
Chapter 6
Fuzzing iOS Applications
The first step in the remote exploitation of a device is to find a security vulnerability in it. As you saw in the discussion of the iOS attack surface in the first chapter, an attacker has many potential ways to supply data to an iOS device. These include some server-side threats such as mDNSresponder, the wireless and Bluetooth stack, and to some extent, SMS messages. On the client side are many programs including the web browser, mail client, audio/video player, and App Store apps. The key is to find an input to one of these programs that you can use to change the behavior of the application.
This is where fuzzing comes in. Fuzzing is the process of dynamically testing applications by repeatedly sending malformed data to the application being tested. Most importantly, fuzzing allows you to discover many vulnerabilities in iOS, sometimes with very little effort or even understanding of the underlying programs being tested. In other words, it is the easiest way to find iOS bugs.
In later chapters, you learn how to take these vulnerabilities and use them to create exploits that can perform some unauthorized action on the devices in question.
How Fuzzing Works
Fuzzing, also known as dynamic analysis, is the art and science of crafting illegal inputs and supplying them to applications in the hope that the application exhibits some security issue. Entire books have been written on the subject, including Fuzzing: Brute Force Discovery by Sutton, Greene, and Amini, (ISBN 978-0321446114) as well as Fuzzing for Software Security Testing and Quality Assurance by Takanen, DeMott, and Miller, (ISBN 978-1596932142). Fuzzing is perhaps the easiest way to find bugs. In the past it has been used to find numerous security-related bugs in products as diverse as the Apache HTTP Server, the Microsoft RPC interface, and of course, MobileSafari on iOS.
The basic idea behind fuzzing is to repeatedly send slightly malformed input into a system. A well-designed and implemented application should be able to handle any inputs provided to it. It should reject invalid inputs and wait for any future data, if relevant. When it receives valid input, it should perform whatever operations it is intended to perform. Under no circumstances should the program crash and stop functioning as designed. Fuzzing tests this idea by sending millions of inputs to the program to see if the program ever crashes (or performs some other unacceptable action). By monitoring an application during fuzzing, the tester can determine which inputs have caused faults in the application.
The typical kinds of bugs found with fuzzing include memory-corruption types of vulnerabilities such as buffer overflows. For example, suppose the programmer assumes that a particular piece of data, say a phone number, will never exceed 32 bytes and thus prepares a buffer of that size for the data. If the developer does not explicitly check the data (or limit the size of the copy into this buffer), a problem could occur because data outside the intended buffer may get corrupted. For this reason, fuzzing is often thought of as a technique that tests the developer's assumptions by submitting malformed data.
One of the great things about fuzzing is that it is very simple to set up a basic fuzzing test environment and find some real bugs, as you see shortly. You don't necessarily have to understand the program being tested (or have source code), or the inputs you are fuzzing. In the simplest case, all you need is a program and a valid input to it. You just need that and some time and CPU cycles to let the fuzzing run. You also see later that, although it is possible to set up fuzzing rather quickly, an understanding of the way the inputs are composed and an understanding of how the underlying program functions will be necessary to fuzz deeply into the program and find the best bugs. After all, corporations (like Apple) and other researchers are all fuzzing, and so sometimes it is necessary to fuzz a little deeper to find the best bugs.
Although fuzzing has many advantages, it does have some drawbacks. Some bugs do not lend themselves to being found with fuzzing. Perhaps there is a checksum on some field that, when the input is modified, causes the program to reject the input. Maybe many bytes of the input are related, and changing one of them is easily detectable and thus the program quickly rejects invalid inputs. Likewise, if a bug is evident only when very precise conditions are met, it is unlikely that fuzzing will find this bug, at least in a reasonable period of time. So, while certain types of protocols and inputs are harder to fuzz than others, different types of applications are harder to fuzz as well. Programs can sometimes mask memory corruption if they handle their own faults and are very robust. Programs can also be hard to monitor if they include heavy anti-debugging such as Digital Rights Management software. For these reasons, fuzzing is not always the best choice for vulnerability analysis. As you see shortly, it works sufficiently well for most iOS applications.
The Recipe for Fuzzing
A few steps are involved when fuzzing an application. The first one is figuring out exactly what application you want to fuzz. Next, you need to generate the fuzzed inputs. After that, you need to find a way to get these inputs to the application. Finally, you need a way to monitor the application being tested for any faults that might occur.
Identifying the application and the type of data to fuzz is probably the most important step of the process, although one that involves a bit of luck. In Chapter 1, you learned about many of the ways data can be sent to an iOS device from an attacker. You have a lot of options when choosing which application to fuzz. Even once that decision is made, you have to decide exactly what types of inputs you want to fuzz. For example, MobileSafari accepts many types of inputs. You may choose to fuzz .mov files in MobileSafari or something even more exact, like Media Header Atoms in .mov files in MobileSafari. A general rule of thumb is that the more obscure the application and protocol, the better off you are likely to be. Also, it helps to target applications that were written a long time ago (such as QuickTime) and/or that have a history of security issues (yep, that's you again QuickTime).
Mutation-Based (“Dumb”) Fuzzing
Once you know what you'd like to fuzz, you need to actually start coming up with the fuzzed inputs, or test cases. You have basically two ways to do this. One is called mutation-based fuzzing, or “dumb” fuzzing. This is the type of fuzzing that takes just a few minutes to set up and get running, but normally can't find deep hidden bugs. The way it works is simple. Take a valid input to the application. This might be a file, like a .mov file, or some network inputs, like an HTTP session, or even just a set of command-line arguments. Then begin randomly making changes to this valid input. For example
GET /index.html HTTP/1.0
might be mutated to strings like
GEEEEEEEEEEEEEET /index.html HTTP/1.0 GET / / / / / / / / / / / / / / / //index.html HTTP/1.0 GET /index................................html HTTP/1.0 GET /index.htmllllllllllllllllllllllllllllllllllllllll HTTP/1.0 GET /index.html HTTP/1.00000000000000000
And so on.
If the programmer made any incorrect assumptions about the size of one of these fields, these inputs may trigger some kind of fault. To make these random changes, you don't necessarily have to know anything about the way the HTTP protocol works, which is nice. However, as you may guess, most web servers that perform any sanity checking on the data will quickly reject most of these inputs. This leads to a subtle issue with regard to input generation. You have to make changes to the valid inputs to find bugs, but if you make your changes too drastic, the inputs will be quickly rejected. You have to find the sweet spot, meaning you have to make enough changes to cause problems but not enough to make the data too invalid. This chapter demonstrates mutation-based fuzzing against MobileSafari.
Generation-Based (“Smart”) Fuzzing
Many researchers believe that the more protocol knowledge you can build into your fuzzed inputs, the better chance you have at finding vulnerabilities. This points to the other approach: constructing fuzzed inputs, generation-based or “smart” fuzzing. Generation-based fuzzing does not start from a particular valid input, but rather begins from the way the protocol specification describes these types of inputs. So, for the previous example, instead of starting for a specific request for a file called index.html on a web server, this method starts from the RFC for HTTP (www.ietf.org/rfc/rfc2616.txt). In section 5 of this document, it describes what an HTTP message must look like:
HTTP-message = Request | Response ; HTTP/1.1 messages
It later defines what form a Request must take:
Request = Request-Line ; Section 5.1
*(( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 4.3
Digging further, you see that Request-Line is specified as follows:
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
where Method is defined like this:
Method = "OPTIONS" ; Section 9.2
| "GET" ; Section 9.3
| "HEAD" ; Section 9.4
| "POST" ; Section 9.5
| "PUT" ; Section 9.6
| "DELETE" ; Section 9.7
| "TRACE" ; Section 9.8
| "CONNECT" ; Section 9.9
| extension-method
extension-method = token
This continues on for quite a while, but eventually, the RFC specifies the possible layout of every HTTP message. You can write a program that will create /valid/ but /malformed/ HTTP messages if the program understands this RFC specification. For example, it could generate a completely valid Request-URI but choose a particularly long method name.
The disadvantage of generation-based fuzzing is that it requires a lot of work! You have to understand the protocol (which may be proprietary) and have a program that can generate inputs that are malformed but mostly compliant. You see later how to use a fuzzing framework to help with this. Clearly, this is much more work than simply finding a valid HTTP message and making random changes to it. However, the advantage should be equally obvious. In this case, if there is a vulnerability in the way the server handles HTTP TRACE requests, the mutation-based fuzzing approach doesn't uncover it because it makes only GET requests (or randomly named request methods). A generation-based approach constructs fuzzed REQUEST-LINEs for each of the possible methods, which reveals this theoretical bug. As they say, you get what you pay for, and the same is true here. The more effort you put into fuzzing, the more likely you'll have something to show for it. Later in this chapter, you see how to create generation-based test cases using the Sulley fuzzing framework.
Submitting and Monitoring the Test Cases
At this point in the process you have a large set of inputs you'd like to send to the program and you have to figure out how to get them there. For files, this might require launching the program over and over with a particular command-line argument. For network servers, you may need to have a program that can repeatedly connect and send one of the test cases. This is normally one of the easiest steps in the fuzzing process, but can be difficult sometimes in iOS because this operating system is not designed to be a fully functioning computer, but rather just a phone or other such device. So, for example, MobileSafari was never designed to be launched from the command line and thus cannot accept URLs that way. Alternative methods must be investigated in this case.
The final step is to monitor the application being fuzzed for any faults. This is a really crucial step in fuzzing that is often overlooked. You may create the cleverest test cases in the world, but if you can't tell when something has gone wrong, it does no good to perform the testing. Likewise, if you cannot replicate faults, by saving the test cases for example, it does no good to discover a problem.
The simplest way to monitor applications is to attach a debugger to them and watch for exceptions or signals. When a program dies, it generates a signal that the debugger can act upon. This generally isn't necessary in Mac OS X or in iOS, which you see shortly. More sophisticated methods can also be used to monitor the application. You can monitor what files are opened by the application, memory usage, and so on. Overall, the more you monitor, the more types of problems you can notice when the right test case is input into the application. It is time to put this introduction to fuzzing to use.
Fuzzing Safari
iOS runs a stripped-down version of Mac OS X. In fact, there is a large portion of the code that is identical, simply recompiled for ARM instead of x86 (or PowerPC). Therefore, one option when looking for bugs in iOS is to look for bugs in the code for Mac OS X that is shared with iOS. This is easier said than done, and it is possible you'll be wasting time looking in code that isn't even in iOS. The advantage of looking for Mac OS X bugs is that everything is simpler on the desktop. You can run multiple fuzzing instances against many computers, all the desktops will have superior hardware compared to the iOS devices, more utilities are available for use, and so on. In other words, it is easier to set up a fuzzing run and you can fuzz many more test cases in a given amount of time on Mac OS X desktops compared to iOS devices. The only real drawback is that you might end up discovering vulnerabilities that are in Mac OS X and not in iOS, which isn't the end of the world. I talk about more iOS-specific options later in this chapter.
Choosing an Interface
First off, you need to choose something to fuzz. Because both Safari and MobileSafari run WebKit, there is a lot of shared code to fuzz there. For simplicity, the example in this section fuzzes the Portable Document Format (PDF). Both Safari and MobileSafari render these documents. This document format is a nice target because it is a binary format, which is pretty complex. Because Adobe announces many vulnerabilities in Acrobat Reader every few months, and the Mac OS X libraries need to handle similar documents, it is reasonable to think there might be vulnerabilities lurking in this code as well.
Generating Test Cases
One of the great things about fuzzing file formats is that it is easy to generate a large number of test cases. To use mutation-based fuzzing, simply find a sample PDF file (or many) and make random mutations to it. The quality of the test cases will depend on the PDF you use. If you use a very simple file, it will not test much of the PDF parsing code. A complex file will work better. Ideally, you should generate test cases from many different initial PDFs, each exercising different features present in the PDF specification.
The following Python function adds random mutations to a buffer. You can imagine reading in a PDF and repeatedly calling this function on its contents to generate different mutated files:
def fuzz_buffer(buffer, FuzzFactor):
buf = list(buffer)
numwrites=random.randrange(math.ceil((float(len(buf)) /
FuzzFactor)))+1
for j in range(numwrites):
rbyte = random.randrange(256)
rn = random.randrange(len(buf))
buf[rn] = "%c"%(rbyte);
return "".join(buf)
Although this code is extremely naive, it has been used in the past to find a large number of vulnerabilities in Mac OS X and iOS.
Testing and Monitoring the Application
You can combine testing and monitoring because the tool you're writing will be responsible for both. The fuzzed inputs generated by the fuzz_buffer function need to be sent to the application under test. Equally importantly, you need to monitor the application to see if the inputs cause it some trouble. After all, it doesn't do any good to craft the perfect malicious input and send it to the program being tested if you don't know that it caused a crash!
Crash Reporter, available on Mac OS X as well as iOS, is an excellent mechanism for determining when something has crashed. This isn't totally ideal for fuzzing, because the results of Crash Reporter are files in a directory that show up a short time after a crash and disappear after some number of crashes occurs. Therefore, for monitoring it may be better to imitate the crash.exe application for Windows. crash.exe, written by Michael Sutton, can be found as part of FileFuzz (http://labs.idefense.com/software/fuzzing.php.) This simple program takes as command-line arguments a program to launch, the number of milliseconds required to run the file, and a list of command-line arguments to the program being tested.
crash.exe then launches the program and attaches to it so it can monitor for crashes or other bad behavior. If the application crashes, it prints some information about the registers at the time of the crash. Otherwise, after the number of milliseconds specified, it kills the program and exits (see Figure 6.1).
Figure 6.1 Finding crashes with crash.exe on Windows

Basically, crash.exe has the following features that are ideal for executing a target program multiple times in succession. It launches the target program with a specified argument. It is guaranteed to return after a specified period of time. It identifies when a crash occurs and gives some information about the crash, in this case, a context dump of the registers. Otherwise, it prints that the process has terminated. Finally, you know that the target process is not running after crash.exe ends. This last piece is important because programs often act differently if they are started while another occurrence of them is already running.
The following example shows that it is pretty straightforward to imitate this behavior on Mac OS X with a simple shell script named crash, taking advantage of the way Crash Reporter works. (This script is written in bash instead of Python so you can use it on iOS later, and it's best to avoid Python in iOS, since it runs a bit slow there.)
#!/bin/bash mkdir logdir 2>/dev/null app=$1 url=$2 sleeptime=$3 filename=∼/Library/Logs/CrashReporter/$app* mv $filename logdir/ 2> /dev/null /usr/bin/killall -9 "$app" 2>/dev/null open -a "$app" "$url" sleep $sleeptime cat $filename 2>/dev/null
This script takes the name of the program to be launched as a command-line argument, a command-line argument to pass to the program, and the number of seconds to sleep before returning. It moves any existing crash reports for the application in question to a logging directory. It then kills off any existing target processes and calls open to launch the application with the specified argument. open is a good way to launch processes because, for example, it allows you to specify a URL as a command-line argument to Safari. If you just launch the Safari application, it expects only a filename. Finally, it sleeps for the number of seconds requested and prints out the crash report, if there is one. Here are two examples of its use:
$ ./crash Safari http://192.168.1.182/good.html 10 $ $ ./crash Safari http://192.168.1.182/bad.html 10 Process: Safari [57528] Path: /Applications/Safari.app/Contents/MacOS/Safari Identifier: com.apple.Safari Version: 5.1.1 (7534.51.22) Build Info: WebBrowser-7534051022000000∼3 Code Type: X86-64 (Native) Parent Process: launchd [334] Date/Time: 2011-12-05 09:15:27.988 -0600 OS Version: Mac OS X 10.7.2 (11C74) Report Version: 9 Crashed Thread: 10 Exception Type: EXC_BAD_ACCESS (SIGBUS) Exception Codes: KERN_PROTECTION_FAILURE at 0x000000010aad5fe8 ... Thread 0:: Dispatch queue: com.apple.main-thread 0 libsystem_kernel.dylib 0x00007fff917b567a mach_msg_trap + 10 1 libsystem_kernel.dylib 0x00007fff917b4d71 mach_msg + 73 ...
With this handy little script, you can easily automate the process of launching an application and detecting if there is a crash by parsing it's standard out. The other good thing is that it works for a variety of applications, not just Safari. Examples like these work just as well:
$ ./crash TextEdit toc.txt 3 $ ./crash "QuickTime Player" good.mp3 3
So, you have a way to generate inputs and a way to launch a program for testing and to monitor it. All that remains is to tie it all together:
import random
import math
import subprocess
import os
import sys
def fuzz_buffer(buffer, FuzzFactor):
buf = list(buffer)
numwrites=random.randrange(math.ceil((float(len(buf)) /
FuzzFactor)))+1
for j in range(numwrites):
rbyte = random.randrange(256)
rn = random.randrange(len(buf))
buf[rn] = "%c"%(rbyte);
return "".join(buf)
def fuzz(buf, test_case_number, extension, timeout, app_name):
fuzzed = fuzz_buffer(buf, 10)
fname = str(test_case_number)+"-test"+extension
out = open(fname, "wb")
out.write(fuzzed)
out.close()
command = ["./crash", app_name, fname, str(timeout)]
output = subprocess.Popen(command,
stdout=subprocess.PIPE).communicate()[0]
if len(output) > 0:
print "Crash in "+fname
print output
else:
os.unlink(fname)
if(len(sys.argv)<5):
print "fuzz <app_name> <time-seconds> <exemplar>
<num_iterations>"
sys.exit(0)
else:
f = open(sys.argv[3], "r")
inbuf = f.read()
f.close()
ext = sys.argv[3][sys.argv[3].rfind(‘.’):]
for j in range(int(sys.argv[4])):
fuzz(inbuf, j, ext, sys.argv[2], sys.argv[1])
Adventures in PDF Fuzzing
If you run the fuzzer outlined in the previous section with PDFs on an old version of Mac OS X (<10.5.7), you'll probably rediscover the JBIG vulnerability from early in 2009 (http://secunia.com/secunia_research/2009-24/). This vulnerability is present in Mac OS X and iOS 2.2.1 and earlier. The crash report for this particular bug in iOS looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>AutoSubmitted</key>
<true/>
<key>SysInfoCrashReporterKey</key>
<string>c81dedd724872cf57fb6a432aa482098265fa401</string>
<key>bug_type</key>
<string>109</string>
<key>description</key>
<string>Incident Identifier: E38AB756-D3E6-43D0-9FFA-
427433986549
CrashReporter Key: c81dedd724872cf57fb6a432aa482098265fa401
Process: MobileSafari [20999]
Path: /Applications/MobileSafari.app/MobileSafari
Identifier: MobileSafari
Version: ??? (???)
Code Type: ARM (Native)
Parent Process: launchd [1]
Date/Time: 2009-06-15 12:57:07.013 -0500
OS Version: iOS OS 2.2 (5G77)
Report Version: 103
Exception Type: EXC_BAD_ACCESS (SIGSEGV)
Exception Codes: KERN_INVALID_ADDRESS at 0xc000000b
Crashed Thread: 0
Thread 0 Crashed:
0 libJBIG2.A.dylib 0x33c88fa8 0x33c80000 + 36776
1 libJBIG2.A.dylib 0x33c89da0 0x33c80000 + 40352
2 libJBIG2.A.dylib 0x33c8a1b0 0x33c80000 + 41392
...
This bug justifies using desktop fuzzing to find iOS bugs, because it demonstrates that bugs found in the desktop operating system are also present (sometimes) in iOS. However, things aren't always so straightforward. It turns out that even though both the Mac OS X desktop and iOS web browsers render and display PDF files, the iOS version is not as full featured and doesn't handle all the intricacies of PDF files as well as the Mac OS X version. One prominent example is the bug Charlie Miller used to win Pwn2Own in 2009 (http://dvlabs.tippingpoint.com/blog/2009/03/18/pwn2own-2009-day-1---safari-internet-explorer-and-firefox-taken-down-by-four-zero-day-exploits). This bug was in the way Mac OS X handled malicious Compact Font Format (CFF). This vulnerability could be triggered directly in the browser with the @font-face HTTP tag, but at the contest Miller embedded the font in a PDF. The heap overflow caused by this vulnerability was a little hard to exploit, but was obviously possible! Things were different in iOS. iOS seemed to ignore the embedded font completely and was not susceptible to the same file. This is an example of where a bug in OS X, which you might think would be in iOS, was not. As a further example, Miller in (securityevaluators.com/files/slides/cmiller_CSW_2010.ppt) found 281 unique PDF-induced crashes of Safari in OS X but only 22 (7.8 percent) crashed MobileSafari.
Here is another font-related PDF crash that triggers on OS X but not on iOS. This vulnerability is unpatched at the time of this writing:
Process: Safari [58082]
Path: /Applications/Safari.app/Contents/MacOS/Safari
Identifier: com.apple.Safari
Version: 5.1.1 (7534.51.22)
Build Info: WebBrowser-7534051022000000∼3
Code Type: X86-64 (Native)
Parent Process: launchd [334]
Date/Time: 2011-12-05 09:46:10.589 -0600
OS Version: Mac OS X 10.7.2 (11C74)
Report Version: 9
Crashed Thread: 0 Dispatch queue: com.apple.main-thread
Exception Type: EXC_BAD_ACCESS (SIGSEGV)
Exception Codes: KERN_INVALID_ADDRESS at 0x0000000000000000
VM Regions Near 0:
-->
_TEXT 00000001041ab000-00000001041ac000
[ 4K] r-x/rwx SM=COW
/Applications/Safari.app/Contents/MacOS/Safari
Application Specific Information:
objc[58082]: garbage collection is OFF
Thread 0 Crashed:: Dispatch queue: com.apple.main-thread
0 libFontParser.dylib 0x00007fff8dd079dd
TFormat6UTF16cmapTable::Map(unsigned short
const*,
unsigned short*, unsigned int&) const + 321
1 libFontParser.dylib 0x00007fff8dd07a9f
TcmapEncodingTable::MapFormat6(TcmapTableData
const&, unsigned char const*&, unsigned int,
unsigned short*, unsigned int&) const + 89
2 libFontParser.dylib 0x00007fff8dce9f71
TcmapEncodingTable::Map(unsigned char const*&,
unsigned int, unsigned short*, unsigned int&)
const
+ 789
3 libFontParser.dylib 0x00007fff8dd197b9
FPFontGetTrueTypeEncoding + 545
Another issue you might find is that files that cause a crash on a desktop system require too many resources for the mobile device. This doesn't tell you whether or not the bug is in iOS, just that the particular file may be too large to render completely. If the bug looks interesting enough on the desktop, it may be worth your time to strip the PDF down to a more manageable size while trying to keep the bug intact. This may require a significant amount of work and possibly a full understanding of the vulnerability. It might not even be possible. To demonstrate this issue, here is an older crash on the desktop:
Process: Safari [11068]
Path: /Applications/Safari.app/Contents/MacOS/Safari
Identifier: com.apple.Safari
Version: 4.0 (5530.17)
Build Info: WebBrowser-55301700∼2
Code Type: X86 (Native)
Parent Process: launchd [86]
Date/Time: 2009-06-15 13:14:04.182 -0500
OS Version: Mac OS X 10.5.7 (9J61)
Report Version: 6
Anonymous UUID: FE533568-9587-4762-94D2-218B84ACA99C
Exception Type: EXC_BAD_ACCESS (SIGBUS)
Exception Codes: KERN_PROTECTION_FAILURE at 0x0000000000000050
Crashed Thread: 0
Thread 0 Crashed:
0 com.apple.CoreGraphics 0x913ba9c1
CGImageSetSharedIdentifier + 78
1 com.apple.CoreGraphics 0x919d3b28
complex_draw_patch + 3153
2 com.apple.CoreGraphics 0x919d5782
cg_shading_type6_draw + 7154
3 com.apple.CoreGraphics 0x919e7bc8
CGShadingDelegateDrawShading + 354
4 libRIP.A.dylib 0x95fd7750
ripc_DrawShading + 8051
5 com.apple.CoreGraphics 0x9142caa7
CGContextDrawShading + 100
If you run the same PDF on the iOS, the browser disappears as if it crashed. However, it is not because of a crash, but rather because the device's limited resources are being exhausted. Here is the report of the problem:
Incident Identifier: FEB0AB3C-CB16-4B4E-A66A-FD27A9F2F7DE
CrashReporter Key: 96fe78ade92e4beeeee112a637133bb905f07623
OS Version: iOS OS 3.0 (7A341)
Date: 2009-06-15 11:18:39 -0700
Free pages: 244
Wired pages: 6584
Purgeable pages: 0
Largest process: MobileSafari
Processes
Name UUID Count resident pages
MobileSafari <72f90a06ab2018c76f683bcd3706fa8b>
5110 (jettisoned) (active)
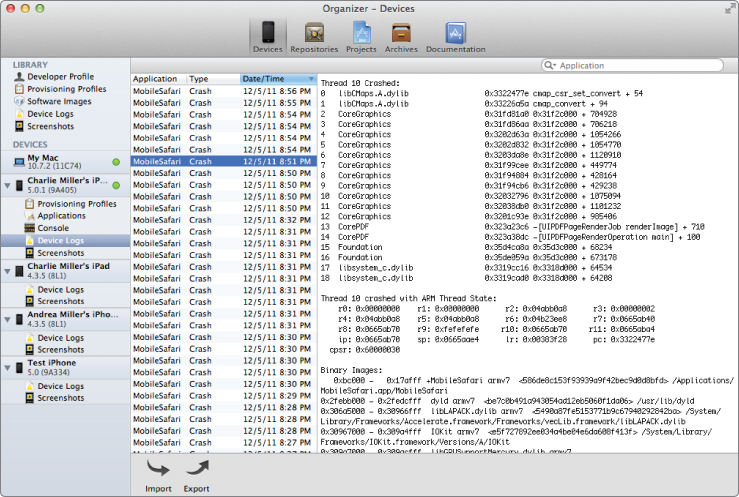
From this information, it is impossible to tell if the code on the phone contains the vulnerability or not. However, it is not all bad news. It is possible to find some real iOS bugs with this approach. Figure 6.2 shows a crash report on Mac OS X.
Figure 6.2 A crash report in OS X

Figure 6.3 shows the same crash (with nearly identical backtrace in iOS).
Figure 6.3 The same report in iOS
Quick Look Fuzzing
For a quick and dirty start, fuzzing Safari in the hopes that MobileSafari will have the same vulnerabilities works well. But they are actually different programs, and if you want to continue the approach of fishing for iOS bugs by fuzzing OS X, you're going to have to do some things differently. Consider the way Microsoft Office file formats (.xls, .ppt, .doc, .docx, and so on) are handled by the two browsers. Safari prompts the user to download the file. MobileSafari automatically parses and renders it. Therefore, you won't be able to fuzz the way MobileSafari handles Office files by fuzzing Safari. This is important because these are file formats that Microsoft Office can't handle in a secure manner, and those are the only file formats that Office cares about. You wouldn't expect iOS to fare much better for a format that is not its main concern. In fact, the .ppt format was used to win the Pwn2Own 2011 contest against the iPhone by two authors of this book.
If you attach gdb to MobileSafari, you'll observe that the first time an Office document is loaded, a particular library is loaded, named OfficeImport. Later, when fuzzing, you can confirm this is the library that handles Office documents because you'll see crashes inside it.
... 165 OfficeImport F 0x38084000 dyld Y Y /System/Library/PrivateFrameworks/OfficeImport.framework/ OfficeImport at 0x38084000 (offset 0x6c6000) /System/Library/PrivateFrameworks/OfficeImport.framework/ OfficeImport" at 0x38084000]
If you know OS X very well, you know that there is a way to preview Office documents, in Finder or as attachments in Mail.app, by highlighting them and pressing the space bar. This previewing capacity is compliments of Quick Look. Quick Look can be controlled on the command line using the qlmanage program. For example,
qlmanage -p good.ppt
renders the requested presentation to the screen. A look at qlmanage in a debugger shows the same library that you saw inside MobileSafari:
173 OfficeImport F 0x1062b0000 dyld Y Y /System/Library/PrivateFrameworks/OfficeImport.framework/ Versions/A/OfficeImport at 0x1062b0000 (offset 0x1062b0000)
Therefore, to fuzz MobileSafari's Office document fuzzing capabilities, it is mostly sufficient to fuzz qlmanage. Keep in mind that in some instances crashes don't always correspond between qlmanage and iOS (or the iOS simulator, which we'll discuss next). For example, a crash in qlmanage might not be present in MobileSafari. However, this seems relatively rare and is probably due more to slightly different library versions rather than because they have different code or functionality. With only minor changes to the PDF fuzzer, you can produce a PPT fuzzer that should find bugs in iOS. Figure 6.4 shows an example of a crash you might find.
Figure 6.4 A crash report from an invalid PPT file

Fuzzing with the Simulator
The iOS SDK comes with an iOS simulator This simulator provides you with the convenience of running and testing applications developed with the SDK without having to use an actual hardware device. You might think this would be an ideal situation for fuzzing because you could fuzz iOS on any Mac OS X system with many processes in parallel. Additionally, with virtualization, you could run multiple instances of OS X systems (and hence multiple simulator instances) on each physical computer. However, the simulator, which is shown in Figure 6.5, turns out to be less than ideal for fuzzing.
Figure 6.5 The iOS simulator
You can find the simulator binary at /Developer/Platforms/iPhoneSimulator.platform/Developer/Applications/iPhone Simulator.app.
For the sake of discussion, let's stick to (Mobile)Safari, because that is what you fuzzed earlier in the chapter.
A look through the SDK reveals that there is something akin to a stripped-down iOS filesystem at /Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator5.0.sdk. For the rest of this section, all files will be relative to this directory:
$ ls -1 Applications Developer Library SDKSettings.plist System usr
Looking in the Applications folder provides the first clue as to why the simulator isn't going to be ideal for fuzzing:
$ ls -1 Applications/ AdSheet.app Camera.app Contacts∼ipad.app Contacts∼iphone.app DataActivation.app Game Center∼ipad.app Game Center∼iphone.app MobileSafari.app MobileSlideShow.app Photo Booth.app Preferences.app TrustMe.app Web.app WebSheet.app iPodOut.app wakemonitor
There isn't a large number of applications in the simulator. For example, there is no iTunes or MobileMail — two definite targets for fuzzing. At least they have MobileSafari, which is one of the best applications to fuzz. However, looking closer at the simulated MobileSafari shows some other problems.
Take a closer look at MobileSafari for the simulator. You can find it at Applications/MobileSafari.app/MobileSafari.
$ file MobileSafari.app/MobileSafari MobileSafari.app/MobileSafari: Mach-O executable i386
This program is an x86 binary and isn't built for the ARM architecture. It runs directly on the processor on which the simulator is running. This means that quite a few differences between this version of MobileSafari and the version on an actual iOS are likely. Looking at the process list on the Mac OS X computer, you can see it running:
$ ps aux | grep MobileSafari cmiller 78248 0.0 0.7 852436 29344 ?? S 9:17AM /Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/ iPhoneSimulator5.0.sdk//Applications/MobileSafari.app/MobileSafari
In fact, you can see all the simulator-related processes that are running. These include processes like
- AppIndexer
- searchd
- SpringBoard
- apsd
- SimulatorBridge
- aggregated
- BTServer
- locationd
- mediaremoted
- ubd
- MobileSafari
You can see what makes this MobileSafari binary different from the actual Safari by looking at the libraries it depends on. Some of these include
- JavaScriptCore
- WebKit
- UIKit
- SpringBoardServices
- CoreTelephony
Some of the libraries listed here are found in Safari as well, and some are not, including the last four in the list. These libraries are referenced from the iOS filesystem and not the root of the underlying host.
So, obviously, the simulator is not an exact copy of the hardware device. It is different from the device in a few other ways, too. It doesn't have the same resource limitations. It used to be that there were file types, like SVG, that the simulator couldn't open but the actual device could. At the very least, the simulator lacks the memory protections of the hardware devices, and you will not be able to test things closely tied to the hardware like SMS (which you learn about later in this chapter).
The biggest obstacle to using the simulator is probably the fact that the simulator is not jailbroken. That is, you cannot easily launch applications in it, which is a fundamental requirement of fuzzing.
If you want to fuzz the simulator despite these difficulties, you'll find that crash reports for this MobileSafari end up in the usual spot on the Mac OS X host, ∼/Library/Logs/CrashReporter, because this is really just an x86 application.
So, you can try fuzzing the simulator, but it is different enough to be difficult and you shouldn't entirely trust the results. Anyway, why fuzz the simulator, when you can fuzz the actual device?
Fuzzing MobileSafari
You can fuzz MobileSafari in pretty much the same way as you fuzz Safari on a Mac OS X computer. The main differences are that the crash files show up in a slightly different place, there is no open binary, and MobileSafari cannot be started from the command line. Of course, due to hardware limitations, the fuzzing goes much slower as well.
Selecting the Interface to Fuzz
You can find a variety of things on MobileSafari to choose for fuzzing. Although the attack surface is smaller than Mac OS X, it is still quite significant in size. One interesting idea is to choose a Microsoft Office file format because it is automatically parsed in iOS but not in Mac OS X. Perhaps this means that Apple has not audited it as heavily. This section demonstrates fuzzing on MobileSafari by using the .ppt PowerPoint format.
Generating the Test Case
For test-case generation, you use the fuzz_buffer function used while fuzzing PDFs. One difference is that you'll want to generate test cases on your desktop and send them to the iOS device, since the iOS device is a bit weak computationally. Therefore, this will again be a mutation-based approach to fuzzing. In just a bit, you'll get to see a generation-based approach.
Fuzzing and Monitoring MobileSafari
In iOS, crashes for processes that run as user mobile end up in /private/var/mobile/Library/Logs/CrashReporter. The last MobileSafari crash will be linked from the file LatestCrash-MobileSafari.plist.
To get something that works like the open binary on Mac OS X, you have to use a small helper program that causes MobileSafari to render a web page for you. You can borrow sbopenurl from https://github.com/comex/sbsutils/blob/master/sbopenurl.c.
#include <CoreFoundation/CoreFoundation.h>
#include <stdbool.h>
#include <unistd.h>
#define SBSApplicationLaunchUnlockDevice 4
#define SBSApplicationDebugOnNextLaunch_plus_SBSApplicationLaunch
WaitForDebugger 0x402
bool SBSOpenSensitiveURLAndUnlock(CFURLRef url, char flags);
int main(int argc, char **argv) {
if(argc != 2) {
fprintf(stderr, "Usage: sbopenurl url
");
}
CFURLRef cu = CFURLCreateWithBytes(NULL, argv[1],
strlen(argv[1]), kCFStringEncodingUTF8, NULL);
if(!cu) {
fprintf(stderr, "invalid URL
");
return 1;
}
int fd = dup(2);
close(2);
bool ret = SBSOpenSensitiveURLAndUnlock(cu, 1);
if(!ret) {
dup2(fd, 2);
fprintf(stderr, "SBSOpenSensitiveURLAndUnlock failed
");
return 1;
}
return 0;
}
This program simply calls the SBSOpenSensitiveURLAndUnlock API from the private SpringBoardServices framework on the URL passed in as a command-line argument. You can build it with the following commands:
/Developer/Platforms/iPhoneOS.platform/Developer/usr/bin/gcc -x objective-c -arch armv6 -isysroot /Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS5.0 .sdk/ -F /Developer/Platforms/iPhoneOS.platform/Developer/ SDKs/iPhoneOS5.0.sdk/System/Library/PrivateFrameworks -g – -framework Foundation -framework SpringBoardServices -o sbopenurl sbopenurl.c
Then you need to give it the proper entitlement to work:
codesign -fs "iPhone Developer" --entitlements ent.plist sbopenurl
Here you'll need to have previously downloaded a developer certificate from Apple. The file ent.plist contains the necessary entitlements and looks like this:
<dict>
<key>com.apple.springboard.debugapplications</key>
<true/>
<key>com.apple.springboard.opensensitiveurl</key>
<true/>
</dict>
Transfer the program to your iOS device and you have a replacement for open. The slightly modified version of crash now runs in iOS:
#!/bin/bash url=$1 sleeptime=$2 filename=/private/var/mobile/Library/Logs/CrashReporter/ LatestCrash-MobileSafari.plist rm $filename 2> /dev/null echo Going to do $url /var/root/sbopenurl $url sleep $sleeptime cat $filename 2>/dev/null /usr/bin/killall -9 MobileSafari 2>/dev/null
and is run the same way as previously:
iPhone:∼ root# ./crash http://192.168.1.2/a/62.pdf 6
Going to do http://192.168.1.2/a/62.pdf
iPhone:∼ root# ./crash http://192.168.1.2/a/63.pdf 6
Going to do http://192.168.1.2/a/63.pdf
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>AutoSubmitted</key>
<true/>
<key>SysInfoCrashReporterKey</key>
<string>411e2ce88eec340ad40d98f220a2238d3696254c</string>
<key>bug_type</key>
<string>109</string>
...
You now have a way to generate inputs, launch MobileSafari against a URL, and detect crashes. All that remains is to tie it all together. We leave that to the interested reader.
PPT Fuzzing Fun
When you run the fuzzer from the previous section, you will quickly begin to find bugs. Following is one such example that is not patched at the time of this writing. It is from the same crash outlined in the “Quick Look Fuzzing” section. Notice that no symbols are available for MobileSafari crashes on the iOS device.
# ./crash http://192.168.1.2/bad.ppt 10
Going to do http://192.168.1.2/bad.ppt
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>AutoSubmitted</key>
<true/>
<key>SysInfoCrashReporterKey</key>
<string>411e2ce88eec340ad40d98f220a2238d3696254c</string>
<key>bug_type</key>
<string>109</string>
<key>description</key>
<string>Incident Identifier: 7A75E653-019B-44AC-BE54-
271959167450
CrashReporter Key: 411e2ce88eec340ad40d98f220a2238d3696254c
Hardware Model: iPhone3,1
Process: MobileSafari [1103]
Path: /Applications/MobileSafari.app/MobileSafari
Identifier: MobileSafari
Version: ??? (???)
Code Type: ARM (Native)
Parent Process: launchd [1]
Date/Time: 2011-12-18 21:56:57.053 -0600
OS Version: iPhone OS 5.0.1 (9A405)
Report Version: 104
Exception Type: EXC_BAD_ACCESS (SIGSEGV)
Exception Codes: KERN_INVALID_ADDRESS at 0x0000002c
Crashed Thread: 10
...
Thread 10 Crashed:
0 OfficeImport 0x383594a0 0x3813e000 + 2208928
1 OfficeImport 0x381bdc82 0x3813e000 + 523394
2 OfficeImport 0x381bcbbe 0x3813e000 + 519102
3 OfficeImport 0x381bb990 0x3813e000 + 514448
4 OfficeImport 0x38148010 0x3813e000 + 40976
5 OfficeImport 0x38147b94 0x3813e000 + 39828
...
Thread 10 crashed with ARM Thread State:
r0: 0x00000024 r1: 0x00000000 r2: 0x00000000 r3: 0x00000000
r4: 0x00000000 r5: 0x0ecbece8 r6: 0x00000000 r7: 0x04fa8620
r8: 0x002d3c90 r9: 0x00000003 r10: 0x00000003 r11: 0x0ecc43b0
ip: 0x04fa8620 sp: 0x04fa8620 lr: 0x381bdc89 pc: 0x383594a0
cpsr: 0x00000030
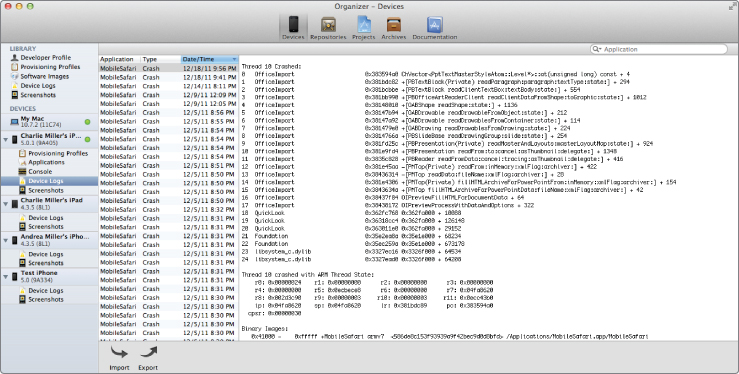
If you sync your device and look at the logs in the Organizer window in Xcode, you get symbols. (Or you can use the standalone symbolicatecrash utility, which comes as part of the iOS SDK). See Figure 6.6.
Figure 6.6 Symbolicated crash report seen in Xcode
SMS Fuzzing
So far, you've fuzzed the web browser that comes with iOS. This is by far one of the largest attack surfaces in iOS. However, iOS is obviously more than a mobile web browser. In this section, you fuzz something that you don't see on many desktops. It demonstrates how to fuzz the way iPhones receive Short Message Service (SMS) messages.
SMS, the technology behind text messages, consists of small amounts of data sent over the wireless carrier radio network to devices. These messages represent a great vector for attacks for a few reasons. The main reason is, unlike the TCP/IP stack, there is no way to “firewall” inbound connections. All new SMS communications arrive unannounced and must be handled by the device. From a targeting perspective, it is also very interesting. Though it might be hard to find someone's IP address, especially for a laptop that is carried from place to place, it is often quite easy to find someone's phone number. Another reason SMS is an attractive attack vector is that it doesn't require any user interaction to get data to the application. This differs from attacking web browsers, which requires getting the user to visit a malicious site. As an added bonus, on iOS, the process that handles SMS messages does not run in a sandbox and is responsible for communication with the baseband processor (more on this in a bit). So, armed with a phone number and an SMS exploit, an attacker could conceivably get code running that can monitor phone calls and text messages, with no user interaction, and there isn't anything the victims can do about it if they want to receive phone calls or SMS messages. An SMS exploit would be very powerful indeed. Let's see how you could find an SMS vulnerability in iOS.
SMS Basics
SMS is really a communications protocol designed to be used in Global System of Mobile Communications (GSM) mobile communication systems. This protocol was originally documented in the GSM standards more than twenty years ago. SMS uses the bandwidth normally reserved for telephony traffic control when not in use. This control channel is used for the phone to communicate to nearby towers, and provides a way for both towers and the phone to know everything is okay on the network. This channel is also needed for call setup, such as the message the tower sends to the phone when there is an incoming call. SMS was designed to also use these control channels so that it could be implemented without adding any expense or hardware for the carrier. The drawback is that messages are necessarily short, as the name suggests. Currently, SMS data is restricted to 140 bytes, or 160 7-bit characters (70 16-bit characters). SMS is now available on a wide range of networks, including 3G and 4G networks.
When a device sends an SMS message, it is sent to a Short Message Service Center (SMSC). The SMSC then forwards the message toward the intended recipient. This may mean passing it to another SMSC or directly to the recipient, depending on whether the sending and receiving device are on the same carrier network. SMSCs play the role of routers in IP networks, with one big exception. If a recipient is not reachable — for example, if their phone is turned off or they are somewhere out of the range of service — the SMSC queues the message for later delivery. SMS delivery is best effort, meaning there is no guarantee that a given message will reach its destination and no guarantee that no delays will occur.
SMS can deliver more than just text. Some providers allow over-the-air programming of devices using SMS messages. It is possible to send binary data such as ringtones and pictures or use SMS to alert when voicemails are received. iOS, in particular, uses SMS messages to provide information concerning visual voicemails and MMS.
The iPhone is actually composed of two processors: the main CPU, called the application processor, and a second CPU, called the baseband processor. The main CPU is the one that runs the iOS operating system kernel and all applications mentioned so far. The baseband processor runs a specialized real-time operating system that controls the mobile phone interface and handles all communication with the cellular phone network. (The baseband processor is covered in detail in Chapter 11.) For now, you need to know only that the baseband processor provides a way for the application processor to communicate with it. This communication takes place over multiple logical serial lines. On older iPhones, the actual software running on the application CPU communicates to the modem over these serial lines using the text-based GSM AT command set. These AT commands are used to control every aspect of the cellular phone network interface, including call control and SMS delivery.
When an SMSC delivers an SMS message to the modem of the iPhone, the modem communicates with the application processor via an unsolicited AT command result code. The result code consists of two lines of text. The first contains the result code and the number of bytes that follow on the next line. The second line contains the SMS message in hexadecimal representation. These AT command result codes are read by some version of the CommCenter process on the iPhone.
Exactly which process handles the communication is dependent on the hardware present on the iPhone. Inside the /System/Library/LaunchDaemons directory are two associated plist files called com.apple.CommCenter.plist and com.apple.CommCenterClassic.plist. Examining these (after converting to XML format using plutil) show they both have the label com.apple.CommCenter, however, they are limited to different hardware. CommCenterClassic lists:
...
<key>LimitLoadToHardware</key>
<dict>
<key>machine</key>
<array>
<string>iPhone1,2</string>
<string>iPhone2,1</string>
<string>iPhone3,1</string>
<string>iPod2,1</string>
<string>iPod2,2</string>
<string>iPod3,1</string>
<string>iPod4,1</string>
<string>iPad0,1</string>
<string>iPad1,1</string>
<string>iPad2,1</string>
<string>iPad2,2</string>
<string>AppleTV2,1</string>
</array>
</dict>
...
By way of comparison, CommCenter lists a different set of hardware:
...
<key>LimitLoadToHardware</key>
<dict>
<key>machine</key>
<array>
<string>iPhone3,3</string>
<string>iPhone4,1</string>
<string>iPhone4,2</string>
<string>iPad2,3</string>
<string>iPad3,1</string>
<string>iPad3,2</string>
<string>iPad3,3</string>
</array>
</dict>
...
For simplicity this chapter examines CommCenterClassic.
Focusing on the Protocol Data Unit Mode
The SMS specification has two modes in which a modem may operate, called SMS text mode and SMS Protocol Data Unit (PDU) mode. When acting in different modes, the syntax of SMS AT commands and the responses returned will differ. The biggest difference is that SMS text mode supports only text. For example, to send an SMS message, you would use something like this:
AT+CMGS="+85291234567" Lame SMS text mode message
Because of this limitation, far fewer features are available in SMS text mode. Another problem with SMS text mode is that it is not as widely supported by modems.
For these reasons, this section focuses on SMS PDU mode. This provides you with a much larger (although compared to a browser, quite small) attack surface in which to look for bugs.
SMS messages exist in two formats. The SMS-SUBMIT format is used for messages sent from mobile devices to the SMSC, and the SMS-DELIVER format is used for messages sent from the SMSC to the mobile device. Because this section focuses on how iOS handles incoming messages, it concentrates on SMS-DELIVER messages.
Following is an example of an unsolicited AT result code for an SMS-DELIVER format in SMS PDU mode:
+CMT: ,30 0791947106004034040D91947196466656F8000090108211421540 0BE8329BFD4697D9EC377D
The CMT result code is used for delivery of SMS messages in iOS. Now that you've seen what a message in SMS-DELIVER format looks like, this format is described in detail as we dissect this example.
The first byte is the length of the SMSC information, in this case 7 octets (bytes). These 7 octets (91947106004034) are further split. Of these, the first byte is the type of address of the SMSC, in this case 91, which means an international phone number. The remaining digits make up the actual SMSC number, +491760000443. Notice that each byte is nibble reversed. The next octet, 04, is the message header flags. The least significant two bits of this octet being zero indicate it is an SMS-DELIVER message. The one bit that is set indicates there are more messages to send. One other important bit discussed later in the “Using User Data Header Information” section is the UDHI bit, which is not set in this example.
Next up is the address of the sender. Like the address of the SMSC, these octets consist of a length, a type, and the data, as follows:
0D 91 947196466656F8
The difference is that the length is calculated as the number of semi-octets minus 3. A semi-octet can be thought of as a nibble (4 bits) if the data is considered as hexadecimal (0x94, 0x71, 0x96,...), or as a “character” in the ASCII representation (“491769...”).
The next byte is the protocol identifier (TP-PID). This byte has various meanings depending on the bits that are set. Normally, this will be 00, which means that the protocol can be determined based on the address. The next byte is the data coding scheme (TP-DCS). This field indicates how the data of the SMS message is encoded. This includes whether the data is compressed, uses a 7-, 8-, or 16-bit alphabet, and also if the data is used as an indicator of some type (like voicemail). In this case, it is 00, which means the data is an uncompressed, 7-bit alert and should be displayed immediately.
The next 7 bytes are the timestamp of the message (TP-SCTS). The first byte is the year, the next the month, and so on. Each byte is nibble swapped. In this case, the message was sent some time on January 28, 2009.
The next byte is the user data length, (TP-UDL). Because the TP-DCS field indicated 7-bit data, this is the number of septets of data that will follow. The remaining bytes are the 7-bit data for the message.
In this case, the bytes E8329BFD4697D9EC377D decode to hellohellot.
Table 6.1 summarizes what you've seen so far.
Table 6.1 PDU Information
| Size | Field |
| 1 byte | Length - SMSC |
| 1 byte | Type - SMSC |
| Variable | Data – SMSC |
| 1 byte | DELIVER |
| 1 byte | Length – Sender |
| 1 byte | Type – Sender |
| Variable | Data – Sender |
| 1 byte | TP-PID |
| 1 byte | TP-DCS |
| 7 bytes | TP-SCTS |
| 1 byte | TP-UDL |
| Variable | TP-UD |
Using PDUspy
When exploring the world of PDU data, one of the most useful tools available is PDUspy (www.nobbi.com/pduspy.html). Unfortunately, this tool is only for Windows. It is indispensable when creating and checking PDUs. See Figure 6.7 for the PDU you analyzed in the previous section dissected by PDUspy.
Figure 6.7 PDUspy dissecting a PDU
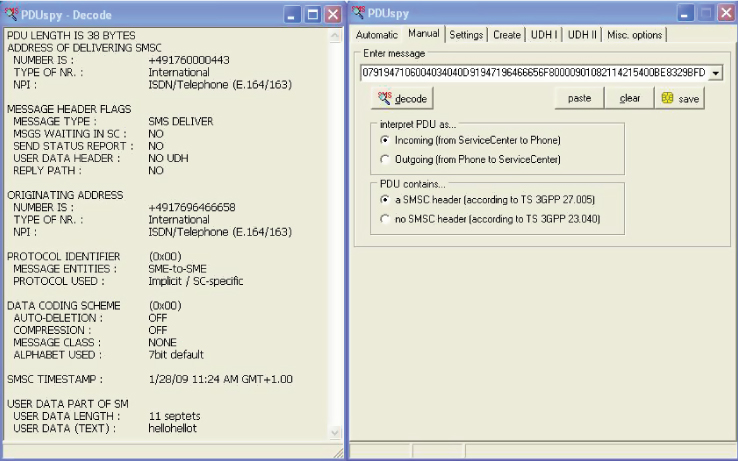
You simply enter the PDU in the field, with the settings as in the picture, and PDSspy will decode the PDU, even as the PDU is being entered! This tool is useful for checking that any test cases generated for SMS fuzzing are more or less legitimate, or at least as expected. It is also extremely useful for analyzing a PDU that has caused a crash. It will normally point out the fields that are incorrect, which should lead you to the root cause of the problem. Interestingly, some of the iOS SMS bugs from the past that are discussed later manifest themselves as exceptions in PDUspy (which it, ironically, handles).
Using User Data Header Information
The previous example was the simplest type of SMS message available. More complicated formats exist, as hinted in the description of the TP-DCS field. The User Data Header (UDH) provides a means to send control information as opposed to just data for an alert. A flag in the DELIVER field of an SMS message indicates the presence of this type of data.
Here is an example of a UDH:
050003000301
This UDH data sits in the general-purpose data field of the SMS message, that is, in the TP-UD field. The UDH begins with a single byte that specifies the number of bytes in the UDH. This field is called the UDHL, and in the preceding example is 05. This field is followed by one or more elements. Each of these headers uses a typical type-length-value (TLV) syntax. That is, the first byte is the type of element. This byte is abbreviated IEI for Information Element Identifier. The next byte is the Information Element Data Length, IEDL. The last is the actual data of the element, the Information Element Data (IED). In this example, the type is 00, the length is 03, and the data is 000301. The UDH can be followed with arbitrary data. The breakdown is shown in Table 6.2.
Table 6.2 UDH Breakdown
| Size | Field | Example Bytes |
| 1 byte | UDHL | 05 |
| 1 byte | IEI | 00 |
| 1 byte | IEDL | 03 |
| Variable | IED | 00 03 01 |
Working with Concatenated Messages
Looking closer at this example, an IEI of 00 means this is a concatenated message with an 8-bit reference number. This type of element is used to send SMS messages that are longer than the maximum 160 bytes. It allows for longer messages to be broken apart, placed in multiple SMS messages, and reassembled by the receiver. The first byte of the IED is the message reference number. This is just some unique number that is used to differentiate in the event that the receiver is receiving more than one concatenated message at a given time. The second byte indicates how many total messages are in this session. The last byte is which message in the session this message happens to be. In the example, the reference number is 00, and there are 03 total messages, of which this one is the first (the counting here is not zero-based but begins with the number 1). Using message concatenation, it is theoretically possible to send an SMS consisting of 255 parts, each containing 154 bytes of data for a total size of around 40,000 bytes for this message.
Using Other Types of UDH Data
iOS can handle a number of different IEI values, as shown in Figure 6.8.
Figure 6.8 Reversing the function that is responsible for IEI values

Here, the CommCenter binary has been reverse-engineered using IDA Pro. This function, among other things, operates on the IEI of an SMS containing a UDH. If you look at this function in detail, you will see that the iPhone can handle the following values of IEI: 0, 1, 4, 5, 0x22, 0x24, 0x25. This is useful information when fuzzing:
- 00 — Concatenated short message, 8-bit reference number
- 01 — Special SMS message indicator (voice-mail)
- 04 — Application port addressing 8-bit
- 05 — Application port addressing 16-bit
- 22 — Alternate reply address
- 24, 25 — Reserved
*List taken from Mobile messaging technologies and services: SMS, EMS, MMS by Gwenael Le Bodic
One of these types of UDH elements occurs when a voicemail is available. An IEI of 01 indicates this. The typical UDH data for such an event looks like 0401020020. Here the UDHL is 04, the IEI is 01, the IEDL is 02, and the IED is 0020. This indicates 0x20 voicemail messages are available. This is a nice way to possibly annoy your friends if you can send raw SMS data to them.
Another use of UDH is to send data to particularly registered applications. Much like the way TCP has ports and certain applications may bind to these ports, applications may listen for data on particular UDH ports. Here the UDH data may look like 06050400000000 followed by whatever data is intended for the application. In this example, the UDHL is 06 and the IEI is 05, which means application port addressing using 16-bit ports. Next is 04 for IEDL followed by the port number information, which is 0000 for the source port and 0000 for the destination port in this example. Any application-specific data would then follow.
Another use in iOS for UDH data in SMS messages is for visual voicemail. When a visual voicemail arrives, an SMS message arrives with a URL on where to go pick it up. This URL resolves only on the carrier network, and if you give it a URL on the Internet, it attempts to go to it (through the carrier network) but the carrier network doesn't allow the full three-way handshake. Regardless, this URL is another thing to try to fuzz. A visual voicemail message is sent from UDH port number 0000 to port 5499 and the text is of the URL. The URL takes a form similar to this:
allntxacds12.attwireless.net:5400?f=0&v=400&m=XXXXXXX&p=&s=5433& t=4:XXXXXXX:A:IndyAP36:ms01:client:46173
where the XXXXXXX is the phone number, which I've removed in the hope that AT&T doesn't shut down my account.
Now that you've seen a sample of the types of SMS data that will be consumed by iOS, you should be dying to begin fuzzing this data and seeing if you can find some nice remote server-side bugs.
Generation-Based Fuzzing with Sulley
The fuzzing examples earlier in this chapter used mutation-based fuzzing. For that, legitimate data is randomly mutated and sent into the application. This is especially useful when the protocol is unknown (in which case there is no other choice) or when you have vast numbers of starting inputs from which to start. For example, when fuzzing .ppt files, it is not difficult to download thousands of these files from the Internet from which to apply the mutations. This is not the case with SMS messages. You might be able to find a handful of distinct, valid classes of SMS messages. However, this is probably not enough to do thorough fuzzing. For this particular target, you need to use a more focused method of fuzzing: generation-based fuzzing.
Generation-based fuzzing constructs the test cases from a specification and intelligently builds the inputs. You've already seen the way SMS messages are constructed. You only have to translate this knowledge into code to generate the test cases. For this, you can utilize the Sulley fuzzing framework.
Sulley allows for methods to represent exactly the kinds of data that compose SMS messages. It also provides methods for sending the data and monitoring the data. In this case, you ignore these extra capabilities and instead only utilize the test case generation capabilities of Sulley.
Much like SPIKE (www.blackhat.com/presentations/bh-usa-02/bh-us-02-aitel-spike.ppt), one of the first generation-based fuzzers, Sulley uses a block-based approach to data representation. Jump right in and see if you can represent an SMSC address using the primitives provided by Sulley. Recall that for this, the first byte is a length, followed by a type, and then the data for the address. For the first byte, you need the s_size primitive. This primitive, when not being fuzzed, will correctly hold the length of the block to which it corresponds. Thus, even with an overly long data field, the SMSC address will be syntactically correct. This is where protocol knowledge can be useful. If you were just inserting bytes at random, the program might quickly reject the SMS message as invalid because the lengths would be wrong. The s_size primitive can be called with many optional arguments. You'll need the following arguments:
- format — This is the way that the output is formatted. Possible values are string, binary, and oct. You want oct or octets. Code to handle octets was added to Sulley especially for SMS fuzzing.
- length — This is how many bytes of which this length field consists, in this case 1.
- math — This is how the length value to be output is computed from the actual length of the block. In this case, the output will be the length of text corresponding to a hexadecimal representation of some bytes. In other words, the number of bytes in this block (the value you want for this byte) is half the actual string length of the block (each “byte” is really two ASCII characters). You represent this by setting math to the value lambda x: x/2.
- fuzzable — This value tells whether this field should be fuzzed. It is useful when debugging the Sulley file to set this to False and then turn it to True when you are ready to actually fuzz.
Putting all these arguments together, you arrive at the following line for the first byte of the SMSC address:
s_size("smsc_number", format="oct", length=1, math=lambda x: x/2)
You indicate which bytes are to be included in this length calculation by putting them in a Sulley block. This block doesn't necessarily have to appear anywhere near where the corresponding s_size primitive lies. However, in this case, the block directly follows the location of the s_size. The Sulley code now looks like this:
s_size("smsc_number", format="oct", length=1, math=lambda x: x/2)
if s_block_start("smsc_number"):
...
s_block_end()
Because there can be multiple s_size primitives and blocks, you establish the connection by using the same string for the s_size and the block. Next up is the type of number. This is one byte of data and so you use the s_byte primitive. This primitive has similar optional arguments available as s_size did. You also use the name option to name the field, just to aid in the readability of the file:
s_byte(0x91, format="oct", name="typeofaddress")
The first (and only non-optional) argument is the default value of this field. Sulley works by fuzzing the first fuzzable field to be fuzzed. While it is iterating through all the values it wants to try for that field, all the other fields are untouched and remain at their default value. So, in this case, when the typeofaddress byte is not being fuzzed, it will always be 91. This has the consequence that Sulley can never find so-called 2x2 vulnerabilities, those that require two fields to be mutated at the same time.
The final field of the SMSC address is the actual phone number. You could choose to represent this as a series of s_bytes; however, the length of an s_byte is always one, even when fuzzing. If you want to allow for this field to have different lengths, you need to instead use the s_string primitive. When fuzzing, this primitive is replaced with many different strings of various sizes. There are a couple of issues with this. For one, PDU data must also consist of hexadecimal ASCII values. You communicate this to Sulley by enclosing it in a block and using the optional encoder field:
if s_block_start("SMSC_data", encoder=eight_bit_encoder):
s_string("x94x71x06x00x40x34", max_len = 256,
fuzzable=True)
s_block_end()
Here, eight_bit_encoder is a user-provided function that takes a string and returns a string. In this case, it is:
def eight_bit_encoder(string):
ret = ‘’
strlen = len(string)
for i in range(0,strlen):
temp = "%02x" % ord(string[i])
ret += temp.upper()
return ret
This function takes arbitrary strings and writes them in the desired form. The only other element that you may have noticed is the max_len option. Sulley's fuzzing library contains some strings that are extremely long, sometimes thousands of bytes long. Because the thing being fuzzed can be at most 160 bytes in length, it doesn't make sense to generate extremely long test cases. max_len indicates the maximum-length string that can be used while fuzzing.
The following is a Sulley protocol file for fuzzing all the fields of an 8-bit encoded SMS message. For more examples of Sulley SMS files, please see www.mulliner.org/security/sms/feed/bh.tar.gz. These include different encoding types, as well as examples of different UDH information elements.
def eight_bit_encoder(string):
ret = ‘’
strlen = len(string)
for i in range(0,strlen):
temp = "%02x" % ord(string[i])
ret += temp.upper()
return ret
s_initialize("query")
s_size("SMSC_number", format="oct", length=1, math=lambda x: x/2)
if s_block_start("SMSC_number"):
s_byte(0x91, format="oct", name="typeofaddress")
if s_block_start("SMSC_data", encoder=eight_bit_encoder):
s_string("x94x71x06x00x40x34", max_len =
256)
s_block_end()
s_block_end()
s_byte(0x04, format="oct", name="octetofsmsdeliver")
s_size("from_number", format="oct", length=1, math=lambda x: x-3)
if s_block_start("from_number"):
s_byte(0x91, format="oct", name="typeofaddress_from")
if s_block_start("abyte2", encoder=eight_bit_encoder):
s_string("x94x71x96x46x66x56xf8", max_len =
256)
s_block_end()
s_block_end()
s_byte(0x0, format="oct", name="tp_pid")
s_byte(0x04, format="oct", name="tp_dcs")
if s_block_start("date"):
s_byte(0x90, format="oct")
s_byte(0x10, format="oct")
s_byte(0x82, format="oct")
s_byte(0x11, format="oct")
s_byte(0x42, format="oct")
s_byte(0x15, format="oct")
s_byte(0x40, format="oct")
s_block_end()
if s_block_start("eight_bit"):
s_size("message_eight", format="oct", length=1, math=lambda x: x / 2, fuzzable=True)
if s_block_start("message_eight"):
if s_block_start("text_eight",
encoder=eight_bit_encoder):
s_string("hellohello", max_len = 256)
s_block_end()
s_block_end()
s_block_end()
fuzz_file = session_file()
fuzz_file.connect(s_get("query"))
fuzz_file.fuzz()
This will generate on the stdout more than 2000 fuzzed SMS messages:
$ python pdu_simple.py [11:08.37] current fuzz path: -> query [11:08.37] fuzzed 0 of 2128 total cases [11:08.37] fuzzing 1 of 2128 0700947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [11:08.37] fuzzing 2 of 2128 0701947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [11:08.37] fuzzing 3 of 2128 0702947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [11:08.37] fuzzing 4 of 2128 0703947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C
…
The final step is to convert this output into something that can easily be parsed by the yet to be written fuzzer. To make things slightly more general, it makes sense to allow the notion of a test case to include more than one SMS message. This will allow a test case to include not only random faults, but also test things like out-of-order arrival of concatenated SMS messages. With this in mind, you run the output of this tool through the following script that puts it in such a format:
import sys
for line in sys.stdin:
print line+"[end case]"
In this case you consider each PDU a separate test case, but this leaves open the possibility for more complex cases.
You can then generate very easily parsed files full of fuzzed test cases by running
$ python pdu_simple.py | grep –v ‘[’ | python convert.py 0700947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [end case] 0701947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [end case] 0702947106004034040D91947196466656F80004901082114215400A68656C6C6F 68656C6C6F [end case]
Note that some of these Sulley-generated PDUs may not be sendable over the real cellular network. For example, an SMSC may set the SMSC address and an attacker has no control over this value. Or, perhaps a carrier performs some sanity checking on the data it is delivering and allows only certain values of particular fields. Either way, not all the test cases you generate may be valid to send over the carrier network. Any crashes will have to be confirmed with live SMS messages over real carrier networks.
SMS iOS Injection
After you have a lot of fuzzed SMS messages, you need a way to deliver them to the iPhone for testing. Sending them from one device to another using the actual carrier network could do this. Such a procedure would involve sending the test cases from one device through the SMSC to the test device. However, this has a few major drawbacks. One is that at five cents an SMS message, this could get expensive fast. Another is that the carrier can observe the testing, and, in particular, the test cases. Additionally, the carrier may take actions that inhibit the testing such as throttling the delivery of the messages. Furthermore, it is possible the fuzzed messages could crash the telephony equipment of the carrier, which would lead to legal problems. Instead, the following is a method first described by Mulliner and Miller (www.blackhat.com/presentations/bh-usa-09/MILLER/BHUSA09-Miller-FuzzingPhone-PAPER.pdf) for iOS 3 and updated here for iOS 5. This posits that you position yourself between the modem and the application processor and inject SMS messages into the serial connection between them on a device. This method has many advantages. These include the fact the carrier is (mostly) unaware of the testing, messages can be sent at a very fast rate, it does not cost anything, and the messages appear to the application processor exactly like real SMS messages arriving over the carrier network.
On the device, the CommCenter or CommCenterClassic processes, depending on the hardware, handle SMS messages. The connection between these CommCenter processes and the modem consist of a number of virtual serial lines. They were represented by /dev/dlci.h5-baseband.[0-15] and /dev/dlci.spi-basebad.[0-15] in iOS 2 and iOS 3, respectively. In iOS 5, they take the form /dev/dlci.spi-baseband.*. The two virtual devices that are needed for SMS messages are /dev/dlci.spi-baseband.sms and /dev/dlci.spi-baseband.low.
To inject created SMS messages, you need to get into the CommCenterClassic process. You do this by injecting a library into it using library preloading. This library will provide new versions of the open(2), read(2), and write(2) functions. The new version of open checks whether the two serial lines mentioned earlier that handle SMS messages are being opened. If so, it opens a UNIX socket /tmp/fuzz3.sock or /tmp/fuzz4.sock, connects to it, and returns this file descriptor instead of one to the device requested. If the open is to some other file, the real version of open (found via dlsym) is called. The result is that for files/devices you are not concerned with, the standard open call will be made. For the two serial lines you want to impersonate, instead of opening the actual devices, a file descriptor to a UNIX socket is returned, which you can read and write to at your convenience. The read and write functions are intercepted for logging and debugging purposes, but not for SMS injection.
Then, you create a daemon process, called injectord, which opens up a connection to the two serial devices you need and also opens up one to the UNIX sockets (the virtual serial ports). The daemon then faithfully copies data read from one file descriptor to the other, playing man in the middle. Additionally, it opens up a network socket on port 4223. When it receives data on this port, it relays it to the UNIX socket. The overall effect is that when CommCenterClassic opens up these serial connections, it really opens up a UNIX socket, which most of the time will act like a connection to the modem. However, by sending data to port 4223, you can inject data and it will appear that it also came from the modem.
Once this injector is in place, given an SMS message in PDU format, the following Python function sends the data in the correct format to the daemon that injects it into the serial line. CommCenterClassic behaves as if the message arrived over the carrier network.
def send_pdu(ip_address, line):
leng = (len(line) / 2) - 8
buffer = "
+CMT: ,%d
%s
" % (leng, line)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ip_addresss, 4223))
s.send(buffer)
s.close()
This allows for a no-cost method of sending SMS messages to the device. These messages can be delivered at a very quick pace, many per second.
Monitoring SMS
You now have just about everything you need to fuzz the iOS SMS implementation. The final missing component is the monitoring. At the very least, you need to check for crashes of CommCenterClassic (and other processes). You do this by watching for Crash Reporter logs.
Before a test case is sent, the logs should be cleaned of previous problems by sshing to the device. Make sure to set up public key authentication so that no password is required from the fuzzing machine:
def clean_logs(ip):
commcenter =
‘/private/var/logs/CrashReporter/LatestCrash.plist’
springboard =
‘/private/var/mobile/Library/Logs/CrashReporter/LatestCrash.plist’
command = ‘ssh root@’+ip+’ "rm -rf %s 2>/dev/null; rm -rf
%s 2>/dev/null"’ % (commcenter, springboard)
c = os.popen(command)
SpringBoard is checked, as well as CommCenter, because during fuzzing it sometimes crashes since it actually displays the message. Notice that the logs reside on the iPhone and not on the desktop running the fuzzer, which is why it is necessary to use ssh to look for and read them. After the test case, it is necessary to check to see if anything showed up in the logs.
def check_for_crash(test_number, ip):
time.sleep(3)
commcenter =
‘/private/var/logs/CrashReporter/LatestCrash.plist’
springboard =
‘/private/var/mobile/Library/Logs/CrashReporter/LatestCrash.plist’
command = ‘ssh root@’+ip+’ "cat %s 2>/dev/null; cat %s
2>/dev/null"’ % (commcenter, springboard)
c = os.popen(command)
crash = c.read()
if crash:
clean_logs()
print "CRASH with %d" % test_number
print crash
print "
"
time.sleep(60)
else:
print ‘ . ‘,
c.close()
You could leave it at that and check for crashes. However, to be completely sure that the CommCenterClassic is still appropriately processing incoming messages, you should use a little more caution. In between each fuzzed test case, you send known good SMS messages. You can try to verify that the device successfully received these messages before continuing with further fuzzing. You do this by querying the sqlite3 database used to store SMS messages by CommCenterClassic:
# sqlite3 /private/var/mobile/Library/SMS/sms.db SQLite version 3.7.7 Enter ".help" for instructions sqlite> .tables _SqliteDatabaseProperties message group_member msg_group madrid_attachment msg_pieces madrid_chat
The madrid tables have to do with multimedia messages and contain filenames of images sent via MMS. For SMS, the most important table is called “message.” Within this table are a few interesting columns. One is an increasing integer called ROWID. Another is text, which holds the text of the message.
The following command, issued on a jailbroken iphone, displays the contents of the last SMS message received by the device:
# sqlite3 -line /private/var/mobile/Library/SMS/sms.db ‘select text from message where ROWID = (select MAX(ROWID) from message);’
Given a random number, the following Python code checks to make sure that the iPhone can still process and store standard SMS messages. It assumes that the user has established public key authentication to the ssh server running on the iOS.
def eight_bit_encoder(string):
ret = ‘’
strlen = len(string)
for i in range(0,strlen):
temp = "%02x" % ord(string[i])
ret += temp.upper()
return ret
def create_test_pdu(n):
tn = str(n)
ret = ‘0791947106004034040D91947196466656F8000690108211421540’
ret += "%02x" % len(tn)
ret += eight_bit_encoder(tn)
return ret
def get_service_check(randnum, ip):
pdu = create_test_pdu(randnum)
send_pdu(pdu)
time.sleep(1)
command = ‘ssh root@’+ip+’ "sqlite3 -line
/private/var/mobile/Library/SMS/sms.db 'select text from message
where ROWID = (select MAX(ROWID) from message);‘"’
c = os.popen(command)
last_msg = c.read()
last_msg = last_msg[last_msg.find(‘=’)+2:len(last_msg)-1]
return last_msg
The function get_service_check returns a string that contains the randnum if everything is functioning properly, or something else otherwise. All that remains is to tie it all together into the following fuzzing script:
#!/usr/bin/python2.5
import socket
import time
import os
import sys
import random
def eight_bit_encoder(string):
ret = ‘’
strlen = len(string)
for i in range(0,strlen):
temp = "%02x" % ord(string[i])
ret += temp.upper()
return ret
def create_test_pdu(n):
tn = str(n)
ret =
‘0791947106004034040D91947196466656F8000690108211421540’
ret += "%02x" % len(tn)
ret += eight_bit_encoder(tn)
return ret
def restore_service(ip):
command = ‘ssh root@’+ip+’ "./lc.sh"’
c = os.popen(command)
time.sleep(60)
def clean_logs(ip):
commcenter =
‘/private/var/logs/CrashReporter/LatestCrash.plist’
springboard =
‘/private/var/mobile/Library/Logs/CrashReporter/LatestCrash.plist’
command = ‘ssh root@’+ip+’ "rm -rf %s 2>/dev/null; rm -rf
%s 2>/dev/null"’ % (commcenter, springboard)
c = os.popen(command)
def check_for_service(ip):
times = 0
while True:
randnum = random.randrange(0, 99999999)
last_msg = get_service_check(randnum, ip)
if(last_msg == str(randnum)):
if(times == 0):
print "Passed!"
else:
print "Lost %d messages" % times
break
else:
times += 1
if(times > 500):
restore_service(ip)
break
def get_service_check(randnum, ip):
pdu = create_test_pdu(randnum)
send_pdu(pdu)
time.sleep(1)
command = ‘ssh root@’+ip+’ "sqlite3 -line
/private/var/mobile/Library/SMS/sms.db 'select text from message
where ROWID = (select MAX(ROWID) from message);‘"’
c = os.popen(command)
last_msg = c.read()
last_msg = last_msg[last_msg.find(‘=’)+2:len(last_msg)-1]
return last_msg
def check_for_crash(test_number, ip):
time.sleep(3)
commcenter =
‘/private/var/logs/CrashReporter/LatestCrash.plist’
springboard =
‘/private/var/mobile/Library/Logs/CrashReporter/LatestCrash.plist’
command = ‘ssh root@’+ip+’ "cat %s 2>/dev/null; cat %s
2>/dev/null"’ % (commcenter, springboard)
c = os.popen(command)
crash = c.read()
if crash:
clean_logs(ip)
print "CRASH with %d" % test_number
print crash
print "
"
time.sleep(60)
else:
print ‘ . ‘,
c.close()
def send_pdu(line, ip):
leng = (len(line) / 2) - 8
buffer = "
+CMT: ,%d
%s
" % (leng, line)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ip, 4223))
s.send(buffer)
s.close()
# test either sends the pdu on the line
# or checks for crash/service if test case is complete
# as indicated by the [end case] in file
def test(i, ip):
global lines
line = lines[i].rstrip()
print "%d," % i,
if line.find(‘end case’) >= 0:
check_for_crash(i, ip)
check_for_service(i, ip)
else:
send_pdu(line, ip)
time.sleep(1)
def read_testcases(filename):
global lines
f = open(filename, ‘r’)
lines = f.readlines()
f.close()
def testall(ip, filename):
global lines
read_testcases(filename)
for i in range(len(lines)):
test(i, ip)
if _name_ == ‘_main_’:
testall(sys.argv[1], sys.argv[2])
Given an IP address of an iPhone with the injector installed and a properly formatted file of test PDUs, this script will send each test case, and at the end, check for crashes and whether the program is still functioning. The advantage of having such a powerful fuzzing test harness is that you can begin fuzzing, leave it completely unmonitored, and feel confident that each test case will be executed and any crashes will be recorded along with the troublesome test case in question. Furthermore, any of this testing can be easily replicated by calling test(i) for some values of i. This is really the ultimate for SMS fuzzing in iOS. In the next section, you see some of the payoff for this attention to detail.
SMS Bugs
In smsfuzzing (http://www.blackhat.com/presentations/bh-usa-09/MILLER/BHUSA09-Miller-FuzzingPhone-PAPER.pdf), Miller and Mulliner found a variety of SMS vulnerabilities in iOS using the fuzzing methodology outlined in the preceding sections of this chapter. Some were in SpringBoard when it tried to display the invalid alert raised by the text message. This would either lock the screen if the process crashed, or possibly provide code execution in the context of SpringBoard, that is, as user mobile. Another vulnerability was found in CommCenter itself. This allowed crashing CommCenter, which knocked the phone off the network for a bit, or in some special cases, remote code execution. Back when they found their results, CommCenter used to run as root, so this allowed remote, server-side root access to any iPhone. To demonstrate what an SMS vulnerability looks like, this section briefly looks at the CommCenter vulnerability found by Miller and Mulliner.
You already saw decompilation of the code responsible for processing UDH in iOS 5. Back in iOS 3, it was slightly different (see Figure 6.9).
Figure 6.9 UDH parsing seen in IDA Pro
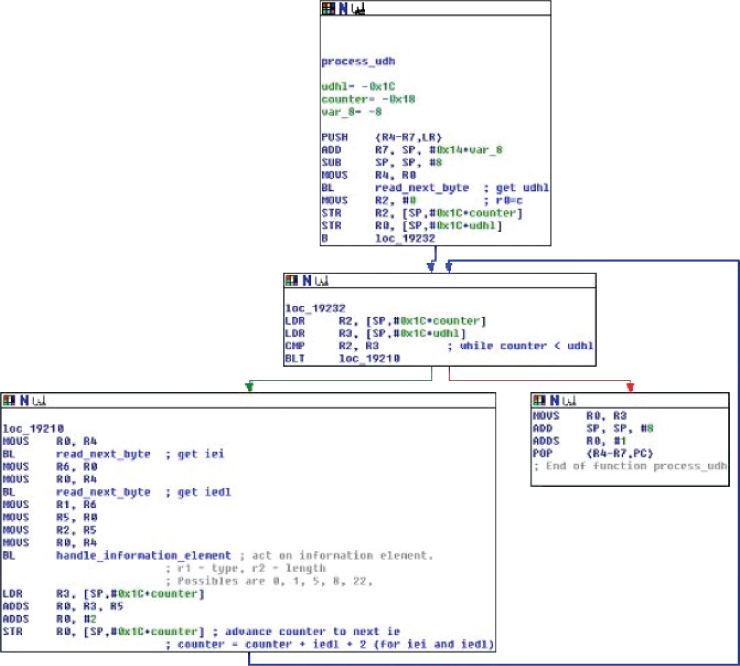
In the figure, you can see the code loop for as long as specified in the UDHL. Each time it reads an IEI and IEDL and processes the corresponding data. Later, it acts on this information. The problem comes when the UDHL is specified as longer than the actual data available. When this occurs, the read_next_byte function returns the value of -1. By itself, this is okay, but later code assumes this value will be positive and make sense. For example, you can make CommCenter call abort() and exit if you make the total message count be -1, as shown in Figure 6.10.
Figure 6.10 Code that is responsible for aborting CommCenter

If such a malformed SMS is sent and CommCenter exits with the call to abort, it will restart, but when it crashes it knocks the phone off the carrier network. This prevents incoming calls for a few seconds and also terminates any existing calls.
However, this bug is not limited only to denial of service. It can end up corrupting memory and leading to code execution. If the message is arranged such that the current message counter is -1, an array is accessed with this index. The value -1 reads a value from before the allocated buffer. This pointer is assumed to be a pointer to a C++ string, and then various methods of this pointer are called. See Figure 6.11.
Figure 6.11 Memory corruption in the iOS SMS stack

This probably isn't the only SMS bug, so please look for more. These types of vulnerabilities are especially important because they require no user interaction and cannot be blocked. They are reminiscent of computer network security 10 years ago before firewalls became prevalent.
Summary
Finding vulnerabilities in any system is hard but important work. Vulnerabilities are the foundation of all computer exploitation. Without vulnerabilities, there are no exploits or payloads or rootkits. Fuzzing is one of the easiest and most effective ways to find vulnerabilities. This chapter introduced fuzzing and showed examples of how to perform tasks such as fuzzing PDFs on Mac OS X, PPTs on the iPhone, and the SMS interface of the iPhone. It also demonstrated the power of this technique by illustrating several bugs identified.