
Chapter 9. Technical Practices
New titles, roles, and responsibilities aren’t the only changes Scrum teams are asked to make. For a Scrum team to be truly successful, it must go beyond adopting the basic, highly visible parts of Scrum and commit to real changes in the way it approaches the actual work of creating a product. I’ve observed teams who work in sprints, conduct good sprint planning and review meetings, never miss a daily Scrum, and do a retrospective at the end of each sprint. They see solid improvements and may be as much as twice as productive as they were before Scrum. But they could do so much better.
What these teams are missing—and what stops them from achieving even more dramatic improvements—are changes to their technical practices. Scrum doesn’t prescribe specific engineering practices. To do so would be inconsistent with the underlying philosophy of Scrum: Trust the team to solve the problem. For example, Scrum doesn’t explicitly say you need to test. It doesn’t say you need to write all code in pairs in a test-driven manner. What it does do is require teams to deliver high-quality, potentially shippable code at the end of each sprint. If teams can do this without changing their technical practices, so be it. Most teams, however, discover and adopt new technical practices because it makes meeting their goals so much easier.
In this chapter we look at five common practices that were made popular by Extreme Programming and have been adopted by many of the highest-performing Scrum teams. We see how these practices are derived from a quest for technical excellence. Finally, we look at how the technical practices of a Scrum team intentionally guide the emergent design of the software system.
Strive for Technical Excellence
Like most kids, when my daughters drew or painted a particularly stunning masterpiece, they would bring it home from school and want it displayed in a place of prominence—namely the refrigerator. One day at work I coded a particularly pleasing use of the strategy pattern in some C++ code. Deciding that the refrigerator door was suitable for displaying anything we’re particularly proud of, onto the fridge it went! Wouldn’t it be nice if we were always so pleased with the quality of our work that we proudly displayed it on the fridge along with our kids’ artwork? Although you probably won’t go as far as taping your code, tests, or database schema on your fridge, producing fridge-worthy work is a goal shared by many Scrum teams.
In this section we will look at common technical practices used by Scrum teams to improve the quality of their work: test-driven development, refactoring, collective ownership, continuous integration, and pair programming. While I just referred to these as common practices, the truth is that they are not so common. These practices are well regarded and lead to higher quality, but because they can be hard to put into practice, they are used less often than they should be. Each, however, is a practice that Scrum teams should consider adopting. Because there are many great books and articles available on each of these practices, I will introduce each only briefly and will reserve the bulk of my comments for ways to introduce the practice into your organization and to overcome common objections to it.
See Also
For specific recommendations of reading material that will help you learn more about the technical practices themselves, see the “Additional Reading” section at the end of this chapter.
Test-Driven Development
If you were to look at how programmers write code on a traditional development team, you would find that they typically select a portion of the program to tackle, write the code, attempt to compile it, fix all the compile errors, walk through the code in a debugger, and then repeat. This is summarized in Figure 9.1. This process is very different from a test-driven approach, which is also shown in that figure. A programmer doing test-driven development works in very short cycles of identifying and automating a failing test, writing just enough code to pass that test, and then cleaning the code up in any necessary ways before starting again. This cycle is repeated every few minutes, rather than every few hours.
Figure 9.1 The microcyclic nature of traditional and test-driven development.
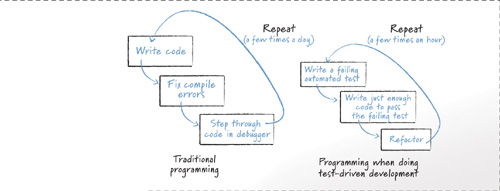
See Also
This cleaning up of the code is called refactoring. It is discussed in detail in the next section of this chapter.
I find test-driven development (TDD) invaluable. One of the biggest reasons is that it ensures that no untested code makes it into the system. If all code must be written in response to a failing test, then if we do nothing else, we at least achieve full code coverage with TDD. You might think a test-right-after approach would achieve the same result. However, I’ve found that when programmers make a commitment to write their unit tests “right after” they finish implementing a feature, they often do not do so. The pressure to get started programming the next feature can be tremendous. So programmers tend to write tests for only a subset of the new functionality or put testing on a list of things to get to later, and then find that later never comes.
It is appropriate to think of TDD as being as much a design practice as a programming practice. After all, the tests a programmer writes and the order in which they are written guide the design and development of a feature. A programmer doesn’t create a list of 50 small unit tests and then randomly choose which to implement first. Instead each test is selected and sequenced so that the uncertainties of the feature are addressed early. In this way, the selection and implementation of tests does indeed drive the development process, resulting in a design that, at least in part, emerges from the needs of the system.
See Also
The idea of driving development with tests has also been scaled up to what is known as acceptance test–driven development, a topic covered in Chapter 16, “Quality.”
There is some debate about whether TDD leads to more robust or otherwise better designs.1 But there is no doubt that TDD is helpful as a practice that helps programmers think through their designs. A design that is hard to test, for example, may indicate poorly structured code. My recommendation is to do TDD for its testing benefits; any potential design improvements it brings are a bonus.
1 For an example, see Abby Fichtner’s blog at http://haxrchick.blogspot.com/2008/07/tdd-smackdown.html, which includes a link to a video-recorded debate between Jim Coplien and Robert Martin.
Refactoring
Consider the classic definition offered by Fred Brooks in The Mythical Man Month of what happens as a software system is modified over time.
All repairs tend to destroy the structure, to increase the entropy and disorder of the system. Less and less effort is spent on fixing original design flaws; more and more is spent on fixing flaws introduced by earlier fixes. As time passes, the system becomes less and less well-ordered. Sooner or later the fixing ceases to gain any ground. Each forward step is matched by a backward one. Although in principle usable forever, the system has worn out as a base for progress. (1995)
Fortunately, since 1975 when Brooks first wrote this, our industry has learned ways to modify systems such that the system does not decay further with each modification. The ability to modify without introducing decay is essential to Scrum because Scrum teams build products incrementally. As Ron Jeffries says, “In agile, the design simply must start simple and grow up. The way to do this is refactoring.”
Refactoring refers to changing the structure but not the behavior of code. Let me give you an example. Suppose a programmer has two methods that each contain three identical statements. These three common statements can be extracted from both methods and put into one new method that is called from both of the old locations. This refactoring (formally known as extract method) has slightly improved the readability and maintainability of the program because it is now more obvious that some code is reused and the duplicated code has been moved to a single place. The structure of the code has been changed while its behavior has not.
Refactoring is not only crucial to the success of TDD, but it also helps prevent code rot. Code rot is the typical syndrome in which a product is released, its code is allowed to decay for a few years, and then an entire rewrite is needed. By constantly refactoring and fixing small problems before they become big problems, we can keep our applications rot free. Robert C. Martin calls this the Boy Scout Rule.
The Boy Scouts of America have a simple rule that we can apply to our profession: Leave the campground cleaner than you found it. If we all checked-in our code a little cleaner than when we checked it out, the code simply could not rot. (2008, 14)
Collective Ownership
Collective ownership refers to all developers feeling ownership over all artifacts of the development process, but especially of the code and automated tests. Because of the fast pace of a Scrum project, the team needs to avoid the trap of saying, “That’s Ted’s code. We can’t touch it.” Collective ownership encourages each team member to feel responsible for all parts of the program so that any programmer can work on any module of the program. When modifying a module, the programmer then shares responsibility for its quality with the module’s initial writer.
Collective ownership is not intended to cause a free-for-all in the coding. Programmers will still tend to have certain areas they specialize in and prefer to work in, but everyone on the team shares the following responsibilities:
• Ensure that no developer becomes so specialized he can contribute only in one area.
• Make certain that no area becomes so intricate that it is understood and worked upon by only one developer.
A natural benefit of fostering a feeling of collective ownership is that it encourages developers to learn new parts of the system. In doing so they generally also learn new ways of doing things. Good ideas used in one part of the application are more quickly propagated to other areas as programmers moving in and out of parts of the application carry the ideas like pollen.
Continuous Integration
Creating an official nightly build of a product has been known as an industry best practice since at least the early 1990s. Well, if a nightly build is a good idea, building a product continuously is an even better one. Continuous integration refers to integrating new or changed code into an application as soon as possible and then testing the application to make sure that nothing has been broken. Rather than checking in code perhaps every few days or even every few weeks, each programmer on a Scrum team running continuous integration is expected to check in code a few times each day—and to run a suite of regression tests over the entire application.
Continuous integration is usually achieved with the help of a tool or script that notices when code has been checked into the version control system. Cruise Control was the first product to gain popularity for automating continuous integration. It could build a product, run as many tests as desired against it, and could then automatically send a notification to the developer who broke the build (or to the entire team). Cruise Control could also send build results to additional feedback devices such as lava lamps, ambient orbs, spare monitors, LED displays, and more.
Some teams opt for a manual approach, in which developers initiate the build and test for each check-in. I strongly recommend against this. Although it is possible to be successful with a manual approach to continuous integration, my experience is that developers will occasionally skip the build and test. It is just too tempting to occasionally think, “I changed only two lines and it worked on my machine.” It’s also tempting to forgo the build and test when checking in code after your planned quitting time for the day: “Yikes, it’s almost six o’clock,” a developer may think. “I’m sure this works and I don’t want to wait 15 minutes for the tests to finish....” Given the ease with which a continuous integration tool can be configured, it is almost always one of the first things I coach teams to do.
For most developers, the first exposure to automated continuous integration is eye-opening. I know it was for me. I’d become very accustomed to the benefits of a nightly build but had somehow never made the mental leap that if once a day is good, many times a day would be better. After working in a continuously integrated environment for a day, I was hooked. Not only could we eliminate all risk of big integration issues at the end of a project, but also the entire development team would be receiving near-real-time feedback on the status of the product.
Pair Programming
Pair programming is the practice of having two developers work together to write code. It originated from the idea that if occasional code inspections are good, constant code inspections are better. Many of the practices just described are made easier through the use of pair programming. Learning how to do test-driven development is made easier when working together. Feelings of collective ownership are created when code is produced in pairs. And having the discipline to leave the code cleaner than you found it comes easier when another developer is sitting beside you.
Clearly, there are some benefits to pair programming. That’s why I invented it. OK, I didn’t really invent it, but I like to think I did. I did happen across it out of true necessity, which is, after all, the mother of invention. In 1986 I was hired by Andersen Consulting in its Los Angeles office. On my first day on the job I completed a skills survey. I marked myself as “proficient” with the C programming language, even though I was very much a beginner at the language. But, I reasoned, I’m studying it every night after work, and I will be proficient by the time they read this skills survey. Unfortunately for me, they read the survey the next day. And on the day after that I was on a plane from Los Angeles to the New York office to a project that desperately needed C programmers.
After arriving in New York, I met another programmer who had also been transferred because he knew C. I knew I couldn’t deceive him, so I came clean and confessed my exaggeration on the skills survey. “Ugh,” he said, “I lied, too.” Our solution was that we would work together—pair programming, although we didn’t call it that. We figured that between us we were as good as one “proficient” C programmer. And, we reasoned, if we worked together on everything, they wouldn’t know which of us to fire.
It worked like a dream. He and I worked together for much of the next eight years at three different companies, pairing as much as possible, especially on anything difficult. We wrote some amazing and incredibly complex products, always with low defect rates. We also felt that even though there were two heads for every pair of hands on the keyboard, we were highly productive when working this way.
Since those early, positive experiences with pair programming, I’ve been hooked. I knew it was a good way to write code. On the other hand, many of us in this industry (myself included) were first attracted to this work because we could sit in a cubicle with our Sony Walkman playing (yes, it was that long ago) and not have to talk with anyone all day. Even now, there are days when I enjoy nothing more than listening to some loud music on my headphones while code is flowing from my fingers as fast as I can type. Because I still relish those days, I have a hard time ever mandating to a team that they must do pair programming 100% of the time.
Fortunately, most teams have realized that the vast majority of the benefits of pairing can be achieved even when it is not done all day, every day. So, when coaching teams, I always push them to adopt pair programming on a part-time basis; use it for the riskiest parts of the application. I encourage teams to find the guidelines that help them pair enough, while stressing that enough is somewhere greater than 0%, but also acknowledging that I can understand the reasons they may have for wanting it to be less than 100%.
There are many advantages to pair programming, even for teams who do it less than 100% of the time. Although most studies show a slight increase in the total number of person-hours used when pairing, this is offset by a decrease in the total duration of the effort. That is, while pairing takes more person-hours, fewer hours pass on the clock (Dybå et. al 2007). Although projects are always under financial pressure, the overriding concern is not so much person-hours as time to market. Pair programming has also been shown to improve quality. In a survey of studies, Dybå and colleagues found that each study showed an improvement in quality with pair programming. Additionally, pair programming facilitates knowledge transfer and is an ideal way to bring new developers up to speed on the application. It is also an effective practice for working in uncharted territory or solving difficult problems in known parts of the system.
Design: Intentional yet Emergent
Scrum projects do not have an up-front analysis or design phase; all work occurs within the repeated cycle of sprints. This does not mean, however, that design on a Scrum project is not intentional. An intentional design process is one in which the design is guided through deliberate, conscious decision making. The difference on a Scrum project is not that intentional design is thrown out, but that it is done (like everything else on a Scrum project) incrementally. Scrum teams acknowledge that as nice as it might be to make all design decisions up front, doing so is impossible. This means that on a Scrum project, design is both intentional and emergent.
A big part of an organization’s becoming agile is finding the appropriate balance between anticipation and adaptation (Highsmith 2002). Figure 9.2 shows this balance along with activities and artifacts that influence the balance. When doing up-front analysis or design, we are attempting to anticipate users’ needs. Because we cannot perfectly anticipate these, we will make some mistakes; some work will need to be redone. When we forgo analysis and design and jump immediately into coding and testing with no forethought at all, we are trying to adapt to users’ needs. All projects of interest will be positioned somewhere between anticipation and adaptation based on their own unique characteristics; no application will be all the way to either extreme. A life-critical, medical safety application may be far to the anticipation side. A three-person startup company building a website of information on kayak racing may be far toward the side of adaptation.
Figure 9.2 Achieving a balance between anticipation and adaptation involves balancing the influence of the activities and artifacts on each side.

Foretelling the agile preference for simplicity, in 1990, was speaker and author Do-While Jones.
I’m not against planning for the future. Some thought should be given to future expansion of capability. But when the entire design process gets bogged down in an attempt to satisfy future requirements that may never materialize, then it is time to stop and see if there isn’t a simpler way to solve the immediate problem.2
2 Jones’ 1990 article, “The Breakfast Food Cooker,” remains a classic parable of what can go wrong when software developers over-design a solution. I highly recommended reading it at http://www.ridgecrest.ca.us/~do_while/toaster.htm.
Scrum teams avoid this “bogging down” by realizing that not all future needs are worth worrying about today. Many future needs may be best handled by planning to adapt as they arise.
Getting Used to Life Without a Big Design
As Scrum teams begin to become adept at the technical practices described in this chapter, they will naturally begin to shift further away from anticipating users’ needs and more toward adapting to them. This will result in a number of changes for the agile architect or designer to become accustomed to. The new realities caused by this shift include the following:
• Planning is harder. Estimating, planning, and committing to deliverables is already hard; it becomes more difficult in the absence of an up-front design. A lot of thinking goes into creating an up-front design. Some of that thinking is helpful in estimating how long things will take and in combining estimates into plans. The upside to forgoing the big up-front design, however, is that the work that needs to be estimated is often simpler so that individual features can be estimated more quickly and easily.
• It is harder to partition the work among teams or individuals. Having a big, up-front design in hand makes it easy to see which features should be developed simultaneously and which should be developed in sequence. This makes it easier to allocate work to teams or individuals.
• It is uncomfortable not to have design done. Even though we’ve always known that no up-front design can be 100% perfect, we took comfort in its existence. “Surely,” we reasoned, “we’ve thought of all the big things so any changes will be minor.”
• Rework will be inevitable. Without a big up-front design, the team will certainly hit a point where it needs to undo some part of the design. This two-steps-forward-one-step-back aspect of iterative development can be unsettling to professionals trained to identify all needs and make all design decisions up front. Fortunately, refactoring and the automated tests created during test-driven development can keep most rework efforts from becoming very large.
Doing a large, up-front design became popular because of the belief that doing so would save time and money. The cost of the up-front design plus the cost of adjustments was viewed as less expensive than the many small changes necessary with emergent design. The situation can be visualized as shown in Figure 9.3, with the question being which weighs more?
Figure 9.3 The costs of significant up-front design and analysis plus occasional expensive changes are weighed against the costs of frequent but smaller changes on a Scrum project.
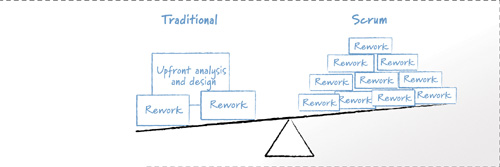
In the past, it was entirely possible that doing a large, up-front design would save time and money. After all, Barry Boehm demonstrated in Software Engineering Economics (1981) that defects are more expensive to fix the later in the development process they are discovered. But the technical practices employed by good Scrum teams can dramatically alter the equation. When a team uses good technical practices—test-driven development, a heavy reliance on automated unit tests, refactoring, and pair programming among them—it may find itself in the situation where it is cheaper to adapt to user needs by reworking the application more often than it is to anticipate those needs and rework only occasionally.
Figure 9.3 shows that in traditional development there is a large cost on upfront analysis and design. This investment keeps down the number of later changes. But when a change is needed, it is relatively expensive to make because the change violates the primary assumption that change will be largely unnecessary. By contrast, the Scrum view shows many more changes, but the size of each bit of rework is smaller. This is the result of anticipating that change will be needed, but not knowing exactly where. Because of that, a Scrum team pursues technical excellence, always keeping the code well factored, with as simple a design as possible, and with a suite of automated tests for early detection of regression problems. So, while there are more occasions for rework, each is less of a setback.
Guiding the Design
When I hear attacks on the lack of design on a Scrum project, the attacks usually start from the position that technical members of the team have no influence on the order in which features are added to the system. This is a faulty premise. In fact, one of the best things a Scrum team can do to ensure the scale shown in Figure 9.3 is tipped in the right direction is to influence the order in which items are worked on.
However, we read in Chapter 7, “New Roles,” that prioritizing the product backlog is the responsibility of the product owner. Although that is true, the chapter also pointed out that a good product owner will listen to the advice of the team. Standard Scrum guidance is that the product owner prioritizes based on some nebulous concept of “business value.” Although this may be true, it is a bit simplistic. The real job of the product owner is to maximize the delivery of features over some period of time. This may mean getting less “business value” now in favor of getting more later. In other words, a good product owner remains focused on ensuring that the product contains as much business value as possible when it is released but lets the team invest in the technical aspects of the product as appropriate because doing so pays later dividends to the product as well.
Especially early on a new project, the team should encourage the product owner to select product backlog items that will maximize learning and drive out technical uncertainty or risk. This is what I meant earlier by saying design on a Scrum project is both intentional and emergent. The design emerges because there is no up-front design phase (even though there are design activities during all sprints). Design is intentional because product backlog items are deliberately chosen with an eye toward pushing the design in different directions at different times.
An Example
As an example of how the product backlog items can be sequenced to influence the architecture of the system, consider a workflow system I worked on. The system supported a fund-raising company that produced specialized T-shirts and similar products. School-age children would go door to door selling these items. The sales revenue would be split between the company and the organization the kids represented, such as a school, sports team, or other group. For each sale, the kid would complete a form and send it to the company, where it was scanned, sent through an optical character recognition (OCR) process, and converted into an order. To keep shipping costs down, orders from the same organization were batched together and sent back to the organization, after which the kids would hand-deliver the items.
Our software handled the entire process—from when the paper was received by the company until the shipment went out the door. Kids have notoriously bad writing and are bad spellers, so our system had to do more than just scan forms and prepare packing lists. There were various levels of validation depending upon how accurately we thought each order form had been read. Some forms were routed to human data-entry clerks who were presented the scanned form on one side of the screen, the system’s interpretation on the right, and an additional space to make corrections.
Because thousands of shirts were processed on the busiest days, this process needed to be as automated as possible. I worked with the product owner, Steve, to write the product backlog. After that I met with the development team to discuss which areas of the system were the highest risk or we were the most uncertain about how to develop. We decided that our first sprint would focus on getting a high-quality document to run through the system from end to end. It would be scanned, go through OCR, and generate a packing list. We would bypass optional steps such as deskewing crooked pages, despeckling pages, and so on but would prove that the workflow could be completed from start to finish. This wasn’t highly valuable but it was something that needed to be done, and it let the developers test out the general architecture. After we accomplished this, we had a basic database in place and could move documents from state to state, triggering the correct workflow steps.
Next the developers asked the product owner if they could work on the part of the system that would display a scanned document to a human, who would be able to override the scanned and interpreted values. This was chosen as the second architectural goal of the project for three reasons:
• It was a manual step, making it different from the workflow steps handled already.
• Getting the user interface right was critical. With the volume of documents flowing through this system, saving seconds was important. We wanted to get early feedback from users to allow time to iterate on usability.
• After this feature was added, users could start processing shirt orders.
The project continued in this way for a few months and was ultimately tremendously successful, meeting all of the prerelease targets for reliability and throughput. A key to the success was that the product owner and technical personnel worked together to sequence the work. The closest the team got to a design phase was the first afternoon in the conference room when we identified risky areas and dark corners and decided which one we wanted to tackle first. From there the design emerged sprint by sprint, yet was intentionally guided by which product backlog items were selected to illuminate the dark corners and risks of the project.
Improving Technical Practices Is Not Optional
The technical practices described in this chapter are ones I would expect to see in use by a top-performing team. Of course, there is room to argue that these practices may not be necessary 100% of the time on your application. All of the practices, though, are ones that members of a good Scrum team should be experienced with. Continuous integration is merely the natural extension of a nightly build, which is a bare minimum for a team to be agile. Skill at refactoring and a mindset of collective ownership can be established over time with any team. Practices such as pair programming and test-driven development lead to higher quality code, which is a goal of every Scrum team.
Used together, these practices result in high-quality, low-defect products. Chapter 1, “Why Becoming Agile Is Hard (But Worth It),” included metrics on the improvements in quality and defect rates agile teams can experience. These improvements are the result of teams deliberately enhancing their technical skills and incorporating better practices.
As a result of these improvements, good Scrum teams are able to shift the balance between anticipation and adaptation further to the side of adaptation. Minimizing, and in some cases eliminating, up-front analysis and design activities saves both time and money. In an aptly titled article, “Design to Accommodate Change,” Dave Thomas, founder of Object Technology International, which was responsible for the early Eclipse development, summarizes how achieving this balance helps make change less painful.
Agile programming is design for change....Its objective is to design programs that are receptive to, indeed expect, change. Ideally, agile programming lets changes be applied in a simple, localized way to avoid or substantially reduce major refactorings, retesting, and system builds. (2005, 14)
Additional Reading
Ambler, Scott W., and Pramod J. Sadalage. 2006. Refactoring databases: Evolutionary database design. Addison-Wesley.
The first five chapters of this book clarify the role of the data professional in the agile organization. The chapters that follow are a compendium of well-thought-out ways to evolve a database design. Each refactoring includes descriptions of why you might make this change, trade-offs to consider before making it, how to update the schema, how to migrate the data, and how applications that access the data will need to change.
Bain, Scott L. 2008. Emergent design: The evolutionary nature of professional software development. Addison-Wesley Professional.
I’ve been waiting for someone to write the book proving how effective designs can emerge without being entirely thought-through up front. I’d hoped from its title that this would be that book. It isn’t, but it is an excellent description of how code should be developed on an agile project. Included are top-notch chapters on many of the technical practices described in this chapter.
Beck, Kent. 2002. Test-driven development: By example. Addison-Wesley Professional.
This slim book will not teach you everything you need to know about test-driven development. (For that, see Test Driven: TDD and Acceptance TDD for Java Developers by Lasse Koskela.) Where Beck’s book excels is at showing how TDD works and why you might want to try it.
Duvall, Paul, Steve Matyas, and Andrew Glover. 2007. Continuous integration: Improving software quality and reducing risk. Addison-Wesley Professional.
This book covers everything you’ll ever need to know about continuous integration. It covers how to get started, incorporate tests, use code analysis tools, and even evaluate continuous integration tools.
Elssamadisy, Amr. 2007. Patterns of agile practice adoption: The technical cluster. C4Media.
This book covers all of the technical practices recommend here (and more) and is an excellent choice if you are looking for one book that covers all of the technical practices in more detail. While full of good advice, the book is written in typical pattern style, where each practice is described in a fixed manner, which I find doesn’t hold my attention well after awhile.
Feathers, Michael. 2004. Working effectively with legacy code. Prentice Hall PTR.
Introducing new technical practices and committing to technical excellence is challenging enough on a new project; it’s even harder on a legacy application. Michael Feathers’ excellent book provides practical and immediately useful advice on doing so.
Fowler, Martin. 1999. Refactoring: Improving the design of existing code. With contributions by Kent Beck, John Brant, William Opdyke, and Don Roberts. Addison-Wesley Professional.
The bible of refactoring. Today’s integrated development environments can do a lot of refactorings for us, but it is still useful to go back to the original source and see the catalog of refactorings presented here. One of my favorite chapters is on “Big Refactorings,” which are often the ones that are most challenging.
Koskela, Lasse. 2007. Test driven: TDD and acceptance TDD for Java developers. Manning.
This is the most thorough book on test-driven development and is appropriate for those new to TDD and those with lots of experience. Koskela doesn’t shy away from the hard topics and presents advice on such often-ignored topics as TDD for multi-threaded code and user interfaces. The book takes a holistic approach to TDD, even including nearly 150 pages on acceptance test–driven development.
See Also
Acceptance test–driven development is described in Chapter 16.
Martin, Robert C. 2008. Clean code: A handbook of agile software craftsmanship. Prentice Hall.
The title page inside this book features the statement, “There is no reasonable excuse for doing anything less than your best.” The book then proceeds to present a compendium of practices for writing clean code. Topics range from the commonplace (meaningful names) to novel (test-driving an architecture and emergence). This is a must-read for all programmers.
Meszaros, Gerard. 2007. xUnit test patterns: Refactoring test code. Addison-Wesley.
This encyclopedic book covers everything a programmer might possibly want to know about the popular xUnit family of unit testing tools. The book starts with the basics but quickly moves on to thoroughly cover advanced topics as well.
Wake, William C. 2003. Refactoring workbook. Addison-Wesley Professional.
A well-organized and easily accessible introduction to refactoring. The book is full of Java code examples for you to refactor and is a combination of a refactoring primer and exercises to drive home the point. The last third of the book is made up of four programs for you to refactor.