, in this case, excessive users on the sales order system (including the e-commerce website) pushed down system performance. Thus, the operations team can take action to ensure that capacity will elastically increase to support more sales activities. Many won’t suspect that these data points are connected, but observability allows you to get such insights into past, current, and even forecasted data.
Tracking: Monitoring system activity data in real time or near-real time allows observability to leverage this data to find, diagnose, and fix issues ongoing. Traditional tracking monitors the activity of multiple systems in the cloud and in the data center. Under the concept of observability, the system can find dynamic insights around real-time data and look at it in the context of related operations data. The system may determine and diagnose issues that can be self-healed through automation. For example, tracking CPU performance of a single virtual server that exists on a major IaaS provider. Tracking can provide real-time insights as to what this performance data means in relation to future performance, processor failure, memory failure, and other insights that may be derived from this relatively innocuous data that was once displayed on an operator’s dashboard for a few seconds and then gone forever.
Learning: Learning systems look at massive amounts of data to find trends and insights, and then leverage that data to learn about emerging patterns and what they mean. Any system that embraces the concept of observability leverages AI systems to train knowledge engines around patterns of data. This can be simple patterns such as an increase in the internal temperature of a server that will accurately indicate an impending failure, which is something that most humans with IT operations experience already understand. Looking at the correlation of systems’ data from hundreds of sources involves much more complex uses of learning to look at patterns over time and what they typically indicate. This can include performance data from specific applications, networks, databases, I/O, and so forth. The knowledge engine can identify and use these patterns to predict and avoid negative issues that impact operations. Complex patterns will emerge that may encompass a detailed review of thousands of current and historical data sets to pinpoint most network, storage, and application failures before they happen. Humans can never physically replicate the same processes to achieve this level of understanding.
Alerting: What issues need to be dealt with in a timely manner? For example, a low-level priority alert for a network performance issue that will eventually lead to the replacement of a network hub. Or an immediate alert that requires immediate attention, such as capacity that needs to be automatically expanded because an application processing load is nearing the limits of a virtual server cluster in the cloud. Again, these can be simple alerts that just let a system or human know about some issue or warning, whereas complex alerts could go out based on different humans and/or systems that need to be involved.
Actions: What happens because of an alert? It could result in a manual action such as a text to IT to reboot a cloud-based server, or some automated action such as kicking off very sophisticated processing to automatically recover from a ransomware attack before there is an impact on core business systems. Complex actions may involve dozens of actions taken by humans and thousands of automated actions to carry out immediate self-healing operations.
Observability provides the ability to manage and monitor modern systems that include applications built to run at faster velocities with more agile features. It will no longer work to deploy applications and then bolt on monitoring and management tools. The new tools must do much more than simply monitor operations data. Again, what’s core to the value of observability are the insights that observability systems can provide by leveraging data that they gather from all platforms under management—for instance, cloud, legacy, and edge-based systems. Keep in mind that “legacy” refers to systems typically over 10 years old but is really anything existing that needs to work and play well with the cloud-based systems.
Figure 10-4 depicts what these insights are now or will likely be. Note that it’s a matter of understanding the present, the past, and what will happen in the future. This is a tall order for most observability systems now, even if the data exists to generate these insights. The trick is to get things right, and that can only be done by the repeated use of data as training data, and the ability to derive outcome patterns of that data. In other words, the answers are somewhere in the data, but we don’t have the approaches and processes to find and interpret the answers. The value of observability is not in its ability to gather and monitor random data. Its value lies in its ability to find answers in overwhelming quantities of seemingly random data.

FIGURE 10-4 Useful insights from observability include an understanding of the current state of systems, such as active cloud services. More useful insights include what happened in the past, what the current state of things really means, and, most importantly, what will happen in the future and how to correct impending problems before they become true problems.
Figure 10-5 is an observability maturity model for IT operations, including cloud and legacy operations. It’s a good guide for the progression of a company that wants to optimize observability for IT operations.
Note
We define the degrees of maturity as CloudOps (cloud operations) 1.0, 2.0, 3.0, and 4.0. The lower number, 1.0, is the least amount of observability maturity, and the highest amount of maturity is 4.0. The higher numbers come with more advanced capabilities and technologies deployed and thus generate the most business value. Obviously, it’s desirable to move from the lowest to the highest maturity levels, and this will hold true for most enterprises well into the future.

FIGURE 10-5 Operations-oriented observability can define several steps of maturity that enterprises will progress through to achieve “zero touch” IT operations that include all cloud and non-cloud resources.
To begin the journey, our company would first start with capabilities that are considered “Foundational,” or, CloudOps 1.0. They could build on existing IT operational approaches and tooling to find a starting point for next-generation IT operations in the cloud. The most important capability here would be to establish a cloud operations strategy that would cover a single and multicloud deployment, as well as extend operations to legacy systems. If our company progressed to CloudOps 2.0, “Transformative,” the most important step for that level of maturity would be to define the cloud operations tactics to support observability. This would include the addition of AIOps and other tooling, which is just an implementation of the cloud operations strategy that we created at the previous level of maturity.
Moving into the future, CloudOps 3.0 and 4.0, “Innovative” and “Optimized,” respectively, many of these capabilities take our company to levels that produce ROI values back to the business for the investment made in observability approaches and tooling. Some of the most important capabilities include the ability to support complex cloud deployments, such as complex and distributed multiclouds that would also include legacy systems under the observability umbrella. Moving up, a fully optimized maturity state includes the ultimate destination of zero touch IT operations with fully optimized and automated legacy and cloud operations. Humans have been removed from the operations processes, including fully automated self-healing systems that proactively correct operational issues using cognitive tools such as AIOps and other force multipliers to fully automate all IT operations.
Note that this is an example of an application of observability that uses observability to add value to cloud operations. Observability can as easily apply to security, application operations, and other areas that can reap benefits from these insights to better deal with their cross-platform jobs. Thus, you need to consider how to use observability generally, meaning just for operations, and observability for specific purposes and its benefit to cloud computing (which is where the future of this concept lies), as well as its benefit to other platforms. Keep cross-cloud observability on your radar.
Cross-Platform Governance
We previously covered governance as it relates to multicloud and single-cloud deployments, so I won’t restate things here. The real future of cross-platform governance is the expanded use of core governance systems that work across platforms, not just for a single platform as it’s leveraged today. Governance systems will once again operate logically above the platforms, which is how this technology and concept will shine. Again, that’s the trend to understand best when you peek into the future of cloud computing.
Governance, as seen in Figure 10-6, is about putting guardrails around the use of services and resources—for example, the governance of cloud services such as storage and database APIs, or the governance of complete resources such as directly leveraging a storage solution rather than going through a service. The future of cross-platform governance begins with the initial use of governance in single and multicloud deployments by those who operate cloud and non-cloud systems. This trend includes or will include
The rise of security and governance systems that work together. For example, ensuring that someone is not granted access to a specific resource or service by using set policies that deny access.
The rise in the use of compliance governance. For example, having cross-platform governance systems and underlying policies that enforce legal and corporate compliance. An example would be to disallow data transfers out of the country, if laws exist that prohibit such transfers.
The rise of governance systems linked with operations. Right now, there is little or no integration between operational tools such as the ones discussed earlier in this chapter and earlier in this book. Moving forward, this lack of integration can’t stand. Governance systems need to work across platforms to work and play well with systems that operate infrastructure, applications, data, and so on, and to control who has access to all the various pieces and parts. This is not about denying access to something just to ensure that everyone and everything is following the rules, it’s about protecting core systems from mistakes that are likely to cause core problems.

FIGURE 10-6 Governance is core to cloud computing success now and into the future. Governance puts limits or guardrails around resources and services to protect them from misuse, and over- or underuse. Today, most enterprises don’t leverage formal governance and will soon find that it’s unavoidable.
Cross-Platform Financial Operations (FinOps)
FinOps has just emerged as the primary means to deal with cloud costs, and the management and optimization of cloud costs. Moving forward, FinOps will cross all platforms to provide true cost optimization.
Cloud-based systems can’t work on an island. They need visibility into the other systems as well, including legacy and edge computing systems. Just because we own the hardware, the idea that we don’t need to manage costs on those systems is just not true. The focus moving forward needs to be on cloud-based resources, as well as how they interact with existing and net-new systems, cloud or not, and how that impacts the ROI value for the business.
Figure 10-7 depicts the benefits of FinOps programs now and into the future. FinOps programs can obtain the maximum amount of value from system resources, which means FinOps will monitor all cloud and non-cloud resources, which allows us to look at how everything works together to provide optimized business value. This approach is a bit different than the FinOps of today that focuses more on cloud resources, or even the resources of a single-cloud provider. That information does not tell us much, other than how a few systems are optimized.

FIGURE 10-7 The core objective of any FinOps program is to monitor cloud costs ongoing and provide information that allows organizations to obtain the maximum amount of value from all computing resources, cloud and non-cloud. FinOps will extend to all systems in the future.
Tomorrow’s FinOps will help developers, operations, finance, and other business teams understand and control all system costs. As we mentioned earlier in this book, there will come a time when non-cloud options offer the most cost-effective solutions. Thus, non-cloud options need to be included in a FinOps program and include observability around how non-cloud and cloud-based resources utilize non-cloud options, and how much business value they generate. If your FinOps program is limited to cloud-only operations, you won’t get the entire picture and you will have limited visibility into cloud-only parts of the cost optimization story.
FinOps also needs central visibility to support data-driven business decisions using near-perfect information to make the most optimized decisions. Again, this goes to observability as the primary objective of future FinOps: Understand what the current state means in the context of many other things that happened and are happening now. Based on that information, make forecasts as to what’s most likely to happen in the future.
The way we view value will change as well. Right now, the focus is on hard cloud values, such as operational cost savings or how much of our own computing equipment we can shut down in favor of cloud computing. As shown in Figure 10-8, this only tells part of the story. Existing and future net-new cloud deployments must work with other technology consumption solutions such as co-location (co-lo) providers, managed services providers (MSPs), and even some of our own hardware.
Moving forward, soft values will be much more important. However, they are much more difficult to determine. Most enterprises don’t trust “dart board” soft value estimates, or they don’t know how to estimate soft values such as business agility, speed-to-market, and other factors that are much more complicated to put a number on. Most systems’ spending doesn’t make much sense without trusted soft value numbers, including cloud computing.
The dirty little secret of cloud computing is that the hard values are just not there, and it’s not so secret anymore. It’s time to look at soft values to justify cloud and non-cloud systems for modernization and expansion. Hype drove yesterday’s decisions, business value drives today’s systems decisions. Hard values may or may not exist. Soft values need to be included in your FinOps program as well.

FIGURE 10-8 The two major types of cloud values are hard and soft values. Hard values are easy to determine, such as the decreased cost of using cloud resources versus more traditional approaches. Soft values are more difficult to determine but end up being of much higher value. Examples include the enhanced values of business agility and speed-to-market delivered by cloud computing.
Cross-Platform Data Federation
Data is the most difficult problem to solve for those looking to modernize their systems. For the last 20 years, I’ve listened to enterprise after enterprise complain about the state of their data, and how they vow to redo and consolidate everything. It’s never done. Instead, the data situation gets worse as more net-new databases are added and complexity is compounded by new database models—for example, the addition of purpose-built databases to deal with a specific application that’s added to pre-existing relational and object databases.
Every enterprise has scads of legacy data that may exist in dated database technology, or even in direct I/O to storage that needs to be part of the database story as well. If we ignore that data and just refocus on cloud-based databases, that approach won’t provide the value needed to make a business case for moving to the cloud. All data needs to be included and leveraged using managed and secured mechanisms that can span all data, cloud and non-cloud. So, how do we solve this values problem moving forward?
Data federation is the most-likely candidate to fix most of the value issues. The data physically will stay where it exists in cloud-based systems or traditional platforms, and data federation will leverage the data using a common control panel. This is depicted in Figure 10-9. Although aspects of this approach are possible today, complete data federation across all platforms, cloud and non-cloud, is difficult to pull off. Data control panels must provide full database virtualization, or the ability to view all data using any schema and metadata model that works best for the application or human that consumes the data. It won’t matter where the data physically exists. You may not even know its location for security reasons, but you will access any data you are authorized to access, at any time, for any reason, in the way you need to access it. The consumption and production of the data will be handled using a common layer that spans all platforms.

FIGURE 10-9 A multicloud leverages data across many public clouds, and it needs a common data control panel. This control panel includes data virtualization or data abstraction, data governance, and data operations, including data observability.
The data control panel should include controls that manage fundamental data issues, such as compliance, and data governance, which allows us to put limitations on data consumption. Observability also needs to be on the control panel for reasons presented earlier in this chapter. The final control panel options should include data operations, security operations, backup and recovery, cross-database management, performance management, and all the blocking and tackling that goes into managing a database. Again, aspects of this data control panel exist today, but only in bits and pieces. The final solution will require more innovation and acceptance in enterprise IT. I suspect that enterprises will have little choice but to adopt a data control panel approach—especially after they come to the hard realization that data complexity will reduce or eliminate the value that data could bring to the business.
Changing Skills Demands
Addressing skills again, let’s focus on what the future will bring. Although the need and demand for cloud skills will most likely increase (if past patterns are any indication), the profile of the in-demand skills will change as well, as it always does. It’s in your best interest to keep skills in mind as you define the next generation of systems to build. This skills list should include cloud and non-cloud skills.
A limited supply of skills will limit your ability to modernize and evolve your systems. Thus, the availability of the required on-staff and on-demand IT skills will determine the enterprise’s degree of success. As I write this book, I’m hearing about all kinds of cancellations and limitation issues with cloud migrations and net-new cloud deployments due to the unavailability of qualified cloud technologists. Although many enterprises believe they can just toss money at a hiring problem, that’s typically not the case with cloud computing. It’s a constant game of “Where’s Waldo?” with a single qualified candidate hiding within a sea of unqualified candidates, or Waldo already works for your competition. Paying more helps, but it does not solve the longer-term problem. So, it’s advantageous to look at how the demand for skills will evolve to make sure you have as many Waldos on staff when they’re needed.
Cloud Generalists vs. Cloud Specialist
One of the issues that keeps arising is the demand for a specific skill set. Just a few years ago, a cloud certification focusing on a single popular cloud provider was enough to get you a “cloud job.” These days, the focus is on specialization such as [name a public cloud brand] security engineer, or [brand] developer, or [brand] architect. The focus is on very specific skills in the narrow versus general skills in the wide.
Figure 10-10 depicts what this demand looks like moving forward. Specialized [cloud brand] technology skill sets become more desirable than cloud computing generalists in architectures, security engineers, operations architects, and so on. Looking from the wide to the narrow will hurt us at some point, and many enterprises have already hit that hiring wall.

FIGURE 10-10 In-demand cloud skills seem to be shifting from generalists to those with specialized skills. It’s no longer a qualifier to be a cloud data expert; it’s best to specialize in a specific cloud provider and cloud-native database. Generalists, including good cloud architects, are in demand as well, but not as much. This could lead to problems if only a few hires are looking at more holistic issues within the cloud architecture.
I’m telling you this for a few reasons. If you focus your career on general cloud computing skills, you will still find a cloud job. It just won’t be as readily available or pay as well as the job that requires specific cloud skills. Cloud providers offer certifications for these narrow skill sets and then convince enterprises that they need these specific skill sets to survive. It will take time for enterprises to realize they also need cloud generalist skill sets.
There are valid reasons why providers take this strategic path—namely, to expand their role in a specific enterprise to expand their business. The unintended consequence of branded certification requirements is that IT often misses the bigger picture issues that will only be caught by those with a broader knowledge of all solutions, cloud and non-cloud; thus, IT staffs will often lack the ability to take a more strategic look at the big picture of cloud technology.
I suspect that this inability to see the big picture will have a few negative effects, including the fact that many viable solutions won’t be considered because no one in the organization understands how they work, or why they should be leveraged as an alternative to the current path. As we discussed earlier in this book, on-premises systems should still be considered a potentially viable solution, as well as other cloud providers and other deployment architectures such as edge computing. Without knowing what the other options are or how they could provide potentially better fits, enterprises often leverage suboptimized architecture (which we cover later in this chapter).
Less Code, More Design
As I write this book, there’s a lot of buzz about low-code and no-code development. Simply put, this type of development can create applications using visual interfaces that sometimes have the ability to add code. The idea is that it democratizes development by allowing those without much training to build and deploy their own applications. Although this capability sounds compelling, it’s not right for all development work. In many other instances, this approach leads to more robust software development projects where the low-code and no-code development is moved to more common application development and deployment approaches.
The point here is that the likely path moving forward will be on systems built using less code, with the focus on the design rather than the underlying mechanisms that make up the application. This approach will provide several core benefits:
The ability to create systems and applications faster and deploy them closer to the speed requirements of most businesses.
The ability to change these applications and systems faster, including core databases and application functionality. Again, we can create and change these applications at the “speed of need.”
The inclusion of the end users in the design of these systems and applications. Right now, requirements are fed into developers who turn out their interpretation of the application solutions. In this low- or no-code scenario, end users actively participate in the design of the applications and even create portions of the applications themselves. This approach should deliver a better final product that better meets the specific needs of the business.
Architectural Optimization Is the Focus
Future optimization will include all systems, cloud and non-cloud, and thus we must move to more strategically focused system deployments. Most initial cloud deployments are much less optimized than they should be, with survey after survey reporting substandard ROIs relative to the promised values of cloud computing. We’ve covered aspects of this type of optimization already, so I don’t redefine it in as much detail here.
It’s time to stop deploying the most popular technology that might “work” but typically results in underoptimized solutions. Figure 10-11 depicts the next shift that will align the end-state solutions with both the business requirements and the optimized use of technology that returns the maximum ROI. This will be a nice change.

FIGURE 10-11 Architecture shifts to become an optimization exercise where we look for a solution pattern that provides the most value for the business. This is a change from cloud architectures that are grossly underoptimized and thus much less efficient than they should be, although they may appear to “work.”
Cloud Security Shifts Focus
Cloud security focused on specific siloed deployments to solve cloud security problems in the past. As mentioned earlier, security will most likely become more centralized and exist logically above all public clouds, and even traditional systems in operations. Let’s look at what security systems themselves are now and what they will likely become in the future.
Figure 10-12 depicts the as-is state of cloud security and security in general. There is nothing surprising about how we deal with security today. We typically focus on identity-based security for each cloud deployment as well as some encryption services. Although biometrics are there for multifactor authentication (MFA) (that is, fingerprint recognition on your iPhone), it’s not leveraged at scale. Neither is observability, where we could look for insights into states that may be an indication of a breach and then take defensive actions as an automatic response.

FIGURE 10-12 Today’s security focuses on core security services such as identity and encryption.
Figure 10-13 depicts the most likely future that features centrally deployed security at the higher layers of the architecture (for example, supercloud/metacloud), which is systemic to all these forward-looking evolutions. New security evolutions will make cloud and non-cloud security more effective than it is today.

FIGURE 10-13 Future security will watch many things and determine insights into those things, that is, security observability. We will spot issues using any number of data points and determine the underlying meaning that relates to security issues, and then automate protection from those issues. This will become the preferred security approach because it considers many things at the same time and thus becomes much more effective.
Figure 10-13 also depicts the most obvious change, the rise of observability. The focus is on proactive security with insights into system states, and what that means to the active security posture. For example, CPU saturation on several cloud-based servers could be an indication of a breach attempt. Observability gathers future insights to determine whether that’s true or not. Today, we wait for things to happen and then respond. A good analogy would be if you have an outdated home security system and burglars break in through an unmonitored window. You must wait until (and hope) they set off an indoor alarm to notify you and authorities. This wait results in more damages and losses, and potentially puts responders in more danger. Instead, today’s security cameras and motion detectors can determine suspicious activity near your home and respond defensively with sirens and notifications to you and/or authorities, which could help avoid the break-in altogether along with its costs or risks.
Biometrics will rise in use for a few core reasons. First, devices that interface with fingerprints and retina scans are getting much less expensive and more accessible. Sometimes people use the same passwords for everything, and that gives the bad guys access to everything after they crack the first password. An astonishing number of passwords are still on Post-It notes stuck to monitors around the world. You know who you are. In your defense, technology users have also hit a complexity wall. Most people can’t possibly memorize all the passwords now involved in our daily lives. It’s much easier to invest in a retina, face, or palm scanner than it is to memorize and/or constantly update passwords, and/or hope no one hacks into your online password manager. Passwords do work, but biometrics are much better.
Cloud Computing Becomes Local
The heading of this section really says it all. Figure 10-14 reflects how future points-of-presence (the physical location of cloud data centers) will multiply and disseminate. Right now, cloud data centers are concentrated in a few physical regions, including one a few miles from where this book is being written. As we move into the future and the workforce continues to geographically disperse itself, the number of cloud computing data centers located just down the street from you will increase no matter how remote you choose to live.
Why? The cost of deploying data centers continues to fall, and remote locations will provide more economically viable alternatives. Higher-performing applications that require less latency will drive this demand as well. Public cloud providers should respond to this shift with more flexible billing terms, and not focus as much on regions as they do today. Data centers should be deployed anywhere and run anywhere at some point in the future.

FIGURE 10-14 Today most providers cluster data centers at or near the same locations. More modern clouds will place cloud data centers everywhere so that they will be closer to their ultimate users. This placement should provide better performance and reliability.
Industry Clouds Become Important
Industry clouds with purpose-built industry-specific services will increase in popularity, as depicted in Figure 10-15. These types of clouds will support faster solutions development, because many of the services required for a specific vertical (that is, retail, finance, health care) are easier to leverage as prebuilt services rather them building them from scratch each time.
Industry-specific services will include database schemas and specialized security for certain industries (such as banking and health care). Again, the market motivation is to move faster by leveraging services you don’t have to build yourself. Currently, public cloud providers are teaming up with industry-specific consulting firms and developers to build and deploy these services. It will take years for these new services to significantly impact affected businesses, but you should have them on your radar.

FIGURE 10-15 Cloud providers are beginning to offer deep industry-specific services, such as the services that finance, government, and retail find most valuable. The more work that’s already done for you, the lower the cost. The industry-specific services will also be more reliable because they are better tested through sharing.
Where Is Edge Computing?
It’s not going out on a limb to say that edge computing will continue to rise, with many of the systems and services that are now a part of public clouds moving to the edge. However, edge computing must be at the edge of something. That “something” will be public cloud providers. After all, the two are related.
If you look at today’s most popular edge computing technology providers, they include all the big public cloud providers. So, edge computing will become just another architectural option that you can leverage if it makes good business and technical sense for your application and/or system. Therefore, it should continue to be on your radar for future evolutions of cloud, and of technology in general.
Figure 10-16 is an example of a modern edge computing system; in this case, it provides a set of services for a motorcycle. Note how the core subsystems are divided into systems that are on the device—in this case, on the bike—and systems that exist on the back-end system on a public cloud provider. The reason for edge computing here is obvious. The system needs to make immediate decisions on the bike, such as turning off the fuel pump if the bike is tipped over. Other systems are more effective off the bike and on the public cloud provider, such as gathering mechanical metrics over time to determine if you have an impeding breakdown event that’s preventable if caught before it happens, such as a part that’s known to break at a certain wear level. The potential system value and ROI are huge if we keep this architectural option in our back pocket.
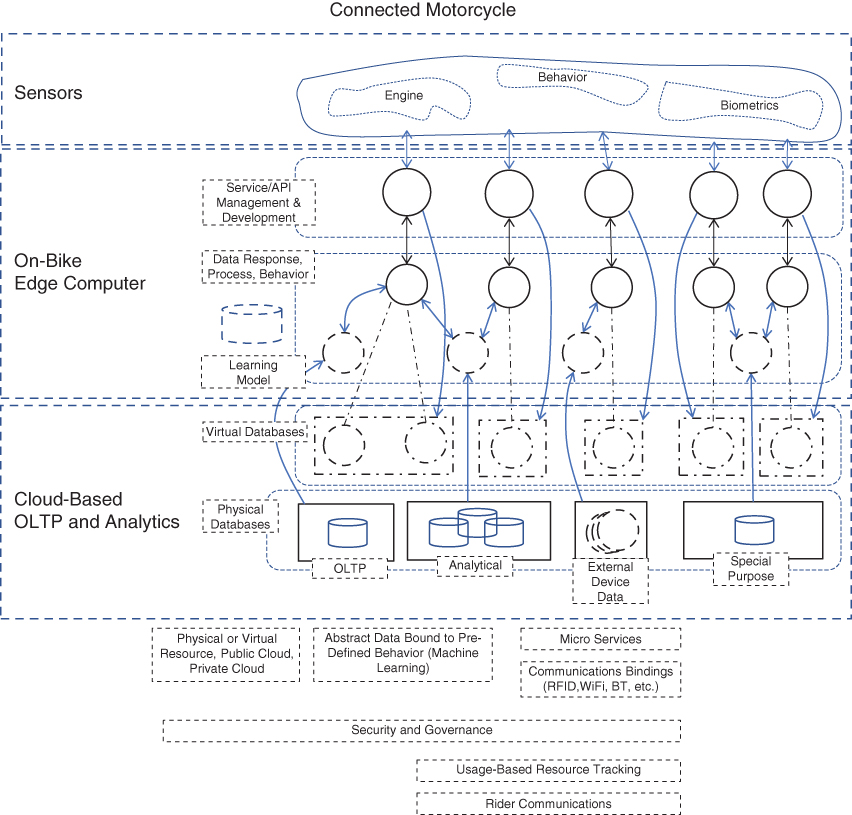
FIGURE 10-16 This example of edge computing depicts a connected vehicle (motorcycle), which hosts an edge device. That device has three different architectural layers. The sensors are physically attached to the bike to gather data. The on-bike edge computer contains the edge computing system that locally gathers and stores data with some processing (even lightweight analytics), and AI (knowledge at the edge). The cloud-based back-end system does some of the heavier processing and provides deeper capabilities around the use of AI and data analytics.
Call to Action
The primary reason we’ll continue to leverage cloud computing is due to its ability to promote innovation, as well as to build products and services that are innovative unto themselves. In Figure 10-17, you’ll notice we flipped the pyramid. Innovation was a smaller result of leveraging most technologies, with the focus being on business efficiency using automations that provided a better product and customer experience. The need to provide a good customer experience remains important, and it’s now more achievable with better technology. Now and moving forward, the focus turns to innovation.

FIGURE 10-17 Innovation was once a random by-product of any technology, valued far less than the customer experience or production efficiency. Today, innovation is the primary value driver for cloud computing and the reason most enterprises go through a data transformation to get the business to a better state.
Value comes from innovation in our modern economy. It’s the reason innovation will remain the focus of cloud computing. If you think about it, we live in a time when we have major transportation companies such as Uber and Lyft that don’t own most of the vehicles that provide their services; they just provide the innovation around how you find and leverage those vehicles. The economy will evolve as innovation becomes the ultimate value. Cloud computing enables faster innovation, which is a major motivator to continue using these technologies.
The future value of cloud computing will be defined as the fastest path to a more innovative business, which is the fastest path to value for the business. Innovation is the reason cloud exists and thrives today and will into the future. Apply the points made in this chapter to make some good bets on where the market is moving and how you and/or your company can take advantage of the evolutions.