
This introduction describes some of the basic concepts, notation, and terminology we use in this book. The vocabulary of software configuration management (SCM) is used in various ways in different contexts, and the definitions here are not a comprehensive survey of the ways these terms are used. Where possible, we use common terminology. We also provide a basic introduction to the practices of version control and some suggestions for further reading.
Software configuration management comprises factors such as configuration identification, configuration control, status accounting, review, build management, process management, and teamwork (Dart 1992). SCM practices taken as a whole define how an organization builds and releases products and identifies and tracks changes. This book concerns itself with the aspects of SCM that have a direct impact on the day-to-day work of the people writing code and implementing features and changes to that code.
Some of the concepts that developers deal with implicitly, if not by name, are workspaces, codelines, and integration.
A workspace is a place where a developer keeps all the artifacts he or she needs to accomplish a task. In concrete terms, a workspace can be a directory tree on disk in the developer's working area, or it can be a collection of files maintained in an abstract space by a tool. A workspace is normally associated with particular versions of these artifacts. A workspace also should have a mechanism for constructing executable artifacts from its contents. For example, if you were developing in Java, your workspace would include
Source code (.java files) arranged in the appropriate package structure
Source code for tests
Java library files (.jar files)
Library files for native interfaces that you do not build (for example, .dll files in windows)
Scripts that define how you build .java files into an executable
Sometimes a workspace is managed in the context of an integrated development environment (IDE). A workspace is also associated with one or more codelines.
A codeline is a progression of the set of source files and other artifacts that make up some software component as it changes over time. Every time you change a file or other artifact in the version control system, you create a revision of that artifact. A codeline contains every version of every artifact along one evolutionary path.
At any point in time, a snapshot of the codeline will contain various revisions of each component in the codeline. Figure I-1 illustrates this; at one point you have version 1 of both file1.java and file2.java. The next time there is a change to the codeline, the resulting state of the tip of the codeline comprises revision 1 of file1.java and revision 2 of file2.java. Any snapshot of the codeline that contains a collection of revisions of every component in the codeline is a configuration of the codeline.[1] Any configuration that is given a distinct name or number is a version of the codeline. If you choose to identify or mark a version as special, you define a label. You might label the set of revisions that went into a release, for example.

In the simplest case, you might have just one codeline that includes all your product code. Components of a codeline evolve at their own rate and have revisions that we can identify. You can identify a version of the codeline by a label. The version of the codeline is a snapshot that includes the revisions of the components up to the point of the label.
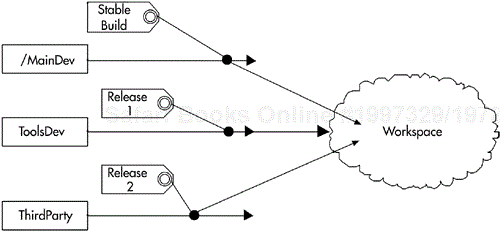
More than one codeline can contribute to a product if each codeline consists of a coherent set of work. Each codeline can have a different purpose, and you can populate your workspace from an identifiable configuration of snapshots from various codelines. For example, you can have third-party code in one codeline, active development in another, and internal tools that are treated as internal products in a third. Figure I-2 illustrates this. Each codeline also has a policy associated with it. These policies define the purpose of the codeline and rules for when and how you can make changes.
As codelines evolve, you may discover that some work is derivative from the intention of the codeline. In this case, you may want to branch the file so that it can evolve independently of the original development. A branch of a file is revision of the file that uses the trunk version as a starting point and evolves independently. Figure I-3 illustrates this. After the second revision, someone creates a branch and changes the file through revisions 2.1, 2.2, and so on. A common notation is to indicate a branch by adding a minor version number (after a “.”) to indicate that the branched revision is based on the major revision on the trunk. An example of a reason to create a branch would be that you want to start work on a new release of a product yet still be able to fix problems with the released version. In this case, you can create a branch to represent the released version and do your ongoing work on the trunk. Some of the changes you make on the branch also may need to make their way to the trunk, so you do a merge to integrate the changes from the branch to the trunk. Figure I-3 shows this with the dotted line from revision 2.2 to revision 3.

Merging can be automated to some degree by tools that identify contextual text differences, but you often need to understand the intention of the change to merge correctly.
Often you will want to branch not just a single file but an associated set of files in an entire codeline. In this case, the versions refer to versions of the entire codeline taken as a unit, where a version of the codeline includes all the revisions in the codeline at that point in time, as shown in Figure I-4.

Every time you change anything in the codeline, you create a new configuration of the tip of the codeline. This new snapshot of the codeline may conceptually imply a new version to identify. In reality, most users of the code base don't need to mark each such change by a unique version number (just the noteworthy ones). Certain versions are significant, including points at which there is a product release, a branch, or a validated build. These versions of the codeline can be identified by labels.
The discussion up to this point has illustrated the concepts of codelines, branches, and so on using the notation that this book uses for most of the examples. This section summarizes the notation and defines the symbols a bit more strictly. The codeline diagram notation is based on the notation for Unified Modeling Language (UML) sequence diagrams, with the addition of symbols to indicate versions and revisions and with the variation that the flow goes from left to right as time increases. The notation is based on the one used in the paper “Streamed Lines” (Appleton et al. 1998) and was further inspired by the diagrams in Michael Bays's book Software Release Methodology (Bays 1999). As with any notation, the purpose of this notation is to convey meaning clearly, so some of the diagrams in the book may use additional symbols or vary slightly from the description here where it helps to explain the subject matter.
Figure I-5 shows the notation that we use in the codeline diagrams in this book, and Table I-1 describes the symbols used.

Table I-1. Codeline Diagram Notation Symbols
Symbol | Description and Notes |
|---|---|
A rectangle with a bold border is the start of a codeline. It often has an indentifying name. | |

| A circle is a version of the codeline or a revision of a file. A branch or merge point is also considered a version. It sometimes has an identifier for the branch, such as a version number. This can be blank. |
A gray-bordered rectangle within a codeline indicates a change task, which can be identified by a description inside the box. | |
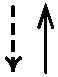
| An arrow with a dotted line indicates a merge from the codeline at the start of the line to the codeline with the arrowhead. A solid arrow indicates a branch. |
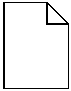
| A document symbol, when it is attached to a codeline start, indicates the policy. You may also see this symbol used informally to represent a document. |
This symbol indicates a label, or an identified revision. There will be a line going from the tag to the part of the codeline that is indicated. |
Tichy's paper on RCS, “A System for Version Control” (Tichy 1985), is a classic paper on an early popular version control system.
The paper, “High-Level Best Practices in Software Configuration Management” (Wingerd and Seiwald 1998), provides a good overview.
Michael Bays's book, Software Release Methodology (Bays 1999), has excellent descriptions of the concepts of codelines and version control.
Babich's book, Software Configuration Management: Coordination for Team Productivity, is a classic (Babich 1986).
Open Source Development with CVS (Fogel and Bar 2001) provides good advice on how to use a common open source version control tool, CVS, on open source projects, among other uses.
Antipatterns and Patterns in Software Configuration Management (Brown et al. 1999) has a good collection of advice on what to do and what not to do.
Configuration Management Principles and Practice (Hass 2003) explains the details of configuration management practices.
Appendixes A and B provide further sources on SCM and tools.
[1] In general, you can also “tag” different revisions of components to identify a version of the codeline—for example, version 1 of file2.java and version 3 of file1.java. But there are other, more intuitive ways of identifying a configuration like this.