
Ongoing research efforts regarding service differentiation can be classified into two approaches: absolute differentiated service and relative differentiated service, as mentioned in Section 2.5.
Absolute differentiated service assures an admitted user of the promised performance level of the DiffServ classes, independent of the traffic status of the network. Therefore, such an approach is useful for applications that require strict QoS guarantees. On the other hand, realization of absolute differentiated service requires stringent admission control.
On the application side, much intelligence can be added to application-layer protocols nowadays. In the case of a multimedia application, the transmission rate can adapt to network congestion through, for example, a choice of different compression rates. Regardless of absolute or relative differentiation, the DiffServ framework can best be utilized by implementing some intelligence at the boundary nodes of the DiffServ domain. As CM applications become more network-adaptive, it appears that many will perform well with relative differentiated service, even though the network performance guaranteed by relative DiffServ is not as solid as that guaranteed by absolute DiffServ. Except for several conversational CM applications (e.g., Internet telephony, including video conferencing), the majority of networked CM applications are tolerant of occasional delay/loss violations. Thus, they do not require tight delay/loss bounds, which can be better provided by DiffServ premium service (PS).[1] For streaming video applications, encoding/decoding is more resilient to the loss rate and delay fluctuations, and thus the capability of relative service differentiation seems adequate for the streaming video applications on which we will focus.
With an appropriate pricing rule, the method of exploiting relative differentiation for CM applications seems to be an important issue for successful cooperation between the differentiated service and the CM applications. Thus, in this chapter, we propose a subscription-based pricing model for differentiated service quality among DS levels[2] specified in the SLA, under which there is a futuristic framework for QoS mapping between practically categorized packet video and a relative DiffServ network employing a unified priority index and an adaptive packet-forwarding mechanism. In this framework, the video application at the source grades the chunks of its content by certain indices (i.e., categories for packets) according to their importance in end-to-end QoS (e.g., in terms of loss probability and delay). Since these indices reflect the desired service preference of a packet compared with others in fine granularity, we denote them with an RPI, which is further divided into a relative loss priority index (RLI) and a relative delay priority index (RDI).
Next, QoS control takes place through the assigning of an appropriate DS level to each packet, a process that we call QoS mapping. Using the RPI association for each packet, an efficient (i.e., content-aware) mapping can be coordinated either at the end-application or at the boundary node. Note that the efficiency of QoS mapping for relative differentiation is dependent on the persistence of the contracted (advertised) quality differentiation over different time scales in the presence of traffic fluctuation. That is, the packet-forwarding mechanisms (e.g., queue management and packet scheduling) of DiffServ needs to provide the target performance differentiation persistently over time. (In Chapters 5 and 6, we will discuss how to seek persistent service differentiation and how such persistence improves end-to-end quality through QoS mapping.) With a relative DiffServ network providing consistent service differentiation persistently over time, CM applications, including streaming video, can be built more reliably and for less cost.
This chapter presents a relative service differentiation framework connecting CM applications, especially streaming video applications, through the proposed RPI. The chapter addresses the following issues: (1) a relative priority-based, per-packet video categorization in terms of delay and loss; and (2) an optimal (or effective) QoS mapping between application categories and DS levels under the pricing cost constraint of the relative service differentiation network. Actually, this framework belongs to joint source/channel coding, and more specifically to the UEP technique. Commonly, UEP enables prioritized protection for source layers (e.g., layered streams of video). It can be realized at the transport end with different levels of FEC and/or ARQ for each layer [91], [92], [93], [94]. However, to the best of our knowledge, no UEP approach has addressed the issue of using packet-level, fine-grained prioritization of the proposed RPI instead of layered protection. For a DiffServ network especially, only layered prioritization in an absolute differentiation sense has recently been proposed in [95], utilizing the video object layer of MPEG-4 and a different packet-discarding mechanism.
The rest of this chapter is organized as follows. The proposed QoS mapping framework is described in Section 3.2. Video categorization with RPI according to several criteria is examined in Section 3.3 for the case of ITU-T H.263+ video [96]. By investigating the error-resilient version of the H.263+ stream, the RPI is assigned so that different video packets can be tied to the relative loss rate/delay differentiation of DiffServ networks. Then, optimal QoS mapping guidance is presented for a certain packet loss rate and given cost curve according to the DS level. Performance assessments using the random loss pattern from a two-state Markov model for each DS level and H.263+ video are given in Section 3.5, where the implications of experimental results are also discussed. Finally, concluding remarks and anticipated future research efforts are given in Section 3.6.
A diagram of the proposed QoS mapping framework is presented in Figure 3.1. In our framework, service differentiation is done in terms of the loss rate and delay performance of network service. (We are assuming that the traffic-conditioning entities of the DiffServ network are taking care of the throughput negotiation.)

Each video flow of a user application must be classified according to its importance to receive low-delay or low-loss packet delivery service from the network. For example, low delay is more important to a video conference application than to a streaming video application. Moreover, each packet is associated with the RPI, which is composed of two normalized indices, the RLI and the RDI. These indices are described in detail in Section 3.3. RLI and RDI are basically indices that indicate the impact of a data segment’s loss and delay, respectively, on the quality of the application. Therefore, these indices specify the data segment’s importance in terms of receiving good service quality from the network layer.
The packets associated with the RPI are categorized into intermediate DS traffic categories (i.e., traffic aggregates with different source traffic priorities) in a fine-grained manner by the application. We use the term “intermediate DS traffic categories” because these categories may change as the packet enters the DS domain. The marking of codepoints in the packets in accordance with these intermediate DS traffic categories is a “pre-marking” [17] from the viewpoint of the DS domain. We allow the application to do such a pre-marking on the basis of the application’s knowledge of the packet’s content without it knowing the status of the network or SLA between the application’s domain and the DS domain. Then, pre-marked (i.e., RPI-categorized) packets are conveyed into the DiffServ-aware node for QoS mapping, which takes into account the SLA with the DS domain, and in the case of dynamic QoS mapping, also the network status. Such QoS mapping can be implemented at the end-system itself, at a DiffServ boundary node, or at both. Thus, given a video application and the responding DiffServ network, the QoS mapping is accomplished by mapping (i.e., marking) the relative prioritized packets to maximize end-to-end video quality under a given cost constraint. Then, at the DiffServ junction (i.e., a DiffServ boundary node), the packets are classified, conditioned, and re-marked to certain network DS levels by considering the traffic profile based on the SLA and current network status. (The QoS mapping implemented at the DiffServ boundary node can be designed to consider the SLA and global view of all the aggregate traffic coming from multiple applications.) Finally, the packets with DS-level mapping are forwarded toward the destination through a packet-forwarding mechanism, which mainly comprises queue management and a scheduling scheme.
In this chapter, we consider the case in which the DS domain provides proportional DiffServ through its packet-forwarding mechanisms. The desired differentiation in queuing may be realized by adopting multiple queues with several drop curves such as multiple RED and RIO [42], [97]. Furthermore, if different weighting factors are adopted, a modified version of WFQ scheduling can be used to complement queue management to provide the desired loss-rate/delay differentiation.
The above QoS mapping framework can be applied to multimedia rate-adaptive transport mechanisms. The framework can be used with a futuristic differentiated service with a pricing mechanism that charges different prices for different classes. Since a video codec has several options for trading compression efficiency for flexible delay manipulation, error resilience, and network friendliness, the QoS coordination has to provide a simplified QoS mapping process between the video encoder and target network. The purpose of introducing RPI is to abstract and isolate coding details from the network adaptation. By assigning RPI to each packet in an appropriate manner (i.e., keeping the fine granularity as much as possible), the proposed delivery system can accommodate the demand of each packet to achieve the best end-to-end performance in adapting to network fluctuations.
A typical DiffServ architecture defines a simple forwarding mechanism at interior network nodes while pushing most of the complexity to network boundaries [17], [98]. The traffic conditioner (composed of the meter, marker, shaper, and dropper) is placed at the boundary of the network. Given this functionality at the boundary, interior nodes use a packet-forwarding mechanism with queue management and scheduling for incoming packets to deliver differentiated services to various packets. This DiffServ architecture can bring benefits to both the end-user and ISP by providing better service quality for CM applications if they are willing to pay more for higher quality. Thus, the design principles for QoS mapping should consider the interests of both the end users and the ISPs. That is, an end-user should benefit from a DiffServ-aware application through having the option of obtaining higher service quality, while an ISP should enjoy the benefit of flexible charging based on the end-user’s preferences. To handle this negotiation, we need to measure the QoS demand of CM applications and the QoS supply of DiffServ networks in terms of pre-defined granularity. With pre-defined granularity, service differentiation can be demanded by marking differently at the end-system to request targeted DS levels. The service level may then be adjusted (i.e., through re-marking) in the DiffServ network and handled (i.e., forwarded) accordingly.
Each DS level is identified by the ToS or DS byte (i.e., the DSCP) defined in the IP header. The DiffServ working group also defines PHBs using the DS byte to specify the required forwarding behavior for packets in accordance with DS levels. Among initial PHBs being standardized are the EF PHB for DiffServ PS [24] and the AF PHB for DiffServ AS [23]. The EF PHB group specifies a forwarding behavior in which packets experience very small losses and queuing delays. EF PHB, based on priority queueing, better suits latency-stringent applications at the cost of a higher price. The AF PHB group specifies a forwarding behavior to preferentially drop best-effort (BE) and/or out-of-profile packets when congestion occurs. By limiting the volume of AF flows and managing the BE traffic appropriately, network nodes can ensure better loss behavior for AF-marked packets. As a result, the DiffServ framework provides DS levels with different losses and delays. For example, one EF queue, four AF queues with three drop preferences, and one BE queue may be defined as depicted on the network side in Figure 3.2. We can draw three equivalent cost lines in Figure 3.2, imagining several pricing model possibilities for the ISP. Line (a) considers only loss rate, while Line (c) depends only on delay. Line (b) relies on both loss rate and delay, and it is flexible. That is, at the same cost, it provides various service combinations such as higher delay with a lower loss rate, and vice versa.

Different DS levels are to be provided based on the marking (on the DS byte) of an application packet, and different amounts of loss and delay are expected based on the requested DS level. Thus, it is natural to think of associating a packet with both loss and delay priorities (i.e., RLI/RDI) rather than with loss alone, albeit in a fine-grained manner. For streaming video applications, the RLI association of each packet should reflect the loss impact of each packet on the video quality. For RDI, classification of video streams depends more on application context (e.g., video conferencing or video-on-demand) than on video content within a stream. For example, as shown on the source side of Figure 3.2, the quality request of two video applications, (A) and (B), are clearly distinguishable in terms of RDI depending on application usage, with added variability expressed by RLI.
For delay differentiation within a stream, Tan and Zakhor [99] considered frame-encoding modes. In this case, the highest delay sensitivity is given to the intra-coded frames (I frames), the next priority is assigned to the predicted frames (P frames), and the bi-directional, interpolated frames (B frames) have the lowest priority based on the encoding and decoding order of each frame type. This implies, however, that within a stream, the RLI and RDI attributes of packets are not completely orthogonal, which makes a reasonable classification somewhat difficult (this is discussed further in Section 3.3). Considering the complexity involved in varying RDI for each packet, we believe an appropriately fixed RDI with varying RLI is more than sufficient. Thus, in this work, we assign a fixed RDI for all packets of an application, as shown in Figure 3.2, and try to establish a satisfactory range of DS levels for the given RDI.
Given the RPI of each packet, our goal is to identify the best QoS mapping for video packets with content-aware forwarding under a cost constraint. At the end-system, an RPI is assigned to each packet, and it is then categorized into the kth category among K DS traffic categories. However, it is still up to a specific deploying environment to determine where the QoS mapping will be conducted. If the QoS mapping is conducted at the network adaptation unit of the end-system, an application can take advantage of its content-awareness (i.e., original RPI) to the extreme. Also, it can cover the early stage of DiffServ deployment, since it does not require any additional supporting network node except for prioritized DS levels. However, it lacks knowledge of the dynamics of the network and of the aggregation effect of competing flows, which can impede the efficiency of mapping because of the lack of a proper feedback mechanism. To provide a better fit into the access network scenario shared by multiple DiffServ-aware applications, it might be worthwhile to introduce a special version of a DiffServ boundary node to handle the proposed QoS mapping. With this, we could treat effective QoS mapping between aggregated CM packets and network DS levels (with fluctuating, but bounded service levels) under the TCA in the SLA. By adjusting the QoS mapping dynamically through coordinated interaction with end-systems, we could expect to achieve sophisticated exploitation of the DiffServ advantage.
However, note that in this chapter, we promote the futuristic concept of a proposed QoS mapping framework while deferring the discussion of practical issues such as dynamic QoS mapping and its aggregation effect.[3] By focusing on the QoS mapping problem of each single flow, we have intensively investigated the potential of the proposed framework. In particular, we will discuss how to create the required building components, such as the RPI association/categorization, the persistent packet-forwarding mechanism desired, and the practical formulation of QoS mapping. Thus, with several DiffServ network deployment scenarios and corresponding QoS mappings to consider, both network and end-to-end video performances of the proposed mapping framework are evaluated for end-to-end streaming video over simulated DiffServ networks.
In our approach, the importance to an end-user of obtaining a low packet loss rate or reduced delay is determined based on the following criteria. First, the decision focuses on relative and fine-grained priorities inside an application, which rely on a linkage to an absolute metric related to the application’s contents. When initially marked in the DS field with RLI/RDI, video application packets at the user end have limited knowledge of the dynamic status of the network and of competing applications within the same boundary. The assigned relative priority for each packet is supposed to be interpreted at the DiffServ-aware node. Next, because more assured (but not guaranteed) service is to be provided, the video application needs to be able to cope with possible packet losses and delays. The assigned RLI/RDI parameters basically assume that the video stream has already been generated with error-resilience features so that the loss or delay of each packet can be tolerated to a certain degree. Finally, the resulting prioritization should exhibit some kind of clustering behavior in the RLI/RDI space so that it can keep its distinction when mapped to the limited DS byte.
As discussed previously, the degree of a video stream’s importance for receiving low-delay network service depends heavily on the application’s context. If we consider different degrees of importance for receiving low delay for different packets within a stream, we find that varying demands for delay quality are usually connected with the layered coding of video compression. For example, the I, P, and B frames of ISO/IEC MPEG-1/2/4 frames have varying demands with regard to delay as well as loss. The situation is similar for the spatial-scalable, SNR-scalable, and data-partitioned layers of MPEG or H.261/H.263, with the exception of the temporal-scalable layer. However, as a video application becomes network-aware, the trend seems to move gradually toward delay variation, even within a stream. A good example is the asynchronous media transmission scenario, where flexible delay margins can be exploited throughout transmission. This idea has been denoted as delay-cognizant video coding in [101], which applied an extended form of region-based scalability to H.263 video. Multiple-region layers within a stream were constructed in [101], where varying delay requirements were associated by perceiving a motion event such as nodding, gesturing, or maintaining lip synchronization. To be more specific, cognizant video coding assigns the lowest delay to the most visually significant region, and vice versa. Since packets assigned a longer delay may arrive late, this presents the opportunity for the network service to route packets through less congested but longer routes and charge lower prices. Another example is packets of the MPEG-4 system that encompass multiple elementary streams with different demands under one umbrella. This kind of integrated stream can justify the demand for inter-media RDI/RLI differentiation. Thus, we propose to distinguish a packet based on the loss rate and delay tuple, leaving flexibility to subsequent stages. Note, however, that only fixed RDI for a flow is employed currently.
Most state-of-the-art video compression techniques, including H.263+ and MPEG-1, 2, and 4 are based on motion-compensated prediction (MCP). The video codec employs inter-frame prediction to remove temporal redundancy and transform coding to reduce spatial redundancy. MCP is performed at the macroblock (MB) level of 16 × 16 luminance pixels. For each MB, the encoder searches the previously reconstructed frame for the MB that best matches the target MB, being encoded. To increase estimation accuracy, sub-pixel accuracy is used for the motion vector representation, and interpolation is used to build the reference block. Residual errors are encoded by the discrete cosine transform (DCT) and quantization. Finally, all information is coded with either a fixed-length code or variable-length code (VLC).
Basically, two different types of MBs can be selected adaptively for each MB. One is the inter-mode coding that includes motion compensation and residual error encoding. The other is intra-mode coding, in which only DCT and quantization are used for the original pixels. In the initial anchor frame, or when a new object appears in a frame to be encoded, the sum of absolute differences (SAD) of the most closely matching MB can be larger than the sum of the original pixels. For these cases, the intra-mode MB is used. Otherwise, the inter-mode MB, which usually costs less due to temporal redundancy elimination, is used.
In the Internet environment, packets may be discarded due to buffer overflow at intermediate nodes of the network, or they may be considered lost due to long queuing delays. VLC is very vulnerable to even one bit of error. If error occurs in the bit-stream once, the VLC decoder cannot decode the next codes until it finds the next synchronization point. Thus, a small error can result in catastrophic distortion in the reconstructed video sequence.
Packet loss results in the loss of encoded MBs as well as the loss of synchronization. It affects MBs in subsequent packets until the decoder is re-synchronized (or refreshed). When packet loss occurs, an error recovery action (i.e., error concealment), which attempts to identify the best alternative for the lost portion, is performed at the decoder.
Usually, no normative error concealment method is defined for most MCP video compression standards, but various error concealment schemes have been proposed [102], [103]. The temporal concealment scheme exploits the temporal correlation in video signals by replacing a damaged MB with the spatially corresponding MB in the previous frame. This straightforward scheme, however, can produce adverse visual artifacts in the presence of large motion, and the motion-compensated version of temporal concealment is usually employed with estimated motion vectors from surrounding MBs. Even after sophisticated error concealment, there remains residual error, which is propagated due to the recursive prediction structure. This temporal error propagation is typical for hybrid video coding that relies on MCP in the inter-frame mode. The number of times a lost MB is referenced in the future depends on the coding mode and motion vectors of MBs in subsequent frames. This tells us the importance of each MB from the viewpoint of error propagation.
While propagating temporally and spatially, the residual error after error concealment decays over time due to leakage in the prediction loop. Leaky prediction is a well-known technique to increase the robustness of differential pulse code modulation (DPCM) by attenuating the energy of the prediction signal. For hybrid video coding, leakage is introduced by spatial filtering operations that are performed during encoding. Spatial filtering can either be introduced explicitly by an explicit loop filter or implicitly as a side-effect of half-pixel motion compensation (i.e., with bilinear interpolation). This spatial filtering effect in the decoder was analyzed by Farber et al. [104]. In their work, the loop filter is approximated as a Gaussian-shaped filter in the spatial frequency domain. It is given by
where ![]() is determined by the filter shape and indicates the strength of the loop filter. As shown in Eq. (3.1), the loop filter behaves like a low-pass filter, and its bandwidth is determined by time t and filter strength
is determined by the filter shape and indicates the strength of the loop filter. As shown in Eq. (3.1), the loop filter behaves like a low-pass filter, and its bandwidth is determined by time t and filter strength ![]() .
.
By further assuming that the power spectral density (PSD) of error signal u(x, y) is a zero-mean, stationary, random process, we obtain
(i.e., a separable Gaussian PSD with variance ![]() that can be interpreted as the average energy). The shape of the PSD of the error signal is characterized as
that can be interpreted as the average energy). The shape of the PSD of the error signal is characterized as ![]() . Thus, the pair of parameters
. Thus, the pair of parameters ![]() determines the energy and shape of the error signal’s PSD and can be used to match Eq. (3.2) with the true PSD. With these approximations, the variance of the error propagation random process v (x, y) can be derived as
determines the energy and shape of the error signal’s PSD and can be used to match Eq. (3.2) with the true PSD. With these approximations, the variance of the error propagation random process v (x, y) can be derived as

where ![]() is a parameter describing the efficiency of the loop filter in reducing the introduced error and α[t] is the power transfer factor after t time steps.
is a parameter describing the efficiency of the loop filter in reducing the introduced error and α[t] is the power transfer factor after t time steps.
This analytical model, as given in Eqs. (3.1, 3.2, 3.3) has been verified in experimental results [103], [104]. While the statistical propagation behavior is analyzed with this model, it is difficult to estimate the loss effect for each packet composed of several MBs [i.e., the group of block (GOB) unit, in general]. Thus, we extend the propagation behavior by incorporating additional coding parameters such as error concealment schemes and the encoding mode so that it is possible to track the error propagation effect better with moderate computational complexity in the following section. The purpose of the corruption model is to estimate the total impact of packet loss. When one or more packets are lost, errors are introduced and propagated. The impact of errors is defined as the difference between reconstructed frames with and without packet loss as measured by mean square errors (MSEs).
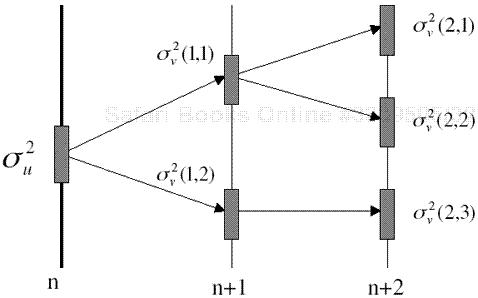
Figure 3.3 shows the error propagation of a lost MB, in which the initial error of the corrupted MB is denoted by u(x, y) and its energy is measured in terms of the error variance ![]() . The propagation error v(x, y) in consecutive frames has energy
. The propagation error v(x, y) in consecutive frames has energy ![]() in impaired MB j of frame n + m.
in impaired MB j of frame n + m.
The initial error due to packet loss is dependent on the error concealment scheme adopted by the decoder. The amount of initial error can be calculated at the encoder if the error concealment scheme used in the decoder is known a priori. For simplicity, we assume that the decoder uses the TCON error concealment scheme as specified in H.263+ Test Model 10 [105]. Also, at this stage, we will confine the corruption model analysis to the case of isolated packet loss. Under a low loss rate, this corruption model exhibits reliable accuracy. The multiple-packet loss case will be discussed in a later section, which will address the scenario involving a higher loss rate. Also, only an MB unit (i.e., 16 × 16) estimation is analyzed, excluding the advanced prediction option, at present. This simplifies an MB as the unit of the coding mode with a unique motion vector (for inter-frame modes). From an MB with 256 pixels, we can extract the PSD of the signal by analyzing its frequency component. In addition, an MB-based calculation costs much less than a pixel-based computation. The MB-level corruption model will also later be extended to the GOB level, with some restrictions.
Let us analyze the energy transition through an error propagation trajectory. Typical propagation trajectories are illustrated in Figure 3.3. A trajectory is composed of two basic trajectory elements: a parallel trajectory and a cascaded trajectory. Before the analysis, some assumptions are required to reduce the computational complexity. Let the decoder with the DPCM loop and spatial filter be a linear system. Also, for each frame to be predicted, the time difference is set to 1, that is, t = 1 in Eq. (3.3).
Figure 3.4(a) shows the parallel propagation trajectory. The error in reference frame n is characterized by ![]() , which determines the PSD of the error. In the parallel trajectory, an error can propagate to more than two different areas in subsequent frames. For each path, a different motion vector and a different spatial filtering can be applied. Thus, a different filter strength can be applied, as depicted in the equivalent linear system of Figure 3.4(b).
, which determines the PSD of the error. In the parallel trajectory, an error can propagate to more than two different areas in subsequent frames. For each path, a different motion vector and a different spatial filtering can be applied. Thus, a different filter strength can be applied, as depicted in the equivalent linear system of Figure 3.4(b).

Ha(ω) and Hb(ω) may have a different filter function, but both functions are the Gaussian approximation of the spatial filter. The PSD of the error frame is transferred to the predicted frame via
and the corresponding error energy is derived as

where ![]() and
and ![]() . Therefore, the MSE can be individually estimated and accumulated for the parallel error propagation trajectory.
. Therefore, the MSE can be individually estimated and accumulated for the parallel error propagation trajectory.
In the cascaded propagation trajectory of Figure 3.4(a), the initial error energy ![]() of U of frame n is referenced in A of frame n + 1 and then it is transferred to B in frame n + 2 again. The equivalent linear system is shown in Figure 3.4(b). For each transition, the loop filter function is characterized by
of U of frame n is referenced in A of frame n + 1 and then it is transferred to B in frame n + 2 again. The equivalent linear system is shown in Figure 3.4(b). For each transition, the loop filter function is characterized by ![]() and
and ![]() respectively. Then, the PSD of the propagation error in frame n + 2 is given by
respectively. Then, the PSD of the propagation error in frame n + 2 is given by

and its energy can be derived as

where

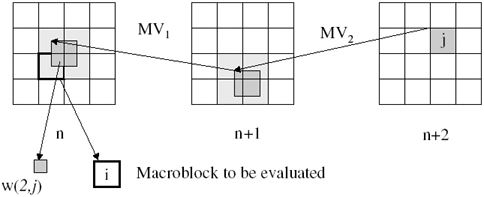
The propagation error energy from U to B is given in Eq. (3.7). It is the same as Eq. (3.3) except for the loop filter efficiency γ. For the cascaded propagation, the loop filter efficiency γ can be derived from the equivalent loop filter strength ![]() , which is the sum of filter strengths σfa and σfb. As a result, the equivalent filter strength for the cascaded propagation is the sum of filter strengths along the propagation path. Because of the motion vector (even in sub-pixel accuracy), a portion of one MB is usually referenced by the predicted frames. In this case, all errors of an impaired MB do not propagate to subsequent frames. Thus, we must consider the portion of an MB that contributes to the next predicted frames as a reference, a quantity that is denoted as the dependency weight. If we denote the ith MB of frame n as MBn,i and a portion of MBn,i contributes to MBn+m,j, then the dependency weight wn,i(m, j) is defined as the normalized number of pixels that are transferred from MBn,i to MBn+m,j. If no portion of an MB is referenced by the jth MB of the (n + m)th frame, wn,i(m, j) is zero. Otherwise, it has a value between zero and one.
, which is the sum of filter strengths σfa and σfb. As a result, the equivalent filter strength for the cascaded propagation is the sum of filter strengths along the propagation path. Because of the motion vector (even in sub-pixel accuracy), a portion of one MB is usually referenced by the predicted frames. In this case, all errors of an impaired MB do not propagate to subsequent frames. Thus, we must consider the portion of an MB that contributes to the next predicted frames as a reference, a quantity that is denoted as the dependency weight. If we denote the ith MB of frame n as MBn,i and a portion of MBn,i contributes to MBn+m,j, then the dependency weight wn,i(m, j) is defined as the normalized number of pixels that are transferred from MBn,i to MBn+m,j. If no portion of an MB is referenced by the jth MB of the (n + m)th frame, wn,i(m, j) is zero. Otherwise, it has a value between zero and one.
The dependency weight can be calculated recursively with stored motion vectors and MB types as shown in Figure 3.5. However, since motion compensation is not a linear operation, we have to assume that the motion vectors of neighboring MBs are the same (or at least very similar), so that the target MB is transferred without severe break, as depicted in Figure 3.5. Another assumption is that the error in an MB is uniformly distributed in the spatial domain while also having a Gaussian PSD. Then, the transferred error energy from MBn,i to MBn+m,j can be calculated with the loop-filtering effect and dependency weight. Finally, to evaluate the total impact of the loss of MBn,i, the weighted error variances for MBs of subsequent frames should be summed. Because the initial error can sustain over a number of frames without converging to zero, we must limit frames to be evaluated under an acceptable computational complexity. Fortunately, when the intra-MB refresh technique is used at the encoder, the propagated error energy converges to zero within a fixed number of frames. Thus, in general, a pre-defined number of frames is sufficient to estimate the total impact of the MB loss. This defines an estimation window for the corruption model.
The appropriate estimation window might be determined based on the strength of the intra-MB refresh. As a result, the total energy of errors due to an MB loss in a sequence can be written as

where M is the size of the estimation window and N is the total number of MBs in a frame, respectively. Also, we have

The corruption model derived above can be viewed as an MB-level extension of the statistical error propagation model given in [104].
The MB-level corruption model described in the previous section indicates the level of importance, for each MB, of not losing the MB. Thus, RLI can be defined on the basis of such a corruption model. However, determining the importance of not losing a particular MB requires an estimation window as data history, which induces some delay before marking RLI per packet. In this section, a simple and practical version is presented for online RPI generation. This RLI is calculated from video factors such as initial error, motion vector, and MB encoding type. Such a simplified MB-based corruption model provides RPI association to approximate the actual loss impact in MSE.
Under packetized video transmission, the RLI assignment for a packet is best when it can precisely represent its error propagation impact on the receiving video quality. However, the specific method for RLI prioritization is totally application- (and furthermore, video compression scheme-) dependent. Thus, we have chosen ITU-T H.263+ video [96] as the evaluation codec, considering its wide acceptance for low-latency video conferencing and its potential for video streaming. Note that with regard to this RLI association, there is not much difference among the motion-compensated prediction codecs, which include both MPEGs and H.261/H.263.
Given frame size and target bit rate, each packet has a different loss effect on end-to-end video quality due to inter-frame prediction. The impact of packet loss may spread within a frame up to the next re-synchronization (e.g., the picture or GOB headers) due to differential coding, run-length coding, and variable-length coding. This is referred to as spatial error propagation, and it can damage any type of frame. For temporal error propagation, damaged MBs affect the non-intra-coded MBs in subsequent frames, which use corrupted MBs as references. Recent research on the corruption model [106] has attempted to model this loss effect. The corruption model is a tool used to estimate the packet loss impact on the overall received video quality. However, most modelling efforts have focused on the statistical side of the loss effect, while a dynamic solution was sought in our approach. Instead of computationally complex options, we devised ways to associate RLI to H.263 packets with a simple and online calculation.
Basically, we use the error-resilient H.263+ stream, compressed at a target rate of 384 kilobits per second (kbps), for a common intermediate format (CIF) test sequence with 10 frames per second (fps). Several error resilience and compression efficiency options (“Annexes D, F, I, J, and T” with random intra-refresh) are used in the generation of the so-called “Anchor” (i.e., GOB) mode stream. The random intra-refresh rate is set to 5% to cover the network packet loss. It is then packetized by one or more packets per GOB, which is dependent on the maximum transfer unit (MTU) size of the IP network. Thus, we propose a simple yet effective RLI association scheme for this H.263+ video stream, which is calculated for each GOB packet.
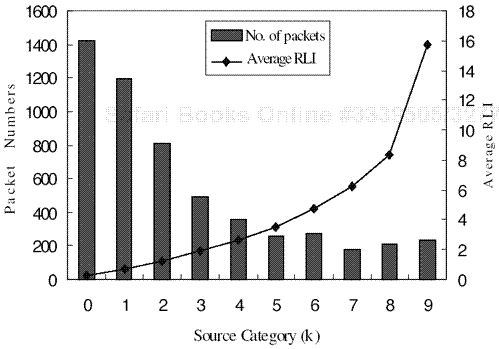
Various video factors are taken into consideration for the proposed RLI association. First, the magnitude and direction of the motion vector for each MB are included to reflect the loss strength and temporal loss propagation due to motion. Then, the encoding types (intra, intra-refreshed, inter, etc.) are considered. In other words, the refreshing effect is added by counting the number of intra-coded MBs in a packet. Finally, the initial error due to packet loss is considered, assuming the normative error concealment adopted at the decoder. To better explain this, sample distributions of these three video factors are depicted in Figure 3.6. The RLI for a packet may take into account all of these video factors by summarizing the normalized video factors with an appropriate weighting as

where NVF is the total number of video factors considered, NVFn stands for the normalized video factors, and Wn stands for the corresponding weight factors. The normalization is done with an online version such as  through updating the sampling mean
through updating the sampling mean ![]() at an ith update time.
at an ith update time.

Figure 3.6. Video factors (VFs) for RLI with “Foreman” sequence: (a) motion vector magnitude; (b) number of I-coded MBs in each packet; and (c) initial error due to packet loss.
Figure 3.7 shows an example of the resulting RLI assignment for a “Foreman” sequence. This model provides a much more accurate estimated MSE, but it needs forehead information in a particular window range to allow calculation of the propagation effect. For our purpose of QoS mapping, we do not need an accurate MSE amount because the relative priority order and relative quantity are enough. Eq. (3.10) is simple and can be generated easily as an online version with the sampling mean. A more accurately estimated RLI based on a corruption model is proposed in [107], but it needs the history information of several subsequent frames to make such an estimate, which is somewhat of a trade off. As shown in Figure 3.8(d), using 20 frame history windows to calculate RLI has more correlation with actual measured MSE than the process shown in Figure 3.8(c).

Figure 3.7. RLI for “Foreman” sequence obtained by applying Wn’s (0.15, 0.15, and 1.75) for the three video factors of Figure 3.6.
![A comparison of: (a) the actually measured MSE coming from loss of each GOB packet; (b) the proposed RLI pattern for a “Foreman” sequence; (c) the correlation distribution between actual MSE and proposed RLI of the same GOB packet number; and (d) the correlation distribution between actual MSE and corruption model-based RLI in [107].](http://imgdetail.ebookreading.net/system_admin/3/0131414631/0131414631__quality-of-service__0131414631__graphics__03fig08.jpg)
Figure 3.8. A comparison of: (a) the actually measured MSE coming from loss of each GOB packet; (b) the proposed RLI pattern for a “Foreman” sequence; (c) the correlation distribution between actual MSE and proposed RLI of the same GOB packet number; and (d) the correlation distribution between actual MSE and corruption model-based RLI in [107].
To show that proposed RLI approximates actual loss propagation, the actually measured MSE from each GOB packet is calculated and compared with the proposed RLI pattern in Figure 3.8. The simple RLI shows a pattern similar to the actual MSE, and there is general correlation between two. This is enough for our goal of differentiating video packets in a stream for prioritization marking according to their importance since the QoS mapping is needed from only several source categories and the network DS levels are few in number.
Finally, RLIs are categorized into K DS traffic categories to enable mapping to limited DS field space (or eventually to be ready for mapping to more limited network DS levels). In our approach, simple non-uniform quantization of RLI is performed for this categorization. That is, as shown in Figure 3.9, categorization is done with gradually increasing steps as category k increases. Another possible approach is to categorize packets into an equal number (i.e., uniform distribution). After categorization, all packets belonging to category k may be represented by their average RLI value, ![]() .
.
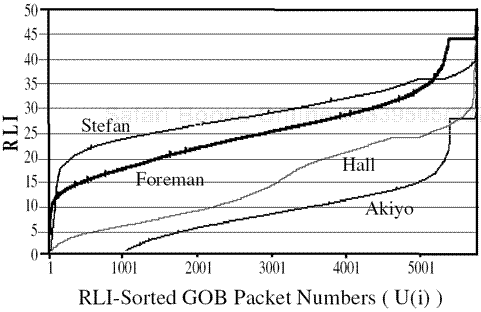
Higher RLI thus represents more potential damage to visual quality. To verify the clustering behavior of RLI association, we observed RLI distribution for several video sequences. As shown in Figure 3.10, the RLI distribution varied according to a scene’s characteristics. Since it affects the QoS mapping, we will explore the impact of RLI distribution patterns in Section 3.4.2. Finally, RLIs are categorized to enable mapping to limited DS field space (or eventually to be ready for mapping to more limited network DS levels), which is represented by source category k among K categories. In our approach, simple, uniform quantization of RLI is performed for this categorization. After categorization, all packets belonging to category k may be represented by their average RLI value, ![]() .
.
In the proposed framework, properly matching the RPI of a video packet with DiffServ classes differentiated by loss rate and by delay QoS of the network service is key to successful video delivery. For this, we first formulate the interaction framework into the QoS mapping problem described in the next section. Then, we derive the solution to this mapping problem to use it as a per-flow QoS mapping guideline.
QoS mapping a relative prioritized packet onto a DS level can be formulated into the following optimization problem for a single flow. Each packet i of the flow, mapped to a certain network DS level q (∊{0, 1, . . . , Q-1}), gets an average packet loss rate ![]() by paying unit price pq. (DS level refers to a DiffServ class or traffic aggregate in IETF terminology, that is, a DS level is associated with a particular DSCP.) For the sake of simplicity, fixed RDI per flow is used to limit the allowed range of [qmin, qmax] to which packets can be mapped without violating the delay requirement. Then, the problem only needs to address the RLI-based optimization as follows. Each packet i of flow f assigned to a certain network DS level q will get an average packet loss rate
by paying unit price pq. (DS level refers to a DiffServ class or traffic aggregate in IETF terminology, that is, a DS level is associated with a particular DSCP.) For the sake of simplicity, fixed RDI per flow is used to limit the allowed range of [qmin, qmax] to which packets can be mapped without violating the delay requirement. Then, the problem only needs to address the RLI-based optimization as follows. Each packet i of flow f assigned to a certain network DS level q will get an average packet loss rate ![]() by paying unit price pq. Given the acceptable total cost P(f), the effort to achieve the best end-to-end quality for flow f can be formulated by minimizing the generalized quality degradation QD(f):
by paying unit price pq. Given the acceptable total cost P(f), the effort to achieve the best end-to-end quality for flow f can be formulated by minimizing the generalized quality degradation QD(f):

where N(f) is the total number of packets in flow f. The QoS mapping is denoted by vector
and q(i) is the DS level to which the ith packet is mapped.
If we fix the mapping decision for all packets that belong to category k, Eq. (3.11) is simplified to Eq. (3.12). Note that the QD in Eq. (3.12) is an expected QD, where the loss effect of a packet belonging to category k is represented by the average loss effect ![]() :
:

where ![]() is the number of packets belonging to category k for flow f. Note that
is the number of packets belonging to category k for flow f. Note that ![]() . The QoS mapping decision is denoted by the K-dimensional vector
. The QoS mapping decision is denoted by the K-dimensional vector ![]() , where K is the number of the source’s packet categories.
, where K is the number of the source’s packet categories.
To solve the above optimization problem, consider the following factors. First, in a real situation, we must limit the resource allocation based on the TCA specified in the SLA with the DiffServ network. Thus, the above formulation must be constrained further by the traffic conditioning agreement before practical utilization. Next, the cost function given above may better reflect a real situation if the added complexity and out-of-order arrival handling cost due to dynamically scattered packets over multiple DS levels are included. These factors are assumed negligible at the current stage. Finally, pq(k) depends on DiffServ provisioning, which will be decided by the service provider and negotiated in the SLA.
To use this as a guiding solution, we assume that a DS domain provides a proportional DiffServ and maintains the specified proportionality persistently in a wide range of time scales. The optimal solution in such an idealized situation can be derived as follows. In an idealized, proportional, and differentiated service, the packet loss rate ![]() can be specified as a particular monotonically decreasing function of the DS level q. (In an proportional DiffServ, the actual value of the loss rates experienced can be a certain factor times the function, and the multiplicative factor varies with time.) We consider the case that the loss rate
can be specified as a particular monotonically decreasing function of the DS level q. (In an proportional DiffServ, the actual value of the loss rates experienced can be a certain factor times the function, and the multiplicative factor varies with time.) We consider the case that the loss rate ![]() is inversely proportional to the DS level q.[4] If unit price pq is assumed to be proportional to DS level q, the optimal mapping solution
is inversely proportional to the DS level q.[4] If unit price pq is assumed to be proportional to DS level q, the optimal mapping solution ![]() to (3.12) can serve as a guide for the mapping decision to be practiced. We can use the Lagrangian technique [108] for both constrained optimization problems (3.11) and (3.12).
to (3.12) can serve as a guide for the mapping decision to be practiced. We can use the Lagrangian technique [108] for both constrained optimization problems (3.11) and (3.12).
Let us assume for simplicity that the value of q(k) can be taken from a continuum. We can then replace the inequality constraint of Eq. (3.12) with an equality constraint because the optimal solution obviously will have to spend all of the allowable cost P(f). According to the Lagrangian principle, there is a useful sufficiency condition that states that if a value λ can be found such that a value of ![]() , say
, say ![]() (λ), minimizing
(λ), minimizing

satisfies the equality constraint

then ![]() solves Eq. (3.12). Thus, we can guess a value of λ that minimizes Eq. (3.13). If the minimum point satisfies the equality constraint (3.14), then the solution is found. Otherwise, we can adjust the value λ and minimize Eq. (3.13) again. Furthermore, Eq. (3.13) is separable, so we can separately minimize
solves Eq. (3.12). Thus, we can guess a value of λ that minimizes Eq. (3.13). If the minimum point satisfies the equality constraint (3.14), then the solution is found. Otherwise, we can adjust the value λ and minimize Eq. (3.13) again. Furthermore, Eq. (3.13) is separable, so we can separately minimize
for each k. This minimizing value of q(k) can be found by drawing a line with slope -λ that is tangent to the convex hull of curve QDk ![]() versus cost. The cost pq(k) corresponding to the contact point of the tangent line is the cost of q(k) that minimizes Jk(λ) for the given λ. Figure 3.11 illustrates such minimizing values of q(k) for different values of k for a given λ. (Note that we are assuming that cost pq(k) is proportional to q(k).)
versus cost. The cost pq(k) corresponding to the contact point of the tangent line is the cost of q(k) that minimizes Jk(λ) for the given λ. Figure 3.11 illustrates such minimizing values of q(k) for different values of k for a given λ. (Note that we are assuming that cost pq(k) is proportional to q(k).)

Figure 3.11. Illustration for mapping from RLI to the DS level. (Given the relationship for RLI categorization, the loss rate per DS level, and the pricing strategy, the Lagrangian formulation leads to optimal mapping.)
With the assumption of loss rate function lq(i) = L / q(i) and unit price function Pl · q(i) (as illustrated by two of the curves in Figure 3.12(b)), the Lagrangian formula for Eq. (3.11) for each i becomes

Then, by searching around the convex hull of the graph of QD versus cost, we can obtain the optimal mapping solution for a particular value of λ. Also, we can obtain a closed-form solution by searching for stationary points where ![]() and applying equality constraint
and applying equality constraint ![]() pq(i) = P(f). For a given operating λ, the minimum can be computed independently for each packet. The point on the QD versus cost characteristic that minimizes Ji(λ) is the point at which the line of absolute slope λ is tangent to the convex hull of the QD versus cost curve. The resulting closed-form solution is expressed by
pq(i) = P(f). For a given operating λ, the minimum can be computed independently for each packet. The point on the QD versus cost characteristic that minimizes Ji(λ) is the point at which the line of absolute slope λ is tangent to the convex hull of the QD versus cost curve. The resulting closed-form solution is expressed by ![]() and
and ![]()
Further assuming knowledge of the video source’s RLI distribution, we can finally obtain a solution to Eq. (3.11). For this, we approximate the RPI distribution of sequences shown in Figure 3.10 as one of the three different RLI patterns shown in Figure 3.12(a): C1 U(i)2 for “Akiyo,” C2 U(i) for “Hall,” and ![]() for the “Stefan” and “Foreman” sequences.
for the “Stefan” and “Foreman” sequences.

Figure 3.12. (a) RLI pattern with typical categorized video types; (b)an example of the packet loss rate and unit cost of DS level q.
This closed-form solution usually matches the actual numeric solutions depicted in Figure 3.13 for “Akiyo,” “Hall,” and “Stefan,” respectively. Note that the mapping distribution resembles that of Figure 3.10, which is again represented by patterns C1 U(i)2, C2 U(i), and ![]() , respectively. We can get some QoS mapping guidance from types such as RLIi, which represent C1 U(i)2, C2 U(i), and
, respectively. We can get some QoS mapping guidance from types such as RLIi, which represent C1 U(i)2, C2 U(i), and ![]() as the ascending order for source category k shown in Figure 3.12(a). The loss rate function of each DS level lq(i) is assumed to be two typical types, such as
as the ascending order for source category k shown in Figure 3.12(a). The loss rate function of each DS level lq(i) is assumed to be two typical types, such as ![]() or
or ![]() , which are shown in Figure 3.12(b).
, which are shown in Figure 3.12(b).

One Lagrangian formula of Eq. (3.16) is for the case of an RLI using C2 U(i). Now,

We can get a closed form in case of ![]() using
using ![]() and the equality constraint. Then, we can obtain the solution q(i), an optimal QoS mapping with the λ determined by total cost constraint, as follows:
and the equality constraint. Then, we can obtain the solution q(i), an optimal QoS mapping with the λ determined by total cost constraint, as follows:

If RLIi has another pattern, such as C1 U(i)2, ![]() , then an optimal QoS mapping takes the forms that are proportional to U(i) and
, then an optimal QoS mapping takes the forms that are proportional to U(i) and ![]() , respectively. It matches the actual numeric solutions of the video test sequences of “Akiyo,” “Hall,” and “Stefan,” which are patterns similar to C1 U(i)2, C2 U(i), and
, respectively. It matches the actual numeric solutions of the video test sequences of “Akiyo,” “Hall,” and “Stefan,” which are patterns similar to C1 U(i)2, C2 U(i), and ![]() , respectively. The numeric solutions under the same total cost constraint (i.e., all k is assigned to q = 4) are shown in Figure 3.13(a) as a categorized source version.
, respectively. The numeric solutions under the same total cost constraint (i.e., all k is assigned to q = 4) are shown in Figure 3.13(a) as a categorized source version.
Now, let us consider the case in which the loss rate is a linear function of q and the cost pq is also a linear function of q (e.g., pq = Pl · q for some Pl). In such a case, the expected quality degradation caused by packet i, ![]() is a linear function of price pq.
is a linear function of price pq.
Let us now narrow our scope further and consider the case in which source packets have been grouped into a small number of categories K, as assumed by Eq. (3.12). We denote the category of packet i by k(i). ![]() denotes the average RLI value of category k(i) or k. Figure 3.14 illustrates that the expected quality degradation measures, QDs, caused by packets i and j, are both linear functions of price. The slope of the line for packet i (or j) is affected by
denotes the average RLI value of category k(i) or k. Figure 3.14 illustrates that the expected quality degradation measures, QDs, caused by packets i and j, are both linear functions of price. The slope of the line for packet i (or j) is affected by ![]() . Figure 3.14 also illustrates how to optimally map the grouped source categories k with different
. Figure 3.14 also illustrates how to optimally map the grouped source categories k with different ![]() to network DS levels q.
to network DS levels q.

Now, let us see how the optimal QoS mapping is determined in this linear loss rate case. In the example case in Figure 3.14, category k(i)’s QD is more sensitive to the price of q than category k(j)’s because the absolute value of ![]() is greater than that of
is greater than that of ![]() .
.
As a simple illustration, let us suppose that we map both packets i and j to the same DS level that incurs cost p0. Next, we insert a perturbation of the QoS mapping. Now, say that we reduce the cost of packet i by amount p0–p1 and increase the cost of packet j by p2–p0 while preserving the total cost. This can be done by choosing p1 and p2 in such a way that p0–p1 = p2–p0. (For conceptual illustration, we are currently assuming that q is in a continuum.) After such a perturbation of QoS mapping, the resulting total of the expected degradation is reduced, while the total cost remains the same. Thus, for any pair of packets belonging to different categories k, we can keep adjusting their DS levels (prices) while keeping the total cost unchanged. If this process is continued, the resulting optimal mapping q(i) has monotonicity with respect to k(i). (The higher k(i), the higher q(i).) Furthermore, the majority of packets are mapped to the extreme values of q. In other words, most packets are mapped to the highest DS class or lowest DS class. The numerical solution in Figure 3.13(b) illustrates this.
The proposed QoS mapping framework is evaluated by simulations in several steps. For video streaming, an error-resilient version of the ITU-T H.263+ stream is used and decoded by an error-robust video decoder. All other components are then simulated by NS [27].
We evaluated simple and online-capable RPI (exactly RLI) in Section 3.3 through an ideal setting in which each DS level q had a different but exact packet loss rate pre-assigned by a given manipulated packet loss curve versus q. Each packet loss rate of q randomly experiences a packet loss rate from the state of the two-state Markov chain known as the Gilbert model, shown in Figure 3.15. The transition probabilities from “Bad” (i.e., packet loss) to “Good” as q = 0.9 and ![]() give a little bit of burst to the packet losses. The average packet loss rate
give a little bit of burst to the packet losses. The average packet loss rate ![]() varies between 0% and 20%.
varies between 0% and 20%.
The Markov model is popular for capturing temporal loss dependency [109], [110], [111]. It is simple to understand and implement in monitoring applications. In Figure 3.15, p is the probability that the next packet will be lost, provided the previous one has arrived. q is the opposite. 1 – q is the conditional loss probability. Normally, p + q < 1. If p + q = 1, the Gilbert model reduces to a Bernoulli model.

First, the proposed RPI performance is evaluated with H.263+ video streams under the ideal network condition of Figure 3.12(b). The result shows the effectiveness of packet-/session-based differentiation (performed by QoS mapping) over several typical video sequences. The idealized packet loss rate for each DS level is simulated by a two-state Markov model known as the Gilbert model with transition probabilities from “Bad” (i.e., packet loss) to “Good” as q = 0.9 (a somewhat large value), which gives slightly bursty packet losses. If we set q as a small probability value, it causes relatively longer bursty packet loss (i.e., a large loss-correlation effect).
The phenomenon of bursty packet loss is found easily, but the bursty loss period depends on various network load conditions. A result [112] shows that a short bursty loss causes a greater extent of video degradation in comparison with a long bursty loss since the former occurs more frequently than the latter under the same packet loss probability. In this experiment, we wanted to show the performance comparison in the case of short bursty packet loss under severe network load conditions.
Figure 3.16 shows the performance comparison between RPI-aware and RPI-blind mapping under total cost constraint. The loss rate and cost curve per DS level are assumed as the curves for pq(i) and ![]() shown in Figure 3.12(b). It is interesting to note that the gain in PSNR varies somewhat depending on the video sequences. For “Akiyo,” the gain is smaller than with other sequences, which is partly due to the small movement involved in this scene. However, for other sequences, we can observe a clear advantage of packet-based differentiation. Overall, this result verifies the obvious benefit of RPI-aware QoS mapping in DiffServ networks.
shown in Figure 3.12(b). It is interesting to note that the gain in PSNR varies somewhat depending on the video sequences. For “Akiyo,” the gain is smaller than with other sequences, which is partly due to the small movement involved in this scene. However, for other sequences, we can observe a clear advantage of packet-based differentiation. Overall, this result verifies the obvious benefit of RPI-aware QoS mapping in DiffServ networks.

Figure 3.16. Average objective video quality (expressed in PSNR) for several video sequences under the loss/cost assumption of Figure 3.12(b).
Focusing on the relative differentiated version of the IP DiffServ model, we have presented a futuristic QoS mapping framework in this chapter. We have proposed RPI-based video categorization and effective QoS mapping under a given cost constraint. The RPI plays a good bridging role in enabling the network to be content-aware and provides delivery of packets with QoS commensurate with their contents. This results in better end-to-end video quality at a given cost. We have also suggested practical guidelines for effective QoS mapping based on categorized RPI. The performance of content-dependent differentiation was demonstrated by extensive experimental results under the two-state Markov chain, modelling a different random packet loss rate for each network DS level (DiffServ class). The results clearly indicate the benefit of the proposed mapping framework. Experimental results showed that the proposed framework enhances end-to-end video quality at the same total cost.
Two areas in this proposed framework can be further elaborated. First, only the differentiation of loss rates was performed in this work, and it must be extended to cover another key QoS measure—delay/jitter. Loss rate/delay-combined differentiation will provide a more comprehensive characterization of multimedia contents (for the video stream itself as well as among various kinds of multimedia traffic). Thus, by summarizing loss rate and delay priorities in the DS byte of the packet header, more enhanced, content-dependent forwarding will be feasible. Second, to consider a more accurate evaluation of error propagation for the QoS mapping decision, we assigned RLIs to source packets on the basis of the corruption model in Section 3.3.2. Such schemes further improve performance. However, assignment based on the simple online-generated RLI in Section 3.3.3 has the advantage of online implementability and simplicity. Indeed, QoS mapping based on this simple online RLI assignment works fairly well already.
[1] Note that DiffServ PS can be regarded as being more in-line with absolute differentiation than with relative differentiation.
[2] “DS level” can be interpreted as the grade of quality provided to a group of packets having an identical DSCP in the IP header.
[3] Regarding the dynamic QoS mapping issue, some preliminary investigation was done in our latest work on the specially designed DiffServ boundary node [100].
[4] Note that the loss rate and DS level may take on diverse relationships in real practice. However, this typical relationship seems to provide reasonable guidance.