
For the first iteration, I wanted to give users the ability to create an account, validate it, and use it to log in. A lot of the workflow details on how this feat is achieved are relatively standard and beyond the scope of this short cut, so let’s skip those things. We will, however, quickly cover the parts of the workflow that affect the database. The user basically goes through three steps:
The first two steps are part of account creation. AuthorEyes.net does not issue a user an account until the user has completed the account creation process. So, from a data perspective, we need two things:
A way to remember that someone has requested an account, which allows us to confirm a user’s purported email address and complete the account creation process
A way to store the minimal data required for an account—account name, email address, and something that lets us validate the user’s password so that a user can log in later
I settled on two tables: NewAccountRequests fills the first role and Accounts takes care of the second. These two tables are depicted in Figure 2.

At this point, it makes sense to build up the underlying theory a little bit more. Let’s assume that we have a tool,[5] and that his tool has the following properties:
It provides a file format that allows us to describe our database as a series of transformations from one version to the next.
It can use the files described previously to apply transformations to a database.
It always applies transformations in the same order (oldest first, youngest last).
It marks up databases with metadata so that it never applies the same transformation to the same database twice.
It can build a database up to any specified version; even if you’ve defined five versions, you can still start with nothing and create a database with the behavior and structure of version 3.
Assuming the existence and characteristics of this tool frees us up quite a bit, because we don’t have to describe how any of those things are done. We can just assume that they are done, in much the same way we assume that a compiler compiles, and move on to more pressing matters.
In the real world, you should have a tool like this one at the core of your database build process. It serves the same role for updating an Agile database that compilers do for rebuilding binaries. Suppose that every time you wanted to translate a new program into byte code, you had to figure out how to do it yourself without the aid of a compiler—what a nightmare! If you don’t want to buy a database build tool, then you should roll your own. In any event, without such a tool, you will be constantly reinventing the wheel.
At this point, things will not look too different from what you have seen in the past. Getting to version 1.0 of a database is very easy, usually works, and almost always looks like it worked. The DDL script we need to run can be found in Listing 1.
Example 1. Schema SQL for version 1.0 of the database
CREATE TABLE [Accounts](
[Identity] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY,
[Name] VARCHAR(50) NOT NULL UNIQUE
CONSTRAINT AccountNameCannotBeBlank
CHECK ([Name] <> ''),
[Email] VARCHAR(200) NOT NULL UNIQUE
CONSTRAINT AccountEmailCannotBeBlank
CHECK ([Email] <> ''),
[PasswordHash] VARCHAR(4000) NOT NULL)
CREATE TABLE [NewAccountRequests](
[Identity] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY,
[PrivateEmailConfirmationCode] UNIQUEIDENTIFIER NOT NULL,
[AccountName] VARCHAR(50) NOT NULL
CONSTRAINT RequestedAccountNameCannotBeBlank
CHECK ([AccountName] <> ''),
[AccountEmail] VARCHAR(200) NOT NULL
CONSTRAINT RequestedAccountEmailCannotBeBlank
CHECK ([AccountEmail] <> ''),
[AccountPasswordHash] VARCHAR(4000) NOT NULL
CONSTRAINT RequestedAccountPasswordHashCannotBeBlank
CHECK ([AccountPasswordHash] <> ''))Because this is version 1.0, I could just charge in like a bull on amphetamines and use that DDL on my production server, test server(s), and any other servers I see. Such recklessness and promiscuity are precisely what we are trying to avoid, however—so I’ll take a more disciplined approach. I will start with nothing and build up the first version of my database definition file little by little in a test-driven way.
For the same reason that unit tests should not be written without a failing acceptance test, transition tests should not be written without a failing unit test. You can assume that we already have a failing acceptance test that was developed outside the scope of this document. What follows is a fairly humble unit test suite: All it does is show that we have an Accounts table.
Before we get to the test suite itself, let’s talk about the environment. Figure 3 shows the major entities involved in my environment.
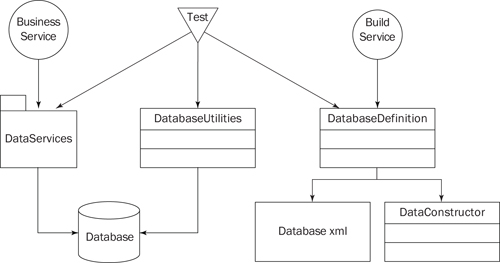
As stated previously (in the section “More Theory”), I have a tool—called DataConstructor—that helps with the database construction process. When I wrote that tool, I was targeting a broad audience with a wide array of needs. My needs in this case are much simpler, so I’ve encapsulated this product behind a class called DatabaseDefinition. DatabaseDefinition is a facade,[6] which means it hides the features I don’t care about and exposes those that are useful, via the most convenient interface possible.
A second class called DatabaseUtilities takes care of the “dirty work” that database tests often need done. For instance, this class has a method that enables the client to easily invoke a SQL command on a database server—for example, to delete a table, to drop a database and create an empty one in its place, and so on.
There is also a lightweight data access layer in place in the DataServices namespace. The DataServices component is used by AuthorEyes.net to load and store all data, thereby insulating the application from the specifics of the database. This component has three types that matter to us right now: Factory, Store, and Table. Factory is an interface for objects that create instances of data services objects. Implementations of the Store interface encapsulate databases, providing access to the tables contained in those databases. The Table class enables access to a table within a database (for selects, inserts, and updates).
Now let’s consider our first database unit test, shown in Listing 2.
Example 2. First unit test for the Accounts table
using System;
using NUnit.Framework;
using AuthorEyes.Website.Tests.Utilities;
using AuthorEyes.Website.Database;
using AuthorEyes.Website.DataServices;
namespace AuthorEyes.Website.Tests.Database.Unit
{
[TestFixture]
public class AccountsTableTests
{
private DatabaseUtilities _databaseUtilities;
private DatabaseDefinition _database;
private DataServices.Factory _dataServicesFactory;
private DataServices.Store _dataStore;
private DataServices.Table _table;
[TestFixtureSetUp]
public void FixtureSetUp()
{
_databaseUtilities = DatabaseUtilities.GetInstance();
_database = DatabaseDefinition.GetInstance();
TryToDestroyTheDatabase();
_database.UpgradeDatabaseToCurrentVersion();
_dataServicesFactory =
DataServices.FactoryLocator.GetFactory();
_dataStore = _dataServicesFactory.GetStore();
_table = _dataStore.GetTable("Accounts");
}
[Test]
public void AccountsTableExists()
{
// select everything
_table.Select(null);
}
private void TryToDestroyTheDatabase()
{
try
{
_databaseUtilities.DestroyDatabase(_database);
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
}
}
}
The FixtureSetUp method runs first and runs only once for all of the tests. This method’s activities can be broken down into four steps:
Instantiating some of the utility objects:
DatabaseUtilitiesandDatabaseDefinitionEliminating whatever test database may have already existed and replacing it with an empty data store
Invoking
DatabaseDefinition’sUpgradeDatabaseToCurrentVersionmethod, to build the empty database up to the current database version (whatever that may be)Putting some of the data access objects in place and giving tests access to the data store and the Accounts table
The test simply calls the Select method on the object encapsulating the Accounts table (_table) with no criterion. If you translated this method from the language of the Table object to SQL, you would get something like SELECT * FROM Accounts without a WHERE clause. Our test assumes that the Table class will throw or percolate an exception if it fails to execute a SQL statement.
There are three really important things to notice about this unit test suite:
The name
The version of the database to which it is coupled
The interface through which it accesses the database
The name of the test suite is important because it couples the tests within the suite to the concept of the Accounts table. This linkage provides minimal protection against developers testing other tables: It would not be logical to put a test related to, say, the NewAccountRequests table into this test suite.
This test suite does not pertain to any version of the database; it pertains to whatever the current version of the database is when it is run. This behavior stands in sharp contrast to transition tests, which are targeted at specific versions (as you will see soon). It will become clear how important this fact is in the coming paragraphs; for now, however, let’s just say that this fact is what makes the test suite a unit test suite instead of something else.
The fact that the unit test goes through an encapsulating layer is also important. Because it is not coupled to the specifics of the underlying database engine or SQL statements, the unit test is shielded from such changes. At the time of this writing, AuthorEyes.net uses a SQL Server back end; even so, if we chose to switch to, say, Oracle or MySQL, these tests would remain useful.
In contrast, the transition tests should have as intimate a relationship as possible with the database because a database is the output of what they are testing. To that end, I do not use the data access layer when transition testing. Instead, I use special services crafted specifically for the purpose of testing. For example, in a transition test I use DatabaseUtilities.ExecuteSql() instead of Table.Select() to verify the existence of the Accounts table.
After I’ve run this unit test suite and seen my first database unit test fail, I know that I need to change my database definition so that it builds a database with an Accounts table. Because adding an Accounts table means making a change to a database, it requires transition testing. Listing 3 shows what the first transition test looks like.
Example 3. First transition test
...proving that an Accounts table is built
using System;
using NUnit;
[TestFixture]
public class Version_1_0_Tests
{
private DatabaseUtilities _databaseUtilities;
private DatabaseDefinition _instance;
[TestFixtureSetUp]
public void SetUp()
{
_databaseUtilities = DatabaseUtilities.GetInstance();
_instance = DatabaseDefinition.GetInstance();
TryToDestroyTheDatabase();
_instance.UpgradeDatabaseToSpecificVersion(new Version(1, 0));
}
[Test]
public void AccountsTableExists()
{
_databaseUtilities.ExecuteSql(_instance,
"SELECT * FROM [Accounts]");
}
private void TryToDestroyTheDatabase()
{
try
{
_databaseUtilities.DestroyDatabase(_instance);
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
}
}
Let’s break down what that test suite does. The fixture setup method (SetUp) is run once for the whole suite. It initializes _databaseUtilities and _instance. The SetUp method uses the former object to eradicate any preexisting database. Then, it uses the _instance object—the DatabaseDefinition that we are testing—to build the test database up to version 1.0.
Note
This call will bring the database up to exactly version 1.0—nothing earlier (if there were such a thing) and nothing later (when such a thing comes to exist). So, even when we add a version 1.1 or 2.0, this test will always bring the target database up to version 1.0. This behavior may seem odd to you but, remember, transition tests do not test the database; the database is just a fixture. Instead, transition tests test the database builder.
Once the fixture setup has run, each test is free to perform some validation on version 1 of the database. The aforementioned test makes a very simple distinction: that something—anything, even an empty results set with garbage columns—can be pulled out of the Accounts table.
Take special note of the name, target version, and database interface used by this transition test. They help illustrate important differences between transition and unit tests.
Whereas the unit test suite shown earlier was scoped to just the Accounts table, the aforementioned class could easily expand to cover all aspects of version 1.0. If the requirements for the Accounts table ever change, the unit test will adapt to the new situation. If the requirements for version 1.0 of the database change—which could happen only in the current iteration—then the transition test will change to suit the new requirements.
Although the transition test can cover all aspects of version 1.0, it will test only that version. The unit test will follow our database definition, continually validating whatever version is the most recent, but this set of transition tests will continue to consider version 1.0 and nothing else.
Furthermore, the unit test will be an evolving standard. As AuthorEyes.net’s needs pertaining to the Accounts table grow, so will the unit test suite for the Accounts table. If a requirement changes, at least one unit test will probably change to reflect the new situation. However, the transition test will not change once the transition it is testing has been applied to a production database.
Unit tests and transition tests are perpendicular in scope; intersecting only in the right part of the database at the right point in time.
The transition test also has a much more intimate relationship with the database that is built than the earlier unit test does. Virtually nothing stands between the two: just a paper-thin abstraction that is part of the test module. In a unit test, that would be a red flag—an omen foretelling the death of the test the first time the database changes in a relevant way.
This kind of coupling, which would be a weakness for a unit test, is exactly what makes transition tests useful. Because they are inherently coupled to a specific version of a database, such tests are unaffected by future changes to the database. They not only can have a deep, interconnected relationship with the database they are inspecting, but also should have such a relationship. In the same way that the tests for a compiler are well within their rights to perform detailed analyses of that compiler’s output, the tests for our database build tool are enfranchised to probe as deep as is required to ensure that the builder is doing its job.
At this point, you might be asking yourself, “But how does the database actually get created?” The answer is that DatabaseDefinition encapsulates a database definition file. Essentially, it ties together configuration information pertaining to connectivity, a “third-party” database construction engine, and a script for the same to create a simple interface through which tests and applications can build up a database. No time will be spent on the third-party engine, but we will discuss the scripts used to define the database at length. Let’s start out with an empty definition (see Listing 4) so that we can see my tests fail.
This code is probably somewhat unfamiliar, so let’s take a moment to describe what the file says. The root element says that we are defining a database in terms of how to get from one version to the next. The only child element of the root node says that the first version we are going to create is version 1.0. The fact that this element has no child elements says that we are going to do nothing to distinguish version 1.0 from an empty database.
What do I need to make the two tests pass? Not much, really. I just need a table named Accounts. The easiest way I know to get a table when you don’t already have one is to use the SQL command CREATE TABLE. I’ll add that command to my database definition file as shown in Listing 5.
Notice that I added just a little bit to the database definition file. All I did was create a table with the right name. None of the required columns exist, and the one column that does exist will not be a useful part of the finished product. That’s okay. I am not running this script in production, at least not yet. Does this sound familiar? It should: I am driving the development of my database definition script, and therefore my database, from tests.
Once the existing tests (both unit and transition) pass, it’s time to add another pair of tests. It might sound weird, adding two tests for one behavior. As intimated earlier, this process is really not that different from adding a unit test in service of a failing acceptance test. Modern test-driven development does not strictly require a maximum of one failing test, so this is really just another test on the “stack” of tests that will be built to validate a piece of a system.
The next pair of tests will make sure that, in the database produced by the database builder, a record can be inserted with the right values into the Accounts table. First, let’s get a failing unit test in place to justify the change (see Listing 6).
Example 6. A unit test demanding that the Accounts table can accept data with the required schema
[Test]
public void CanInsertCompletelyUniqueAccountsRecord()
{
Record record = _dataServicesFactory.CreateRecord();
record.SetProperty("Identity", Guid.NewGuid());
record.SetProperty("Name", "Unique");
record.SetProperty("Email", "[email protected]");
record.SetProperty("PasswordHash", "P%%#@C");
_table.Insert(record);
}The test gets a record that is guaranteed to be unique, assuming the Accounts table has been properly cleared and barring any shenanigans. It then inserts that record into the Accounts table via the data services layer. If the insert fails for any reason, an exception will be generated, causing the test to fail. Once again, this test is relatively independent of the underlying database technology. Transitioning to another platform—even one that is radically different, such as a platform that does not use SQL—would not be that difficult.
After seeing the unit test that was previously added fail, I added the test shown in Listing 7 to characterize the problem I want the database builder to solve.
Example 7. A transition test ensuring that the Accounts test will accept a fully populated, unique record
[Test]
public void CanInsertCompletelyUniqueAccountsRecord()
{
_databaseUtilities.ExecuteSql(_instance, @"
INSERT INTO [Accounts]([Identity], [Name], [Email], [PasswordHash])
VALUES(newid(), 'Unique1', '[email protected]', 'P%%#@C')");
}The test in Listing 7 says not only that DatabaseDefinition must produce an Accounts table, but also that the required table must have a schema appropriate for inserting the relevant account data. If I ran my unit and transition test suites at this point, the two tests pertaining to the mere existence of an Accounts table would pass, but those asserting the schema of the table would fail.
A failing transition test justifies another change to the database definition file. Again, I wanted to add the minimum amount of information required to make the second set of tests pass without breaking the first set. To accomplish that goal, I changed the database definition script to create an unconstrained Accounts table with an Identity column, a Name column, an Email column, and a PasswordHash column. The new version of the script can be seen in Listing 8.
Example 8. A database definition file creating an unconstrained Accounts table with the correct schema
<DatabaseWithVersions>
<Version Id="1.0">
<Sql>
CREATE TABLE [Accounts](
[Identity] UNIQUEIDENTIFIER,
[Name] VARCHAR(50),
[Email] VARCHAR(200),
[PasswordHash] VARCHAR(4000))
</Sql>
</Version>
</DatabaseWithVersions>Running the unit and transition test suites again confirms that this change has the intended effect.
Note how the database definition is evolving with each test, in much the same way a program might. I am not creating a new version for every change; instead, I am slowly building version 1.0 up as I am able to define requirements in the form of tests. Version 1.0 is evolving—it can evolve—because the script is a program that builds a database, rather than a database itself. In other words, the script is evolving in a way that enables emergent design in something that cannot evolve (deployed databases).
The code shown so far is not enough to finish the Accounts table; some constraints need to be added. Of course, it would be pretty monotonous if the rest of the short cut dealt with you reading about me testing all of the nooks and crannies of the first two tables in AuthorEyes.net’s database. So we’ll do one more cycle of tests on this version and then move on to the next iteration.
The next pair of tests confirms that a row cannot be inserted without a value for the Identity column. Up to this point, we have been relying on the generation of an exception implying the failure of a test. Now let’s treat the absence of an exception as a failure.
To achieve this, we can leverage the ExpectException[7] method on an object named _exceptionUtilities, which invokes a delegate and fails the calling test if that invocation does not result in a certain kind of exception. Listing 9 contains the Accounts table unit test suite with this new test included.
Example 9. Adding a unit test asserting that a constraint exists on the Accounts table
private ExceptionUtilities _exceptionUtilities;
[Test]
public void CannotInsertAccountWithoutId()
{
Record record = _dataServicesFactory.CreateRecord();
record.SetProperty("Identity", DBNull.Value);
record.SetProperty("Name", "Unique");
record.SetProperty("Email", "[email protected]");
record.SetProperty("PasswordHash", "P%%#@C");
_exceptionUtilities.ExpectException<Exception>(
() => _table.Insert(record));
}With the exception of adding an instance of ExceptionUtilities as a fixture, the setup for the Accounts table unit test suite is no different from the earlier code. The additional test is also a lot like the unit test introduced earlier. The difference is that this test damages the record that is being inserted by rendering the Identity field null and then tests that the broken record cannot be inserted into the Accounts table. For those of you not familiar with C# 3.0, () => is shorthand for an anonymous delegate that takes no parameters and executes whatever expression appears immediately to the right of these symbols.[8]
Once the unit test failed, the corresponding transition test was added (see Listing 10).
Example 10. A transition test showing that a constraint was added to the Accounts table on the Identity column
[Test]
public void CannotInsertAccountWithoutId()
{
_exceptionUtilities.ExpectException<Exception>(
() => _databaseUtilities.ExecuteSql(_instance, @"
INSERT INTO [Accounts]([Name], [Email], [PasswordHash])
VALUES('Unique2', '[email protected]', 'P%%#@C')"));
}Running the test in Listing 10 showed that the Accounts table built by DatabaseBuilder did not already protect itself from null Identity values. This finding justified yet another change to the database definition script—namely, adding a NOT NULL constraint to the Identity column (see Listing 11).
Example 11. A database definition script including a NOT NULL constraint on the Identity column
<DatabaseWithVersions>
<Version Id="1.0">
<Sql>
CREATE TABLE [Accounts](
[Identity] UNIQUEIDENTIFIER NOT NULL,
[Name] VARCHAR(50),
[Email] VARCHAR(200),
[PasswordHash] VARCHAR(4000))
</Sql>
</Version>
</DatabaseWithVersions>I continued in this fashion, incrementally adding tests and then updating my database definition file appropriately, until I was satisfied that DatabaseDefinition would do what I wanted it to do when asked for version 1.0 of a database.
The question now running through your mind may be “What’s different?” or perhaps “What did all that work buy me?” At the risk of a little redundancy, what we’ve done is set ourselves up to roll out future versions of a database safely. And why is that? By gaining confidence in how version 1.0 is built, we know what version 1.0 really is—not what we think it is or what we wish it would be—so we can use version 1.0 as a foundation upon which version 2.0 is built. If we do the same thing with version 2.0, then it can be treated as the makings of 3.0. Version 3.0 will lead to 4.0, version 4.0 to 5.0, and so on.
The true meaning runs deeper than that, however. One of the major problems with tests that touch the database—acceptance tests, database unit tests, and certain integration tests—is credibility. Without a solid definition of the database that the tests are building, the entire testing exercise has very little credibility. Tests that run against shared databases often die because of data changes or collisions that trigger constraints. Tests that run against databases local to developer machines have their own crop of issues surrounding the viability of the local database as a test subject (e.g., freshness of data, freshness of structure, and applicability of the way that structure is changed in development to the way it will be modified in production).
Having a sturdy, reliable, and highly repeatable mechanism for constructing a database that can be invoked from a test and that requires no human intervention alleviates these and many other test-credibility issues. In other words, having a solid definition of how you get to version N provides you with a jumping-off point for all kinds of tests that depend on that version, including how you get to version N + 1, how version N should behave, and how dependent systems interact with that version.
[5] You can further assume that I have written this tool and it is available online (http://www.dataconstructor.com). (Don’t worry: This is not an advertisement in disguise. I am using the tool I have written because it is genuinely easier to express these ideas with it than without it. Plus there’s a community edition that is available for free at the time of this writing.
[7] I know—in NUnit, there’s ExpectedExceptionAttribute. This is not sufficient for my needs for several reasons which are out of the scope of this document.
[8] 8 There’s more to it than that. This syntax also attempts to adapt the return value of the expression on the righthand side so that it becomes a return value for the delegate if and only if such a return value is required. If the context calls for a delegate with a void return type, then one is generated regardless of the type of the expression.