
Algorithms operating on strings are fundamental to many computer programs, and in particular searching for one string in another is the core of many algorithms. An example is searching for a word in a text document, where we want to know everywhere it occurs. This search can be exact, meaning that we are looking for the positions where the word occurs verbatim, or approximative, where we allow for some spelling mistakes.
This book will teach you fundamental algorithms and data structures for exact and approximative search. The goal of the book is not to cover the theory behind the material in great detail. However, we will see theoretical considerations where relevant. The purpose of the book is to give you examples of how the algorithms can be implemented. For every algorithm and data structure in the book, I will present working C code and nowhere will I use pseudocode. When I argue for the correctness and running time of algorithms, I do so intentionally informal. I aim at giving you an idea about why the algorithms solve a specific problem in a given time, but I will not mathematically prove so.
You can copy all the algorithms and data structures in this book from the pages, but they are also available in a library on GitHub: https://github.com/mailund/stralg. You can download and link against the library or copy snippets of code into your own projects. On GitHub you can also find all the programs I have used for time measurement experiments so you can compare the algorithm’s performance on your own machine and in your own runtime environment.
Notation and conventions
Unless otherwise stated , we use x, y, and p to refer to strings and i, j, k, l, and h to denote indices. We use ? to denote the empty string. We use a, b, and c for single characters. As in C, we do not distinguish between strings and pointers to a sequence of characters. Since the book is about algorithms in C, the notation we use matches that which is used for strings, pointers, and arrays in C. Arrays and strings are indexed from zero, that is, A[0] is the first value in array A (and x[0] is the first character in string x). The ith character in a string is at index i − 1.
When we refer to a substring, we define it using two indices, i and j, i ≤ j, and we write x[i, j] for the substring. The first index is included and the second is not, that is, x[i, j] = x[i]x[i + 1] · · · x[ j − 1]. If a string has length n, then the substring x[0, n] is the full string. If we have a character a and a string x, then ax denotes the string that has a as its first character and is then followed by the string x. We use ak to denote a sequence of as of length k. The string a3 x has a as its first three characters and is then followed by x. A substring that starts at index 0, x[0, i], is a prefix of the string, and it is a proper prefix if it is neither the empty string x[0, 0] = ? nor the full string x[0, n]. A substring that ends in n, x[i, n], is a suffix, and it is a proper suffix if it is neither the empty string nor the full string. We will sometimes use x[i, ] for this suffix.
We use $ to denote a sentinel in a string, that is, it is a character that is not found in the rest of the string. It is typically placed at the end of the string. The zero-terminated C strings have the zero byte as their termination sentinel, and unless otherwise stated, $ refers to that. All C strings x have a zero sentinel at index n if the string has length n, x = x[0]x[1] · · · x[n − 1]0. For some algorithms, the sentinel is essential; in others, it is not. We will leave it out of the notation when a sentinel isn’t needed for an algorithm, but naturally include the sentinel when it is necessary.
Graphical notation
Most data structures and algorithmic ideas are simpler to grasp if we use drawings to capture the structure of strings rather than textual notation. Because of this, I have chosen to provide more figures in this book than you will typically see in a book on algorithms. I hope you will appreciate it. If there is anything you find unclear about an algorithm, I suggest you try to draw key strings yourself and work out the properties you have problems with.

Graphical string notation
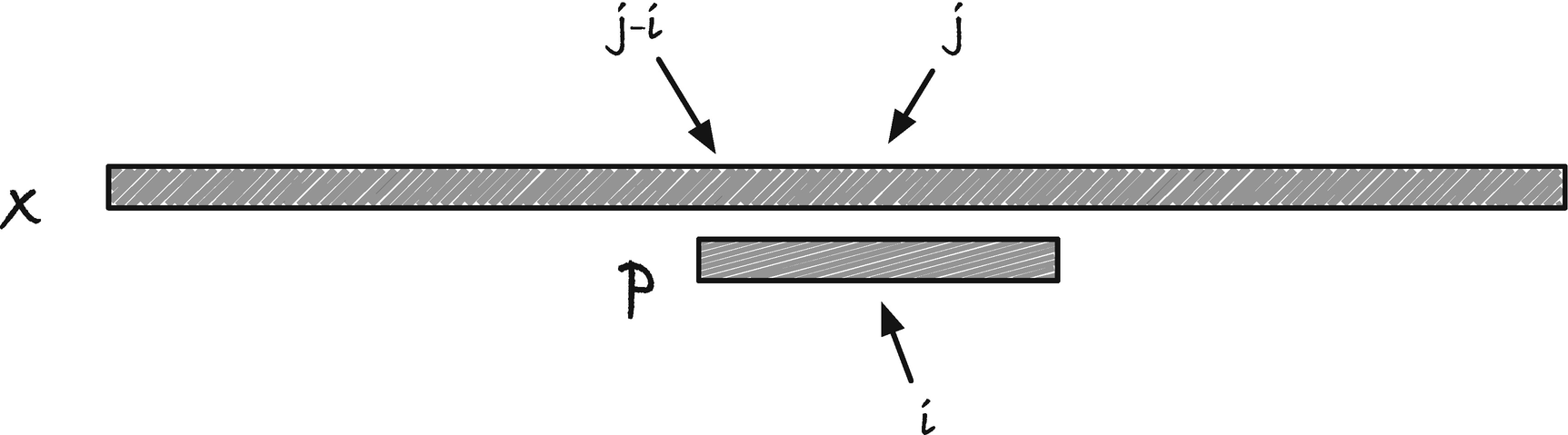
Graphical notation for comparing indices in two different strings
Code conventions
I make an exception for functions that take no arguments, that is, have void as their argument type.
There are many places where an algorithm needs to use characters to look up in arrays. If you use the conventional C string type, char *, then the character can be either signed or unsigned, depending on your compiler, and you have to cast the type to avoid warnings. A couple of places we also have to make assumptions about the alphabet size. Because of this, I use arrays of uint8_t with a zero termination sentinel as strings. On practically all platforms, char is 8 bits so this type is, for all intents and purposes, C strings. We are just guaranteed that we can use it unsigned and that the alphabet size is 256. Occasionally it is necessary to cast a uint8_t * string to a C string. A direct cast, (char *)x, will most likely work unless you are on an exotic platform. If it doesn’t, you have to build a char buffer and copy characters byte by byte. It has to be a very exotic platform if you cannot store 8 bits in a char! Because I assume that you can always cast to char *, I will use the C library string functions (with a cast) when this is appropriate. It is a small matter to write your own if it is necessary.
I will use uint32_t for indices, assuming that strings are short enough that we can index them with 32 bits. You can change it as needed, but I find it a good trade-off between likely lengths of strings and the space I need for data structures. I work in bioinformatics, so hundreds of millions of characters are usually the longest I encounter.
Reporting a sequence of results
If a global report function is all you need in your program, then this is an excellent solution. Often, however, we need different reporting functions for separate calls to the search function. Or we need the report function to collect data for further processing (and preferably not use global variables). We need some handle to choose different report functions and to provide them with data.
Callback functions have their uses, especially to handle events in interactive programs, but also some substantial drawbacks. To use them, you have to split the control flow of your program into different functions which hurts readability. Especially if you need to handle nested loops, for example, iterate over all nodes in a tree and for each node iterate over the leaves in another tree where for each node-leaf pair you find occurrences… (the example here is made up, but there are plenty of real algorithms with nested loops, and we will see some later in the book).
We can get the control flow back to the calling function using the iterator design pattern. We define an iterator structure that holds information about the loop state, and we provide functions for setting it up, progressing to the next point in the loop, and reporting a match and then a function for freeing resources once the iterator is done.
The iterator structure contains the loop information. That means it must save the preprocessing data from when we create it and information about how to resume the loop after each time it is suspended. To report occurrences, it takes a “match” structure through which it can inform the caller about where matches occur. The iterator is initialized with data that determines what it should loop over. The loop is handled using a “next” function that returns true if there is another match (and if it does it will have filled out match). If there are no more matches, and the loop terminates, then it returns false. The iterator might contain allocated resources, so there should always be a function for freeing those.
We set up the loop with information from the iterator and search from there. If we find an occurrence, we store the new loop information in the iterator and the match information in the match structure and return true. If we reach the end of the loop, we report false.
Since the deallocation function doesn’t do anything, we could leave it out. Still, consistency in the use of iterators helps avoid problems. Plus, should we at some point add resources to the iterator, then it is easier to update one function than change all the places in the code that should now call a deallocation function.
Iterators complicate the implementation of algorithms, especially if they are recursive and the iterator needs to keep track of a stack. Still, they greatly simplify the user interface to your algorithms, which makes it worthwhile to spend a little extra time implementing them. In this book, I will use iterators throughout.