
3 Missing Values
Of the thirty-six alternatives, running away is best.—Chinese Proverb
Missing values and the proper handling of them is a very delicate subject within the database community. The debate centers on how (or whether) missing values should be stored in relational databases and how many and what types of tokens should be used to represent them in SQL.
There are at least three different schools of thought regarding how to handle missing values. The inventor of the relational database, Dr. E. F. Codd, advocates two separate missing value tokens: one for values that should be there but aren’t (e.g., the gender of a person) and one for values that shouldn’t be there at all because they are inapplicable (e.g., the gender of a corporation). Chris Date, noted database author and lecturer, takes the minimalist position. He believes that SQL is better off without a missing value token of any kind. ANSI/ISO SQL-92 splits the difference and provides one general-purpose missing value token: NULL.
At the risk of stating the obvious, missing values and empty values are two different things. An integer whose value is missing is not the same as an integer whose value is zero. A null string is not the same as a zero-length string or one containing only blanks. This distinction is important because comparisons between empty values and missing values always fail. In fact, NULL values aren’t even equal to one another in such comparisons.
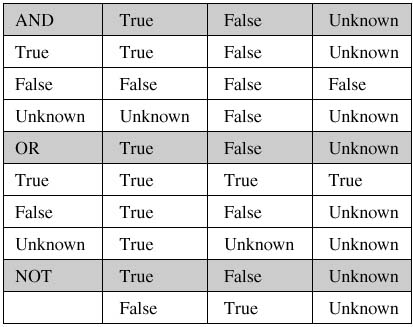
The possibility of missing values in relational data indicates that there are three possible outcomes for any comparison: True, False, and Unknown. Of course, this necessitates the use of three-valued logic. The truth tables in Figure 3.1 illustrate.
Note that I use NULL and Unknown interchangeably, even though, technically speaking, they aren’t. NULL is a data value, while Unknown represents a logical value. The distinction is a bit abstruse—especially for veteran software developers—and is the reason you must use ...WHERE column IS NULL rather than ...WHERE column = NULL if you want your SQL to behave sensibly. (Transact-SQL doesn’t forbid the latter syntax, but since one NULL never equals another—or even itself—it never returns True. See the section below on Transact-SQL’s ANSI NULL compliance.) As much fun as it would be, I have no desire to enter the philosophical debate over NULLs and their proper use. So, for simplicity’s sake, since our purpose is to view the world of data and databases through the eyes of Transact-SQL, I’ll stick with treating NULL and Unknown identically throughout the book.
Typically, involving a NULL value in an expression yields a NULL result. For example, SELECT5+NULLreturns NULL, not 5, as does SELECT SUBSTRING(’Groucho’,3,2+NULL). The notable exceptions to this rule are aggregate functions.
Similarly, NULL values are never equal to one another; in fact, a NULL value is not even equal to itself, as illustrated by the following query:
CREATE TABLE #nulltest
(c1 int NULL)
GO
INSERT #nulltest VALUES (1)
INSERT #nulltest VALUES (NULL)
INSERT #nulltest VALUES (3)
GO
DECLARE @nv int
SELECT @nv=c1 FROM #nulltest WHERE c1 IS NULL -- Gets the NULL from row 2
SELECT MyNV=c1 FROM #nulltest WHERE c1=@nv -- Returns no rows
As with simple expressions, most functions involving NULL values return NULL, so SELECT SIGN(NULL) returns NULL, as do SELECT ABS(NULL) and SELECT LTRIM(NULL). The exceptions to this are functions designed to work with NULL in the first place. In addition to aggregates, functions intended to be used with NULLs include ISNULL() and COALESCE().
ISNULL() translates a NULL value into a non-NULL value. For example,
SELECT ISNULL(c1,0) FROM #nulltest
translates all NULL values found in c1 to 0. Caution should be exercised when doing this, though, since translating NULLs to other values can have unexpected side effects. For example, the AVG query from the example above can’t ignore translated NULLs:
SELECT AVG(ISNULL(c1,0)) FROM #nulltest
The value zero is figured into the average, significantly lowering it.
Note that ISNULL()’s parameters aren’t limited to constants. Consider this example:
DECLARE @x int,@y int
SET @x=5
SET @y=2
SELECT ISNULL(CASE WHEN @x>=1 THEN NULL ELSE @x END,
CASE WHEN @y<5 THEN @x*@y ELSE 10 END)
Here, both arguments consist of expressions, including the one returned by the function. ISNULL() can even handle SELECT statements as parameters, as in this example:
DECLARE @x int,@y int
SET @x=5
SET @y=2
SELECT ISNULL(CASE WHEN @x>=1 THEN NULL ELSE @x END,
(SELECT COUNT(*) FROM authors))
The NULLIF() function is a rough inverse of ISNULL(). Though it doesn’t handle NULL values being passed into it any better than any other function, it was designed to return a NULL value in the right circumstances. It takes two parameters and returns NULL if they’re equal; otherwise it returns the first parameter. For example,
DECLARE @x int,@y int
SET @x=5
SET @y=2
SELECT NULLIF(@x,@y+3)
returns NULL, while
SELECT NULLIF(@x, @y)
returns 5.
COALESCE() returns the first non-NULL value from a horizontal list. For example,
SELECT COALESCE(@x / NULL, @x * NULL, @x+NULL, NULL, @y*2, @x,
(SELECT COUNT(*) FROM authors))
returns @y*2, or 4. As with ISNULL(), parameters passed to COALESCE() can be expressions and subqueries as well as constants, as the code sample illustrates.
With each successive version, SQL Server’s ANSI/ISO compliance has steadily improved. Using a variety of configuration switches and modern command syntax, you can write Transact-SQL code that’s portable to other ANSI-compliant DBMSs.
NULLs represent one area in which ANSI compliance improved substantially in version 7.0. A number of new configuration settings and syntax options were added to enhance SQL Server’s ANSI compliance in terms of NULL values. Many of these are discussed below.
Regarding the handling of NULL values in expressions, the ANSI/ISO SQL specification correctly separates aggregation from basic expression evaluation (this is contrary to what a couple of otherwise fine SQL books have said). This means, as far as the standard is concerned, that adding a NULL value to a number is not the same as aggregating a column that contains both NULL and non-NULL values. In the former case, the end result is always a NULL value. In the latter, the NULL values are ignored and the aggregation is performed. Per the ANSI spec, the only way to return a NULL result from an aggregate function is to start with an empty table or have nothing but NULL values in the aggregated column (COUNT() is an exception—see below). Since Transact-SQL follows the standard in this regard, these statements apply to it as well. For example, consider the following table from earlier:
CREATE TABLE #nulltest
(c1 int NULL)
and the following data:

The query:
SELECT AVG(c1) FROM #nulltest
doesn’t return NULL, even though one of the values it considers is indeed NULL. Instead, it ignores NULL when it computes the average, which is exactly what you’d want. This is also true for the SUM(), MIN(), and MAX() functions but not for COUNT(*). For example,
SELECT COUNT(*) FROM #nulltest
returns “3,” so SELECT SUM(c1)/COUNT(*) is not the same as SELECT AVG(c1). COUNT(*) counts rows, regardless of missing values. It includes the table’s second row, even though the table has just one column and the value of that one column in row 2 is NULL. If you want COUNT() behavior that’s consistent with SQL Server’s other aggregate functions, specify a column in the underlying table rather than using “*” (e.g., COUNT(c1)). This syntax properly ignores NULL values, so that SELECT SUM(c1)/COUNT(c1) returns the same value as SELECT AVG(c1).
This subtle distinction between COUNT(*) and COUNT(c1) is an important one since they return different results when NULLs enter the picture. Generally, it’s preferable to use COUNT(*) and let the optimizer choose the best method of returning a row count rather than forcing it to count a specific column. If you need the “special” behavior of COUNT(c1), it’s probably wise to note what you’re doing via comments in your code.
By default, SQL Server’s ANSI_WARNINGS switch is set if you connect to the server via ODBC or OLEDB. This means that the server generates a warning message for any query where a missing value is ignored by an aggregate. This is nothing to worry about if you know about your missing values and intend them to be ignored but could possibly alert you to data problems otherwise.
ANSI_WARNINGS can be set globally for a given database via sp_dboption or per session using the SET ANSI_WARNINGS command. As with all database options, session-level settings override database option settings.
Other important ANSI NULL-related settings include SET ANSI_NULL_DFLT_ON/ _OFF, SET ANSI_NULLS, and SET CONCAT_NULL_YIELDS_NULL.
SET ANSI_NULL_DFLT_ON/_OFF determines whether columns in newly created tables can contain NULL values by default. You can query this setting via the GETANSINULL() system function.
SET ANSI_NULLS controls how equality comparisons with NULL work. The ANSI SQL standard stipulates that any expression involving comparison operators (“=,” “<>,” “>=,” and so forth—“theta” operators in Codd parlance) and NULL returns NULL. Turning this setting off (it’s on by default when you connect via ODBC or OLEDB) enables equality comparisons with NULL to succeed if the column or variable in question contains a NULL value.
SET CONCAT_NULL_YIELDS_NULL determines whether string concatenation involving NULL values returns a NULL value. Normally, SELECT “Rush Limbaugh’s IQ=”+NULL yields NULL, but you can disable this by way of Transact-SQL’s SET CONCAT_ NULL_YIELDS_NULL command. Note that this setting has no effect on other types of values. Adding a NULL to a numeric value always returns NULL, regardless of CONCAT_NULL_ YIELDS_NULL.
I should pause for a moment and mention a peculiarity in the SQL standard that has always seemed contradictory to me. I find the fact that the standard allows you to assign column values using “= NULL” but does not allow you to search for them using the same syntax a bit incongruous. For example,
UPDATE authors SET state=NULL WHERE state=’CA’
followed by:
SELECT * FROM authors WHERE state=NULL
doesn’t work as you might expect. The SELECT statement returns no rows, even when a number of them were just set to NULL. Having NULLs not equal one another is not as difficult to swallow as the obvious syntactical inconsistency. In my opinion, the standard would be more symmetrical if it required something like this instead:
UPDATE authors SET state TO NULL WHERE state=’CA’
If this were allowed, the prohibition against “=NULL” would make more sense, but, alas, that’s not the case.
Stored procedures are one area where it’s particularly handy to be able to control Transact-SQL’s ANSI-compliant behavior. Consider the following stored procedure:

Despite the fact that the temporary table includes a row whose c1 column is set to NULL, passing NULL as the procedure’s lone parameter will not return any rows since one NULL never equals another. Of course, the stored procedure could provide special handling for NULL values, but this approach becomes untenable very quickly as procedures with large numbers of parameters are considered. For example, a procedure with just two nullable parameters would require a nested IF that’s four levels deep and would multiply the amount of code necessary to perform the query. However, thanks to SET ANSI_NULLS, this behavior can be overridden like so:

This changes the viability of Transact-SQL’s “5NULL” extension for the duration of the procedure. By “viability” I mean that, beyond not generating an error, the syntax actually works as you expect. Though the syntax is technically valid regardless of SET ANSI_NULLS, it never returns True when ANSI compatibility is enabled. As you might guess from the example code, this extension greatly simplifies the handling of nullable stored procedure parameters, which is the main reason it was added to the language.
This technique works because the status of ANSI_NULLS is recorded at the time each stored procedure is compiled. This provides a virtual snapshot of the environment in which the procedure was built, allowing you to manage the setting so that it doesn’t affect anything else. The corollary to this is that regardless of the current state of ANSI_NULLS when a procedure is executed, it will behave as though ANSI_NULLS matched its setting at the time the procedure was compiled, so be careful. For example:
SET ANSI_NULLS OFF
GO
EXEC ListIdsByValue @val=NULL
GO
SET ANSI_NULLS ON
GO
won’t produce any rows if ANSI_NULLS wasn’t set OFF when the procedure was compiled.
Note that SET ANSI_NULLS also affects the viability of the IN (value, value, NULL) syntax. This means that a query like:
SELECT * from #values where (c1 in (1, NULL))
won’t return rows with NULL values unless ANSI_NULLS is disabled. If you think of the IN predicate as shorthand for a series of equality comparisons joined by ORs, this makes perfect sense.

Note
I should point out here that I don’t encourage needless departure from the ANSI/ISO SQL specification. It’s always better to write code that complies with the standard, regardless of the syntactical offerings of your particular SQL dialect. ANSI/ISO-compliant code is more portable and, generally speaking, more readable by more people. As with using NULL values themselves, you should carefully consider the wisdom of writing deviant code in the first place, especially when working in multi-DBMS environments.
As I mentioned earlier, I don’t intend to get drawn into the debate on the proper use of NULLs. However, it’s worth mentioning that, as a practical matter, NULL values in relational databases can be a royal pain. This is best illustrated by a couple of examples. Assuming we start with the following table and data:

one might think that this query:
SELECT * FROM #values WHERE c1=1
followed by this one:
SELECT * FROM #values WHERE c1<>1
would return all the rows in the #values table, but that’s not the case. Remember that SQL is based on three-value logic. To return all rows, we have to allow for NULL values, so something like this is necessary:
SELECT * FROM #values WHERE c1=1 OR c1 IS NULL
This makes perfect sense if you consider that the NULL in row 2 is really just a placeholder. Actually, the value of the c1 column in row 2 is not known, so we can’t positively say whether it does or does not equal 1, hence the exclusion from both queries. Unfortunately, this sort of reasoning is very foreign to many developers. To most coders, either something is or it isn’t—there is no middle ground. For this reason alone, NULLs are the bane of many a new SQL developer. They continually perplex and frustrate the unwary.
Another problem with NULLs is the inability of most host languages to represent them properly. The increasing use of OLE data types is changing this, but it’s not unusual for host languages to use some predefined constant to simulate NULL values if they support them at all. An unassigned variable is not the same thing as one containing NULL, and assuming it is will lead to spurious results. Also, few database servers, let alone traditional programming languages, implement ANSI SQL NULL behavior completely or uniformly, and differences in the way that NULLs are handled between an application’s various components can introduce layered obfuscation.
Behind the scenes, SQL Server tracks which columns in a table are NULLable via a bitmap column in the sysobjects system table. Obviously, this carries with it a certain amount of overhead. Every aggregate function must take into account the fact that a column allows NULLs and take special precautions so that NULL values in the column don’t skew results. Basically, NULLs are nasty little beasties that require special handling by anything that works with them.
To be fair, NULLs are a necessary evil in many cases. Accurate calculations involving quantities quickly become overly complex when there is no direct support for missing values. The difference between zero and an unknown value is the same as that between any other known value and an unknown one—it’s a conceptual chasm. It’s the difference between a zero checking account balance and not having a checking account at all. Datetime columns often require NULL values as well because dates are frequently expressed in relative rather than absolute terms.
One accepted method for avoiding the use of NULL is to use dummy values to signify missing data. For example, the string ‘N/A’ or ‘NV’ can be used to supplant NULLs in character string columns. –1 can be used to indicate a missing value in many integer columns, ‘1900-01-01’ can be used for dates, and so forth. In these instances, the NULLIF() function comes in handy, especially when working with aggregate functions. For example, to get SUM() to ignore numeric columns containing –1, you could use something like SELECT SUM(NULLIF(c1, -1)) because SUM() ignores NULLs. You could code similar expressions to handle other types of dummy NULL values.
The moral of the story is this: NULL is the kryptonite of the database world—it sucks the life out of anything that gets near it. Use it if you must, but avoid it when you can.