


LDAP concepts and architecture
LDAP is based on the client/server model of distributed computing. The success of LDAP has been largely due to the following characteristics that make it simpler to implement and use, compared to X.500 and DAP.
This chapter explains the basic architecture of LDAP. It discusses the information, naming, functional, and security models that form the basis of the LDAP architecture. Various terms and concepts defined by or needed to understand the LDAP architecture are introduced along the way. After a general overview of the architecture, each of the models that form the backbone of the LDAP architecture is discussed in detail.
2.1 Overview of LDAP architecture
LDAP defines the content of messages exchanged between an LDAP client and an LDAP server. The messages specify the operations requested by the client (that is, search, modify, and delete), the responses from the server, and the format of data carried in the messages. LDAP messages are carried over TCP/IP, a connection-oriented protocol, so there are also operations to establish and disconnect a session between the client and server.
However, for the designer of an LDAP directory, it is not so much the structure of the messages being sent and received over the wire that is of interest. What is important is the logical model that is defined by these messages and data types, how the directory is organized, what operations are possible, how information is protected, and so forth.
The general interaction between an LDAP client and an LDAP server takes the following form:
1. The client establishes a session with an LDAP server. This is known as binding to the server. The client specifies the host name or IP address and TCP/IP port number where the LDAP server is listening.
2. The client can provide a user name and a password to properly authenticate with the server, or the client can establish an anonymous session with default access rights. The client and server can also establish a session that uses stronger security methods such as encryption of data.
3. The client then performs operations on directory data. LDAP offers both read and update capabilities. This allows directory information to be managed as well as queried. LDAP also supports searching the directory for data meeting arbitrary user-specified criteria. Searching is a very common operation in LDAP. A user can specify what part of the directory to search and what information to return. A search filter that uses Boolean conditions specifies what directory data matches the search.
4. When the client is finished making requests, it closes the session with the server. This is also known as unbinding.
The philosophy of the LDAP API is to keep simple things simple. This means that adding directory support to existing applications can be done with low overhead. Because LDAP was originally intended as a lightweight alternative to DAP for accessing X.500 directories, it follows a X.500 model. The directory stores and organizes data structures known as entries. A directory entry usually describes an object such as a person, device, a location, and so on. Each entry has a name called a distinguished name (DN) that uniquely identifies it. The DN consists of a sequence of parts called relative distinguished names (RDNs), much like a file name consists of a path of directory names in many operating systems such as UNIX® and Windows. The entries can be arranged into a hierarchical tree-like structure based on their distinguished names. This tree of directory entries is called the Directory Information Tree (DIT).
Each entry contains one or more attributes that describe the entry. Each attribute has a type and a value. For example, the directory entry for a person might have an attribute called telephoneNumber. The syntax of the telephoneNumber attribute would specify that a telephone number must be a string of numbers that can contain spaces and hyphens. The value of the attribute would be the person’s telephone number, such as 512-555-1212.
A directory entry describes some object. An object class is a general description, sometimes called a template, of an object, as opposed to the description of a particular object. For instance, the object class person has a surname attribute, whereas the object describing John Smith has a surname attribute with the value Smith. The object classes that a directory server can store and the attributes they contain are described by schema. Schema define what object classes are allowed where in the directory, what attributes they must contain, what attributes are optional, and the syntax of each attribute. For example, a schema could define a person object class. The person schema might require that a person have a surname attribute that is a character string, specify that a person entry can optionally have a telephoneNumber attribute that is a string of numbers with spaces and hyphens, and so on.
LDAP defines operations for accessing and modifying directory entries such as:
•Binding and unbinding
•Searching for entries meeting user-specified criteria
•Adding an entry
•Deleting an entry
•Modifying an entry
•Modifying the distinguished name or relative distinguished name of an entry (move)
•Comparing an entry
The version of LDAP all modern directory servers use today is LDAPv3. LDAPv3 is documented in several IETF RFCs. The key LDAP Version 3 RFCs are listed below along with a short description to provide an overview of the documents defining the LDAP architecture.
•RFC 2251 Lightweight Directory Access Protocol (v3)
Describes the LDAP protocol designed to provide lightweight access to directories supporting the X.500 model. The lightweight protocol is meant to be implementable in resource-constrained environments such as browsers and small desktop systems.
This RFC is the core of the LDAP family of RFCs. It describes how entries are named with distinguished names, defines the format of messages exchanged between client and server, enumerates the operations that can be performed by the client, and specifies that data is represented using UTF-8 character encoding. The RFC specifies that the schema describing directory entries must themselves be readable so that a client can determine what type of objects a directory server stores. It defines how the client can be referred to another LDAP server if a server does not contain the requested information. It describes how individual operations can be extended using controls and how additional operations can be defined using extensions. It also discusses how clients can authenticate to servers and optionally use Simple Authentication and Security Layer (SASL) to allow additional authentication mechanisms.
•RFC 2252 Lightweight Directory Access Protocol (v3): Attribute Syntax Definitions
LDAP uses octet strings to represent the values of attributes for transmission in the LDAP protocol. This RFC defines how values such as integers, time stamps, mail addresses, and so on are represented. For example, the integer 123 is represented by the string "123". These definitions are called attribute syntaxes. This RFC describes how an attribute with a syntax such as “telephone number” is encoded. It also defines matching rules to determine if values meet search criteria. An example is caseIgnoreString, which is used to compare character strings when case is not important.
These attribute types and syntaxes are used to build schema that describe objects classes. A schema lists what attributes a directory entry must or may have. Every directory entry has an objectclass attribute that lists the (one or more) schema that describe the entry. For example, a directory entry could be described by the object classes inetOrgPerson and organizationalPerson. If an objectclass attribute includes the value extensibleObject, it can contain any attribute.
•RFC 2253 Lightweight Directory Access Protocol (v3): UTF-8 String Representation of Distinguished Names
Distinguished names (DNs) are the unique identifiers, sometimes called primary keys, of directory entries. X.500 uses ASN.1 to encode distinguished names. LDAP encodes distinguished names as strings. This RFC defines how distinguished names are represented as strings. A string representation is easy to encode and decode and is also human readable. A DN is composed of a sequence of relative distinguished names (RDNs) separated by commas. The sequence of RDNs making up a DN names the ancestors of a directory entry up to the root of the DIT. Each RDN is composed of an attribute value from the directory entry. For example, the DN cn=John Smith,ou=Austin,o=IBM,c=US represents a directory entry for a person with the common name (cn) John Smith under the organizational unit (ou) Austin in the organization (o) IBM in the country (c) US.
•RFC 2254 The String Representation of LDAP Search Filters
LDAP search filters provide a powerful mechanism to search a directory for entries that match specific criteria. The LDAP protocol defines the network representation of a search filter. This document defines how to represent a search filter as a human-readable string. Such a representation can be used by applications or in program source code to specify search criteria. Attribute values are compared using relational operators such as equal, greater than, or “sounds like” for approximate or phonetic matching. Boolean operators can be used to build more complex search filters. For example, the following search filter searches for entries that either have a surname attribute of Smith or that have a common name attribute that begins with Jo:
(| (sn=Smith) (cn=Jo*))
•RFC 2255 The LDAP URL Format
Uniform Resource Locators (URLs) are used to identify Web pages, files, and other resources on the Internet. An LDAP URL specifies an LDAP search to be performed at a particular LDAP server. An LDAP URL represents in a compact and standard way the information returned as the result of the search. The LDAP URL Format is discussed in more detail later in this chapter.
•RFC 2256 A Summary of the X.500(96) User Schema for use with LDAPv3
Many schema and attributes commonly accessed by directory clients are already defined by X.500. This RFC provides an overview of those attribute types and object classes that LDAP servers should recognize. For instance, attributes such as cn (common name), description, and postalAddress are defined. Object classes such as country, organizationalUnit, groupOfNames, and applicationEntity are also defined.
The RFCs listed above build up the core LDAP Version 3 specification. LDAP can be better understood by considering the four models upon which it is based:
•Information: Describes the structure of information stored in an LDAP directory
•Naming: Describes how information in an LDAP directory is organized and identified
•Functional: Describes what operations can be performed on the information stored in an LDAP directory
•Security: Describes how the information in an LDAP directory can be protected from unauthorized access
The following sections discuss the four LDAP models.
2.2 The informational model
The basic unit of information stored in the directory is called an entry. Entries represent objects of interest in the real world such as people, servers, organizations, and so on. Entries are composed of a collection of attributes that contain information about the object. Every attribute has a type and one or more values. The type of the attribute is associated with a syntax. The syntax specifies what kind of values can be stored. For example, an entry might have a attribute. The syntax associated with this type of attribute would specify that the values are telephone numbers represented as printable strings optionally followed by keywords describing paper size and resolution characteristics. It is possible that the directory entry for an organization would contain multiple values in this attribute—that is, that an organization or person represented by the entity would have multiple fax numbers. The relationship between a directory entry and its attributes and their values is shown in Figure 2-1.

Figure 2-1 Entries, attributes and values
In addition to defining what data can be stored as the value of an attribute, an attribute syntax also defines how those values behave during searches and other directory operations. The attribute telephoneNumber, for example, has a syntax that specifies:
•Lexicographic ordering.
•Case, spaces and dashes are ignored during the comparisons.
•Values must be character strings.
For example, using the correct definitions, the telephone numbers 512-838-6008, 512838-6008, and 5128386008 are considered the same. A few of the syntaxes that have been defined for LDAP are listed in Table 2-1.
Table 2-1 Some of the attribute syntaxes
|
Syntax
|
Description
|
|
bin
|
Binary information
|
|
ces
|
Case exact string, also known as a directory string, case is significant during comparisons.
|
|
cis
|
Case ignore string. Case is not significant during comparisons.
|
|
tel
|
Telephone number. The numbers are treated as text, but all blanks and dashes are ignored.
|
|
dn
|
Distinguished name.
|
|
Generalized Time
|
Year, month, day, and time represented as a printable string.
|
|
Postal Address
|
Postal address with lines separated by "$" characters.
|
Table 2-2 lists some common attributes. Some attributes have alias names that can be used wherever the full attribute name is used. For example, cn can be used when referring to the attribute commonName.
Table 2-2 Common LDAP attributes
|
Attribute, Alias
|
Syntax
|
Description
|
Example
|
|
commonName, cn
|
cis
|
Common name of an entry
|
John Smith
|
|
surname, sn
|
cis
|
Surname (last name) of a person
|
Smith
|
|
telephoneNumber
|
tel
|
Telephone number
|
512-838-6008
|
|
organizationalUnitName, ou
|
cis
|
name of organizational unit
|
Tivoli
|
|
owner
|
dn
|
DN of person that owns the entry
|
cn=John Smith,o=IBM,c=us
|
|
organization, o
|
cis
|
Name of organization
|
IBM
|
|
jpegPhoto
|
bin
|
Photographic image in JPEG format
|
Photograph of John Smith
|
Constraints can be associated with attribute types to limit the number of values that can be stored in the attribute or to limit the total size of a value. For example, an attribute that contains a photo could be limited to a size of 10 KB to prevent the use of unreasonable amounts of storage space. Or an attribute used to store a social security number could be limited to holding a single value.
Schemas define the type of objects that can be stored in the directory. Schemas also list the attributes of each object type and whether these attributes are required or optional. For example, in the person schema, the attribute surname (sn) is required, but the attribute description is optional. Schema-checking ensures that all required attributes for an entry are present before an entry is stored. Schema-checking also ensures that attributes not in the schema are not stored in the entry. Optional attributes can be filled in at any time. Schema also define the inheritance and subclassing of objects and where in the DIT structure (hierarchy) objects may appear.
Table 2-3 lists a few of the common schema (object classes and their required attributes). In many cases, an entry can consist of more than one object class.
Table 2-3 Object classes and required attributes
|
Object class
|
Description
|
Required attributes
|
|
InetOrgPerson
|
Defines entries for a person
|
commonName (cn)
surname (sn)
objectClass
|
|
organizationalUnit
|
Defines entries for organizational units
|
ou
objectClass
|
|
organization
|
Defines entries for organizations
|
o
objectClass
|
Though each server can define its own schema, for interoperability it is expected that many common schema will be standardized (refer to RFC 2252, Lightweight Directory Access Protocol (v3): Attribute Syntax Definitions, and RFC 2256, A Summary of the X.500(96) User Schema for use with LDAPv3).
There are times when new schema will be needed at a particular server or within an organization. In LDAP Version 3, a server is required to return information about itself, including the schema that it uses. A program can therefore query a server to determine the contents of the schema. This server information is stored at the special zero-length DN.
Objects can be derived from other objects. This is known as subclassing. For example, suppose an object called person was defined that included an attribute surname and so on. An object class organizationalPerson could be defined as a subclass of the person object class. The organizationPerson object class would have the same attributes as the person object class and could add other attributes such as title and officenumber. The person object class would be called the superior of the organizationPerson object class. One special object class, called top, has no superiors. The top object class includes the mandatory objectClass attribute. Attributes in top appear in all directory entries as specified (required or optional).
Each directory entry has a special attribute called objectClass. The value of the objectClass attribute is a list of two or more schema names. These schema define what type of object(s) the entry represents. One of the values must be either top or alias. Alias is used if the entry is an alias for another entry, otherwise top is used. The objectClass attribute determines what attributes the entry must and may have.
The special object class extensibleObject allows any attribute to be stored in the entry. This can be more convenient than defining a new object class to add a special attribute to a few entries, but also opens up that object to be able to contain anything (which might not be a good thing in a structured system).
2.2.1 LDIF
When an LDAP directory is loaded for the first time or when many entries have to be changed at once, it is not very convenient to change every single entry on a one-by-one basis. For this purpose, LDAP supports the LDAP Data Interchange Format (LDIF) that can be seen as a convenient, yet necessary, data management mechanism. It enables easy manipulation of mass amounts of data. See Example 2-1 for the basic form of an LDIF entry.
Example 2-1 Basic form of an LDIF entry
dn: <distinguished name>
<attrtype> : <attrvalue>
<attrtype> : <attrvalue>
...
A line can be continued by starting the next line with a single space or tab character, for example:
dn: cn=John E Doe, o=University of Higher
Learning, c=US
Multiple attribute values are specified on separate lines, for example:
cn: John E Doe
cn: John Doe
If an attrvalue contains a non-US-ASCII character, or begins with a space or a colon (:), the attrtype is followed by a double colon and the value is encoded in base-64 notation. For example, the value "begins with a space" would be encoded like this:
cn:: IGJlZ2lucyB3aXRoIGEgc3BhY2U=
Multiple entries within the same LDIF file are separated by a blank line. Multiple blank lines are considered a logical end-of-file.
Example 2-2 shows a simple LDIF file which contains an organizational unit, People, located beneath the organization ibm.com in the DIT. The entry of John Smith is the only data entry for People. Further on, there is an organizational unit called marketing. Note that John Smith is a member of the marketing department due to the attribute value pair ou: marketing.
Example 2-2 Example LDIF File with organizational and person entries
dn: o=ibm.com
objectclass: top
objectclass: organization
o: ibm.com
dn: ou=People, o=ibm.com
objectclass: organizationalUnit
ou: people
dn: ou=marketing, o=ibm.com
objectclass: organizationalUnit
ou: marketing
dn: cn=John Smith, ou=people, o=ibm.com
objectclass: top
objectclass: organizationalPerson
cn: John Smith
sn: Smith
givenname: John
uid: jsmith
ou: marketing
ou: people
telephonenumber: 838-6004
2.2.2 LDAP schema
In this section we discuss LDAP schema.
Objectclasses
An object class is an LDAP term that denotes the type of object being represented by a directory entry or record. Some typical object types are person, organization, organizational unit, domain component and groupOfNames. There are also object classes that define an object's relationship to other objects, such as object class top denotes that the object may have subordinate objects under it in a hierarchical tree structure. Note that some LDAP object classes may be combined, for example, an object class of organizational unit will most often also be simultaneously defined as a top object class because it will have entries beneath it.
An object class is declared as abstract, structural, or auxiliary. An abstract object class is used as a template for creating other object classes. A directory entry cannot be instantiated from an abstract object class. Directory entries are instantiated from structural object classes. An auxiliary object class cannot be instantiated by itself as a directory entry; it can be attached to directory entries that are instantiated from structural object classes. Auxiliary object classes provide a method for extending structural object classes without having to change the schema definition of a structural class.
LDAP object classes defined sets of standard attributes that are listed as must contain (mandatory attributes) and may contain (optional attributes). Different object classes may prescribe some attributes that overlap, or are redundant with other object classes. And it is common practice in LDAP directories to use multiple object classes to define a single directory entry. Most object classes are defined in a hierarchical order, where one object class is said to "inherit" from another superior object class. Consider an LDAP object that is defined with the object classes, as shown in Example 2-3.
Example 2-3 LDAP object definition
objectclass: top
objectclass: person
objectclass: organizationalPerson
objectclass: inetOrgPerson
objectclass: eDominoAccount
The order shown for the object classes above indicates a hierarchical relationship between these object classes, but not necessarily. The top objectclass is of course at the top of the hierarchy. Most other objectclasses that are not intended to be subordinate to another class should have top as its superior. Not all LDAP directories expect a user record to have the top object class assigned to it, while others require it for using Access Control Lists (ACLs) on the object. The person class is subordinate to the top class and requires that the cn (Common Name) and sn (Surname) attributes be populated, and allows several other optional attributes. The organizationalPerson class inherits from the person class. The inetOrgPerson class inherits from the organizationalPerson class. Now here is the tricky part: The eDominoAccount object class is subordinate to the top class and requires that the sn and userid attributes be populated. Notice that this overlaps with the person object class requirement for the sn attribute. Does this mean that we need to store the sn attribute twice? No, because it is a standard attribute. We will talk more about attributes a little later in this section. Example 2-3 on page 37 illustrates that you cannot necessarily tell the hierarchical relationship of object classes by the order they appear in a list. So then, how do we tell? We tell (or in reality, your LDAP directory interface shows you) by looking at the object class definitions themselves. The methods for defining object classes for LDAP V3 are described in RFC-2251 and RFC-2252. Example 2-4 shows object class definitions taken from ITDS.
Example 2-4 Some ITDS object class definitions
objectclass: top
objectclasses=( 2.5.6.0 NAME 'top' DESC 'Standard ObjectClass' ABSTRACT MUST ( objectClass ) )
objectclass: person
objectclasses=( 2.5.6.6 NAME 'person' DESC 'Defines entries that generically represent people.' SUP 'top' STRUCTURAL MUST ( cn $ sn ) MAY ( userPassword $ telephoneNumber $ seeAlso $ description ) )
objectclass: organizationalPerson
objectclasses=( 2.5.6.7 NAME 'organizationalPerson' DESC 'Defines entries for people employed by or associated with an organization.' SUP 'person' STRUCTURAL MAY ( title $ x121Address $ registeredAddress $ destinationIndicator $ preferredDeliveryMethod $ telexNumber $ teletexTerminalIdentifier $ internationalISDNNumber $ facsimileTelephoneNumber $ street $ postalAddress $ postalCode $ postOfficeBox $ physicalDeliveryOfficeName $ ou $ st $ l ) )
objectclass: inetOrgPerson
objectclasses=( 2.16.840.1.113730.3.2.2 NAME 'inetOrgPerson' DESC 'Defines entries representing people in an organizations enterprise network.' SUP 'organizationalPerson' STRUCTURAL MAY ( audio $ businessCategory $ carLicense $ departmentNumber $ employeeNumber $ employeeType $ givenName $ homePhone $ homePostalAddress $ initials $ jpegPhoto $ labeledURI $ mail $ manager $ mobile $ pager $ photo $ preferredLanguage $ roomNumber $ secretary $ uid $ userCertificate $ userSMIMECertificate $ x500UniqueIdentifier $ displayName $ o $ userPKCS12 ) )
Note that each object class begins with a string of numbers delimited by decimals. This number is referred to as the OID (object identifier). After the OID is the object class name (NAME) followed by a description (DESC). If it is subordinate to another object class, the superior (SUP) object class is listed. Finally, the object class definition specifies what attributes are mandatory (MUST) and which are optional (MAY).
The OID is a numeric string that is used to uniquely identify an object. OIDs are a managed hierarchy administered by the International Organization for Standardization (ISO - Web site http://www.iso.ch/) and the International Telecommunication Union (ITU - Web site http://www.itu.ch/). ISO and ITU delegate OID management to organizations by assigning them OID numbers. Organizations can then assign OIDs to objects or further delegate to other organizations. OIDs are associated with objects in protocols and data structures defined using Abstract Syntax Notation (ASN.1).
OIDs are intended to be globally unique. They are formed by taking a unique numeric string (for example, 1.3.4.7.4.17) and adding additional digits in a unique fashion (such as 1.3.4.7.4.17.1, 1.3.4.7.4.17.2, 1.3.4.7.4.17.3, etc.) An organization may acquire a "branch" from some root or vertex in the OID tree. Such a branch is more commonly referred to as an arc (in the previous example it was 1.3.4.7.4.17). The organization may then extend the arc (called subarcs) as shown above to create additional OIDs and arcs. We have no idea why the terminology for the OID tree uses the words "vertex" and "arc" instead of "root" and "branch" as is more commonly used in LDAP and its X.500 heritage.
If you have an LDAP directory that is a derivative of the original University of Michigan LDAP code (many open source and commercial LDAP directory servers are), your object class definitions are contained in files ending with ".oc".
Note that IBM-specific OIDs begin with the arc 1.3.18.0.2; this is a unique private enterprise number that has been assigned to IBM. The number breaks down as shown in Example 2-5.
Example 2-5 IBM-specific OIDs
1 (ISO-assigned OID)
1.3 (ISO-identified organization)
1.3.18 (IBM)
1.3.18.0 (IBM Objects)
1.3.18.0.2 (IBM Distributed Directory)
As you may have guessed, the "dot notation" as first used by the IETF for IP addresses was adopted to OIDs to keep things simple. However, unlike IP addresses, there is no limit to the length of an OID.
If your organization must define your own attributes for use within your internal directories, you should consider obtaining your own private enterprise number arc to identify these attributes. We do not recommend that you "make up" your own numbers, as you will probably not be able to interoperate with other organizations (or some vendor's LDAP products). This is not to say obtaining your own OID arc from ISO, IANA or some other authority to define your own object classes and attributes will guarantee interoperability. But it will prevent you from using OIDs that have already been assigned to or by someone else. OIDs are only used for "equality-matching". That is, two objects (for example, directory attributes or certificate policies) are considered to be the same if they have exactly the same OID. There are no implied navigational or hierarchical capabilities with OIDs (unlike IP addresses, for example); given an OID one can not readily find out who owns the OID, related OIDs, etc. OIDs exist to provide a unique identifier. There is nothing to stop two organizations from picking the same identical names for objects that they manage, however, the OIDs will be unique assuming they were assigned from legitimate arc numbers. If you are interested in obtaining a private enterprise number (arc) for your own organization, you may apply for one (free of charge) at the Internet Assigned Numbers Authority Web site:
For more information regarding OIDs, the trees of assigned numbers, and registration, we recommend starting at the ASN.1 frequently asked questions Web site at:
Let us look at the following example: Top is an abstract class that contains the objectClass attribute. Person is a structural class that instantiates the directory entry for a given person where the objectClass attribute is also part of that Person entry. So far, this example has used only attributes and object classes defined in a standard. So, now, you may want to tailor the people entries to include information that your company requires and that is not defined in the standard Person object definition. There are two ways to do this:
•Subclass the Person object to create a new structural class that includes those additional attributes defined by your company, and instantiate the Person directory entry based on that new class.
•Define that collection of company attributes needed for your company’s Person definition as an auxiliary class, and attach it to the directory entry instantiated from the Person class.
Either method is recommended. The downside to auxiliary classes is that if the auxiliary class includes an attribute that is also included in the structural class definition, when that attribute is included in the instantiated directory entry and that attribute contains multiple values and you want to delete the attribute, you cannot tell whether the attribute (when added to the entry) was added when the structural class was instantiated or when the auxiliary class was instantiated. This may be important to the implementor or administrator.
Special entries exist in the namespace, called aliases. Aliases represent links to other entries or partitions of the namespace. When the distinguished name of an alias is used, the entry accessed is the entry to which the alias refers (unless specified otherwise through the programming interface). The collection of directory entries forms the Directory Information Tree (DIT). The method of storage for the DIT of the LDAP directory is implementation-dependent and hidden from the user of that LDAP directory. For example, the ITDS uses IBM DB2 as its data store, but no DB2 constructs are externalized to LDAP.
Attributes
All the object class does is define the attributes, or types of data items contained in that type of object. Some examples of typical attributes are cn (common name), sn (surname), givenName, mail, uid, and userPassword. Just as the object classes are defined with unique OIDs, each attribute also has a unique OID number assigned to it. LDAP V3 attributes follow a notation similar (ASN.1) to object classes. Example 2-6 shows some attribute definitions.
Example 2-6 Attribute definitions
attribute: name
attributetypes=( 2.5.4.41 NAME 'name' DESC 'The name attribute type is the attribute supertype from which string attribute types typically used for naming may be formed. It is unlikely that values of this type itself will occur in an entry.' EQUALITY 1.3.6.1.4.1.1466.109.114.2 SUBSTR 2.5.13.4 SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 USAGE userApplications )
attribute: sn
attributetypes=( 2.5.4.4 NAME ( 'sn' 'surName' ) DESC 'This is the X.500 surname attribute, which contains the family name of a person.' SUP 2.5.4.41 EQUALITY 2.5.13.2 ORDERING 2.5.13.3 SUBSTR 2.5.13.4 USAGE userApplications )
attribute: mail
attributetypes=( 0.9.2342.19200300.100.1.3 NAME ( 'mail' 'rfc822mailbox' ) DESC 'Identifies a users primary email address (the email address retrieved and displayed by white-pages lookup applications).' EQUALITY 2.5.13.2 SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 USAGE userApplication)
Notice in Example 2-6 on page 41 that the superior (SUP) of sn is the attribute 2.5.4.41, which happens to be the name attribute. But then the name attribute description says unlikely that values of this type itself will occur.... This illustrates just one of the many peculiarities of the way the attributes have been defined. It merely provides a shorthand way to defining name-like attributes such as surname. We did not need to define the syntax for sn because it inherits this from name.
The attribute mail also has an alias of rfc822mailbox. As you may have guessed, the "EQUALITY" and "SYNTAX" are yet more ASN.1 definitions.
2.3 The naming model
The LDAP naming model defines how entries are identified and organized. Entries are organized in a tree-like structure called the Directory Information Tree (DIT). Entries are arranged within the DIT based on their distinguished name (DN). A DN is a unique name that unambiguously identifies a single entry. DNs are made up of a sequence of relative distinguished names (RDNs).
Each RDN in a DN corresponds to a branch in the DIT leading from the root of the DIT to the directory entry. Each RDN is derived from the attributes of the directory entry. In the simple and common case, an RDN has the form <attribute name> = <value>. A DN is composed of a sequence of RDNs separated by commas.
An example of a DIT is shown in Figure 2-2 on page 43. The example is very simple, but can be used to illustrate some basic concepts. Each box represents a directory entry. The root directory entry is conceptual, but does not actually exist.
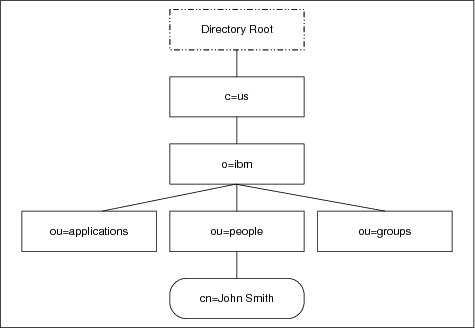
Figure 2-2 Example of a Directory Information Tree (DIT)
The organization of the entries in the DIT is restricted by their corresponding object class definitions.
Entries are named according to their position in the DIT. The directory entry at the bottom of the figure has the DN of cn=John Smith,ou=people,o=ibm,c=us. The organizational group people has the DN of ou=people,o=ibm,c=us.
2.3.1 LDAP distinguished name syntax (DNs)
Entries in an LDAP directory are identified by their names. The characteristics of these names are:
•They have two forms: A string representation and a URL.
•They have a uniform syntax.
•Namespace boundaries are not apparent in them.
A component of a name is called a relative distinguished name (RDN). An RDN represents a point within the namespace hierarchy. RDNs are separated by and concatenated using a comma (,). Each RDN is typed. RDNs have the form type=value for single valued RDNs. The plus sign (+) is used to form multi-valued RDNs: type=value+type=value.
The type is case-insensitive and the value is defined to have a particular syntax. The order of RDNs in an LDAP name is the most specific RDN first followed by the less specific RDNs moving up the DIT hierarchy. A concatenated series of RDNs equates to a distinguished name. The DN is used to represent an object and the path to the object in the hierarchical namespace. A URL format for LDAP has been defined that includes a DN as a component of the URL. These forms are explained in the sections that follow.
Every entry in the directory has a DN. The DN is the name that uniquely identifies an entry in the directory. A DN is made up of attribute=value pairs, separated by commas, for example:
cn=Roger Smith,ou=sales,o=ib,c=US
cn=Sandy Brown,ou=marketing,o=ibm,c=US
cn=Leslie Jones,ou=development,o=ibm,c=US
Any of the attributes defined in the directory schema may be used to make up a DN. The order of the component attribute value pairs is important. The DN contains one component for each level of the directory hierarchy from the root down to the level where the entry resides. LDAP DNs begin with the most specific attribute (usually some sort of name), and continue with progressively broader attributes, often ending with a country attribute. The first component of the DN is referred to as the Relative Distinguished Name (RDN). It identifies an entry distinctly from any other entries that have the same parent. In the examples above, the RDN cn=Roger Smith separates the first entry from the second entry, (with RDN cn=Sandy Brown). These two example DNs are otherwise equivalent. The attribute:value pair making up the RDN for an entry must also be present in the entry. (This is not true of the other components of the DN.)
The Distinguished Name (DN) syntax supported by this server is based on RFC 2253. The Backus-Naur Form (BNF) syntax is shown in Example 2-7.
Example 2-7 DN syntax
<name> ::= <name-component> ( <spaced-separator> )
| <name-component> <spaced-separator> <name>
<spaced-separator> ::= <optional-space>
<separator>
<optional-space>
<separator> ::= "," | ";"
<optional-space> ::= ( <CR> ) *( " " )
<name-component> ::= <attribute>
| <attribute> <optional-space> "+"
<optional-space> <name-component>
<attribute> ::= <string>
| <key> <optional-space> "=" <optional-space> <string>
<key> ::= 1*( <keychar> ) | "OID." <oid> | "oid." <oid>
<keychar> ::= letters, numbers, and space
<oid> ::= <digitstring> | <digitstring> "." <oid>
<digitstring> ::= 1*<digit>
<digit> ::= digits 0-9
<string> ::= *( <stringchar> | <pair> )
| '"' *( <stringchar> | <special> | <pair> ) '"'
| "#" <hex>
<special> ::= "," | "=" | <CR> | "+" | "<" | ">"
| "#" | ";"
<pair> ::= "" ( <special> | "" | '"')
<stringchar> ::= any character except <special> or "" or '"'
<hex> ::= 2*<hexchar>
<hexchar> ::= 0-9, a-f, A-F
A semicolon (;) character can be used to separate RDNs in a distinguished name, although the comma (,) character is the typical notation.
White-space characters (spaces) might be present on either side of the comma or semicolon. The white-space characters are ignored, and the semicolon is replaced with a comma.
In addition, space (' ' ASCII 32) characters may be present either before or after a '+' or '='. These space characters are ignored when parsing.
A value may be surrounded by double quotation ('"' ACSII 34) characters, which are not part of the value. Inside the quoted value, the following characters can occur without being interpreted as escape characters:
A space or "#" character occurring at the beginning of the string
A space character occurring at the end of the string
One of the characters "'", "=", "+", "", "<", ">", or ";"
Alternatively, a single character to be escaped may be prefixed by a backslash ('' ASCII 92). This method can be used to escape any of the characters listed previously and the double quotation marks ('"' ASCII 34) character.
This notation is designed to be convenient for common forms of names. The following example is a distinguished name written using this notation. First is a name containing three components. The first of the components is a multi valued RDN. A multivalued RDN contains more than one attribute:value pair and can be used to distinctly identify a specific entry in cases where a simple CN value might be ambiguous:
OU=Sales+CN=J. Smith,O=Widget Inc.,C=US
2.3.2 String form
The exact syntax for names is defined in RFC 2253. Rather than duplicating the RFC text, the following are examples of valid distinguished names written in string form:
•cn=Leslie Smith, ou=Austin, o=IBM
This is a name containing three relative distinguished names (RDNs).
•ou=deptUVZS + cn=Leslie Smith, ou=Austin, o=IBM
This a name containing three RDNs in which the first RDN is multi-valued.
•cn=L. Eagle, o=Sue, Grabbit and Runn, c=GB
This example shows the method of quoting a comma (using a backslash as the escape character) in an organization name.
•cn=Before�DAfter,o=Test,c=GB
This is an example name in which a value contains a carriage return character (0DH).
•sn=LuC48DiC487
This last example represents an RDN surname value consisting of five letters (including non-standard ASCII characters) that is written in printable ASCII characters. Table 2-4 explains the quoted character codes.
Table 2-4 The ASCII encoding of an RDN surname (example)
|
Unicode letter description
|
ISO 10646 code
|
UTF-8
|
Quoted
|
|
Latin capital letter L
|
U0000004C
|
0x4C
|
L
|
|
Latin capital letter u
|
U00000075
|
0x75
|
u
|
|
Latin small letter c with caron
|
U0000010D
|
0xC48D
|
C48D
|
|
Latin small letter i
|
U00000069
|
0x69
|
i
|
|
Latin small letter c with acute
|
U00000107
|
0xC487
|
C487
|
For the detailed definition of DNs in string form, consult RFC 2253. More about Unicode character encoding (superset of ISO 10646) and its transformation into UTF-8 can be found at http://www.unicode.org and in RFC 2279.
2.3.3 URL form
The LDAP URL format has the general form ldap://<host>:<port>/<path>, where <path> has the form <dn>[?<attributes>[?<scope>?<filter>]].
The <dn> is an LDAP distinguished name using a string representation. The <attributes> indicate which attributes should be returned from the entry or entries. If omitted, all attributes are returned. The <scope> specifies the scope of the search to be performed. Scopes may be current entry, one-level (current entry’s children), or the whole subtree. The <filter> specifies the search filter to apply to entries within the specified scope during the search. The URL format allows Internet clients, for example, Web browsers, to have direct access to the LDAP protocol and thus LDAP directories.
Examples of LDAP URLs are:
•ldap://austin.ibm.com/ou=Austin,o=IBM
This URL corresponds to a base object search of the <ou=Austin, o=IBM> entry using a filter <of objectClass=*> requesting all attributes (if a filter is omitted, a filter of <objectClass=*> is assumed by definition).
•ldap://austin.ibm.com/o=IBM?postalAddress
This is an LDAP URL referring to only the postalAddress attribute of the IBM entry.
•ldap:///ou=Austin,o=IBM??sub?(cn=Joe Q. Public)
This is an LDAP URL referring to the set of entries found by querying any capable LDAP server (no hostname was given) and doing a subtree search of the IBM Austin subtree for any entry with a common name of Joe Q. Public retrieving all attributes. The LDAP URL format is defined in RFC 2255.
2.4 Functional model
The LDAP functional model is comprised of three categories of operations that can be performed against a LDAPv3 directory service:
•Authentication: Bind, Unbind, and Abandon operations used to connect and disconnect to and from an LDAP server, establish access rights and protect information.
•Query: Search for and Compare entries for entries meeting user-specified criteria.
•Update: Add an entry, Delete an entry, Modify an entry, and modify the distinguished name (ModifyRDN) or relative distinguished name of an entry.
2.4.1 Query
The most common operation is search. The search operation is very flexible and has some of the most complex options.
The search operation allows a client to request that an LDAP server search through some portion of the DIT for information meeting user-specified criteria in order to read and list the result(s). There are no separate operations for read and list; they are incorporated in the search function. The search can be very general or very specific. The search operation allows one to specify the starting point within the DIT, how deep within the DIT to search, what attributes an entry must have to be considered a match, and what attributes to return for matched entries.
Some example searches expressed informally in English are:
•Find the postal address for cn=John Smith,o=IBM,c=DE.
•Find all the entries that are children of the entry ou=ITSO,o=IBM,c=US.
•Find the e-mail address and phone number of anyone in IBM whose last name contains the characters “miller” and who also has a fax number.
To perform a search, the following parameters must be specified:
•Base
A DN that defines the starting point, called the base object, of the search. The base object is a node within the DIT.
•Scope
Specifies how deep within the DIT to search from the base object. There are three choices: baseObject, singleLevel, and wholeSubtree. If baseObject is specified, only the base object is examined. If singleLevel is specified, only the immediate children of the base object are examined; the base object itself is not examined. If wholeSubtree is specified, the base object and all of its descendants are examined.
•Search Filter
Specifies the criteria an entry must match to be returned from a search. The search filter is a Boolean combination of attribute value assertions. An attribute value assertion tests the value of an attribute for equality, less than or equal to, and so on. For example, a search filter might specify entries with a common name containing “wolf” or belonging to the organization ITSO.
•Attributes to Return
Specifies which attributes to retrieve from entries that match the search criteria. Since an entry may have many attributes, this allows the user to only see the attributes they are interested in. Normally, the user is interested in the value of the attributes. However, it is possible to return only the attribute types and not their values. This could be useful if a large value like a JPEG photograph was not needed for every entry returned from the search, but some of the photographs would be retrieved later as needed.
•Alias Dereferencing
Specifies if aliases are dereferenced—that is, if the alias entry itself or the entry it points to is used. Aliases can be dereferenced or not when locating the base object and/or when searching under the base object. If aliases are dereferenced, then they are alternate names for objects of interest in the directory. Not dereferencing aliases allows the alias entries themselves to be examined.
•Limits
Searches can be very general, examining large subtrees and causing many entries to be returned. The user can specify time and size limits to prevent wayward searching from consuming too many resources. The size limit restricts the number of entries returned from the search. The time limit limits the total time of the search. Servers are free to impose stricter limits than requested by the client.
2.4.2 Referrals and continuation references
If the server does not contain the base object, it will return a referral to a server that does, if possible. Once the base object is found singleLevel and wholeSubtree searches may encounter other referrals. These referrals are returned in the search result along with other matching entries. These referrals are called continuation references because they indicate where a search could be continued. For example, when searching a subtree for anybody named Smith, a continuation reference to another server might be returned, possibly along with several other matching entries. It is not guaranteed that an entry for somebody named Smith actually exists at that server, only that the continuation reference points to a subtree that could contain such an entry. It is up to the client to follow continuation references if desired. Since only LDAP Version 3 specifies referrals, continuation references are not supported in earlier versions.
2.4.3 Search filter syntax
The search filter defines criteria that an entry must match to be returned from a search. The basic component of a search filter is an attribute value assertion of the form:
attribute operator value
For example, to search for a person named John Smith the search filter would be cn=John Smith. In this case, cn is the attribute, = is the operator, and John Smith is the value. This search filter matches entries with the common name John Smith. Table 2-5 shows the search filter options.
Table 2-5 Search filter options
|
Operator
|
Description
|
Example
|
|
=
|
Returns entries whose attribute is equal to the value.
|
cn=John Smith finds the entry with common name John Smith.
|
|
>=
|
Returns entries whose attribute is greater than or equal to the value.
|
sn>=smith finds all entries from smith to z*.
|
|
<=
|
Returns entries whose attribute is less than or equal to the value.
|
sn<=smith finds all entries from a* to smith.
|
|
=*
|
Returns entries that have a value set for that attribute.
|
sn=* finds all entries that have the sn attribute.
|
|
~=
|
Returns entries whose attribute value approximately matches the specified value. Typically, this is an algorithm that matches words that sound alike.
|
sn~= smit might find the entry “sn=smith”.
|
The * character matches any substring and can be used with the = operator. For example, cn=J*Smi* would match John Smith and Jan Smitty.
Search filters can be combined with Boolean operators to form more complex search filters. The syntax for combining search filters is:
( "&" or "|" (filter1) (filter2) (filter3) ...) ("!" (filter))
The Boolean operators are listed in Table 2-6 on page 51.
Table 2-6 Boolean operators
|
Boolean operator
|
Description
|
|
&
|
Returns entries matching all specified filter criteria.
|
|
|
|
Returns entries matching one or more of the filter criteria.
|
|
!
|
Returns entries for which the filter is not true. This operator can only be applied to a single filter. (!(filter)) is valid, but (!(filter1)(filter2)) is not.
|
For example, (|(sn=Smith)(sn=Miller)) matches entries with the surname Smith or the surname Miller. The Boolean operators can also be nested as in (| (sn=Smith) (&(ou=Austin)(sn=Miller))), which matches any entry with the surname Smith or with the surname Miller that also has the organizational unit attribute Austin.
2.4.4 Compare
The compare operation compares an entry for an attribute value. If the entry has that value, compare returns TRUE. Otherwise, compare returns FALSE. Although compare is simpler than a search, it is almost the same as a base scope search with a search filter of attribute=value. The difference is that if the entry does not have the attribute at all (the attribute is not present), the search will return not found. This is indistinguishable from the case where the entry itself does not exist. On the other hand, compare will return FALSE. This indicates that the entry does exist, but does not have an attribute matching the value specified.
2.4.5 Update operations
Update operations modify the contents of the directory. Table 2-7 summarizes the update operations.
Table 2-7 Update operations
|
Operation
|
Description
|
|
add
|
Inserts new entries into the directory.
|
|
delete
|
Deletes existing entries from the directory. Only leaf nodes can be deleted. Aliases are not resolved when deleting.
|
|
modify
|
Changes the attributes and values contained within an existing entry. Allows new attributes to be added and existing attributes to be deleted or modified.
|
|
modify DN
|
Changes the least significant (left most) component of a DN or moves a subtree of entries to a new location in the DIT. Entries cannot be moved across server boundaries.
|
2.4.6 Authentication operations
Authentication operations are used to establish and end a session between an LDAP client and an LDAP server. The session may be secured at various levels ranging from an insecure anonymous session, an authenticated session in which the client identifies itself by providing a password, to a secure, encrypted session using SASL mechanisms. SASL was added in LDAP Version 3 to overcome the weak authentication in LDAP Version 2. Table 2-8 summarizes the authentication operations.
Table 2-8 Authentication operations
|
Operation
|
Description
|
|
Bind
|
Initiates an LDAP session between a client and a server. Allows the client to prove its identity by authenticating itself to the server.
|
|
Unbind
|
Terminates a client/server session.
|
|
Abandon
|
Allows a client to request that the server abandon an outstanding operation.
|
2.4.7 Controls and extended operations
Controls and extended operations allow the LDAP protocol to be extended without changing the protocol itself. Controls modify the behavior of an operation, and extended operations add new operations to the LDAP protocol. The list of controls and extensions supported by an LDAP server can be obtained by examining the root DSE of that server. Controls can be defined to extend any operation.
Controls are added to the end of the operation’s protocol message. They are supplied as parameters to functions in the API.
A control has a dotted decimal string object ID used to identify the control, an arbitrary control value that holds parameters for the control, and a criticality level. If the criticality level is TRUE, the server must honor the control; or if the server does not support the control, reject the entire operation. If the criticality level is FALSE, a server that does not support the control must perform the operation as if there was no control specified. For example, a control might extend the delete operation by causing an audit record of the deletion to be logged to a file specified by the control value information.
An extended operation allows an entirely new operation to be defined. The extended operation protocol message consists of a dotted decimal string object ID used to identify the extended operation and an arbitrary string of operation-specific data.
2.5 Security model
The security model is based on the bind operation. There are several different bind operations possible, and thus the security mechanism applied is different as well. One possibility is when a client requesting access supplies a DN identifying itself along with a simple clear-text password. If no DN and password is declared, an anonymous session is assumed by the LDAP server. The use of clear text passwords is strongly discouraged when the underlying transport service cannot guarantee confidentiality and may therefore result in disclosure of the password to unauthorized parties.
LDAP V3 comes along with a bind command supporting the Simple Authentication and Security Layer (SASL) mechanism. This is a general authentication framework, where several different authentication methods are available for authenticating the client to the server; one of them is Kerberos.
Furthermore, extended protocol operations are available in LDAP V3. An extension related to security is the Extension for Transport Layer Security (TLS) for LDAPv3. This allow operations too use TLS as a means to encrypt an LDAP session and protect against spoofing. TLS has a mechanism which enables it to communicate to an SSL server so that it is backwards compatible. The basic principles of SSL and TLS are the same.
2.6 Directory security
Security is of great importance in the networked world of computers, and this is true for LDAP as well. When sending data over insecure networks, internally or externally, sensitive information may need to be protected during transportation. There is also a need to know who is requesting the information and who is sending it. This is especially important when it comes to the update operations on a directory. The term security, as used in the context of this book, generally covers the following four aspects:
•Authentication: Assurance that the opposite party (machine or person) really is who he/she/it claims to be.
•Integrity: Assurance that the information that arrives is really the same as what was sent.
•Confidentiality: Protection of information disclosure by means of data encryption to those who are not intended to receive it.
•Authorization: Assurance that a party is really allowed to do what he/she/it is requesting to do. This is basically achieved by assigning access controls, like read, write, or delete, to user IDs or common names.
The following sections focus on the first three aspects (since authorization is not yet contained in the LDAP Version 3 standard): Authentication, integrity and confidentiality. There are several methods that can be used for this purpose; the most important ones are discussed here. These are:
•No authentication.
•Basic authentication.
•Simple Authentication and Security Layer (SASL). This includes DIGEST-MD5. When a client uses Digest-MD5, the password is not transmitted in clear text and the protocol prevents replay attacks.
2.6.1 No authentication
This is the simplest authentication method, one that obviously does not need to be explained in much detail. This method should only be used when data security is not an issue and when no special access control permissions are involved. This could be the case, for example, when your directory is an address book browsable by anybody. No authentication is assumed when you leave the password and DN fields empty in an ldap operation. The LDAP server then automatically assumes an anonymous user session and grants access with the appropriate access controls defined for this kind of access (not to be confused with the SASL anonymous user).
2.6.2 Basic authentication
The security mechanism in LDAP is negotiated when the connection between the client and the server is established. This is the approach specified in the LDAP application program interface (API). Besides the option of using no authentication at all, the most simple security mechanism in LDAP is called basic authentication, which is also used in several other Web-related protocols, such as in HTTP.
When using basic authentication with LDAP, the client identifies itself to the server by means of a DN and a password which are sent in the clear over the network (some implementations may use Base64 encoding instead). The server considers the client authenticated if the DN and password sent by the client match the password for that DN stored in the directory. Base64 encoding is defined in the Multipurpose Internet Mail Extensions (MIME) LDAP standard (RFC 1521). It is a relatively simple encryption, and therefore it is not hard to break once one has captured the data on the network.
2.6.3 SASL
SASL is a framework for adding additional authentication mechanisms to connection-oriented protocols. It has been added to LDAP Version 3 to overcome the authentication shortcomings of Version 2. SASL was originally devised to add stronger authentication to the IMAP protocol. SASL has since evolved into a more general system for mediating between protocols and authentication systems. It is a proposed Internet standard defined in RFC 2222.
In SASL, connection protocols, like LDAP, IMAP, and so on, are represented by profiles; each profile is considered a protocol extension that allows the protocol and SASL to work together. A complete list of SASL profiles can be obtained from the Information Sciences Institute (ISI). Each protocol that intends to use SASL needs to be extended with a command to identify an authentication mechanism and to carry out an authentication exchange. Optionally, a security layer can be negotiated to encrypt the data after authentication and so ensure confidentiality. LDAP Version 3 includes a command (ldap_sasl_bind()) to encrypt the data after authentication.
2.6.4 SSL and TLS
The Secure Socket Layer (SSL) protocol was devised to provide both authentication and data security. It encapsulates the TCP/IP socket so that basically every TCP/IP application can use it to secure its communication.
SSL/TLS supports server authentication (client authenticates server), client authentication (server authenticates client), or mutual authentication. In addition, it provides for privacy by encrypting data sent over the network. SSL/TLS uses a public key method to secure the communication and to authenticate the counterparts of the session. This is achieved with a public/private key pair. They operate as reverse functions to each other, which means data encrypted with the private key can be decrypted with the public key and vice versa. The assumption for the following considerations is that the server has its key pair already generated. This is usually done when setting up the LDAP server.
The simplified interchange between a client and a server negotiating an SSL/TLS connection is explained in the following steps:
1. As a first step, the client asks the server for an SSL/TLS session. The client also includes the SSL/TLS options it supports in the request.
2. The server sends back its SSL/TLS options and a certificate which includes, among other things, the server’s public key, the identity for whom the certificate was issued (as a distinguished name), the certifier’s name and the validity time. A certificate can be thought of as the electronic equivalent of a passport. It has to be issued by a general, trusted Certificate Authority (CA) which vouches that the public key really belongs to the entity mentioned in the certificate. The certificate is signed by the certifier which can be verified with the certifier’s freely available public key.
3. The client then requests the server to prove its identity. This is to make sure that the certificate was not sent by someone else who intercepted it on a former occasion.
4. The server sends back a message including a message digest (similar to a check sum) which is encrypted with its private key. A message digest that is computed from the message content using a hash function has two features. It is extremely difficult to reverse, and it is nearly impossible to find a message that would produce the same digest. The client can decrypt the digest with the server’s public key and then compare it with the digest it computes from the message. If both are equal, the server’s identity is proved, and the authentication process is finished.
5. Next, server and client have to agree upon a secret (symmetric) key used for data encryption. Data encryption is done with a symmetric key algorithm because it is more efficient than the computing-intensive public key method. The client therefore generates a symmetric key, encrypts it with the server’s public key, and sends it to the server. Only the server with its private key can decrypt the secret key.
6. The server decrypts the secret key and sends back a test message encrypted with the secret key to prove that the key has safely arrived. They can now start communicating using the symmetric key to encrypt the data.
As outlined above, SSL/TLS is used to authenticate a server to a client using its certificate and its private key and to negotiate a secret key later on used for data encryption.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.