
To see what is in front of one's nose needs a constant struggle. | ||
| --George Orwell, "In Front Of Your Nose" | ||
Topics Covered in This Chapter
Getting to Know the Current Database
Conducting the Analysis
Looking at How Data Is Collected
Looking at How Information Is Presented
Conducting Interviews
Conducting User Interviews
Conducting Management Interviews
Compiling a Complete List of Fields
CASE STUDY
Summary
To determine where you should go, it's necessary to understand where you are. The database currently in use can provide a dependable resource for developing the new database. What is required is a detailed understanding of the current database, and careful judgment of the features that can remain useful, or conversely, those that should be discarded. To make such judgments, you need to answer the following questions:
What types of data does the organization use?
How does it use that data?
How does it manage and maintain that data?
The answers to these inquiries provide the basic guidelines for creating the new database structure. Armed with this information you can design a database that best suits the organization's needs.
The best way to answer these questions is by analyzing the database the organization currently uses. (It's very likely that it is using some type of database, whether it is a paper-based database, a legacy database, or even a system based on the memory of some of the employees.) The goal of the analysis is to determine the types of data the organization uses and how the data is managed and maintained. It also serves to identify how the data is viewed and used. If you conduct this investigation properly, it will reduce the time it takes to define the preliminary field and table structures for the new database.
This analysis requires reviewing the various ways data is collected, reviewing the ways in which the data is presented, and conducting a set of interviews with users and management. The information gathered from the analysis is then used to define a preliminary field list and help determine the tables that should be included in the initial database structure. Furthermore, if the analysis reveals that the current database is poorly designed, precautions can be implemented to guard against making the same mistakes in the new database. Despite whatever shortcomings the current database may have, it can help you identify a number of the fields and tables that you should define in the new database.
Yet there's one particularly significant point to remember as you're analyzing the current database: do not adopt the current database structure as the basis for the new database structure. This is a particularly bad idea, because imported errors are the most difficult to identify. Every so often, there's a point during the analysis when a novice database developer (and sometimes experienced ones as well) will stop and think, "This database doesn't look too bad. Let's just end the analysis here and use this database as the basis for the new one." The danger posed by this line of thinking is that any "hidden" problems within the current database will be transferred into the new database. These types of problems include awkward table structures, poorly defined relationships, and inconsistent field specifications. And without a doubt, these problems always surface later at the least opportune time. So by all means explore the old database for information on types of data, uses of data, and perhaps use some of the old database's data, once you have tested it. But it's always better to define a new database structure explicitly than to copy an existing structure. After all, if the old database didn't have any problems, you wouldn't be building a new one.
Two types of databases are typically analyzed during this part of the database design process: paper-based databases and legacy databases. In some cases, an organization uses either one or the other; sometimes it uses both. Although you use fundamentally the same analysis process for both types of databases, there are some minor differences in the approach you will use to analyze each type of database. These differences have more to do with the databases themselves than with the overall analysis process. Both approaches are seamlessly incorporated into the analysis process presented in this book.
Data that is literally collected, stored, and maintained on paper is known as a paper-based database. The paper used in this type of database appears in a variety of shapes, sizes, and configurations. Some of the more common formats include index cards, hand-written reports, and various types of preprinted forms. Anyone who has ever worked in an office for a business or organization is very familiar with this type of database.
Analyzing this type of database can be a daunting task. One of the most immediate problems is finding someone who completely understands how the database works so you can learn its use and purpose. There are several problems with the paper-based database itself, especially in terms of the way data is collected and managed. Typically, this type of database contains inconsistent data, erroneous data, duplicate data, redundant data, incomplete entries, and data that should have been purged from the database long ago. Clearly, the only reason to analyze this type of database is to identify various items that will be incorporated into the new database. For example, individual pieces of data extracted from various sections of forms in the paper-based database will be turned into fields in the new database.
Any database that has been in existence and in use for five years or more is considered to be a legacy database. Mainframe databases typically fall into this category, as do older PC-based databases. "Legacy" is used as part of the name of this type of database for several reasons. First, it suggests that the database has been around for a long time, possibly longer than anyone can clearly remember. Second, the term "legacy" may mean that the individual who originally created the database has either shifted responsibilities within the organization or is working for someone else, and thus the database has become his or her legacy to the organization. Third, the term implies the disturbing possibility that no single individual completely understands the database structure or how it is implemented in the RDBMS software program.
Mainframe legacy databases present some special problems in the analysis process. One of the problems is that a number of older mainframe databases are based on hierarchical or network database models. If neither you nor the staff has a firm understanding of these models, it will take some time to decipher the structure of the database. In this case, it is very helpful to make printouts of the data in each of the database structures.
Even if a legacy database is based on the relational model, that doesn't necessarily mean that the structure is sound. Unfortunately, sometimes the people who created these databases didn't completely understand the concept of a relational database. (After you have read this book, you won't fall into that group.) As a result, many of the older database structures are improperly or inefficiently designed.
Improperly or inefficiently designed database structures are found on PC-based legacy databases as well. A very large number of PC-based databases were originally designed and implemented in dBase II and dBase III, which were nonrelational database management systems. As a result, the database structures implemented within these systems could not take advantage of the benefits provided by the relational model; for example, many of the structures contain duplicate fields and store redundant data.
Analyzing a legacy database is somewhat easier than analyzing a paper-based database because a legacy database is typically more organized and structured than a paper-based database, the structures within the database are explicitly defined, and usually the company or organization uses an application program to interact with the data in the database. (The application program can reveal a lot of information about the data structures and the tasks performed against the data in the database.) The time it will take to perform the analysis properly will depend to some degree on the platform (mainframe or PC) and the RDBMS used to implement the database.
The key point to remember when analyzing either a paper-based or a legacy database is to proceed patiently and methodically through the process in order to ensure a thorough and accurate analysis.
There are three steps in the analysis process: reviewing the way data is collected, reviewing the manner in which information is presented, and conducting interviews with users and management.
As you conduct the first two steps in this process, it will be necessary for you to speak to various people in the organization. Be sure your conversations with them are related purely to the reviews you're conducting. You'll have the opportunity to ask them other in-depth questions later. Keep in mind that these reviews are an integral part of your preparation for the interviews that will follow. Indeed, the reviews help to determine the types of questions you will need to ask in subsequent interviews.
The first step in the analysis process involves reviewing the ways in which data is collected. This includes everything from index cards and hand-written lists to preprinted forms and data-entry screens (such as those used in a database software program).
Begin this step by reviewing all paper-based items. Find out what types of paper documents are being used to record data, and then gather a single sample of each type. Assemble these samples together in a folder for use later in the design process. As an example, say that supplier data is collected on index cards. Go through each of the index cards until you find one with an entry that is as complete as possible. When you've found an appropriate sample, make a copy of it and place the copy in your stack of samples. Proceed through this process for each type of paper being used. Figure 6-1 shows examples of paper currently used to collect data.

Next review the computer software programs currently being used to collect data. The objective here is to gather a set of sample screen shots that represent how the programs are used. A word of caution: many people have discovered unique and ingenious ways to use common programs, such as word processors and spreadsheets, as a way to collect and manage data. Make sure you speak with someone who is familiar with the way the computers are being used within the organization, and discover which programs are used to manage the organization's data.

As you review how each program is being used to collect data, find a screen that best represents how the program is used. You're looking for screens like those shown in Figure 6-2. The first screen is typical of those found in database programs, and the second screen is typical of those found in spreadsheet programs. When you've found an appropriate sample, create a screen shot (use [ALT]-[PRTSC] or a screen-capture program), paste it into a document in your word processing program, and then print the document. You'll find that you will want to have several samples for each program you review. Repeat this procedure for each program.
Once you have all the appropriate screen shots gathered together, assemble them in a folder for use later in the design process. Make sure you clearly mark the folder containing the samples of paper and the folder containing the screen shots.
The second step in the analysis process is to review any methods currently used to present information needed by the organization. This includes all hand-written documents, computer printouts, and on-screen presentations. The most common method of presenting information is by means of a report. A report is any hand-written, typed, or computer-generated document used to arrange and present data in such a way that it is meaningful to the person or people viewing it. Thus the report transforms the data into information!
Another method of presenting information is through on-screen presentations, also known as "slide shows." These presentations are typically used to present a variety of information by means of a computer screen or overhead projector; such presentations are generally created with programs such as Microsoft PowerPoint or Harvard Graphics.
Begin this step by reviewing all the reports generated from the database, regardless of whether they are produced by hand or generated by the computer. Identify all of the reports currently being used, gather a sample of each one, and assemble each one in a separate folder as you did with the items in the previous step. Overall, this task is easier to perform in this step than it was in the previous step because people are typically more familiar with the reports their organization uses. Usually copies of the reports are readily available, and most reports can be reprinted if necessary. Figure 6-3 shows an example of a hand-written report and a computer-generated report currently used by an organization.

The final part of this step is to review any on-screen presentations that use or incorporate the data in the database. It's unnecessary to review every presentation, but you do need to review those that have a direct bearing on the data in the database. For example, you don't need to review a presentation on the features of the organization's new product, but you do need to review a presentation on year-to-date sales statistics.
Once you've identified which presentations you need to review, go through each one carefully and make screen shots of the slides that use or incorporate data from the database. Then gather the screen shots together and assemble them in a folder for later use. (Write the name of the presentation on the folder; you may need to refer to it again at a later time.) Follow this procedure separately for each presentation. You want to make sure you don't accidentally combine two or more presentations together, because this mistake will inevitably lead to mass confusion and result in one huge mess!
Figure 6-4 shows an example of the type of slides you're looking for within a presentation.
Reviewing a presentation is difficult in some cases, and deciding whether or not a slide should be included as a sample is purely a discretionary decision. Therefore, work closely with the person most familiar with the presentation to ensure that you include all appropriate slides in the samples.

Now that you have a general idea of how the organization collects and presents its data, it's time to interview users and management to determine how the organization uses its data. Interviews are useful in the analysis phase for the following reasons:
They provide details about the samples you assembled in reviewing how data is collected and how information is presented. . During the reviews, the discussions you had with users and management were solely meant to identify in general terms how data used by the organization is collected and presented. During the interview phase you can ask specific questions about the samples you assembled during those reviews. You can clarify any aspects of a specific sample that you consider to be vague or ambiguous.
They provide information on the way the organization uses its data. . By conducting interviews you will learn how the users work with the data on a daily basis and how management uses information based on that data to manage the affairs of the organization.
They are instrumental in defining preliminary field and table structures. . Initial or "first cut" field and table structures can be identified based on the responses provided by users and management during this round of interviews.
They help to define future information requirements. . Discussions with users and management regarding the organization's future growth can reveal new information requirements that must be supported by the database.
Note
Throughout the remainder of the book, the term management is used to refer to the person or persons controlling or directing an organization.
Note
The following techniques are used for both user interviews and management interviews. The only differences between the two sets of interviews lie in the subject matter and the content of the questions.
Conducting interviews is a two-part process: the first part involves speaking with users, and the second part involves speaking with management. You'll speak to the users first because they represent the "front lines" of the organization. They have the clearest picture of the details connected with the day-to-day operations of the organization. Also the information you gather from the users should help you to understand the answers you receive from management.
You'll use both open-ended and closed questions throughout the interviews, alternating between each type as the interview progresses. The open-ended questions are used to focus on specific subjects; the closed questions are used to obtain specific details on a certain subject. At the beginning of the interview, for example, start with a few open-ended questions in order to establish some general subjects for discussion, then select a subject and ask more specific (closed) questions relating to that subject. For example, start with an open-ended question such as the following:
"How would you define the work that you do on a daily basis?"
This type of question usually elicits a response of three or more sentences. It's perfectly acceptable if you receive a long, descriptive response because it's easier to work with than one that is terse. To illustrate this point, assume you received the following response to the previous question:
"As an account representative, I'm responsible for ten clients. Each of my clients makes an appointment to come into the showroom to view the merchandise we have to offer for the current season. Part of my job is to answer any questions they have about our merchandise and make recommendations regarding the most popular items. Once they make a decision on the merchandise they'd like to purchase, I write up a sales order for the client. Then, I give the sales order to my assistant, who promptly fills the order and sends it to the client."
This is a very good response. The participant not only answered your question; he provided you with the opportunity to begin asking follow-up questions. The response also suggests several subjects that you can discuss later in the interview.
Note
When you receive a terse response (such as "I fill out customer sales orders"), you'll have to ask even more questions to obtain the information you need from the participant. Yet this type of response may indicate that a participant is just nervous or uncomfortable. In this case, you could put him at ease by discussing an unrelated topic for a few moments, or by allowing him to select a more familiar or comfortable subject.
As you ask each open-ended question, identify any subjects suggested within the response to the question. You can identify subjects by looking for nouns within the sentences that make up the response. Subjects are always represented by nouns and identify an object (such as a person, place, or thing) or an event (something that occurs at a given point in time). There are some nouns, however, that represent a characteristic of an object or event; you don't need to concern yourself with these just yet. Therefore, make sure you only look for nouns that specifically represent an object or event. To ensure that you account for every subject you need to discuss, mark the nouns with a double-underline as you identify them; for example,
"As an account representative, I'm responsible for ten clients."
After you've identified all of the appropriate nouns within the response, list them on a sheet of paper; this is your list of subjects. You'll add more subjects to the list as you continue to work through the design process. This list serves two purposes: you'll use it to discuss the subjects as the interview progresses, and you'll use it later in the design process to help define tables.
The entire procedure just described is referred to as the subject identification technique throughout the remainder of the book. It is a very useful tool because it helps you identify subjects that need to be addressed by the database.
Returning to the example, say you underlined the appropriate nouns within this response:
"As an account representative, I'm responsible for ten clients. Each of my clients makes an appointment to come into the showroom to view the merchandise we have to offer for the current season. Part of my job is to answer any questions they have about our merchandise and make recommendations regarding the most popular items. Once they make a decision on the merchandise they'd like to purchase, I write up a sales order for the client. Then, I give the sales order to my assistant, who promptly fills the order and sends it to the client."
Based on this response, we can produce the following list of subjects:
| Account representatives | Merchandise |
| Appointments | Sales orders |
| Assistant | Seasons |
| Clients | Showroom |
| Items |
You can use this list of subjects to come up with further questions during the interview.
To verify that the nouns you've underlined are genuine subjects, review the way they're used in the response. For example, consider the first two subjects on this list. The first subject, "account representatives," is suggested in the first sentence. Because of the way this noun is used in the sentence, you can assume it represents an object (person, place, or thing), which in this case is an individual or group of individuals collectively known as "account representatives." The second subject in the list, "appointments," is suggested in the second sentence. You can assume this noun represents an event (something that occurs at a given point in time) because of the way it is used in the sentence.
Once you've identified the subjects suggested within the response, pick a particular subject and begin to ask follow-up questions related to it. The purpose of this line of questioning is to obtain as much detailed information as possible about the subject you've selected. Therefore, make your follow-up questions more specific as you progress through this part of the discussion. The nature of your follow-up questions will depend on the responses you receive from the participant. Based on our sample response, for example, you can continue to ask more specific questions regarding sales orders or you could begin a new line of questioning regarding clients. However, say you asked the following question to learn more about sales orders:
Let's discuss sales orders for a moment. What does it take to complete a sales order for a client?
Note that this question begins with a statement directing the interview participant to focus on a particular subject. Once you've selected a specific subject to discuss, always use a statement similar to the one in the example as a preface to your first question about the subject. The statement will guide the discussion. Also note that although the question itself is open-ended, it prompts the participant for details regarding the subject you've chosen (sales orders) and allows you to establish the focus of the participant's responses.
Now assume that the participant gave the following reply:
W"ell, I enter all the client information first, such as the client's name, address, and phone number. Then I enter the items the client wants to purchase. After I've entered all the items, I tally up the totals and I'm done. Oh, I forgot to mention: I enter the client's fax number and shipping address—if they have one."
Start your analysis of this response by using the subject identification technique to determine whether there are any further subjects suggested within the response. If so, add them to your list of subjects. Remember: list only those nouns that represent an object or event.
Once you've finished, begin looking for any details regarding the subject under discussion. Your objective here is to obtain as many facts about the subject as possible. Now you're interested in the nouns that represent characteristics of the subject—they describe a particular aspect of the subject. These nouns are easy to identify within a sentence because they are typically in singular form ("phone number," "address"). In contrast, the noun used to identify the subject is usually in possessive form ("the client's phone number," "the company's address").
As you identify nouns that represent characteristics, mark each one with a single underline. Try to account for as many characteristics of the subject as possible. Here's an example of a user response:
"Well, I enter all the client information first, such as the client's name, address, and phone number."
As you identify the appropriate nouns within the response, list them on a sheet of paper. This becomes your list of characteristics. You'll add more characteristics to the list as you work through the design process, and later you'll use this list when you are determining the fields for the database. Use a separate sheet of paper for the list of characteristics. Do not list the subjects and characteristics on the same sheet! (The reason for keeping them on different lists will become clear when you begin to define tables for the database inChapter 7.)
Throughout the remainder of the book, we will refer to this procedure as the characteristic identification technique. It's a very useful tool because it helps you determine the fields that need to be defined in the database.
To continue the example, say that you underlined the appropriate nouns within this response:
"Well, I enter all the client information first, such as the client's name, address, and phone number. Then I enter the items the client wants to purchase. After I've entered all the items, I tally up the totals and I'm done. Oh, I forgot to mention that I enter the client's fax number and shipping address— if they have one."
You could then produce the following list (shown in alphabetical order):
| Address | Phone number |
| Fax number | Shipping address |
| Name | Totals |
You now have a list of characteristics for the subject under discussion. These characteristics will subsequently become fields in the database.
Verify that the nouns you've marked with a single underline are genuine characteristics by reviewing the way they're used in the response. For example, consider the two characteristics on this list. The first characteristic, "names," is suggested in the first sentence of the response. By the way the noun is used in the sentence, you can assume that it describes some aspect of the subject Client. The characteristic "Shipping address" is suggested in the last sentence of the response. You can assume this noun also represents some aspect of the subject Client by the way it is used in that sentence.
After you've finished discussing a particular subject, move on to the next subject on your subjects list and begin the same pattern of questioning. Start with open-ended questions, identify the subjects suggested in the responses, ask more specific questions as the discussion progresses, and identify as many of the subject's characteristics as possible. Continue this process in an orderly manner until you've discussed every subject on your list.
Note
Although the subject identification technique and characteristic identification technique are very useful, they do take a short amount of time to learn. With some practice, however, they become intuitive. You'll use these techniques during your interviews with users and management, and later when you're identifying fields and tables for the initial database structure.
The first part of the interview process involves conducting user interviews. These interviews will focus on the following four issues:
the types of data users are currently using;
how users are currently using their data;
the data-collection samples, report samples, and on-screen presentation samples you assembled during the first two steps of the analysis; and
the types of information users need in conjunction with their daily work.
You can usually discuss the first two issues at the same time if you carefully phrase your questions at the beginning of the interview. Your objective for this part of the interview is to identify the types of data the users are currently using and how they use that data in support of the work they do. You'll use this information later in the design process to help define field and table structures. Use the data-collection and data representation samples to help formulate questions about data. (However, don't discuss the samples just yet; they should be treated as a separate issue.) During this discussion, you'll start with open-ended questions, identify subjects within the responses, and then use specific follow-up questions to identify the characteristics of each subject.
As you begin the interview, ask each participant about the work he or she performs on a daily basis. After the participant has provided an overall description of the work he does, ask him to explain his job in more detail. Have the participant "walk you through" the job he performs on a daily basis.
Following is a dialog that is typical of what occurs during this part of the interview:
| INTERVIEWER: | What kind of work do you do on a day-to-day basis? |
| PARTICIPANT: | I accept land-use applications that are submitted by various people, log them in, and set a hearing date with the Hearing Examiner. I also assist applicants if they have any questions regarding a specific application. |
| INTERVIEWER: | Let's talk about the applications for a moment. What type of facts are associated with an application? |
| PARTICIPANT: | There's quite a number, actually. There are facts concerning the type and name of the application, its designation and address, and its location. |
| INTERVIEWER: | Tell me about the facts concerning the application's type and name. |
| PARTICIPANT: | There are four things we record: the type of application, the name of the subdivision, the purpose of the project, and the description of the project. |
Note how the interviewer starts the discussion with an open-ended question. After the participant responds, the interviewer uses the subject identification technique to identify subjects within the response. The interviewer then chooses a particular subject and uses another open-ended question to focus the participant on that subject. Because the participant's next response was stated in general terms, the interviewer uses the subject identification technique once again and selects yet another subject. This time, however, the interviewer focuses on a particular aspect of the subject and uses a more specific follow-up question to elicit a detailed response from the participant.
The interviewer can continue to narrow the focus of questions as the discussion progresses. As the participant responds to each question, the interviewer continues to use the characteristic identification technique to identify characteristics of the subject that appear in the response. After all of the characteristics have been identified, the interviewer then moves on to the next subject and begins the entire process again. This procedure will be repeated until all the subjects have been discussed. You'll use exactly the same procedure when you act as interviewer.
The next issue you'll discuss concerns the data-collection samples, report samples, and on-screen presentation samples you assembled earlier in the analysis process. Your objectives during this discussion are to identify how the objects represented by the samples are used, to clarify any aspects of the samples you don't understand, and to assign a description to each sample.
Now that you have an idea of the types of data the participants use as well as how they use those types of data, you'll find it easy to talk to participants about the samples. Start the conversation by selecting a sample to discuss, and then begin asking questions about it. Say you've chosen to work with the data-collection sample shown in Figure 6-5.
Before you ask your first question, review your notes from the discussions held at the beginning of the interview to determine whether any of what you have already discussed is relevant to the sample you're about to discuss. For example, in one of the previous discussions, a participant indicated that part of his job is to keep track of all the organization's customers. Using that statement as a starting point, you could ask him how he uses this data-collection sample to perform that task. You could ask this question, for instance:

"You mentioned in a previous discussion that you keep track of all the customers. How does this screen help you to carry out that task?"
This is a well-phrased question. It is prefaced with a statement that focuses on a particular subject, and the question itself then brings the participant's attention to the sample. The question is open enough to elicit a clear and complete response.
To continue this example, say the participant responds with the following reply:
"This screen allows me to enter new customers, as well as modify and maintain all the information we have on existing customers."
If this reply answers the question to your complete satisfaction, you'll use it as the basis for describing the sample. On the other hand, if this reply does not completely answer the question, continue with the appropriate line of questioning until the participant clearly identifies the purpose and use of the sample. It's necessary for each sample to have a description because you'll use the samples again later in the design process.
The description should be succinct yet give a clear indication of the purpose of the sample and how it is used. Write the description on a slip of paper and attach it to the sample. The following sentence is an example of a description you might use for the sample in Figure 6-5.
"This screen is used to collect and maintain all customer data."
It's necessary for you to understand the sample as completely as possible so that you can write a clear and concise description. If there are any aspects of a given sample you don't understand, ask the participant to clarify them for you. For example, assume you're working with the report sample shown in Figure 6-6.
If you don't know what the abbreviation "SRP" represents, you'll have to ask someone to tell you what it means. You could pose a simple question:
"What do the letters `SRP' stand for in the `Current Product Inventory' report?"

Such a direct approach usually elicits the clear and definitive response you seek.
As you compose descriptions for each of the samples, you'll find that writing a description of a complex sample can be difficult. A sample is complex if it represents more than one subject. The sample in Figure 6-6, for example, only covers one subject: Products. The sample in Figure 6-7, however, covers at least three subjects: Doctor Services, Nursing Services, and Patients. With a complex sample you will often have to do more work to determine the sample's purpose and use. In some cases you'll have to use the subject identification technique to determine what subjects are represented within the sample. Once the subjects are identified, it's easier to clarify the function or functions of the sample. You can then compose a description that gives a clear picture of the sample's purpose.
For example, say you're working with the report sample shown in Figure 6-7 and you have questions regarding the nursing services. You wonder whether the organization is using this report as an indirect means of maintaining a current list of nursing services. At the same time, you want to avoid asking a participant a question whose answer is simply yes or no. You'd rather use a question that elicits a more informative response. You could use the following open-ended question to begin the discussion on this sample:
"What nursing services do you provide besides those listed in this sample?"
By using this type of question, you give the participant an opportunity to give a detailed response. Furthermore, you give yourself the opportunity to ask follow-up questions as warranted by the participant's reply. To continue the example, say you received the following answer:

"We provide various specialized services for the more complex patient. You only see the general services on this report. However, I can show you a complete list of our services that Katherine maintains on her computer."
If this reply clarifies the point in question and you now understand the purpose of this report sample, you can continue with the process of writing the description of the sample. If the point is still unclear, you can continue with follow-up questions until everything is explained to your satisfaction.
The final issue you'll discuss with users concerns their information requirements. The objectives of this discussion are to determine whether individual users receive information based on data they don't directly control or maintain, to determine what types of additional information they need, and to determine what types of information they can foresee themselves needing in the future. The information you gather during this discussion will be used later in the design process to help define and verify field and table structures. You can also use this information as yet another way of determining whether anything was accidentally overlooked during any of the previous discussions.
Users typically receive the information they use through a variety of reports. Therefore, the best way to begin this discussion is by reviewing the report samples. This time around, though, you're not so concerned with how the report is used as you are with the data the reports are based on. It's quite common that information on some of the reports a user receives is based on data he does not personally create and maintain. If such is the case, you must determine the origin of that data so that you can identify all the data used by a user, whether he uses it directly or indirectly.
Start the conversation by first selecting a report from the report samples. Then work with one of the participants to determine what data is used to produce the report. Ask him if he creates and maintains the data on which the report is based. If the answer is yes, you can move on to the next sample. But if the answer is no, then you need to identify the origin of the data. The following example illustrates this process.
Say you have an assistant by the name of Kendra who is beginning a discussion with a participant named Gregory on the report sample shown in Figure 6-8. As Kendra begins the conversation, Gregory mentions that he works in the telemarketing department. When Kendra first asks about the sample report, Gregory indicates that he receives it every Monday morning. So Kendra asks him the following question:

"Do you provide the data that's used to generate this report?"
Her next course of action depends on the Gregory's response to this question. If his answer is yes, she can move on to the next sample. It's a good idea, however, for her to ask a follow-up question to double-check that his answer is true. She can use a question such as the following:
"Do you personally enter and maintain this data on a daily basis?"
If his answer is still yes, she can definitely move on to the next sample.
On the other hand, if Gregory's answer to the original question is no, Kendra will need to ask a few follow-up questions. First, she will ask him whether he contributes any data to the report. If he does, she'll determine what data he specifically submits. Then she'll ask whether or not he knows the source of the remaining data.
To continue the example, say Gregory's reply to the original question is no and that the following dialog takes place after his response:
| KENDRA: | Can you tell me, then, if there is any data that you contribute to the report at all? |
| GREGORY: | I do supply the customer's name and phone number. |
| KENDRA: | Then you don't supply the Customer Type or the Last Purchase Date, is that correct? |
| GREGORY: | Yes, that's correct. |
| KENDRA: | Can you tell me who provides the Customer Type and the Last Purchase Date? |
| GREGORY: | I'm not really sure, but… |
| KENDRA: | Do you have an idea of where these items come from? |
| GREGORY: | As a matter of fact, I do. They come from the sales department. |
| KENDRA: | That sounds good to me. I'll make a note of that on this sample, and then we can move on to the next one. |
Note that as the dialog begins, Kendra first tries to determine whether Gregory submits any data at all to the report. When Gregory reveals that he contributes two of the items for the report, she then poses a follow-up question to verify that he is not submitting any of the other data. Finally, she tries to identify the source of the remaining data by asking Gregory if he knows where the data originates. In this case, it takes only two well-phrased questions to find the answer. If Gregory could not answer the last two questions, Kendra would need to continue her investigation with other participants.
If your discussion progresses in the same manner as that of the preceding dialog, you're sure to obtain all the information you need about your report samples. Remember: follow-up questions are a crucial part of the conversation. You must phrase your questions properly to elicit the types of responses you need from the participants.
The next subject of discussion is additional information requirements. The objective here is to determine whether the users require additional information that is not being delivered to them currently. If this is the case, then you must identify what it is. If necessary, you'll define new data structures to support this extra information later in the design process.
Start this conversation by directing the participants to review the reports they currently receive. Ask them whether there is any other information they would like to see in any of the reports. Next direct them to discuss the additional information, what reports it pertains to, and the reason they believe it is necessary. Then determine whether the new information represents new subjects or new characteristics. If it does, identify each new item and add it to the appropriate list. Finally, review the comments the participants have made and determine whether there are any further issues you need to discuss with them in regards to the reports.
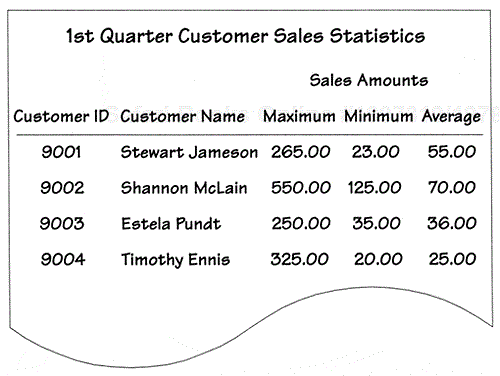
To illustrate this process, say you're beginning this discussion and you've just asked the participants to review the report samples they currently use. One of the participants is reviewing the sample report shown in Figure 6-9.
Now instruct this particular participant to note any additional infor-mation she would like to see on the reports as well as to give a brief statement indicating why the information is necessary. At this point, it doesn't really matter exactly how the notations are made so long as they are clear and attached to the report in an obvious manner. In this case, the participant who was reviewing the sample report shown in Figure 6-9 decided to use large sticky notes as a means of documenting her comments. On each sticky note she has specified a new field she'd like to include on the report along with the reason for its inclusion. She has also suggested a possible location for the field by writing its name on the report itself. Figure 6-10 shows the sample report with her comments.

Next determine whether any new subjects or new characteristics are represented in the additional information. Examine each report and apply the subject identification technique and the characteristic identification technique to the comments attached to the report. We can apply these techniques to the first comment in Figure 6-10:
"Can we include the Vendor name? It would make it easier to identify a specific product."
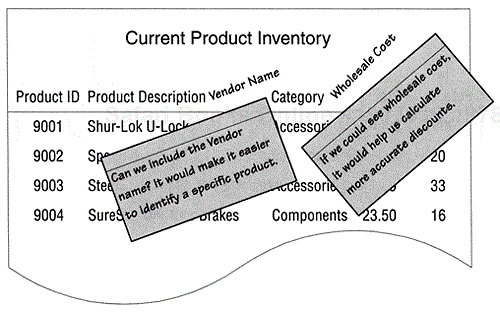
Both a subject and a characteristic have been identified. (Note that the subject and characteristic aren't directly related: "Vendor name" is a characteristic of a "Vendor," not of a "product." There's no problem here, but you should be aware that this apparent mismatch of subjects and characteristics is typical. This will be addressed later in the design process.) Check your subjects list and characteristics list to determine whether you've already accounted for these items. If you have, move on to the next comment and repeat this procedure.
If this process turns up a new subject, add it to your list of subjects and then identify as many of its characteristics as possible. When you're finished, add these items to your list of characteristics, move on to the next comment, and repeat the entire procedure. In many instances, however, you'll only identify new characteristics. Don't be alarmed. People often want to add items to a report that are characteristics of subjects that are already represented by the information on the report.
Finally, reexamine each report and determine if you have any questions or concerns about the notes participants have made. For instance, you may question the rationale behind one participant's belief that specific fields are necessary on a given report. Or you might wonder why another participant wants to exclude certain fields from one of his reports. You definitely want to make sure that the fields he wants to exclude are truly unnecessary and that their removal will not adversely affect the information the report provides to other people. In either case, the inclusion or exclusion of fields will affect the final database structure.
If a report has one or more remarks that are cause for concern, review it with the appropriate participant and settle as many of the issues as you can. You can usually resolve all your concerns with a few simple questions, but in some cases the resolution to certain issues will not become apparent until later in the design process. For example, there are instances in which some fields appear on two or more reports. It's difficult to determine if they are being unnecessarily duplicated until you begin to define the field and table structures. When you encounter an issue that is difficult to resolve at the present time, make a note of it and put the report aside for later review.
The last subject of discussion concerns future information requirements. Your objective here is to identify any information that the participants believe will be necessary for them to receive as the organization grows. Once such future information requirements are identified, you can ensure that the data structures needed to support that information are defined in the database.
First you'll need to make sure that every participant has some idea of how the organization is growing and in what direction it is growing. The nature of the organization's growth will determine what new information participants will require. If several people are unacquainted with these issues, you'll need to obtain this information from management and then relay it to the participants prior to the discussion. Once everyone is familiar with these matters, you can begin the conversation.
Start the discussion by directing the participants to think about the future growth of the organization and how it may affect the work they do on a daily basis. Keep in mind that some of them are going to have a difficult time envisioning this scenario. When this happens, use the following types of questions as a means of helping them focus their thoughts:
"How will the organization's growth affect the amount of information you'll need to do your job?"
"Do you think you'll need additional types of information to carry out your duties effectively as the organization grows?"
"How will the growth of the organization increase the time you spend on your day-to-day tasks?"
"Can you predict what types (categories, not specific items) of new information you'll need in order to carry out your duties as the organization expands?"
"Do you anticipate a need for new information if your duties are increased because of the organization's growth?"
Keep in mind that most of the participants' answers will be based on speculation. There's no accurate way for them to predict what types of information they'll really need until the organization's growth occurs. However, if you can anticipate their hypothetical information requirements, you can prepare for them by defining the necessary data structures in advance.
As the participants make their responses, use the subject identification technique to identify brand new subjects, and then add them to your list of subjects. Then use the characteristic identification technique to uncover any new details concerning existing or new subjects, and add them to your list of characteristics.
To help participants visualize the types of information they may need in the future, it is useful to sketch ideas for new reports or data entry forms, identifying any new subjects and characteristics that need to be addressed in the database structure. If you create several rough drawings of sample reports, be sure to assemble them in a separate, clearly marked folder. Then code each revision so that you can compare it with earlier revisions. Figure 6-11 shows an example of a preliminary design for a future report.
Continue the conversation with users until you're satisfied that you've accounted for as many of the participants' future information requirements as possible. When you've completed the discussion, you're ready to conduct interviews with management.
Note
All of the techniques you learned during the user interviews section can be used in the management interviews section as well. The following section is somewhat shorter and more concise, because I have assumed that by now you understand how to use the techniques described earlier.
The second part of the interview process involves interviewing management personnel. These interviews will focus on the following issues:
the types of information managers currently receive,
the types of additional information they need to receive,
the types of information they foresee themselves needing, and
their perception of the business's overall information requirements.
Your objectives during the first part of this interview are to identify the information that management routinely receives and to determine whether they currently receive any reports that are not represented in your group of report samples.
As you begin the interview, ask each participant about the work he performs and the responsibilities associated with his position. Because most people in management positions tend to have a number of things on their minds, your questions will help them focus their attention on the matters at hand. Their answers will give you some idea of how they might use the information on the reports they receive and provide you with a perspective of their need for this information.
Next ask each participant if he uses any of the reports in your collection of report samples. If the participant doesn't use any of the reports, proceed with the next step. But if the participant does, examine each report, and ask him to identify any other subjects on the report that might have been previously overlooked. Use the subject identification technique as necessary to aid with this process. If the manager identifies a new subject, add it to your list of subjects and use the characteristic identification technique to uncover the subject's characteristics. Then add these to your list of characteristics. Repeat this procedure for each sample report.
Continue the discussion by asking each participant whether he receives any reports that are not represented in the group of report samples. If the answer is yes, obtain a sample of each "new" report. Next review each new report with the participant. Use the subject identification technique and the characteristic identification technique to identify the subjects represented by each new report and their associated characteristics. Then add the subjects and characteristics to their respective lists. Finally, attach a description to each new report and add the new report to your collection of report samples. Repeat this procedure until you've accounted for every new report.
The next subject of discussion concerns management's need for additional information. Your objective is to determine whether they require some supplemental information that is currently missing from the reports they receive. If you conclude that this is the case, you must identify that additional information. Later in the design process, you'll define new data structures (if necessary) to support this extra information. However, if no additional information is required, move on to the next part of the interview.
You'll use the same techniques for this discussion that you used for this segment of the user interviews. Here are the steps you'll follow:
Review the report samples with the participants once again, and ask them if there is any additional information they would like to include in any of the reports.
Have them note the additional information—including the reasons why they believe it's necessary—on the appropriate reports. Remember that it doesn't matter how these notations are made so long as they are clear, noticeable, and are attached to the applicable report.
Determine if the information represents new subjects or new characteristics. If it does, identify each new item and add it to the appropriate list.
Review the reports and discuss any concerns you have about them with the participants. Once your concerns are resolved, this process is complete.
Future information requirements is the next subject of discussion. Your objective during this discussion is to determine what information management foresees itself needing in the future. Once these needs have been identified, you can ensure that the data structures are in place to support the information as the need for it arises.
As you begin the discussion, have the participants take into consideration how the organization is growing and in what direction it's growing. Then ask them what effect that growth will have on the information they require to make sound decisions and what effect it will have on the way they guide or direct the organization. Remember that their answers are going to be based on speculation, as was the case with similar questions you asked users. Until the organization's growth occurs, there's no way for management to predict their future needs accurately. However, it's always a good idea to plan for the future as much as possible.
As the participants respond, use the subject identification technique and characteristic identification technique to identify items within their replies. Then add each new item to the appropriate list.
If they have ideas about new reports they may need, make sketches of them. Then take each new report and determine what subjects and characteristics the information on the report represents. When you've identified all the items, add them to the appropriate list. Then assemble these new reports in a clearly marked folder.
When you've accounted for as many of their future requirements as possible, you're ready to move on to the last subject.
The last topic of discussion concerns the organization's overall information requirements. In the opinion of management, what generic class of information does the organization need? In pursuing this question, you're trying to discover whether there is any data that the organization needs to maintain that has not been previously discussed, either in the user interviews or the management interviews. If you determine that there is such data, you'll need to account for it in the database structure.
To help participants answer this question, review with them both the group of sample reports and the group of new reports that you've gathered throughout the analysis and interview processes. Ask participants to consider the information provided by the reports and how that information will be used. (They'll have to have made assumptions that led to suggesting the new reports.) Next ask participants to determine whether there is any information that would be useful or valuable to the organization but that is not currently being received by anyone within the organization. If such information is needed, go through the normal process of identifying the information and the subjects and characteristics it represents. Sketch a sample of a new report that will contain the new information and add that sample to the group of new report samples.
For example, assume that one of the participants has identified a need for demographic information; he believes that it would help the organization identify a more specific target market for its product. But currently there is no report that provides this information. To clearly identify the information he needs, work with this participant to create a sketch of a report that will present this information. Then use the appropriate techniques to identify and note the subjects and characteristics represented by the report. Finally, add the new report to the folder of new reports. Now the data structures necessary to support the new information can be defined in the database.
Continue to repeat this procedure until participants can no longer identify any further information that could be of use or of value to the organization. Once you are reasonably confident that you have accounted for all the information the organization needs or will need, you may suspend the interview process and begin the process of compiling the preliminary field list.
In the next step, aim toward making the preliminary field list complete. But keep in mind that even though you and the participants may believe you've accounted for all the information that the organization could possibly use, you may have to revisit this process. It's common that new information continues to be identified as the database design process unfolds.
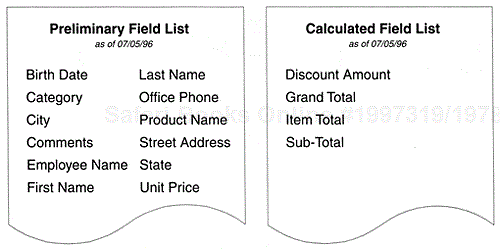
Now that you have completed your analysis of the current database and the interviews with users and management, you can create a preliminary field list. This list represents the fundamental data requirements of the organization and constitutes the core set of fields that will be defined in the database. You'll create the preliminary field list using the following two-step process:
Review and refine the list of characteristics you have compiled.
Determine whether there are any characteristics in the data--collection samples, report samples, and on-screen presentation samples that need to be added to the preliminary field list.
The first step is to review and refine the list of characteristics you compiled throughout the analysis and interview process. As you'll remember from its definition inChapter 3, a field represents a characteristic of a particular subject. Therefore, each item on the list of characteristics should become a field. But before you can define characteristics as fields, first you need to review the list to identify and remove duplicate characteristics.
As you conducted the interviews, you used the characteristic identification technique to identify characteristics in each participant's responses. You then collected these characteristics on a list as the interview process continued. There were probably times when you mistakenly added the same characteristic to the list more than once or unknowingly added an item with a different name but representing the same characteristic as one already listed. Refine the list using the following procedure.
Look for items in the list with the same name. When you find one or more duplicates, determine whether the duplicates represent the same characteristic. If they do, remove the duplicates from the list. If they don't, determine what each occurrence of the item represents. In many instances, you'll find that each instance represents a characteristic of a different subject. If this is the case, rename each occurrence of the item to reflect how it relates to the appropriate subject.
For example, say the item "Name" appears three times on your list of characteristics. Because your current objective is to eliminate duplicate characteristics, your first inclination will be to remove the duplicates. But before you do so, determine what subject each instance of "Name" represents. You can easily do this by reviewing your interview notes; this will help you remember when you added the item to the list and why it was added.
Now say that after careful examination, you discover that the first occurrence of "Name" represents a characteristic of the subject Clients, the second a characteristic of the subject Employees, and the third a characteristic of the subject Contacts. To resolve the duplication, rename each occurrence of "Name" to reflect its true meaning. You now have three new characteristics: "Client Name," "Employee Name," and "Contact Name."
As you review your list of characteristics, you'll find that there are instances similar to "Name" that need to addressed in the same manner. It's common to see one or more occurrences of items such as "Address," "City," "State," "Zip Code," and "Phone Number." These are referred to collectively as generic items. The main point to remember is that you'll need to rename each instance of a generic item to reflect its true relation to a subject, thus ensuring that you have as accurate a field list as possible.
Now look for items that have different names but the same meaning and remove all but one. There should be only a single occurrence of a particular characteristic. For example, say that "Product #," "Product No.," and "Product Number" appear on your list of characteristics. It's evident that these items all have the same meaning, and you only need one of them on your list. Choose the one that conveys the intended meaning clearly, completely, and unambiguously. Remove the remaining items from the list of characteristics. (In this case, the best choice is "Product Number.")
Finally, make sure that each item on your list represents a characteristic. It's easy to accidentally place items on the list that represent subjects. You can test each item by asking yourself questions like these:
"Can this word be used to describe something?"
"Does this word represent a component or detail or piece of something in particular?"
"Does this word represent a collection of things?"
"Does this word represent something that can be broken down into smaller pieces?"
Depending on the item you're working with, some questions will be easier to answer than others. If you find that an item represents a subject rather than a characteristic, remove it from the list of characteristics and add it to the list of subjects. Be sure to identify the new subject's characteristics and add them to your list of characteristics.
For example, say "Item" appears on your list and you're not quite sure whether it represents a characteristic or a subject. Use the questions listed above to help you make a determination. For instance,
"Can `Item' be used to describe something?"
"Does `Item' represent a component or detail or piece of something in particular?"
You could make a case that "Item" helps to describe a "Sale" inasmuch as it identifies what a customer purchased. On the other hand, you could also say that "Item" isn't a characteristic because it doesn't represent a singular aspect of a "Sale." "Date Sold," for example, represents a singular characteristic of a "Sale." So leaving the quandary surrounding these questions unresolved, you go on to the next question.
"Does `Item' represent a collection of things?"
You can answer this question easily by looking at the plural form of the word, which in this case is "Items." If "Items" can be referred to as a collection, it is a subject. It's beginning to become clear that "Item" does represent a collection of some sort, and you can make a final determination by asking yourself the last question:
"Does "Items" represent something that can be broken down into smaller pieces?"
To answer this question, determine whether you can identify any characteristics for "Items." If so, then it definitely represents a subject and should be moved to the list of subjects. Also you'll need to identify its characteristics and add them to your list of characteristics.
Continue with this procedure until you've reviewed and refined the entire list of characteristics to your satisfaction. When you are through you have your first version of the preliminary field list. You'll add new items to it and refine it further during the next step.
The second step involves studying the data-collection samples, report samples, and on-screen presentation samples you gathered during the analysis of the current database. In this step, your objective is to determine whether there are any characteristics found on the data and report samples that need to be added to the preliminary field list.
To begin this step, highlight every characteristic you find on each sample. Then take each characteristic and determine whether it's already on the preliminary field list; if it's on the list, cross it out on the sample. Next look at the remaining characteristics and determine whether any of them has the same meaning as an existing field; if it does, cross it out on the sample. (Use the same procedure you used in the first step to make this determination.) Finally, if there are any highlighted characteristics left on the samples, add them to the Preliminary field list.
For example, say you're working with the data-collection sample shown in Figure 6-12. Highlight each characteristic you find on the sample, as shown in Figure 6-13. In some instances, you'll find duplicate characteristics. As you can see, both "Name" and "Phone No." appear twice on the sample. Because the duplicate has the same meaning as the original in each case, you can cross out the duplicates.
To continue with the example, say you've reviewed your preliminary field list and found that every characteristic on the sample is already on the preliminary field list with the exception of "Name" and "Phone No." Cross out the existing items on the sample to show that you have accounted for them. But before you add "Name" and "Phone No." to the preliminary field list, make sure that the names of these items prop erly describe their relation to the subject. In this case, the two remaining fields represent characteristics of a group of people known as "Contacts." Therefore, these characteristics are renamed and added to the list as "Contact Name" and "Contact Phone Number." Repeat this procedure for each sample you've gathered until you have gone through all the samples you have collected.


There's one final refinement you need to make to the preliminary field list before it can be considered complete: every "calculated field" must be removed and placed on a separate list. This new list becomes your calculated field list. A calculated field is one that stores the result of a mathematical calculation as its value. Calculated fields are listed separately because they are used in a specific manner later in the design process.
To build the calculated field list, look for any field in the preliminary field list that can be considered to be the result of a calculation. "Amount," "total," "sum," "average," "minimum," "maximum," and "count" are a few of the words typically used to name calculated fields. Common names for calculated fields include "Subtotal," "Average Age," "Discount Amount," and "Customer Count." As you identify each calculated field, remove it from the preliminary field list and place it on the calculated field list. When you've finished screening all the fields in the preliminary field list, you're then left with two complete new lists: the final version of the preliminary field list and the calculated field list.
Conduct brief interviews with users and management to review the items that appear on the preliminary field list and the calculated field list. The purpose of the interviews is to determine whether there are any fields that have been left out of either list. If everyone believes that the lists are complete, continue with the next step in the design process. Otherwise, identify the fields that are missing and add them to the appropriate list.
Be sure to conduct interviews at this juncture; the feedback participants provide is a means of verifying the fields on both lists. To prevent distress and frustration, let me warn you again to avoid becoming too invested in the idea that these lists are complete and final. At this point you still may not have identified every field that needs to be included in the database—inadvertently, you're almost sure to miss a few fields—but if you strive to make your lists as nearly complete as you can, the inevitable additions or deletions will be quick and easy to make.
You've already defined the mission statement and mission objectives for Mike's new database. Now it's time to perform an analysis, conduct interviews, and compile a preliminary field list.
First, analyze Mike's current database. As you already know, he keeps most of his data on paper. The only exception is the product inventory he maintains on a spreadsheet program. So first you'll need to gather a sample of each type of paper-based format Mike uses to collect data. You'll also need to get a screen shot or printout of the spreadsheet he uses to maintain the product inventory. Assemble these samples together in a folder for later use. For example, Figure 6-14 shows a sample of the index cards Mike uses to collect customer information and a screen shot from his spreadsheet program.
Next identify the methods Mike uses to present information. He currently uses a number of reports to present the information he and his staff need to conduct their day-to-day affairs. Most of the reports are produced on a typewriter; the remainder are generated from the computer with a word processing program. Gather samples of all the reports and place them in a folder for later use. Figure 6-15 shows a sample report that Mike creates on his typewriter.
Now you're ready to interview Mike's staff. Here are some points to remember as you're conducting the interviews:
Identify the types of data staff members are using and how the data is being used. Be sure to use the subject identification technique and the characteristic identification technique to help you analyze responses and formulate follow-up questions.
Review the data-collection, report, and on-screen presentation samples you gathered during the beginning of the analysis process. Determine how each sample is used, write an appropriate description, and attach the description to the sample.
Identify the staff members' information requirements. Determine what information they're currently using, what additional information they need (remember to use the samples.), and what kind of information they believe they'll need as the business grows.


During the interview, one of the employees wonders whether she can add a new field to the Supplier Phone List report. Your response? You hand her the report and ask her to attach a note indicating the name of the new field and a brief explanation of why she believes it's necessary. When she's finished, return the sample to the report samples folder. Figure 6-16 shows the report sample with the attached note.
The final interview you'll conduct is with Mike. Keep the following points in mind as you speak with him:
Identify the reports he currently receives; you need to know what kind of information he uses to make business decisions. If he receives any reports that are not represented in your group of report samples, obtain a sample of each report and add it to the group, updating the subject and characteristic lists as needed.
Review the group of report samples with him and determine whether he can identify any subjects or characteristics that have been overlooked by his staff. Use the appropriate techniques to identify these items and add any new items to the proper list.
Determine whether there is any additional information Mike needs to supplement the information he currently receives.
Determine what types of information Mike will need as the business grows.

As you and Mike discuss his future information needs, he indicates that there is some new information he'd like to receive once the business really gets rolling: he'd like to see total bike sales by manufacturer. He believes this information would help him determine which bikes should be consistently well stocked. Such a report does not currently exist, so have Mike sketch it out on a sheet of paper. Next, identify the subjects and characteristics represented on the report and add them to the appropriate list. Then add the new report to your group of report samples. Figure 6-17 shows the sketch of Mike's new report.


Your analysis is complete: you've interviewed Mike and his staff, you've gathered all the relevant samples, and you've created a list of subjects and a list of characteristics. A partial list of subjects and characteristics is shown in Figure 6-18. All you need to do now is to create your preliminary field list.
As you already know, you'll need to refine your list of characteristics before it can become your first version of the preliminary field list. So remove all duplicate characteristics, delete items that have different names but that refer to the same characteristics, and refine those items that have "generic" characteristic names. (Remember the problem with the characteristic called "Name"? If you find such instances, now is the time to resolve them.) Next review all your samples and determine whether they contain characteristics that do not currently appear on the preliminary field list. If you find any, add them to the list. When you're done, you have the first version of your preliminary field list.
Now you need to remove all the calculated fields from the preliminary field list. As you know, a calculated field is one that stores the result of a mathematical calculation as its value. Once you've removed all the calculated fields, placed them on their own new list, which becomes your calculated field list. Figure 6-19 shows a small portion of your final preliminary field list and your list of calculations.
Note
You may have noticed that each list includes a date in the title. It's a good idea to date your lists so that you retain a clear history of their development.
This chapter begins with a discussion of the reasons that an organization's current database should be analyzed. You learned that to make that analysis, there are specific questions and answers that will identify aspects of the current database. Armed with the answers you can design a database that best suits the organization's needs. Next, we briefly looked at the two types of databases commonly used by organizations: paper-based databases and legacy databases. We ended this discussion by identifying the three steps used in the analysis process: reviewing the way data is collected, reviewing of the way information is presented, and conducting interviews with the organization's staff.
The chapter continues with a discussion of the review process. You learned how to review the ways an organization collects its data and how to assemble a set of data-collection samples. Then you learned how to review the ways the organization presents information and saw how to assemble a set of report samples.
Next, we discussed the process used to conduct interviews, and we saw why interviews are useful in this stage of the design process. During this discussion you learned two techniques that are crucial to the success of interviews: the subject identification technique and the characteristic identification technique.
Conducting user interviews was the next subject of discussion. We delved into the four issues addressed during this set of interviews along with the techniques used to address them. This section was followed by a discussion about conducting management interviews. You learned the issues addressed and the techniques used during this set of interviews as well.
Finally we went through the process of compiling a list of fields based on the list of characteristics and any characteristics that appear in sample reports. You learned that your list of fields is broken down into two separate lists: a preliminary field list and a calculated field list. The preliminary field list enumerates the fundamental data requirements of the organization and the core set of fields to be defined in the database. The calculated field list consists of fields whose values are the result of mathematical computations.