
In the previous chapter, you got an overview of the Azure cloud and learned about some of the important concepts related to it. This chapter is about Azure cloud patterns that are related to virtual networks, storage accounts, regions, Availability Zones, and Availability Sets. These are important constructs that affect the final architecture delivered to customers in terms of cost, efficiencies, and overall productivity. The chapter also briefly discusses the cloud patterns that help us to implement scalability and performance for an architecture.
In this chapter, we'll cover the following topics:
- Azure Virtual Network design
- Azure Storage design
- Azure Availability Zones, regions, and Availability Sets
- Azure design patterns related to messaging, performance, and scalability
Azure Availability Zones and Regions
Azure is backed up by large datacenters interconnected into a single large network. The datacenters are grouped together, based on their physical proximity, into Azure regions. For example, datacenters in Western Europe are available to Azure users in the West Europe region. Users cannot choose their preferred datacenter. They can select their Azure region and Azure will allocate an appropriate datacenter.
Choosing an appropriate region is an important architectural decision as it affects:
- The availability of resources
- Data and privacy compliance
- The performance of the application
- The cost of running applications
Let's discuss each of these points in detail.
Availability of resources
Not all resources are available in every Azure region. If your application architecture demands a resource that is not available in a region, choosing that region will not help. Instead, a region should be chosen based on the availability of the resources required by the application. It might be that the resource is not available while developing the application architecture, and it could be on Azure's roadmap to make it available subsequently.
For example, Log Analytics is not available in all regions. If your data sources are in Region A and the Log Analytics workspace is in Region B, you need to pay for the bandwidth, which is the data egress charges from Region A to B. Similarly, some services can work with resources that are located in the same region. For instance, if you would like to encrypt the disks of your virtual machine that is deployed in Region A, you need to have Azure Key Vault deployed in Region A to store the encryption keys. Before deploying any services, you need to check whether your dependency services are available in that region. A good source to check the availability of Azure products across regions is this product page: https://azure.microsoft.com/global-infrastructure/services.
Data and privacy compliance
Each country has its own rules for data and privacy compliance. Some countries are very specific about storing their citizens' data in their own territories. Hence, such legal requirements should be taken into consideration for every application's architecture.
Application performance
The performance of an application is dependent on the network route taken by requests and responses to get to their destinations and back again. The location that is geographically closer to you may not always be the region with the lowest latency. We calculate distance in kilometers or miles, but latency is based on the route the packet takes. For example, an application deployed in Western Europe for Southeast Asian users will not perform as well as an application deployed to the East Asia region for users in that region. So, it's very important that you architect your solutions in the closest region to provide the lowest latency and thus the best performance.
Cost of running applications
The cost of Azure services differs from region to region. A region with an overall lower cost should be chosen. There is a complete chapter on cost management in this book (Chapter 6, Cost management for Azure solutions), and it should be referred to for more details on cost.
So far, we have discussed how to choose the right region to architect our solution. Now that we have a suitable region in mind for our solution, let's discuss how to design our virtual networks in Azure.
Virtual networks
Virtual networks should be thought of like a physical office or home LAN network setup. Conceptually, they are the same, although Azure Virtual Network (VNet) is implemented as a software-defined network backed up by a giant physical network infrastructure.
A VNet is required to host a virtual machine. It provides a secure communication mechanism between Azure resources so that they can connect to each other. The VNets provide internal IP addresses to the resources, facilitate access and connectivity to other resources (including virtual machines on the same virtual network), route requests, and provide connectivity to other networks.
A virtual network is contained within a resource group and is hosted within a region, for example, West Europe. It cannot span multiple regions but can span all datacenters within a region, which means we can span virtual networks across multiple Availability Zones in a region. For connectivity across regions, virtual networks can be connected using VNet-to-VNet connectivity.
Virtual networks also provide connectivity to on-premises datacenters, enabling hybrid clouds. There are multiple types of VPN technologies that you can use to extend your on-premises datacenters to the cloud, such as site-to-site VPN and point-to-site VPN. There is also dedicated connectivity between Azure VNet and on-premises networks through the use of ExpressRoute.
Virtual networks are free of charge. Every subscription can create up to 50 virtual networks across all regions. However, this number can be increased by reaching out to Azure Support. You will not be charged if data does not leave the region of deployment. At the time of writing, inbound and outbound data transfers within Availability Zones from the same region don't incur charges; however, billing will commence from July 1, 2020.
Information about networking limits is available in the Microsoft documentation at https://docs.microsoft.com/azure/azure-resource-manager/management/azure-subscription-service-limits.
Architectural considerations for virtual networks
Virtual networks, like any other resource, can be provisioned using ARM templates, REST APIs, PowerShell, and the CLI. It is quite important to plan the network topology as early as possible to avoid troubles later in the development life cycle. This is because once a network is provisioned and resources start using it, it is difficult to change it without having downtime. For example, moving a virtual machine from one network to another will require the virtual machine to be shut down.
Let's look at some of the key architectural considerations while designing a virtual network.
Regions
VNet is an Azure resource and is provisioned within a region, such as West Europe. Applications spanning multiple regions will need separate virtual networks, one per region, and they also need to be connected using VNet-to-VNet connectivity. There is a cost associated with VNet-to-VNet connectivity for both inbound and outbound traffic. There are no charges for inbound (ingress) data, but there are charges associated with outbound data.
Dedicated DNS
VNet by default uses Azure's DNS to resolve names within a virtual network, and it also allows name resolution on the internet. If an application wants a dedicated name resolution service or wants to connect to on-premises datacenters, it should provision its own DNS server, which should be configured within the virtual network for successful name resolution. Also, you can host your public domain in Azure and completely manage the records from the Azure portal, without the need to manage additional DNS servers.
Number of virtual networks
The number of virtual networks is affected by the number of regions, bandwidth usage by services, cross-region connectivity, and security. Having fewer but larger VNets instead of multiple smaller VNets will eliminate the management overhead.
Number of subnets in each virtual network
Subnets provide isolation within a virtual network. They can also provide a security boundary. Network security groups (NSGs) can be associated with subnets, thereby restricting or allowing specific access to IP addresses and ports. Application components with separate security and accessibility requirements should be placed within separate subnets.
IP ranges for networks and subnets
Each subnet has an IP range. The IP range should not be so large that IPs are underutilized, but conversely shouldn't be so small that subnets become suffocated because of a lack of IP addresses. This should be considered after understanding the future IP address needs of the deployment.
Planning should be done for IP addresses and ranges for Azure networks, subnets, and on-premises datacenters. There should not be an overlap to ensure seamless connectivity and accessibility.
Monitoring
Monitoring is an important architectural facet and must be included within the overall deployment. Azure Network Watcher provides logging and diagnostic capabilities with insights on network performance and health. Some of the capabilities of the Azure Network Watcher are:
- Diagnosing network traffic filtering problems to or from a virtual machine
- Understanding the next hop of user-defined routes
- Viewing the resources in a virtual network and their relationships
- Communication monitoring between a virtual machine and an endpoint
- Traffic capture from a virtual machine
- NSG flow logs, which log information related to traffic flowing through an NSG. This data will be stored in Azure Storage for further analysis
It also provides diagnostic logs for all the network resources in a resource group.
Network performance can be monitored through Log Analytics. The Network Performance Monitor management solution provides network monitoring capability. It monitors the health, availability, and reachability of networks. It is also used to monitor connectivity between public cloud and on-premises subnets hosting various tiers of a multi-tiered application.
Security considerations
Virtual networks are among the first components that are accessed by any resource on Azure. Security plays an important role in allowing or denying access to a resource. NSGs are the primary means of enabling security for virtual networks. They can be attached to virtual network subnets, and every inbound and outbound flow is constrained, filtered, and allowed by them.
User-defined routing (UDR) and IP forwarding also helps in filtering and routing requests to resources on Azure. You can read more about UDR and forced tunneling at https://docs.microsoft.com/azure/virtual-network/virtual-networks-udr-overview.
Azure Firewall is a fully managed Firewall as a Service offering from Azure. It can help you protect the resources in your virtual network. Azure Firewall can be used for packet filtering in both inbound and outbound traffic, among other things. Additionally, the threat intelligence feature of Azure Firewall can be used to alert and deny traffic from or to malicious domains or IP addresses. The data source for IP addresses and domains is Microsoft's threat intelligence feed.
Resources can also be secured and protected by deploying network appliances (https://azure.microsoft.com/solutions/network-appliances) such as Barracuda, F5, and other third-party components.
Deployment
Virtual networks should be deployed in their own dedicated resource groups. Network administrators should have the owner's permission to use this resource group, while developers or team members should have contributor permissions to allow them to create other Azure resources in other resource groups that consume services from the virtual network.
It is also a good practice to deploy resources with static IP addresses in a dedicated subnet, while dynamic IP address–related resources can be on another subnet.
Policies should not only be created so that only network administrators can delete the virtual network, but also should also be tagged for billing purposes.
Connectivity
Resources in a region on a virtual network can talk seamlessly. Even resources on other subnets within a virtual network can talk to each other without any explicit configuration. Resources in multiple regions cannot use the same virtual network. The boundary of a virtual network is within a region. To make a resource communicate across regions, we need dedicated gateways at both ends to facilitate conversation.
Having said that, if you would like to initiate a private connection between two networks in different regions, you can use Global VNet peering. With Global VNet peering, the communication is done via Microsoft's backbone network, which means no public internet, gateway, or encryption is required during the communication. If your virtual networks are in the same region with different address spaces, resources in one network will not be able to communicate with the other. Since they are in the same region, we can use virtual network peering, which is similar to Global VNet peering; the only difference is that the source and destination virtual networks are deployed in the same region.
As many organizations have a hybrid cloud, Azure resources sometimes need to communicate or connect with on-premises datacenters or vice versa. Azure virtual networks can connect to on-premises datacenters using VPN technology and ExpressRoute. In fact, one virtual network is capable of connecting to multiple on-premises datacenters and other Azure regions in parallel. As a best practice, each of these connections should be in their dedicated subnets within a virtual network.
Now that we have explored several aspects of virtual networking, let's go ahead and discuss the benefits of virtual networks.
Benefits of virtual networks
Virtual networks are a must for deploying any meaningful IaaS solution. Virtual machines cannot be provisioned without virtual networks. Apart from being almost a mandatory component in IaaS solutions, they provide great architectural benefits, some of which are outlined here:
- Isolation: Most application components have separate security and bandwidth requirements and have different life cycle management. Virtual networks help to create isolated pockets for these components that can be managed independently of other components with the help of virtual networks and subnets.
- Security: Filtering and tracking the users that are accessing resources is an important feature provided by virtual networks. They can stop access to malicious IP addresses and ports.
- Extensibility: Virtual networks act like a private LAN on the cloud. They can also be extended into a Wide Area Network (WAN) by connecting other virtual networks across the globe and can be extensions to on-premises datacenters.
We have explored the benefits of virtual networks. Now the question is how we can leverage these benefits and design a virtual network to host our solution. In the next section, we will look at the design of virtual networks.
Virtual network design
In this section, we will consider some of the popular designs and use case scenarios of virtual networks.
There can be multiple usages of virtual networks. A gateway can be deployed at each virtual network endpoint to enable security and transmit packets with integrity and confidentiality. A gateway is a must when connecting to on-premises networks; however, it is optional when using Azure VNet peering. Additionally, you can make use of the Gateway Transit feature to simplify the process of extending your on-premises datacenter without deploying multiple gateways. Gateway Transit allows you to share an ExpressRoute or VPN gateway with all peered virtual networks. This will make it easy to manage and reduce the cost of deploying multiple gateways.
In the previous section, we touched on peering and mentioned that we don't use gateways or the public internet to establish communication between peered networks. Let's move on and explore some of the design aspects of peering, and which peering needs to be used in particular scenarios.
Connecting to resources within the same region and subscription
Multiple virtual networks within the same region and subscription can be connected to each other. With the help of VNet peering, both networks can be connected and use the Azure private network backbone to transmit packets to each other. Virtual machines and services on these networks can talk to each other, subject to network traffic constraints. In the following diagram, VNet1 and VNet2 both are deployed in the West US region. However, the address space for VNet1 is 172.16.0.0/16, and for VNet2 it is 10.0.0.0/16. By default, resources in VNet1 will not be able to communicate with resources in VNet2. Since we have established VNet peering between the two, the resources will be able to communicate with each other via the Microsoft backbone network:
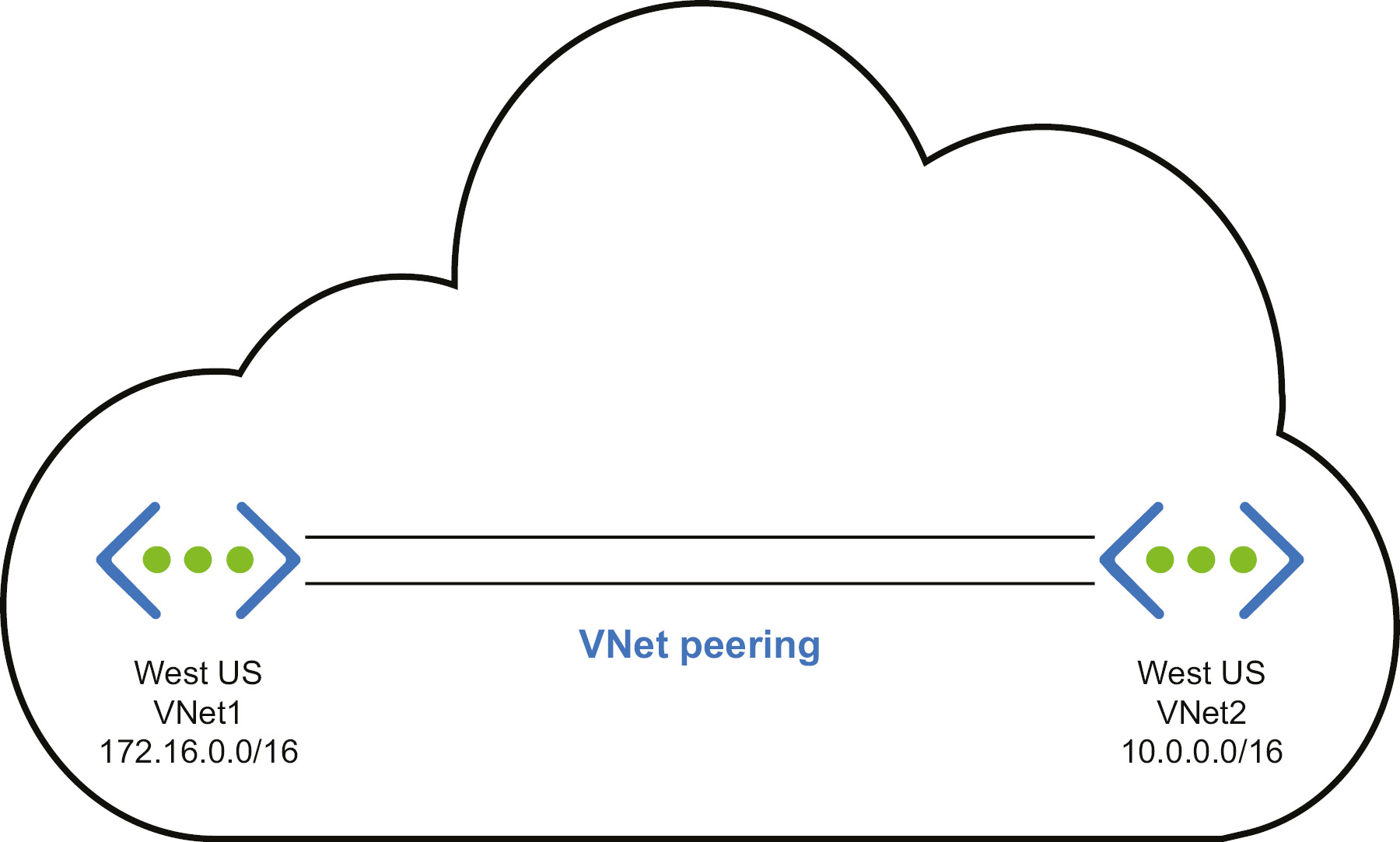
Figure 3.1: VNet peering for resources with the same subscription
Connecting to resources within the same region in another subscription
This scenario is very similar to the previous one except that the virtual networks are hosted in two different subscriptions. The subscriptions can be part of the same tenant or from multiple tenants. If both the resources are part of the same subscription and from the same region, the previous scenario applies. This scenario can be implemented in two ways: by using gateways or by using virtual network peering.
If we are using gateways in this scenario, we need to deploy a gateway at both ends to facilitate communication. Here is the architectural representation of using gateways to connect two resources with different subscriptions:
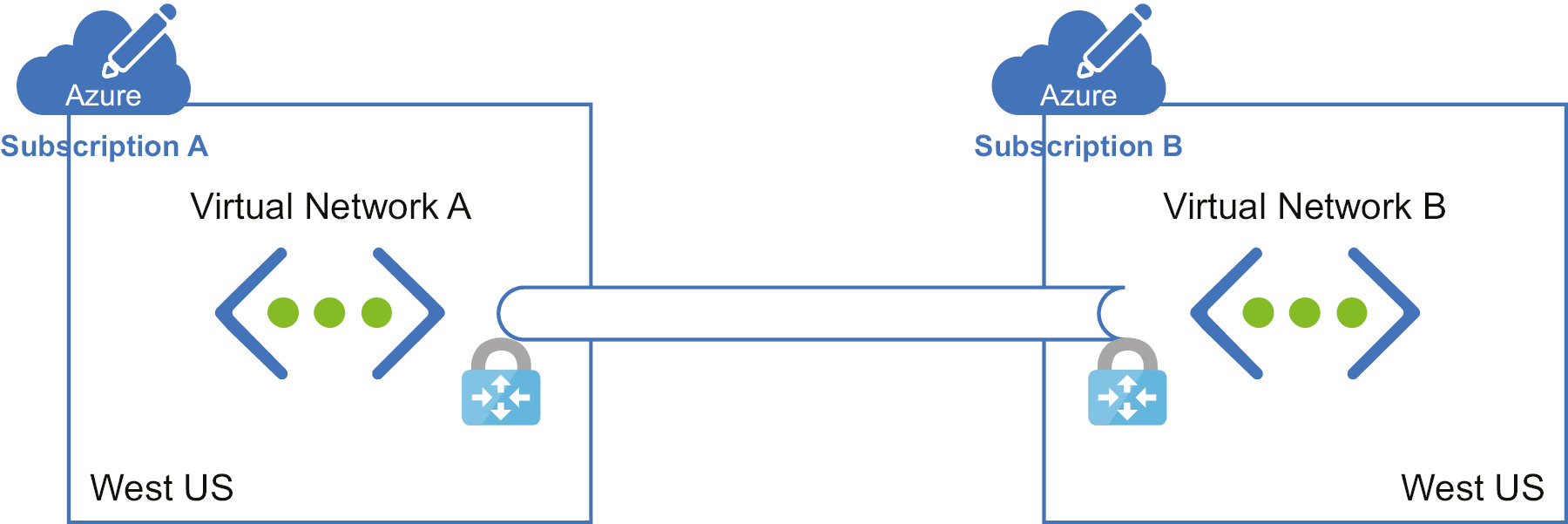
Figure 3.2: VNet peering for resources with different subscriptions using gateways
However, the deployment of gateways incurs some charges. We will discuss VNet peering, and after that we will compare these two implementations to see which is best for our solution.
While using peering, we are not deploying any gateways. Figure 3.3 represents how peering is done:
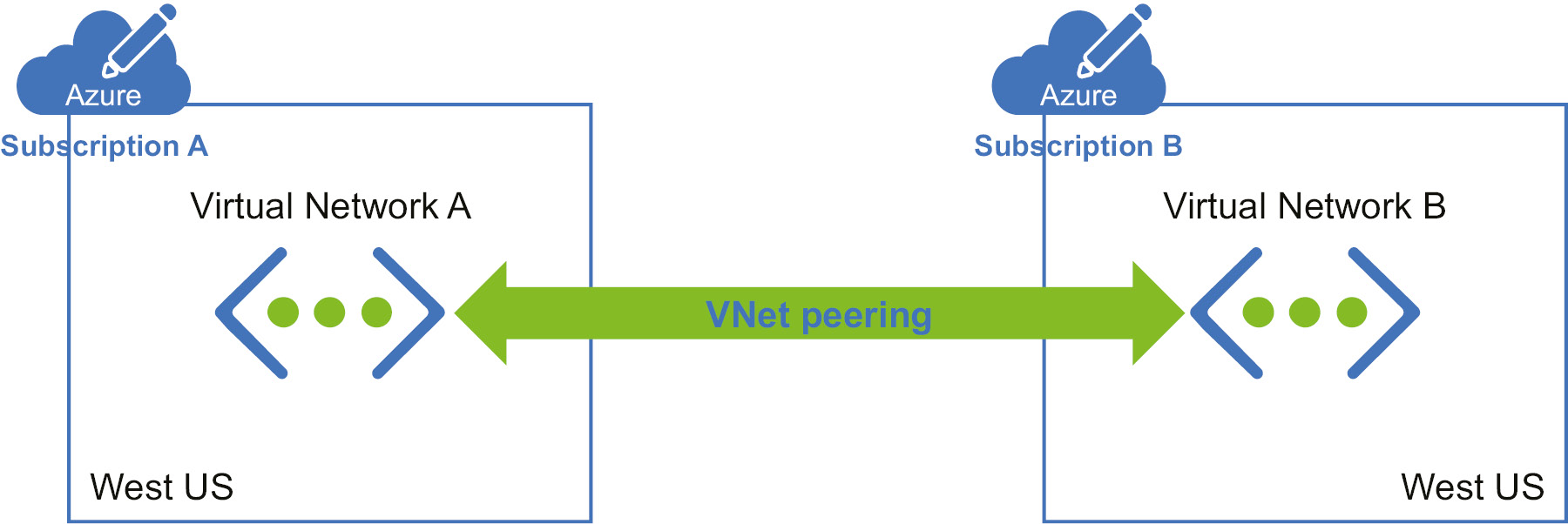
Figure 3.3: VNet peering across subscriptions
VNet peering provides a low-latency, high-bandwidth connection, and, as shown in the diagram, we are not deploying any gateways to make the communication happen. This is useful for scenarios such as data replication or failover. As mentioned earlier, peering uses the Microsoft backbone network, which eliminates the need for the public internet.
Gateways are used in scenarios where encryption is needed and bandwidth is not a concern, as this will be a limited-bandwidth connection. However, this doesn't mean that there is a constraint on bandwidth. Also, this approach is used where customers are not so latency-sensitive.
So far, we have looked at resources in the same region across subscriptions. In the next section, we will explore how to establish a connection between virtual networks in two different regions.
Connecting to resources in different regions in another subscription
In this scenario, we have two implementations again. One uses a gateway and the other uses Global VNet peering.
Traffic will pass through the public network, and we will have gateways deployed at both ends to facilitate an encrypted connection. Figure 3.4 explains how it's done:

Figure 3.4: Connecting resources in different regions with different subscriptions
We will take a similar approach using Global VNet peering. Figure 3.5 shows how Global VNet peering is done:

Figure 3.5: Connecting resources in different regions using Global VNet peering
The considerations in choosing gateways or peering have already been discussed. These considerations are applicable in this scenario as well. So far, we have been connecting virtual networks across regions and subscriptions; we haven't talked about connecting an on-premises datacenter to the cloud yet. In the next section, we will discuss ways to do this.
Connecting to on-premises datacenters
Virtual networks can be connected to on-premises datacenters so that both Azure and on-premises datacenters become a single WAN. An on-premises network needs to be deployed on gateways and VPNs on both sides of the network. There are three different technologies available for this purpose.
Site-to-site VPN
This should be used when both the Azure network and the on-premises datacenter are connected to form a WAN, where any resource on both networks can access any other resource on the networks irrespective of whether they are deployed on Azure or an on-premises datacenter. VPN gateways are required to be available on both sides of networks for security reasons. Also, Azure gateways should be deployed on their own subnets on virtual networks connected to on-premises datacenters. Public IP addresses must be assigned to on-premises gateways for Azure to connect to them over the public network:
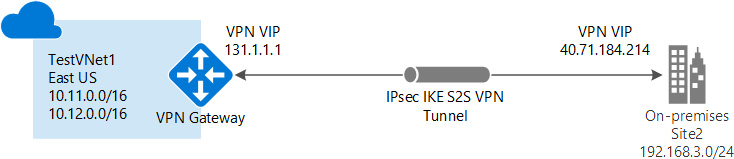
Figure 3.6: Site-to-site VPN architecture
Point-to-site VPN
This is similar to site-to-site VPN connectivity, but there is a single server or computer attached to the on-premises datacenter. It should be used when there are very few users or clients that would connect to Azure securely from remote locations. Also, there is no need for public IPs and gateways on the on-premises side in this case:
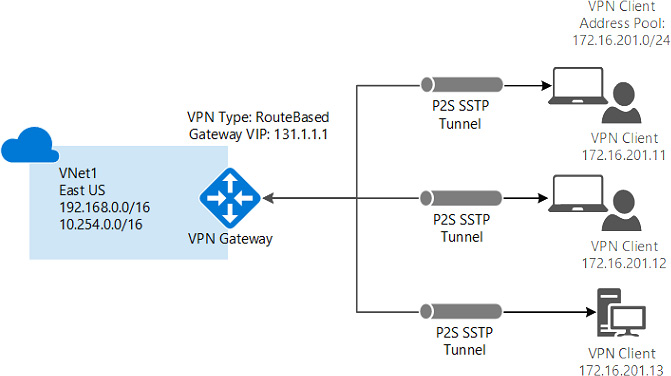
Figure 3.7: Point-to-site VPN architecture
ExpressRoute
Both site-to-site and point-to-site VPNs work using the public internet. They encrypt the traffic on the networks using VPN and certificates technology. However, there are applications that want to be deployed using hybrid technologies—some components on Azure, with others on an on-premises datacenter—and at the same time do not want to use the public internet to connect to Azure and on-premises datacenters. Azure ExpressRoute is the best solution for them, although it's a costly option compared to the two other types of connection. It is also the most secure and reliable provider, with higher speed and reduced latency because the traffic never hits the public internet. Azure ExpressRoute can help to extend on-premises networks into Azure over a dedicated private connection facilitated by a connectivity provider. If your solution is network intensive, for example, a transactional enterprise application such as SAP, use of ExpressRoute is highly recommended.
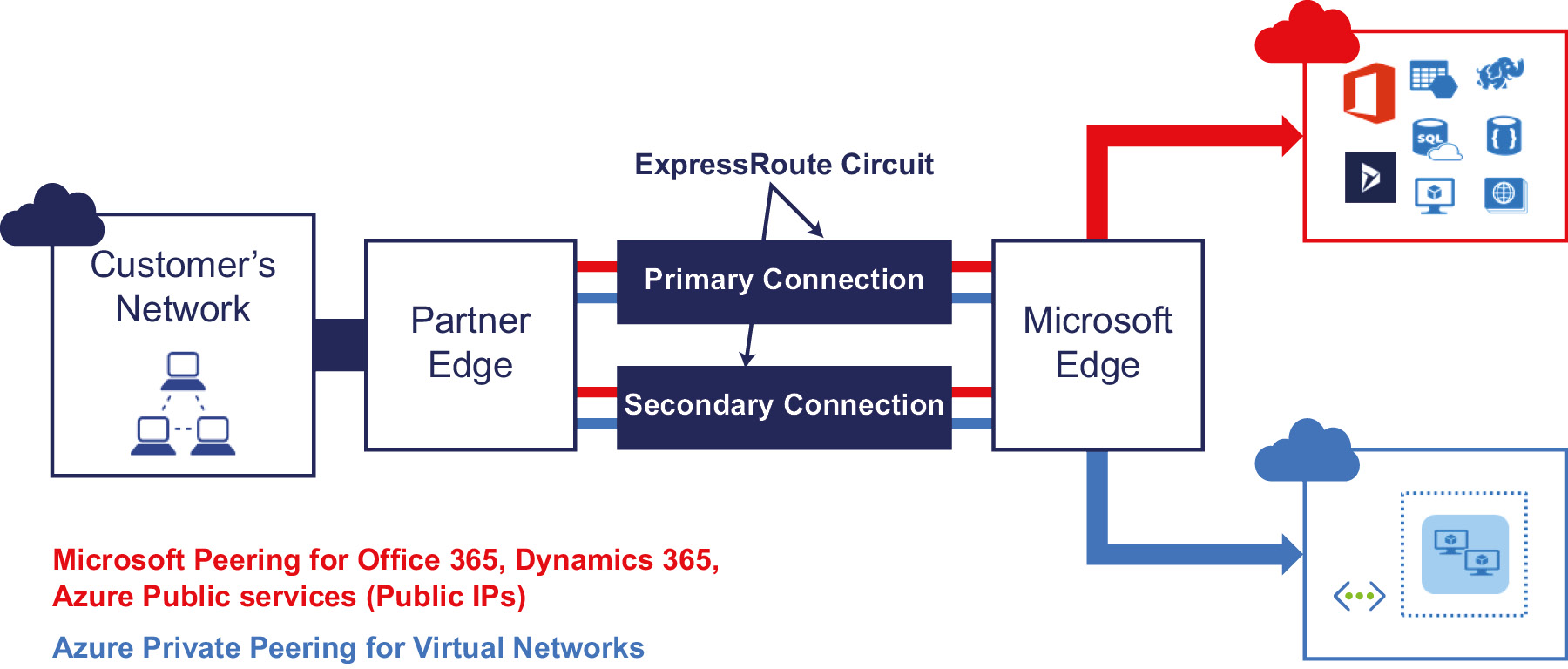
Figure 3.8: ExpressRoute network architecture
Figure 3.9 shows all three types of hybrid networks:
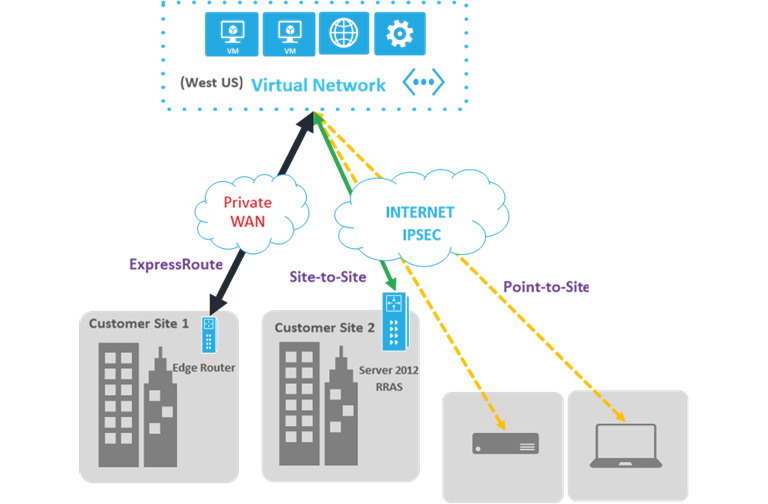
Figure 3.9: Different types of hybrid networks
It is a good practice for virtual networks to have separate subnets for each logical component with separate deployments, from a security and isolation perspective.
All the resources we deploy in Azure require networking in one way or another, so a deep understanding of networking is required when architecting solutions in Azure. Another key element is storage. In the next section, you will be learning more about storage.
Storage
Azure provides a durable, highly available, and scalable storage solution through storage services.
Storage is used to persist data for long-term needs. Azure Storage is available on the internet for almost every programming language.
Storage categories
Storage has two categories of storage accounts:
- A standard storage performance tier that allows you to store tables, queues, files, blobs, and Azure virtual machine disks.
- A premium storage performance tier supporting Azure virtual machine disks, at the time of writing. Premium storage provides higher performance and IOPS than standard general storage. Premium storage is currently available as data disks for virtual machines backed up by SSDs.
Depending on the kind of data that is being stored, the storage is classified into different types. Let's look at the storage types and learn more about them.
Storage types
Azure provides four types of general storage services:
- Azure Blob storage: This type of storage is most suitable for unstructured data, such as documents, images, and other kinds of files. Blob storage can be in the Hot, Cool, or Archive tier. The Hot tier is meant for storing data that needs to be accessed very frequently. The Cool tier is for data that is less frequently accessed than data in the Hot tier and is stored for 30 days. Finally, the Archive tier is for archival purposes where the access frequency is very low.
- Azure Table storage: This is a NoSQL key-attribute data store. It should be used for structured data. The data is stored as entities.
- Azure Queue storage: This provides reliable message storage for storing large numbers of messages. These messages can be accessed from anywhere via HTTP or HTTPS calls. A queue message can be up to 64 KB in size.
- Azure Files: This is shared storage based on the SMB protocol. It is typically used for storing and sharing files. It also stores unstructured data, but its main distinction is that it is sharable via the SMB protocol.
- Azure disks: This is block-level storage for Azure Virtual Machines.
These five storage types cater to different architectural requirements and cover almost all types of data storage facilities.
Storage features
Azure Storage is elastic. This means that you can store as little as a few megabytes or as much as petabytes of data. You do not need to pre-block the capacity, and it will grow and shrink automatically. Consumers just need to pay for the actual usage of storage. Here are some of the key benefits of using Azure Storage:
- Azure Storage is secure. It can only be accessed using the SSL protocol. Moreover, access should be authenticated.
- Azure Storage provides the facility to generate an account-level Secure Access Signature (SAS) token that can be used by storage clients to authenticate themselves. It is also possible to generate individual service-level SAS tokens for blobs, queues, tables, and files.
- Data stored in Azure storage can be encrypted. This is known as secure data at rest.
- Azure Disk Encryption is used to encrypt the OS and data disks in IaaS virtual machines. Client-Side Encryption (CSE) and Storage Service Encryption (SSE) are both used to encrypt data in Azure Storage. SSE is an Azure Storage setting that ensures that data is encrypted while data is being written to storage and decrypted while it is read by the storage engine. This ensures that no application changes are required to enable SSE. In CSE, client applications can use the Storage SDK to encrypt data before it is sent and written to Azure Storage. The client application can later decrypt this data while it is read. This provides security for both data in transit and data at rest. CSE is dependent on secrets from Azure Key Vault.
- Azure Storage is highly available and durable. What this means is that Azure always maintains multiple copies of Azure accounts. The location and number of copies depend on the replication configuration.
Azure provides the following replication settings and data redundancy options:
- Locally redundant storage (LRS): Within a single physical location in the primary region, there will be three replicas of your data synchronously. From a billing standpoint, this is the cheapest option; however, it's not recommended for solutions that require high availability. LRS provides a durability level of 99.999999999% for objects over a given year.
- Zone-redundant storage (ZRS): In the case of LRS, the replicas were stored in the same physical location. In the case of ZRS, the data will be replicated synchronously across the Availability Zones in the primary region. As each of these Availability Zones is a separate physical location in the primary region, ZRS provides better durability and higher availability than LRS.
- Geo-redundant storage (GRS): GRS increases the high availability by synchronously replicating three copies of data within a single primary region using LRS. It also copies the data to a single physical location in the secondary region.
- Geo-zone-redundant storage (GZRS): This is very similar to GRS, but instead of replicating data within a single physical location in the primary region, GZRS replicates it synchronously across three Availability Zones. As we discussed in the case of ZRS, since the Availability Zones are isolated physical locations within the primary region, GZRS has better durability and can be included in highly available designs.
- Read-access geo-redundant storage (RA-GRS) and read-access geo-zone-redundant storage: The data replicated to the secondary region by GZRS or GRS is not available for read or write. This data will be used by the secondary region in the case of the failover of the primary datacenter. RA-GRS and RA-GZRS follow the same replication pattern as GRS and GZRS respectively; the only difference is that the data replicated to the secondary region via RA-GRS or RA-GZRS can be read.
Now that we have understood the various storage and connection options available on Azure, let's learn about the underlying architecture of the technology.
Architectural considerations for storage accounts
Storage accounts should be provisioned within the same region as other application components. This would mean using the same datacenter network backbone without incurring any network charges.
Azure Storage services have scalability targets for capacity, transaction rate, and bandwidth associated with each of them. A general storage account allows 500 TB of data to be stored. If there is a need to store more than 500 TB of data, then either multiple storage accounts should be created, or premium storage should be used.
General storage performs at a maximum of 20,000 IOPS or 60 MB of data per second. Any requirements for higher IOPS or data managed per second will be throttled. If this is not enough for your applications from a performance perspective, either premium storage or multiple storage accounts should be used. For an account, the scalability limit for accessing tables is up to 20,000 (1 KB each) entries. The count of entities being inserted, updated, deleted, or scanned will contribute toward the target. A single queue can process approximately 2,000 messages (1 KB each) per second, and each of the AddMessage, GetMessage, and DeleteMessage counts will be treated as a message. If these values aren't sufficient for your application, you should spread the messages across multiple queues.
The size of virtual machines determines the size and capacity of the available data disks. While larger virtual machines have data disks with higher IOPS capacity, the maximum capacity will still be limited to 20,000 IOPS and 60 MB per second. It is to be noted that these are maximum numbers and so generally lower levels should be taken into consideration when finalizing storage architecture.
At the time of writing, GRS accounts offer a 10 Gbps bandwidth target in the US for ingress and 20 Gbps if RA-GRS/GRS is enabled. When it comes to LRS accounts, the limits are on the higher side compared to GRS. For LRS accounts, ingress is 20 Gbps and egress is 30 Gbps. Outside the US, the values are lower: the bandwidth target is 10 Gbps and 5 Gbps for egress. If there is a requirement for a higher bandwidth, you can reach out to Azure Support and they will be able to help you with further options.
Storage accounts should be enabled for authentication using SAS tokens. They should not allow anonymous access. Moreover, for blob storage, different containers should be created with separate SAS tokens generated based on the different types and categories of clients accessing those containers. These SAS tokens should be periodically regenerated to ensure that the keys are not at risk of being cracked or guessed. You will learn more about SAS tokens and other security options in Chapter 8, Architecting secure applications on Azure.
Generally, blobs fetched for blob storage accounts should be cached. We can determine whether the cache is stale by comparing its last modified property to re-fetch the latest blob.
Storage accounts provide concurrency features to ensure that the same file and data is not modified simultaneously by multiple users. They offer the following:
- Optimistic concurrency: This allows multiple users to modify data simultaneously, but while writing, it checks whether the file or data has changed. If it has, it tells the users to re-fetch the data and perform the update again. This is the default concurrency for tables.
- Pessimistic concurrency: When an application tries to update a file, it places a lock, which explicitly denies any updates to it by other users. This is the default concurrency for files when accessed using the SMB protocol.
- Last writer wins: The updates are not constrained, and the last user updates the file irrespective of what was read initially. This is the default concurrency for queues, blobs, and files (when accessed using REST).
By this point, you should know what the different storage services are and how they can be leveraged in your solutions. In the next section, we will look at design patterns and see how they relate to architectural designs.
Cloud design patterns
Design patterns are proven solutions to known design problems. They are reusable solutions that can be applied to problems. They are not reusable code or designs that can be incorporated as is within a solution. They are documented descriptions and guidance for solving a problem. A problem might manifest itself in different contexts, and design patterns can help to solve it. Azure provides numerous services, with each service providing specific features and capabilities. Using these services is straightforward, but creating solutions by weaving multiple services together can be a challenge. Moreover, achieving high availability, super scalability, reliability, performance, and security for a solution is not a trivial task.
Azure design patterns provide ready solutions that can be tailored to individual problems. They help us to make highly available, scalable, reliable, secure, and performance-centric solutions on Azure. Although there are many patterns and some of the patterns are covered in detail in subsequent chapters, some of the messaging, performance, and scalability patterns are mentioned in this chapter. Also, links are provided for detailed descriptions of these patterns. These design patterns deserve a complete book by themselves. They have been mentioned here to make you aware of their existence and to provide references for further information.
Messaging patterns
Messaging patterns help connect services in a loosely coupled manner. What this means is that services never talk to each other directly. Instead, a service generates and sends a message to a broker (generally a queue) and any other service that is interested in that message can pick it and process it. There is no direct communication between the sender and receiver service. This decoupling not only makes services and the overall application more reliable but also more robust and fault tolerant. Receivers can receive and read messages at their own speed.
Messaging helps the creation of asynchronous patterns. Messaging involves sending messages from one entity to another. These messages are created and forwarded by a sender, stored in durable storage, and finally consumed by recipients.
The top architectural concerns addressed by messaging patterns are as follows:
- Durability: Messages are stored in durable storage, and applications can read them after they are received in case of a failover.
- Reliability: Messages help implement reliability as they are persisted on disk and never lost.
- Availability of messages: The messages are available for consumption by applications after the restoration of connectivity and before downtime.
Azure provides Service Bus queues and topics to implement messaging patterns within applications. Azure Queue storage can also be used for the same purpose.
Choosing between Azure Service Bus queues and Queue storage is about deciding on how long the message should be stored, the size of the message, latency, and cost. Azure Service Bus provides support for 256 KB messages, while Queue storage provides support for 64 KB messages. Azure Service Bus can store messages for an unlimited period, while Queue storage can store messages for 7 days. The cost and latency are higher with Service Bus queues.
Depending on your application's requirements and needs, the preceding factors should be considered before deciding on the best queue. In the next section, we will be discussing different types of messaging patterns.
The Competing Consumers pattern
A single consumer of messages works in a synchronous manner unless the application implements the logic of reading messages asynchronously. The Competing Consumers pattern implements a solution in which multiple consumers are ready to process incoming messages, and they compete to process each message. This can lead to solutions that are highly available and scalable. This pattern is scalable because with multiple consumers, it is possible to process a higher number of messages in a smaller period. It is highly available because there should be at least one consumer to process messages even if some of the consumers crash.
This pattern should be used when each message is independent of other messages. The messages by themselves contain all the information required for a consumer to complete a task. This pattern should not be used if there is any dependency among messages. The consumers should be able to complete the tasks in isolation. Also, this pattern is applicable if there is variable demand for services. Additional consumers can be added or removed based on demand.
A message queue is required to implement the Competing Consumers pattern. Here, patterns from multiple sources pass through a single queue, which is connected to multiple consumers at the other end. These consumers should delete each message after reading so that they are not re-processed:
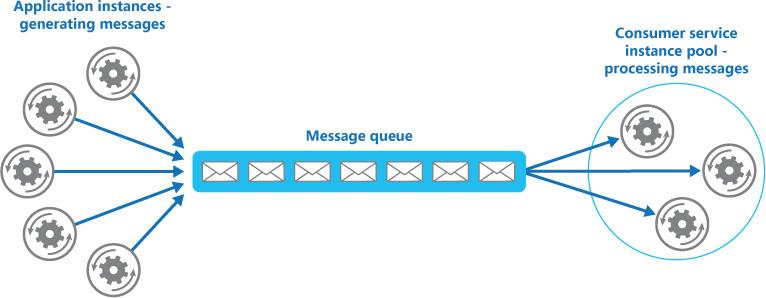
Figure 3.10: The Competing Consumers pattern
Refer to the Microsoft documentation at https://docs.microsoft.com/azure/architecture/patterns/competing-consumers to learn more about this pattern.
The Priority Queue pattern
There is often a need to prioritize some messages over others. This pattern is important for applications that provide different service-level agreements (SLAs) to consumers, which provide services based on differential plans and subscriptions.
Queues follow the first-in, first-out pattern. Messages are processed in a sequence. However, with the help of the Priority Queue pattern, it is possible to fast-track the processing of certain messages due to their higher priority. There are multiple ways to implement this. If the queue allows you to assign priority and re-order messages based on priority, then even a single queue is enough to implement this pattern:
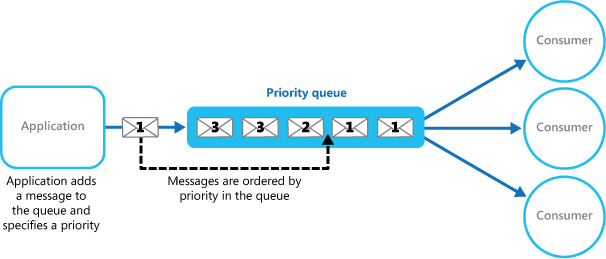
Figure 3.11: The single Priority Queue pattern
However, if the queue cannot re-order messages, then separate queues can be created for different priorities, and each queue can have separate consumers associated with it:
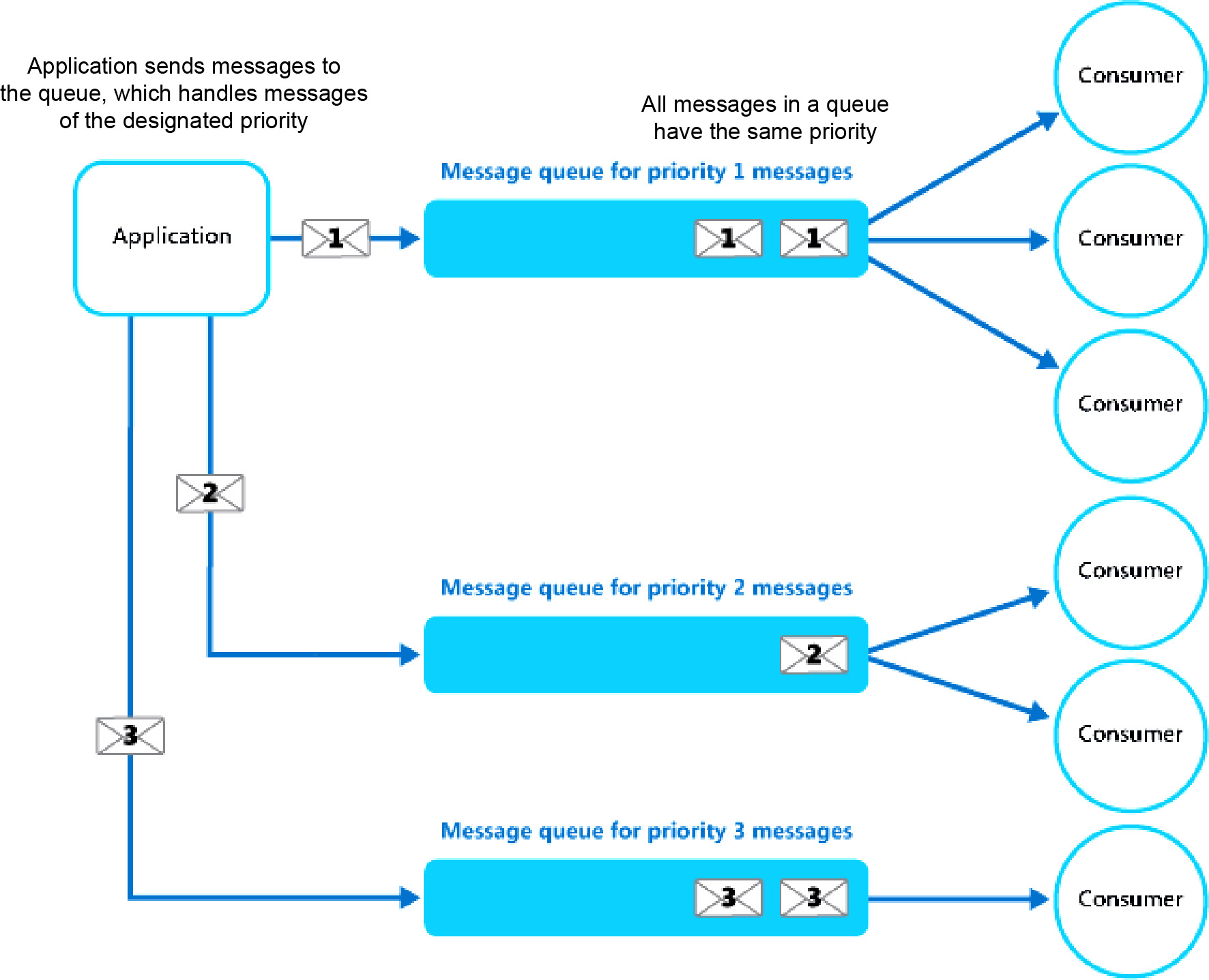
Figure 3.12: Using separate message queues for different priorities
In fact, this pattern can use the Competing Consumer pattern to fast-track the processing of messages from each queue using multiple consumers. Refer to the Microsoft documentation at https://docs.microsoft.com/azure/architecture/patterns/priority-queue to read more about the Priority Queue pattern.
The Queue-Based Load Leveling pattern
The Queue-Based Load Leveling pattern reduces the impact of peaks in demand on the availability and alertness of both tasks and services. Between a task and a service, a queue will act as a buffer. It can be invoked to handle the unexpected heavy loads that can cause service interruption or timeouts. This pattern helps to address performance and reliability issues. To prevent the service from getting overloaded, we will introduce a queue that will store a message until it's retrieved by the service. Messages will be taken from the queue by the service in a consistent manner and processed.
Figure 3.13 shows how the Queue-Based Load Leveling pattern works:

Figure 3.13: The Queue-Based Load Leveling pattern
Even though this pattern helps to handle spikes of unexpected demand, it is not the best choice when you are architecting a service with minimal latency. Talking of latency, which is a performance measurement, in the next section we will be focusing on performance and scalability patterns.
Performance and scalability patterns
Performance and scalability go together. Performance is the measure of how quickly a system can execute an action within a given time interval in a positive manner. On the other hand, scalability is the ability of a system to handle unexpected load without affecting the performance of the system, or how quickly the system can be expanded with the available resources. In this section, a couple of design patterns related to performance and scalability will be described.
The Command and Query Responsibility Segregation (CQRS) pattern
CQRS is not an Azure-specific pattern but a general pattern that can be applied in any application. It increases the overall performance and responsiveness of an application.
CQRS is a pattern that segregates the operations that read data (queries) from the operations that update data (commands) by using separate interfaces. This means that the data models used for querying and updates are different. The models can then be isolated, as shown in Figure 3.14, although that's not an absolute requirement.
This pattern should be used when there are large and complex business rules executed while updating and retrieving data. Also, this pattern has an excellent use case in which one team of developers can focus on the complex domain model that is part of the write model, and another team can focus on the read model and the user interfaces. It is also wise to use this pattern when the ratio of read to write is skewed. The performance of data reads should be fine-tuned separately from the performance of data writes.
CQRS not only improves the performance of an application, but it also helps the design and implementation of multiple teams. Due to its nature of using separate models, CQRS is not suitable if you are using model and scaffolding generation tools:
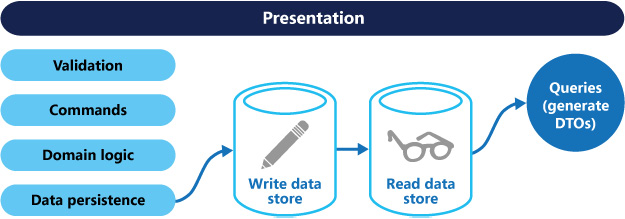
Figure 3.14: The CQRS pattern
Refer to the Microsoft documentation at https://docs.microsoft.com/azure/architecture/patterns/cqrs to read more about this pattern.
The Event Sourcing pattern
As most applications work with data and as the users are working with it, the classic approach for the application would be to maintain and update the current state of the data. Reading data from the source, modifying it, and updating the current state with the modified value is the typical data processing approach. However, there are some limitations:
- As the update operations are directly made against the data store, this will slow down the overall performance and responsiveness.
- If there are multiple users working on and updating the data, there may be conflicts and some of the relevant updates may fail.
The solution for this is to implement the Event Sourcing pattern, where the changes will be recorded in an append-only store. A series of events will be pushed by the application code to the event store, where they will be persisted. The events persisted in an event store act as a system of record about the current state of data. Consumers will be notified, and they can handle the events if needed once they are published.
The Event Sourcing pattern is shown in Figure 3.15:
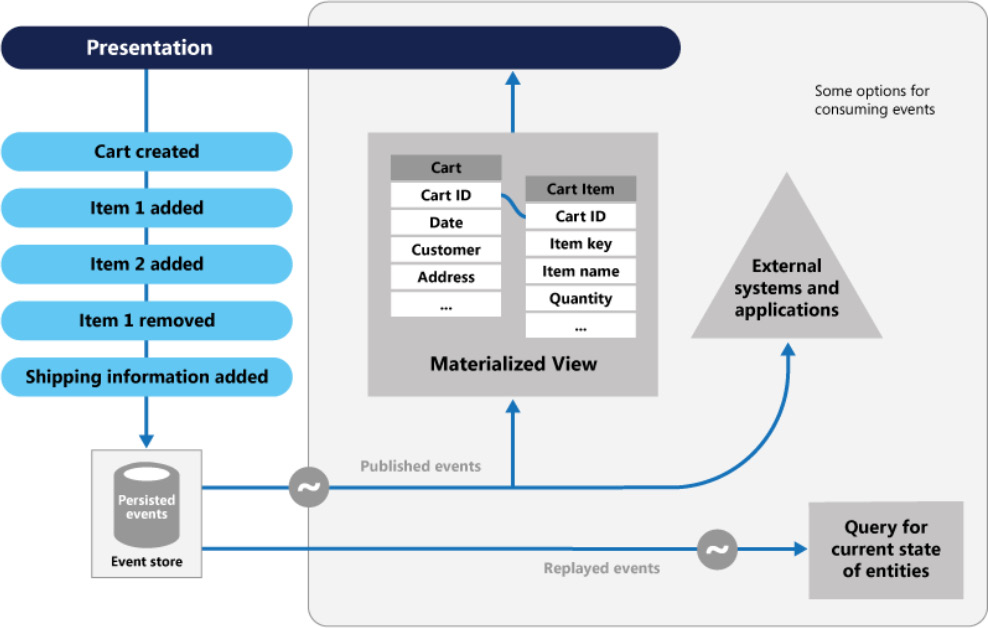
Figure 3.15: The Event Sourcing pattern
More information about this pattern is available at https://docs.microsoft.com/azure/architecture/patterns/event-sourcing.
The Throttling pattern
At times, there are applications that have very stringent SLA requirements from a performance and scalability perspective, irrespective of the number of users consuming the service. In these circumstances, it is important to implement the Throttling pattern because it can limit the number of requests that are allowed to be executed. The load on applications cannot be predicted accurately in all circumstances. When the load on an application spikes, throttling reduces pressure on the servers and services by controlling the resource consumption. The Azure infrastructure is a very good example of this pattern.
This pattern should be used when meeting the SLA is a priority for applications to prevent some users from consuming more resources than allocated, to optimize spikes and bursts in demand, and to optimize resource consumption in terms of cost. These are valid scenarios for applications that have been built to be deployed on the cloud.
There can be multiple strategies for handling throttling in an application. The Throttling strategy can reject new requests once the threshold is crossed, or it can let the user know that the request is in the queue and it will get the opportunity to be executed once the number of requests is reduced.
Figure 3.16 illustrates the implementation of the Throttling pattern in a multi-tenant system, where each tenant is allocated a fixed resource usage limit. Once they cross this limit, any additional demand for resources is constrained, thereby maintaining enough resources for other tenants:
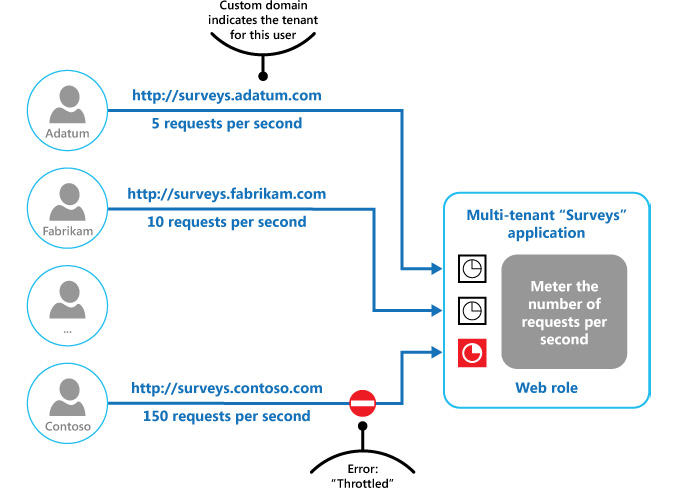
Figure 3.16: The Throttling pattern
Read more about this pattern at https://docs.microsoft.com/azure/architecture/patterns/throttling.
Retry pattern
The Retry pattern is an extremely important pattern that makes applications and services more resilient to transient failures. Imagine you are trying to connect to and use a service, and the service is not available for some reason. If the service is going to become available soon, it makes sense to keep trying to get a successful connection. This will make the application more robust, fault tolerant, and stable. In Azure, most of the components are running on the internet, and that internet connection can produce transient faults intermittently. Since these faults can be rectified within seconds, an application should not be allowed to crash. The application should be designed in a manner that means it can try to use the service again repeatedly in the case of failure and stop retrying when either it is successful or it eventually determines that there is a fault that will take time to rectify.
This pattern should be implemented when an application could experience transient faults as it interacts with a remote service or accesses a remote resource. These faults are expected to be short-lived, and repeating a request that has previously failed could succeed on a subsequent attempt.
The Retry pattern can adopt different retry strategies depending on the nature of the errors and the application:
- Retry a fixed number of times: This denotes that the application will try to communicate with the service a fixed number of times before determining that there's been a failure and raising an exception. For example, it will retry three times to connect to another service. If it is successful in connecting within these three tries, the entire operation will be successful; otherwise, it will raise an exception.
- Retry based on schedule: This denotes that the application will try to communicate with the service repeatedly for a fixed number of seconds or minutes and wait for a fixed number of seconds or minutes before retrying. For example, the application will try to connect to the service every three seconds for 60 seconds. If it is successful in connecting within this time, the entire operation will be successful. Otherwise, it will raise an exception.
- Sliding and delaying the retry: This denotes that the application will try to communicate with the service repeatedly based on the schedule and keep adding an incremental delay in subsequent tries. For example, for a total of 60 seconds, the first retry happens after a second, the second retry happens two seconds after the previous retry, the third retry happens four seconds after the previous retry, and so on. This reduces the overall number of retries.
Figure 3.17 illustrates the Retry pattern. The first request gets an HTTP 500 response, the second retry again gets an HTTP 500 response, and finally the request is successful and gets HTTP 200 as the response:
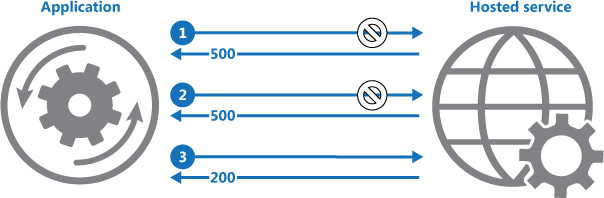
Figure 3.17: The Retry pattern
Refer to this Microsoft documentation at https://docs.microsoft.com/azure/architecture/patterns/retry to find out more about this pattern.
The Circuit Breaker pattern
This is an extremely useful pattern. Imagine again that you are trying to connect to and use a service, and the service is not available for some reason. If the service is not going to become available soon, there is no use continuing to retry the connection. Moreover, keeping other resources occupied while retrying wastes a lot of resources that could potentially be used elsewhere.
The Circuit Breaker pattern helps eliminate this waste of resources. It can prevent applications from repeatedly trying to connect to and use a service that is not available. It also helps applications to detect whether a service is up and running again, and allow applications to connect to it.
To implement the Circuit Breaker pattern, all requests to the service should pass through a service that acts as a proxy to the original service. The purpose of this proxy service is to maintain a state machine and act as a gateway to the original service. There are three states that it maintains. There could be more states included, depending on the application's requirements.
The minimal states needed to implement this pattern are as follows:
- Open: This denotes that the service is down and the application is shown as an exception immediately, instead of allowing it to retry or wait for a timeout. When the service is up again, the state is transitioned to Half-Open.
- Closed: This state denotes that the service is healthy and the application can go ahead and connect to it. Generally, a counter shows the number of failures before it can transition to the Open state.
- Half-Open: At some point, when the service is up and running, this state allows a limited number of requests to pass through it. This state is a litmus test that checks whether the requests that pass through are successful. If the requests are successful, the state is transitioned from Half-Open to Closed. This state can also implement a counter to allow a certain number of requests to be successful before it can transition to Closed.
The three states and their transitions are illustrated in Figure 3.18:
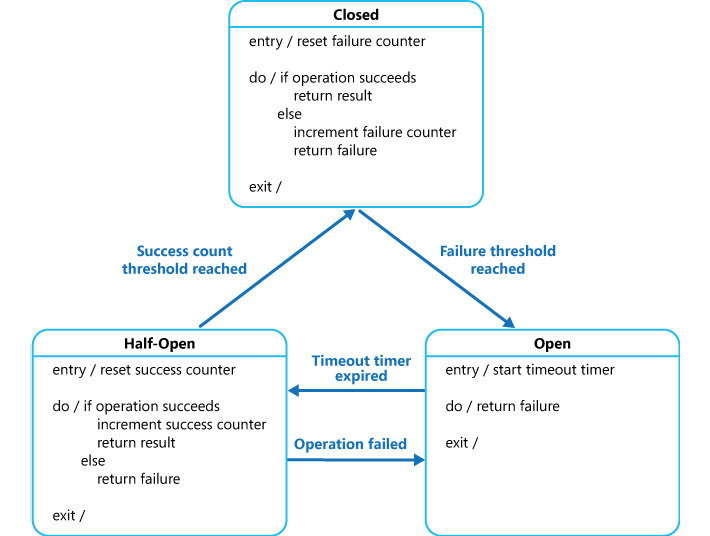
Figure 3.18: The Circuit Breaker pattern
Read more this pattern in the Microsoft documentation at https://docs.microsoft.com/azure/architecture/patterns/circuit-breaker.
In this section, we discussed design patterns that can be used to architect reliable, scalable, and secure applications in the cloud. There are other patterns, though, which you can explore at https://docs.microsoft.com/azure/architecture/patterns.
Summary
There are numerous services available on Azure, and most of them can be combined to create real solutions. This chapter explained the three most important services provided by Azure—regions, storage, and networks. They form the backbone of the majority of solutions deployed on any cloud. This chapter provided details about these services and how their configuration and provisioning can affect design decisions.
Important considerations for both storage and networks were detailed in this chapter. Both networks and storage provide lots of choices, and it is important to choose an appropriate configuration based on your requirements.
Finally, some of the important design patterns related to messaging, such as Competing Consumers, Priority Queue, and Load Leveling, were described. Patterns such as CQRS and Throttling were illustrated, and other patterns, such as Retry and Circuit Breaker, were also discussed. We will keep these patterns as the baseline when we deploy our solutions.
In the next chapter, we will be discussing how to automate the solutions we are going to architect. As we move ahead in the world of automation, every organization wants to eliminate the overhead of creating resources one by one, which is very demanding. Since automation is the solution for this, in the next chapter you will learn more about it.