
1.5. Terminology for XSLT
Now that we have seen some very simple XSLT stylesheets, it is important to understand the way in which both XSLT and XPath refer to their parts. For instance, while you may be familiar with “root elements,” the distinction between them and the “root” or "document root” might not be clear. Similarly, the idea of nodes and document order may be generally clear, but their precise applications deserve attention.
1.5.1. The Root of the Matter
The definition of root, shown below, supplies key concepts for working with XSLT stylesheets and other XML document instances.
root: A unique node or vertex of a graph from which every other node can be reached.
[first computer usage] Formally, a tree is a set of nodes connected by branches such that there is one and only one way of going from one node to another via branch connections, and which has a distinguished node called the root node. W. C. Gear, Introd. Computer Sci., vii. 282, 1973 (OED, 2000, XIV: 88)
This definition introduces three key components for working with XSLT: nodes, directional navigation (though, as we'll see, when using XPath we are not limited to “one and only one way of going from one node to another”), and the uniqueness of the root node. We will address each of these in turn in the following sections, beginning—naturally—with the root.
In both XML and XSLT, the distinction between the “root” and the "root element" is often confused. The simplest way to untangle these is to look at both terms separately.
Root—that from which all else comes, on which all else is predicated, and from which every other node can be reached.
The root is not an element, it is a container for the XML document. Sometimes the root is also called the document root or the root node. The reference is to the document itself—the object that contains all the elements, attributes, comments, text, and so on. The root is not a child of any other node.
Root Element—the first element in a document, also known as the document element.
The root element is the single element of which all other elements in the XML document instance are children or descendants. The root element is itself a child of the root. The root element is also known as the document element, because it is the first element in a document, and it contains all other elements in the document.[5]
[5] It is the document element that is referenced as the document type in a Doctype Declaration. For example, in <!DOCTYPE myelement SYSTEM "mydtd.dtd">, myelement is the document element.
In XSLT, the root is the XSLT stylesheet. It contains the XML declaration, <?xml version="1.0"?>, as its first child. Following that is the document element of the XSLT stylesheet, which can be either <xsl:stylesheet> or <xsl:transform>.
The XML declaration and the document element are the only direct children of the XSLT stylesheet. All other parts of an XSLT stylesheet are contained within the XSLT document element.
Because of the general confusion between the root and the root element, we will generally refer to the root element as the document element.
When an XSLT stylesheet refers to the root of the XML document instance it is processing, the symbol “/” is used. This symbol, called a token, is similar in meaning to the UNIX use, which refers to the “root” on a server. In fact, the entire syntax for referencing parts of the tree descended from the root in an XML document instance is very much like the syntax used in UNIX or MS-DOS to refer to directories and subdirectories. The / symbol and other tokens are discussed in the XPath introduction in Chapter 4.
1 5 2. Branching Out: Nodes
In XML, any point you can identify in the document's tree structure is a node. XSLT and XPath, when used effectively, permit direct access to any node in the tree. If you refer to “this paragraph,” it's a node. If you refer to “that element,” “that attribute,” and so on, they are all nodes.
The terminology of nodes is used throughout both XSLT and XPath and has crucial import in understanding and accessing each object in a document.
node: The point of a stem from which the leaves spring…a point or vertex of a network or graph. (OED, 2000, X: 459-460)
Let's reconsider the diagram of the book tree, shown again in Figure 1-5, this time with some of the nodes identified. The book, chapters, sections, and so on are all element nodes. The text contained in each topic is a text node.
Figure 1-5. Nodes in an XML tree structure.

Suppose we used attributes to distinguish between types of topics, shown in this example as the attribute “Source” with a value of “song.” This is important with the word “Xanadu,” where it can mean a mythical place enshrined in the flowing words of a Coleridge poem, a pop-music song by Olivia Newton-John, or even a whimsical name used by locals for Sun Microsystems' new campus just northwest of Boston. We could use attributes in a <topic></topic> element to mark “Xanadu” to clarify each kind of use. In this case, each attribute along with its value would comprise a node.
There are seven kinds of nodes in XSLT, but we will focus first on the element node as most common to both XML and XSLT stylesheets. The other six node types (that the designers of XSLT thought were significant) are discussed throughout the remainer of this book.
The nodes extending from, or “under,” a chapter would be a set of nodes that is best understood as a node branch. A node branch is any logical structure consisting of a node and its descendants, sometimes referred to as a subtree. A little “pruning” of our tree terminology is implied by the notion of nodes and node branches. You will find that XML terminology does not include “leaves” or “branches.” Nodes and node branches are the closest correlations to these concepts.
Consider again the diagram of a book, shown in Figure 1-6, this time with some of its parts also identified in terms of a node branch.
Figure 1-6. Nodes and node branches in an XML tree.
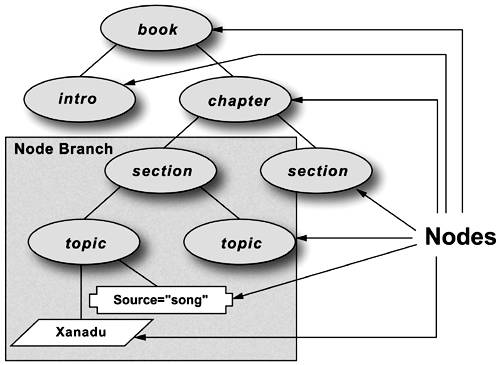
You would use XSLT and XPath to access any one of these nodes or a combination of them, as well as other types of nodes not shown here. The nodes descended from and including the “section” on the far left are a node branch.
Node-sets, on the other hand, are described in the XPath specification as “an unordered collection of nodes without duplicates.” They are the set of nodes returned by an expression (discussed in Chapter 3), regardless of the location of the nodes in the tree or branch of the XML instance. For example, the set of two section elements can comprise a node-set.
1.5.3. Document Order
The concept of document order might seem self-evident, but it is an important concept because the process and order by which nodes are evaluated depend on it. In essence, document order is the order of nodes as they are encountered while traversing the document as it would be read left-to-right and top-to-bottom.
The elements in our <year> example, in document order, would be: <year>, <planting>, the <season> with the period attribute with a value of spring, then the <month> elements in the first <season>—March, April, May—followed by the <season> with the period attribute with a value of summer and its <month> contents, and so on. In other words, document order is what you would expect as the order according to the direction, or sequence, in which the data is read.
Sometimes, a sequence of “reverse document order” can be stipulated, which means, as you would expect, the opposite of the order in which the content would be read at the node level. The reversing of document order occurs based on a starting node. If, in the example above, an expression referred to the second <month> starting from July, in reverse document order, it would be referring to the <month> node that contained the string June. It would not, for instance, be referring to "enuJ", or the string value being read in reverse. The first element in document order is the starting element, in this case, the <month> containing July, so the second element in reverse document order is the <month> containing June.
The document order of nodes is based on the tree hierarchy of the XML instance. The first node, then, would be the root node, or document root. Element nodes are ordered prior to their children, so the first element node would be the document element (<year> in our example), followed by its children. Nodes are selected in document order based on their starting tag, or opening tag. Children nodes are processed prior to sibling nodes, and closing tags, or end tags, are implicitly ignored. Attribute and namespace nodes of a given element are ordered prior to the children of the element. This can be more readily seen in Figure 1-7, which shows the document order for the nodes from our <year> (with a few extras thrown in to demonstrate their position).
Figure 1-7. Document order using six node types.

The root node
The document element <year>
The attribute for the iowa namespace declaration
The element node <planting>
The element node <season>
The iowa namespace node
The period attribute with a value of "Spring"
The element node <month>
The March text node
The element node <month>
The April text node
The element node <month>
The May text node
The element node <season>
The iowa namespace node
The period attribute with a value of "Summer"
The element node <month>
The June text node
The element node <month>
The July text node
The element node <month>
The August text node
The comment node
Figure 1-7 displays the document order for six of the seven node types, the seventh being the processing-instruction node, which is not included in this example.
The only other possible order for the above nodes is the exact reverse, if specified in an expression as reverse document order. However, there is a mechanism in XSLT that will allow the sorting of nodes, which would then change the order of the nodes to something other than document order. Sorting will be addressed further in Chapter 9.