

Photo by John Vachon. Library of Congress, Prints & Photographs Division, FSA-OWI Collection, Reproduction Number: LC-USF34-061836-D.
Man who operates a small grocery store and secondhand furniture store in his home. Chanute, Kansas, November 1940.
You want to focus on building the components for which you can add the most value, not on basic functionality that you can easily buy. Your codeline is associated with a set of external components that you will ship with your product. You may customize some of these to fit your needs. You need to associate versions of these components with your product. When you create your Private Workspace (6) or when you build a release for distribution, you need to associate these components with the version you are checking out. You also want your Repository (7) to contain the complete set of components that make up your system. This pattern shows how to track the third-party components in the same way you track your own code.
Note
What is the most effective strategy to coordinate versions of vendor code with versions of product code?
Using components developed by someone else means letting go of control of both the implementation and the release cycle for what could be a key building block of your system. The essence of source control and release management is the identification of what components go together to reconstruct a given version of a product. You still need to be able to reconstruct old builds for debugging and support, so you need a way to track which vendor release goes with which version of your code. If this were all your own code, you could simply label it in the version control system when you made a release. But vendor release cycles are different from your release cycles, as Figure 10-1 shows.
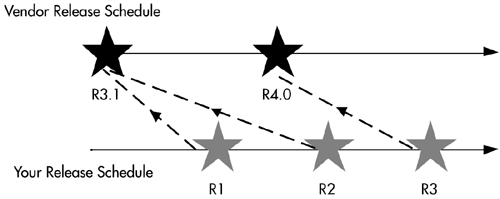
You need to identify easily which versions of third-party components go with which versions of your product. You could have a manifest or list to show this information.
Using a list to associate a vendor release with your product's version can be tricky during development. It is easy to use the third-party component's installation process if you are working with a static version, but in a dynamic environment, you should make installation with the correct version simple for developers. This can become complicated during development as well, because you need to coordinate third-party code versions with your code when you build a workspace, and you should be able to build and update a workspace automatically. Consulting a list and installing the right versions of components add an element of risk.
When you decided to use third-party code, it was because you wanted to save yourself work and because the third party added more value in a specific domain. Sometimes the outside code is not perfect and needs adaptations to work. You could be using publicly available code and need to customize it to fit your particular needs, or you might need to fix a bug in vendor code if you have access to the source. If you make custom changes to the vendor-provided code, you need to provide a way to integrate these changes into your subsequent releases until the vendor makes a release with the changes you need. In some cases, your changes may never be in the vendor release, and you need to reapply them to subsequent vendor releases.
Even with binary-only components that you do not change, you still need to associate releases of the outside code with releases of your product.
Using third-party code is, by its nature, risky, but treating third-party code as “outside” your system is risky if your system depends on it.
Note
Create a codeline for third-party code. Build workspaces and installation kits from this codeline.
Use your version control system to archive both the versions of the software you receive from the vendor and the versions you deliver to your customer. Use the branching facility of the version control system to track separate but parallel branches of development for the vendor's code and your customized versions of the vendor's code. When you get vendor code, make it the next version in the vendor branch and then merge the code from that branch into your customized branch. Your version control system should maintain enough information to build any version of your product using the correct versions of all components, internal and external.
What is “third-party code?” Third-party code is any code supplied by someone outside your organization or fixes and enhancements to that code. “Plug-ins” and extensions to a third-party framework are not third-party code and should be treated as product code. For example, if you have a library for parsing XML, that is third-party code. If you find that a version of the parser does not parse certain XML correctly, the fix for that should be made to the third-party codeline. Parsing event handlers that you write to use in your application are not part of the third-party codeline, though they certainly depend on the third-party code.
To accept vendor code, do the following.
Add the vendor code to the appropriate directory of a vendor codeline. Add it to this codeline in exactly the way it unpacks from the distribution medium. If the component is something you can build, you should be able to build it from the checkout area.
Label the check-in point with a label identifying the product and version.
Immediately branch this new codeline. All the projects that will use this version of the vendor code will use the code from of the branch, making it possible to customize the code when the source is available. If you need to build the components locally, build them on this branch and check in the derived objects.
Check in derived objects here to save time and effort; they should not change frequently.
When a new vendor release appears, add it to the mainline portion of the vendor codeline. Branch again, and merge any relevant changes from the prior branch into the new branch.
Figure 10-2 shows the resulting codeline.
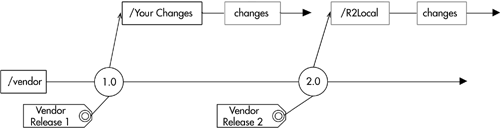
You can now easily reproduce prior versions of your own releases as well as those of the vendor. Customization differences can easily be isolated and reproduced so that you can see what you had to change for a given release. Differences between vendor releases can easily be isolated and reproduced to see what the vendor changed from release to release. By tracking customization changes on a separate branch from vendor changes, you are basically applying a divide-and-conquer approach of orthogonalization: Instead of one big change, you logically partition it into vendor changes and custom changes from a common base version. This reduces merge complexity. The resulting project version tree reflects the real-world development path relationships between the vendor and your group. This requires more storage space than simply keeping one source tree or one set (branch) of versions of the source tree. It also requires the oft-despised merging of parallel changes. Many feel that “merging is evil!” However, in this case, you are not the one who controls the development of the code. You are at the mercy of the third-party supplier for this. The best you can hope for is that they incorporate all your changes into their code base. Thus merging is unavoidable here.
When you release a version of your product, label the code that your product has been built and tested against on the third-party codeline with the same label as the product release.
Even if you make no changes to the vendor code, the release history is now traceable, and the vendor releases can be labeled with the appropriate product releases. Even if all you have access to are interface files (header files) and derived objects (libraries, jar files, and so on), track these using version control as well, even though the same amount of delta information is not available. If you do make changes, you should check in “compiled” versions of the product that include the changes. When you get a new vendor release, you can compare the source code in the various branches and consider doing a merge if your changes are not in the later release.
To create a developer workspace, make sure that you check out the third-party components that are part of the product check in. If your version control system supports the concept of sets of related parts of the source tree (that is, modules), when you check out a given point in time of your product, you get the appropriate version of the third-party component free. If your version control system allows you to rearrange the locations of objects during a check-in, check binary objects in to the appropriate common “bin” directory. Otherwise, be sure to alter PATHs and CLASSPATHs appropriately so that build and runtime environments point to the correct version.
Include the appropriate third-party product branches when labeling the release. For some components, you may have licensing constraints that say you must use the vendor installer. In this case, you still have traceability built into your version control system, and you know that what you are shipping matches what you are developing with. You may also be able simply to integrate the third-party code into your own installation process by placing binary objects in the same place as your product-specific code.
To reproduce a prior build, including the correct third-party code, check out the appropriate label into a new workspace, and have the correct versions of all components. For some software component systems, such as COM, you need to deal with systemwide registration of specific component versions.
If you have customized versions of build tools (for example, gcc) or if your product depends on a particular version of a particular tool, you can handle it by thinking about what you need to ship. If you need to ship all or part of the tool as a runtime component, use this approach. If the tool is used only at build time, you can still track it in your system using a third-party codeline, but dependencies between the tool version and the product version can be handled by flags and identifiers in makefiles, for example.
The procedures here apply to any runtime component—for example, language extensions to languages such as Perl, Python, or Tcl. The specific version of the interpreter environment is another story.
When you are using a dynamically loaded third-party component that is a shared resource that other products may use, you have to decide how to install it if it already exists on the target system. The options are to upgrade existing installations, require that your version be the correct one, or, if the component technology supports this, install the version you expect on the target system in addition to any existing versions. This may be tricky, for example, in the case of a COM component, where the vendor has not followed the appropriate version conventions. Because only one version of a COM component can be the latest, it may be impossible to have more than one installed. In other cases, you can install multiple versions by altering the PATH or CLASSPATH environment when you load your system. This is not so much a technical issue as a support and positioning issue. Having multiple copies means using more space, but running with a known version of a third-party component makes verification and testing easier.
Interpreted languages present a special case of this problem. If your system depends on a specific version of Python or Perl, you can install the additional version of the interpreter in a “special” path, or you can overwrite an existing installation, affecting all users of the product. Some of these tools allow you to build an executable that has an embedded interpreter, increasing isolation at the cost of a larger executable and less access to the source code, which eliminates a benefit of using a scripting language.
If you are using a third-party product that is very stable or that you will never customize, you may not need to create a branch. The cost of the branch in this case is small, and it gives you the flexibility to make changes later, if you need to.
Brian Berliner's 1990 paper, "CVS II: Parallelizing Software Development" (Berliner 1990), popularized the term “vendor branch” for this specific purpose.