
Chapter 1. Understanding and Measuring Bias with AIF 360
Bias can occur at any stage in the machine learning pipeline (Figure 1-1), and fairness metrics and bias mitigation algorithms can be performed at various stages within the pipeline. We recommend checking for bias as often as possible, using as many metrics as are relevant to your application. We also recommend integrating continuous bias detection into your automated pipeline. AIF360 is compatible with the end-to-end machine learning workflow and is designed to be easy to use and extensible. Practitioners can go from raw data to a fair model easily while comprehending the intermediate results, and researchers can contribute new functionality with minimal effort.
In this chapter, we look at current tools and terminology and then begin looking at how AIF360’s metrics work.
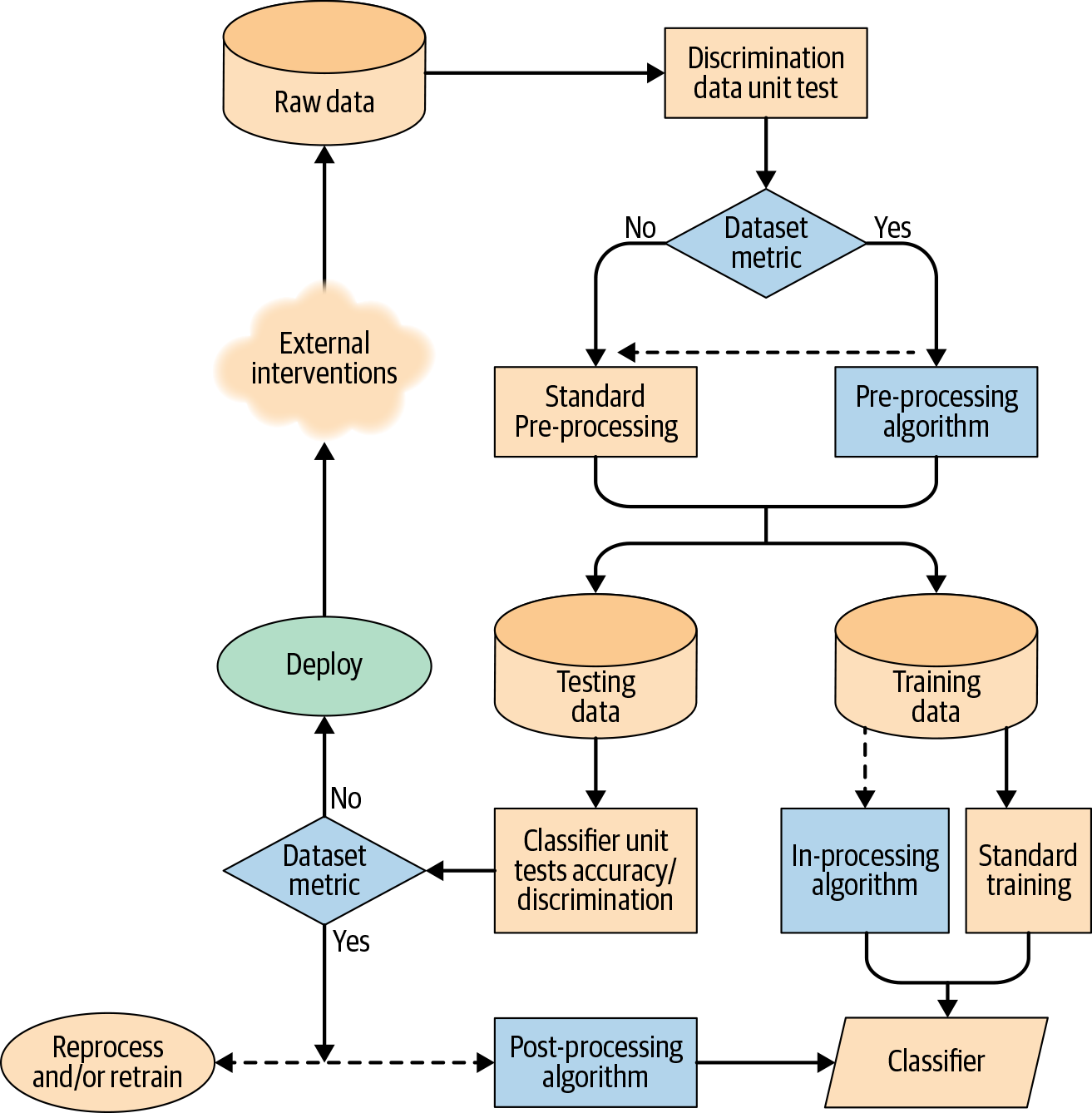
Figure 1-1. Bias in the machine learning pipeline
Tools and Terminology
Several open source libraries have been developed in recent years to contribute to building fairer AI models. Most address only bias detection, not mitigating bias. Just a handful of toolkits (like Themis-ML and Fairness Comparison) address both, but they are often limited for commercial use due to their usability and license restrictions. IBM fairness researchers took on the initiative to unify these efforts, as shown in Table 1-1, and bring together a comprehensive set of bias metrics, bias mitigation algorithms, bias metric explanations, and industrial usability in one open source toolkit with AIF360.
| Open source library | Advantages/disadvantages |
|---|---|
| Fairness Measures | Provides several fairness metrics, including difference of means, disparate impact, and odds ratio. It also provides datasets, but some are not in the public domain and require explicit permission from the owners to access or use the data. |
| FairML | Provides an auditing tool for predictive models by quantifying the relative effects of various inputs on a model’s predictions, which can be used to assess the model’s fairness. |
| FairTest | Checks for associations between predicted labels and protected attributes. The methodology also provides a way to identify regions of the input space where an algorithm might incur unusually high errors. This toolkit also includes a rich catalog of datasets. |
| Aequitas | This is an auditing toolkit for data scientists as well as policy makers; it has a Python library and website where data can be uploaded for bias analysis. It offers several fairness metrics, including demographic, statistical parity, and disparate impact, along with a “fairness tree” to help users identify the correct metric to use for their particular situation. Aequitas’s license does not allow commercial use. |
| Themis | An open source bias toolbox that automatically generates test suites to measure discrimination in decisions made by a predictive system. |
| Themis-ML | Provides fairness metrics, such as mean difference, some bias mitigation algorithms,a additive counterfactually fair estimator,b and reject option classification.c The repository contains a subset of the methods described in this book. |
| Fairness Comparison | Includes several bias detection metrics as well as bias mitigation methods, including disparate impact remover,d prejudice remover,e and two-Naive Bayes.f Written primarily as a test bed to allow different bias metrics and algorithms to be compared in a consistent way, it also allows additional algorithms and datasets. |
a F. Kamiran and T. Calders, “Data preprocessing techniques for classification without discrimination,” in Knowledge and Information Systems 33, no. 1, 2012, 1–33. b M. J. Kusner et al., “Counterfactual Fairness,” in Advances in Neural Information Processing Systems, 2017, 4,069–4,079. c F. Kamiran et al., “Decision Theory for Discrimination-Aware Classification,” in Proceedings of IEEE International Conference on Data Mining, 2012, 924–929. d M. Feldman et al., “Certifying and Removing Disparate Impact,” in Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 2015, 259–268. e T. Kamishima et al., “Fairness-Aware Classifier with Prejudice Remover Regularizer,” in Machine Learning and Knowledge Discovery in Databases, 2012, 35–50. f T. Calders and S. Verwer, “Three Naive Bayes Approaches for Discrimination-Free Classification,” in Data Mining and Knowledge Discovery 21, 2010, 77–292. | |
AIF360 is an extensible, open source toolkit for measuring, understanding, and reducing AI bias. It combines the top bias metrics, bias mitigation algorithms, and metric explainers from fairness researchers across industry and academia. The goals of the AIF360 toolkit are as follows:
-
To promote a deeper understanding of fairness metrics and mitigation techniques
-
To enable an open common platform for fairness researchers and industry practitioners to share and benchmark their algorithms
-
To help facilitate the transition of fairness research algorithms for use in an industrial setting
AIF360 currently includes Python packages that implement techniques from eight published papers across the greater AI fairness research community. There are currently 77 bias detection metrics and 10 bias mitigation algorithms that can be called in a standard way similar to scikit-learn’s fit/transform/predict paradigm. The toolkit is open source and contains documentation, demonstrations, and other artifacts.
Terminology
To use the AIF360 toolkit effectively, it helps to be familiar with the relevant fairness terminology. Here are a few of the specialized machine learning terms to know:
- Favorable label
-
A label whose value corresponds to an outcome that provides an advantage to the recipient (such as receiving a loan, being hired for a job, not being arrested)
- Protected attribute
-
An attribute that partitions a population into groups whose outcomes should have parity (such as race, gender, caste, and religion)
- Privileged value (of a protected attribute)
-
A protected attribute value indicating a group that has historically been at a systemic advantage
- Fairness metric
-
A quantification of unwanted bias in training data or models
- Discrimination/unwanted bias
-
Although bias can refer to any form of preference, fair or unfair, our focus is on undesirable bias or discrimination, which is when specific privileged groups are placed at a systematic advantage and specific unprivileged groups are placed at a systematic disadvantage. This relates to attributes such as race, gender, age, and sexual orientation.
Which Metrics Should You Use?
AIF360 currently contains 77 fairness metrics to measure bias (see Figure 1-2), so it can be difficult to understand which metrics to use for each use case. Because there is no one best metric for every case, it is recommended to use several metrics, carefully chosen with the guidance of subject matter experts and key stakeholders within your organization. AIF360 has both difference and ratio versions of metrics that essentially convey the same information, so you can choose based on the comfort of the users examining the results.
AIF360’s API documentation allows you to view all of its metrics and algorithms along with a definition of each metric, algorithm, or explainer; the research on which it is based; its source code; and its parameters and exceptions. There are several classes of metrics listed in the API categories that follow. If your use case requires metrics on training data, use the ones in the DatasetMetric class (and in its child classes, such as BinaryLabelDatasetMetric). If the application requires metrics on models, use the ClassificationMetric class. Here are the relevant classes:
- BinaryLabelDatasetMetric
-
A class for computing metrics based on a single binary label dataset
- ClassificationMetric
-
A class for computing metrics based on a two binary label dataset
- Sample Distortion Metric
-
A class for computing metrics based on two structured datasets
- Utility Functions
-
A helper script for implementing metrics

Figure 1-2. How bias is measured
Individual Versus Group Fairness Metrics
If your use case is focused on individual fairness, use the metrics in the SampleDistortionMetric class or the consistency metric. If your focus is on group fairness, use the DatasetMetric class (and its child classes, such as the BinaryLabelDatasetMetric) as well as ClassificationMetric. And if your use case is concerned with both individual and group fairness and requires the use of a single metric, use the generalized entropy index and its specializations to the Theil index and the coefficient of variation in the ClassificationMetric class. However, multiple metrics, including ones from both individual and group fairness, can be examined simultaneously.
Worldviews and Metrics
If your use case follows the WAE worldview, use the demographic parity metrics (such as disparate_impact and statistical_parity _difference). If your use case follows the WYSIWYG worldview, use the equality of odds metrics (such as average_odds_difference and average_abs_odds_difference). Other group fairness metrics (often labeled “equality of opportunity”) lie in between the two worldviews. Relevant metrics include the following:
-
false_negative_rate_ratio -
false_negative_rate_difference -
false_positive_rate_ratio -
false_positive_rate_difference -
false_discovery_rate_ratio -
false_discovery_rate_difference -
false_omission_rate_ratio -
false_omission_rate_difference -
error_rate_ratio -
error_rate_difference
Dataset Class
The Dataset class and its subclasses are a key abstraction that handle all forms of data. Training data is used to learn classifiers, whereas testing data is used to make predictions and compare metrics. Besides these standard aspects of a machine learning pipeline, fairness applications also require associating protected attributes with each instance or record in the data. To maintain a common format, independent of what algorithm or metric is being applied, AIF360 structures the Dataset class so that all relevant attributes (features, labels, protected attributes, and their respective identifiers) are present in and accessible from each instance of the class. Subclasses add further attributes that differentiate the dataset and dictate with which algorithms and metrics it can interact.
Structured data is the primary type of dataset studied in fairness literature and is represented by the StructuredDataset class. Further distinction is made for a BinaryLabelDataset—a structured dataset that has a single label per instance that can take only one of two values: favorable or unfavorable. Unstructured data can be accommodated in the AIF360 architecture by constructing a parallel class to the StructuredDataset class, without affecting existing classes or algorithms that do not apply to unstructured data.
Transparency in Bias Metrics
We now turn our focus to the broader issue of improving transparency in bias metrics.
Explainer Class
The AIF 360 toolkit prioritizes the need to explain fairness metrics, so IBM researchers developed an Explainer class to coincide with the Metrics class that provides further insights about computed fairness metrics. Different subclasses of varying complexity that extend the Explainer class can be created to output explanations that are meaningful to different kinds of users. The explainer capability implemented in the first release of AIF360 is basic reporting through printed JSON outputs. Future releases might include fine-grained localization of bias, actionable recourse analysis, and counterfactual fairness.
AI FactSheets
One barrier to fairness and trust in AI is the lack of standard practices to document how AI services are created, tested, trained, deployed, and evaluated. Organizations are asking for transparency in AI services as well as how they should and should not be used. To address this need, AI FactSheets1 provide information about a machine learning model’s important characteristics in a similar way to food nutrition labels or appliance specification sheets. They would contain information such as system operation, training data, underlying algorithms, test setup and results, performance benchmarks, fairness and robustness checks, intended uses, maintenance, and retraining. Example questions could be as follows:
-
Does the dataset used to train the service have a datasheet or data statement?
-
Were the dataset and model checked for biases? If so, describe the bias policies that were checked, bias checking methods, and results.
-
Was any bias mitigation performed on the dataset? If so, describe the mitigation method.
-
Are algorithm outputs explainable or interpretable? If so, explain how (for example, through a directly explainable algorithm, local explainability, or explanations via examples).
-
Who is the target user of the explanation (machine learning expert, domain expert, general consumer, regulator, etc.)?
-
Was the service tested on any additional datasets? Do they have a datasheet or data statement?
-
Describe the testing methodology.
-
Is usage data from service operations retained?
-
What behavior is expected if the input deviates from training or testing data?
-
How is the overall workflow of data to the AI service tracked?
This information will aid users in understanding how the service works, its strengths and limitations, and whether it is appropriate for the application they are considering.
1 M. Arnold et al., “FactSheets: Increasing Trust in AI Services through Supplier’s Declarations of Conformity” in IBM Journal of Research and Development 63, no. 4/5, (July/September 2019): 6, https://oreil.ly/Bvo10.