
Chapter 7. Security Operations
This chapter covers the following topics:
![]() Investigations: Concepts discussed include forensic and digital investigations and evidence.
Investigations: Concepts discussed include forensic and digital investigations and evidence.
![]() Investigation Types: Concepts discussed include operations, criminal, civil, regulatory, and eDiscovery investigations.
Investigation Types: Concepts discussed include operations, criminal, civil, regulatory, and eDiscovery investigations.
![]() Logging and Monitoring Activities: Concepts discussed include audit and review, intrusion detection and prevention, security information and event management, continuous monitoring, and egress monitoring.
Logging and Monitoring Activities: Concepts discussed include audit and review, intrusion detection and prevention, security information and event management, continuous monitoring, and egress monitoring.
![]() Resource Provisioning: Concepts discussed include asset inventory, configuration management, physical assets, virtual assets, cloud assets, and applications.
Resource Provisioning: Concepts discussed include asset inventory, configuration management, physical assets, virtual assets, cloud assets, and applications.
![]() Security Operations Concepts: Concepts discussed include security operations topics, including need to know/least privilege; managing accounts, groups, and roles; separation of duties; job rotation; sensitive information procedures; record retention; monitoring special privileges; information life cycle; and service-level agreements.
Security Operations Concepts: Concepts discussed include security operations topics, including need to know/least privilege; managing accounts, groups, and roles; separation of duties; job rotation; sensitive information procedures; record retention; monitoring special privileges; information life cycle; and service-level agreements.
![]() Resource Protection: Concepts discussed include protecting tangible and intangible assets and asset management.
Resource Protection: Concepts discussed include protecting tangible and intangible assets and asset management.
![]() Incident Management: Concepts discussed include event versus incident, incident response team and incident investigations, rules of engagement, authorization, scope, incident response procedures, incident response management, and the steps in the incident response process.
Incident Management: Concepts discussed include event versus incident, incident response team and incident investigations, rules of engagement, authorization, scope, incident response procedures, incident response management, and the steps in the incident response process.
![]() Preventive Measures: Concepts discussed include clipping levels, deviations from standards, unusual or unexplained events, unscheduled reboots, unauthorized disclosure, trusted recovery, trust paths, input/output controls, system hardening, vulnerability management systems, IDS/IPS, anti-malware/antivirus, firewalls, whitelisting/blacklisting, third-party security services, sandboxing, and honeypots/honeynets.
Preventive Measures: Concepts discussed include clipping levels, deviations from standards, unusual or unexplained events, unscheduled reboots, unauthorized disclosure, trusted recovery, trust paths, input/output controls, system hardening, vulnerability management systems, IDS/IPS, anti-malware/antivirus, firewalls, whitelisting/blacklisting, third-party security services, sandboxing, and honeypots/honeynets.
![]() Patch Management: Concepts discussed include the enterprise patch management process.
Patch Management: Concepts discussed include the enterprise patch management process.
![]() Change Management Process: Concepts discussed include the change management process.
Change Management Process: Concepts discussed include the change management process.
![]() Recovery Strategies: Concepts discussed include redundant systems, facilities, and power; fault-tolerance technologies; insurance; data backup; fire detection and suppression; high availability; quality of service; system resilience; and creating recovery strategies.
Recovery Strategies: Concepts discussed include redundant systems, facilities, and power; fault-tolerance technologies; insurance; data backup; fire detection and suppression; high availability; quality of service; system resilience; and creating recovery strategies.
![]() Disaster Recovery: Concepts discussed include response, personnel, communications, assessment, restoration, and training and awareness.
Disaster Recovery: Concepts discussed include response, personnel, communications, assessment, restoration, and training and awareness.
![]() Testing Recovery Plans: Concepts discussed include read-through test, checklist test, table-top exercise, structured walk-through test, simulation test, parallel test, full-interruption test, functional drill, and evacuation drill.
Testing Recovery Plans: Concepts discussed include read-through test, checklist test, table-top exercise, structured walk-through test, simulation test, parallel test, full-interruption test, functional drill, and evacuation drill.
![]() Business Continuity Planning and Exercises: Concepts discussed include business continuity planning and exercises.
Business Continuity Planning and Exercises: Concepts discussed include business continuity planning and exercises.
![]() Physical Security: Concepts discussed include perimeter security and building and internal security.
Physical Security: Concepts discussed include perimeter security and building and internal security.
![]() Personnel Privacy and Safety: Concepts discussed include duress, travel, and monitoring.
Personnel Privacy and Safety: Concepts discussed include duress, travel, and monitoring.
Security Operations includes foundational security operations concepts, investigations, incident management, and disaster recovery. It also covers physical and personnel security. Security practitioners should receive the appropriate training in these areas or employ experts in these areas to ensure that the organizations assets are properly protected.
Security operations involves ensuring that all operations within an organization are carried out in a secure manner. It is concerned with investigating, managing, and preventing events or incidents. It also covers logging activities as they occur, provisioning and protecting resources as needed, managing event and incidents, recovering from events and disasters, and providing physical security. Security operations involves day-to-day operation of an organization.
Foundation Topics
Investigations
Investigations must be carried out in the appropriate manner to ensure that any evidence collected can be used in court. Without proper investigations and evidence collection, attackers will not be held responsible for their actions. In this section we discuss forensic and digital investigations and evidence.
Forensic and Digital Investigations
Computer investigations require different procedures than regular investigations because the timeframe for the investigator is compressed and an expert might be required to assist in the investigation. Also, computer information is intangible and often requires extra care to ensure that the data is retained in its original format. Finally, the evidence in a computer crime is much more difficult to gather.
After a decision has been made to investigate a computer crime, you should follow standardized procedures, including the following:
![]() Identify what type of system is to be seized.
Identify what type of system is to be seized.
![]() Identify the search and seizure team members.
Identify the search and seizure team members.
![]() Determine the risk that the suspect will destroy evidence.
Determine the risk that the suspect will destroy evidence.
After law enforcement has been informed of a computer crime, the organization’s investigator’s constraints are increased. Turning the investigation over to law enforcement to ensure that evidence is preserved properly might be necessary.
When investigating a computer crime, evidentiary rules must be addressed. Computer evidence should prove a fact that is material to the case and must be reliable. The chain of custody must be maintained. Computer evidence is less likely to be admitted in court as evidence if the process for producing it must be documented.

Any forensic investigation involves the following steps:
1. Identification
2. Preservation
3. Collection
4. Examination
5. Analysis
7. Decision
The forensic investigation process is shown in Figure 7-1.
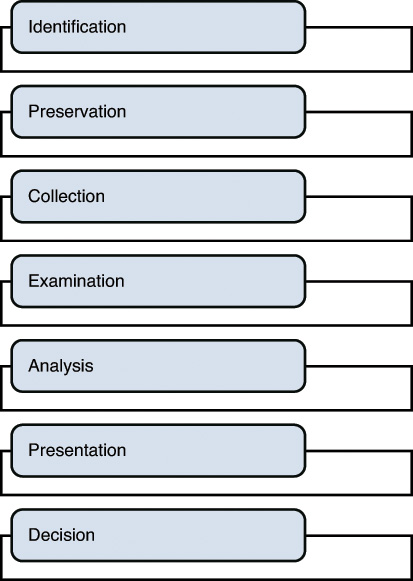
The following sections cover these forensic investigation steps in detail as well as explain IOCE/SWGDE and NIST, the crime scene, MOM, the chain of custody, and interviewing.
Identify Evidence
The first step in any forensic investigation is to identify and secure the crime scene and identify the evidence. Identifying the evidence is done through reviewing audit logs, monitoring systems, analyzing user complaints, and analyzing detection mechanisms. Initially, the investigators might be unsure of which evidence is important. Preserving evidence that you might not need is always better than wishing you had evidence that you did not retain.
Identifying the crime scene is also part of this step. In digital investigations, the attacked system is considered the crime scene. In some cases, the system from which the attack originated can also be considered part of the crime scene. However, fully capturing the attacker’s systems is not always possible. For this reason, you should ensure that you capture any data that can point to a specific system, such as capturing IP addresses, user names, and other identifiers.
Preserve and Collect Evidence
The next steps in forensic investigations include preserving and collecting evidence. This involves making system images, implementing chain of custody (which is discussed in detail in its own section later), documenting the evidence, and recording timestamps.
Before collecting any evidence, consider the order of volatility. This order ensures that investigators collect evidence from the components that are most volatile first.
The order of volatility is as follows:
1. Memory contents
2. Swap files
3. Network processes
4. System processes
5. File system information
6. Raw disk blocks
To make system images, you need to use a tool that creates a bit-level copy of the system. In most cases, you must isolate the system and remove it from production to create this bit-level copy. You should ensure that two copies of the image are retained. One copy of the image will be stored to ensure that an undamaged, accurate copy is available as evidence. The other copy will be used during the examination and analysis steps. Message digests should be used to ensure data integrity.
Although the system image is usually the most important piece of evidence, it is not the only piece of evidence you need. You might also need to capture data that is stored in cache, process tables, memory, and the registry. When documenting a computer attack, you should use a bound notebook to keep notes.
Remember that using experts in digital investigations to ensure that evidence is properly preserved and collected might be necessary. Investigators usually assemble a field kit to help in the investigation process. This kit might include tags and labels, disassembly tools, and tamper-evident packaging. Commercial field kits are available, or you could assemble your own based on organizational needs.
Examine and Analyze Evidence
After evidence has been preserved and collected, the investigator then needs to examine and analyze the evidence. While examining evidence, any characteristics, such as timestamps and identification properties, should be determined and documented. After the evidence has been fully analyzed using scientific methods, the full incident should be reconstructed and documented.
Present Findings
After an examination and analysis of the evidence, it must be presented as evidence in court. In most cases when presenting evidence in court, presenting the findings in a format the audience can understand is best. Although an expert should be used to testify as to the findings, it is important that the expert be able to articulate to a nontechnical audience the details of the evidence.
Decide
At the end of the court proceeding, a decision will be made as to the guilt or innocence of the accused party. At that time, evidence will no longer need to be retained. However, documenting any lessons learned from the incident is important. Any individuals involved in any part of the investigation should be a part of this lessons-learned session.
IOCE/SWGDE and NIST
The International Organization on Computer Evidence (IOCE) and Scientific Working Group on Digital Evidence (SWGDE) are two groups that study digital forensics and help to establish standards for digital investigations. Both groups release guidelines on many formats of digital information, including computer data, mobile device data, automobile computer systems data, and so on. Any investigators should ensure that they comply with the principles from these groups.
The main principles as documented by IOCE are as follows:
![]() The general rules of evidence should be applied to all digital evidence.
The general rules of evidence should be applied to all digital evidence.
![]() Upon seizing digital evidence, actions taken should not change that evidence.
Upon seizing digital evidence, actions taken should not change that evidence.
![]() When a person needs to access original digital evidence, that person should be suitably trained for the purpose.
When a person needs to access original digital evidence, that person should be suitably trained for the purpose.
![]() All activity relating to the seizure, access, storage, or transfer of digital evidence must be fully documented, preserved, and available for review.
All activity relating to the seizure, access, storage, or transfer of digital evidence must be fully documented, preserved, and available for review.
![]() An individual is responsible for all actions taken with respect to digital evidence while the digital evidence is in his possession.
An individual is responsible for all actions taken with respect to digital evidence while the digital evidence is in his possession.
![]() Any agency that seizes, accesses, stores, or transfers digital evidence is responsible for compliance with IOCE principles.
Any agency that seizes, accesses, stores, or transfers digital evidence is responsible for compliance with IOCE principles.
NIST SP 800-86, “Guide to Investigating Forensic Techniques into Incident Response,” provides guidelines on the data collection, examination, analysis, and reporting related to digital forensics. It explains the use of forensic investigators, IT staff, and incident handlers as part of any forensic investigation. It discusses how cost, response time, and data sensitivity should affect any forensic investigation.
To establish an organizational forensic capability, NIST SP 800-86 provides the following guidelines:
![]() Organizations should have a capability to perform computer and network forensics.
Organizations should have a capability to perform computer and network forensics.
![]() Organizations should determine which parties should handle each aspect of forensics.
Organizations should determine which parties should handle each aspect of forensics.
![]() Incident handling teams should have robust forensic capabilities.
Incident handling teams should have robust forensic capabilities.
![]() Many teams within an organization should participate in forensics.
Many teams within an organization should participate in forensics.
![]() Forensic considerations should be clearly addressed in policies.
Forensic considerations should be clearly addressed in policies.
![]() Organizations should create and maintain guidelines and procedures for performing forensic tasks.
Organizations should create and maintain guidelines and procedures for performing forensic tasks.
NIST SP 800-86 provides guidelines for using data from data files, operating systems, network traffic, and applications. Organizations can use this standard to help ensure that personnel follow the appropriate guidelines in performing forensic investigations.
Crime Scene
A crime scene is the environment in which potential evidence exists. After the crime scene has been identified, steps should be taken to ensure that the environment is protected, including both the physical and virtual environment. To secure the physical crime scene, an investigator might need to isolate the systems involved by removing them from a network. However, the systems should NOT be powered down until the investigator is sure that all digital evidence has been captured. Remember: Live computer data is dynamic and is possibly stored in several volatile locations.
When responding to a possible crime, it is important to ensure that the crime scene environment is protected using the following steps:
1. Identify the crime scene.
2. Protect the entire crime scene.
3. Identify any pieces of evidence or potential sources of evidence that are part of the crime scene.
4. Collect all evidence at the crime scene.
5. Minimize contamination by properly securing and preserving all evidence.
Remember that there can be more than one crime scene, especially in digital crimes. If an attacker breaches an organization’s network, all assets that were compromised are part of the crime scene, and any assets that the attacker used are also part of the crime scene.
Access to the crime scene should be tightly controlled and limited only to individuals who are vital to the investigation. As part of the documentation process, make sure to note anyone who has access to the crime scene. After a crime scene is contaminated, no way exists to restore it to the original condition.
MOM
Documenting motive, opportunity, and means (MOM) is the most basic strategy for determining suspects. Motive is all about why the crime was committed and who committed the crime. Opportunity is all about where and when the crime occurred. Means is all about how the crime was carried out by the suspect. Any suspect that is considered must possess all three of these qualities. For example, a suspect might have a motive for a crime (being dismissed from the organization) and an opportunity for committing the crime (user accounts were not disabled properly) but might not possess the means to carry out the crime.
Understanding MOM can help any investigator narrow down the list of suspects.
Chain of Custody
At the beginning of any investigation, you should ask the questions who, what, when, where, and how. These questions can help get all the data needed for the chain of custody. The chain of custody shows who controlled the evidence, who secured the evidence, and who obtained the evidence. A proper chain of custody must be preserved to successfully prosecute a suspect. To preserve a proper chain of custody, the evidence must be collected following predefined procedures in accordance with all laws and regulations.
The primary purpose of the chain of custody is to ensure that evidence is admissible in court. Law enforcement officers emphasize chain of custody in any investigations that they conduct. Involving law enforcement early in the process during an investigation can help to ensure that the proper chain of custody is followed.
Interviewing
An investigation often involves interviewing suspects and witnesses. One person should be in charge of all interviews. Because evidence needs to be obtained, ensuring that the interviewer understands what information needs to be obtained and all the questions to cover is important. Reading a suspect his rights is ONLY necessary if law enforcement is performing the interview. Recording the interview might be a good idea to provide corroboration later when the interview is used as evidence.
If an employee is suspected of a computer crime, a representative of the human resources department should be involved in any interrogation of the suspect. The employee should only be interviewed by an individual who is senior to that employee.
Evidence
For evidence to be admissible, it must be relevant, legally permissible, reliable, properly identified, and properly preserved. Relevant means that it must prove a material fact related to the crime in that it shows a crime has been committed, can provide information describing the crime, can provide information regarding the perpetrator’s motives, or can verify what occurred. Reliability means that it has not been tampered with or modified. Preservation means that the evidence is not subject to damage or destruction.
All evidence must be tagged. When creating evidence tags, be sure to document the mode and means of transportation, a complete description of evidence including quality, who received the evidence, and who had access to the evidence.
Any investigator must ensure that evidence adheres to the five rules of evidence (see the following section). In addition, the investigator must understand each type of evidence that can be obtained and how each type can be used in court. Investigators must follow surveillance, search, and seizure guidelines. Finally, investigators must understand the differences among media, software, network, and hardware/embedded device analysis.
Five Rules of Evidence
When gathering evidence, an investigator must ensure that the evidence meets the five rules that govern it:
![]() Be authentic.
Be authentic.
![]() Be accurate.
Be accurate.
![]() Be complete.
Be complete.
![]() Be convincing.
Be convincing.
![]() Be admissible.
Be admissible.
Because digital evidence is more volatile than other evidence, it still must meet these five rules.
Types of Evidence
An investigator must be aware of the types of evidence used in court to ensure that all evidence is admissible. Sometimes the type of evidence determines its admissibility.
The types of evidence that you should understand are as follows:
![]() Best evidence
Best evidence
![]() Secondary evidence
Secondary evidence
![]() Direct evidence
Direct evidence
![]() Conclusive evidence
Conclusive evidence
![]() Circumstantial evidence
Circumstantial evidence
![]() Corroborative evidence
Corroborative evidence
![]() Opinion evidence
Opinion evidence
![]() Hearsay evidence
Hearsay evidence
The best evidence rule states that when evidence, such as a document or recording, is presented, only the original will be accepted unless a legitimate reason exists for why the original cannot be used. In most cases, digital evidence is not considered best evidence because investigators must capture copies of the original data and state.
However, courts can apply the best evidence rule to digital evidence in a case-by-case basis, depending on the evidence and the situation. In this situation, the copy must be proved by an expert witness who can testify as to the contents and confirm that it is an accurate copy of the original.
Secondary evidence has been reproduced from an original or substituted for an original item. Copies of original documents and oral testimony are considered secondary evidence.
Direct evidence proves or disproves a fact through oral testimony based on information gathered through the witness’s senses. A witness can testify on what he saw, smelled, heard, tasted, or felt. This is considered direct evidence. Only the witness can give direct evidence. No one else can report on what the witness told them because that is considered hearsay evidence.
Conclusive evidence does not require any other corroboration and cannot be contradicted by any other evidence.
Circumstantial evidence provides inference of information from other intermediate relevant facts. This evidence makes a jury come to a conclusion by using a fact to imply that another fact is true or untrue. An example is implying that a former employee committed an act against an organization due to his dislike of the organization after his dismissal.
Corroborative evidence supports another piece of evidence. For example, if a suspect produces a receipt to prove he was at a particular restaurant at a certain time and then a waitress testifies that she waited on the suspect, then the waitress provides corroborating evidence through her testimony.
Opinion evidence is based on what the witness thinks, feels, or infers regarding the facts. However, if an expert witness is used, that expert is able to testify on a fact based on his knowledge in a certain area. For example, a psychiatrist can testify as to conclusions on a suspect’s state of mind. Expert testimony is not considered opinion evidence because of the expert’s knowledge and experience.
Hearsay evidence is evidence that is secondhand where the witness does not have direct knowledge of the fact asserted but knows it only from being told by someone. In some cases, computer-based evidence is considered hearsay, especially if an expert cannot testify as to the accuracy and integrity of the evidence.
Surveillance, Search, and Seizure
Surveillance, search, and seizure are important facets of any investigation. Surveillance is the act of monitoring behavior, activities, or other changing information, usually of people. Search is the act of pursuing items or information. Seizure is the act of taking custody of physical or digital components.
Two types of surveillance are used by investigators: physical surveillance and computer surveillance. Physical surveillance occurs when a person’s actions are reported or captured using cameras, direct observance, or closed-circuit TV (CCTV). Computer surveillance occurs when a person’s actions are reported or captured using digital information, such as audit logs.
A search warrant is required in most cases to actively search a private site for evidence. For a search warrant to be issued, probable cause that a crime has been committed must be proven to a judge. The judge must also be given corroboration regarding the existence of evidence. The only time a search warrant does not need to be issued is during exigent circumstances, which are emergency circumstances that are necessary to prevent physical harm, the evidence destruction, the suspect’s escape, or some other consequence improperly frustrating legitimate law enforcement efforts. Exigent circumstances will have to be proven when the evidence is presented in court.
Seizure of evidence can only occur if the evidence is specifically listed as part of the search warrant unless the evidence is in plain view. Evidence specifically listed in the search warrant can be seized, and the search can only occur in areas specifically listed in the warrant.
Search and seizure rules do not apply to private organizations and individuals. Most organizations warn their employees that any files stored on organizational resources are considered property of the organization. This is usually part of any no-expectation-of-privacy policy.
A discussion of evidence would be incomplete without discussing jurisdiction. Because computer crimes can involve assets that cross jurisdictional boundaries, investigators must understand that the civil and criminal laws of countries can differ greatly. It is always best to consult local law enforcement personnel for any criminal or civil investigation and follow any advice they give for investigations that cross jurisdictions.
Media Analysis
Investigators can perform many types of media analysis, depending on the media type. A media recovery specialist may be employed to provide a certified forensic image, which is an expensive process.
The following types of media analysis can be used:
![]() Disk imaging: Creates an exact image of the contents of the hard drive.
Disk imaging: Creates an exact image of the contents of the hard drive.
![]() Slack space analysis: Analyzes the slack (marked as empty or reusable) space on the drive to see whether any old (marked for deletion) data can be retrieved.
Slack space analysis: Analyzes the slack (marked as empty or reusable) space on the drive to see whether any old (marked for deletion) data can be retrieved.
![]() Content analysis: Analyzes the contents of the drive and gives a report detailing the types of data by percentage.
Content analysis: Analyzes the contents of the drive and gives a report detailing the types of data by percentage.
![]() Steganography analysis: Analyzes the files on a drive to see whether the files have been altered or to discover the encryption used on the file.
Steganography analysis: Analyzes the files on a drive to see whether the files have been altered or to discover the encryption used on the file.
Software Analysis
Software analysis is a little more difficult to perform than media analysis because it often requires the input of an expert on software code, including source code, compiled code, or machine code. It often involves decompiling or reverse engineering. This type of analysis is often used during malware analysis and copyright disputes.
Software analysis techniques include the following:
![]() Content analysis: Analyzes the content of software, particularly malware, to determine for which purpose the software was created.
Content analysis: Analyzes the content of software, particularly malware, to determine for which purpose the software was created.
![]() Reverse engineering: Retrieves the source code of a program to study how the program performs certain operations.
Reverse engineering: Retrieves the source code of a program to study how the program performs certain operations.
![]() Author identification: Attempts to determine the software’s author.
Author identification: Attempts to determine the software’s author.
![]() Context analysis: Analyzes the environment the software was found in to discover clues to determining risk.
Context analysis: Analyzes the environment the software was found in to discover clues to determining risk.
Network Analysis
Network analysis involves the use of networking tools to preserve logs and activity for evidence.
Network analysis techniques include the following:
![]() Communications analysis: Analyzes communication over a network by capturing all or part of the communication and searching for particular types of activity.
Communications analysis: Analyzes communication over a network by capturing all or part of the communication and searching for particular types of activity.
![]() Log analysis: Analyzes network traffic logs.
Log analysis: Analyzes network traffic logs.
![]() Path tracing: Tracing the path of a particular traffic packet or traffic type to discover the route used by the attacker.
Path tracing: Tracing the path of a particular traffic packet or traffic type to discover the route used by the attacker.
Hardware/Embedded Device Analysis
Hardware/embedded device analysis involves using the tools and firmware provided with devices to determine the actions that were performed on and by the device. The techniques used to analyze the hardware/embedded device vary based on the device. In most cases, the device vendor can provide advice on the best technique to use depending on what information you need. Log analysis, operating system analysis, and memory inspections are some of the general techniques used.
This type of analysis is used when mobile devices are analyzed. For performing this type of analysis, NIST makes the following recommendations:
![]() Any analysis should not change the data contained on the device or media.
Any analysis should not change the data contained on the device or media.
![]() Only competent investigators should access the original data and must explain all actions they took.
Only competent investigators should access the original data and must explain all actions they took.
![]() Audit trails or other records must be created and preserved during all steps of the investigation.
Audit trails or other records must be created and preserved during all steps of the investigation.
![]() The lead investigator is responsible for ensuring that all these procedures are followed.
The lead investigator is responsible for ensuring that all these procedures are followed.
![]() All activities regarding digital evidence, including its seizure, access to it, its storage, or its transfer, must be documented, preserved, and available for review.
All activities regarding digital evidence, including its seizure, access to it, its storage, or its transfer, must be documented, preserved, and available for review.
Investigation Types
Security professionals are called on to investigate any incidents that occur. As a result of the different assets that are affected, security professionals must be able to perform different types of investigations, including operations, criminal, civil, regulatory, and eDiscovery investigations. These investigation types are discussed in the following sections.
Operations
Operations investigations are investigations that do not result in any criminal, civil, or regulatory issue. In most cases, this type of investigation is completed to determine the root cause of an incident so that steps can be taken to prevent this incident from occurring again in the future. This process is referred to as root-cause analysis. Because no criminal, civil, or regulatory law has been violated, it is not as important to document the evidence. However, security professionals should still take measures to document the lessons learned.
As an example of this type of investigation, say that a user is assigned inappropriate permissions based on her job role. If this was the result of criminal action, a criminal investigation should occur. However, this could have occurred simply through mistakes made by personnel. Because a security professional would not know the cause of the inappropriate permissions, he would need to start the investigation following proper forensic guidelines. However, once he determined that the incident was the result of an accident, it would no longer be necessary to follow those guidelines. Any individual who carries out this type of investigation must ensure that the appropriate changes are made to prevent such an incident from occurring again, including putting in place security controls. In the case of the inappropriate permissions example, the security professional might find that the user account template that was used to create the user account was assigned to an inappropriate group and must therefore ensure that the user account template is revised.
Criminal
Criminal investigations are investigations that are carried out because a federal, state or local law has been violated. In this type of investigation, an organization should ensure that law enforcement is involved in the investigation as early as possible to ensure that the crime can be properly documented, investigated, and prosecuted. Criminal investigations result in a criminal trial.
Civil
A civil investigation occurs when one organization or party suspects another organization of civil wrongdoing. For example, if an organization suspects that another organization violated a copyright, a civil suit could be filed. While criminal copyright cases do occur, they can only be filed by government prosecutors. In a civil case, the organization should ensure that all evidence rules are followed and that legal representation is involved as part of the investigation.
Regulatory
A regulatory investigation occurs when a regulatory body investigates an organization for a regulatory infraction. In recent history, the Securities and Exchange Commission (SEC) has carried out many regulatory investigations regarding organizations and their financial dealings. No matter which regulatory body is performing the investigation, the organization being investigated will be notified that an investigation is being carried out. The organization should have policies and guidelines in place to ensure full compliance with the investigation. Failure to comply with such an investigation can result in charges being filed against the organization and any personnel involved.
eDiscovery
Electronic discovery (eDiscovery) refers to litigation or government investigations that deal with the exchange of information in electronic format as part of the discovery process. It involves electronically stored information (ESI) and includes emails, documents, presentations, databases, voicemail, audio and video files, social media, and websites. Security professionals should ensure that the original content and metadata of ESI is preserved to prevent claims of spoliation or tampering with evidence later in the litigation. Once the appropriate ESI is collected, it must be held in a secure environment for review.
Logging and Monitoring Activities
As part of operations security, administrators must ensure that user activities are logged and monitored regularly. This includes audit and review, intrusion detection and prevention, security information and event management, continuous monitoring, and egress monitoring.
Audit and Review
Accountability is impossible without a record of activities and review of those activities. Capturing and monitoring audit logs provide the digital proof when someone who is performing certain activities needs to be identified. This goes for both the good guys and the bad guys. In many cases it is required to determine who misconfigured something rather than who stole something. Audit trails based upon access and identification codes establish individual accountability. The questions to address when reviewing audit logs include the following:
![]() Are users accessing information or performing tasks that are unnecessary for their jobs?
Are users accessing information or performing tasks that are unnecessary for their jobs?
![]() Are repetitive mistakes (such as deletions) being made?
Are repetitive mistakes (such as deletions) being made?
![]() Do too many users have special rights and privileges?
Do too many users have special rights and privileges?
The level and amount of auditing should reflect the security policy of the company. Audits can be either self-audits or be performed by a third party. Self-audits always introduce the danger of subjectivity to the process. Logs can be generated on a wide variety of devices including intrusion detection systems (IDSs), servers, routers, and switches. In fact, a host-based IDS makes use of the operating system logs of the host machine.
When assessing controls over audit trails or logs, address the following questions:
![]() Does the audit trail provide a trace of user actions?
Does the audit trail provide a trace of user actions?
![]() Is access to online logs strictly controlled?
Is access to online logs strictly controlled?
![]() Is there separation of duties between security personnel who administer the access control function and those who administer the audit trail?
Is there separation of duties between security personnel who administer the access control function and those who administer the audit trail?
Keep and store logs in accordance with the retention policy defined in the organization’s security policy. They must be secured to prevent modification, deletion, and destruction. When auditing is functioning in a monitoring role, it supports the detection security function in the technical category. When formal review of the audit logs takes place, it is a form of detective administrative control. Reviewing audit data should be a function separate from the day-to-day administration of the system.
Intrusion Detection and Prevention
IDSs alert organizations when unauthorized access or actions occurs, while intrusion prevention systems (IPSs) monitor the same kind of activity but actually work to prevent the actions from being successful. IDS and IPS devices can be used during investigations to provide information regarding traffic patterns that occur just before an attack succeeds. Security professionals must constantly tune IDS and IPS devices to ensure that the correct activity is being detected or prevented. As changes occur in the way that attacks are carried out, these systems must be adjusted.
Note
IDS and IPS devices are discussed in more detail in Chapter 4, “Communication and Network Security.”
Security Information and Event Management (SIEM)
SIEM can collect log and system information to comply with regulatory requirements, provide internal accountability, provide risk management, and perform monitoring and trending. SIEM stores raw information from various systems and devices and aggregates that information into a single database. Security professionals must work together to ensure that the appropriate actions will be monitored and to ensure that the correct examinations of the records occur. Because SIEM systems are centralized repositories of security information, organizations should take particular care to provide adequate security for these systems to ensure that attackers cannot access or alter the records contained in them.
Continuous Monitoring
Any logging and monitoring activities should be part of an organizational continuous monitoring program. The continuous monitoring program must be designed to meet the needs of the organization and implemented correctly to ensure that the organization’s critical infrastructure is guarded. Organizations may want to look into Continuous Monitoring as a Service (CMaaS) solutions deployed by cloud service providers.
Egress Monitoring
Egress monitoring occurs when an organization monitors the outbound flow of information from one network to another. The most popular form of egress monitoring is carried out using firewalls that monitor and control outbound traffic.
Data leakage occurs when sensitive data is disclosed to unauthorized personnel either intentionally or inadvertently. Data loss prevention (DLP) software attempts to prevent data leakage. It does this by maintaining awareness of actions that can and cannot be taken with respect to a document. For example, it might allow printing of a document but only at the company office. It might also disallow sending the document through email. DLP software uses ingress and egress filters to identify sensitive data that is leaving the organization and can prevent such leakage.
Another scenario might be the release of product plans that should be available only to the Sales group. A security professional could set a policy like the following for that document:
![]() It cannot be emailed to anyone other than Sales group members.
It cannot be emailed to anyone other than Sales group members.
![]() It cannot be printed.
It cannot be printed.
![]() It cannot be copied.
It cannot be copied.
There are two locations where a DLP can be implemented:
![]() Network DLP: Installed at network egress points near the perimeter, network DLP analyzes network traffic.
Network DLP: Installed at network egress points near the perimeter, network DLP analyzes network traffic.
![]() Endpoint DLP: Endpoint DLP runs on end-user workstations or servers in the organization.
Endpoint DLP: Endpoint DLP runs on end-user workstations or servers in the organization.
You can use both precise and imprecise methods to determine what is sensitive:
![]() Precise methods: These methods involve content registration and trigger almost zero false-positive incidents.
Precise methods: These methods involve content registration and trigger almost zero false-positive incidents.
![]() Imprecise methods: These methods can include keywords, lexicons, regular expressions, extended regular expressions, metadata tags, Bayesian analysis, and statistical analysis.
Imprecise methods: These methods can include keywords, lexicons, regular expressions, extended regular expressions, metadata tags, Bayesian analysis, and statistical analysis.
The value of a DLP system lies in the level of precision with which it can locate and prevent the leakage of sensitive data.
Note
Steganography and watermarking are sometimes part of egress monitoring. Both of these cryptographic tools are discussed in Chapter 3, “Security Engineering.”
Resource Provisioning
Resource provisioning is a process in security operations which ensures that an organization deploys only the assets it currently needs. Resource provisioning must follow the organization’s resource life cycle. To properly manage the resource life cycle, an organization must maintain an accurate asset inventory and use appropriate configuration management processes. Resources that are involved in provisioning include physical assets, virtual assets, cloud assets, and applications.
Asset Inventory
An asset is any item of value to an organization, including physical devices and digital information. Recognizing when assets are stolen or improperly deployed is impossible if no item count or inventory system exists or if the inventory is not kept updated. All equipment should be inventoried, and all relevant information about each device should be maintained and kept up to date. Each asset should be fully documented, including serial numbers, model numbers, firmware version, operating system version, responsible personnel, and so on. The organization should maintain this information both electronically and in hard copy. Maintaining this inventory will aid in determining when new assets should be deployed or when currently deployed assets should be decommissioned.
Security devices, such as firewalls, network address translation (NAT) devices, and IDSs and IPSs, should receive the most attention because they relate to physical and logical security. Beyond this, devices that can easily be stolen, such as laptops, tablets, and smartphones, should be locked away. If that is not practical, then consider locking these types of devices to stationary objects (for example, using cable locks with laptops).
When the technology is available, tracking of small devices can help mitigate the loss of both devices and their data. Many smartphones now include tracking software that allows you to locate a device after it has been stolen or lost by using either cell tower tracking or GPS. Deploy this technology when available.
Another useful feature available on many smartphones and other portable devices is a remote wiping feature. This allows the user to send a signal to a stolen device, instructing it to wipe out the data contained on the device. Similarly, these devices typically also come with the ability to be remotely locked when misplaced.
Strict control of the use of portable media devices can help prevent sensitive information from leaving the network. This includes CDs, DVDs, flash drives, and external hard drives. Although written rules should be in effect about the use of these devices, using security policies to prevent the copying of data to these media types is also possible. Allowing the copying of data to these drive types as long as the data is encrypted is also possible. If these functions are provided by the network operating system, you should deploy them.
It should not be possible for unauthorized persons to access and tamper with any devices. Tampering includes defacing, damaging, or changing the configuration of a device. Integrity verification programs should be used by applications to look for evidence of data tampering, errors, and omissions.
Encrypting sensitive data stored on devices can help prevent the exposure of data in the event of a theft or in the event of inappropriate access of the device.
Configuration Management
Although it’s really a subset of change management, configuration management specifically focuses itself on bringing order out of the chaos that can occur when multiple engineers and technicians have administrative access to the computers and devices that make the network function. It follows the same basic process as discussed under “Change Management Processes,” but it can take on even greater importance here, considering the impact that conflicting changes can have (and in some immediately) on a network.
The functions of configuration management are:
![]() Report the status of change processing.
Report the status of change processing.
![]() Document the functional and physical characteristics of each configuration item.
Document the functional and physical characteristics of each configuration item.
![]() Perform information capture and version control.
Perform information capture and version control.
![]() Control changes to the configuration items, and issue versions of configuration items from the software library.
Control changes to the configuration items, and issue versions of configuration items from the software library.
Note
In the context of configuration management, a software library is a controlled area accessible only to approved users who are restricted to the use of an approved procedure. A configuration item (CI) is a uniquely identifiable subset of the system that represents the smallest portion to be subject to an independent configuration control procedure. When an operation is broken into individual CIs, the process is called configuration identification.
Examples of these types of changes are:
![]() Operating system configuration
Operating system configuration
![]() Software configuration
Software configuration
![]() Hardware configuration
Hardware configuration
From a CISSP perspective, the biggest contribution of configuration management controls is ensuring that changes to the system do not unintentionally diminish security. Because of this, all changes must be documented, and all network diagrams, both logical and physical, must be updated constantly and consistently to accurately reflect the state of each configuration now and not as it was two years ago. Verifying that all configuration management policies are being followed should be an ongoing process.
In many cases it is beneficial to form a configuration control board. The tasks of the configuration control board can include:
![]() Ensuring that changes made are approved, tested, documented, and implemented correctly.
Ensuring that changes made are approved, tested, documented, and implemented correctly.
![]() Meeting periodically to discuss configuration status accounting reports.
Meeting periodically to discuss configuration status accounting reports.
![]() Maintaining responsibility for ensuring that changes made do not jeopardize the soundness of the verification system.
Maintaining responsibility for ensuring that changes made do not jeopardize the soundness of the verification system.
In summary, the components of configuration management are:
![]() Configuration control
Configuration control
![]() Configuration status accounting
Configuration status accounting
![]() Configuration audit
Configuration audit
Physical Assets
Physical assets include servers, desktop computers, laptops, mobile devices, and network devices that are deployed in the enterprise. Physical assets should be deployed and decommissioned based on organizational need. For example, suppose an organization deploys a wireless access point for use by a third-party auditor. Proper resource provisioning should ensure that the wireless access point is decommissioned once the third-party auditor no longer needs access to the network. Without proper inventory and configuration management, the wireless access point may remain deployed and can be used at some point to carry out a wireless network attack.
Virtual Assets
Virtual assets include software-defined networks, virtual storage-area networks (VSANs), guest operating systems deployed on virtual machines (VMs), and virtual routers. As with physical assets, the deployment and decommissioning of virtual assets should be tightly controlled as part of configuration management because virtual assets, just like physical assets, can be compromised. For example, a Windows 10 virtual machine deployed on a Windows Server 2012 R2 should be retained only until it is no longer needed. As long as the virtual machine is being used, it is important to ensure that the appropriate updates, patches, and security controls are deployed on it as part of configuration management. When users no longer access the virtual machine, the virtual machine should be removed.
Virtual storage occurs when physical storage from multiple network storage devices is compiled into a single virtual storage space. Block virtualization separates the logical storage from the physical storage. File virtualization eliminates the dependency between data accessed at the file level and the physical storage location of the files. Host-based virtual storage requires software running on the host. Storage device–based virtual storage runs on a storage controller and allows other storage controllers to be attached. Network-based virtual storage uses network-based devices, such as iSCSI or Fibre Channel, to create a storage solution.
Cloud Assets
Cloud assets include cloud services, virtual machines, storage networks, and other cloud services contracted through a cloud service provider. Cloud assets are usually billed based on usage and should be carefully provisioned and monitored to prevent the organization from paying for portions of service that it does not need. Configuration management should ensure that the appropriate monitoring policies are in place to ensure that only resources that are needed are deployed.
Applications
Applications include commercial applications that are locally installed, web services, and any cloud-deployed application services, such as Software as a Service (SaaS). The appropriate number of licenses should be maintained for all commercial applications. An organization should periodically review its licensing needs. For cloud deployments of software services, configuration management should be used to ensure that only personnel who have valid needs for the software are given access to it.
Security Operations Concepts
Throughout this book, you’ve seen references made to policies and principals that can guide all security operations. In this section, we review some concepts more completely that have already been touched on and introduce some new issues concerned with maintaining security operations.
Need to Know/Least Privilege
In regard to allowing access to resources and assigning rights to perform operations, always apply the concept of least privilege (also called need to know). In the context of resource access, that means that the default level of access should be no access. Give users access only to resources required to do their job, and that access should require manual implementation after the requirement is verified by a supervisor.
Discretionary access control (DAC) and role-based access control (RBAC) are examples of systems based on a user’s need to know. To ensure least privilege requires that the user’s job be identified and each user be granted the lowest clearance required for their tasks. Another example is the implementation of views in a database. Need-to-know requires that the operator have the minimum knowledge of the system necessary to perform his task.
Managing Accounts, Groups, and Roles
Devices, computers, and applications implement user and group accounts and roles to allow or deny access. User accounts are created for each user needing access. Group accounts are used to configure permissions on resources. User accounts are added to the appropriate group accounts to inherit the permissions granted to that group. User accounts can also be assigned to roles. Roles are most often used by applications.
Security professionals should understand the following accounts:
![]() Root or built-in administrator account: These are the most powerful accounts on the system. It is best to disable such an account after you have created another account with the same privileges because most of these account names are well known and can be used by attackers. If you decide to keep these accounts, most vendors suggest that you change the account name and give it a complex password. Root or administrator accounts should be used only when performing administrative duties, and use of these accounts should always be audited.
Root or built-in administrator account: These are the most powerful accounts on the system. It is best to disable such an account after you have created another account with the same privileges because most of these account names are well known and can be used by attackers. If you decide to keep these accounts, most vendors suggest that you change the account name and give it a complex password. Root or administrator accounts should be used only when performing administrative duties, and use of these accounts should always be audited.
![]() Service account: These accounts are used to run system services and applications. Therefore, security professionals can limit the service account’s access to the system. Always research the default user accounts that are used. Make sure that you change the passwords for these accounts on a regular basis. Use of these accounts should always be audited.
Service account: These accounts are used to run system services and applications. Therefore, security professionals can limit the service account’s access to the system. Always research the default user accounts that are used. Make sure that you change the passwords for these accounts on a regular basis. Use of these accounts should always be audited.
![]() Regular administrator accounts: These administrator accounts are created and assigned only to a single individual. Any user who has an administrative account should also have a regular account to use for normal day-to-day operations. Administrative accounts should only be used when performing administrative-level duties, and use of these accounts should always be audited.
Regular administrator accounts: These administrator accounts are created and assigned only to a single individual. Any user who has an administrative account should also have a regular account to use for normal day-to-day operations. Administrative accounts should only be used when performing administrative-level duties, and use of these accounts should always be audited.
![]() Power user accounts: These accounts have more privileges and permissions than normal user accounts. These accounts should be reviewed on a regular basis to ensure that only users who need the higher-level permissions have these accounts. Most modern operating systems limit the abilities of the power users or even remove this account type entirely.
Power user accounts: These accounts have more privileges and permissions than normal user accounts. These accounts should be reviewed on a regular basis to ensure that only users who need the higher-level permissions have these accounts. Most modern operating systems limit the abilities of the power users or even remove this account type entirely.
![]() Regular user accounts: These are the accounts users use while performing their normal everyday job duties. These accounts must strictly follow the principle of least privilege.
Regular user accounts: These are the accounts users use while performing their normal everyday job duties. These accounts must strictly follow the principle of least privilege.
Separation of Duties
The concept of separation of duties prescribes that sensitive operations be divided among multiple users so that no one user has the rights and access to carry out the operation alone. Separation of duties is valuable in deterring fraud by ensuring that no single individual can compromise a system. It is considered a preventive administrative control. An example would be one person initiating a request for a payment and another authorizing that same payment. This is also sometimes referred to as dual control.
Job Rotation
From a security perspective, job rotation refers to the training of multiple users to perform the duties of a position to help prevent fraud by any individual employee. The idea is that by making multiple people familiar with the legitimate functions of the position, the higher the likelihood that unusual activities by any one person will be noticed. This is often used in conjunction with mandatory vacations, in which all users are required to take time off, allowing another to fill their position while gone, which enhances the opportunity to discover unusual activity. Beyond the security aspects of job rotation, additional benefits include:
![]() Trained backup in case of emergencies
Trained backup in case of emergencies
![]() Protection against fraud
Protection against fraud
![]() Cross training of employees
Cross training of employees
Rotation of duties, separation of duties, and mandatory vacations are all administrative controls.
Sensitive Information Procedures
Access control and its use in preventing unauthorized access to sensitive data is important for organizational security. It follows that the secure handling of sensitive information is critical. Although we tend to think in terms of the company’s information, it is also critical that the company protect the private information of its customers and employees as well. A leak of users’ and customers’ personal information causes at a minimum embarrassment for the company and possibly fines and lawsuits.
Regardless of whether the aim is to protect company data or personal data, the key is to apply the access control principles to both sets of data. When examining accessing access control procedures and policies, the following questions need to be answered:
![]() Is data available to the user that is not required for his job?
Is data available to the user that is not required for his job?
![]() Do too many users have access to sensitive data?
Do too many users have access to sensitive data?
Record Retention
Proper access control is not possible without auditing. This allows us to track activities and discover problems before they are fully realized. Because this can sometimes lead to a mountain of data to analyze, only monitor the most sensitive of activities, and retain and review all records. Moreover, in many cases companies are required by law or regulation to maintain records of certain data.
Most auditing systems allow for the configuration of data retention options. In some cases the default operation is to start writing over the older records in the log when the maximum log size is full. Regular clearing and saving of the log can prevent this from happening and avoid the loss of important events. In cases of extremely sensitive data, having a server shut off access when a security log is full and cannot record any more events is even advisable.
Monitor Special Privileges
Inevitably some users, especially supervisors or those in the IT support department, will require special rights and privileges that other users do not possess. For example, it might be required that a set of users who work the Help Desk might need to be able to reset passwords or perhaps make changes to user accounts. These types of rights carry with them a responsibility to exercise the rights responsibly and ethically.
Although in a perfect world we would like to assume that we can expect this from all users, in the real world we know this is not always true. Therefore, one of the things to monitor is the use of these privileges. Although we should be concerned with the amount of monitoring performed and the amount of data produced by this monitoring, recording the exercise of special privileges should not be sacrificed, even if it means regularly saving the data as a log file and clearing the event gathering system.
Information Life Cycle
In security operations, security professionals must understand the life cycle of information, which includes creation, distribution, usage, maintenance, and disposal of information. After information is gathered, it must be classified to ensure that only authorized personnel can access the information.
Service-Level Agreements
Service-level agreements (SLAs) are agreements about the ability of the support system to respond to problems within a certain timeframe while providing an agreed level of service. They can be internal between departments or external to a service provider. By agreeing on the quickness with which various problems are addressed, some predictability is introduced to the response to problems, which ultimately supports the maintenance of access to resources.
The SLA should contain a description of the services to be provided and the expected service levels and metrics that the customer can expect. It also includes the duties and responsibilities of each party of the SLA. It lists the service specifics, exclusions, service levels, escalation procedures, and cost. It should include a clause regarding payment to the customers resulting from a breach of the SLA. While SLAs can be transferable, they are not transferable by law. Metrics that should be measured include service availability, service levels, defect rates, technical quality, and security. SLAs should be periodically reviewed to ensure that the business needs, technical environment, or workloads have not changed. In addition, metrics, measurement tools, and processes should be reviewed to see if they have improved.
Resource Protection
Enterprise resources include both assets we can see and touch (tangible), such as computers and printers, and assets we cannot see and touch (intangible), such as trade secrets and processes. Although typically we think of resource protection as preventing the corruption of digital resources and as the prevention of damage to physical resources, this concept also includes maintaining the availability of those resources. In this section, we discuss both aspects of resource protection.
Protecting Tangible and Intangible Assets
In some cases among the most valuable assets of a company are intangible ones such as secret recipes, formulas, and trade secrets. In other cases the value of the company is derived from its physical assets such as facilities, equipment, and the talents of its people. All are considered resources and should be included in a comprehensive resource protection plan. In this section, some specific concerns with these various types of resources are explored.
Facilities
Usually the largest tangible asset an organization has is the building in which it operates and the surrounding land. Physical security is covered later in this chapter, but it bears emphasizing that vulnerability testing (discussed more fully in Chapter 6) ought to include the security controls of the facility itself. Some examples of vulnerability testing as it relates to facilities include:
![]() Do doors close automatically, and does an alarm sound if they are held open too long?
Do doors close automatically, and does an alarm sound if they are held open too long?
![]() Are the protection mechanisms of sensitive areas, such as server rooms and wiring closets, sufficient and operational?
Are the protection mechanisms of sensitive areas, such as server rooms and wiring closets, sufficient and operational?
![]() Does the fire suppression system work?
Does the fire suppression system work?
![]() Are sensitive documents shredded as opposed to being thrown in the dumpster?
Are sensitive documents shredded as opposed to being thrown in the dumpster?
Beyond the access issues, the main systems that are needed to ensure operations are not disrupted include fire detection/suppression, HVAC (including temperature and humidity controls), water and sewage systems, power/backup power, communications equipment, and intrusion detection.
Hardware
Another of the more tangible assets that must be protected is all the hardware that makes the network operate. This includes not only the computers and printers with which the users directly come in contact, but also the infrastructure devices that they never see such as routers, switches, and firewall appliances. Maintaining access to these critical devices from an availability standpoint is covered later in the sections “Redundancy and Fault Tolerance” and “Backup and Recovery Systems.”
From a management standpoint, these devices are typically managed remotely. Special care must be taken to safeguard access to these management features as well as protect the data and commands passing across the network to these devices. Some specific guidelines include:
![]() Change all default administrator passwords on the devices.
Change all default administrator passwords on the devices.
![]() Limit the number of users that have remote access to these devices.
Limit the number of users that have remote access to these devices.
![]() Rather than Telnet (which sends commands in clear text) use an encrypted command-line tool such as Secure Shell (SSH).
Rather than Telnet (which sends commands in clear text) use an encrypted command-line tool such as Secure Shell (SSH).
![]() Manage critical systems locally.
Manage critical systems locally.
![]() Limit physical access to these devices.
Limit physical access to these devices.
Software
Software assets include any propriety application, scripts, or batch files that have been developed in house that are critical to the operation of the organization. Secure coding and development practices can help to prevent weaknesses in these systems. Attention must also be paid to preventing theft of these assets as well.
Moreover, closely monitoring the use of commercial applications and systems in the enterprise can prevent unintentional breach of licensing agreements. One of the benefits of only giving users the applications they require to do their job is that it limits the number of users that have an application, helping to prevent exhaustion of licenses for software.
Note
Software development security is discussed in detail in Chapter 8, “Software Development Security.”
Information Assets
Information assets are the last asset type that needs to be discussed, but by no means are they the least important. The primary purpose of operations security is to safeguard information assets that are resident in the system. These assets include recipes, processes, trade secrets, product plans, and any other type of information that enables the enterprise to maintain competitiveness within its industry. The principles of data classification and access control apply most critically to these assets. In some cases the dollar value of these assets might be difficult to determine, although it might be clear to all involved that the asset is critical. For example, the secret formula for Coca-Cola has been closely guarded for many years due to its value to the company.
Asset Management
In the process of managing these assets, several issues must be addressed. Certainly access to the asset must be closely controlled to prevent its deletion, theft, or corruption (in the case of digital assets) and from physical damage (in the case of physical assets). Moreover, the asset must remain available when needed. This section covers methods of ensuring availability, authorization, and integrity.
Redundancy and Fault Tolerance
One of the ways to provide uninterrupted access to information assets is through redundancy and fault tolerance. Redundancy refers to providing multiple instances of either a physical or logical component such that a second component is available if the first fails. Fault tolerance is a broader concept that includes redundancy but refers to any process that allows a system to continue making information assets available in the case of a failure.
In some cases redundancy is applied at the physical layer, such as network redundancy provided by a dual backbone in a local network environment or by using multiple network cards in a critical server. In other cases redundancy is applied logically such as when a router knows multiple paths to a destination in case one fails.
Fault tolerance countermeasures are designed to combat threats to design reliability. Although fault tolerance can include redundancy, it also refers to systems such as Redundant Array of Independent Disks (RAID) in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from the remaining disks in the array without resorting to a backup tape. Be familiar with a number of RAID types because not all provide fault tolerance. Regardless of the technique employed for fault tolerance to operate, a system must be capable of detecting and correcting the fault.
Backup and Recovery Systems
Although comprehensive coverage of backup and recovery systems is found throughout this chapter, it is important to emphasize here the role of operations in carrying out those activities. After the backup schedule has been designed, there will be daily tasks associated with carrying out the plan. One of the most important parts of this system is an ongoing testing process to ensure that all backups are usable in case a recovery is required. The time to discover that a backup did not succeed is during testing and not during a live recovery.
Identity and Access Management
From an operations perspective, it is important to realize that managing these things is an ongoing process that might require creating accounts, deleting accounts, creating and populating groups, and managing the permissions associated with all of these concepts. Ensuring that the rights to perform these actions are tightly controlled and that a formal process is established for removing permissions when they are no longer required and disabling accounts that are no longer needed is essential.
Another area to focus on is the control of the use of privileged accounts or accounts that have rights and permissions that exceed those of a regular user account. Although this obviously applies to built-in administrator, root, or supervisor accounts (which in some operating systems are called root accounts) that have vast permissions, it also applies to any account that confers special privileges to the user.
Moreover, maintain the same tight control over the numerous built-in groups that exist in Windows to grant special rights to the group members. When using these groups, make note of any privileges held by the default groups that are not required for your purposes. You might want to remove some of the privileges from the default groups to support the concept of least privilege.
Media Management
Media management is an important part of operations security because media is where data is stored. Media management includes RAID, SAN, NAS, and HSM.
Redundant Array of Independent Disks (RAID) refers to a system whereby multiple hard drives are used to provide either a performance boost or fault tolerance for the data. When we speak of fault tolerance in RAID, we mean maintaining access to the data even in a drive failure without restoring the data from a backup media. The following are the types of RAID with which you should be familiar.
RAID 0, also called disk striping, writes the data across multiple drives. Although it improves performance, it does not provide fault tolerance. Figure 7-2 depicts RAID 0.
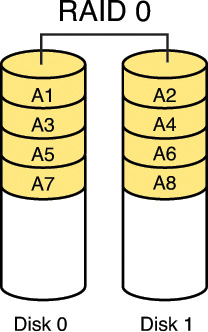
RAID 1, also called disk mirroring, uses two disks and writes a copy of the data to both disks, providing fault tolerance in the case of a single drive failure. Figure 7-3 depicts RAID 1.
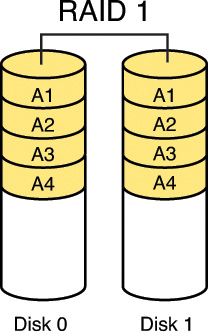
RAID 3, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written to a single dedicated drive. The parity information is used to regenerate the data in the case of a single drive failure. The downfall is that the parity drive is a single point of failure if it goes bad. Figure 7-4 depicts RAID 3.
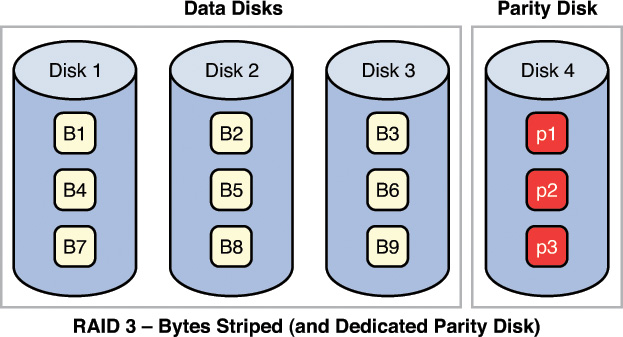
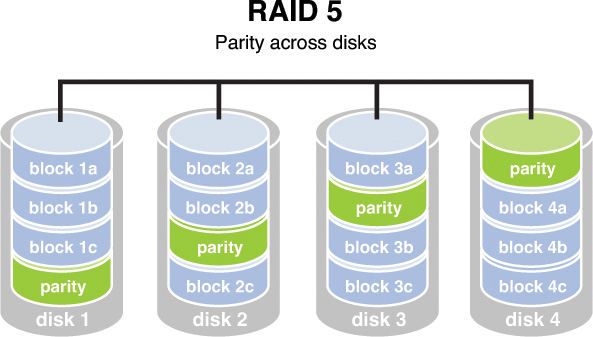
RAID 5, requiring at least three drives, also requires that the data is written across all drives like striping and then parity information is written across all drives as well. The parity information is used in the same way as in RAID 3, but it is not stored on a single drive so there is no single point of failure for the parity data. With hardware RAID level 5, the spare drives that replace the failed drives are usually hot swappable, meaning they can be replaced on the server while it is running. Figure 7-5 depicts RAID 5.
RAID 7, though not a standard but a proprietary implementation, incorporates the same principles as RAID 5 but enables the drive array to continue to operate if any disk or any path to any disk fails. The multiple disks in the array operate as a single virtual disk.
RAID 10, which requires at least four drives, is a combination of RAID 0 and RAID 1. First, a RAID 1 volume is created by mirroring two drives together. Then a RAID 0 stripe set is created on each mirrored pair. Figure 7-6 depicts RAID 10.
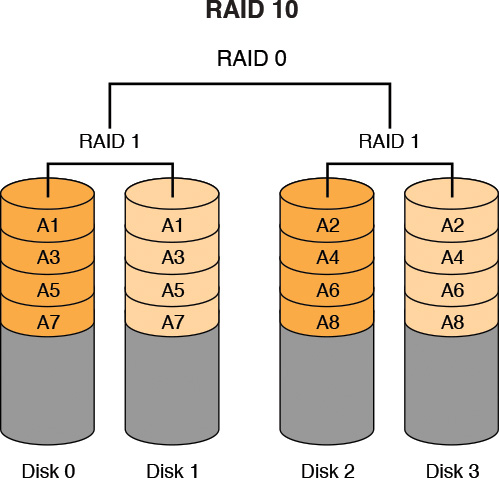
Although RAID can be implemented with software or with hardware, certain types of RAID are faster when implemented with hardware. When software RAID is used, it is a function of the operating system. Both RAID 3 and 5 are examples of RAID types that are faster when implemented with hardware. Simple striping or mirroring (RAID 0 and 1), however, tend to perform well in software because they do not use the hardware-level parity drives. Table 7-1 summarizes the RAID types.
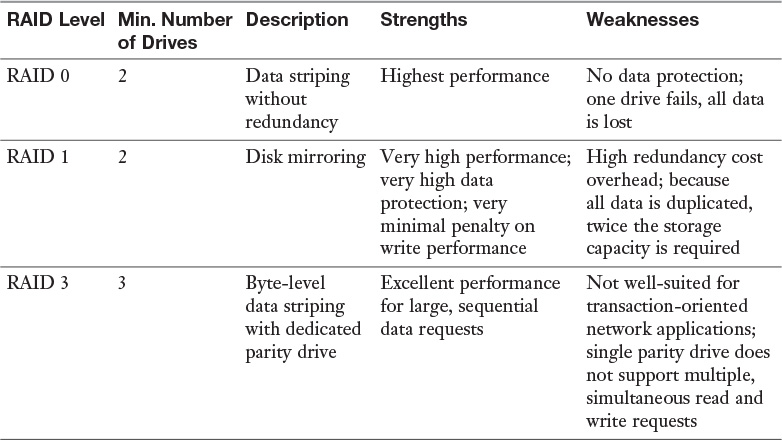

Storage-area networks (SAN) are comprised of high-capacity storage devices that are connected by a high-speed private network (separate from the LAN) using storage-specific switches. This storage information architecture addresses the collection of data, management of data, and use of data.
Network-attached storage (NAS) serves the same function as SAN, but clients access the storage in a different way. In a NAS, almost any machine that can connect to the LAN (or is interconnected to the LAN through a WAN) can use protocols such as NFS, CIFS, or HTTP to connect to a NAS and share files. In a SAN, only devices that can use the Fibre Channel SCSI network can access the data, so it is typically done though a server that has this capability. Figure 7-7 shows a comparison of the two systems.
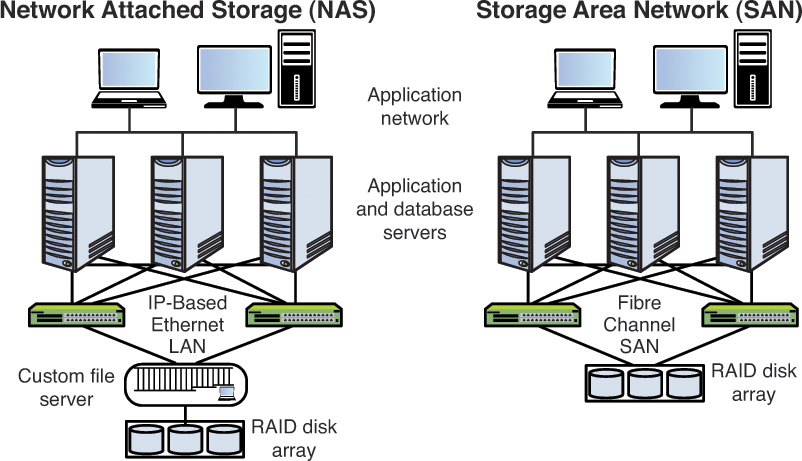
A hierarchical storage management (HSM) system is a type of backup management system that provides a continuous online backup by using optical or tape “jukeboxes.” It operates by automatically moving data between high-cost and low-cost storage media as the data ages. When continuous availability (24 hours-a-day processing) is required, HSM provides a good alternative to tape backups. It also strives to use the proper media for the scenario. For example, a rewritable and erasable (CDR/W) optical disc is sometimes used for backups that require short time storage for changeable data but require faster file access than tape.
Media History
Accurately maintain media library logs to keep track of the history of the media. This is important in that all media types have a maximum number of times they can safely be used. A log should be kept by a media librarian. This log should track all media (backup and other types such as OS installation discs). With respect to the backup media, use the following guidelines:
![]() Track all instances of access to the media.
Track all instances of access to the media.
![]() Track the number and location of backups.
Track the number and location of backups.
![]() Track age of media to prevent loss of data through media degeneration.
Track age of media to prevent loss of data through media degeneration.
![]() Inventory the media regularly.
Inventory the media regularly.
Media Labeling and Storage
Plainly label all forms of storage media (tapes, optical, and so on) and store them safely. Some guidelines in the area of media control are to
![]() Accurately and promptly mark all data storage media.
Accurately and promptly mark all data storage media.
![]() Ensure proper environmental storage of the media.
Ensure proper environmental storage of the media.
![]() Ensure the safe and clean handling of the media.
Ensure the safe and clean handling of the media.
![]() Log data media to provide a physical inventory control.
Log data media to provide a physical inventory control.
The environment where the media will be stored is also important. For example, damage starts occurring to magnetic media above 100 degrees. The Forest Green Book is a Rainbow Series book that defines the secure handling of sensitive or classified automated information system memory and secondary storage media, such as degaussers, magnetic tapes, hard disks, and cards. The Rainbow Series is discussed in more detail in Chapter 3.
Sanitizing and Disposing of Media
During media disposal, you must ensure no data remains on the media. The most reliable, secure means of removing data from magnetic storage media, such as a magnetic tape cassette, is through degaussing, which exposes the media to a powerful, alternating magnetic field. It removes any previously written data, leaving the media in a magnetically randomized (blank) state. Some other disposal terms and concepts with which you should be familiar are
![]() Data purging: Using a method such as degaussing to make the old data unavailable even with forensics. Purging renders information unrecoverable against laboratory attacks (forensics).
Data purging: Using a method such as degaussing to make the old data unavailable even with forensics. Purging renders information unrecoverable against laboratory attacks (forensics).
![]() Data clearing: Renders information unrecoverable by a keyboard. This attack extracts information from data storage media by executing software utilities, keystrokes, or other system resources executed from a keyboard.
Data clearing: Renders information unrecoverable by a keyboard. This attack extracts information from data storage media by executing software utilities, keystrokes, or other system resources executed from a keyboard.
![]() Remanence: Any data left after the media has been erased.
Remanence: Any data left after the media has been erased.
Network and Resource Management
Although security operations focuses on providing confidentiality and integrity of data, availability of the data is also one of its goals. This means designing and maintaining processes and systems that maintain availability to resources despite hardware or software failures in the environment. The following principles and concepts are available to assist in maintaining access to resources:
![]() Redundant hardware: Failures of physical components, such as hard drives and network cards, can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access. In some cases, changing out a component might require manual intervention, but in many cases these items are hot swappable (they can be changed with the device up and running), in which case a momentary reduction in performance might occur rather than a complete disruption of access.
Redundant hardware: Failures of physical components, such as hard drives and network cards, can interrupt access to resources. Providing redundant instances of these components can help to ensure a faster return to access. In some cases, changing out a component might require manual intervention, but in many cases these items are hot swappable (they can be changed with the device up and running), in which case a momentary reduction in performance might occur rather than a complete disruption of access.
![]() Fault-tolerant technologies: Taking the idea of redundancy to the next level are technologies that are based on multiple computing systems working together to provide uninterrupted access even in the event of a failure of one of the systems. Clustering of servers and grid computing are both great examples of this approach.
Fault-tolerant technologies: Taking the idea of redundancy to the next level are technologies that are based on multiple computing systems working together to provide uninterrupted access even in the event of a failure of one of the systems. Clustering of servers and grid computing are both great examples of this approach.
![]() MTBF and MTTR: Although SLAs are appropriate for services that are provided, a slightly different approach to introducing predictability can be used with regard to physical components that are purchased. Vendors typically publish values for a product’s mean time between failure (MTBF), which describes how often a component fails on average. Another valuable metric typically provided is the mean time to repair (MTTR), which describes the average amount of time it will take to get the device fixed and back online.
MTBF and MTTR: Although SLAs are appropriate for services that are provided, a slightly different approach to introducing predictability can be used with regard to physical components that are purchased. Vendors typically publish values for a product’s mean time between failure (MTBF), which describes how often a component fails on average. Another valuable metric typically provided is the mean time to repair (MTTR), which describes the average amount of time it will take to get the device fixed and back online.
![]() Single point of failure (SPOF): Though not actually a strategy, it is worth mentioning that the ultimate goal of any of these approaches is to avoid an SPOF of failure in a system. All components and groups of components and devices should be examined to discover any single element that could interrupt access to resources if a failure occurs. Each SPOF should then be mitigated in some way.
Single point of failure (SPOF): Though not actually a strategy, it is worth mentioning that the ultimate goal of any of these approaches is to avoid an SPOF of failure in a system. All components and groups of components and devices should be examined to discover any single element that could interrupt access to resources if a failure occurs. Each SPOF should then be mitigated in some way.
Incident Management
Incident response is vital to every organization to ensure that any security incidents are detected, contained, and investigated. Incident response is the beginning of any investigation. After an incident has been discovered, incident response personnel perform specific tasks. During the entire incident response, the incident response team must ensure that they follow proper procedures to ensure that evidence is preserved.
As part of incident response, security professionals must understand the difference between events and incidents (see the following section). The incident response team must have the appropriate incident response procedures in place to ensure that the incident is handled, but the procedures must not hinder any forensic investigations that might be needed to ensure that parties are held responsible for any illegal actions. Security professionals must understand the rules of engagement and the authorization and scope of any incident investigation.
Event Versus Incident
In regard to incident response, a basic difference exists between events and incidents. An event is a change of state that occurs. Whereas events include both negative and positive events, incident response focuses more on negative events—events that have been deemed as negatively impacting the organization. An incident is a series of events that negatively impact an organization’s operations and security.
Events can only be detected if an organization has established the proper auditing and security mechanisms to monitor activity. A single negative event might occur. For example, the auditing log might show that an invalid login attempt occurred. By itself, this login attempt is not a security concern. However, if many invalid login attempts occur over a period of a few hours, the organization might be undergoing an attack. The initial invalid login is considered an event, but the series of invalid login attempts over a few hours would be an incident, especially if it is discovered that the invalid login attempts all originated from the same IP address.
Incident Response Team and Incident Investigations
When establishing the incident response team, organizations must consider the technical knowledge of each individual. The members of the team must understand the organization’s security policy and have strong communication skills. Members should also receive training in incident response and investigations.
When an incident has occurred, the primary goal of the team is to contain the attack and repair any damage caused by the incident. Security isolation of an incident scene should start immediately when the incident is discovered. Evidence must be preserved, and the appropriate authorities should be notified.
The incident response team should have access to the incident response plan. This plan should include the list of authorities to contact, team roles and responsibilities, an internal contact list, securing and preserving evidence procedures, and a list of investigations experts who can be contacted for help. A step-by-step manual should be created that the incident response team must follow to ensure that no steps are skipped. After the incident response process has been engaged, all incident response actions should be documented.
If the incident response team determines that a crime has been committed, senior management and the proper authorities should be contacted immediately.
Rules of Engagement, Authorization, and Scope
An organization ought to document the rules of engagement, authorization, and scope for the incident response team. The rules of engagement define which actions are acceptable and unacceptable if an incident has occurred. The authorization and scope provide the incident response team with the authority to perform an investigation and with the allowable scope of any investigation they must undertake.
The rules of engagement act as a guideline for the incident response team to ensure that they do not cross the line from enticement into entrapment. Enticement occurs when the opportunity for illegal actions is provided (luring) but the attacker makes his own decision to perform the action, and entrapment means to encourage someone to commit a crime that the individual might have had no intention of committing. Enticement is legal but does raise ethical arguments and might not be admissible in court. Conversely, entrapment is illegal.
Incident Response Procedures
When performing incident response, it is important that the incident response team follow incident response procedures. Depending on where you look, you might find different steps or phases included as part of the incident response process.
For the CISSP exam, you need to remember the following steps:
1. Detect the incident.
2. Respond to the incident.
3. Report the incident to the appropriate personnel.
4. Recover from the incident.
5. Remediate all components affected by the incident to ensure that all traces of the incident have been removed.
6. Review the incident, and document all findings.
The actual investigation of the incident occurs during the respond, report, and recover steps. Following appropriate forensic and digital investigation processes during the investigation can ensure that evidence is preserved.
The incident response process is shown in Figure 7-8.

Incident Response Management
Security events will inevitably occur, and the response to these events says much about how damaging the events will be to the organization. Incident response policies should be formally designed, well communicated, and followed. They should specifically address cyber-attacks against an organization’s IT systems.
Detect
The first step is to detect the incident. Prior to any incident response investigation, security professionals must first perform the appropriate triage for the affected assets. This includes initially detecting the incident and determining how serious the incident is. In some cases, during the triage phase, security professionals may determine that a false positive has occurred, meaning that an attack really did not occur, even though an alert indicated that it did. If an attack is confirmed, then the incident response will progress into investigative actions.
All detective controls, such as auditing, discussed in Chapter 1, “Security and Risk Management,” are designed to provide this capability. The worst sort of incident is the one that goes unnoticed.
Respond
The response to the incident should be appropriate for the type of incident. Denial-of-service (DoS) attacks against the web server would require a quicker and different response than a missing mouse in the server room. Establish standard responses and response times ahead of time.
Response involves containing the incident and quarantining the affected assets to reduce the potential impact by preventing other assets from being affected. Different methods can be used, depending on the category of the attack, the asset affected, and the data criticality or infection risk.
After an attack is contained or isolated, analysts should work to examine and analyze the cause of the incident. This includes determining where the incident originated. Security professionals should use experience and formal training to make the appropriate conclusions regarding the incident. After the root cause has been determined, security professionals should follow incident handling policies that the organization has in place.
Mitigate
Although mitigation is a standard part of incident response, it is not listed as a separate step. However, security professionals should understand the importance of mitigation as part of any incident response. Mitigation is actually part of responding to an incident and includes limiting the scope of what the attack might do to the organization’s assets. If damage has occurred or the incident may broaden and affect other assets, proper mitigation techniques ensure that the incident is contained to within a certain scope of assets. Mitigation options vary, depending on the kind of attack that has occurred. Security professionals should develop procedures in advance that detail how to properly mitigate any attacks that occur against organizational assets. Preparing these mitigation procedures in advance ensures that they are thorough and gives personnel a chance to test the procedures.
Report
All incidents should be reported within a timeframe that reflects the seriousness of the incident. In many cases establishing a list of incident types and the person to contact when that type of incident occurs is helpful. Exercising attention to detail at this early stage while time-sensitive information is still available is critical.
Recover
Recovery involves a reaction designed to make the network or system that is affected functional again; it includes repair of the affected assets and prevention of similar incidents in the future. Exactly what recovery means depends on the circumstances and the recovery measures that are available. For example, if fault-tolerance measures are in place, the recovery might consist of simply allowing one server in a cluster to fail over to another. In other cases, recovery could mean restoring the server from a recent backup. The main goal of this step is to make all resources available again. Delay putting any asset back into operation until it is at least protected from the incident that occurred. Thoroughly test assets for vulnerabilities and weaknesses before reintroducing them into production.
Remediate
This step involves eliminating any residual DoS attacks danger or damage to the network that still might exist. For example, in the case of a virus outbreak, it could mean scanning all systems to root out any additional effected machines. These measures are designed to make a more detailed mitigation when time allows.
Lessons Learned and Review
Finally, review each incident to discover what could be learned from it. Changes to procedures might be called for. Share lessons learned with all personnel who might encounter this type of incident again. Complete documentation and analysis is the goal of this step.
Preventive Measures
As you have probably gathered by now, a wide variety of security threats face those charged with protecting the assets of an organization. Luckily, a wide variety of tools is available to use to accomplish this task. This section covers some common threats and mitigation approaches.
Clipping Levels
Clipping levels set a baseline for normal user errors, and violations exceeding that threshold will be recorded for analysis of why the violations occurred. When clipping levels are used, a certain number of occurrences of an activity might generate no information whereas recording of activities begins when a certain level is exceeded.
Clipping levels are used to:
![]() Reduce the amount of data to be evaluated in audit logs
Reduce the amount of data to be evaluated in audit logs
![]() Provide a baseline of user errors above which violations will be recorded
Provide a baseline of user errors above which violations will be recorded
Deviations from Standards
One of the methods that you can use to identify performance problems that arise is by developing standards or baselines for the performance of certain systems. After these benchmarks have been established, deviations for the standards can be identified. This is especially helpful in identifying certain types of DoS attacks as they occur. Beyond the security benefit, it also aids in identifying systems that might need upgrading before the situation effects productivity.
Unusual or Unexplained Events
In some cases events occur that appear to have no logical cause. That should never be accepted as an answer when problems occur. Although the focus is typically on getting systems up and running again, the root causes of issues must be identified. Avoid the temptation to implement a quick workaround (often at the expense of security). When time permits, using a methodical approach to find exactly why the event happened is best, because inevitably the problem will come back if the root cause has not been addressed.
Unscheduled Reboots
When systems reboot on their own, it is typically a sign of hardware problems of some sort. Reboots should be recorded and addressed. Overheating is the cause of many reboots. Often reboots can also be the result of a DoS attack. Have a system monitoring in place to record all system reboots, and investigate any that are not initiated by a human or have occurred as a result of an automatic upgrade.
Unauthorized Disclosure
The unauthorized disclosure of information is a large threat to organizations. It includes destruction of information, interruption of service, theft of information, corruption of information, and improper modification of information. Enterprise solutions must be deployed to monitor for any potential disclosure of information.
Trusted Recovery
When an application or operating system suffers a failure (crash, freeze, and so on), it is important that the system respond in a way that leaves the system in a secure state or that it makes a trusted recovery. A trusted recovery ensures that security is not breached when a system crash or other system failure occurs. You might recall that the Orange Book requires a system be capable of a trusted recovery for all systems rated B3 or A1.
Trusted Paths
A trusted path is a communication channel between the user or the program through which he is working and the trusted computer base (TCB). The TCB provides the resources to protect the channel and prevent it from being compromised. Conversely, a communication path that is not protected by the system’s normal security mechanisms is called a covert channel. Taking this a step further, if the interface offered to the user is secured in this way, it is referred to as a trusted shell.
Operations security must ensure that trusted paths are validated. This occurs using log collection, log analysis, vulnerability scans, patch management, and system integrity checks.
Input/Output Controls
The main thrust of input/output control is to apply controls or checks to the input that is allowed to be submitted to the system. Performing input validation on all information accepted into the system can ensure that it is of the right data type and format and that it does not leave the system in an insecure state.
Also, secure output of the system (printouts, reports, and so on). All sensitive output information should require a receipt before release and have proper access controls applied regardless of its format.
System Hardening
Another of the ongoing goals of operations security is to ensure that all systems have been hardened to the extent that is possible and still provide functionality. The hardening can be accomplished both on a physical and logical basis. Physical security of systems is covered in detail later in this chapter. From a logical perspective
![]() Remove unnecessary applications.
Remove unnecessary applications.
![]() Disable unnecessary services.
Disable unnecessary services.
![]() Block unrequired ports.
Block unrequired ports.
![]() Tightly control the connecting of external storage devices and media if it’s allowed at all.
Tightly control the connecting of external storage devices and media if it’s allowed at all.
Vulnerability Management Systems
The importance of performing vulnerability and penetration testing has been emphasized throughout this book. A vulnerability management system is software that centralizes and to a certain extent automates the process of continually monitoring and testing the network for vulnerabilities. These systems can scan the network for vulnerabilities, report them, and in many cases remediate the problem without human intervention. Although they’re a valuable tool in the toolbox, these systems, regardless of how sophisticated they might be, cannot take the place of vulnerability and penetration testing performed by trained professionals.
IDS/IPS
Setup, configuration, and monitoring of any intrusion detection and intrusion prevention systems (IDS/IPS) are also ongoing responsibilities of operations security. Many of these systems must be updated on a regular basis with the attack signatures that enable them to detect new attack types. The analysis engines that they use also sometimes have updates that need to be applied.
Moreover, the log files of systems that are set to log certain events rather than take specific actions when they occur need to have those logs archived and analyzed on a regular basis. Spending large sums of money on software that gathers information and then disregarding that information makes no sense.
IDS and IPS are discussed in more detail earlier in this chapter and in Chapter 4.
Intrusion response is just as important as intrusion detection and prevention. Intrusion response is about responding appropriately to any intrusion attempt. Most systems use alarms and signals to communicate with the appropriate personnel or systems when an intrusion has been attempted. An organization must respond to alerts and signals in a timely manner.
Firewalls
Firewalls can be implemented on multiple levels to allow or prevent communication based on a variety of factors. If personnel discover that certain types of unwanted traffic are occurring, it is often fairly simple to configure a firewall to prevent that type of traffic. Firewalls can protect the boundaries between networks, traffic within a subnetwork, or a single system. Make sure to keep firewalls fully updated per the vendor’s recommendations.
Whitelisting/Blacklisting
Whitelisting occurs when a list of acceptable email addresses, Internet addresses, websites, application, or some other identifier is configured as good senders or as allowed. Blacklisting identifies bad senders. Graylisting is somewhere in between the two, listing entities that cannot be identified as whitelist or blacklist items. In the case of graylisting, the new entity must pass through a series of tests to determine whether it will be whitelisted or blacklisted.
Whitelisting, blacklisting, and graylisting are commonly used with spam filtering tools.
Third-Party Security Services
Security professionals may need to rely on third-party security services to find threats in the enterprise. Some common third-party security services include malware/virus detection and honeypots/honeynets. It is often easier to rely on a solution developed by a third party than to try to develop your own in-house solution. Always research the features provided with a solution to determine if it meets the needs of your organization. Compare the different products available to ensure that the organization purchases the best solution for its needs.
Sandboxing
Sandboxing is a software virtualization technique that allows applications and processes to run in an isolated virtual environment. Applications and processes in the sandbox are not able to make permanent changes to the system and its files.
Some malware attempts to delay or stall code execution, allowing the sandbox to time out. A sandbox can use hooks and environmental checks to detect malware. These methods do not prevent many types of malware. For this reason, third-party security services are important.
Honeypots/Honeynets
Honeypots are systems that are configured with reduced security to entice attackers so that administrators can learn about attack techniques. In some cases, entire networks called honeynets are attractively configured for this purpose. These types of approaches should only be undertaken by companies with the skill to properly deploy and monitor them. Some third-party security services can provide this function for organizations.
Anti-malware/Antivirus
Finally, all updates of antivirus and anti-malware software are the responsibility of operations security. It is important to deploy a comprehensive anti-malware/antivirus solution for the entire enterprise.
Patch Management
Patch management is often seen as a subset of configuration management. Software patches are updates released by vendors that either fix functional issues with or close security loopholes in operating systems, applications, and versions of firmware that run on the network devices.
To ensure that all devices have the latest patches installed, deploy a formal system to ensure that all systems receive the latest updates after thorough testing in a non-production environment. It is impossible for the vendor to anticipate every possible impact a change might have on business critical systems in the network. The enterprise is responsible for ensuring that patches do not adversely impact operations.
The patch management life cycle includes the following steps:
1. Patch prioritization and scheduling: Determine the priority of the patches and schedule the patches for deployment.
2. Patch testing: Test the patches prior to deployment to ensure that they work properly and do not cause system or security issues.
3. Patch installation: Install the patches in the live environment.
4. Patch assessment and audit: After patches are deployed, ensure that the patches work properly.
Many organizations deploy a centralized patch management system to ensure that patches are deployed in a timely manner. With this system, administrators can test and review all patches before deploying them to the systems they affect. Administrators can schedule the updates to occur during non-peak hours.
Change Management Processes
All networks evolve, grow, and change over time. Companies and their processes also evolve and change, which is a good thing. But manage change in a structured way so as to maintain a common sense of purpose about the changes. By following recommended steps in a formal process, change can be prevented from becoming the tail that wags the dog. The following are guidelines to include as a part of any change control policy:
![]() All changes should be formally requested. Change logs should be maintained.
All changes should be formally requested. Change logs should be maintained.
![]() Each request should be analyzed to ensure that it supports all goals and polices. This includes baselining and security impact analysis.
Each request should be analyzed to ensure that it supports all goals and polices. This includes baselining and security impact analysis.
![]() Prior to formal approval, all costs and effects of the methods of implementation should be reviewed. Using the collected data, changes should be approved or denied.
Prior to formal approval, all costs and effects of the methods of implementation should be reviewed. Using the collected data, changes should be approved or denied.
![]() After they’re approved, the change steps should be developed.
After they’re approved, the change steps should be developed.
![]() During implementation, incremental testing should occur, and it should rely on a predetermined fallback strategy if necessary. Versioning should be used to effectively track and control changes to a collection of entities.
During implementation, incremental testing should occur, and it should rely on a predetermined fallback strategy if necessary. Versioning should be used to effectively track and control changes to a collection of entities.
![]() Complete documentation should be produced and submitted with a formal report to management.
Complete documentation should be produced and submitted with a formal report to management.
One of the key benefits of following this method is the ability to make use of the documentation in future planning. Lessons learned can be applied and even the process itself can be improved through analysis.
Recovery Strategies
Identifying the preventive controls is the third step of the business continuity steps as outlined in NIST SP 800-34 R1. If preventive controls are identified in the BIA, disasters or disruptive events might be mitigated or eliminated. These preventive measures deter, detect, and/or reduce impacts to the system. Preventive methods are preferable to actions that might be necessary to recover the system after a disruption if the preventive controls are feasible and cost effective.
The following sections discuss the primary preventive controls that organizations can implement as part of business continuity and disaster recovery, including redundant systems, facilities, and power; fault-tolerant technologies; insurance; data backup; and fire detection and suppression.
Redundant Systems, Facilities, and Power
In anticipation of disasters and disruptive events, organizations should implement redundancy for critical systems, facilities, and power and assess any systems that have been identified as critical to determine whether implementing redundant systems is cost effective. Implementing redundant systems at an alternate location often ensures that services are uninterrupted. Redundant systems include redundant servers, redundant routers, redundant internal hardware, and even redundant backbones. Redundancy occurs when an organization has a secondary component, system, or device that takes over when the primary unit fails.
Redundant facilities ensure that the organization maintains a facility at whatever level it chooses to ensure that the organizational services can continue when a disruptive event occurs. Redundant facilities are discussed in more depth elsewhere in this chapter.
Power redundancy is implemented using uninterruptible power supplies (UPSs) and power generators.
Redundancy on individual components can also be provided. The spare components are either cold spares, warm spares, or hot spares. A cold spare is not powered up but can be inserted into the system if needed. A warm spare is in the system but does not have power unless needed. A hot spare is in the system and powered on, ready to become operational at a moment’s notice.
Fault-Tolerance Technologies
Fault tolerance enables a system to continue operation in the event of the failure of one or more components. Fault tolerance within a system can include fault-tolerant adapter cards and fault-tolerant storage drives. One of the most well-known fault tolerance systems is RAID, which is discussed earlier in this chapter.
By implementing fault-tolerant technologies, an organization can ensure that normal operation occurs if a single fault-tolerant component fails.
Insurance
Although redundancy and fault tolerance can actually act as preventive measures against failures, insurance is not really a preventive measure. If an organization purchases insurance to provide protection in the event of a disruptive event, the insurance has no power to protect against the event itself. The purpose of the insurance is to ensure that the organization will have access to additional financial resources to help in the recovery.
Keep in mind that recovery efforts from a disruptive event can often incur large financial costs. Even some of the best estimates might still fall short when the actual recovery must take place. By purchasing insurance, the organization can ensure that key financial transactions, including payroll, accounts payable, and any recovery costs, are covered.
Insurance actual cost valuation (ACV) compensates property based on the value of the item on the date of loss plus 10 percent. However, keep in mind that insurance on any printed materials only covers inscribed, printed, or written documents, manuscripts, or records. It does not cover money and securities. A special type of insurance called business interruption insurance provides monetary protection for expenses and lost earnings.
Organizations should annually review insurance policies and update them as necessary.
Data Backup
Data backup provides prevention against data loss but not prevention against the disruptive event. All organizations should ensure that all systems that store important files are backed up in a timely manner. Users should also be encouraged to back up personal files that they might need. In addition, periodic testing of the restoration process should occur to ensure that the files can be restored.
Data recovery, including backup types and schemes and electronic backup, is covered in more detail later in this chapter.
Fire Detection and Suppression
Organizations should implement fire detection and suppression systems as part of any business continuity plan (BCP). Fire detection and suppressions vary based on the method of detection/suppression used and are discussed in greater detail in the “Environmental Security” section of Chapter 3.
High Availability
High availability in data recovery is a concept that ensures that data is always available using redundancy and fault tolerance. Most organizations implement high-availability solutions as part of any disaster recovery plan (DRP).
High-availability terms and techniques that you must understand include the following:
![]() Redundant Array of Independent Disks (RAID): A hard-drive technology in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from remaking disks in the array without restoring from a backup tape or other backup media.
Redundant Array of Independent Disks (RAID): A hard-drive technology in which data is written across multiple disks in such a way that a disk can fail and the data can be quickly made available from remaking disks in the array without restoring from a backup tape or other backup media.
![]() Storage-area network (SAN): High-capacity storage devices that are connected by a high-speed private network using storage-specific switches.
Storage-area network (SAN): High-capacity storage devices that are connected by a high-speed private network using storage-specific switches.
![]() Failover: The capacity of a system to switch over to a backup system if a failure in the primary system occurs.
Failover: The capacity of a system to switch over to a backup system if a failure in the primary system occurs.
![]() Failsoft: The capability of a system to terminate non-critical processes when a failure occurs.
Failsoft: The capability of a system to terminate non-critical processes when a failure occurs.
![]() Clustering: Refers to a software product that provides load-balancing services. With clustering, one instance of an application server acts as a master controller and distributes requests to multiple instances using round-robin, weighted round-robin, or least-connections algorithms.
Clustering: Refers to a software product that provides load-balancing services. With clustering, one instance of an application server acts as a master controller and distributes requests to multiple instances using round-robin, weighted round-robin, or least-connections algorithms.
![]() Load balancing: Refers to a hardware product that provides load-balancing services. Application delivery controllers (ADCs) support the same algorithms but also use complex number-crunching processes, such as per-server CPU and memory utilization, fastest response times, and so on, to adjust the balance of the load. Load-balancing solutions are also referred to as farms or pools.
Load balancing: Refers to a hardware product that provides load-balancing services. Application delivery controllers (ADCs) support the same algorithms but also use complex number-crunching processes, such as per-server CPU and memory utilization, fastest response times, and so on, to adjust the balance of the load. Load-balancing solutions are also referred to as farms or pools.
Quality of Service
Quality of service (QoS) is a technology that manages network resources to ensure a predefined level of service. It assigns traffic priorities to the different types of traffic or protocol on a network. QoS deploys when a bottleneck occurs and decides which traffic is more important than the rest. Exactly what traffic is more important than what other traffic is based on rules the administrator supplies. Importance can be based on IP address, MAC address, and even service name. However, QoS works only when a bottleneck occurs in the appropriate location and the settings are your bandwidth declarations. For example, if the QoS settings are set beyond the ISP’s bandwidth, traffic will not be prioritized if a router thinks there is enough available bandwidth. But what if the ISP’s maximums are being met, and the ISP decides what is or is not important? The key to any QoS deployment is to tweak the settings and observe the network over time.
System Resilience
System resilience is the ability of a system, device, or data center to recover quickly and continue operating after an equipment failure, a power outage, or another disruption. It involves the use of redundant components or facilities. When one component fails or is disrupted, the redundant component takes over seamlessly and continues to provide services to the users.
Create Recovery Strategies
Organizations must create recovery strategies for all assets that are vital to successful operation. Higher-level recovery strategies identify the order in which processes and functions are restored. System-level recovery strategies define how a particular system is to be restored. Keep in mind those individuals who best understand the system should define system recovery strategies. Although the BCP committee probably can develop the prioritized recovery lists and high-level recovery strategies, system administrators and other IT personnel need to be involved in the development of recovery strategies for IT assets.
Disaster recovery tasks include recovery procedures, personnel safety procedures, and restoration procedures. The overall business recovery plan should require a committee to be formed to decide the best course of action. This recovery plan committee receives its direction from the BCP committee and senior management.
All decisions regarding recovery should be made in advance and incorporated into the DRP. Any plans and procedures that are developed should refer to functions or processes, not specific individuals. As part of the disaster recovery planning, the recovery plan committee should contact critical vendors ahead of time to ensure that any equipment or supplies can be replaced in a timely manner.
When a disaster or disruptive event has occurred, the organization’s spokesperson should report the bad news in an emergency press conference before the press learns of the news through another channel. The DRP should detail any guidelines for handling the press. The emergency press conference site should be planned ahead of time.
When resuming normal operations after a disruptive event, the organization should conduct a thorough investigation if the cause of the event is unknown. Personnel should account for all damage-related costs that occur as a result of the event. In addition, appropriate steps should be taken to prevent further damage to property.
The commonality between all recovery plans is that they all become obsolete. For this reason, they require testing and updating.
This section includes a discussion of categorizing asset recovery priorities, business process recovery, facility recovery, supply and technology recovery, user environment recovery, data recovery, and training personnel.
Categorize Asset Recovery Priorities
As discussed in Chapter 1, the recovery time objective (RTO), work recovery time (WRT), and recovery point objective (RPO) values determine what recovery solutions are selected. An RTO stipulates the amount of time an organization will need to recover from a disaster, and an RPO stipulates the amount of data an organization can lose when a disaster occurs. The RTO, WRT, and RPO values are derived during the BIA process.
In developing the recovery strategy, the recovery plan committee takes the RTO, WRT, and RPO value and determines the recovery strategies that should be used to ensure that the organization meets these BIA goals.
Critical devices, systems, and applications need to be restored earlier than devices, systems, or applications that do not fall into this category. Keep in mind when classifying systems that most critical systems cannot be restored using manual methods. The recovery plan committee must understand the backup/restore solutions that are available and implement the system that will provide recovery within the BIA values and cost constraints. The window of time for recovery of data-processing capabilities is based on the criticality of the operations affected.
Business Process Recovery
As part of the DRP, the recovery plan committee must understand the interrelationships between the processes and systems. A business process is a collection of tasks that produce a specific service or product for a particular customer or customers.
For example, if the organization determines that an accounting system is a critical application and the accounting system relies on a database server farm, the DRP needs to include the database server as a critical asset. Although restoring the entire database server farm to restore the critical accounting system might not be necessary, at least one of the servers in the farm is necessary for proper operation.
Workflow documents should be provided to the recovery plan committee for each business process. As part of recovering the business processes, the recovery plan committee must also understand the process’s required roles and resources, input and output tools, and interfaces with other business processes.
Facility Recovery
When dealing with an event that either partially or fully destroys the primary facility, the organization will need an alternate location from which to operate until the primary facility is restored. The DRP should define the alternate location and its recovery procedures, often referred to as a recovery site strategy.
The DRP should include not only how to bring the alternate location to full operation, but also how the organization will return from the alternate location to the primary facility after it is restored. Also, for security purposes, the DRP should include details on the security controls that were used at the primary facility and guidelines on how to implement these same controls at the alternate location.
The most important factor in locating an alternate location during the development of the DRP is to ensure that the alternate location is not affected by the same disaster. This might mean that the organization must select an alternate location that is in another city or geographic region. The main factors that affect the selection of an alternate location include the following:
![]() Geographic location
Geographic location
![]() Organizational needs
Organizational needs
![]() Location’s cost
Location’s cost
![]() Location’s restoration effort
Location’s restoration effort
Testing an alternate location is a vital part of any DRP. Some locations are easier to test than others. The DRP should include instructions on when and how to periodically test alternate facilities to ensure that the contingency facility is compatible with the primary facility.
The alternate locations that security professionals should understand for the CISSP exam include the following:
![]() Tertiary site
Tertiary site
A hot site is a leased facility that contains all the resources needed for full operation. This environment includes computers, raised flooring, full utilities, electrical and communications wiring, networking equipment, and UPSs. The only resource that must be restored at a hot site is the organization’s data, often only partially. It should only take a few hours to bring a hot site to full operation.
Although a hot site provides the quickest recovery, it is the most expensive to maintain. In addition, it can be administratively hard to manage if the organization requires proprietary hardware or software. A hot site requires the same security controls as the primary facility and full redundancy, including hardware, software, and communication wiring.
A cold site is a leased facility that contains only electrical and communications wiring, air conditioning, plumbing, and raised flooring. No communications equipment, networking hardware, or computers are installed at a cold site until it is necessary to bring the site to full operation. For this reason, a cold site takes much longer to restore than a hot or warm site.
Although a cold site provides a slowest recovery, it is the least expensive to maintain. It is also the most difficult to test.
A warm site is a leased facility that contains electrical and communications wiring, full utilities, and networking equipment. In most cases, the only devices that are not included in a warm site are the computers. A warm site takes longer to restore than a hot site but less than a cold site.
A warm site is somewhere between the restoration time and cost of a hot site and cold site. It is the most widely implemented alternate leased location. Although testing a warm site is easier than testing a cold site, a warm site requires much more effort for testing than a hot site.
Figure 7-9 is a chart that compares the components deployed in these three sites.
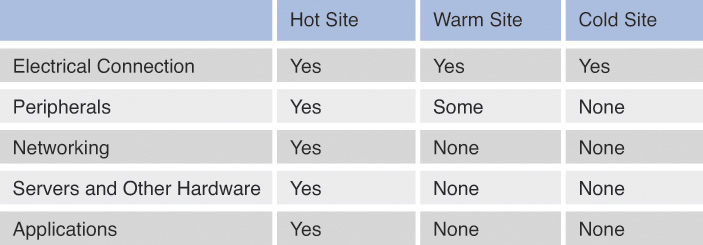
A tertiary site is a secondary backup site that provides an alternate in case the hot site, warm site, or cold site is unavailable. Many large companies implement tertiary sites to protect against catastrophes that affect large geographic areas.
For example, if an organization requires a data center that is located on the coast, the organization might have its primary location in New Orleans, Louisiana, and its hot site in Mobile, Alabama. This organization might consider locating a tertiary site in Miami, Florida, because a hurricane can affect both the Louisiana and Alabama Gulf coast.
A reciprocal agreement is an agreement between two organizations that have similar technological needs and infrastructures. In the agreement, both organizations agree to act as an alternate location for the other if either of the organization’s primary facilities are rendered unusable. Unfortunately in most cases, these agreements cannot be legally enforced.
A disadvantage of this site is that it might not be capable of handling the required workload and operations of the other organization.
Note
A mutual-aid agreement is a pre-arranged agreement between two organizations in which each organization agrees to provide assistance to the other in the event of a disaster.
A redundant or mirrored site is a site that is identically configured as the primary site. A redundant or mirrored site is not a leased site but is usually owned by the same organization as the primary site. The organization is responsible for maintaining the redundant site. Multiple processing sites can also be configured to serve as operationally redundant sites.
Although redundant sites are expensive to maintain, many organizations today see them as a necessary expense to ensure that uninterrupted service can be provided.
Supply and Technology Recovery
Although facility recovery is not often a concern with smaller disasters or disruptive events, almost all recovery efforts usually involve the recovery of supplies and technology. Organizations must ensure that any DRPs include guidelines and procedures for recovering supplies and technology. As part of supply and technology recovery, the DRP should include all pertinent vendor contact information in the event that new supplies and technological assets must be purchased.
The DRP must include recovery information on the following assets that must be restored:
![]() Hardware backup
Hardware backup
![]() Software backup
Software backup
![]() Human resources
Human resources
![]() Heating, ventilation, and air conditioning (HVAC)
Heating, ventilation, and air conditioning (HVAC)
![]() Supplies
Supplies
![]() Documentation
Documentation
Hardware that must be included as part of the DRP includes client computers, server computers, routers, switches, firewalls, and any other hardware that is running on the organization’s network. The DRP must include not only guidelines and procedures for restoring all the data on each of these devices, but also information regarding restoring these systems manually if the systems are damaged or completely destroyed. Legacy devices that are no longer unavailable in the retail market should also be identified.
As part of preparing the DRP, the recovery plan team must determine the amount of time that it will take the hardware vendors to provide replacements for any damaged or destroyed hardware. Without this information documented, any recovery plans might be ineffective due to lack of resources. Organizations might need to explore other options, including purchasing redundant systems and storing them at an alternate location, if vendors are unable to provide replacement hardware in a timely manner. When replacement of legacy devices is possible, organizations should take measures to replace them before the disaster occurs.
Even if an organization has every device needed to restore its infrastructure, those devices are useless if the applications and software that run on the devices is not available. The applications and software include any operating systems, databases, and utilities that need to be running on the device.
Many organizations might think that this requirement is fulfilled if they have a backup on either tape, DVD, flash drive, hard drive, or other media of all their software. But all software that is backed up usually requires at least an operating system to be running on the device on which it is restored. These data backups often also require that the backup management software is running on the backup device, whether that is a server or dedicated device.
All software installation media, service packs, and other necessary updates should be stored at an alternate location. In addition, all license information should be documented as part of the DRP. Finally, frequent backups of applications should be taken, whether this is through the application’s internal backup system or through some other organizational backup. A backup is only useful if it can be restored so the DRP should fully document all the steps involved.
In many cases, applications are purchased from a software vendor, and only the software vendor understands the coding that occurs in the applications. Because there are no guarantees in today’s market, some organizations might decide that they need to ensure that they are protected against a software vendor’s demise. A software escrow is an agreement whereby a third party is given the source code of the software to ensure that the customer has access to the source code if certain conditions for the software vendor occur, including bankruptcy and disaster.
No organization is capable of operating without personnel. An occupant emergency plan specifically addresses procedures for minimizing loss of life or injury when a threat occurs. The human resources team is responsible for contacting all personnel in the event of a disaster. Contact information for all personnel should be stored onsite and offsite. Multiple members of the HR team should have access to the personnel contact information. Remember that personnel safety is always the primary concern. All other resources should be protected only after the personnel is safe.
After the initial event is over, the HR team should monitor personnel morale and guard against employee stress and burnout during the recovery period. If proper cross-training has occurred, multiple personnel can be rotated in during the recovery process. Any DRP should take into consideration the need to provide adequate periods of rest for any personnel involved in the disaster recovery process. It should also include guidelines on how to replace any personnel who is a victim of the disaster.
The organization must ensure that salaries and other funding to personnel continue during and after the disaster. Because funding can be critical both for personnel and for resource purchases, authorized, signed checks should be securely stored offsite. Lower-level management with the appropriate access controls should have the ability to disperse funds using these checks in the event that senior management is unavailable.
An executive succession plan should also be created to ensure that the organization follows the appropriate steps to protect itself and continue operation.
Often disasters affect the ability to supply an organization with its needed resources, including paper, cabling, and even water. The organization should document any resources that are vital to its daily operations and the vendors from which these resources can be obtained. Because supply vendors can also be affected by the disaster, alternative suppliers should be identified.
For disaster recovery to be a success, the personnel involved must be able to complete the appropriate recovery procedures. Although the documentation of all these procedures might be tedious, it is necessary to ensure that recovery occurs. In addition, each department within the organization should be asked to decide what departmental documentation is needed to carry out day-to-day operations. This documentation should be stored in a central location onsite, and a copy should be retained offsite as well. Specific personnel should be tasked with ensuring that this documentation is created, stored, and updated as appropriate.
User Environment Recovery
All aspects of the end user environment recovery must be included as part of the DRP to ensure that the end users can return to work as quickly as possible. As part of this user environment recovery, end user notification must occur. Users must be notified of where and when to report after a disaster occurs.
The actual user environment recovery should occur in stages, with the most critical functions being restored first. User requirements should be documented to ensure that all aspects of the user environment are restored. For example, users in a critical department might all need their own client computer. These same users might also need to access an application that is located on a server. If the server is not restored, the users will be unable to perform their job duties even if their client computers are available.
Finally, manual steps that can be used for any function should be documented. Because we are so dependent on technology today, we often overlook the manual methods of performing our job tasks. Documenting these manual methods might ensure that operations can still occur, even if they occur at a decreased rate.
Data Recovery
In most organizations, the data is one of the most critical assets when recovering from a disaster. The BCPs and DRPs must include guidelines and procedures for recovering data. However, the operations teams must determine which data is backed up, how often the data is backed up, and the method of backup used. So while this section discusses data backup, remember that the BCP teams do not actually make any data backup decisions. The BCP teams are primarily concerned with ensuring that the data that is backed up can be restored in a timely manner.
This section discusses the data backup types and schemes that are used as well as electronic backup methods that organizations can implement.
To design an appropriate data recovery solution, security professionals must understand the different types of data backups that can occur and how these backups are used together to restore the live environments.
For the CISSP exam, security professionals must understand the following data backup types and schemes:
![]() First in, first out rotation scheme
First in, first out rotation scheme
![]() Grandfather/father/son rotation scheme
Grandfather/father/son rotation scheme
The three main data backups are full backups, differential backups, and incremental backups. To understand these three data backup types, you must understand the concept of archive bits. When a file is created or updated, the archive bit for the file is enabled. If the archive bit is cleared, the file will not be archived during the next backup. If the archive bit is enabled, the file will be archived during the next backup.
With a full backup, all data is backed up. During the full backup process, the archive bit for each file is cleared. A full backup takes the longest time and the most space to complete. However, if an organization only uses full backups, then only the latest full backup needs to be restored. Any backup that uses a differential or incremental backup will first start with a full backup as its baseline. A full backup is the most appropriate for offsite archiving.
In a differential backup, all files that have been changed since the last full backup will be backed up. During the differential backup process, the archive bit for each file is not cleared. A differential backup might vary from taking a short time and a small amount of space to growing in both the backup time and amount of space it needs over time. Each differential backup will back up all the files in the previous differential backup if a full backup has not occurred since that time. In an organization that uses a full/differential scheme, the full backup and only the most recent differential backup must be restored, meaning only two backups are needed.
An incremental backup backs up all files that have been changed since the last full or incremental backup. During the incremental backup process, the archive bit for each file is cleared. An incremental backup usually takes the least amount of time and space to complete. In an organization that uses a full/incremental scheme, the full backup and each subsequent incremental backup must be restored. The incremental backups must be restored in order. If your organization completes a full backup on Sunday and an incremental backup daily Monday through Saturday, up to seven backups could be needed to restore the data. Figure 7-10 compares the different types of backups.

Copy and daily backups are two special backup types that are not considered part of any regularly scheduled backup scheme because they do not require any other backup type for restoration. Copy backups are similar to normal backups but do not reset the file’s archive bit. Daily backups use a file’s time stamp to determine whether it needs archiving. Daily backups are popular in mission-critical environments where multiple daily backups are required because files are updated constantly.
Transaction log backups are only used in environments where capturing all transactions that have occurred since the last backup is important. Transaction log backups help organizations to recover to a particular point in time and are most commonly used in database environments.
Although magnetic tape drives are still used to back up data, many organizations today back up their data to optical discs, including CD-ROMs, DVDs, and Blu-ray discs; high-capacity, high-speed magnetic drives; flash-based media; or other media. No matter the media used, retaining backups both onsite and offsite is important. Store onsite backup copies in a waterproof, heat-resistant, fire-resistant safe or vault.
As part of any backup plan, an organization should also consider the backup rotation scheme that it will use. Cost considerations and storage considerations often dictate that backup media is reused after a period of time. If this reuse is not planned in advance, media can become unreliable due to overuse. Two of the most popular backup rotation schemes are first in, first out and grandfather/father/son.
In the first in, first out (FIFO) scheme, the newest backup is saved to the oldest media. Although this is the simplest rotation scheme, it does not protect against data errors. If an error in data exists, the organization might not have a version of the data that does not contain the error.
In the grandfather/father/son scheme (GFS), three sets of backups are defined. Most often these three definitions are daily, weekly, and monthly. The daily backups are the sons, the weekly backups are the fathers, and the monthly backups are the grandfathers. Each week, one son advances to the father set. Each month, one father advances to the grandfather set.
Figure 7-11 displays a typical 5-day GFS rotation using 21 tapes. The daily tapes are usually differential or incremental backups. The weekly and monthly tapes must be a full backup.
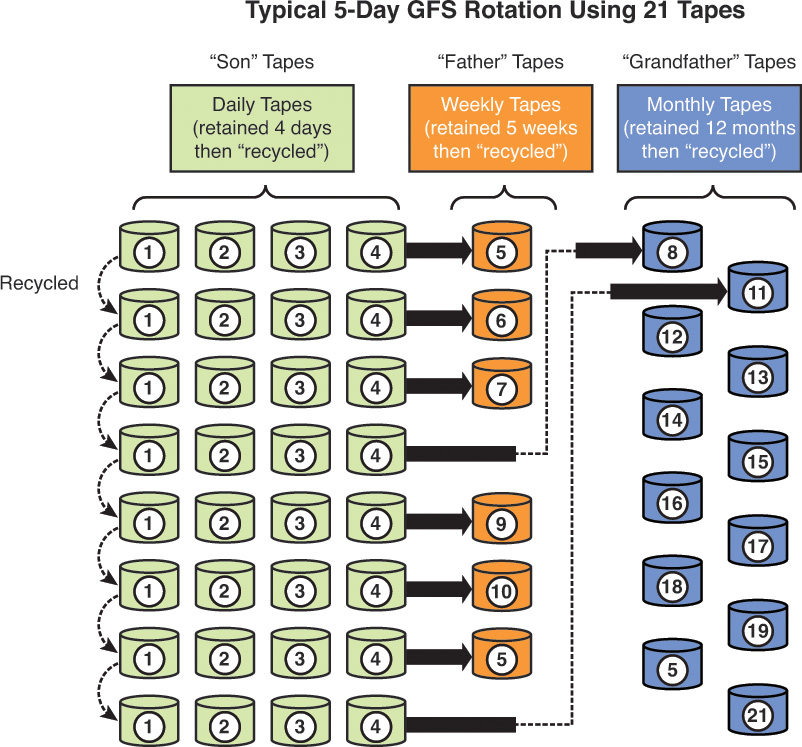
Electronic backup solutions back up data quicker and more accurately than the normal data backups and are best implemented when information changes often.
For the CISSP exam, you should be familiar with the following electronic backup terms and solutions:
![]() Electronic vaulting: Copies files as modifications occur. This method occurs in real time.
Electronic vaulting: Copies files as modifications occur. This method occurs in real time.
![]() Remote journaling: Copies the journal or transaction log offsite on a regular schedule. This method occurs in batches.
Remote journaling: Copies the journal or transaction log offsite on a regular schedule. This method occurs in batches.
![]() Tape vaulting: Creates backups over a direct communication line on a backup system at an offsite facility.
Tape vaulting: Creates backups over a direct communication line on a backup system at an offsite facility.
![]() Hierarchical storage management (HSM): Stores frequently accessed data on faster media and less frequently accessed data on slower media.
Hierarchical storage management (HSM): Stores frequently accessed data on faster media and less frequently accessed data on slower media.
![]() Optical jukebox: Stores data on optical disks and uses robotics to load and unload the optical disks as needed. This method is ideal when 24/7 availability is required.
Optical jukebox: Stores data on optical disks and uses robotics to load and unload the optical disks as needed. This method is ideal when 24/7 availability is required.
![]() Replication: Copies data from one storage location to another. Synchronous replication uses constant data updates to ensure that the locations are close to the same, whereas asynchronous replication delays updates to a predefined schedule.
Replication: Copies data from one storage location to another. Synchronous replication uses constant data updates to ensure that the locations are close to the same, whereas asynchronous replication delays updates to a predefined schedule.
Many companies use cloud backup or replication solutions. Any organization considering a cloud solution should research the full security implications of this type of deployment.
Training Personnel
Even if an organization takes the steps to develop the most thorough BCPs and DRPs, these plans are useless if the organization’s personnel do not have the skills to completely recover the organization’s assets when a disaster occurs. Personnel should be given the appropriate time and monetary resources to ensure that adequate training occurs. This includes allowing personnel to test any DRPs.
Training should be obtained from both internal and external sources. When job duties change or new personnel are hired, policies should be in place to ensure the appropriate transfer of knowledge occurs.
Disaster Recovery
Disaster recovery involves restoring services and systems from a contingency state, or the temporary state that operations may be in where they are running but not at the primary facility or on the optimum resources. The disaster recovery plan (DRP) is discussed in detail in Chapter 1. In this chapter, we talk about the disaster recovery process further, in terms of response, personnel, communications, assessment, restoration, and training and awareness.
Response
Once an event has occurred, the appropriate personnel should be contacted to initiate the communications that alert the appropriate recovery team and the affected personnel of the event. All the teams listed in the personnel section then need to perform their duties. A process hierarchy must be developed so that each team performs its duties as part of the disaster recovery process in the correct order.
Personnel
Although the number one and number two priorities when a disaster occurs are personnel safety and health and damage mitigation, respectively, recovering from a disaster quickly becomes an organization’s priority after these two are handled. However, no organization can recover from a disaster if the personnel are not properly trained and prepared. To ensure that personnel can perform their duties during disaster recovery, they must know and understand their job tasks.
During any disaster recovery, financial management is important. Financial management usually includes the chief financial officer and any other key accounting personnel. This group must track the recovery costs and assess the cash flow projections. They formally notify any insurers of claims that will be made. Finally, this group is responsible for establishing payroll continuance guidelines, procurement procedures, and emergency costs tracking procedures.
Organizations must decide which teams are needed during a disaster recovery and ensure that the appropriate personnel are placed on each of these teams. The disaster recovery manager directs the short-term recovery actions immediately following a disaster.
Organizations might need to implement the following teams to provide the appropriate support for the DRP:
![]() Damage assessment team
Damage assessment team
![]() Legal team
Legal team
![]() Media relations team
Media relations team
![]() Recovery team
Recovery team
![]() Relocation team
Relocation team
![]() Restoration team
Restoration team
![]() Salvage team
Salvage team
![]() Security team
Security team
Damage Assessment Team
The damage assessment team is responsible for determining the disaster’s cause and the amount of damage that has occurred to organizational assets. It identifies all affected assets and the critical assets’ functionality after the disaster. The damage assessment team determines which assets will need to be restored and replaced and contacts the appropriate teams that need to be activated.
Legal Team
The legal team deals with all legal issues immediately following the disaster and during the disaster recovery. The legal team oversees any public relations events that are held to address the disaster, although the media relations team will actually deliver the message. The legal team should be consulted to ensure that all recovery operations adhere to federal and state laws and regulations.
Media Relations Team
The media relations team informs the public and media whenever emergencies extend beyond the organization’s facilities according to the guidelines given in the DRP. The emergency press conference site should be planned ahead. When issuing public statements, the media relations team should be honest and accurate about what is known about the event and its effects. The organization’s response to the media during and after the event should be unified.
A credible, informed spokesperson should deliver the organization’s response. When dealing with the media after a disaster, the spokesperson should report bad news before the media discovers it through another channel. Anyone making disaster announcements to the public should understand that the audience for such announcements includes the media, unions, stakeholders, neighbors, employees, contractors, and even competitors.
Recovery Team
The recovery team’s primary task is recovering the critical business functions at the alternate facility. This mostly involves ensuring that the physical assets are in place, including computers and other devices, wiring, and so on. The recovery team usually oversees the relocation and restoration teams.
Relocation Team
The relocation team oversees the actual transfer of assets between locations. This includes moving assets from the primary site to the alternate site and then returning those assets when the primary site is ready for operation.
Restoration Team
The restoration team actually ensures that the assets and data are restored to operations. The restoration team needs access to the backup media.
Salvage Team
The salvage team recovers all assets at the disaster location and ensures that the primary site returns to normal. The salvage team manages the cleaning of equipment, the rebuilding of the original facility, and identifies any experts to employ in the recovery process. In most cases, the salvage team declares when operations at the disaster site can resume.
Security Team
The security team is responsible for managing the security at both the disaster site and any alternate location that the organization uses during the recovery. Because the geographic area that the security team must manage after the disaster is often much larger, the security team might need to hire outside contractors to aid in this process. Using these outside contractors to guard the physical access to the sites and using internal resources to provide security inside the facilities is always better because the reduced state might make issuing the appropriate access credential to contractors difficult.
Communications
Communication during disaster recovery is important to ensure that the organization recovers in a timely manner. It is also important to ensure that no steps are omitted and that the steps occur in the correct order. Communication with personnel depends on who is being contacted about the disaster. Personnel who are affected by a disaster should receive communications that list the affected systems, the projected outage time, and any contingencies they should follow in the meantime. The different disaster recovery teams should receive communications that pertain to their duties during the recovery from the disaster.
During recovery, security professionals should work closely with the different teams to ensure that all assets remain secure. All teams involved in the process should also communicate often with each other to update each other on the progress.
Assessment
When an event occurs, personnel need to assess the event’s severity and impact. Doing so ensures that the appropriate response is implemented. Most organizations establish event categories, including non-incident, incident, and severe incident. Each organization should have a disaster recovery assessment process in place to ensure that personnel properly assess each event.
Restoration
The restoration process involves restoring the primary systems and facilities to normal operation. The personnel involved in this process depend on the assets that were affected by the event. Any teams involved in the recovery of assets should carefully coordinate their recovery efforts. Without careful coordination, recovery could be negatively impacted. For example, if full recovery of a web application requires that the database servers be operational, the database administrator must work closely with the web application administrator to ensure that both are returned to normal function.
Training and Awareness
Personnel at all levels need to be given the proper training on the disaster recovery process. Regular users just need to be given awareness training so that they understand the complexity of the process. Leadership needs training on how to lead the organization during a crisis. Technical teams need training on the recovery procedures and logistics. Security professionals need training on how to protect assets during recovery.
Most organizations include business continuity and disaster recovery awareness training as part of the initial training given to personnel when they are hired. Organizations should also periodically update personnel to ensure that they do not forget about disaster recovery.
Testing Recovery Plans
After the BCP is fully documented, an organization must take measures to ensure that the plan is maintained and kept up to date. At a minimum, an organization must evaluate and modify the BCP and DRP on an annual basis. This evaluation usually involves some sort of test to ensure that the plans are accurate and thorough. Testing frequently is important because any plan is not viable unless testing has occurred. Through testing, inaccuracies, deficiencies, and omissions are detected.
Testing the BCP and DRP prepares and trains personnel to perform their duties. It also ensures that the alternate backup site can perform as needed. When testing occurs, the test is probably flawed if no issues with the plan are found.
The types of tests that are commonly used to assess the BCP and DRP include the following:
![]() Checklist test
Checklist test
![]() Table-top exercise
Table-top exercise
![]() Functional drill
Functional drill
![]() Evacuation drill
Evacuation drill
Read-Through Test
A read-through test involves the teams that are part of any recovery plan. These teams read through the plan that has been developed and attempt to identify any inaccuracies or omissions in the plan.
Checklist Test
The checklist test occurs when managers of each department or functional area review the BCP. These managers make note of any modifications to the plan. The BCP committee then uses all the management notes to make changes to the BCP.
Table-Top Exercise
A table-top exercise is the most cost-effective and efficient way to identify areas of overlap in the plan before conducting higher level testing. A table-top exercise is an informal brainstorming session that encourages participation from business leaders and other key employees. In a table-top exercise, the participants agree to a particular disaster scenario upon which they will focus.
Structured Walk-Through Test
The structured walk-through test involves representatives of each department or functional area thoroughly reviewing the BCP’s accuracy. This type of test is the most important test to perform prior to a live disaster.
Simulation Test
In a simulation test, the operations and support personnel execute the DRP in a role-playing scenario. This test identifies omitted steps and threats.
Parallel Test
A parallel test involves bringing the recovery site to a state of operational readiness but maintaining operations at the primary site.
Full-Interruption Test
A full-interruption test involves shutting down the primary facility and bringing the alternate facility up to full operation. This is a hard switch-over in which all processing occurs at the primary facility until the “switch” is thrown. This type of test requires full coordination between all the parties and includes notifying users in advance of the planned test. An organization should perform this type of test only when all other tests have been implemented and are successful.
Functional Drill
A functionality drill tests a single function or department to see whether the function’s DRP is complete. This type of drill requires the participation of the personnel that perform the function.
Evacuation Drill
In an evacuation drill, personnel follow the evacuation or shelter-in-place guidelines for a particular disaster type. In this type of drill, personnel must understand the area to which they are to report when the evacuation occurs. All personnel should be accounted for at that time.
Business Continuity Planning and Exercises
After a test is complete, all test results should be documented, and the plans should be modified to reflect those results. The list of successful and unsuccessful activities from the tests will be the most useful to management when maintaining the BCP. All obsolete information in the plans should be deleted, and any new information should be added. In addition, modifying current information based on new regulations, laws, or protocols might be necessary.
Version control of the plans should be managed to ensure that the organization always uses the most recent version. In addition, the BCP should be stored in multiple locations to ensure that it is available if a location is destroyed by the disaster. Multiple personnel should have the latest version of the plans to ensure that the plans can be retrieved if primary personnel are unavailable when the plan is needed.
Physical Security
Physical security involves using the appropriate security controls to protect all assets from physical access. Perimeter security involves implementing the appropriate perimeter security controls, including gates and fences, perimeter intrusion detection, lighting, patrol force, and access control, to prevent access to the perimeter of a facility. Building and internal security involves implementing the appropriate building and internal security controls.
Perimeter Security
When considering the perimeter security of a facility, taking a holistic approach, sometimes known as the concentric circle approach, is sometimes helpful (see Figure 7-12). This approach relies on creating layers of physical barriers to information.
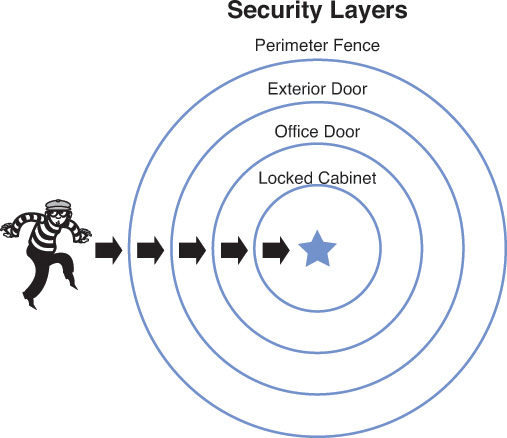
In this section, we’ll look at implementing this concept in detail.
Gates and Fences
The outermost ring in the concentric circle approach is comprised of the gates and fences that surround the facility. Within that are interior circles of physical barriers, each of which has its own set of concerns. In this section, considerations for barriers (bollards), fences, gates, and walls are covered.
Barriers called bollards have become quite common around the perimeter of new office and government buildings. These are short vertical posts placed at the building’s entrance way and lining sidewalks that help to provide protection from vehicles that might either intentionally or unintentionally crash into or enter the building or injure pedestrians. They can be made of many types of materials. The ones shown in Figure 7-13 are stainless steel.

Fencing is the first line of defense in the concentric circle paradigm. When selecting the type of fencing to install, consider the determination of the individual you are trying to discourage. Use the following guidelines with respect to height:
![]() Fences 3 to 4 feet tall deter only casual intruders.
Fences 3 to 4 feet tall deter only casual intruders.
![]() Fences 6 to 7 feet tall are too tall to climb easily.
Fences 6 to 7 feet tall are too tall to climb easily.
![]() Fences 8 feet and taller deter more determined intruders, especially when augmented with razor wire.
Fences 8 feet and taller deter more determined intruders, especially when augmented with razor wire.
A geo-fence is a geographic area within which devices are managed using some sort of radio frequency communication. For example, a geo-fence could be set up in a radius around a store or point location or within a predefined set of boundaries, such as around a school zone. It is used to track users or devices entering or leaving the geo-fence area. Alerts could be configured to message the device’s user and the geo-fence operator of the device’s location.
Gates can be weak points in a fence if not handled correctly. Gates are rated by the Underwriters Laboratory in the following way. Each step up in class requires additional levels of protection:
![]() Class 1: Residential use
Class 1: Residential use
![]() Class 2: Commercial usage
Class 2: Commercial usage
![]() Class 3: Industrial usage
Class 3: Industrial usage
![]() Class 4: Restricted area
Class 4: Restricted area
In some cases walls might be called for around a facility. When that is the case, and when perimeter security is critical, intrusion detection systems can be deployed to alert you of any breaching of the walls. These types of systems are covered in more detail in the next section.
Perimeter Intrusion Detection
Regardless of whether you use fences or walls, or even if you decide to deploy neither of these impediments, you can significantly reduce your exposure by deploying one of the following types of perimeter intrusion detection systems. All the systems described next are considered physical intrusion detection methods.
Passive infrared systems (PIR) operate by identifying changes in heat waves in an area. Because the presence of an intruder would raise the temperature of the surrounding air particles, this system alerts or sounds an alarm when this occurs.
Electromechanical systems operate by detecting a break in an electrical circuit. For example, the circuit might cross a window or door and when the window or door is opened the circuit is broken, setting off an alarm of some sort. Another example might be a pressure pad placed under the carpet to detect the presence of individuals.
Photometric, or photoelectric, systems operate by detecting changes in the light and thus are used in windowless areas. They send a beam of light across the area and if the beam is interrupted (by a person, for example) the alarm is triggered.
Acoustical systems use strategically placed microphones to detect any sound made during a forced entry. These systems only work well in areas where there is not a lot of surrounding noise. They are typically very sensitive, which would cause many false alarms in a loud area, such as a door next to a busy street.
These devices generate a wave pattern in the area and detect any motion that disturbs the wave pattern. When the pattern is disturbed, an alarm sounds.
These devices emit a magnetic field and monitor that field. If the field is disrupted, which will occur when a person enters the area, the alarm will sound.
Closed-circuit television system (CCTV) uses sets of cameras that can either be monitored in real time or can record days of activity that can be viewed as needed at a later time. In very high security facilities, these are usually monitored. One of the main benefits of using CCTV is that it increases the guard’s visual capabilities. Guards can monitor larger areas at once from a central location. CCTV is a category of physical surveillance, not computer/network surveillance.
Camera types include outdoor cameras, infrared cameras, fixed position cameras, pan/tilt cameras, dome cameras, and Internet Protocol (IP) cameras. When implementing cameras, organizations need to select the appropriate lens, resolution, frames per second (FPS), and compression. In addition, analysis of the lighting requirements of the different cameras must be understood; a CCTV system should work in the amount of light that the location provides. In addition, an organization must understand the different type of monitor displays, including single-image display, split-screen, and large-format displays.
Lighting
One of the best ways to deter crime and mischief is to shine a light on areas of concern. In this section, we look at some types of lighting and some lighting systems that have proven to be effective. Lighting is considered a physical control for physical security.
The security professional must be familiar with several types of lighting systems:
![]() Continuous lighting: An array of lights that provide an even amount of illumination across an area
Continuous lighting: An array of lights that provide an even amount of illumination across an area
![]() Standby lighting: A type of system that illuminates only at certain times or on a schedule
Standby lighting: A type of system that illuminates only at certain times or on a schedule
![]() Movable lighting: Lighting that can be repositioned as needed
Movable lighting: Lighting that can be repositioned as needed
![]() Emergency lighting: Lighting systems with their own power source to use when power is out
Emergency lighting: Lighting systems with their own power source to use when power is out
A number of options are available when choosing the illumination source or type of light. The following are the most common choices:
![]() Fluorescent: A very low-pressure mercury-vapor gas-discharge lamp that uses fluorescence to produce visible light.
Fluorescent: A very low-pressure mercury-vapor gas-discharge lamp that uses fluorescence to produce visible light.
![]() Mercury vapor: A gas-discharge lamp that uses an electric arc through vaporized mercury to produce light.
Mercury vapor: A gas-discharge lamp that uses an electric arc through vaporized mercury to produce light.
![]() Sodium vapor: A gas-discharge lamp that uses sodium in an excited state to produce light.
Sodium vapor: A gas-discharge lamp that uses sodium in an excited state to produce light.
![]() Quartz lamps: A lamp consisting of an ultraviolet light source, such as mercury vapor, contained in a fused-silica bulb that transmits ultraviolet light with little absorption.
Quartz lamps: A lamp consisting of an ultraviolet light source, such as mercury vapor, contained in a fused-silica bulb that transmits ultraviolet light with little absorption.
Regardless of the light source, it will be rated by its feet of illumination. When positioning the lights, you must take this rating into consideration. For example, if a controlled light fixture mounted on a 5-meter pole can illuminate an area 30 meters in diameter, for security lighting purposes, the distance between the fixtures should be 30 feet. Moreover, there should be extensive exterior perimeter lighting of entrances or parking areas to discourage prowlers or casual intruders.
Patrol Force
An excellent augmentation to all other detection systems is the presence of a guard patrolling the facility. This option offers the most flexibility in reacting to whatever occurs. One of the keys to success is adequate training of the guards so they are prepared for any eventuality. There should be a prepared response for any possible occurrence. One of the main benefits of this approach is that guards can use discriminating judgment based on the situation, which automated systems cannot do.
The patrol force can be internally hired, trained, and controlled or can be outsourced to a contract security company. An organization can control the training and performance of an internal patrol force. However, some organizations outsource the patrol force to ensure impartiality.
Access Control
When granting physical access to the facility, a number of guidelines should be followed with respect to record keeping. Every successful and unsuccessful attempt to enter the facility, including those instances where admission was granted, should be recorded as follows:
![]() Date and time
Date and time
![]() Specific entry point
Specific entry point
![]() User ID employed during the attempt
User ID employed during the attempt
Building and Internal Security
Building and internal security involves the locks, keys, and escort requirements/visitor controls that organizations should consider. Building and internal security is covered in detail in Chapter 3.
Personnel Privacy and Safety
The human resources are the most important assets the organization possesses. You might recall that in the event of a fire, the first action to always take is to evacuate all personnel. Their safety comes before all other considerations. Although equipment and in most cases the data can be recovered, human beings can neither be backed up nor replaced.
An Occupant Emergency Plan (OEP) provides coordinated procedures for minimizing loss of life or injury and protecting property damage in response to a physical threat. In a disaster of any type, personnel safety is the first concern.
The organization is responsible for protecting the privacy of each individual’s information, especially as it relates to personnel and medical records. Although this expectation of privacy does not necessarily and usually does not extend to their activities on the network, both federal and state laws hold organizations responsible for the release of this type of information with violations resulting in heavy fines and potential lawsuits that result if the company is found liable.
Organizations should develop policies for dealing with employee duress, travel, and monitoring.
Duress
Employee duress occurs when an employee is coerced to commit an action by another party. This is a particular concern for high-level management or employees with high security clearances because they have access to extra assets. Organizations should train employees on what to do when under duress. For any security codes, PINs, or passwords that are used, it is a good policy to implement a secondary duress code. Then, if personnel are under duress, they use the duress code to access the systems, facilities, or other assets. Security personnel are alerted that the duress code has been used. Organizations should stress to personnel that the protection of life should trump any other considerations.
Travel
Employees often travel for business purposes and take their organization-issued assets while traveling. Employees must be given the proper training to ensure that they keep organization-issued assets safe during the travel period and to be particularly careful when in public. They should also receive instructions on properly reporting lost or stolen assets.
Monitoring
Employee actions on organizational assets may need to be monitored, particularly for personnel with high clearance levels. However, it is important that personnel understand that they are being monitored. Organizations that will monitor employees should issue a no expectation of privacy statement. Employees should be given a copy of this statement when hired and should sign a receipt for the statement. In addition, periodic reminders of this policy should be placed in prominent locations, including on bulletin boards, login screens, and websites.
For any monitoring to be effective, organizations should capture baseline behavior for users.
Exam Preparation Tasks
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 7-2 lists a reference of these key topics and the page numbers on which each is found.

Table 7-2 Key Topics for Chapter 7
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
closed circuit television (CCTV) system
data loss prevention (DLP) software
electronic discovery (eDiscovery)
hierarchical storage management (HSM) system
network-attached storage (NAS)
RAID 2
Answer Review Questions
1. What is the first step of the incident response process?
a. Respond to the incident.
b. Detect the incident.
c. Report the incident.
d. Recover from the incident.
2. What is the second step of the forensic investigations process?
a. identification
b. collection
c. preservation
d. examination
3. Which of the following is NOT one of the five rules of evidence?
a. Be accurate.
b. Be complete.
c. Be admissible.
d. Be volatile.
4. Which of the following refers to allowing users access only to the resources required to do their jobs?
a. job rotation
b. separation of duties
c. need to know/least privilege
d. mandatory vacation
5. Which of the following is an example of an intangible asset?
a. disc drive
b. recipe
c. people
d. server
6. Which of the following is not a step in incident response management?
a. detect
b. respond
c. monitor
d. report
7. Which of the following is NOT a backup type?
a. full
b. incremental
c. grandfather/father/son
d. transaction log
8. Which term is used for a leased facility that contains all the resources needed for full operation?
a. cold site
b. hot site
c. warm site
d. tertiary site
9. Which electronic backup type stores data on optical discs and uses robotics to load and unload the optical disks as needed?
a. optical jukebox
b. hierarchical storage management
c. tape vaulting
d. replication
10. What is failsoft?
a. the capacity of a system to switch over to a backup system if a failure in the primary system occurs
b. the capability of a system to terminate non-critical processes when a failure occurs
c. a software product that provides load-balancing services
d. high-capacity storage devices that are connected by a high-speed private network using storage-specific switches
11. What investigation type specifically refers to litigation or government investigations that deal with the exchange of information in electronic format as part of the discovery process?
a. data loss prevention (DLP)
b. regulatory
c. eDiscovery
d. operations
12. An organization’s firewall is monitoring the outbound flow of information from one network to another. What specific type of monitoring is this?
a. egress monitoring
b. continuous monitoring
c. CMaaS
d. resource provisioning
13. Which of the following are considered virtual assets? (Choose all that apply.)
a. software-defined networks
b. virtual storage-area networks
c. guest OSs deployed on VMs
d. virtual routers
14. Which of the following describes the ability of a system, device, or data center to recover quickly and continue operating after an equipment failure, power outage, or other disruption?
b. recovery time objective (RTO)
c. recovery point objective (RPO)
d. system resilience
15. Which of the following are the main factors that affect the selection of an alternate location during the development of a DRP? (Choose all that apply.)
a. geographic location
b. organizational needs
c. location’s cost
d. location’s restoration effort
Answers and Explanations
1. b. The steps of the incident response process are as follows:
1. Detect the incident.
2. Respond to the incident.
3. Report the incident to the appropriate personnel.
4. Recover from the incident.
5. Remediate all components affected by the incident to ensure that all traces of the incident have been removed.
6. Review the incident and document all findings.
2. c. The steps of the forensic investigation process are as follows:
1. Identification
2. Preservation
3. Collection
4. Examination
5. Analysis
6. Presentation
7. Decision
3. d. The five rules of evidence are as follows:
![]() Be authentic.
Be authentic.
![]() Be accurate.
Be accurate.
![]() Be complete.
Be complete.
![]() Be convincing.
Be convincing.
![]() Be admissible.
Be admissible.
4. c. When allowing access to resources and assigning rights to perform operations, the concept of least privilege (also called need to know) should always be applied. In the context of resource access, this means the default level of access should be no access. Give users access only to resources required to do their jobs, and that access should require manual implementation after the requirement is verified by a supervisor.
5. b. In many cases, some of the most valuable assets for a company are intangible ones, such as secret recipes, formulas, and trade secrets.
6. c. The steps in incident response management are:
1. Detect
2. Respond
3. Report
4. Recover
5. Remediate
6. Review
7. c. Grandfather/father/son is not a backup type; it is a backup rotation scheme.
8. b. A hot site is a leased facility that contains all the resources needed for full operation.
9. a. An optical jukebox stores data on optical discs and uses robotics to load and unload the optical discs as needed.
10. b. Failsoft is the capability of a system to terminate non-critical processes when a failure occurs.
11. c. Electronic discovery (eDiscovery) refers to litigation or government investigations that deal with the exchange of information in electronic format as part of the discovery process. It involves electronically stored information (ESI) and includes emails, documents, presentations, databases, voicemail, audio and video files, social media, and websites. Data loss prevention (DLP) software attempts to prevent data leakage. It does this by maintaining awareness of actions that can and cannot be taken with respect to a document. A regulatory investigation occurs when a regulatory body investigates an organization for a regulatory infraction. Operations investigations involve any investigations that do not result in any criminal, civil, or regulatory issue. In most cases, this type of investigation is completed to determine the root cause so that steps can be taken to prevent this incident in the future.
12. a. Egress monitoring occurs when an organization monitors the outbound flow of information from one network to another. The most popular form of egress monitoring is carried out using firewalls that monitor and control outbound traffic. Continuous monitoring and Continuous Monitoring as a Service (CMaaS) are not specific enough to answer this question. Any logging and monitoring activities should be part of an organizational continuous monitoring program. The continuous monitoring program must be designed to meet the needs of the organization and implemented correctly to ensure that the organization’s critical infrastructure is guarded. Organizations may want to look into CMaaS solutions deployed by cloud service providers. Resource provisioning is the process in security operations that ensures that the organization only deploys the assets that it currently needs.
13. a, b, c, d. Virtual assets include software-defined networks, virtual storage-area networks (VSANs), guest operating systems deployed on virtual machines (VMs), and virtual routers. As with physical assets, the deployment and decommissioning of virtual assets should be tightly controlled as part of configuration management because virtual assets, like physical assets, can be compromised.
14. d. System resilience is the ability of a system, device, or data center to recover quickly and continue operating after an equipment failure, power outage, or other disruption. It involves the use of redundant components or facilities. Quality of service (QoS) is a technology that manages network resources to ensure a predefined level of service. It assigns traffic priorities to the different types of traffic on a network. A recovery time objective (RTO) stipulates the amount of time an organization needs to recover from a disaster, and a recovery point objective (RPO) stipulates the amount of data an organization can lose when a disaster occurs.
15. a, b, c, d. The main factors that affect the selection of an alternate location during the development of a disaster recovery plan (DRP) include the following:
![]() Geographic location
Geographic location
![]() Organizational needs
Organizational needs
![]() Location’s cost
Location’s cost