
Chapter 2
The Realities and Opportunities of Cloud-Based Storage Services That Your Cloud Provider Will Not Tell You About
Nothing makes us so lonely as our secrets.
— Paul Tournier
In this chapter, we take on the pragmatic use of cloud computing resources. We focus first on storage and then move on to compute in the next chapter.
We also cover the more modern offerings such as serverless, AI, and so forth later in this book. However, we don’t focus on the use and definitions of these cloud computing services; there are plenty of places you can go to figure that out. Instead, we look at how to effectively use these services to solve real business problems.
We also discuss some of the confusion around cloud services, some of it caused by the marketing messages from the larger cloud providers, some from confusion and cheerleading from the tech press, and, realistically, some of our own confusion as we think like a flock of birds and all move in the same direction. Sometimes it’s the right direction, but most of the time we need to course-correct as we fly.
The purpose of this chapter, and really the entire book, is to get you flying in the right directions to effectively leverage cloud computing and other technologies.
Cloud Storage Evolves
In the beginning, Infrastructure as a Service (IaaS) providers all had one thing in common: They all provided storage systems. This includes the two dozen or so cloud providers that popped up around 2008–2010 at the beginning of the cloud hype. Storage growth exploded as raw data and binaries (for example, video and audio files) experienced such rapid growth that enterprises struggled to keep up with new and bigger on-premises storage systems. These systems included raw storage such as object, block, and file storage, as well as databases that leverage raw storage.
Storage costs soon became the focus of IT budgets, with storage often accounting for up to 60 percent of IT spending each year. It’s no surprise that enterprises were eager to find more cost-effective solutions. Enter the ability to purchase storage as a utility, and thus the rapid rise of IaaS cloud computing.
What happened between then and now is that IaaS cloud providers, most of whom provided storage, were unable to keep up with better-funded hyperscalers such as AWS, Microsoft, and Google. They either exited the IaaS cloud market, got bought out, or pivoted in more unique directions. Today, practically speaking, we have only about five to seven viable IaaS clouds, with three holding most of the market.
Of course, IaaS cloud was never just about storage. Cloud compute, databases, AI, serverless, DevOps, security, governance, operational, and other specialized services (such as IoT and edge computing) provide more holistic solutions. Enterprises go to the cloud for a complete solution that will match or surpass existing capabilities onsite.
Therefore, cloud computing should be considered as an entire holistic platform, in terms of value. But it’s helpful to separate and break out the larger cloud resource offerings (such as storage) to determine opportunities for better optimization of the technology itself and the cost.
Here are the primary reasons to focus on the best ways to use cloud computing storage:
Storge is a component of most services leveraged on public clouds, including databases, AI, development, and anything that stores durable information between compute sessions. In most cases, you don’t know it’s working behind the scenes until you see the monthly bill.
For most enterprises, storage is the largest portion of their ongoing cloud budget. Moreover, it increases exponentially year over year.
Cloud-based storage systems house more and more corporate data each year. Many believe that a business’s data is the business. As such, the importance of selecting and leveraging the best storage system in terms of security, performance, and resilience becomes a much higher priority.
Junk Data on Premises Moved to the Cloud Is Still Junk Data
Backing up a bit, let’s focus on how most enterprises first leverage cloud storage. Most migrate applications and data to the cloud, and thus must pick sound analogs for their platforms (including storage and compute). Again, this initial system could leverage raw storage, such as that needed to store structured and unstructured data. However, most enterprise storage comes along with the databases they want to leverage. Examples are large relational databases such as Oracle or moving to proprietary purpose-built cloud databases such as the dozens of object-based databases that are offered only as a public cloud service (such as AWS’s DynamoDB). It’s helpful to first look at the process of data on premises-to-public cloud migration and then look at how and where we can find areas of improvement.
Here’s the core mistake that most in IT make when they migrate data to the cloud: They move data, databases, and raw storage systems that are in a poor as-is state, including data that has no single sources of truth.
We’ve all seen this happen. The first outcome is a ton of redundant data that requires unneeded excess storage. The second outcome includes the larger problems of poorly designed and deployed data storage systems that lack efficiency or the ability to allow for easy change. Data in a poor as-is state on premises will be just as bad, if not worse, in the cloud (see Figure 2-1).

FIGURE 2-1 Broken and poorly designed on-premises data won’t fix itself when you move the data to the cloud.
Efficiency, simply put, is the ability for the storage systems to serve people and applications in the most optimized way possible, including cost efficiency, performance efficiency, and the ability to support all business requirements such as security and governance. The challenge here is to get those in charge of moving storage to the cloud to understand that they have an existing problem to solve before they can move the data.
Most believe that the public cloud’s ability to access as many resources as needed will solve many of the existing problems with performance and capacity issues. In some regards, this is true. You can certainly throw resources and money at problems, and they will become less noticeable. That is, until someone bothers to read the monthly cloud storage bill, which is likely many times what it should and needs to be. Efficiency is about doing the most with a cloud storage system to support the business goals and minimize the cost of using those resources. This level of efficiency only comes with fundamental design and deployment changes that need to occur before or during the relocation of these storage systems to a public cloud.
Support for change is the storage system’s ability to support core changes in processes and thus data stored in databases or on raw storage systems. As described in Chapter 1, “How ‘Real” Is the Value of Cloud Computing?” agility is a fundamental benefit (that is, soft value) of leveraging public cloud computing resources. However, having the ability to support rapid change by using cloud storage services does not mean that you have optimized agility.
For optimized agility, you must consider the core design of the database along with the current and future ways you will leverage the data. We’ve all had the experience of changing the meaning or structure of data to meet a new business requirement, and then we watch that change break a dozen or so applications that are tightly coupled to the data. This does and will happen if the data is not designed and deployed to support change, even if it’s on a cloud storage platform that enables easy changes because resources can be instantly added and removed. Broken data is still broken data.
The bad news is that migrating data to the public cloud will usually make the situation worse for most businesses. Take some time to fix the issues before or during the migration process via major or minor design and deployment changes. Otherwise, poorly designed storage systems (including on-premises data) will be just as bad or worse in the cloud. To compound the problems, the “panic fixes” deployed in the cloud (for example, just tossing resources at problems) will result in more cost inefficiencies.
Many mistakenly think that cloud providers will also offer best practice information about moving data from on-premises storage systems to their cloud-based storage systems. Think that through for a minute. It’s not their responsibility, and there is zero business incentive for them to increase your storage efficiencies and agility because poorly planned results make them more money.
This failure to provide best practices does not mean that cloud providers are working against you; they’re not. The providers are in business to be experts at providing well-maintained storage services. It’s their job to keep their services running and to fix any issues that arise on their end. You, not cloud providers, must be or become the expert in terms of what your business needs to solve its specific problems. It’s your responsibility as a technologist to leverage the technologies in the most efficient and effective ways possible. Providers will not actively work to ensure that you’ll be efficient with your own storage needs because they can’t. If we fail at our end of the bargain, that’s on us.
The cloud providers call this “shared responsibility.” You’ll encounter this term with most major cloud systems, especially security. They provide the tools, but how you use them to serve your own business needs is entirely up to you. Ultimately, your business use of their products is your responsibility.
This relationship is much like our relationship with our electric power providers. We know that a poorly designed and maintained HVAC system for our home will result in higher electric bills. With a bit of research, we can fix and/or replace the system and improve the efficiency of our electric usage. However, it’s on us to act and do what’s best for us or our business. Cloud storage is no different.
Lift-Fix-and-Shift
Many of us are already familiar with lift-and-shift, where we just move the applications and data from the traditional platforms to a public cloud provider with the minimum number of changes needed to make it functional in the cloud. Lift-and-shift does not look at how to optimize data storage, but at how to do the move as cheaply as possible. Lift-and-shift “kicks the can down the road” by just migrating a problem from one platform to the next. We’ll eventually have to fix the problems or suffer the consequences of leveraging bad data, no matter where it exists.
Instead, we should fix issues with storage and data before or during the movement to the cloud. It’s a best practice to take the existing on-premises data and improve or “fix” the data as it’s moved from the on-premises storage systems to the cloud storage systems. We can call this lift-fix-and-shift.
Figure 2-2 depicts the basic idea. We start with the existing data, which is on traditional on-premises platforms, in most cases, but can also be on public and private clouds. The core issue is that the existing data is in a bad state, and we need to “move and improve” it. In other words, it’s our intention to change the data and typically the attached applications as well, for the better.
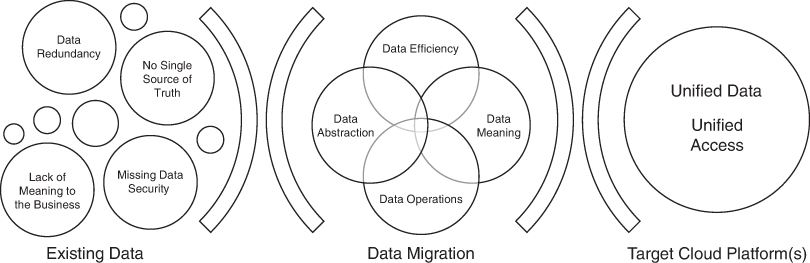
FIGURE 2-2 We must fix data before or as it’s being migrated to the target cloud or clouds. The idea is to get to a unified data storage system, with unified and meaningful access.
Again, referring to Figure 2-2, we move toward a state where we eliminate data redundancy, establish a single source of truth, define a true business meaning of the data, and meet the minimum data security requirements. These are only a few of many issues we may have with the as-is state of data.
Moving on to the migration of the data, we have several methods to make the data easier to use by applications and humans. There are technologies such as data virtualization to hide dysfunctional physical data structures that can create an abstraction layer between the physical data and the applications and humans that need to leverage the data in more meaningful ways. The data has true meaning, such as the concept of a “customer” that may be an aggregation of 100 different data elements, from a dozen different physical databases. We move it from a confusing amount of information to place customer data in a single place where it is easy to find and to leverage, with meaningful data that we would normally associate with a customer, such as name, address, phone number, and account. This can happen only after we’ve fixed the data and storage issues as our data and applications move to the cloud.
The approach here is to look for a “minimum viable data layer” that can produce a single source of truth, no matter if you’re looking for customer information, an invoice, sales history data, or anything else you need to know to effectively run the business. The goal is to avoid major costly and risky changes to the back-end data storage systems. This is not to say that the same data would be undiscoverable if the existing data models, structures, and storage systems were just relocated to the cloud, but the lift-fix-and-shift approach does not cost that much more than just pushing the problems down the road. Because you pay for cloud services based on the efficiency of your data and applications, you’ll likely avoid a much larger bill as well as provide better data access to services that promote more efficiency, agility, and innovation, which, as we covered in Chapter 1, go right to the bottom-line value of cloud computing.
The objective illustrated in Figure 2-2 is clear. The goal with lift-fix-and-shift is to create a unified data layer, with unified data and unified access. Enterprises have long dreamed of this ideal, but most don’t get there. Instead, many just layer new databases and data storage systems over old and never really figure out what the data needs to do. So, most enterprises are not there yet…even if they say they are.
A unified data layer means that we have the following advantages:
Common views of data related to all concepts that need to be leveraged by applications, such as a single view of a customer, invoice, inventory, product, or sales record, which often number in the thousands for more complex enterprises.
Common access to the data, typically using APIs such as services and microservices. This means we provide access to the data using a controlled mechanism. These API/services can monitor what questions are being asked of the data and how to respond with the right data in an efficient way. This capability is critical to a unified data layer because we also provide behavior that’s bound directly to the data, which can be leveraged directly from an application without having to add behavior each time as to how the data gets leveraged. This access needs to be truly unified, which means the data, no matter where it exists, can be found, and then read through these unified interfaces with all the connectivity, security, and data operations taking place behind the scenes. The end game is to have access to all data, at any time, for any reason, and put the burden on the unified data access system to make this happen, and not on the end users or the developers, as was done in the past. Common access should work across all platforms, including all public clouds, private clouds, traditional on-premises systems, and so forth.
Common security and governance define how the data is to be secured within the data. For example, allowing access only by a specific group of users and applications and then placing guardrails around this data access layer (such as allowing data access only every one second) to push off performance issues (such as those caused by a developer accidentally saturating the data with a single application). Keep in mind that common security and governance are not cloud-only, but across platforms and systems that include multicloud, private clouds, and traditional systems. The goal is to solve data security and data governance once and then use those solutions everywhere they’re needed.
Common metadata that spans applications, databases, cloud platforms, and even traditional platforms. While a discussion of master data management (MDM) is beyond the scope of this book, it’s a powerful concept related to how we understand the meaning of the data within a few databases, as well as within databases operating across different cloud providers (multicloud), databases on traditional platforms such as mainframes, and any new types of platforms such as edge computing and IoT. The idea is to understand what the data means no matter where it exists and have access to it using a single unified access mechanism.
Cloud Storage Abstraction: Shortcut or Innovation?
Let’s drill down a bit on single storage systems and databases, and those that operate across cloud providers or within a single provider. Here we look at how to deal with any number of the same or heterogeneous data stores that exist in a single public cloud or may exist in many public clouds. The goal is to get to a state where it really does not matter.
Building on the concepts introduced in the preceding section, again we want to deal with data complexity and find data meaning using common mechanisms that don’t solve a data problem one single time, on one single cloud platform. Instead, the system should provide unified, secured, and governed access to all data using common interfaces that can span application solutions.
Unfortunately, this is a problem that enterprises rarely solve. Most enterprises still rely on several different mechanisms to access a variety of different databases. More disturbing, the data storage systems are tightly coupled to the applications. This means that any changes made to the database, such as changing the zip code attribute from five digits to nine, would end up breaking most of the applications that are coupled to that database.
It’s time to do a few things better, including decoupling applications from data storage. Decoupling allows changes to be made to the physical databases without having to drive changes to all applications. More importantly, and as we learned in the preceding section, decoupling provides the ability to get to a unified data and access layer that can simplify access to the data, and do so across cloud providers, database technology providers, and other technology that may add to the complexity.
We can accomplish this goal in a few ways. First, blow up all the databases and combine the data and the data entities into a single unified data storage system that’s the mother ship for all enterprise data. As you may recall, this was tried in the ’80s and ’90s with the acknowledgment that big honking enterprise databases from vendors such as Oracle, IBM, and others would be the destination for all enterprise data. Unified data storage would provide a single way to store and access the data.
This approach did not work for several reasons, primarily because a single database could not (and still can’t) solve all our business problems. Purpose-built databases do provide more capabilities, such as providing better transactional performance or more flexibility in how data is stored. Databases that are data warehouse-focused or transactional-focused meant that we had a mix of different databases. All store data in different ways, with different meanings for the same data (for example, customer), and use different methods to access the data, everything from SQL to cryptic APIs. So, blowing up all the databases and forcing all data to move to a single database almost never works.
The second option is to change all the back-end databases to some sort of unified standard way of looking at the data. At the same time, normalize the databases so there is no redundant data being stored, and there is a single source of truth. Although you still have the same number of access approaches and mechanisms as you do data storage approaches and databases, this is the price you feel you must pay to leverage best-of-breed data storage, one that’s been heavily modified to build a heterogeneous data layer that’s much easier to use and understand.
Of course, there are issues with this second approach as well. Namely, you must still operate a very complex data layer and run different databases that you will need to operate and administer, including changing the physical structure of the data that must be reflected in the applications that are coupled to the data storage systems, from raw storage to sophisticated databases. While this is an improvement over the first option, you must still deal with many of the same issues you dealt with in the past, including data complexity that leads to efficiency issues. This approach is also prone to errors.
The third option involves a concept that’s been around for decades, and one that I first addressed in my Enterprise Application Integration (EAI) book back in the ’90s. Data virtualization was a game changer back then, but the technology had some evolving to do. As you can see in Figure 2-3, using the data virtualization concept, you don’t have to change all the back-end databases to some sort of unified data model. Instead, you put forth an abstraction layer or a virtual database structure that exists only in software. Its structure and data representations, including metadata, map directly to back-end databases that can include objects, attributes, tables, and elements.
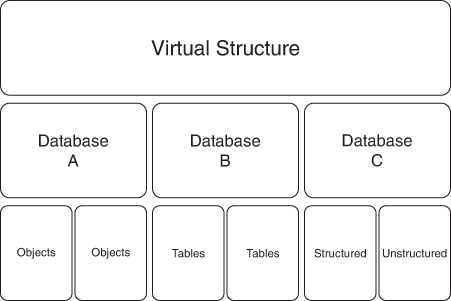
FIGURE 2-3 Data virtualization is an old technology trick that allows us to fix data issues in middleware, above the physical databases. We can map any physical structure, no matter how poorly designed, to a new abstract structure that will better represent the way that the business needs to use the data. This can be done in the cloud and/or on traditional systems.
Data virtualization technologies allow us to represent the data any way that we would like and provide unified access to the data. It’s the job of these tools to translate the physical representation of the data into a virtual representation of the data. The virtual representation is more meaningful to the business because it includes a single source of truth for customer information that might be an abstraction of four different physical back-end databases, as we can also see in Figure 2-3.
Data virtualization provides several advantages. You change only the virtual structure to support a required single application-driven change rather than change the actual physical database, which could end up breaking 20 other applications that are coupled to the database. As far as the single application is concerned, the data is represented in a new way that the application requires. Any other applications connected to the database, whether they access the physical database directly or through the data virtualization layer, will see the same structure, either virtual or physical. In other words, data virtualization puts data volatility into a configurable domain.
So, why bring up data virtualization in a chapter about cloud data storage secrets? There are many benefits to using data virtualization technology as we look to modernize and cloud-enable our existing data. Today’s data virtualization (a.k.a., cloud fabric) can work within a single cloud provider, and it can be made to work across multiple cloud providers. This allows us to deal with overly complex and distributed data that exists over many public clouds, private clouds, and even existing legacy systems on premises. Data virtualization deals with data in the same way, no matter where it’s physically located or how it’s structured.
Many view data virtualization as a work-around that just pushes off the need to fix all the back-end data stores. Data virtualization becomes a more realistic approach when it reduces the cost and the risk of changing data that’s moving or has moved to the cloud. Yes, you could go to the back-end data and fix everything, and that would be a good call. However, in the real world, no one has an unlimited budget to move data to the cloud. The amount of time and talent needed to manually change all of the back-end databases is the most expensive option possible, although it will provide better business meaning and a single source of truth. Most business leaders would ask you to come up with a less expensive but still best-possible solution. Data virtualization provides a compromise.
There are downsides to all technology solutions, and data virtualization is no exception. First, you must pay for data virtualization technology through a subscription within a public cloud provider or use traditional enterprise licenses. While there are open-source solutions available, the cost of the talent and time required to customize a solution will incur an eyebrow-raising line item in most enterprise budgets. Second, there is a bit of a performance hit when you leverage a data virtualization layer. The severity of the hit depends on the complexity of your data-to-virtual data mappings, thus how much processing needs to occur behind the scenes, but it’s not as good as direct native access to the database. On the positive side, the advances made in high-performance input/output systems now provide better performance. Considering that we’ve been at data virtualization for about 30 years, give or take, data virtualization technology is perhaps the best that it can be.
The Fallacy of Structured Versus Unstructured Data Storage
The last several years saw an explosion in the amounts of structured and unstructured data, in the cloud and not. The idea is that some data exists within a structure, such as the Oracle relational database. Unstructured data includes anything else of meaning such as documents, audio files, video files, and other information that is not a part of a formal structure. Another way to look at it is that structured data exists mostly in databases, such as object and relational databases, whereas unstructured data exists mostly in file systems, like those you would find on your laptop.
When you move all data to the cloud, structured and unstructured, it’s my strong recommendation to deal with the data as a holistic concept. By this, I mean that no matter if it exists in a database or not, you can find the data, extract the data, process the data, and find meaning within the data. It shouldn’t matter if you leverage deep analytics tooling, AI, or simple business processes where decisions are made to support real-time business data, such as the status of shipping a product, or an alert to production to accelerate fabrication of a specific product based on inventory levels.
Data virtualization renders structured and unstructured data the same, because we’re defining a structure in middleware, which is applied on both structured data, such as a relational database, and unstructured data, such as a bunch of PDF files. You won’t hear that from the average IT person who moves data to the cloud or builds net-new systems that leverage data in the cloud. The IT tendency to deal with unstructured and structured data differently remains firmly embedded in the IT psyche. But that just leads to more data complexity and limits what developers, processes, applications, and other humans can do with the data. The end objective here is to leverage all data using a set of unified services or APIs that allow access to all data, at any time, for any reason, with the full meaning of the data available as well.
What we must deal with in the meantime is a set of data silos. Unfortunately, cloud computing just makes silos worse as we move data to data storage systems (such as databases in specific clouds). For example, let’s say we start with 10 enterprise databases on premises, and a file farm of documents and binary information (such as audio files). When we move to the cloud, we end up with 7 databases on premises and 7 in the cloud. The extra 4 databases came from new requirements found in the migrated applications, plus the trend to expand database heterogeneity and complexity to meet the expanding needs of the business. So, was this the right move?
Data needs to be part of the infrastructure, much like the infrastructure requirements for networking, compute, and raw storage. No matter what type of technology stores the data, documents, or binaries, we should be able to access all this information in the most optimally useful ways for the humans, processes, or applications to access and process the data. And they need the ability to do so without dealing with semantic differences in the data that exist between databases and to be able to bind data directly to documents and binaries if there are links and meanings.
The goal is to create something like the unified data access interface represented in Figure 2-4. Here we’re defining a single access point to all data, data within our data center, IaaS clouds, SaaS clouds, and so on. The data may be virtualized, meaning that we’re defining virtual schemas to represent the back-end physical data, or it may be just access to the native physical schemas. What’s important here is that we’re accessing the data centrally, and not pushing developers and data users to work through a bunch of native database interfaces, all that are different.
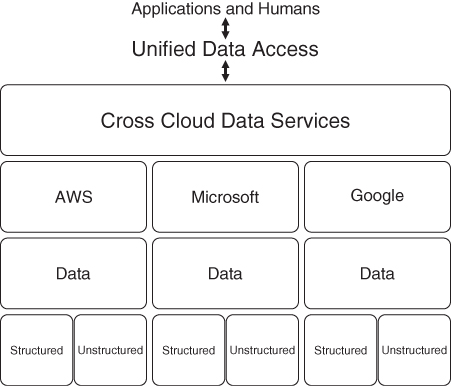
FIGURE 2-4 The ultimate objective of unified data access is to get to a data layer that crosses all clouds and even traditional systems. The physical back-end databases and raw storage simply function as data providers. We can leverage data from anywhere, at any time, for any reason, and (most important) use views of the data that are the most productive for the business.
Note
Whether the databases or file storage system exists in AWS, Microsoft, or Google clouds—or two or three of these options—does not matter. What matters most is that we consistently do certain things such as
Deal with data as a single layer, where all data that’s associated with a business including external data (from suppliers, for instance) exists behind a set of governed and secure database servers.
Manage the common meaning of the data, no matter where the data exists and/or how it’s defined within a specific database. We opt for more holistic understanding of repositories that exist across the databases and raw storage systems.
Define common security mechanisms that are coupled to the data rather than decoupled within some centralized data security system. The governance policies, security policies, and authentications are a part of the data and thus easily transferable when leveraged on other platforms, such as across a multicloud.
Referring again to Figure 2-4, we work from the ground up to meet unified data access objectives. Don’t focus on migrating the data from one database to another, but instead leverage the data where it currently exists, in whatever format it exists in. This applies to raw data such as binary files, all the way to highly structured data that may exist in a high-end enterprise database.
If you think unified data access will commoditize existing storage mechanisms, you’re right. I mean, who cares what the back-end database is or the number of databases; we’re looking at them the same way. If performance and functionality are good, the database can be anyone.
I’m not saying that the databases will go away, but they will have a diminished role over time. The focus on technology growth will include the tools that provide you with the ability to manage heterogeneous data, externalize that data, and provide the data as sets of services where meaning, security, and governance are bound to the data. This will exist at the “Cross Cloud Data Services” level shown at the top of Figure 2-4.
So, what specifically are “Cross Cloud Data Services?” They should consist of
Data virtualization and/or abstraction as defined in the previous section. This is the layer that can take data in any structure or with any meaning and remap it to a common set of structures and services.
Service management, or the ability to externalize microservices or other types of APIs that are discoverable and callable for any application, process, or a human using a data-oriented tool such as analytics.
Security and governance, including the ability to hide some data from those who need it for processing, but allow it to be used in that process in an anonymous form. For instance, the ability to leverage a security layer that keeps the data encrypted but still allows certain information to be seen by nonhumans, such as data with governance derived from laws and regulations. HIPAA data would be an example. In a more specific example, if you analyze the rise of a viral disease to create a treatment, you will need to analyze personally identifiable information (PII) of exposed patients, but you are not allowed to view the PPI portions of the data. It will remain encrypted, become visible only to the analytics processes, and won’t be seen by nonauthorized applications or any humans.
The quest for common and unified data access has been a topic of white papers and tech articles for decades. What’s different here is that it doesn’t matter how the data is physically stored and/or structured; we don’t treat the data any differently. We must figure out how to create a single unified data layer that contains most of the services we’ll need, as well as security and governance. Otherwise, multicloud and the future directions of complex and distributed cloud architectures will just lead to too much data complexity, which will prove impossible to scale. We must deal with the data access issues before we move to those architectures.
Secrets to Finding the Best Cloud Storage Value
Storage is fundamental to all cloud architectures, no matter if you create a simple cloud-based application or a complete cloud computing architecture for the enterprise. We need to persist files, information, and data as a foundation for how we do computing.
That said, it’s your business needs that will determine the type of storage you’ll leverage for a cloud or even a non-cloud-based solution. Business needs will depend on the industry the enterprise is in, any data regulations and laws that affect the enterprise, as well as the enterprise’s ability to take full advantage of the agility and innovation benefits of cloud computing as discussed in Chapter 1. Thus, “it depends” comes up a lot when it’s time to pick the right cloud storage solution…or any storage solution. It’s something you constantly need to adjust and monitor to leverage the best and most cost-effective storage solutions that meet the requirements of your applications and business, today and into the future.
What If the Best Cloud Storage Is Not in the Cloud?
Here’s something we often overlook when we search for a cloud storage solution: Cloud storage is not always the solution. Traditional on-premises storage could be more cost effective than cloud-based storage, even considering the potential benefits of cloud computing such as speed, agility, and the ability to better support innovation. Those soft values often make cloud computing worth the price of admission over more traditional storage solutions.
However, be sure to compare cloud-based storage to other storage solutions, such as traditional on-premises hard disk drive (HDD) storage, even when loaded with the additional costs of administration, power, and network expenses. Of course, there are other and perhaps better options, such as solid-state storage device (SSD), but let’s use HDD for our comparative purposes.
Cloud computing and traditional on-premises storage are typically apples and oranges, when you think of all the add-on services you get with cloud-based storage, such as maintenance, power, networking, and a layer of experienced people who keep the cloud storage systems running. You must consider those benefits and factor them into your cost and technical decisions. However, if your enterprise produces a product that hasn’t changed much over decades, where innovation or speed to market are rarely if ever factors while doing business, HDD storage could be a more cost-effective solution.
In the last few years, the price of on-premises storage, or HDD, has sharply dropped. Looking at Figure 2-5, you can see that around 2010, the prices for HDD storage leveraged for on-premises systems began to drop and continue to drop. The reasons for this are the normal ones, including better and cheaper manufacturing processes, and even the fact that cloud storage forced traditional storage vendors to become more competitive, in terms of pricing.
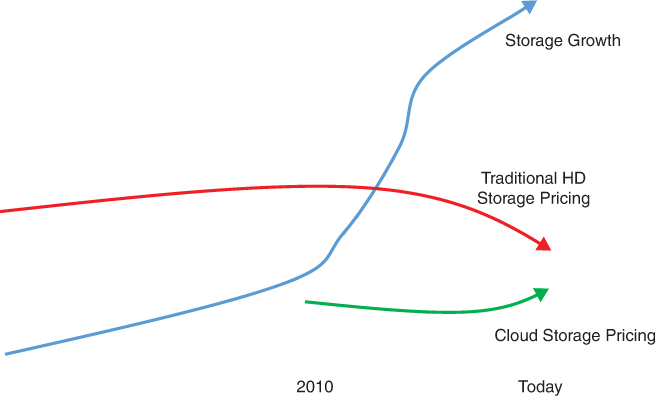
FIGURE 2-5 The prices for cloud storage remain stable and even rose over time. The prices for traditional on-premises storage systems fell in the last 10 years. While not the same, you need to consider the extra cost that comes with cloud storage. This does not mean that on-premises storage will be a better and more cost-effective solution in all business use cases, now and moving forward.
As you can also see in Figure 2-5, storage growth exploded while the prices dropped for traditional HDD storage. We now store everything. Systems that underwent digital enablement using cloud computing (or not) have nearly eliminated the use of paper. Most enterprises also eliminated duplicate information. However, we may still store the same things several times for slightly different reasons—for example, inventory data that needs to be a part of a sales transaction database but also needs to be stored in another database for compliance audit purposes.
At the same time, cloud storage pricing initially fell but mostly flattened out and then began to rise in the last few years. Of course, cloud storage comes with added capabilities from the cloud providers that make using cloud storage more useful to many businesses. However, they pay less for their core storage systems, or the physical storage that makes up their on-demand storage systems that provide the public cloud services, this due to their ability to buy a great deal of storage hardware at a time. Thus, we can assume that the profit margins improved for public cloud providers.
So, what are the general cost differences between traditional on-premises storage and cloud storage? Table 2-1 depicts a cost comparison over 10 years between traditional on-premises storage and cloud-based storage. As you can see, the core differences are that the subscription cost for cloud-based storage is $2,000 per year, whereas HDD on-premises storage costs $4,500 per unit (or units). Additional maintenance, power, and people costs for on-premises storage are combined for a total of $820 a year. This cost is wrapped into the cloud computing storage costs.
TABLE 2-1 Sample yearly cost differences of cloud versus on-premises storage. Note that we include on-premises maintenance costs that we must pay for non-cloud storage that we own and maintain in our data centers.
| Cloud |
|
| On-Premises |
|
|---|---|---|---|---|---|
|
| Cumulative | Purchase | Maintenance | Cumulative |
Year |
|
| $4,500.00 |
| $4,500.00 |
1 | $2,000.00 | $2,000.00 |
| $820.00 | $5,320.00 |
2 | $2,000.00 | $4,000.00 |
| $820.00 | $6,140.00 |
3 | $2,000.00 | $6,000.00 |
| $820.00 | $6,960.00 |
4 | $2,000.00 | $8,000.00 |
| $820.00 | $7,780.00 |
5 | $2,000.00 | $10,000.00 |
| $820.00 | $8,600.00 |
6 | $2,000.00 | $12,000.00 |
| $820.00 | $9,420.00 |
7 | $2,000.00 | $14,000.00 |
| $820.00 | $10,240.00 |
8 | $2,000.00 | $16,000.00 |
| $820.00 | $11,060.00 |
9 | $2,000.00 | $18,000.00 |
| $820.00 | $11,880.00 |
10 | $2,000.00 | $20,000.00 |
| $820.00 | $12,700.00 |
Total | $20,000.00 |
| $4,500.00 | $8,200.00 |
|
Figure 2-6 is just a graph of Table 2-1, illustrated to show a few points of interest. First, in Year 4, the cumulative cost of cloud-based storage surpasses that of on-premises-based storage, all costs assumed to be fully loaded. Thus, if we assume the business advantages are the same for both types of storage, traditional on-premises HDD storage will be more cost effective in this case. However, we must also consider many of the soft values described in Chapter 1.
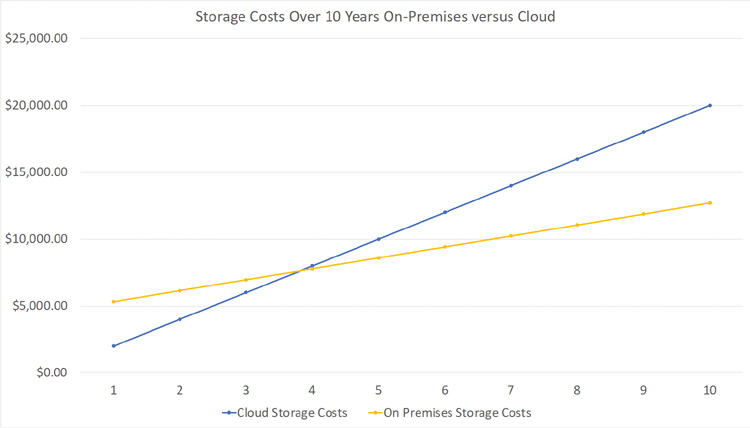
FIGURE 2-6 This graphic depicts the data in Table 2-1. At about Year 4, the on-premises storage solutions become more cost effective than the cloud. Remember to consider all costs, including operations and data center costs, when comparing the two storage solutions.
The kicker is that, for certain storage use cases, the advantages that cloud computing provides are not that helpful. “It depends” on the specific industry, business type, and/or applications to determine if a cloud computing storage solution or on-premises solution is best. And it’s another indication that one-size-fits-all is not the case when it comes to picking storage solutions or other technologies for that matter.
Some questions to ask when you evaluate storage options, cloud or not cloud, include
What is the value of agility and speed for my business and this use case?
What is the cost sensitivity within the organization? Is saving a buck more important than making a buck?
What is the long-term strategy for the enterprise, including the expanded or limited use of cloud computing?
What are the security issues to consider that may make on-premises storage or cloud-based storage more advantageous?
What is the growth of costs over time? Will it be consistent for both types of storage, as we saw in Table 2-1? Will it be highly volatile and difficult to predict?
What are the performance requirements and issues such as sensitivity to latency? Will leveraging on-premises storage provide a performance advantage versus cloud storage leveraged over the open Internet? Is performance a make-or-break factor for the business?
What sunk costs already exist in purchased storage equipment?
What about existing depreciation of existing storage equipment? Will the lack of depreciation cause a tax concern?
And so forth…
Table 2-2 is basically the same type of comparison model as Table 2-1 is to Figure 2-6, but this time the model for cloud storage costs is reduced by about $1,500 per month. In this case, perhaps the cloud storage provider (that is, an IaaS cloud provider) offered a substantial discount if the enterprise commits to a 10-year deal. Sometimes this could involve purchasing storage ahead of use, and thus the cost model for cloud will compare favorably to on-premises storage costs, because the enterprise guarantees payment up front to get the storage at a discount.
TABLE 2-2 Sample yearly cost difference of cloud versus on-premises storage, but this time modeling lower cloud costs. You can often find cloud storage bargains when you purchase capacity ahead of need or when leveraging a third-tier non-brand-name provider. Or this may become true of cloud storage as costs begin to drop again as they did when cloud computing first appeared on the market.
| Cloud |
|
| On-Premises |
|
|---|---|---|---|---|---|
|
| Cumulative | Purchase | Maintenance | Cumulative |
Year |
|
| $4,500.00 |
| $4,500.00 |
1 | $500.00 | $500.00 |
| $820.00 | $5,320.00 |
2 | $500.00 | $1,000.00 |
| $820.00 | $6,140.00 |
3 | $500.00 | $1,500.00 |
| $820.00 | $6,960.00 |
4 | $500.00 | $2,000.00 |
| $820.00 | $7,780.00 |
5 | $500.00 | $2,500.00 |
| $820.00 | $8,600.00 |
6 | $500.00 | $3,000.00 |
| $820.00 | $9,420.00 |
7 | $500.00 | $3,500.00 |
| $820.00 | $10,240.00 |
8 | $500.00 | $4,000.00 |
| $820.00 | $11,060.00 |
9 | $500.00 | $4,500.00 |
| $820.00 | $11,880.00 |
10 | $500.00 | $5,000.00 |
| $820.00 | $12,700.00 |
Total | $5,000.00 |
| $4,500.00 | $8,200.00 |
|
Figure 2-7 depicts the data from Table 2-2 as a graph. Note that the cloud costs are lower and about even in cumulative growth with the on-premises solution’s costs. The key here is that the business obtained a significant cloud discount, which made cloud-based storage the most cost-effective solution, combined with the other soft cloud benefits we previously mentioned.
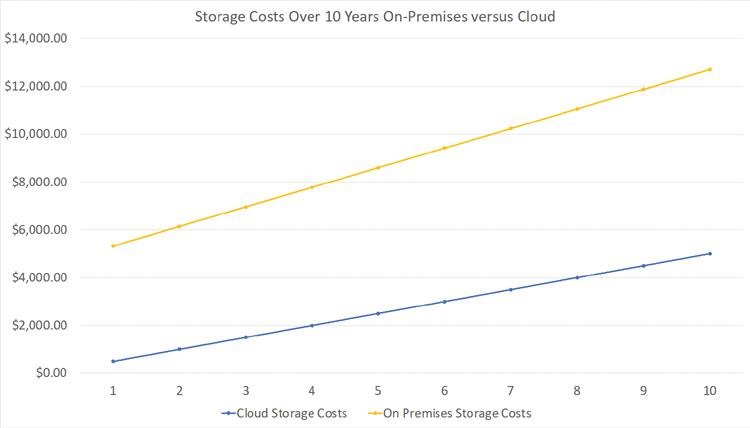
FIGURE 2-7 This graph depicts the data in Table 2-2. Note how the line items are relatively the same, in terms of cumulative growth, with the cloud storage solution providing lower overall costs for this scenario. Again, you’ll have to consider your own business needs, current pricing, and other costs that may be part of your unique “it depends” situation when calculating your own storage costs.
So, on-premises storage solutions are not always cheaper than public cloud storage solutions, and vice versa. These are complex calculations that need to be made with everything considered. Considerations include business requirements, the cloud services you currently leverage, the cloud services you want to leverage, and (of course) the value you may or not place on the soft cost benefits of agility, speed, and innovation.
Here’s where we frequently circle back to “it depends.” However, these examples are accurate representations of how we can figure this out for each problem we need to solve with storage.
Leveraging Storage Growth
The growth rate of your storage requirements is an asset that you can leverage in negotiations with a cloud storage provider. It may not work out as well as prices for traditional on-premises storage if you’re just talking yourself into purchasing too much storage ahead of need. However, cloud-based storage can grow as needed, and you’ll pay as you grow.
As you can see in Figure 2-8, a storage growth rate of, say, 1 petabyte to 10 petabytes over a five-year period should also see a reduction in pricing for that storage time. As storage growth rises, the prices of cloud-based storage should fall as a percentage of the amount of storage you leverage. The fact is that the provider will get a big chunk of cash from your business ongoing, and thus you deserve to have favorable pricing. You can promise (in writing) to grow storage at a specific rate and thus request a discount for promised future growth. Although most public cloud providers say they don’t discount, most will when dealing with large enterprises’ spending commitments, depending on the cloud provider. The more you use, and the higher rate of growth, the less you should pay per gigabyte and petabyte.
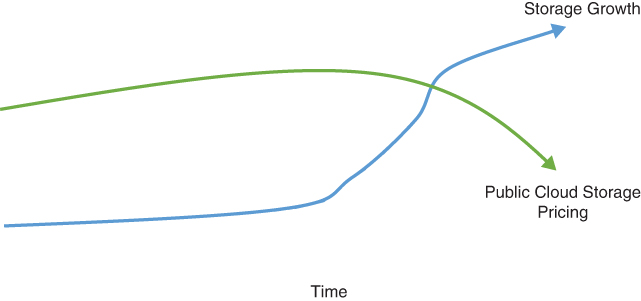
FIGURE 2-8 As storage growth rises, the prices of cloud-based storage should fall as a percentage of the amount of storage you leverage. You can promise (in writing) to grow storage at a specific rate and thus request a discount for promised future growth. Although most public cloud providers say they don’t discount, most will when dealing with large enterprises’ spending commitments.
It’s not uncommon when negotiating or renegotiating with a major public cloud provider to use the storage growth estimates as a bargaining chip to obtain more favorable pricing. Also keep this in mind: From a provider’s perspective, they won’t have much more overhead if you move from 1 petabyte to 5 petabytes. The same base costs exist for the provider to support you as a tenant, other than more physical storage space. As pointed out earlier in this chapter, the forecast is for storage space to get cheaper over time.
These discounts typically come with some strings attached. First, the provider may request that you sign a nondisclosure agreement (NDA), which means you can’t reveal the price you paid for storage. Their most likely concerns are that others will use your price as leverage within their own negotiations. Second, the provider may require that you commit to a specific amount of storage use or growth over time, say a half a petabyte per year, or something as significant. This requirement introduces the risk that you won’t be able to drive that promised growth (such as during a business downturn) and would still have to pay penalties when you do not meet your growth promises.
Finally, this agreement contractually locks you into a specific provider. If you find issues with that cloud provider down the road, it will be difficult to exit the contract. There is an advantage to leveraging a cloud provider as a noncontractual customer, where you can leave the cloud provider at any time, for any reason, which is why many enterprises leverage cloud computing in the first place.
Add-ons Needed
Storage does not work by itself, and many different systems need to work with storage to provide a complete solution. These systems include storage management, storage operations, storage security, storage governance, databases, database management, database security, and other cloud-based add-ons you’ll need to get the most value from storage.
Of course, the add-ons you need will depend entirely on what you plan to do with your cloud storage system. I brought up this point here because those who build their cloud architecture typically remember that they need storage, of course, but many overlook the other cloud services that will keep their storage systems healthy and secure. Don’t forget to factor in those necessary services and consider them in the negotiations of the storage costs with your cloud provider. Providers often toss them in for free on the front end, but they could cost thousands per month if you add them in at the last minute.
To define a solid storage solution, look holistically at the potential storage systems. Describe its current intended use, as well as its use into the future. Storage systems are often multiuse, meaning they will support thousands of applications and tools that directly access the storage system, or access the system through a database. Yes, define the use cases for the storage solution when it’s accessed by a specific application, but remember its other uses as well. This includes how the storage system will be used in 1 year, 5 years, 10 years, and so on. We get deeper into this discussion in the next section.
How Will the Business Leverage Cloud Storage?
How your business will leverage cloud storage is a question that most good cloud service salespeople will ask when you shop for cloud computing storage. In most cases, you’ll pick different storage systems and/or databases for specific use cases—for example, purpose-built for data analytics versus a storage system purpose-built to deal with highly transactional systems.
The three major types of storage are block, object, and file storage. Each serves different purposes. Many times, you’ll leverage a database that needs a specific type of storage, and then the number of use cases that call for a specific type of database become more numerous as well. In most cases, the recommendation is to leverage different types of storage that focus specifically on what you plan to leverage with the storage system.
Figure 2-9 represents how an enterprise typically leverages storage. At the top of the stack are applications that often use automation to leverage the data, and humans who leverage the data directly, typically through a tool of some sort. At the next layer are the types of databases we may leverage, either focused on analytical data uses or standard transactional systems.
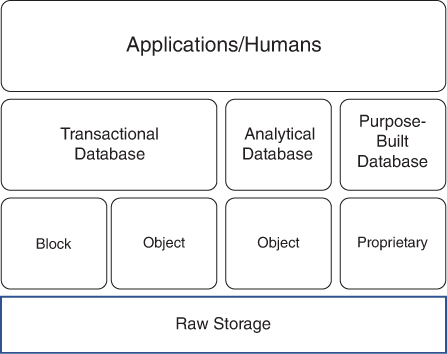
FIGURE 2-9 A storage system could have many applications and/or humans that access a specific database that is designed for a specific purpose, such as sales transactions, or for analytical purposes, such as looking at the history of sales over the last five years. In some cases, the system may leverage purpose-built databases that don’t have a specific or standard type of storage, or the purpose-built database could use its own proprietary approach.
Moreover, many purpose-built databases are beginning to emerge that solve a specific problem—for example, a database that is built to store data related to medical treatments or a database designed for edge computing. The idea is the same, that we have a use case so unique that we need a specialized database to solve the problem.
Note the third layer on Figure 2-9, where standard types of storage include object and block storage that the database above it might leverage. Again, it depends on the database you leverage. Some may leverage the native raw storage system of the cloud; some could have their own way of setting up their raw storage. All use raw physical storage systems that data is persisted on a public cloud provider.
Automation Is King
In terms of cloud storage, automation means that you want to automate most of the activities around maintaining a native cloud storage system and/or database that leverages a native cloud storage system. For example, data backup and recovery, deduplication, performance tuning, auto scaling, and other functions associated with storage and database management that need to be carried out by humans or, preferably, by automation.
The objective here is to automate as much as you can. By doing so, you remove many of the reasons storage systems fail—typically some routine activity that’s not carried out due to human error. This does not mean you can’t make mistakes when using automation; you can. However, you do create repeatable processes that happen no matter whether someone remembers them or not, and thus remove much of the risk from storage maintenance.
Examples of storage maintenance and operations automation include
Automated storage and/or database backup that includes migrating backups to other public cloud regions in case of localized failures. If data is lost in one region due to a hurricane, then the data that’s backed up to region two remains unaffected and available for use. This data gets automatically and periodically migrated to region two through geographic redundancy to lower the risk of data loss.
Automated security checks that include proactive scans of the storage system or database to find and fix issues with security—for example, unencrypted data that should be encrypted, and/or suspicious activity that could indicate an attempted breach.
Automated performance maintenance such as deduplication to eliminate redundant data and increase the value of the data that’s there. Also, automate the tweaking of data and/or storage tuning parameters to enhance storage and database performance. This includes items such as increasing the cache size as the database grows organically over time.
And so forth…
Weaponizing AI
Let’s not get into the functions of AI engines here; there are many other places you can go to find that information. However, it’s important to mention the use of AI when looking at how to leverage data to obtain the most business value.
AI is the single most valuable thing that you can do with your cloud data. Because AI systems now live on cloud providers, the cost and risk of leveraging AI continue to decline. Many of the startup businesses that appeared over the last five years or so are built around the use of data and AI. Those businesses are now household names because AI and data became the business.
AI is useless unless it has data that it can use to train the AI engine. AI and machine learning are good at spotting patterns in the data, and through understanding what those patterns mean, take on a learning role that can grow well beyond any human capabilities that could try to reproduce the same analytics.
Take fraud detection. AI can look for specific transactions, say, banking transactions that tend to show patterns of fraud. We can feed training data into AI that shows known patterns of fraud and nonfraud to teach our AI or knowledge engine what a fraudulent transaction looks like. In turn, AI can look at thousands of transactions in a single minute and flag the likelihood of fraud for specific transactions. Perhaps ranking them from 0, or no likely fraud, to 10, where fraud is very likely. As the humans review what the AI engine spots, we can train the knowledge base even more when we further tag and vet transactions, and the results of the vetting get fed back into the knowledge engine.
What’s important to remember is that AI only exists to provide value with a great deal of useful data, and that brings in the power of storage and databases. A common mistake is to believe that AI is like what we see in science fiction movies, where the AI engine has human characteristics. In the real world, we will leverage AI as a tool to target specific business problems that require a great deal of data and data storage to solve specific problems.
The Future of Cloud Storage
If I were to predict the future of cloud storage, the easiest thing to call out is the growth of storage. There is no end in sight, in terms of how much data we’re likely to store, and it will include data of all kinds and all functions. Enterprises no longer purge data after a certain amount of time since digitized data and AI make all data valuable or potentially valuable. In a sense, enterprises have become data hoarders.
At the same time, we can’t store all that data on traditional storage platforms, nor can everything be stored on the cloud. The growth of data will mean that some data storage will be on traditional on-premises systems for cost reasons in cases where the value of using public clouds is less compelling and the cost of on-premises storage is too competitive. This shift to thinking about on-premises storage will be geared toward specific types of data and specific types of companies. This does not mean that these companies are anti-cloud, only that they are pragmatic about which storage systems will provide the best value for a specific business use case.
The elephant in the room is cloud egress costs. It’s kind of a ransom that you must pay when you’re removing your own data from public cloud providers. I get why they charge that fee: You’re leveraging a huge number of resources, including network bandwidth, and intermediate storage. In the future, with the growth of multicloud, the hope is that these fees will be reduced, as we need to move data from cloud-to-cloud and cloud-to-data center more often, and the pushback on how these egress costs will drive cloud providers to be more reasonable with egress and ingress costs.
Of course, cloud storage will continue to explode as well, and for reasons that even the cloud providers don’t currently forecast. First, the instant expandability aspect of cloud storage will be too attractive for enterprises whose businesses need to quickly grow around new market opportunities. The near zero latency of cloud storage means that IT won’t have to constantly think and plan around what storage resources must be added to meet the changing needs of the business. However, a few years ago, who would have thought that cloud storage would often be the more expensive option? However, it also provides the most business value, considering the type and purpose of the business. Again, we’re back to “it depends.”
Call to Action
Most of us look at cloud storage as table stakes for moving to the cloud. It’s something that’s always there, and a known asset that’s easy to understand and use. As with other cloud assets, people who don’t focus on the true cost and true value of cloud storage are more likely to make key mistakes: They will overpay for cloud storage, and thus remove value and add risk to the business.
The clear message is that cloud computing architects need to understand that there are no “unimportant” layers of cloud computing technology. They are all interdependent upon each other, all incur ongoing costs, you must secure and govern everything, and no layer of technology is less or more important than the other.