
3
A Comparative Overview of Hybrid Recommender Systems: Review, Challenges, and Prospects
Rakhi Seth* and Aakanksha Sharaff
National Institute of Technology Raipur, Chhattisgarh, India
Abstract
Recommender System (RS) helps to find the items according to user interest and provides various suggestions that help in the decision-making process. These suggestions depend on distinct recommendation techniques. These approaches are divided into different categories like Collaborative, Content, Demographic, Utility, Knowledge-based, and Hybrid. Collaborative RS works on the concept of “people to people co-relation”. Content-Based RS suggests the idea of recommendation in which next item for a user is similar to the item that user like in the past. Demographic RS categorized the attributes based on the demographics of the user or item and make recommendations based on these demographics classes. Utility-based RS is a concept which depends on the estimation of the utility for a user for each item by using a specific utility function. Knowledge-Based RS works on “a particular user needs that how it meets with the item”. Hybrid RS is a combination of two or more recommendation strategies in a distinguished way to create a better and more personalized experience for the individual user like one of the recent study suggested the novel approach of solving sentimental issues faced in recommendation system by combining the two models of collaborative filtering i.e., by taking the rating score from memory-based and tagging (vital role in describing user feelings using Matrix Factorization (MF)) approach from model-based. So our objective is to find out how the hybrid approach is better and also understand the different types of solutions using the hybrid recommender systems and demonstrating new challenges and future scope of the hybrid system. The basic and widely discussed problem of the traditional RS technique is cold start problem and the problems associated with demographics, the utility is also considered for the study and how the Hybrid based approach is used to analyze and solve these problems.
Keywords: Recommender system, matrix factorization, root mean square, mean absolute error
3.1 Introduction
Initially, recommendation plays a supporting role but with time as the internet grows, more and more people ask queries through the internet and the evolution of the recommender system has done. In this evolution process, various types of recommendation techniques are introduced in different fields like medicine, movies, music, e-commerce based recommendation, and many others.
A conversational RS [1] is one of the approaches described as a more one-to-one user preference got attention at the time of conversation and become a more personalized one for each user. In this paper [1] the RS provides the differential diagnosis to schizophrenia, schizoaffective and bipolar diseases by using fuzzy implications. In Health care, there is not only the conversational RS that is useful but also the web page RS is very helpful for those users who have any previous record and on that basis, they want to take suggestion from the internet but the problem is that the recommended data is in a very scattered way [2] so researcher suggests the new idea of Web Page based RS for web pages in one place provided to patients so that patient get very precise and related information regarding his/her disease.
Sentiment Analysis is one of the fields that is also explored in RS; we need to understand that in RS each review that a user provides connects to some emotions either positive or negative. So from the text we need to understand the sentiment of the user [3]. The authors propose the model called a stochastic model of HMM (Hidden Markow Model) for the customer reviews that come in various marketing portal like Amazon, Flipkart and others. Through this, the author achieves the higher precision and accuracy of analyzing the sentiment of the customer in reviews. Now there is another type of recommendation system which is built on trust. Trust is one of the major issues or aspects of interaction with the user [4]. So for achieving this goal, the researcher built the system which not only works on privacy but also sees the multi-dimension reputation of the user like what contribution as well as what are the social link and rating among similar users.
There are several recommendations that are provided when one visits a web portal for a specific item like carwale, cardekho, OLx, and magicbricks. All these are examples of how interactive and advanced this system works. Now the question arises as to how this recommendation system works. For that we need to understand the evolution of RS [5]. The recommender systems are categorized into three generations: basic one, knowledge-based one, and Sentiment or emotion-based recommender systems have been developed. As evolution has been done in three different generations we can understand it through Figure 3.1.
The recommender system belongs to the domain of Data Mining which is used to store and manipulate data. Different methods are used in data mining for processing the dataset and valuable information. One can understand how the recommender system works from Figure 3.2. First, Data, which is meaningful information, is collected from the legal source, and then pre-processing starts in which cleaning of that data has been done by removing the noisy redundant data and making the information clear and useful for further work.
The next step is model learning which means to classify according to the dataset and how one wants to see the model working in the real-world as well as according to challenges one is finding in the existing model. There are many aspects of model learning in which different testing and verification strategies are applied. In classification, there are some issues related to the classification that is discussed [6] in this paper, the authors focus on one of the issues of dodging spam filters by spamming. When a high dimensionality of email is sent or received then the main challenge is to train the classifier in a way that prediction may not be compromised and the author gives the solution for this type of classification. The last step is testing and validation in which RMSE and MAE are the evaluation measures that evaluate which RS gives the best result between the predicted and measured interest.

Figure 3.1 Evolution process of RS.

Figure 3.2 Recommender systems.
3.2 Related Work on Different Recommender System
The RS are classified into six different types and the working of all the approaches is different from one another. The types are as follows:
Collaborative Filtering: CF is an automatic filtering technique used for prediction. It means that recommendation for any user (as per his/her interest criteria) is done through preferring the ratings of many users who rate similar items. CF works on recommendations that focus on user liking about the item and then finds the pattern and rating for each item and then classified according to user interest.
For example: If user X1 likes item Y1, Y2, and Y3.
If user X2 likes item Y1, Y3, Y4
If user X3 likes item Y1?
So there are higher chances that person X3 gets a recommendation for an item liked by X1 and X2.
When we talk about CF then we have two models: one is memory-based, which is also known as neighborhood filtering, user-item rating which is directly used to predict the new-items. It works on similarity measures such as cosine similarity and correlation coefficient. But there is a problem in the [7] technique is that the rating is not uniform and some user ratings are stringent and some are lenient. So how do we suggest the items to a set of users who are stringent and to predict the rating values for each user. The authors provide the solution for it by an algorithm called NCFR (Normalization based Collaborative filtering) which finds the average user per item and does the user count then normalize it with min–max normalization.
The other one is model-based CF, which works on learning the predictive model by using rating as input; for modeling a parameter the characteristics of user and item are used. In this paper [8] the authors discuss this CF in phases, the first one is a factorization-based model and the other is a NN (neural network) based model.
Content-Based (CBRS): This method is based on the profile of different users as well as different items. First CBRS matches basic data of the user with all similar items rated and if not then bases on the profile of the items that are recommended [9]. It follows certain steps as given below:
- a. Content Analyzer: It is used at the initial step when there is no structure and we need only relevant data so pre-processing is done and only data items can be used when important features are extracted. It works as input for profile learners and filtering components.
- b. Profile learner: In this step, the user profile is created by taking preference data and tries to generalize those data, for example feedback-based recommender system, in which positive and negative feedbacks could be learned and according to that recommendation that the user makes.
- c. Filtering Component: Here the matching item related to the item list will be found out and this will be done by calculating cosine similarity between the item and prototype vector. Through a diagrammatic view, we understand its working process better.
When we talk about RS data it is one of the major focuses and creates a problem too because maintenance and cleaning the data is not an easy task. The most important thing is how one will retrieve the data as per the user interest or preferences [10] The authors give the solution through the method which uses POS-taggers to format the dataset. By using the NLTK (Natural language processing kit) framework taggers it is not the first time to be used by anyone as it has been used many times like in blogs, Facebook, and Instagram for categorizing the data and making the search easy for the user.
Demographic Recommender System (DRS): It works on the demographic profiles of the user as we can see in Figure 3.3. Now what does the demographic mean. It means that it works on a different attribute like age, gender, occupation for recommendation purposes. Half-trusted means third parties use this technique for recommendation purposes on individual users. It also solves the problem of cold start and it works on the concept of “People to People” correlation but uses dissimilar data. In [11] the author gives an idea for developing more personalized RS and provides a better fitting recommendation. Demographic approach is used in the music-based dataset. The author is proposing the feature modeling approach by using Term Frequency-Inverse Document Frequency (TF-IDF) for an artist based listening information as well as tags combined with extracted features (user-traits prediction).

Figure 3.3 Demographic recommender systems.
Utility-Based Recommender System (UBRS): This RS works on the computation of utility to the user of each item as shown in Figure 3.4 but the problem is how to understand the utility of individual users. So the solution is the utility function which can be extracted from the rating of items and apply it to the objects [12]. Multi-attribute utility concept is a systematic as well as a quantitative method for utility-based RS which helps in decision making. There is one method called critiquing [13] defined as the method used in the Conversational recommender where the recommendation is based on the user preference feedback regarding item attributes and associated with constraint and utility-based methods. One implementation is in conversational RS [13] which combines the utility-based method with a deep learning framework and recommendation is done based on preference feedback regarding item attributes as well as constraint associated with it.
Knowledge-Based Recommender System (KBRS): KBRS uses knowledge about users and products to make recommendations in Figure 3.5. Using Knowledge acquisition means that acquired knowledge must be in some structured machine-readable form. Knowledge-based RS works on the definite realm of knowledge about how users’ needs are met with items’ features and generate preferences on how a particular item is appropriate to a particular user. In these, a similarity function estimates how much the user’s needs match the recommendation. These identity or similarity scores can precisely be explained as the recommendation for the user. In recent years, as the author proposed [14] recommendation system which works with the knowledge graphs. It is a heterogeneous graph where node functions as entities and edge works as the relation among nodes. There are many KG based RS present which work better in real-time. One more problem is how we do the decision making in a Knowledge-based system [13]. Here the authors provide the idea of argumentation-based RS in which competing argument is the center of user’s query answering process. This approach handles multiple arguments for understanding and improving the reasoning capabilities. In this paper, [15] provide the recommendation for higher education in which system saw the past publication, research interest, education background to generate the best scholarship plan for student as per the suitable faculty whose data is also maintained

Figure 3.4 Utility recommender system.

Figure 3.5 Knowledge-Based RS.
Hybrid Recommender System: All the methods that we mentioned have their advantages and disadvantages so researchers adopted a new technique which results to two or more recommendation techniques as seen in Figure 3.6. Collaborative Filtering can’t handle the new item problems. In content-based, this problem will be handled through item description so there are several ways of combining the basic RS technique to provide the new improved version of the recommendation technique. We saw in the above mentioned diagrams how two distinguished RS approach works; here we combine content and collaborative filtering and understands the more useful as well as advantageous approach. Here also deep learning is used [16] with the hybrid approach as a solution to the overfitting problem by installing the learning for user and items based on Latent-factors for non-linear data set. Reference [17] proposed RS use the tagging feature for this semantically related tags which are extracted from the WordNet lexical database and then by using CF’s the implicit rating is found out using similarity measures. In an online system [18] many influencers bribe the different users to change their ratings so that sellers’ reputation may increase. Here the solution is provided by using a novel technique called matrix completion algorithm using hybrid memory-based collaborative filtering that uses an approximation of Kolmogorov complexity to be used for bribery resistance approach.

Figure 3.6 Hybrid recommender system.
3.2.1 Challenges in RS
The recommender system faces many challenges [19, 20] that may affect the working of the system, and finding a solution for these challenges is the main task of research.
- Novelty: When the user has no clear idea about items and is not known to the user or a new item is also used for the emotional replay of users towards the suggestion.
- Cold Start problem: This problem is generated when a site has a new user and a new item then the first issue is how one would recommend items to the new user and as we don’t know about the user interest. The second issue is new item is not rated yet so how we recommend this item to any user.
- Serendipity: When RS accidentally suggests novel items that are unexpected but useful for users but the problem is that the quality of RS may suffer.
- Sparsity Problem: This problem is generated when a large number of users focus on a few items and don’t rate every item they buy as well as some items are always untouched.
- Scalability: It measures the system’s ability to work effectively when information grows with high performance.
- Over Specialization Problem: Items recommended to the user are already known.
- Correctness: It calculates or evaluates the degree to which how close the measured value is to each other. It gives truthfulness.
- Diversity: It shows the correlation between the recommended items. It can be measured by using the objective difference. It answers the question “How unrelated are the suggested item”.
- Stability: It evaluates the level of consistency and reliability among the predictions made by the recommendation algorithm. It answers the question “How reliable is the system for making recommendations”.
- Privacy: It is one of the main concerns in RS because user data collected from different sources are in two forms: one is explicit and the other one is implicit and this dimension affects the scalability and accuracy. It answers the question “Is there any issue or hazard with the user privacy?”.
- Gray Sheep: It occurs when the opinion of the user doesn’t fit with any group and as a result, the RS will not work for that user it happens in collaborative filtering.
- Usability: It aims to provide a well-organized and effective recommendation that gives the result to some degree that satisfies the user and gives the answer to the question that “how functional is an RS?”.
- User Preference: It is a way through which one can monitor the choices and the items preferred which can discriminate from those that are not preferred. It simply means that users perception of the recommended approach.
- Shilling attack: When any malicious user comes into the system and gives false ratings so that items get popular or decreasing the value of the item.
3.2.2 Research Questions and Architecture of This Paper
Based on our study we explore the following research questions not only this. In Table 3.1 we discuss the different filtering techniques and what the advantages and disadvantages are of each technique and also we provide the architecture of this paper in Figure 3.7.
Table 3.1 Show the advantage and disadvantage of different types of RS.
| No. | Types | Advantage | Disadvantage |
| 1 | Collaborative Filtering | 1. This filtering doesn’t use the demographic for recommending the items. 2. There is a proper match between users and items. 3. This system recommends the items to the user outside their preferences. | 1. The highest rating of any item in the dataset determines the quality. 2. One of the major problems seen in this recommendation system is the “Cold Start” problem that the system doesn’t provide recommendations for new users. |
| 2 | Content-Based Recommender System | 1. It uniquely characterizes each user profile. 2. The system can recommend a new user based on the similarity between item specifications. | 1. For creating a recommendation list one needs to create all features of items which is one of the complex tasks. 2. In Content-based user-item rating is not included so one cannot determine the quality of the recommendation system. |
| 3 | Demographic Recommender System | 1. It is based on the demographics of the user so without rating also recommends items. | 1. One of the major issues is that every customer is not comfortable in sharing personal data as well as it’s a privacy issue. 2. Stability vs. plasticity problem. |
| 6 | Utility-Based Recommender System | 1. It works on utility function so it becomes closer to user interest 2. Prioritize the item. | 1. How to find the utility of any user. |
| 5 | Knowledge-Based Recommender System | 1. It provides qualitative preferences based on feedback. 2. It also handles the changes in preferences. | 1. A knowledge database is required. 2. The suggestion ability is static. |
| 4 | Hybrid Recommender System | 1. This approach mainly targets the advantage of one system and is used for other systems so by combining one get a better recommendation system. 2. Its main focus is a content-related description and user evaluation. 3. The Hybrid approach works on a specialized solution. 4. Improve customer satisfaction rates. | 1. Early Rater problem for products. 2. Sparsity problem. |
- RQ1: Up to which level the existing individual approach like Collaborative filtering can provide recommender systems according to the users’ best interest in the requested field.
- RQ2: To what extent do existing algorithm handles the problem like cold start problem (like new users), data sparsity, scalability, diversity, and stability.
- RQ3: How the hybrid approach comes into the role of overcoming the drawbacks of the existing algorithms based on a research perspective.
3.2.3 Background
There is a rapid increase of global research community on the recommender system findings and everyday new development is coming based on different aspects or attributes used for recommendation. Here in Table 3.2, we discuss the technique used and what the drawbacks are of those algorithms. Through this, we also understand that for which technique which evaluation criteria are used for performance measure. In this section, we also understand the architecture of the hybrid approach.

Figure 3.7 Architecture of this paper.
3.2.3.1 The Architecture of Hybrid Approach
Here we discuss the different approaches of applying Hybridization according to the challenges faced by the researchers where we need to understand the problems and what they are the different possible solutions of it. There are several Hybridization Methods (HM) which are as follows:
- Weighted: A single recommendation will be provided from the score of several recommendation technique ex-P-Tango systems.
- Switching: It is a method which switches between different recommendation techniques depending on the situation like Netflix initially content-based is there and after that, it switches to collaborative filtering.
Table 3.2 Shows which technique, evaluation criteria are used in different RS.
Paper name Type of RS Technique Evaluation metric Drawback/Future work Panda, S.K., et al. [7] CF Normalization based collaborative filtering 1. Recall
2. Precision
3. Mean Absolute Error (MAE)
4. F-Score
5. FMI
6. Root Mean Square Error (RMSE)
1. The rating matrix used in the suggested algorithm is static.
2. The authors have not observed user and item biases in the proposed algorithm.
3. The proposed algorithm is not exhibited using a standard dataset due to the inclusion of rigid users.
Amara, S., et al. [10] Content-Based RS Tagger-User Profile-Tree 1. Precision 1. The tag-based system updates over a while.
2. It shows that profiling through this algorithm is much better than personal and content-based filtering.
Deng, F., [12] Utility-Based RS IU-GA (Item Utility-Genetic Algorithm) extracts the utility functions based on user behavior while browsing not one attribute. This utility function is multiattribute and then the genetic algorithm is used. 1. Precision
2. Recall
3. F1
1. This recommendation system works on limited context online. Ullah, F., et al. [21] Collaborative Filtering A novel Deep Neural Collaborative Filtering 1. RMSE
2. MAE
3. Similarity measure
4. Predicted Score
1. The side information and other contextual data in the educational service recommendation. Feng, C., et al. [22] Collaborative Filtering Uses the model that integrates the rating matrix with neighbors information and this model is called the Fusion probability Matrix Factorization model 1. MAE
2. RMSE
1. In the future, the author wants to use the incremental learning approach with the proposed CF model i.e. Fusion based. Zarzour, H., et al. [23] Collaborative Filtering A trust-based model implemented through collaborative filtering 1. RMSE 1. This collaborative filtering method established on a method called dimensionality reduction which can be paired with a clustering algorithm. Mustaqeem, A., Anwar, et al. [24] Collaborative Filtering Cluster-Based Modular Recommendation System 1. Precision
2. Recall
3. MAE
1. It dealt with only one type of patients.
2. The dataset will be extended by adding more patients and partitioned based on demographics.
Zhang, B., et al. [25] Collaborative Filtering Residual Convolution CF (Work on Combined approach of PMT + CNN) 1. RMSE 1. Current work is on textual features, in the future latent factor features can also be considered. Gu, Y., Zhao, B., et al. [26] Content-Based RS An approach that learns (Supervised Learning) simultaneously how to find optimal global term weight and finds the similarity on the multiple text features between user and item profiles.
1. Area under ROC(Receiver operating characteristics)
2. Precision
3. Recall
4. Area under precision-recall curve.
2. The proposed approach improves AUC up to 17% but in the future efficiency can be increased. So this unified framework provides an overall relevance model. Zheng, Y., [27] Utility-Based RS It uses a Multi-criteria utility-based algorithm. 1. Pearson correlation
2. Cosine similarity
3. Euclidean distance
1. There is an issue called over expectation, which may contribute to finger-grained recommendation models. Huang, S.L., et al. [28] Utility-Based RS A decomposed and holistic utility-based based method. 1. Accuracy
2. Time Expense
1. In this paper, only 96 students as subjects the limited no of participants decrease the credibility of the research.
2. Utility-based can be compared with collaborative filtering too.
3. Research finds that content-based work on nominal attributes, decomposed one will work better with numerical attributes and holistic will work in different contexts.
Patro, S.G.K., et al. [29] Knowledgebased RS Based on domain knowledge, the preference is created and a learning model is prepared with an adaptive neuro-fuzzy model 1. Mean absolute percentage error
2. Root Mean Square Error
3. Mean Absolute Error
4. Precision
5. F1-score
1. This algorithm works in three steps first one is clustering then decomposition and then prediction any step error may affect the prediction. Dong, M., et al. [30] Knowledge-Based RS Interactive Knowledge-based Design Recommender System 1. Rate of satisfaction 1. It can be enhanced by learning different design cases. Bobadilla, J., et al. [31] Demographic RS Obtaining different demographic features from the different latent factors by using the gradient localization method 2. Accuracy 1. This algorithm cannot be able to work on zip code or salary as user demographic feature.
2. Detection of unreported minority users, as well as items, is still one of the limitations which can be solved in the future.
Yang, C., et al. [32] Collaborative Filtering Neural Collaborative filtering approach i.e. Gated and Attentive (GANCF) 1. Hit ratio
2. Normalized Discounted Cumulative Gain (NDCG)
1. In the future, explore the area of social networks and how users trust this platform.
2. The list of interests of the user is realized in the online recommender system.
Huang, X.Y., et al. [33] Collaborative Filtering Logo (Local and global) online CF algorithm 1. RMSE
2. MAE
1. Implicit and explicit feedback can be used in the recommendation.
2. Assumptions for each rating vector can be a mixture of some distributions.
Cami, B.R., et al. [34] Content-Based RS A New Extended Distance Dependent CRP (Chinese Restaurant Process) 1. Precision
2. Recall
3. F1-measure
1. Incorporating a collaborative approach with the current technology provides a richer user profile. Bagher, R.C., et al. [35] Content-Based RS A Bayesian framework works on the nonparametric area is known as DPMM (Dirichlet Process Mixture model) 1. Precision
2. Recall
3. F1-measure
4. DCG (Discounted cumulative Gain)
1. User rate feedback can be used as a parameter.
2. For improving the diversity measure one can use the CF.
- Mixed: Different recommendation methods are present and used over the same time.
- Feature Combination: Using different features that come as the result of different recommendation data and put it into one recommendation algorithm.
- Cascade: It follows the staged process in which first produces the coarse ranking of user and items as well and refines the recommendation with other techniques.
- Feature augmentation: It is a technique in which the output of one is the input of another recommendation technique
- Meta-level: Here the model learned by one recommender is used as input to another.
As we all know that recommender system is increasingly used in the field of e-commerce, movies, music as well as education and health sectors. Hybrid is a solution for all the individual recommender system which comes with certain inbuilt problems [16] As we all know, collaborative filtering has one major problem which is the cold start problem “problem of Recommendation in which no past interaction provided for the user as well as for an item”. The categorization of cold start is of two types which are as follows:
- User Cold Start
- Item Cold Start.
Both the above mentioned cold start problems are fixed by using the side information about users and items into a deep neural network. Also, resolves the problem of the linear latent factors, the solution is learning through no-linear latent factors of users and items. This is not the only way to handle the problems of different recommender systems there are [36] which focuses on the item targeting problem means “best as per user interest” so it finds the solution through a hybrid approach in which the Bayesian recommender model is being created which shows the advantages of memory-based and model-based collaborative filtering. Individually, Model-based CF has better fitting operations as well as works when data is missing (data sparsity). Matrix factorization is one of the techniques used for latent factors as well as it solves the problem of cold start. The Hybrid approach comes with several advantages that are useful for solving existing problems:
- a) It increases the interaction between user and item as most as possible for making a better recommendation system.
- b) Researchers work on merging several recommendation models like factor-based, item-based, and user-based collaborative filtering models as a hybrid for artist based recommender system it improves the user-item interaction.
- c) For the item identification problem, the hybrid approach works to propose a model called the “Bayesian inference-based model”.
As the author is focusing on serendipity [37] which is one of the challenges we discussed in an earlier section of the paper, the author provides the hybridization method to face this challenge. This is more subjective than the attribute-based so a large set of data set has been taken and find the following criteria:
- Content difference: It is defined as a movie that is not searched by the user in past and gets the recommendation.
- Genre accuracy: For the short term of preference for the movie for the user.
- Serendipity: It shows both attractiveness and surprise based on Content difference and Genre accuracy.
- User elasticity: It is the ability to accept the difference from past behavior.
- Movie elasticity: It is the possibility of being adopted by a different user.
- Relevance network: It is a network that shows the asymmetric association between different nodes; this node is nothing but the movies and users.
3.2.4 Analysis
3.2.4.1 Evaluation Measures
How will one find out which recommender system is better than the other? So for that we need appropriate evaluation criteria or metric through which one can understand there are different evaluation metrics like Accuracy, Adaptability, and Reliability which are all not used in all the RS. It depends on the models which evaluation criteria provide the performance analysis. Recommender systems can be evaluated through various evaluation metrics; it is based on the experimental setup for various research studies. It can be understood through these terms:
- Hypothesis: Before starting an experiment, a hypothesis is built up like any algorithm X is better than algorithm Y so we need to be precise about these hypotheses and only use one measure to find and prove this hypothesis is “prediction accuracy”. The researcher doesn’t require any other factor for this hypothesis. The major drawback is the researcher becomes restrictive.
- Controlling Variable: So when according to variable the result may change and we can’t just depend on prediction accuracy because dataset is never static as it changes from time to time and we can’t publish the fact that results differ because of algorithm or dataset so we require more evaluation measures.
- Generalization Power: It is generalizing the experiments based on different datasets. When one will deploy or develop any new algorithm it should not be specific to any one application; it must be beyond that application for that generalization of results are necessary.
How one will decide which recommendation system is to select or better so the answer different parameters that affect the properties of the recommender system is used to evaluate and these measures get affected based on user experience.
Prediction Accuracy: It is one of the properties of RS and it provides more accurate predictions according to the user’s interest. PA evaluates the accuracy of item ratings displayed by users.
Measuring Rating Prediction Accuracy
- a. Root Mean Square Error: When the true ratings are known and the system produces predicted ratings for a test of user-item pairs.

Where, Ŷ1, Ŷ2… Ŷi is predicted values
Y1, Y2…..Yi is the observed value N is no. of observation.
- b. Mean Absolute Error: The average of all absolute errors in the definition of MAE. An absolute error is a difference between the measured value and the true value.
Where xi is the measurement, x is the true value.

Where, n = the number of errors, |xi – x| = the absolute errors
Measuring Usage Predication
A dataset consisting of items that each user used is known as usage prediction and inside these various measures are works based on True Negative, False Positive, False Negative, True positive. Now, these four types are based on the actual value and predicted value as we can see in Table 3.3.
- a. Precision: When fractions of positive number of cases among the total number of positive cases in the system are retrieved then it is known as positive class prediction which is another name of precision. When it predicts yes the person likes cats, how often is it correct?

Table 3.3 Base of usage predication.
Conditions Actual value Predicted value True Negative False False False Positive False True False Negative True False True Positive True True - b. Recall: Number of positive class predictions out of positive class in the dataset. It answers the questions that when it is actually yes the person likes cats, how often does it predict correctly?
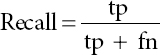
- c. F-measure: It is a measure that takes both precisions and recalls into account and when one finds out the weighted average of precision and recall then it is known as F-measure and it also defines as a parameter that makes a compromise to be reached concerning precision and recall.

Measuring Ranking of Items
Normalized Distance-Based Performance Measure: When there is a need for information retrieval then this measure is used and it distinguishes correct and incorrect orders of pairs and ties.

3.2.5 Materials and Methods
Recommender System is a part of Data mining. As we see in recommender systems the main focus is on sampling, dimensional reduction, and classification, clustering technique in RS. Also there is association rule discovery and RS is also implemented through deep learning so in this section we understand different algorithm works on the above-mentioned concept.
Sampling is the concept of selecting a small amount of relevant data i.e. subset from a large dataset. This subset is used for training and testing purposes. When a task like model fitting is there then a training dataset is used. When one wants to see how the model generalizes then a testing dataset is used. Various sampling techniques are there like random sampling, stratified sampling. The approach used for sampling is with replacement means items can be removed from the population once they get selected and without replacement means that no item gets removed.
A dimension reduction is a technique that helps to overcome the problem by changing high-dimensional space into lower dimensionality. There is a various method of doing so, PCA, Matrix factorization (like SVD) is one of the most common and powerful techniques of dimensionality reduction.
Denoising is a very important part of pre-processing in which removal of the unwanted effect on data when widening of information is done; in simple words we define unwanted artifacts as noise.
A classifier is of two types: supervised and unsupervised. It is defined as the mapping between label space and feature space. Now here feature means elements characteristics for proper classification and for representing classes label space is used. For example, Hospital RS classifies into two categories i.e. either good or bad based on features that are associated with it.
Instance-Based Classifier: It is defined as the classifier that works on the training and uses it to forecast the labels of unseen cases. It learns the entire set of training and classifies when a new record matches the training example.
kNN classifier is one of the most used classifiers not only in the recommender system but in machine learning too. It is also known as lazy learners and one of the advantages of this technique is that it doesn’t require learning and maintaining a given model and in RS it is used in Collaborative filtering. Nearest Neighbor is used in CF to find like-minded users but this approach is also get challenged by other approaches called Matrix completion.
Decision Tree: It is a type of Nearest Neighbor and as the name suggests it creates a tree based on the target class. A single attribute-value is represented as a Decision node and is tested to find which branch of leaf nodes indicates the target value. Different methods are used for the decision tree like Hunt’s Algorithm. Hunt algorithm works on test conditions implemented on the specified attribute that inclines the observations by their target value. The Decision tree for ranking has also been used.
Rule-Based Classifier works based on various “if...else rules ” and thus this classifier is used to develop the descriptive models and the condition used with “if” is called precedent and the predicted class for each rule works as a consequence. To implement the Rule-based classifier is a classifier that extracts rules directly over different data some examples are Ripper, CN2.
Logistic Regression is the basic probabilistic classification model; it is a type of classifier but then also it is called regression because of the legacy used for linear regression. Linear regression is used for linear equations. In one paper [38] the author uses the regression technique and other nonlinear techniques like AI and made the comparison between which model works better for weather prediction so the researcher can analyze the performance of both linear and non-linear methods. In the regression model, a regular value comes as output but on other hand, the classifier has the output in the form of a class label. Logistic Regression work on the decision boundary many other classification methods that work on a similar concept like SVM (Support Vector Machine).

A Support Vector Machine is a classifier that is a user to find the linear hyperplane which separates the data with maximum margin. Here a linear separation is w.x + b = 0 and the other two are separated by using the class separation function which is based on minimum distance but when the condition arises of non-linearly item then SVM (Support Vector Machine) provides the solution of soft margin classifier by introducing a new variable called “Slack Variable”. Now condition arises of non-linear decision boundary so for that data to change into higher dimensional space it can be done through the help of a mathematical transformation called “Kernel Trick”.
A Bayesian classifier is used to solve the classification problem which works on the concept of a probabilistic framework. Some researchers say that this classifier is the fastest and the gradient boost model is the most accurate algorithm. It is used to represent the uncertainty among the relationship learned from data. It considers each of the attribute and class labels as random variables. It not only uses in collaborative filtering but also in a hybrid approach the example of this is [36] the method calculates or computes the probability through which the user rate the item. When we talk about the hybrid approach it includes all clustering and classification algorithms in a certain way.
Artificial Neural Network is an accumulation [39] of interconnected nodes and these nodes are known as a neuron. The simplest case is the perceptron model when we specify an activation function as a threshold function. Another most common approach is feed-forward ANN.
An Ensemble of Classifiers is a classifier that creates training data from a set of classifiers and does the prediction based on class labels. The two most common techniques used in ensemble learning is Bagging and Boosting.
Bagging is defined as performing the sampling with reinstatement and built the classifier on each step of bootstrap.
Boosting is an adaptive change of distribution in training data by giving importance to the previous misclassified records. In this initially, all records are of equal weights, and then wrongly classified records have higher weights have their weights increased, and those which are correctly classified with lessen weights. Adaboost is one of the algorithms that is used for boosting an ensemble classifier. This classifier is most commonly used in the hybrid approach RS.
In this clustering technique, the researcher [2] proposed a new algorithm that works on the semantics information of the web page, and pages are set into clusters by using a clustering algorithm and builds upon the similarity of semantics with the user. In this, the author provides the user agent which works as an interface where the user can input and gets output. The knowledge base is also created to classify the information as the user model there is a behavior model that precisely suggests the behavior of each user and all this model help in finding a better recommendation system.
In this paper, [24] the author gives the new method applied on supervised data in four different classes of disease retrieved by using the Kmean clustering and this method is implemented on each partition separately, and once the query patient is partitioned into the correct class of disease then it requires the similarity scores for reduced sub-clusters so it means that a separate recommendation is used for each class of disease and the whole process is known as modularization.
In this paper [40] the author suggests the solution for the issue of classifying the text to a discrete set of predefined categories it helps in identifying the categorical terms present in emails for this author uses the LDA modeling approach. The author [41] built the two datasets for evaluation: first one is transaction data and the other one is demographic data (personal data of user transaction data is calculated through similarity matrix and demographic data works on the cluster-product rating matrix by using K mean clustering technique. Fuzzy logic is an application-based approach that is used for classification [42]; the author proposed the idea for text summarization, fuzzy logic is used to normalize the unspecific reasoning of human ability. As the author proposed the Fuzzy logic based on the triangular member function which maps the input space points to membership functions and by using this method improvement takes place on the present model which is evaluated through different measures like precision and recall.
3.2.6 Comparative Analysis With Traditional Recommender System
When we say comparative analysis it means that what are the problems in one system and how it is solved by any other system through which better RS we get and we understand it through various evaluations metric in Table 3.4. Dataset of different types shows different results so we can’t say that if one algorithm is working in one data set so it will work for another so the size of the data set also matters at the time of implementing any new algorithm.
3.2.7 Practical Implications
As per Research Questions (RQ), we find the answers to these questions:
- RQ1 (Answer): When we talk about collaborative filtering then there are various challenges we face in an existing system like the cold start problem as well as gray sheep problem (discussed in challenges) are present prominently and if we say what are the practical implications are there so the solution is tagging as well as using content-based or feature-related extraction and make a recommendation through that main problem with collaborative is it depends on rating matrix either it is user-based or item-based but recommendations explored by many researchers says that accuracy and precision not only based on this, it depends on the ranking scheme and user profile through this we get better results so by combining all this approach in a different way hybrid approach arises and all the paper we read hybrid gives a better result than the individual traditional approach.
- RQ2 (Answer): If we talk about existing solutions through the existing traditional approach of RS then for cold start content-based work as a solution, for data-sparsity one can provide the solution like building a trust-based model, one of the challenges of diversity is solved through the hybrid system [36]. The scalability problem is solved through a context-aware strategy.
Table 3.4 Comparative study of hybrid approach with traditional approach.








- RQ3 (Answer): After exploring and understanding the above two research we concluded that the hybrid approach is one of the most flexible and by taking a different approach and combined in a distinguished way and gives a better result.
3.2.8 Conclusion & Future Work
The hybrid approach solves the problem of the traditional filtering technique and improves the effectiveness of recommendation by using different classifiers and clustering techniques. Many significant works have been done in this field to give users a recommendation based on their interests. In various traditional approaches there are some drawbacks like collaborative filtering suffers from data sparsity, cold start and scalability problems in demographic, there is a problem of breaching user privacy and in utility-based how to find that which product is more utilized for user and knowledge base create a complex system to understand and maintain. In all these, we have various other issues regarding dataset not in all dataset proposed algorithm works appropriately and accurately. Training and testing are one of the fields that may change the experiment results so all these will become the discussion point shortly that how researcher decides what the percentage of testing data is and what the percentage of training data will be present. Also Hybrid approach includes the deep neural network concept which also provides better results in terms of precision and recall.
A hybrid approach is the most flexible and most used approach of research which shows how many different ways one can use the traditional approaches and solve all the disadvantages of an individual approach but the problem is that how one will find that which two combination works better than the other.
References
1. Cordero, P., Enciso, M., López, D., Mora, A., A conversational recommender system for diagnosis using fuzzy rules. Expert Syst. Appl., 154, 113449, 2020.
2. Manikandan, R. and Saravanan, V., A novel approach on Particle Agent Swarm Optimization (PASO) in semantic mining for web page recommender system of multimedia data: A health care perspective. Multimed. Tools Appl., 79, 5, 3807–3829, 2020.
3. Soni, S. and Sharaff, A., Sentiment analysis of customer reviews based on hidden markov model, in: Proceedings of the 2015 International Conference on Advanced Research in Computer Science Engineering & Technology (ICARCSET 2015), pp. 1–5, 2015.
4. Ardissono, L. and Mauro, N., A compositional model of multi-faceted trust for personalized item recommendation. Expert Syst. Appl., 140, 112880, 2020.
5. Sinha, B.B. and Dhanalakshmi, R., Evolution of recommender system over the time. Soft Comput., 23, 23, 12169–12188, 2019.
6. Sharaff, A. and Srinivasarao, U., Towards classification of email through selection of informative features, in: 2020 First International Conference on Power, Control and Computing Technologies (ICPC2T), IEEE, pp. 316–320, 2020.
7. Panda, S.K., Bhoi, S.K., Singh, M., A collaborative filtering recommendation algorithm based on normalization approach. J. Ambient Intell. Hum. Comput., 1–23, Springer, 2020.
8. Pujahari, A. and Sisodia, D.S., Model-Based Collaborative Filtering for Recommender Systems: An Empirical Survey, in: First International Conference on Power, Control and Computing Technologies (ICPC2T), IEEE, pp. 443–447, 2020.
9. Mohamed, M.H., Khafagy, H.M., Ibrahim, M.H., Recommender systems challenges and solutions survey, in: International Conference on Innovative Trends in Computer Engineering (ITCE), IEEE, pp. 149–155, 2019.
10. Amara, S. and Subramanian, R.R., Collaborating personalized recommender system and content-based recommender system using TextCorpus, in: 6th International Conference on Advanced Computing and Communication Systems (ICACCS), IEEE, pp. 105–109, 2020.
11. Krismayer, T., Schedl, M., Knees, P., Rabiser, R., Predicting user demographics from music listening information. Multimedia Tools Appl., 78, 3, 2897–2920, 2019.
12. Deng, F., Utility-based recommender systems using implicit utility and genetic algorithm, in: International Conference on Mechatronics, Electronic, Industrial and Control Engineering (MEIC-15), Atlantis Press, 2015.
13. Wu, G., Luo, K., Sanner, S., Soh, H., Deep language-based critiquing for recommender systems, in: Proceedings of the 13th ACM Conference on Recommender Systems, pp. 137–145, 2019.
14. Guo, Q., Zhuang, F., Qin, C., Zhu, H., Xie, X., Xiong, H., He, Q., A survey on knowledge graph-based recommender systems. arXiv preprint arXiv:2003.00911, 2020.
15. Samin, H. and Azim, T., Knowledge based recommender system for academia using machine learning: A case study on higher education landscape of Pakistan. IEEE Access, 7, 67081–67093, 2019.
16. Kiran, R., Kumar, P., Bhasker, B., DNNRec: A novel deep learning based hybrid recommender system. Expert Syst. Appl., 144, 113054, 2020.
17. Riyahi, M. and Sohrabi, M.K., Providing effective recommendations in discussion groups using a new hybrid recommender system based on implicit ratings and semantic similarity. Electron. Commer. Res. Appl., 40, 100938, 2020.
18. Ramos, G., Boratto, L., Caleiro, C., On the negative impact of social influence in recommender systems: A study of bribery in collaborative hybrid algorithms. Inf. Process. Manage., 57, 2, 102058, 2020.
19. Anwar, T. and Uma, V., A review of recommender system and related dimensions, in: Data, Engineering and Applications, pp. 3–10, 2019.
20. Kumar, B. and Sharma, N., Approaches, issues and challenges in recommender systems: A systematic review. Indian J. Sci. Technol., 9, 1–12, 2016.
21. Ullah, F., Zhang, B., Zou, G., Ullah, I., Qamar, A.M., Large-scale Distributive Matrix Collaborative Filtering for Recommender System, in: Proceedings of the 2020 International Conference on Computing, Networks and Internet of Things, pp. 55–59, 2020.
22. Feng, C., Liang, J., Song, P., Wang, Z., A fusion collaborative filtering method for sparse data in recommender systems. Inf. Sci., 521, 365–379, 2020.
23. Zarzour, H., Jararweh, Y., Al-Sharif, Z.A., An Effective Model-Based Trust Collaborative Filtering for Explainable Recommendations, in: 2020 11th International Conference on Information and Communication Systems (ICICS), IEEE, pp. 238–242, 2020.
24. Mustaqeem, A., Anwar, S.M., Majid, M., A modular cluster based collaborative recommender system for cardiac patients. Artif. Intell. Med., 102, 101761, 2020.
25. Zhang, B., Zhu, M., Yu, M., Pu, D., Feng, G., Extreme residual connected convolution-based collaborative filtering for document context-aware rating prediction. IEEE Access, 8, 53604–53613, 2020.
26. Gu, Y., Zhao, B., Hardtke, D., Sun, Y., Learning global term weights for content-based recommender systems, in: Proceedings of the 25th International Conference on World Wide Web, pp. 391–400, 2016.
27. Zheng, Y., Utility-based multi-criteria recommender systems, in: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, pp. 2529–2531, 2019.
28. Huang, S.-L., Designing utility-based recommender systems for e-commerce: Evaluation of preference-elicitation methods. Electron. Commer. Res. Appl., 10, 4, 398–407, 2011.
29. Patro, S.G.K., Mishra, B.K., Panda, S.K., Kumar, R., Long, H.V., Knowledge based preference learning model for recommender system using adaptive neuro-fuzzy inference system. J. Intell. Fuzzy Syst., 39, 3, 4651–4665, 2020.
30. Dong, M., Zeng, X., Koehl, L., Zhang, J., An interactive knowledge-based recommender system for fashion product design in the big data environment. Inf. Sci., 540, 469–488, 2020.
31. Bobadilla, J., González-Prieto, Á., Ortega, F., Lara-Cabrera, R., Deep learning feature selection to unhide demographic recommender systems factors.
32. Yang, C., Miao, L., Jiang, B., Li, D., Cao, D., Gated and attentive neural collaborative filtering for user generated list recommendation. Knowledge-Based Syst., 187, 104839, 2020.
33. Huang, X.-Y., Liang, B., Li, W., Online collaborative filtering with local and global consistency. Inf. Sci., 506, 366–382, 2020.
34. Cami, B.R., Hassanpour, H., Mashayekhi, H., User preferences modeling using Dirichlet process mixture model for a content-based recommender system. Knowledge-Based Syst., 163, 644–655, 2019.
35. Bagher, R.C., Hassanpour, H., Mashayekhi, H., User trends modeling for a content-based recommender system. Expert Syst. Appl., 87, 209–219, 2017.
36. Ngaffo, A.N., El Ayeb, W., Choukair, Z., A Bayesian Inference Based Hybrid Recommender System. IEEE Access, 8, 101682–101701, 2020.
37. Li, X., Jiang, W., Chen, W., Wu, J., Wang, G., Haes: A new hybrid approach for movie recommendation with elastic serendipity, in: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, pp. 1503–1512, 2019.
38. Sharaff, A. and Roy, S.R., Comparative analysis of temperature prediction using regression methods and back propagation neural network, in: 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), IEEE, pp. 739–742, 2018.
39. Ricci, F., Rokach, L., Shapira, B., Introduction to recommender systems handbook, in: Recommender Systems Handbook, pp. 1–35, Springer, Boston, MA, 2011.
40. Sharaff, A. and Nagwani, N.K., Identifying categorical terms based on latent Dirichlet allocation for email categorization, in: Emerging Technologies in Data Mining and Information Security, pp. 431–437, Springer, Singapore, 2019.
41. Oyebode, O. and Orji, R., A hybrid recommender system for product sales in a banking environment. J. Bank. Financ. Technol., 1–11, Springer, 2020.
42. Sharaff, A., Khaire, A.S., Sharma, D., Analysing Fuzzy Based Approach for Extractive Text Summarization. International Conference on Intelligent Computing and Control Systems (ICCS), pp. 906–910, 2019.
43. Lee, Y., Won, H., Shim, J., Ahn, A Hybrid Collaborative Filtering-based Product Recommender System using Search Keywords. J. Intell. Inf. Syst., 26, 1, 151–166, 2020.
44. Pradhan, T. and Pal, S., A hybrid personalized scholarly venue recommender system integrating social network analysis and contextual similarity. Future Gener. Comput. Syst., 110, 1139–1166, 2020.
45. Walek, B. and Fojtik, V., A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl., 158, 113452, 2020.
46. Shanmuga Sundari, P. and Subaji, M., Integrating sentiment analysis on hybrid collaborative filtering method in a big data environment. Int. J. Inf. Technol. Decis. Mak., 19, 2, 385–412, 2020.
47. Pérez-Marcos, J., Martin-Gomez, L., Jiménez-Bravo, D.M., López, V.F., Moreno-García, M.N., Hybrid system for video game recommendation based on implicit ratings and social networks. J. Ambient Intell. Hum. Comput., 11, 11, 4525–4535, 2020.
48. Logesh, R. and Subramaniyaswamy, V., Exploring hybrid recommender systems for personalized travel applications, in: Cognitive Informatics and Soft Computing, pp. 535–544, 2019.
49. Waqar, M., Majeed, N., Dawood, H., Daud, A., Aljohani, N.R., An adaptive doctor-recommender system. Behav. Inf. Technol., 38, 9, 959–973, 2019.
50. Pereira, N. and Varma, S.L., Financial planning recommendation system using content-based collaborative and demographic filtering, in: Smart Innovations in Communication and Computational Sciences, pp. 141–151, 2019.
- *Corresponding author: [email protected]