
9
Architectures with Bus-Based Switch Fabrics: Case Study—Cisco Catalyst 6500 Series Switches with Supervisor Engine 32
9.1 Introduction
The Cisco Catalyst 6500 is a family of switch/routers supporting a range of Supervisor Engine and line card options. The older generation of the Cisco Catalyst 6500 supports Supervisor Engines 1A or 2 and two backplanes. One backplane is a 32 Gb/s shared switching bus for interconnecting line cards within the switch/router, and the another backplane allows line cards to interconnect over a high-speed crossbar switch fabric.
The crossbar switch fabric provides each connecting module with a set of distinct high-speed switching paths for data transmission to and data reception from the crossbar switch fabric. This first generation switch fabric (implemented in a stand-alone switch fabric module) provides a total switching capacity of 256 Gb/s.
The newer generation Catalyst 6500 was introduced with the newer high-performing Supervisor Engines 32 and 720 that have advanced features beyond the Supervisor Engines 1A and 2 [CISC6500DS04, CISCCAT6500]. The discussion in this chapter focuses on the architectures of the Catalyst 6500 Series with Supervisor Engine 32. The Supervisor Engine 32 provides connectivity only to the 32 Gb/s shared switching bus and, as a result, supports only line cards that connect to this switching bus. These line card types are the “classic” (also called nonfabric-enabled) and CEF256-based line cards.
By supporting these line card types, the higher performing Supervisor Engine 32 provides investment protection to users who have already deployed Cisco Catalyst 6500 modules that connect to the 32 Gb/s backplane. The Supervisor Engine 32 protects current 32 Gb/s-based switch investments by supporting all existing “classic” and CEF256-based line cards.
As will be described below, the Supervisor Engine 32 has two uplink options: eight-port Gigabit Ethernet (GbE) Small Form Pluggable (SFP)-based uplinks and two-port 10 GbE XENPAK-based uplinks. The Catalyst 6500 with Supervisor Engine 32 is designed primarily for deployment at the network access layer.
Adopting the architecture categories broadly used to classify the various designs in Chapter 3, the following architectures are covered in this chapter:
- Architectures with bus-based switch fabrics and centralized forwarding engines (see Figure 9.1):
- - Architectures with “Classic” line cards.
- - Architectures with CEF256 line cards (optional Distributed Forwarding Card (DFC) not installed).
- Architectures with bus-based switch fabrics and distributed forwarding engines (see Figure 9.2):
- - Architectures with CEF256 line cards with optional DFC installed.

Figure 9.1 Bus-based architecture with routing and forwarding engines in separate centralized processors.

Figure 9.2 Bus-based architecture with fully distributed forwarding engines in line cards.
9.2 Cisco Catalyst 6500 32 Gb/s Shared Switching Bus
The 32 Gb/s switching bus allows all the modules connected to it to share the common bandwidth available for both data transmission and data reception. As described in Chapter 7, the shared bus consists of three (sub-)buses, each playing a specific role in the data forwarding operation in the system. These buses are the Data Bus (DBus), Results Bus (RBus), and the Control Bus (CBus).
The DBus is the main system bus that carries all end-user data transmitted and received between modules. It has a bandwidth of 32 Gb/s (i.e., 2 × 256 bits wide × 62.5 MHz clock speed). The “32 Gb/s” in the name of the switching bus comes from this data transfer rate. The DBus is a shared bus, so to transmit a packet, a line card must arbitrate for access to the DBus by submitting a transmit request to a master arbitration mechanism that is located on the Supervisor Engine (or primary Supervisor Engine if a redundant Supervisor Engine is installed).
If the DBus is not busy, the master arbitration mechanism grants access permitting the line card to transmit the packet on the DBus. With this bus access permission, the line card transmits the packet over the DBus to the Supervisor Engine. During the packet transfer over the DBus, all connected line cards will sense the packet being transmitted and capture a copy of the packet into their local buffers.
The Supervisor Engine uses the RBus to forward the forwarding instructions (obtained after forwarding table lookup) to each of the attached line cards. The forwarding instruction sent by the Supervisor Engine to each line card is either a drop or forward action. A drop action means a line card should flush the packet from its buffers, and a forward action means the packet should be sent out a port to its destination. The CBus (or Ethernet out-of-band channel (EOBC)) is the bus that carries control information between the line cards and the control and management entity on the Supervisor Engine.
9.2.1 Main Features of the Catalyst 6500 Shared Bus
The Cisco Catalyst 6500 shared switching bus employs two methods to achieve improved performance over the traditional shared bus: pipelining and burst mode.
9.2.1.1 Pipelining Mode
The traditional implementation of the shared bus allows a single frame transmission over the shared bus at any given point in time. Let us consider the situation where the system employs a traditional shared bus. The Supervisor Engine receives a packet from a line card and performs a lookup into its local forwarding table to determine which line card port the packet should be forwarded to. It sends the result of the forwarding table lookup to all ports connected to the shared bus over the RBus.
In the traditional implementation, while the table lookup is being performed, no subsequent packets are sent over the bus. This means there are some idle times in data transfers over the bus resulting in suboptimal use of the bus – Bus utilization is not maximized.
The Catalyst 6500 employs pipelining to allow ports to transmit up to 31 frames across the shared bus (to be pipelined at the Supervisor Engine for lookup operation) before a lookup result is transmitted via the RBus. If it happens that there is a 32nd packet to be transmitted, it will be held locally at the transmitting port until the port receives a result over the RBus. Pipelining allows the system to reduce the idle times that would have been experienced in the traditional bus implementation and also provides improvements in the overall utilization of the shared bus architecture.
9.2.1.2 Burst Mode
Another concern in the use of traditional shared bus is that the bus usage could unfairly favor ports transmitting larger frames. Let us consider, for example, two ports that are requesting access to the shared bus. Let us assume that Port A is transmitting 512 byte frames and Port B is transmitting 1518 byte frames. Port B would gain an unfair bus usage advantage over Port A when it sends a sequence of frames over a period of time because it consumes relatively more bandwidth in the process. The Catalyst 6500 uses the burst mode feature to mitigate this kind of unfairness.
To implement the burst mode feature, the port ASIC (which handles access to the shared bus) maintains a count of the number of bytes it has transmitted and compares this with a locally configured threshold. If the byte count is below the threshold, then a packet waiting to be transmitted can be forwarded. If the byte count exceeds the threshold, then the port ASIC stops transmitting frames and bus access is removed for this port (done by the master arbitration mechanism in the Supervisor Engine). The threshold is computed by the port using a number of local variables extracted from the system (see related discussion in Chapter 7) in order to ensure fair distribution of bus bandwidth.
9.3 Supervisor Engine 32
The Supervisor Engine is the main module in the Catalyst 6500 responsible for all centralized control plane and data plane operations. The control plane is responsible for running the routing protocols and generating the routing table that contains the network topology information (location of each destination IP address in the network). Each destination IP address in the routing table is associated with a next hop IP address, which represents the next closest Layer 3 device or router to the final destination. The contents of the routing table are distilled into a much compact and simple table called the forwarding table.
The data plane is responsible for the operations that are actually performed on a packet in order to forward it to the next hop. These operations involve performing a forwarding table lookup to determine the next hop address and egress interface, decrementing the IP TTL, recomputing the IP checksum, rewriting the appropriate source and destination Ethernet MAC addresses in the frame, recomputing the Ethernet checksum, and then forwarding the packet out the appropriate egress interface to the next hop. Control plane functions are typically handled in software, whereas data plane functions are simple enough to be implemented in hardware, if required.
9.3.1 Supervisor Engine 32 Architecture
The Supervisor Engine 32 has connectivity only to the 32 Gb/s shared bus and supports packet forwarding of up to 15 Mpps [CISCSUPENG32]. Unlike the Supervisor Engines 2 and 720, Supervisor Engine 32 does not provide connectivity to a crossbar switch fabric, as illustrated in Figures 9.3 and 9.4. As shown in these figures, Supervisor Engine 32 supports the PFC3B and MSFC2a as a default configuration.

Figure 9.3 Supervisor Engine 32-8GE baseboard architecture.
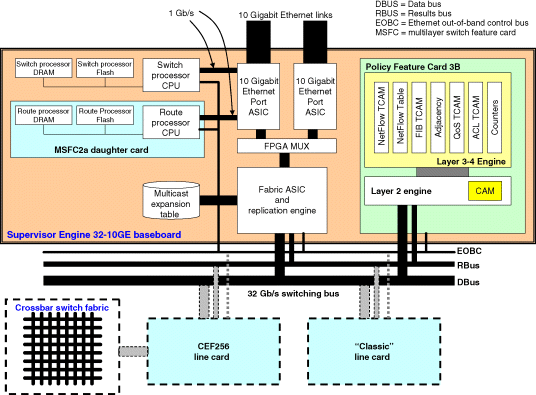
Figure 9.4 Supervisor Engine 32-10GE baseboard architecture.
The Supervisor Engine 32 comes in two versions:
- Supervisor Engine 32-8GE: This Supervisor Engine option supports 8 GbE Small Form-Factor Pluggable uplink ports (see Figure 9.3).
- Supervisor Engine 32-10GE: This Supervisor Engine option supports 2 × 10 GbE uplink ports (see Figure 9.4).
These Supervisor Engines also support an additional 10/100/1000TX front port and two USB ports on the front panel (type A and type B USB port). The type A USB port, which is designated for host use, can be used to plug in devices such as a laptop or PC. The type B is designated as a device port and can be used for attaching devices such as a Flash memory key.
A chassis that supports redundancy with two Supervisor Engine 32-8GE modules provides a total of 18 active Gigabit Ethernet ports (i.e., 2 × (8 +1) ports) to the user, where all ports on both the primary and secondary Supervisor Engines are active.
9.3.2 Multilayer Switch Feature Card 2a (MSFC2a)
The MSFC2a provides Layer 3 control plane functionality that enables the Supervisor Engine 32 to function as a full-fledged Layer 3 device. Without the MSFC2a, the Supervisor Engine 32 will function purely as a Layer 2 device. Forwarding using network topology-based forwarding tables and optimized lookup algorithms (called CEF (Cisco Express Forwarding)) is the forwarding architecture implemented in the Supervisor Engine 32. The MSFC2a and the MSFC2 used in the Supervisor Engine 2 (see Chapter 7) are functionality equivalent, except the MSFC2a uses a bigger DRAM.
In the Supervisor Engine 32, a Switch Processor CPU, as shown in Figures 9.3 and 9.4, is responsible for running all the Layer 2 control plane protocols, such as Spanning Tree Protocol (STP), IEEE 802.1AB Link Layer Discovery Protocol (LLDP), and VLAN Trunking Protocol (VTP). The Switch Processor is allocated its own (upgradeable) DRAM and nonvolatile RAM (NVRAM).
A route processor CPU on the MSFC2a (Figures 9.3 and 9.4) is responsible for running the Layer 3 routing protocols and ICMP, carrying out address resolution functions to map IP addresses to Layer 2 addresses, initializing and managing switched virtual interfaces (SVIs), and running and configuration of the Cisco IOS Software. An Ethernet out-of-band control bus (a full duplex, 1 Gb/s in-band connection) shown in Figures 9.3 and 9.4) enables the MSFC2a to communicate and exchange information with other entities on the Supervisor Engine 32 baseboard.
The MSFC2a communicates with its Layer 3 peers in a network (via the configured routing protocols (Open Shortest Path First (OSPF), Enhanced Interior Gateway Routing Protocol (EIGRP), border Gateway Protocol (BGP), etc.) and generates routing information about the network topology (which is maintained in the routing table). The MSFC2a then distills this routing information to generate a more compact forwarding table or FIB, which is then forwarded to the PFC3B.
The PFC3B stores the forwarding table in a FIB ternary content addressable memory (TCAM). As shown in Figures 9.3 and 9.4, the FIB TCAM is implemented on the PFC3B daughter card and is a very high-speed memory that allows the PFC3B to perform fast forwarding table lookups during packet forwarding. The Layer 3 features that are supported on a Supervisor Engine 32 are described in more detail in [CISCSUPENG32].
As with the Supervisor Engine 720, the Supervisor Engine 32 also implements hardware counters, registers, and control plane policing (CoPP) (of control plane traffic) to limit the effect of denial of service (DoS) attacks on the control plane. The hardware-based control plane policing allows a control plane quality of service (QoS) policy to be applied to the Supervisor Engine 32 in order to limit the total amount of traffic that is sent to its control plane.
9.3.3 Policy Feature Card 3B (PFC3B)
The PFC3B (Figures 9.3 and 9.4) supports hardware-based features that allow the Supervisor Engine 32 to perform more enhanced QoS and security operations. For example, to secure and prioritize data, the PFC3B provides hardware support for security and QoS-based ACLs using Layer 2, 3, and 4 classification criteria. The PFC3B also allows the Supervisor Engine 32 to support new hardware accelerated features such as ACL hit counters, port access control lists (PACLs), Enhanced Remote Switched Port Analyzer (ERSPAN), CPU rate limiters, IP Source Guard, and NetFlow capacities:
- ACL Hit Counters: ACL hit counters allow a network administrator to monitor how many times (i.e., hits) a specific access control entry (ACE) within an ACL has been applied as traffic pass through the device port or interface. The ACE hit patterns (number of hits) provide the user with additional information that can be used to fine-tune the ACLs to be more effective for the traffic the ACLs are applied to.
- Port ACLs (PACLs): A PACL is an ACL that can be applied at a single port on a Layer 2 switch within a VLAN (i.e., physical switch port or trunk port that belongs to a specific VLAN). It provides a functionality similar to a VLAN ACL (VACL), but unlike a VACL (which when applied, extends and covers an entire VLAN), the PACL is applied only to a single port within a VLAN. The PACL can be applied at the ingress of a switch port to screen ingress traffic and is processed before any VACLs that may be applied to the switch port.
- Enhanced Remote SPAN (ERSPAN): The switched port analyzer (SPAN) feature (also referred to as port mirroring or port monitoring) is a feature that can be applied to a switch port to copy or sample traffic to be examined and analyzed by a network traffic analyzer such as a Remote Monitoring (RMON) probe. ERSPAN allows a switch to forward a copy of traffic passing through a switch port to a destination SPAN port that may be located in another network reachable over multiple Layer 3 hops. For example, ERSPAN can be applied on a switch port located in one IP subnet while the destination SPAN port is located in another subnet. ERSPAN uses the tunneling protocol, generic routing encapsulation (GRE), to carry the traffic over the Layer 3 network to the destination SPAN port.
- CPU Rate Limiting: The control plane provides a critical set of functions to a switch, switch/router, or router. CPU rate limiters are rate-limiting mechanisms that can be applied to different traffic types sent to the control plane of the switch, switch/router, or router. The CPU rate limiters in Supervisor Engine 32 are designed to protect the performance of the Layer 3 control plane (or route processor) from being overwhelmed or overloaded with unnecessary or DoS traffic. From a performance perspective, implementing CPU rate limiters in hardware further strengthens the Supervisor Engine 32 from high-speed attacks that can compromise the performance of the system. The Layer 2, 3, and application rate limiters as well as unicast and multicast rate limiters are listed in [CISCSUPENG32].
- Bidirectional Protocol-Independent Multicast (BIDIR-PIM): BIDIR-PIM allows the network nodes involved in multicast traffic distribution to construct bidirectional multicast distribution trees, which support bidirectional traffic flow. BIDIR-PIM provides an alternative multicast distribution model to the other PIM distribution models (PIM Dense Mode (PIM-DM), PIM Sparse Mode (PIM-SM), PIM Source-Specific Multicast (PIM-SSM)) and is designed to support many-to-many multicast communications within a single PIM domain. BIDIR-PIM also reduces or lessens the amount of PIM forwarding state information that a multicast router must maintain (in its multicast forwarding table), a feature that is particularly important during many-to-many multicast transfers with many and widely spread out data senders and receivers. The BIDIR-PIM shared trees provide a valuable feature in that many multicast sources can transmit on the same shared tree without the multicast routers having to explicitly maintain state for each source. This feature also provides the added benefit of reduced processing load on the Supervisor Engine's CPU and memory.
- IP Source Guard: Spoofing attacks occur when a client that is unknown or untrusted floods a network with malicious packets that are intended to harm the operations of the network. Often the clients in these attacks utilize source IP address spoofing to hide the true source of the attack. Hackers often use spoofed packets to gain access into a network by changing their true source IP address to one that is recognized by the network as a genuine internal or secure address. IP Source Guard is a method that can be used to provide protection against spoofed packets. Using Dynamic Host Configuration Protocol (DHCP) snooping, IP Source Guard snoops on DHCP requests and constructs a dynamic PACL (Port ACL) that is applied to incoming traffic to deny all packets that do not match the assigned DHCP address. The PACL is applied at an interface of the device running the IP Source Guard feature.
Other QoS services supported on the PFC3B include ingress traffic policing and classification of incoming data. This allows the rewrite of IEEE 802.1p class of service (CoS) bits in the Ethernet header and IP Precedence/DSCP priority bits in the IPv4 header.
9.3.4 Supervisor Engine 32 as a “Classic” Module
The Supervisor Engine 32 is also referred to as a “Classic” module (see Chapter 7) because it supports connectivity only to the “Classic” 32 Gb/s shared switching bus that allows it to communicate with other line cards connected to the bus. The Supervisor Engine 32 also has no built-in crossbar switch fabric (as in other Supervisor Engines like Supervisor Engine 720), nor does it support connectivity to a separate crossbar switch fabric module (like in Supervisor Engine 2).
The support of only the Classic (32 Gb/s) shared bus thus dictate the type of line cards that can operate with the Supervisor Engine 32. Line cards that do not support connectivity over the Classic 32 Gb/s shared bus cannot be used with the Supervisor Engine 32.
A full list of the line card architectures supported with the Supervisor Engine 32 is given in [CISCSUPENG32]. As explained below, the Supervisor Engine 32 supports both the CEF256 and Classic line card architectures. Both of these line cards have a connector on the line card that provides connectivity to the Classic 32 Gb/s bus.
The 32 Gb/s shared bus allows all ports connected (on both the Supervisor Engine 32 and line cards) to exchange data. The DBus is 256 bits wide and is clocked at 62.5 MHz, which yields bandwidth of 16 Gb/s. The RBus also operates at 62.5 MHz and is 64 bits wide.
9.3.5 Fabric ASIC and Replication Engine
The Supervisor Engine 32 baseboard (Figures 9.3 and 9.4) has a number of onboard application-specific integrated circuits (ASICs) that enable the support of Layer 2, 3, and 4 services and also serves as an interface to the 32 Gb/s shared switching bus. One ASIC is used to connect the Supervisor Engine to the 32 Gb/s shared switching bus. This specialized ASIC (referred to as the Fabric ASIC and Replication Engine) is also used for multicast packet replication in the Supervisor Engine 32 and supports the SPAN functionality used for port mirroring.
The Supervisor Engine 32 via the Fabric ASIC and Replication Engine supports only ingress replication mode of multicast packets. As shown in Figures 9.3 and 9.4, the Fabric ASIC and Replication Engine also provides an interface to the multicast expansion table (MET), which supplies the Supervisor Engine 32 with the relevant information regarding the multicast group membership it serves. Another onboard port ASIC holds the port interface logic that provides connectivity to the 9 GbE ports (Figure 9.3) or the two 10 GbE ports (Figure 9.4).
9.4 Catalyst 6500 Line Cards Supported by Supervisor Engine 32
The Cisco Catalyst 6500 supports a number of line card types with different physical media types and speed options. These line cards are designed with a range of features to allow the Catalyst 6500 to meet the needs of deployment in the access, distribution, and core layers of a network. A line card slot may provide a connection to the 32 Gb/s shared bus and in some designs, another connection to a crossbar switch fabric if either a Supervisor Engine 2 or 720 is present.
The Catalyst 6500 supports four general line card types, that is, the Classic, CEF256, CEF720, dCEF256, and dCEF720 line cards [CISCCAT6500]. All of these line cards can interoperate and communicate with each other when installed in the same chassis as long as the relevant fabric connections are present in the chassis. The Catalyst 6500 with Supervisor Engine 32 supports only the line cards that have connectivity to the 32 Gb/s shared bus – the Classic and CEF256 line cards.
9.4.1 Classic Line Card Architecture
The Classic line card (also called the nonfabric-enabled line card (see discussion in Chapter 7)) supports connectivity only to the 32 Gb/s shared switching bus. It has a shared bus connection only and no connection to a stand-alone or Supervisor Engine integrated crossbar switch fabric. Furthermore, it does not support packet forwarding locally in the line card (i.e., distributed forwarding).
All generations and versions of the Supervisor Engines, from the Supervisor Engine 1A through to the newer Supervisor Engine 720-3BXL, support the Classic line cards. A Classic line card when installed in a Cisco Catalyst 6500 chassis does not allow the line cards to operate in compact (switching) mode (see bus switching modes discussion below). Thus, with the presence of this line card, the centralized forwarding rate of the PFC3B reaches only 15 Mpps.
9.4.2 CEF256 Line Card Architecture
Figure 9.5 shows the architecture of the CEF256 line card. The CEF256 line card is a fabric-enabled line card and supports one connection to the 32 Gb/s shared switching bus and another connection to the crossbar switch fabric [CISCCAT6500]. The connection to the crossbar switch fabric is a single 8 Gb/s fabric channel.

Figure 9.5 Cisco Express Forwarding Line Card Architecture (CEF256 Line Card).
The line card also supports a single internal 16 Gb/s local shared switching bus over which local packets are forwarded. The 16 Gb/s local shared switching bus has a similar function and operation as the main chassis 32 Gb/s shared bus. The chassis 32 Gb/s shared bus is the main bus that connects all shared switching bus capable line cards (i.e., the nonfabric-enabled and fabric-enabled line cards) in the Cisco Catalyst 6500 chassis.
The 16 Gb/s local switching bus on the CEF256 line card is utilized for forwarding packets that have port destinations local within the line card. Using this bus, a packet that is to be forwarded locally (utilizing an optional DFC or DFC3a to determine the forwarding destination) avoids being sent over the 32 Gb/s shared bus or the crossbar switch fabric. This local forwarding capability reduces the overall latency of forwarding packets and frees up the chassis 32 Gb/s shared bus or crossbar switch fabric capacity for those line cards that cannot forward packets locally.
As shown in Figure 9.5, the CEF256 line card supports internally a fabric Interface ASIC, which serves as the interface between the local ports on the line card and other modules connected to the crossbar switch fabric. The fabric Interface ASIC also allows line card to connect to the 32 Gb/s shared switching bus.
The CEF256 line cards will use the crossbar switch fabric for forwarding packets to other modules when it is installed in a chassis with a Supervisor Engine 720. However, if a Supervisor Engine 32 is installed, the system will fall back to using the 32 Gb/s shared switching bus since the Supervisor Engine 32 supports connectivity only to the 32 Gb/s shared switching bus.
9.5 Cisco Catalyst 6500 32 Gb/s Shared Switching Bus Modes
We describe here the three switching modes used by the 32 Gb/s shared switching bus and fabric interface ASICs in the CEF256 and CEF720 line cards [CISCCAT6500]. The switching modes define the format of the internal packet header or forwarding tag used to transfer data across the DBus (of the 32 Gb/s shared switching bus) and also communicate with other CEF256 and CEF720 modules in the chassis. These switching modes do not apply to line cards that support Distributed Forwarding Card (DFC) feature.
9.5.1 Flow-Through Mode
The Flow-Through mode of operation is used by the CEF256 (fabric-enabled) line cards when a crossbar switch fabric is not present in the chassis. This mode enables CEF256 line cards to operate in the system and over only the 32 Gb/s shared bus as if they were Classic (nonfabric-enabled) line cards. This mode does not apply to the dCEF256, CEF720, and dCEF720 line cards because they do not support connectivity to the 32 Gb/s shared bus.
In this mode, the whole (original) packet (i.e., the original packet header and data) is forwarded by the CEF256 line card over the 32 Gb/s shared bus to the Supervisor Engine for forwarding table lookup and forwarding to the destination port. In the flow-through mode, the Catalyst 6500 achieves a centralized forwarding rate of up to 15 Mpps.
9.5.2 Compact Mode
For a system to operate in the compact mode, the system must support a crossbar switch fabric in addition to the 32 Gb/s shared switching bus. The crossbar switch fabric can be realized in the form of a stand-alone switch fabric module (installed in a chassis slot) or a Supervisor Engine 720 (which has an integrated crossbar switch fabric). The line cards in the chassis must all be fabric enabled (i.e., CEF256) for the system to run in compact mode.
Classic line cards (which do not have a crossbar switch fabric connection), when installed in the chassis, will not allow the system to operate in compact mode. Note that the dCEF256, CEF720, and dCEF720 line cards do not have connections to the 32 Gb/s shared bus.
In compact mode, a line card will send only the (original) packet header over the DBus of the 32 Gb/s shared bus to the Supervisor Engine for processing. To conserve DBus bandwidth and to allow for faster header transmission, the original packet header is compressed before to being transmitted on the DBus. The line card transmits the data portion of the packet over the crossbar switch fabric channels to the destination port. In this mode, the system achieves (independent of packet size) a centralized forwarding rate of up to 30 Mpps.
9.5.3 Truncated Mode
The truncated mode is used when the chassis has the following three module types present: a crossbar switch fabric, CEF256 and/or CEF720 line cards, and Classic line cards. When operating in this mode, the Classic line cards will forward over the DBus of the 32 Gb/s shared bus to the Supervisor Engine, the header, plus the data portion of the (original) packet. The CEF256 and CEF720 line cards, on the other hand, will forward the packet header over the DBus and the data portion over the crossbar switch fabric.
In the truncated mode, the system achieves a centralized forwarding rate up to 15 Mpps. Furthermore, in this mode, because the CEF256 and CEF720 line cards transmit the data portion of the packet over the crossbar switch fabric, the overall aggregate bandwidth achieved can be higher than the 32 Gb/s shared switching bus capacity. However, the performance of line cards that have the DFC feature is not affected by the truncated mode – the forwarding performance stays the same and does not change regardless of the line card mix in the system.
9.6 Supervisor Engine 32 QoS Features
We review in this section the queue structures and QoS features on the uplink ports (Figures 9.3 and 9.4) of the Supervisor Engine 32 [CISCSUPENG32].
9.6.1 Uplink Port Queues and Buffering
The transmit side of each Gigabit Ethernet uplink port (see Figure 9.3) is assigned a single strict priority queue and three normal (lower priority) queues. Each of these normal transmit queues supports eight queue fill thresholds, which can be used with a port congestion management algorithm for congestion control. The receive side is assigned two normal queues, each with eight queue fill thresholds for congestion management. There receive side has no strict priority queue.
Each of the Ethernet uplink ports on the Supervisor Engine 32 Gigabit (Figure 9.3) is allocated 9.5 MB of per port buffering. The 10 GbE ports (Figure 9.4), on the other hand, are assigned 100 MB of per port buffering. The provision of large per port buffering is of particular importance when the switch is operating in networks that carry bursty applications or high data volume applications (e.g., long flow TCP sessions, network video, etc.). With large buffering per port, these applications can use the extra buffering should the data transfers become very bursty.
9.6.2 DSCP Transparency
Both the Supervisor Engine 32 and Supervisor Engine 720 support a feature called differentiated services code point (DSCP) transparency. DSCP transparency is a feature that allows the switch to maintain the integrity of the DSCP bits carried in a packet as it transits the switch. Let us consider the situation where a packet arrives on a switch port carrying traffic that is not trusted (an untrusted port) and the switch assigns a lower class-of-service (CoS) value to the packet.
From this incoming CoS value, the switch derives an internal priority value that is used to write the DSCP bits on egress. DSCP transparency prevents this situation, and similar ones, by not allowing the switch to use the internal priority to derive the egress DSCP value. Instead, the switch will simply write the ingress DSCP value on egress.
When DSCP transparency is not used, the DSCP field in an incoming packet will be modified by the switch, and the DSCP field in the outgoing packet will be modified based on the port QoS settings that may include the policing and marking policies configured, port trust level setting, and the DSCP-to-DSCP mutation map configured at the port.
On the other hand, if DSCP transparency is used, the DSCP field in the incoming packet will not be modified by the switch, and the DSCP field in the outgoing packet will not be modified and stays unchanged – The value is the same as that in the incoming packet. It is worth noting that regardless of whether DSCP transparency is used or not, the switch will still use an internal DSCP value for the packet, which it uses for internal traffic processing to generate a CoS value that reflects the priority of the traffic. The internal DSCP value is also used by the switch to select an egress queue and queue fill threshold for the outgoing packet.
9.6.3 Traffic Scheduling Mechanisms
Two important scheduling mechanisms that can be used on the Supervisor Engine 32 GbE uplink ports (Figure 9.3) are the shaped round-robin (SRR) and deficit weighted round-robin (DWRR) algorithms. SRR allows the maximum amount of bandwidth that each queue is allowed to use to be defined. SRR like DWRR requires a scheduling weight to be configured for each of the queues, but the weight values are used differently in SRR.
After the scheduling weights are assigned to all queues, the SRR algorithm normalizes the total of the weights to 1 (or equivalently, 100%). Then a maximum bandwidth value is derived from the normalized values and assigned to each queue. The flow of data out of the queue will then be shaped to not exceed this (maximum) bandwidth value. But unlike DWRR, each queue that is shaped will not be allowed to exceed the maximum bandwidth value computed from the normalized weights. With SRR, traffic in excess of the maximum bandwidth value will be buffered and scheduled resulting in the traffic appearing to have a smoothing output over a given period of time.
The DWRR algorithm, on the other hand, aims to provide a fairer allocation of bandwidth between the queues than when the ordinary weighted round-robin (WRR) is used. The weights in DWRR determine how much bandwidth each queue is allowed to use, but, in addition, the algorithm maintains a measure or count of excess bandwidth each queue has used.
To understand the DWRR algorithm, let us consider, for example, a queue that has used up all but 500 bytes of its allocation, but has another packet in the queue that is 1500 bytes in size. When this 1500 packet is scheduled, the queue has consumed 1000 bytes of bandwidth in excess of its allocation on that scheduling round. The DWRR algorithm works by recognizing that an extra 1000 bytes has been used and deducts this (excess bytes) from the queue's bandwidth allocation in the next scheduling round. When the operation of the DWRR algorithm is viewed over a period of time, all the queues will on average be served closer to their allocated portion of the overall bandwidth.
9.7 Packet Flow Through Supervisor Engine 32
This section describes how a packet is forwarded through the Supervisor Engine 32. The steps involved in forwarding packets over the shared bus are described below and are also marked in Figures 9.6 and 9.7.

Figure 9.6 Packet Flow through the Supervisor Engine 32 – Steps 1–6 of the packet flow.
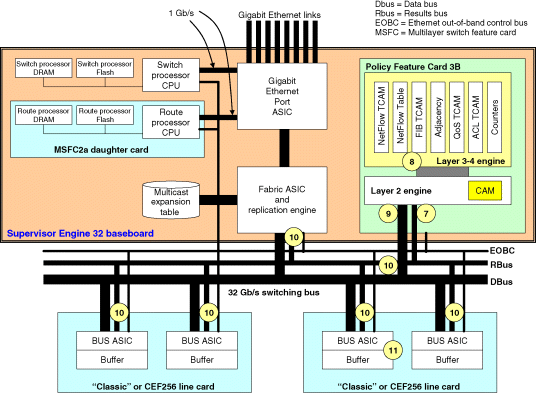
Figure 9.7 Packet flow through the Supervisor Engine 32 – Steps 7–11 of the packet flow.
Step 1: Packet Enters an Input Port on the Switch from the Network
- A packet from the network enters a port on a Classic or CEF256 line card and is temporarily stored in an input buffer.
- Based on the arriving packet header information, the port BUS ASIC constructs an internal tag or header carrying information that the centralized Supervisor Engine 32 forwarding engine will use to forward the packet.
- This information will be used by the Supervisor Engine 32 to perform lookup in its forwarding table and also apply any necessary QoS and security policies. All the necessary ingress QoS policies can also be applied here if configured.
Step 2:– Ingress Port Arbitrates for Access to 32 Gb/s Shared Switching Bus
- The port BUS ASIC on the ingress line card arbitrates for access to the 32 Gb/s shared bus to enable it transmit the packet to the Supervisor Engine 32.
- Each line card has a local arbitration mechanism that allows the line card to communicate and send bus access requests to the central arbitration mechanism located on the Supervisor Engine 32.
Step 3:– Access Granted to 32 Gb/s Shared Bus
- If the 32 Gb/s shared bus is idle, the central arbitration mechanism on the Supervisor Engine 32 will grant access to the bus (by forwarding a grant or permit message to the local arbitration mechanism on the line card indicating that it is allowed to transmit).
Step 4: Ingress Port Forwards Packet over the 32 Gb/s Shared Bus
- When the local arbitration mechanism on the ingress line card receives the grant message from the central arbitration mechanism on the Supervisor Engine 32, the port BUS ASIC transmits the packet on the 32 Gb/s shared bus.
Step 5: Packet Received by the Supervisor Engine 32
- The port BUS ASIC forwards the packet over the 32 Gb/s shared bus to the Supervisor Engine 32 and is received by the Layer 2 forwarding engine located on the PFC3B.
Step 6: All Line Cards Connected to the 32 Gb/s Shared See the Transmitted Packet
- Given that the 32 Gb/s shared bus is a shared medium, all other line cards connected to this shared bus will sense the transmitted packet and copy the packet temporarily in their transmit buffers.
- This packet will be stored in the transmit buffers of the line cards until the Supervisor Engine 32 informs the line cards to either drop or forward the packet out to the network.
Step 7: Layer 2 Forwarding Engine in the PFC3B Processes the Packet
- The Layer 2 forwarding engine on the PFC3B receives the packet and performs a lookup in its Layer 2 forwarding table using the destination MAC address in the packet.
- After this Layer 2 operation, the packet is passed on to the Layer 3 forwarding engine (on the PFC3B) for further processing.
Step 8: Layer 3 Forwarding Engine in the PFC3B Processes the Packet
- The Layer 3 forwarding engine on the PFC3B then executes a number of tasks in parallel in order to forward the packet.
- Upon system start-up and initialization, the MSFC2a continues to run the routing protocols and populate the FIB TCAM located on the PFC3B that maintains a view of the network topology. The FIB is generated from the master routing tables created by the routing protocols running on the MSFC2a.
- The PFC3B Layer 3 forwarding engine would perform a FIB lookup if the packet forwarding operation demands a Layer 3 forwarding operation.
- In parallel to the Layer 3 lookup process, lookups are also performed in the QoS TCAM and security ACL TCAM to determine if any of the QoS and ACLs configured need to be applied to this packet.
- If necessary, the PFC3B will also update NetFlow statistics for the flow that this packet belongs to.
Step 9: PFC3B Generates Lookup Results
- The PFC3B assembles the results of all lookup operations that contain the following key information:
- - Instructions to the egress line cards to either drop or forward the packet.
- - MAC rewrite information to be used by the egress line cards to modify the Layer 2 MAC destination address (corresponding to the next hop IP address) so that the packet can be sent to its correct next hop node
- - QoS information instructing the egress line cards to store the packet into the correct output port queue and any rewrite information needed for modifying outgoing DSCP values
Step 10: PFC3B Forwards Lookup Results over the RBus to Egress Line Cards
- The PFC3B forwards the result of the lookup operation over the RBus to all destination line cards and ports.
Step 11: Destination Ports Receive Lookup Results from the PFC3B
- The line cards and destination ports receive (over the RBus) the results information from the PFC3B and use this information to construct the Ethernet frame header for the outgoing packet.
- The reconstructed packet is extracted from the destination port's local transmit buffer and transmitted out the egress interface to the network.