
Chapter 3
Server Maintenance
COMPTIA SERVER+ EXAM OBJECTIVES COVERED IN THIS CHAPTER:
- ✓ 2.2 Compare and contrast server roles and requirements for each
- Web server
- Application server
- Directory server
- Database server
- File server
- Print server
- Messaging server
- Mail server
- Routing and remote access server
- Network services server (DHCP, DNS/WINS, NTP)
- ✓ 2.4 Given a scenario, perform proper server maintenance techniques
- Change management
- Patch management (operating system updates, application updates, security software updates, firmware updates, device drivers updates, compatibility lists [operating systems, hardware, applications] testing and validation)
- Outages & service level agreements (scheduled downtime, unscheduled downtime, impact analysis, client notification, MTTR
- Performance monitoring (CPU utilization, memory utilization, network utilization, disk utilization [Disk IOPS, storage capacity] comparison against performance baseline, processes and services monitoring, log monitoring)
- Hardware maintenance (check system health indicators [LEDs, error codes, beep codes, LCD messages], replace failed components [fans, hard drives, RAM, backplanes, batteries], preventative maintenance [clearing dust, check proper air flow], proper shut down procedures
- Fault tolerance and high availability techniques (clustering [active/active, active/passive], load balancing [round robin, heartbeat])
- ✓ 2.5 Explain the importance of asset management and documentation
- Asset management (licensing, labeling, warranty, life cycle management [procurement, usage, end of life, disposal/recycling], inventory [make, model, serial, number, asset tag])
- Documentation (service manuals, network diagrams, architecture diagrams, dataflow diagrams, recovery documentation, baseline documentation, change management policies, service level agreement, server configuration)
- Secure storage of sensitive documentation
 Once you’ve installed your servers, you must take additional steps to enable them to perform the roles you chose for them in the network. You also need to monitor and maintain the servers so that they continue to perform well. In addition, you want to avoid security-related issues such as malware infections and data breaches by instituting and following best practices with regard to patches, updates, and data security. Finally, you must develop systems that allow you to manage these critical organizational assets in a standardized method throughout the entire asset life cycle.
Once you’ve installed your servers, you must take additional steps to enable them to perform the roles you chose for them in the network. You also need to monitor and maintain the servers so that they continue to perform well. In addition, you want to avoid security-related issues such as malware infections and data breaches by instituting and following best practices with regard to patches, updates, and data security. Finally, you must develop systems that allow you to manage these critical organizational assets in a standardized method throughout the entire asset life cycle.
Server Roles and Requirements
Servers exist to serve the network and its users in some form. Each server has a certain role to play, although in small networks a server performs multiple roles. Each of those roles places different types of demand on the hardware and software of the server. Some roles demand lots of memory, whereas others place a heavier load on that CPU. By understanding each server role, you can more appropriately ensure that the proper resources are available to enable the server to successfully serve the network with as little latency and downtime as necessary. In this section we’ll explore the major server roles you are likely to encounter and the specific compute resources (CPU, memory, network, and disk) that are stressed in the process of performing those roles.
Web Server
Web servers are used to provide access to information to users connecting to the server using a web browser, which is the client part of the application. A web server uses HTTP as its transfer mechanism. This server can be contained within a network and made so it is only available within the network (called an intranet server) or it can be connected to the Internet where it can be reached from anywhere. To provide security to a web server it can be configured to require and use HTTPS, which uses SSL to encrypt the connection with no effort on the part of the user, other than being aware that the URL must use https rather than http.
Here are some of the components that should be maximized to ensure good performance in a web server:
Disk Subsystem Disk latency is one of the major causes of slow web performance. The disk system should be as fast as possible. Using high-speed solid-state drives can be beneficial, and if possible, you should deploy either a RAID 0 or RAID 5 configuration, either of which will improve the read performance. If fault tolerance is also a consideration, then go with RAID 5 since RAID 0 will give you no fault tolerance.
RAM Memory is also critical to a web server. Eighty percent of the web requests will be for the same 20 percent of content. Therefore, plenty of memory may ensure requested pages may still be contained in memory from which access is faster. You can help this situation by deploying web caching. This can be done on the proxy server if you use one.
CPU CPU is important but not a critical issue for a web server unless the server will be performing encryption and decryption. If that is the case, it may be advisable to use a network card with its own processor for this process.
NIC The NIC should be at a least 1 Gbps, and using multiple cards would be even better. The amount of traffic you expect will influence this.
Application Server
An application server is one that users connect to and then run their applications on. This means the server is doing all the heavy lifting while the user machine is simply sending requests to the server and displaying the output. In many cases this server is the middle tier in a three-tier architecture that accepts users’ requests to its application and then communicates with a database server where content is stored, as shown in Figure 3.1.

Figure 3.1 Three tiers
Here are some of the components that should be maximized to ensure good performance in an application server:
CPU This component is stressed on an application server since it is doing all of the processing on behalf of the clients. Multicore and multiple processors are advisable.
NIC Considering the traffic the server will be handling (and that could be in two directions if the server is running middleware), the NIC(s) should be 1 Gbps at least.
Disk The disk system should be fast but it’s not the most critical part of the equation for an application server.
Memory Application servers also require lots of memory, especially if acting as a middle tier to a backend database server.
Directory Services Server
A directory services server is one that accepts and verifies the credentials of users. Typically it not only authenticates them but also provides them with access to resources using single sign-on (SSO). SSO allows users to authenticate once and not be required to authenticate again to access the resources to which they have been given access. Moreover, these resources may be located across the network on various devices. One of the best examples is a domain controller in a Windows Active Directory domain. These servers are the point to which all users are directed when they need to log in to the network.
Here are some of the components that should be maximized to ensure good performance in a directory services server:
Disks Use a fast system, and since this function is so important, implement RAID 5 for fault tolerance and performance. Put the Active Directory (AD) database (ntds.dit) onto separate disk spindles. Allow at least 0.5 GB per 1,000 users when allocating disk space for the AD database.
Network Connections Although this will probably not be the bottleneck on the system, if other resources are sufficient it could become one. Ensure you have 1 Gbps cards. If encryption will be involved (which is highly likely), consider offloading this encryption to the network card.
Processor Multiple-core processors should be used if the server will be performing encryption. If you have not offloaded that encryption to the NIC, you should have multiple CPUs as well. Keep in mind that as the number of users goes up, you may need to add more processing power.
Memory The memory requirements depend on the size of the AD database or the ntds.dit file. You should have enough memory to hold this file or file with 20 percent additional space added. The ntds.dit file is located at %systemroot%
tds
tds.dit.
Database Server
A database server is one that runs database software such as SQL Server or Oracle. It contains information stored in the database and users can search the database, either directly by issuing commands or by using an application that does this through a GUI. Here are some of the components that should be maximized to ensure good performance in a database server:
CPU Your CPUs (yes, multiple) should be as fast as you can afford with multiple cores and plenty of cache. The specific number should be driven by the database software recommendations and the number of users.
Memory With respect to memory, you should fill all available slots with the cheapest memory you can get. That means smaller DIMMs (dual in-line memory modules) but more of them. For example, rather than filling 12 slots with 64 GB of memory, save some money for very little cost in speed by installing 32 GB DIMMs.
Disk You should use multiple disks in a RAID5 configuration so you get performance and fault tolerance. The exact number of disks depends on the features you are installing and the size of the database. Review the database software recommendations.
Network As with all enterprise servers you should use a 1 Gbps card at a minimum. If the server is critical, use multiple cards for fault tolerance and load balancing.
File Servers
File servers are used to store files that can be accessed by the network users. Typically users are encouraged or even required to store any important data on these servers rather than on their local hard drives, because these servers are typically backed up on a regular basis, whereas the user machines typically are not. Here are some of the components that should be maximized to ensure good performance in a file server:
Disk File servers should have significant amounts of storage space and may even have multiple hard drives configured in a RAID array to provide quicker recovery from a drive crash than could be provided by recovering with the backup.
CPU The number of processors is driven by the number of concurrent users you expect and whether you will be doing encryption on the server. As the number of users increases, at a certain point it becomes better to use more and slower processors rather than fewer and faster ones. This is because as many concurrent requests come in, multiple slower CPUs will handle the overall load better by spreading the requests among themselves, whereas fewer faster CPUs will try to keep up with a form of multitasking that is not as efficient.
Memory You should increase RAM in step with the increase in users accessing the file server. Start with the amount designated as a minimum for the operating system and add at least 50 percent to that.
NIC The same recommendation I gave for all of these roles applies. Use 1 Gbps NICs, and if this server will be very busy, use more than one for fault tolerance and load balancing.
Print Server
Print servers are used to manage printers, and in cases where that is their only role, they will manage multiple printers. A print server provides the spooler service to the printers that it manages, and when you view the print queue, you are viewing it on the print server. Many enterprise printers come with a built-in print server, which makes using a dedicated machine for the role unnecessary. Here are some of the components that should be maximized to ensure good performance in a print server:
Memory Print servers need lots of memory to hold the print jobs waiting in the print queue. The exact amount will depend on the number of users assigned to the printers being managed by this print server.
CPU The number and type of CPUs are impacted by the amount of processing power available on the print devices the server is managing. If they are heavy-duty enterprise printers with plenty of memory and processing power, you’ll need less on the server. A physical server will need less processing power than a virtual print server because the physical server can offload some of the print processing to the CPU on the graphics card whereas a virtual print server cannot.
Disk As is the case with processing power, if there is plenty of disk space on the print device, you will need less on the print server. One thing you should do is to move the spool file to a disk other than the one where the operating system is located. If your enterprise requires that completed print jobs be stored, ensure that you periodically remove them to keep them from eating up all the space.
NIC As always use 1 Gbps NICs, and if the server will be managing many printers and thus many users, you may want to have multiple NICs for fault tolerance and load balancing.
Messaging Server
Messaging servers run instant messaging software and allow users to collaborate in real time through either chat or video format. Here are some of the components that should be maximized to ensure good performance in a messaging server:
Memory The amount of memory required is a function of the number of concurrent connections. Users have varying habits when it comes to messaging. Some never use it and others use it constantly, so this is hard to predict and you may have to monitor the server usage and adjust memory accordingly.
Disk Include disk space for the operating system and the instant messaging software. The disk throughput of the system is critical so that the server can keep up, which means you should use faster disks.
CPU The processing power required is a function of the types of users you have. If most of the users are inactive (that is, they are connected but not chatting), then you will need less CPU than if a high percentage of them are active.
NIC This resource should be sized using the same guidelines as CPU. If you have many active users, you need faster and/or multiple NICs (as always, 1 Gbps).
Mail Server
Mail servers run email server software and use SMTP to send email on behalf of users who possess mailboxes on the server and to transfer emails between email servers. Those users will use a client email protocol to retrieve their email from the server. Two of the most common are POP3, which is a retrieve-only protocol, and IMAP4, which has more functionality and can be used to manage the email on the server. Here are some of the components that should be maximized to ensure good performance in a mail server:
Disk The disk system is most often the bottleneck on an email server. It should be high speed, perhaps solid state, and it should be set up in a RAID 5 configuration unless you are using a distributed configuration and the server is not the mail server.
Memory The amount of memory should be based not on the number of users, but rather on the amount of email they generate and receive. This is an item for which you should seek guidance from the vendor’s documentation.
CPU The amount of CPU used will be a function of the amount of email that is sent and received at a time, meaning if the email traffic is spread out evenly over the day, it will need less CPU than if the email all comes in during a 4-hour window.
Routing and Remote Access Service (RRAS) Server
A server running Windows Routing and Remote Access Service (RRAS) can act as a remote access (dial-up) and virtual private network (VPN) server, while it is also able to act as a router. In its role as a remote access or VPN server (its most common role), some of the components that should be maximized to ensure good performance are as follows:
CPU The amount of processing power is driven by the number of users you expect to be connecting concurrently and the type of data transfer. Transfers that create smaller packets will take more processing power as will a larger number of concurrent connections.
Memory Treat the sizing of the memory as you would CPU. As the number of concurrent users increases, memory needs will as well. Memory and CPU are the most stressed resource on this server.
Disk The disk system is not an area where contention usually occurs with RRAS servers.
NIC The speed and number of NICs will depend on the amount of concurrent traffic and the need for redundancy. If the VPN connection is mission critical, you should have multiple NICs.
Network Services Server
The next three server roles are critical to the functioning of the network and you should probably have more than one for redundancy. They provide automatic IP configurations to the devices, manage name resolution, and keep the devices in the network in sync from a time perspective, which is critical for the function of certain security features and for proper log analysis.
DHCP
Dynamic Host Configuration Protocol (DHCP) servers are used to automate the process of providing an IP configuration to devices in the network. These servers respond to broadcast-based requests for a configuration by offering an IP address, subnet mask, and default gateway to the DHCP client. While these options provide basic network connectivity, many other options can also be provided, such as the IP address of a Trivial File Transfer Protocol (TFTP) server that IP phones can contact to download a configuration file. Here are some of the components that should be maximized to ensure good performance:
CPU Processing power is not one of the critical resources on a DHCP server. Ensure you have the recommended speed for the operating system with the DHCP service installed as indicated by the operating system documentation.
Memory RAM is one of the critical components on the DHCP server. You should provide plenty of RAM. After deployment you may discover you need to add more if you find the server’s usage of memory to be exceeding its capacity.
Disk Disk is the second critical component. If you intend to host a large number of scopes (scopes are ranges of IP addresses) on the server, keep in mind that each time you add a scope you need more disk space.
NIC Although this is not a component that’s critical to the operation of DHCP, the NIC could become a bottleneck in the system if it is not capable enough or if there are not enough NICs. Use at least 1 Gbps NICs and consider the option of using multiple NICs.
DNS
Domain Name System (DNS) servers resolve device and domain names (website names) to IP addresses, and vice versa. They make it possible to connect to either without knowing the IP address of the device or the server hosting the website. Clients are configured with the IP address of a DNS server (usually through DHCP) and make requests of the server using queries. The organization’s DNS server will be configured to perform the lookup of IP addresses for which it has no entry in its database by making requests of the DNS servers on the Internet, which are organized in a hierarchy that allows these servers to more efficiently provide the answer. When the DNS servers have completed their lookup, they return the IP address to the client so the client can make a direct connection using the IP address. Here are some of the components that should be maximized to ensure good performance:
RAM Memory is the most important resource because the entire DNS zone file will be loaded into memory. As you add zones, or as a zone gets larger, you should add memory. If you expect the server to be answering large numbers of queries concurrently, then that will require additional memory as well.
Disk Disk is not a critical component, but it does need to be large enough to hold all of the zones as well.
NIC The NIC is not a critical resource unless it becomes a bottleneck during times when there is an overwhelming number of concurrent queries. If you find that to be the case often, add more NICs.
CPU CPU is not a critical resource, but if you expect a heavy query load then you should get the fastest processor the budget allows. The CPU can become a bottleneck just as the NIC can in times of high workload.
NTP
Network Time Protocol (NTP) servers are used as a time source by the devices in the network. When the devices are configured with the address of an NTP server, they will periodically check in with the server to ensure their time is correct. This service ensures that log entries that are time stamped can be properly interpreted and that digital certificates, which depend heavily on time, continue to function correctly. NTP servers do not typically have high resource requirements, and this service is a good candidate for adding to a server already performing another role.
Proper Server Maintenance Techniques
Like all networking devices, servers need some attention from time to time. If regular maintenance procedures are followed, there will be less downtime, fewer hardware issues, and less frequent headaches for all. In this section, we’ll look at what those procedures should be.
Change Management
The old saying “Too many cooks spoil the broth” applies when it comes to managing servers. When technicians make changes to the servers that are not centrally managed and planned, chaos reigns. In that environment, changes might be made that work at cross purposes. All organizations need a change management process whereby every change goes through a formal evaluation process before it is implemented.
This process ensures that all changes support the goals of the organization and that the impact of each change is anticipated before the change is made. There should be a change management board to which all changes are submitted for review. Only when the change has been approved should it be made.
Patch Management
You already know how important it is keep current on security patches, but that is not the only type of patch and update about which you should be concerned. In this section we’ll identify some of the types of updates that should be a part of a formal patch management policy. This policy should be designed to ensure that none of these types of updates fall through the cracks.
Operating System Updates
All operating system vendors periodically offer updates for their systems. These updates sometimes fix bugs or issues, and sometimes they add functionality. In some cases they close security loopholes that have been discovered. Regardless of the reason for their issuance, you should obtain, test, and deploy all of these updates. Many vendors like Microsoft makes that simple by including tools such as Windows Update that allow you to automate the process. If the operating system does not provide such a utility, then you should take it upon yourself to seek it out. In Exercise 3.1 you will schedule updates using the Windows Update tool in Windows Server 2012 R2.
Application Updates
Many servers run applications and services that require updating from time to time. The server might be running a database program or email software or any of the services required for the server to perform the roles described in the earlier section “Server Roles and Requirements.” Although keeping up with these updates may not be as simple as operating system updates (which in many cases can be automated), you should develop a system to keep aware of these updates when they are available. You might get on the mailing list of the application vendor so that you can be informed when updates are available. If all else fails, make it a point to visit their website from time to time and check for these updates.
Security Software Updates
These are among the most critical updates we will cover in this section. These updates include those for antivirus and antimalware. This software should be regularly updated (with particular interest paid to the definition files). While steps and options to configure these updates are unique to each product, with respect to the built-in Windows tools, such as Windows Defender, those definitions will be updated along with other updates you receive from Windows Update. Most vendors of security software provide a mechanism to download and apply these updates automatically. You should take advantage of such a mechanism if it is available. Although this software is important for users’ machines, it is even more essential for servers, which are frequent targets of attacks.
Firmware Updates
Any software that is built into a hardware device is called firmware. Firmware is typically in flash ROM and can be updated as newer versions become available. An example of firmware is the software in a laser printer that controls it and allows you to interact with it at the console (usually through a limited menu of options). Firmware updates are often released by hardware vendors. You should routinely check their websites for updates that you need to download and install.
Device Driver Updates
Device drivers are files that allow devices to communicate with the operating system. Called drivers for short, they’re used for interacting with printers, monitors, network cards, sound cards, and just about every type of hardware attached to the server. One of the most common problems associated with drivers is not having the current version—as problems are fixed, the drivers are updated. Typically driver updates don’t come into the picture until something stops working. When that is the case, you should consider the possibility that a driver update for the device might solve the issue before wasting a lot of time troubleshooting.
Compatibility Lists
When deploying a new server or when adding devices and applications to a server, it can be highly beneficial to ensure compatibility between the new addition and the server before spending money. Vendors of both software and hardware create compatibility lists that can be used to ensure that a potential piece of software or hardware will work with the server. These compatibility lists fall into three categories, as covered in the following sections.
Operating Systems
Major operating system vendors issue several types of compatibility lists. Some list the hardware requirements of each operating system. Others list hardware devices that have been tested and are known to work with the operating system. Microsoft calls its list the Windows Compatible Products List. You’ll find it here: https://sysdev.microsoft.com/en-US/Hardware/lpl/.
Hardware
Vendors of the hardware we often connect to our servers also create compatibility lists that describe the operating systems and other pieces of hardware with which their devices are compatible.
Applications
Finally, vendors of software applications also issue compatibility lists that describe the operating systems on which their software will run and the hardware requirements of the system on which the software will be installed.
Testing and Validation
We’ve just finished discussing all kinds of updates that you might apply to a server. Because servers are so important to the function of the network, you must treat updates for them with a dose of caution and skepticism. It is impossible for vendors to anticipate every scenario in which the server might be operating and thus impossible for them to provide assurance that the update won’t break something (like a mission-critical operation). With the potential exception of security updates, you should always test the updates and validate their compatibility with your set of hardware and software.
These tests should occur in a test network and not on production servers. One of the benefits of having a virtualization environment is the ability to take images of your servers and test the updates on those images in a virtual environment. Once the updates have been validated as compatible, you can deploy them to the live servers.
Outages and Service-Level Agreements
IT support departments typically have written agreements with the customers they support called service-level agreements (SLAs). In some cases these agreements are with other departments of the same company for which they provide support. These agreements specify the type of support to be provided and the acceptable amount of time allowed to respond to support calls.
Typically these time windows are different for different types of events. For example, they may be required to respond to a server outage in 20 minutes, whereas responding to a user having problems with a browser may only require a response by the end of the day. The following sections explore some of the issues that might be covered in a formal SLA as well as other related issues.
Scheduled Downtime
An SLA might specify that taking any infrastructure equipment down for maintenance requires prior notification and that the event may only occur during the evening or on the weekend. This type of event is called scheduled downtime. It is important that when you schedule this event, you allow enough time in the window to accomplish what you need to, and you should always have a plan in case it becomes obvious that the maintenance cannot be completed in the scheduled downtime.
Unscheduled Downtime
Unscheduled downtime is the nightmare of any administrator. This is when a device is down or malfunctioning outside of a scheduled maintenance window. Some SLAs might include an unscheduled downtime clause that penalizes the support team in some way after the amount of unscheduled downtime exceeds a predetermined level. If the support is being provided to a customer, there might be a financial penalty. If the SLA applies to another department in the same organization, the penalty might be in a different form.
Impact Analysis
Another typical issue requirement in most SLAs is that any schedule downtime should be communicated to all users and that the communication should include the specific parties that will be affected by the downtime and exactly what the impact will be. For example, a notification email describing the scheduled downtime might include the following:
- Departments affected
- Specific applications or service impacted
- Expected length of downtime
Client Notification
SLAs should also specify events that require client notification and the time period in which that must occur. It will cover all scheduled downtime but should also address the time period in which notifications should be sent out when unscheduled events occur. It might also discuss parameters for responding to client requests.
MTTR
One of the metrics that is used in planning both SLAs and IT operations in general is mean time to repair (MTTR). This value describes the average length of time it takes a vendor to repair a device or component. By building MTTR into the SLA, IT can assure that the time taken to repair a component or device will not be a factor that causes them to violate the SLA requirements. Sometimes MTTR is considered to be from the point at which the failure is first discovered to the point at which the equipment returns to operation. In other cases it is a measure of the elapsed time between the point where repairs actually begin and the point at which the equipment returns to operation. It is important that there is a clear understanding by all parties with regard to when the clock starts and ends when calculating MTTR.
Performance Monitoring
Earlier in this chapter, we covered the resources typically required by certain server roles. As noted, those were only guidelines and starting points in the discussion based on general principles. You should monitor the servers once deployed on a regular basis to determine whether the system is indeed handling the workload. When monitoring resources, you select performance counters that represent aspects of the workload the resource is undergoing. But first you need to know what normal is for your server.
Comparison Against Performance Baseline
If you have ever tried to look up a particular performance metric on the Internet to find out what a “normal” value is, you may be quite frustrated that you can’t get a straight answer. This is because you have to define what is normal for your network. This is done by creating a set of performance metrics during normal operations when all is working well. While earlier in this chapter we listed some rough guidelines about certain metrics, that is all they are: guidelines.
Only until you have created this set of values called a performance baseline can you say what is normal for your network. Creating the set of values should be done during regular operations, not during either times of unusual workload or times of very little workload. After this you can compare the performance metrics you generate later with this baseline. Let’s look at the four main resources.
CPU Utilization
When monitoring CPU, the specific counters you use depends on the server role. Consult the vendor’s documentation for information on those counters and what they mean to the performance of the service or application. Common counters monitored by server administrators are
Processor\% Processor Time The percentage of time the CPU spends executing a non-idle thread. This should not be over 85 percent on a sustained basis.
Processor\% User Time Represents the percentage of time the CPU spends in user mode, which means it is doing work for an application. If this value is higher than the baseline you captured during normal operation, the service or application is dominating the CPU.
Processor\% Interrupt Time The percentage of time the CPU receives and services hardware interrupts during specific sample intervals. If this is over 15 percent, there could be a hardware issue.
SystemProcessor Queue Length The number of threads (which are smaller pieces of an overall operation) in the processor queue. If this value is over 2 times the number of CPUs, the server is not keeping up with the workload.
Memory Utilization
As with CPUs, different server roles place different demands on the memory, so there may be specific counters of interest you can learn by consulting the vendor documentation. Common counters monitored by server administrators are
Memory\% Committed Bytes in Use The amount of virtual memory in use. If this is over 80 percent, you need more memory.
MemoryAvailable Mbytes The amount of physical memory (in megabytes) currently available. If this is less than 5 percent, you need more memory.
MemoryFree System Page Table Entries The number of entries in the page table not currently in use by the system. If the number is less than 5,000, there may be a memory leak (memory leaks occur when an application is issued memory that is not returned to the system. Over time this drains the server of memory.).
MemoryPool Non-Paged Bytes The size, in bytes, of the non-paged pool, which contains objects that cannot be paged to the disk. If the value is greater than 175 MB, you may have a memory leak (an application is not releasing its allocated memory when it is done).
MemoryPool Paged Bytes The size, in bytes, of the paged pool, which contains objects that can be paged to disk. (If this value is greater than 250 MB, there may be a memory leak.)
MemoryPages per Second The rate at which pages are written to and read from the disk during paging. If the value is greater than 1,000 as a result of excessive paging, there may be a memory leak.
Network Utilization
As you learned in the section “Server Roles and Requirements,” the NIC can become a bottleneck in the system if it cannot keep up with the traffic. Some common counters monitored by server administrators are
Network InterfaceBytes Total/Sec The percentage of bandwidth of which the NIC is capable that is currently being used. If this value is more than 70 percent of the bandwidth of the interface, the interface is saturated or not keeping up.
Network InterfaceOutput Queue Length The number of packets in the output queue. If this value is over 2, the NIC is not keeping up with the workload.
Disk Utilization
On several of the server roles we discussed, disk was the critical resource. When monitoring the disk subsystem, you must consider two issues: the speed with which the disk is being accessed and the capacity you have available. Let’s examine those metrics in more detail.
Disk IOPS
Disk Input/Output Operations per Second (IOPS) represents the number of reads and writes that can be done in a second. One of the advantages of newer solid-state drives (SSDs) is that they exhibit much higher IOPS values than traditional hard disk drives. For example, a 15,000 rpm SATA drive with a 3 Gb/s interface is listed to deliver approximately 175–210 IOPS, whereas an SSD with a SATA 3 Gb/s interface is listed at approximately 8,600 IOPS (and that is one of the slower SSD drives).
Storage Capacity
The second metric of interest when designing a storage solution is capacity. When planning and managing storage capacity, consider the following questions:
- What do you presently need? Remember that this includes not only the total amount of data you have to store but also the cost to the system for fault tolerance. For example, if data is located on a RAID 1 or mirrored drive, you need twice as much space for the data. Moreover, if the data is located on a RAID 5 array, your needs will depend on the number of drives in the array. As the number of drives in the array go up, the amount of space required for the parity information goes down as a percentage of the space in the drive. For example, with three drives you are losing 33 percent of the space for parity, but if you add another drive, that goes down to 25 percent of the space used for parity. Add another, and it goes down to 20 percent.
- How fasts are the needs growing? Remember that your needs are not static. They are changing at all times and probably growing. You can calculate this growth rate manually or you can use capacity-planning tools. If you have different classes of storage, you may want to make this calculation per class rather than overall because the growth rates may be significantly different for different classes.
- Are there major expansions on the table? If you are aware that major additions are occurring, you should reflect that in your growth rate. For example, if you know you adding a datacenter requiring a certain amount of capacity, that capacity should be added to the growth rate.
In many cases you find yourself in a crunch for space at a time when capacity cannot be added. In such cases, you should be aware of techniques for maximizing the space you have. Some of those approaches are as follows:
Using Disk Deduplication Tools In many cases, data is located on the same drive. Deduplication tools remove this redundancy while still making the data available at any location it was previously located by pointing to the single location. This process can be done after the data is on the drive or it can be implemented inline, which means data being written to the drive is examined first to see if it already exists on the drive. These two processes are shown in Figure 3.2.

Figure 3.2 Deduplication techniques
Archiving Older Data You can also choose to have the older data moved off main storage to backup tapes or media to free up space.
Processes and Services Monitoring
On a more granular basis, you can separate the workload created by specific applications and services on a server. You do this by monitoring performance counters specific to the service or application. Often this exercise is undertaken when a server is experiencing a high workload and you need to determine the source of this workload. If you need to identify the performance counter that applies to an application or service, the best place to go for that information is the application or operating system vendor.
Log Monitoring
When you discover that a service or application is using more resources than normal, you may want to investigate the logs related to that service or application. Most server operating systems create these logs, or you may decide that it is easier to invest in a log monitoring system that can grab these logs off multiple servers and make them available to you in a central interface of some sort. This can be done in Windows by creating what are called event subscriptions. This simply means that one server subscribes to access a log on another server and make it available in the console of the first server. This is also called log forwarding. This concept is shown in Figure 3.3.

Figure 3.3 Log forwarding
Hardware Maintenance
Like workstations, servers last longer, perform better, and break down less frequently when they get proper care. In this section we’ll list regular hardware maintenance activities you should perform and identify specific areas on which you should concentrate.
Check System Health Indicators
First there are some indicator mechanisms that will be provided by the vendor of the hardware and the software that can give you an early warning that something is amiss or is about to go bad. You should always react to these indicators in the same way you would react to a warning that your car is overheating, because they typically don’t come into play until the situation is getting serious.
LEDs
Most network devices, including servers, have LEDs on them that indicate certain things. The LED diagram for a Sun Blade X6250 Server Module is shown in Figure 3.4. The purpose of the LEDS and buttons is as follows:
- #1: LED that helps you identify which system you are working on
- #2: Indicates whether the server module is ready to be removed from the chassis
- #3: Service Action Required
- #4: Power/OK

Figure 3.4 LEDs
Error Codes
Many servers come with integrated diagnostics that will generate error codes. These are usually text-based interfaces that you can access even when the server is having significant issues. In other cases, you receive error code messages when you reboot the server (which is often done when issues occur). For example, Dell servers issue these messages and provide tables on their website to help you not only interpret the problem, but in many cases, tell you exactly what to do to resolve the issue.
For example, if you receive the following message when rebooting, it indicates that something has changed and it suggests that if this is unexpected (you neither added nor removed memory), you have a piece of bad memory that is not now being included in the memory amount:
Amount of memory has changedBeep Codes
Another possible source of information when troubleshooting server issues are the beep codes heard when rebooting the server. Like workstations, servers emit beep codes that indicate the status of the POST during boot. For example, an IBM blade server emits two long beeps followed by a short beep when a microprocessor register test fails. By using the online list of code descriptions (or the documentation), you will find that the document not only lists the meaning of the pattern but tells you exactly what to do (in this instance, reseat the processor). It goes on to tell you that if reseating the processor doesn’t work, you should change out the processor, and if that doesn’t work, change out the board.
LCD Messages
Many hardware devices like servers also have small LCD screens on the front that may be a source of messages that are helpful during troubleshooting. The Dell PowerEdge has the panel shown in Figure 3.5.

Figure 3.5 Dell LCD
Not only is this panel used to make configurations, but it also displays error messages. When it does this, it changes the backlight color from blue to amber so that you notice it quicker. The types of alerts covered are as follows:
- Cable and board presence
- Temperature
- Voltages
- Fans
- Processors
- Memory
- Power supplies
- BIOS
- Hard drives
IBM calls their system light path diagnostics. This is a system consisting of an LED panel on the front and a series of LEDs inside the box near various components. One of the LEDs is the Information LED, and when it indicated there is an error, you can open the box and LEDs inside the box might be lit near the problem component, as shown in Figure 3.6.

Figure 3.6 IBM Light path diagnostics
Replace Failed Components
Inevitably, parts will go bad and you will have to replace them. Common components replacements are covered in this section.
Fans
Servers typically have multiple fans. For example, a Dell PowerEdge has a fan on the chassis back panel and a front fan beneath the drive bays. In Exercise 3.2 you’ll change out the one in the back panel.
Hard Drives
At one time, hard disk drives had a higher rate of unexpected failures with respect to the mechanical parts and SSDs had a shorter normal lifetime. However, this is changing as SSDs become more and more durable. At any rate, you will at some point have to replace a drive. The exact method depends on the type of drives. In Exercise 3.3 you’ll use a Dell 1850 rack server and look at changing out a drive.
RAM
Replacing RAM in a server is not all that different from doing so in a workstation. The box looks different but otherwise the basic steps are the same. In Exercise 3.4 you’ll use an IBM blade server.
Backplanes
Servers have backplanes that abut the drives and make a connection with the drive so no cables are required. These can go bad and sometimes need replacing. In Exercise 3.5 you’ll do this on a Dell PowerEdge 2650.
Batteries
Yes, servers have system batteries and they can die and need replacing. Always use the type of battery recommended by the vendor. In Exercise 3.6 you’ll use an IBM System x3250 M4.
Preventive Maintenance
Even when the servers are humming along happily with no issues, there are maintenance tasks that, if performed regularly, will increase the life of your servers and ward off avoidable issues. Two of these will go a long way toward avoiding overheating issues.
Clearing Dust
Dust will accumulate inside the server and, if it is not removed, will act as an insulator to the components and increase the likelihood of overheating. When cleaning the dust, use an antistatic vacuum or use compressed air. If you use compressed air, make sure you are blowing the dust out of the server so it doesn’t just go into the air and land back in the same area.
Check Proper Air Flow
Although clearing the dust is important while you are inside the box, you should examine the server while running and ensure that the fans are working together to ensure proper airflow. This will be less of a concern if the server is in the stock condition in which you purchased it because the vendor probably made sure that the fans were positioned properly. But if you have made changes to the server, perhaps adding processors or new cards in the box, the airflow may have been altered in an unfavorable way or may even be significantly blocked.
Generally speaking, you want the air to enter the front of the server and proceed unimpeded toward the back and then to exit the server at the back. Anything added to the server that disrupts this flow needs attention. Also, any fans that may be added should not push hot air toward the front of the server.
Proper Shutdown Procedures
When shutting down the server for maintenance, make sure you follow proper shutdown procedures. There are two types of reboots:
Soft Reboot Better for the system than a hard reboot, a soft reboot allows the proper shutdown of all running applications and services, yet requires that you be logged in as either administrator or root and that the server be in a responsive state. It is also good to know that since power is not completely removed, memory registers are not cleared.
Hard Reboot A hard reboot is not good for the system and equivalent to turning off the power and turning it back on. However, in cases where the server is unresponsive, a hard reboot may be the only option.
Always use a soft reboot whenever possible. A hard reboot does not give the server an opportunity to properly shut down all running applications and services.
Fault Tolerance and High Availability Techniques
Since servers are so critical to the operation of the network, in many cases we need to protect ourselves against the negative effects of a server going down. In other cases, we simply need to add more server horsepower to meet a workload. We accomplish these goals through fault tolerance and high availability techniques. This section explores several types of these methods.
Clustering
Clustering is the process of combining multiple physical or virtual servers together in an arrangement called a cluster, in which the servers work together to service the same workload or application. This may be done to increase performance or to ensure continued access to the service if a server goes down, or its goal could be both. A server cluster is generally recommended for servers running applications that have long-running in-memory state or frequently updated data. Typical uses for server clusters include file servers, print servers, database servers, and messaging servers. Clustering can be implemented in one of two ways: active/active or active/passive.
Active/Active
In an active/active cluster, both or all servers are actively servicing the workload. That doesn’t necessarily mean they are running the same applications at all times, but only that they are capable of taking over the workload of an application running on another cluster member if that member goes down. For example, in Figure 3.7 the server on the left is running two applications prior to failing, whereas the server on the right is running only one of the three applications. After the failure, the server on the right takes over the work of all three applications. With this arrangement you must ensure that the remaining server can handle the total workload.

Figure 3.7 Active/active cluster
Active/Passive
In an active/passive cluster, at least one of the servers in the cluster is not actively working but simply sitting idle until a failure occurs. This is shown in Figure 3.8. This arrangement comes at the cost of having a server sitting idle until a failure occurs. It has the benefit of providing more assurance that the workload will continue to be serviced with the same level of resources if the servers are alike.
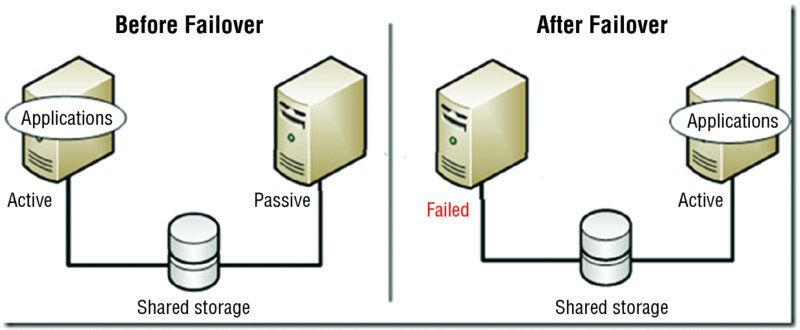
Figure 3.8 Active/passive cluster
Load Balancing
A second form of fault tolerance that focuses more on providing high availability of a resource is load balancing. In load balancing a frontend device or service receives work requests and allocates the requests to a number of backend servers. This type of fault tolerance is recommended for applications that do not have long-running in-memory state or frequently updated data. Web servers are good candidates for load balancing. The load balancing device or service can use several methods to allocate the work. Let’s look at the most common allocation method, round robin, and also talk about a key function in the load balancing system, the heartbeat.
Round Robin
In a round robin allocation system, the load balancer allocates work requests to each server sequentially, resulting in each getting an equal number of requests. As shown in Figure 3.9, this could mean that a user may make two requests that actually go to two different servers.

Figure 3.9 Round robin load balancing
Heartbeat
A heartbeat connection is a connection between servers in a load balancing scenario across which the servers send a signal (called a heartbeat) used to determine when the other server is down. If one server goes down, the other will service the entire workload. The two servers are typically identical (content-wise), and this is used often as a failover technique. It may be a direct physical connection, as shown in Figure 3.10, or it might be done over the network.

Figure 3.10 Heartbeat connection
Asset Management and Documentation
You would be amazed at how many network administrators can’t tell you exactly how many devices of a certain type they have, and if they can, they can’t tell you where they all are. This is the result of a combination of poor record keeping and frequent job turnover. While the job turnover may just be an unfortunate characteristic of the business, it should not cause an issue if proper documentation policies are followed. In this section the proper management of assets through the entire asset life cycle will be covered. We’ll also talk about the type of documentation you keep and how it should be handled, especially sensitive information.
Asset Management
Proper asset management is not rocket science. It boils down to knowing exactly what you have, when you got it, where it is, and where the license to use it is. Most server administrators don’t set out to intentionally exercise poor asset management; they simply don’t assign it the importance it requires to be done correctly. Let’s break the process down and talk about its individual parts and why each is important.
Licensing
When you purchase software, you are purchasing the right to use it. At any point in time you may face a software audit from one of the major vendors. When this occurs, you will need to be able to provide written proof that you possess a number of licenses for a particular product that is equal or greater than the number of installations in your network. When that time comes, will you be able to locate these? They should be kept in a safe place where you can put your hand on them at a moment’s notice. That does not mean the records can’t be digital, but they must be available.
Labeling
Labeling servers, workstations, printers, ports on infrastructure devices (routers and switches), and other items is another form of asset documentation that often doesn’t receive enough attention. Not only does this make your day-to-day duties easier, it makes the process of maintaining accurate records simpler and supports a proper asset management plan. When periodic inventories are taken (you are doing that, right?), having these items labeled makes the process so much quicker. This goes for cables in the server room as well.
Warranty
Warranty information should be readily available to you when equipment breaks. You should never spend time or money repairing items that are still under warranty. It should not take you hours to locate this information when that time comes. Keep this paperwork or its digital equivalent close at hand in the same way you would the licensing information.
Life-Cycle Management
Managing assets becomes easier if you understand that an asset goes through various stages called its life cycle. Consequently, life-cycle management comprises the activities that we undertake with respect to the asset at various points in the life cycle. Let’s examine these stages.
Procurement
This includes all activities that might go into purchasing a product. It includes activities such as product research, requests for bids, product selection, and delivery.
Usage
This stage includes day-to-day maintenance tasks that are involved in using the item. This might encompass things like updating the software or firmware or tasks that would be unique to the device type, such as defragmenting a hard drive.
End of Life
End of life can mean a couple of different things. From the vendor perspective, it probably means that they are no longer providing support for a product. From your perspective, it probably means that the product no longer meets your needs or that you have decided to replace the item with a new version. It could also mean that changes in your business process make the item no longer necessary.
Disposal/Recycling
The final stage in the life of an asset is its disposal. Regardless of your approach—whether it is throwing the item away, donating the item to charity, or turning the item in for recycling—you should ensure that all sensitive data is removed. This requires more than simple deletion, and the extent to which you go with this process depends on how sensitive that data is. Degaussing is a way to remove the data for good. With extremely sensitive data, you may find it advisable to destroy the device.
Proactive Life-Cycle Management
Here’s a final word of advice: you may find it beneficial to stagger replacement cycles so that your entire server room doesn’t need to be replaced all at once. It’s much easier to get smaller upgrades added to the budget.
Inventory
As I mentioned at the start of this section, asset management includes knowing what you have. You can’t know something is missing until you take an inventory, so you should take inventory on a regular basis. So what type of information is useful to record? You may choose to record more, but the following items should always be included:
Make The manufacturer of the device should be recorded as well as the name they give the device.
Model The exact model number should be recorded in full, leaving nothing out. Sometimes those dangling letters at the end of the model number are there to indicate how this model differs from another, or they could indicate a feature, so record the entire number.
Serial Number The serial number of the device should be recorded. This is a number that will be important to you with respect to the warranty and service support. You should be able to put your hands on this number quickly.
Asset Tag If your organization places asset tags on devices, it probably means you have your own internal numbering or other identification system in place. Record that number and any other pertinent information that the organization deems important enough to place on the asset tag, such as region and building.
Documentation
Along with a robust asset management plan, you should implement a formal plan for organizing, storing, and maintaining multiple copies in several locations of a wide array of documentation that will support the asset management plan. Just as you should be able to put your hands on the inventory documentation at a moment’s notice, you should be able to obtain needed information from any of the following documents at any time.
Service Manuals
All service manuals that arrive with new hardware should be kept. They are invaluable sources of information related to the use and maintenance of your devices. They also contain contact information that may make it easier to locate help at a critical time. Many manuals have troubleshooting flowcharts that may turn a 4-hour solution into a 30-minute one. If a paper copy has not been retained, you can usually obtain these service manuals online at the vendor website.
Network Diagrams
All network diagrams should be kept in both hard copy and digital format. Moreover, these diagrams must be closely integrated with the change management process. The change management policy (covered later in this section) should specifically call for the updating of the diagram at the conclusion of any change made to the network that impacts the diagram and should emphasize that no change procedure is considered complete unless this update has occurred.
Architecture Diagrams
Any diagrams created to depict the architecture of a software program or group of programs should be kept. When the original developers are no longer with the company, they are invaluable to those left behind to understand the workings of the software. There may multiple layers of this documentation. Some may only focus on a single piece of software whereas others may depict how the software fits into the overall business process of the company. An example of such a diagram, called an enterprise architecture diagram, is shown in Figure 3.11.

Figure 3.11 Enterprise architecture diagram
Dataflow Diagrams
While some of your network diagrams will focus on the physical pieces of the network, others will be focused on the flow of data in the network in the process of doing business. So these may depict a workflow and how information involved in a single transaction or business process goes from one logical component in the network to another. An example of a dataflow diagram for an order system is shown in Figure 3.12.

Figure 3.12 Data flow for order entry
Recovery Documentation
If your organization has a disaster recovery plan, that plan should call for recovery documentation. It should outline, in detail, the order with which devices should be recovered in the event of a disaster that causes either complete or partial destruction of the facility. It should also cover the steps to be taken in lesser events as well, such as a power outage, the theft of a device, or the failure of a device, and data recovery procedures as well.
Baseline Documentation
Earlier you learned the importance of creating performance baselines for major systems. The baselines will be used as a comparison point to readings taken at regular intervals. This means that the baseline data will need to be available at all times. A plan should be in place to consider at regular intervals whether major changes in the network may require new baselines to be taken.
Change Management Policies
As a part of the overall security policy, the change management policy will outline the steps involved in suggesting, considering, planning, executing, and documenting any change in the server configuration. No change should be made without it undergoing this process. The policy should be available at times for consultation when questions arise about making configuration changes.
Service-Level Agreement
Service-level agreements (SLAs) can be made with customers or with departments within the organization. These documents describe the type of service to be provided, in what format, in what time frame, and at what cost. Some SLAs are executed with vendors that provide service to the organization. These documents should be readily available when disagreements arise and clarifications need to be made.
Server Configuration
The exact configuration of every server should be fully recorded and updated any time a change is made. The following is information that should be included:
General
- Server name
- Server location
- Function or purpose of the server
- Software running on the server, including operating system, programs, and services
Hardware
- Hardware components, including the make and model of each part of the system
Configuration Information
- Event logging settings
- Services that are running
- Configuration of any security lockdown tool or setting
- Configuration and settings of software running on the server
Data
- Types of data stored on the server
- Owners of the data stored on the server
- Sensitivity of data stored on the server
- Data that should be backed up, along with its location
- Users or groups with access to data stored on the server
- Administrators, with a list of rights of each
- Authentication process and protocols for users of data on the server
- Authentication process and protocols used for authentication
- Data encryption requirements
- Authentication encryption requirements
Users
- Account settings
- List of users accessing data from remote locations and type of media they access data through, such as the Internet or a private network
- List of administrators administrating the server from remote locations and type of media they access the server through
Security
- Intrusion detection and prevention method used on the server
- Latest patch to operating system and each service running
- Individuals with physical access to the area the server is in and the type of access, such as key or card access
- Emergency recovery disk and date of last update
- Disaster recovery plan and location of backup data
Secure Storage of Sensitive Documentation
No discussion of documentation storage would be complete without covering storage of sensitive documents. There should be a system of data classification that extends to cover sensitive documents such as contracts, leases, design plans, and product details. The data protection method accorded each category should reflect its sensitivity label. Any such documents labeled sensitive should be encrypted and stored separately from other categories of data. Examples of this sort of information are
- Personally identifiable information, which in part or in combination can be used to identify a person
- Human resources information
- Financial documents that are not public
- Trade secrets and propriety methods
- Plans and designs
- Any other documents that the company deems to be sensitive
Summary
In this chapter you learned about server roles and the requirements for those roles. We also covered proper server maintenance techniques such as patch management, performance monitoring, and hardware maintenance. You learned the importance of change management and the steps in replacing components in the server. Finally, we discussed asset management from the perspective of the asset life cycle and the role that proper documentation management plays in proper network management.
Exam Essentials
Compare and contrast server roles and requirements for each. Understand the possible roles servers can play in the network and describe the hardware requirements of these roles.
Perform proper server maintenance. Identify the procedures involved in patch management and updating drivers and firmware. Describe how SLAs are used to control the delivery of service to the network. List the major resources that should be monitored during performance monitoring.
Explain the importance of asset management and documentation. List what should be included when creating an asset inventory. Understand the importance of organizing and maintaining documentation. Describe some of the types of sensitive documents that require special treatment.
Review Questions
You can find the answers in the Appendix.
-
Which server role uses HTTP as its transfer mechanism?
- Web
- Application
- Directory
- Database
-
Which resource is stressed the most on an application server?
- Disk
- NIC
- CPU
- Memory
-
Which of the following server roles is used to authenticate users to the network?
- Web
- Application
- Directory
- Database
-
Which server role automates the process of providing an IP configuration to devices in the network?
- DNS
- Routing and Remote Access
- DHCP
- NTP
-
Which server role is critical to the operation of digital certificates?
- DNS
- Routing and Remote Access
- DHCP
- NTP
-
Which server role resolves hostnames to IP addresses?
- DNS
- Routing and Remote Access
- DHCP
- NTP
-
Which of the following are the software stubs that allow devices to communicate with the operating system?
- Drivers
- Patches
- Shims
- Manifests
-
Which of the following describes the average length of time it takes a vendor to repair a device or component?
- MTBF
- MMTR
- MTTR
- MTR
-
Which of the following represents aspects of the workload the resource is undergoing?
- Counters
- Alerts
- Metrics
- Markers
-
Which of the following is not one of the four major resources?
- Memory
- CPU
- Disk
- Pagefile
-
Which of the following is the percentage of time the CPU spends executing a non-idle thread?
- Processor\% Processor Time
- Processor\% User Time
- Processor\% Interrupt Time
- SystemProcessor Queue Length
-
Which of the following is the amount of physical memory, in megabytes, available for running processes?
- Memory\% Committed Bytes in Use
- MemoryPool Non-Paged Bytes
- MemoryAvailable Mbytes
- MemoryPool Paged Bytes
-
What is a common disk metric that describes how fast the disk subsystem is able to read and write to the drive?
- ILO
- IOPS
- IOS
- TIOS
-
To which component do drives abut and make a connection with the server so no cables are required?
- Frontplane
- Drive board
- Backplane
- Disk plane
-
Which of the following allows the proper shutdown of all running applications and services?
- Hard reboot
- Soft reboot
- Slow reboot
- Easy boot
-
Which type of fault tolerance is recommended for servers running applications that do not have long-running in-memory state or frequently updated data?
- Load balancing
- Hot site
- Clustering
- Cold site
-
Which of the following means that the device is no longer supported by the vendor?
- Proprietary
- Legacy
- End of life
- Expiration
-
What drives the amount of memory for a print server?
- Number of printers
- Number of users assigned to the printer
- Size of the network
- Fault tolerance required
-
Which of the following protocols is used when mail servers send email?
- POP3
- SMTP
- SNMP
- IMAP4
-
Which RAID type increases fault tolerance and performance?
- RAID 0
- RAID 1
- RAID 3
- RAID 5