
Autoencoders like PCA can be used for dimensionality reduction, but while PCA can only represent linear transformations, we can use nonlinear activation functions in autoencoders, thus introducing non-linearities in our encodings. Here is the result reproduced from the Hinton paper, Reducing the dimensionality of data with Neural Networks. The result compares the result of a PCA (A) with that of stacked RBMs as autoencoders with architecture consisting of 784-1000-500-250-2:
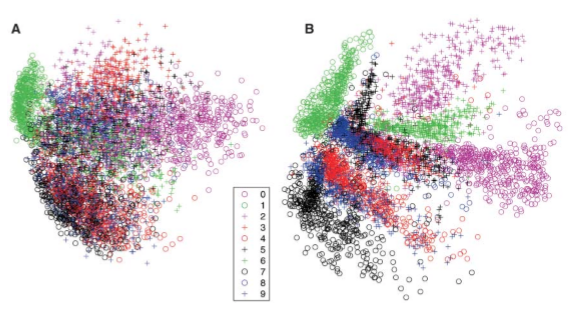
As we will see later when an autoencoder is made using stacked autoencoders, each autoencoder is initially pretrained individually, and then the entire network is fine-tuned for better performance.