
Intervals
The key to the problems identified in the previous chapter is to recognize that intervals are best thought of as objects in their own right, instead of just as pairs of points (“from/to pairs”). The chapter discusses some immediate consequences, and advantages, of this state of affairs. It then discusses in detail the concept of an interval data type and the concept of the associated point type, stressing in particular the role of the corresponding successor function. The chapter also stresses the fact that intervals aren’t necessarily temporal in nature—in fact, intervals in general are a widely applicable and useful abstraction. The chapter concludes with a brief discussion of relations having two or more interval attributes.
Keywords
interval type; point type; successor function; two or more interval attributes
Lucid intervals and happy pauses
—Francis Bacon:
History of King Henry VII (1622)
We’re now ready to embark on our development of an appropriate set of constructs for dealing properly with temporal data. The first and most fundamental step is to recognize the need to deal with intervals as such—i.e., the need to treat them as values in their own right, instead of as pairs of separate FROM and TO values as in the previous chapter.
What’s an Interval?
Take another look at Fig. 5.3 in Chapter 5. According to that figure, supplier S1 was able to supply part P1 during the interval from day 4 to day 10. But what does “the interval from day 4 to day 10” mean? It’s clear that days 5, 6, 7, 8, and 9 are included—but what about days 4 and 10 themselves? It turns out that if some interval i is described as stretching “from b to e,” sometimes we want to consider the points b and e as part of i and sometimes we don’t. If we do want to consider b as part of i, we say i is closed at its beginning, otherwise we say it’s open at its beginning. Likewise, if we want to consider e as part of i, we say i is closed at its end, otherwise we say it’s open at its end.
Conventionally, therefore, we denote an interval by a pair of points b and e separated by a colon,1 preceded by an opening bracket or parenthesis and followed by a closing bracket or parenthesis. We use a bracket where we want the closed interpretation, a parenthesis where we want the open one. There are thus four distinct ways to denote the specific interval that runs from the “begin point” day 4 to the “end point” day 10, inclusive:
[d04:d10]
[d04:d11)
(d03:d10]
(d03:d11)
Now, you might think it odd to use, say, an opening bracket with a closing parenthesis. In fact, however, there are good reasons to allow all four styles. Indeed, the closed:open style—i.e., closed at the beginning and open at the end, as in, e.g., [d04:d11)—is the style most often used in practice. But the closed:closed style, as in, e.g., [d04:d10], is surely the most intuitive, and it’s the one we’ll favor throughout what follows. Note: To see why the closed:open style might be advantageous, consider the operation of splitting the interval [d04:d11) immediately before, say, day 7. The result is the abutting pair of intervals [d04:d07) and [d07:d11).
Now, given that an interval such as [d04:d10] can be considered as a value in its own right, it clearly makes sense to combine the FROM and TO attributes of each of the relvars of Fig. 5.3 into a single attribute, DURING, whose values are drawn from some interval type (see the section “Point and Interval Types” later in this chapter). Fig. 6.1 shows what happens to our running example if we adopt this approach (note the relvar name changes):

The predicate for S_DURING is:
Supplier SNO was under contract throughout the interval from the day that’s the begin point of DURING to the day that’s the end point of DURING, inclusive, and not throughout any interval that properly includes that interval.
And the predicate for SP_DURING is:
Supplier SNO was able to supply part PNO throughout the interval from the day that’s the begin point of DURING to the day that’s the end point of DURING, inclusive, and not throughout any interval that properly includes that interval.
The idea of replacing the pair of attributes FROM and TO by the single attribute DURING has a number of immediate advantages. Here are some of them:
■ It avoids the problem (if it really is a problem) of having to make an arbitrary choice as to which of two keys should be regarded as primary. For example, relvar S_FROM_TO had two keys, {SNO,FROM} and {SNO,TO}, but relvar S_DURING has just one, {SNO,DURING}, which we can therefore designate as primary if we want to without any undesirable arbitrariness.2 Similarly, relvar SP_FROM_TO also had two keys but relvar SP_DURING has just one, {SNO,PNO,DURING}, which again we can designate as primary if we want to.
■ It also avoids the problem of having to know whether the FROM-TO intervals in the previous version of the database (Fig. 5.3) are to be interpreted as closed or open with respect to FROM and TO. In Chapter 5, those intervals were implicitly taken to be closed with respect to both FROM and TO. But now, e.g., [d04:d10], [d04:d11), (d03:d10], and (d03:d11) are four distinct “possible representations” of the very same interval, and we can use whichever of these four styles we like—whichever one best serves our purposes at the time.3 If we like, we can even mix styles and show, e.g., the DURING values for suppliers S1 and S4 in S_DURING as [d04:d10] and (d03:d11), respectively, even though those two values are actually identical. Note: Refer to Chapter 1 if you need to refresh your memory regarding the concept of possible representations.
■ Yet another advantage is that constraints “to guard against the absurdity of a FROM-TO pair in which the TO value is less than the FROM value” (as we put it in the previous chapter) are no longer necessary, because the constraint FROM ≤ TO is implicit in the very notion of an interval type. That is, those explicit constraints of the form FROM ≤ TO are all effectively replaced by a generic constraint that implicitly applies to intervals of each and every specific interval type. Those specific interval types are defined by means of invocations of the interval type generator (again, see the section “Point and Interval Types,” later), and that generic constraint can be thought of as being associated with that type generator, just as the generic interval operators to be discussed later in this chapter and in the next can also be thought of as being associated with that type generator.
Other advantages will become clear over the next few chapters.
As for the constraints and queries discussed in the previous chapter, it should be clear that direct analogs of those constraints and queries can be formulated against the database of Fig. 6.1, just so long as we have a way of accessing the begin and end points of any given interval (once again, see the section “Point and Interval Types”). We won’t bother to show such formulations, however, since it’s precisely part of our goal to come up with a better way of dealing with such matters—a way, that is, of expressing such constraints and queries that involves something better than just direct analogs of those earlier formulations. We’ll discuss such a better way in subsequent chapters; to be specific, we’ll deal with queries in Chapters 9-11 (and again in Chapter 15) and constraints in Chapters 13 and 14.
One final remark: We should stress the point, implicit in much of what we’ve been saying already, that intervals as discussed in this chapter are scalar values—they have no user visible components. (The begin and end points for a given interval are components of a certain possible representation of that interval, not components of that interval as such.) Another way of saying the same thing is to say that intervals are “encapsulated” (but see reference [36]).
Applications of Intervals
The interval concept is the key to addressing the problems raised in the previous chapter; in other words, intervals are the abstraction we need for dealing with temporal data satisfactorily. Before we start getting into details of temporal intervals as such, however, we want to emphasize the fact that the interval concept is actually of much wider applicability; that is, there are many other applications for intervals, applications in which the intervals aren’t necessarily temporal ones as such (see, e.g., reference [75]). Here are a few examples:
■ Tax brackets are represented by taxable income ranges—i.e., intervals whose contained points are money values.
■ Machines are built to operate within certain temperature and voltage ranges—i.e., intervals whose contained points are temperatures and voltages, respectively.
■ Animals vary in the range of frequencies of light and sound waves to which their eyes and ears are receptive.
■ Various natural phenomena occur and can be measured in ranges in depth of soil or sea or height above sea level.
And so on. And although our focus in this book is, for the most part, on temporal intervals specifically, many of our discussions are relevant to intervals in general, not just to temporal ones in particular. However, we’ll consider certain specifically temporal issues in Part III of this book, when we get to the chapters that discuss temporal database design and various related matters.
Note: All of the intervals discussed so far can be thought of as one-dimensional. Given two one-dimensional intervals, however, we might sometimes want to consider them in combination as forming a two-dimensional interval. For example, a rectangular plot of ground might be thought of as a two-dimensional interval, because it is, by definition, an object with length and width, each of which is basically a one-dimensional interval measured along some axis. And, of course, we can extend this idea to any number of dimensions. For example, a (rather simple!) building might be regarded as a three-dimensional interval: It’s an object with length, width, and height, or in other words a cuboid. (More realistically, a building might be regarded as a set of such cuboids that overlap in various ways.) And so on. In what follows, however, we’ll restrict our attention to one-dimensional intervals specifically (barring explicit statements to the contrary), and we’ll omit the “one-dimensional” qualifier for simplicity.
Point and Interval Types
Our discussion of intervals so far has been mostly intuitive in nature. Now we need to address the issue a little more formally. We begin by considering the interval [d04:d10] once again; let’s agree to refer to it as “the interval value i,” or just interval i for short. In accordance with our running convention, the points that make up interval i—namely, d04, d05, …, and d10—are all, specifically, days. For the sake of the example, therefore, let’s assume those points are in fact all values of type DATE, where (as in the previous chapter) type DATE represents calendar dates, accurate to the day. Then type DATE is said to be the point type for interval i.
But how exactly do we know the points in i, in sequence, are the ones we said they were (namely, d04, d05,…, d10)? Well, we certainly know that i includes its begin and end points d04 and d10, by definition. We also know that i consists of a set of points arranged in accordance with some agreed ordering. So if we’re to determine the complete set of points in i in their proper sequence, we first need to determine the point—informally, let’s refer to it as d04+1—that immediately follows the begin point d04 according to that agreed ordering. That point d04+1 is the successor of d04 according to that ordering, and the function by which that successor is determined is the corresponding successor function. In the case at hand, where the point type is DATE, the successor function is basically “next day” (meaning “add one day to the given date”)—i.e., it’s a function that, given a DATE value d, returns the DATE value that’s the immediate successor of d. Note: If d+1 is the successor of d in some ordering, then of course d is the predecessor of d+1 in that same ordering. Informally, we sometimes refer to the predecessor of d as d−1.
Having determined that d04+1 is the successor of d04, we must next determine whether d04+1 comes after the end point d10 according to that same agreed ordering. If it doesn’t, then d04+1 is indeed a point in i = [d04:d10], and we must now consider the next point, d04+2. Repeating this process until we come to the first point d04+n (actually d04+7, or in other words d11) that comes after d10—or, just possibly, until we come to “the last day” (see below)—we’ll discover every point, in sequence, in i = [d04:d10].
More generally, let interval i = [b:e], where b and e are again values of type DATE, and the same “next day” successor function applies. Then there are, of course, a couple of special cases to consider:
■ b = “the first day” (i.e., the point corresponding to “the beginning of time,” which has no predecessor). The expression b−1 is undefined in this case.
■ e = “the last day” (i.e., the point corresponding to “the end of time,” which has no successor). The expression e+1 is undefined in this case.
So, as the foregoing discussion should be sufficient to suggest, we have the following:
Definition: Type T is usable as a point type if all of the following are defined for it:
a. A total ordering, according to which the operator “>” (greater than) is defined for every pair of values v1 and v2 of type T, such that if v1 and v2 are distinct, exactly one of the expressions v1 > v2 and v2 > v1 returns TRUE and the other returns FALSE
b. Niladic first and last operators, which return the smallest (first) and largest (last) value of type T, respectively, according to the aforementioned ordering
c. Monadic next and prior operators, which return the successor (if it exists) and predecessor (if it exists), respectively, of any given value of type T according to the aforementioned ordering
Points arising (pardon the pun):
■ The next operator is the successor function, of course. Also, as already noted, next and prior are undefined if their argument—the given value of point type T—is in fact the last or first value, respectively, of that type T.
■ As we know from Chapter 1, the “=” operator is certainly defined for any given point type T. Given that “>” is defined as well, therefore (and given also the availability of the boolean operator NOT), we can assume without loss of generality that all of the usual comparison operators—“=”, “≠”, “>”, “≥”, “<”, and “≤”—are in fact available for all pairs of values of type T.
We now make an important assumption. To be specific, we assume until further notice that the successor function is unique; in other words, if T is a point type, then T has exactly one successor function. Now, this assumption might seem reasonable at first glance—but is it? Consider type DATE once again. In practice, we don’t always want to deal with dates that are accurate to the day. For example, U.S. presidential administrations are usually specified in terms of dates that are accurate only to the year (e.g., “Gerald R. Ford, 1974-1977”), and the same is true for reigns of monarchs and the like. It follows that we might want to consider two distinct successor functions for type DATE, “next day” and “next year” (note that these two functions correspond informally to two distinct DATE granularities—see Chapter 4). Such considerations muddy the picture considerably, as you might expect. We therefore choose to defer detailed discussion of them to a later chapter (Chapter 18); until then, we’ll simply stay with our “unique successor function” assumption. Please understand, however, that certain of the concepts and issues discussed prior to Chapter 18 will need to be revisited (and extended slightly, in some cases) when we get to that chapter.
To get back to our example of the interval i = [d04:d10], we can now pin down the type of that value precisely, as follows:
■ First, of course, it’s of some interval type, and that fact by itself is sufficient to determine the generic interval operators that are available for the interval value in question (just as to say that, e.g., some value is of some relation type is sufficient to determine the generic relational operators—restrict, project, and so on—that are available for the relation value in question). A few such operators are discussed later in this section, and more are discussed in Chapter 7.
■ Second, the interval value in question is, specifically, an interval from one DATE value to another, and—thanks to our “unique successor function” assumption—that fact is sufficient to determine the specific set of values that together constitute the interval type in question: It’s precisely the set of intervals of the form [b:e], where b and e are values of type DATE and, by definition, b ≤ e.
In other words, we can say the specific type of the interval value i = [d04:d10] is, precisely, INTERVAL_DATE, where:
■ INTERVAL is a type generator, and INTERVAL_DATE represents a specific invocation of that type generator.
■ DATE is, as already explained, the point type for this interval type; i.e., intervals of this specific interval type are made up of points of this specific point type.
Here by way of illustration are a couple more examples of interval types:
■ INTERVAL_INTEGER
The point type here is INTEGER; the successor function is “next integer” (i.e., “add one”), and values of this interval type are intervals of the form [b:e], where b and e are values of type INTEGER (and b ≤ e).
■ INTERVAL_MONEY
MONEY here is—let’s assume—a type that represents monetary amounts measured in dollars and cents. The successor function is “add one cent.” Values of this interval type are intervals of the form [b:e], where b and e are values of type MONEY (and b ≤ e).
And here (at last!) is a formal definition of the term interval:
Definition: Let T be a point type. Then an interval value (or just an interval for short) i of type INTERVAL_T is a value for which two monadic operators, BEGIN and END, and one dyadic operator, “∈”, are defined, such that:
a. BEGIN (i) and END (i) both return a value of type T.
c. If p is a value of type T, then p ∈ i is true if and only if BEGIN (i) ≤ p and p ≤ END (i) are both true. Note: Of course, “∈” here is just a variant on the conventional set membership operator. The expression “p ∈ i” can be pronounced as “p belongs to i” or “p is contained in i” or, more simply, just “p [is] in i.”
■ Observe that intervals are always nonempty—i.e., there’s always at least one point in any given interval.
■ Intervals i1 and i2 of the same interval type are equal—i.e., i1 = i2 is true—if and only if BEGIN (i1) = BEGIN (i2) and END (i1) = END (i2) are both true (see Chapter 7 for further discussion).
■ As noted earlier, the begin and end points for a given interval together constitute a possible representation for that interval. In Tutorial D, therefore, we would normally refer to those BEGIN and END operators as THE_BEGIN and THE_END, respectively (see Chapter 1). However, we use BEGIN and END in this book for consistency with other writings in this field.
■ By the same token, an expression of the form “[b:e]” can be thought of, informally, as an interval selector invocation. We’ll have a little more to say in the next chapter as to what interval selectors (as well as the crucially important successor and predecessor functions) might look like in a real language.
■ An interval i for which BEGIN (i) = END (i) is true is called a unit interval. In other words, a unit interval is an interval that contains exactly one value of the associated point type; for example, the interval [d04:d04] is a unit interval of type INTERVAL_DATE.
To close this section, here are definitions for relvars S_DURING and SP_DURING:
VAR S_DURING BASE RELATION
{ SNO SNO , DURING INTERVAL_DATE } KEY { SNO , DURING } ;VAR SP_DURING BASE RELATION
{ SNO SNO , PNO PNO , DURING INTERVAL_DATE } KEY { SNO , PNO , DURING } ;Please note, however, that these definitions are very incomplete! We’ll come back and elaborate on them in Chapters 13 and 14.
A More Searching Example
Relvars S_DURING and SP_DURING both have just one interval attribute, called DURING in both cases. However, it’s certainly possible for a relvar to have two or more such attributes. For example:
■ Suppose, not unreasonably, that there’s a total ordering on part numbers, such that P1 < P2 < P3 (etc.)—more precisely, suppose type PNO can legitimately be used as a point type—and suppose further that we wish our database to show that certain suppliers were able to supply certain ranges of parts during certain intervals of time.
■ Then relvar SP_DURING could well have two interval attributes, DURING and PARTS (say), where DURING is as before and PARTS indicates the corresponding part ranges.
To avoid confusion, let’s refer to this revised version of the relvar as S_PARTS_DURING instead of SP_DURING. A sample value is shown in Fig. 6.2. Note: That sample value is deliberately not meant to correspond in any particular way to the sample value shown for relvar SP_DURING in Fig. 6.1.
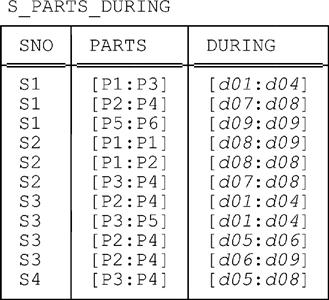
Here’s the predicate for S_PARTS_DURING:
Throughout the interval from the begin point of DURING to the end point of DURING, inclusive, supplier SNO was able to supply every part PNO in the interval from the begin point of PARTS to the end point of PARTS, inclusive.
Observe that, with respect to attribute DURING, this predicate doesn’t include text of the form “and not throughout any interval that properly includes that interval”; nor does it include any analogous text with respect to attribute PARTS. Indeed, you might have noticed that the sample value in Fig. 6.2 suffers—again deliberately, of course—from certain redundancies; for example, it tells us twice that supplier S3 was able to supply part P4 on days 1 to 4 inclusive. (The point is, of course, that if the predicate did include text of the form “and not throughout any interval that properly includes that interval,” then such redundancies couldn’t occur. We’ll have a lot more to say about such issues in later chapters—in Chapters 10 and 13 in particular.)
Aside: Actually, given the predicate as stated, the relation shown in Fig. 6.2 can’t possibly be a legitimate value for the relvar. At best it’s incomplete. The reason is as follows: Since the predicate does indeed not include text of the form “not throughout any interval that properly includes that interval,” it follows that if, e.g., the sole tuple shown for supplier S4 appears, then numerous additional tuples for supplier S4 ought by rights to appear as well: one saying supplier S4 supplies parts P3 and P4 on day 5, one saying supplier S4 supplies parts P3 and P4 on days 5 and 6, one saying supplier S4 supplies part P3 on days 5 and 6, and so on, for a grand total of 30 tuples altogether—and that’s just for supplier S4! For space reasons, however, we certainly don’t want to expand the figure to show all of those “missing” tuples; for simplicity, therefore, we adopt the fiction—where it makes any difference—that the relation shown in the figure does in fact constitute a legitimate value for the relvar after all. End of aside.
In the remainder of the book we’ll occasionally make use of examples based on relvar S_PARTS_DURING instead of our more usual relvar SP_DURING. Meanwhile, here are a few final points to close the present chapter:
■ Relvar S_PARTS_DURING has two interval attributes, but only one of them represents temporal intervals specifically. Here by contrast is a relvar (in outline) with two distinct interval attributes, both of them representing temporal intervals specifically:
EMP { ENO , PRIMARY , SECONDARY }
Here attributes PRIMARY and SECONDARY show the intervals of time during which the employee identified by ENO received his or her primary and secondary education, respectively.
■ Second, note that even if we had no relvars (like EMP or S_PARTS_DURING) with two or more interval attributes, we’d still need to be able to deal with relations—i.e., relation values—with two or more such attributes. For example, as soon as we join the two relations r1 {A,B} and r2 {A,C}, where B and C are interval attributes, we obtain a relation with two such attributes.
■ Third, we could extend the S_PARTS_DURING example to one with three interval attributes by replacing attribute SNO by an attribute SUPPLIERS showing supplier number ranges (assuming type SNO is also a legitimate point type, of course). Here’s a sample value:

In general, there’s obviously no reason why a relation (or a relvar) shouldn’t have any number of interval attributes. What’s more, it’s possible, as the foregoing example also demonstrates, to have a relation or relvar with interval attributes only (i.e., every attribute is of some interval type).
Exercises
6.1 State the predicates, as precisely as you can, for relvars S_DURING and SP_DURING from Fig. 6.1.
6.2 List as many advantages as you can think of in favor of replacing FROM-TO attribute pairs by individual DURING attributes.
6.3 Give some examples of your own of nontemporal intervals, over and above the ones listed earlier in the chapter.
6.4 Define the terms point type and interval type. Complete the following sentence in your own words: “Type T is usable as a point type if … .”
6.5 Is a singleton scalar type—i.e., one containing just a single scalar value—a valid point type? What about the empty scalar type (i.e., the scalar type containing no values at all, called omega in reference [51])?
6.6 Let i be an interval. What do the expressions BEGIN (i), END (i), and p ∈ i return?
6.8 Give a plausible predicate for the relation with three interval attributes shown at the end of the section “A More Searching Example.”
6.9 Give examples of your own of (a) a relation or relvar with two interval attributes; (b) a relation or relvar with three.
6.10 The following relvar definitions are for a considerably extended version of the courses-and-students database from Exercise 2.2 in Chapter 2:
VAR COURSE BASE RELATION
{ COURSENO COURSENO, CNAME NAME, AVAILABLE DATE }
KEY { COURSENO } ;
VAR CANCELED_COURSE BASE RELATION
{ COURSENO COURSENO, CANCELED DATE }
KEY { COURSENO }
FOREIGN KEY { COURSENO } REFERENCES COURSE ;
VAR STUDENT BASE RELATION
{ STUDENTNO STUDENTNO, SNAME NAME, REGISTERED DATE }
KEY { STUDENTNO, REGISTERED } ;
VAR UNREG_STUDENT BASE RELATION
{ STUDENTNO STUDENTNO, UNREGISTERED DATE }
KEY { STUDENTNO, UNREGISTERED } ;
VAR ENROLLMENT BASE RELATION
{ COURSENO COURSENO, STUDENTNO STUDENTNO, ENROLLED DATE }
KEY { COURSENO, STUDENTNO }
FOREIGN KEY { COURSENO } REFERENCES COURSE
FOREIGN KEY { STUDENTNO } REFERENCES STUDENT ;
VAR COMPLETED_COURSE BASE RELATION
{ COURSENO COURSENO, STUDENTNO STUDENTNO, COMPLETED DATE, GRADE GRADE }
KEY { COURSENO, STUDENTNO }
FOREIGN KEY { COURSENO } REFERENCES COURSE ;
The predicates are as follows:
■ COURSE: Course COURSENO, named CNAME, became available on date AVAILABLE.
■ CANCELED_COURSE: Course COURSENO ceased to be available on date CANCELED.
■ STUDENT: Student STUDENTNO, named SNAME, registered with the university on date REGISTERED.
■ UNREG_STUDENT: Student STUDENTNO left the university on date UNREGISTERED.
■ ENROLLMENT: Student STUDENTNO enrolled on course COURSENO on date ENROLLED.
■ COMPLETED_COURSE: Student STUDENTNO completed course COURSENO on date COMPLETED, achieving grade GRADE.
a. Assuming this database constitutes a record of the relevant part of a typical university’s business, what additional constraints (expressed in natural language) might be required?
b. Suppose we decide to add the following relvar, with the intent (eventually) of using it to replace relvar COMPLETED_COURSE:
VAR STUDIED BASE RELATION
{ COURSENO COURSENO, STUDENTNO STUDENTNO, DURING INTERVAL_DATE, GRADE GRADE }
KEY { COURSENO, STUDENTNO }
FOREIGN KEY { COURSENO } REFERENCES COURSE ;
The predicate is:
Student STUDENTNO studied course COURSENO throughout interval DURING (and not throughout any interval that properly includes that interval), achieving grade GRADE.
Write a query, using relvars ENROLLMENT and COMPLETED_COURSE, whose result corresponds to exactly this predicate (and can therefore usefully be assigned to relvar STUDIED).
c. Write a definition for a relvar called COURSE_AVAILABILITY that combines relvars COURSE and CANCELED_COURSE analogously to the way STUDIED combined relvars ENROLLMENT and COMPLETED_COURSE in part b. of this exercise.
d. Write a query that makes use of relvars STUDENT and UNREG_STUDENT to obtain the entire student registration history of the university. The heading of the result should look like this:
{ STUDENTNO STUDENTNO, SNAME NAME, REG_DURING INTERVAL_DATE }
The value of END (REG_DURING) for current registrations should be set to “the last day,” which we assume—see Chapter 7—can be denoted LAST_DATE ( ).
Answers
6.1 See the section “What’s an Interval?” in the body of the chapter.
6.2 See the section “What’s an Interval?” in the body of the chapter.
6.3 Here are some possibilities:
■ Intervals of exam scores, such as those determining grades for a course
■ Intervals of page numbers, such as those found in an index to a book
■ Intervals of chapter numbers, such as the constituent chapters of parts of a book
■ Intervals of latitude, such as those within which certain winds blow
■ Salary ranges, such as those agreed for different job levels
■ Intervals of house numbers such as, in some countries, those of buildings on the same block in some street
■ Intervals of letters of the alphabet, such as those indicating the contents of the different volumes of an encyclopedia
6.4 See the section “Point and Interval Types” in the body of the chapter.
6.5 Yes, a singleton scalar type is a valid point type, even though none of its values has a successor. Let PT be such a type, and let p be the sole value of that type. Then the first and last operators both return p, and the next and prior operators always fail. Note: The interval type INTERVAL_PT is a singleton type also, of course—it contains just the unit interval [p:p].
As for the empty scalar type, believe it or not, it too satisfies the requirements for a point type!—vacuously so, however, because if the point type is empty, then the corresponding interval type will necessarily be empty as well. Of course, the operators first, last, next, prior, BEGIN, END, and “∈” will all be undefined in this case.
6.6 See the section “Point and Interval Types” in the body of the chapter.
6.7 A unit interval is an interval i for which BEGIN (i) = END (i) is true.
6.8 Throughout the interval from the begin point of DURING to the end point of DURING, inclusive, every supplier SNO in the interval from the begin point of SUPPLIERS to the end point of SUPPLIERS, inclusive, was able to supply every part PNO in the interval from the begin point of PARTS to the end point of PARTS, inclusive.4
a. Here are some reasonable possibilities:
■ A course can be canceled only if it’s currently available.
■ A student can register only if he or she isn’t already registered.
■ A student can enroll in a course only if he or she is currently registered, the course is currently available, and he or she isn’t already enrolled in the course.
■ A student can become “unregistered” only if he or she is currently registered.
■ A student can complete a course only if the student is currently enrolled in the course.
Note that the following constraint doesn’t need to be added, because it’s implied by the KEY specification for relvar COURSE:
■ A course can become available only if it’s not already available.
b. (EXTEND ( ENROLLMENT JOIN COMPLETED_COURSE ) :
{ DURING := INTERVAL_DATE ( [ ENROLLED : COMPLETED ] ) } ) { COURSENO, STUDENTNO, DURING, GRADE }
Note: The expression INTERVAL_DATE ( [ ENROLLED:COMPLETED ] ) here is an interval selector invocation (see Chapter 7).
c. VAR COURSE_AVAILABILITY BASE RELATION
{ COURSENO COURSENO , CNAME NAME , DURING INTERVAL_DATE }
KEY { COURSENO } ;
d. WITH ( t1 := EXTEND STUDENT : { UNREGISTERED := LAST_DATE ( ) } { STUDENTNO , UNREGISTERED } ,
t2 := t1 UNION UNREG_STUDENT,
t3 := t2 JOIN STUDENT,
t4 := t3 WHERE UNREGISTERED ≥ REGISTERED,
t5 := EXTEND t4 { STUDENTNO, SNAME, REGISTERED } : { UNREGISTERED := MIN ( !!t4, UNREGISTERED ) },
t6 := EXTEND t5 : { REG_DURING := INTERVAL_DATE ( [ REGISTERED : UNREGISTERED ] ) } :
t6 { STUDENTNO, SNAME, REG_DURING }