
16
Testing Product Lines
Like all engineering disciplines, software engineering relies on a reuse discipline to achieve economies of scale, improved product quality, shorter production cycles, and reduced process risk. But contrary to all other engineering disciplines, reuse is very difficult in software engineering and has been found to be effective only within the confines of product line engineering (PLE). The purpose of this chapter is to briefly introduce the reader to the reuse discipline of PLE and to focus specifically on testing software products produced and evolved within this discipline.
16.1 PLE: A STREAMLINED REUSE MODEL
Given that software is very labor-intensive (hence hard to automate), that software labor is very expensive (as it requires a great deal of specialized expertise), and that software products are very hard to produce (due to their size and complexity), one would expect software reuse to be an indispensable component of software engineering. Indeed, for an industry that is under as much stress as the software industry, reuse offers a number of significant advantages, including the following:
- Enhanced productivity, which stems from using the same product in a wide variety of applications at little or no extra cost.
- Enhanced quality, which stems from investing an adequate amount of effort in the quality assurance of the product, with the knowledge that this effort will be amortized through the multiple uses of the product.
- Shorter time to market, which can be achieved by saving, not only the development effort but also the development schedule required for a custom product development.
- Reduced risk, which stems from trading the risk inherent in any software project development for the safety and predictability of using an existing component that has survived extensive field testing and field usage.
Despite all these advantages, software reuse has not caught on as a general routine practice in software engineering, for a number of reasons, chief among them is the absence of a reference architecture in software products. Indeed, in order for reuse to happen, the party that produces reusable assets and the party that consumes them need to have a shared product architecture in mind. In the automobile industry, for example, component reuse has been a routine practice for over a century because the basic architecture of automobiles has not changed since the late nineteenth century: All cars are made up of a chassis, four wheels, a cab, an engine, a transmission, a steering mechanism, a braking mechanism, a battery, an electric circuitry, a fuel tank, an exhaust pipe, an air-conditioning system, and so on. As a result of this standard architecture, many industries emerge around the production of specific parts of this architecture, such as tire manufacturers, battery manufacturers, transmission manufacturers, exhaust manufacturers, and air-conditioning manufacturers, as well as other more specialized (and less visible to the average user) auto parts manufacturers. This standard architecture supports reuse on a large scale: when they design a new automobile, car manufacturers do not reinvent what is a car every time; rather, they may make some design decision pertaining to look, styling, engine performance characteristics, standard features, and optional features, then pick up their phone and order all the auto parts that they envision for their new car. Unfortunately, such an efficient/flexible process is not possible for software products, for lack of a standard architecture for such products.
But while software products have no common architecture across the broad range of applications where software is prevalent, they may have a common architecture within specific application domains—whence PLE. PLE is a software development and evolution process that represents a streamlined form of software reuse. It is geared toward the production of a family of related software products within a particular application domain and includes two major phases, which are as follows:
- Domain Engineering, which consists in developing the necessary infrastructure to build and evolve applications within the selected application domain. This phase includes the following steps/activities:
- Domain Analysis, which is the PLE equivalent of the requirements engineering phase in traditional waterfall lifecycles and consists of analyzing the application domain to understand its domain-specific knowledge (abstractions, assumptions, axioms, rules, etc.).
- Domain Scoping, which consists of determining the boundaries of the domain by specifying which applications fall within and which fall outside the selected domain.
- Economic Rationale, which consists of making a case for the product line based on an estimation of the return on investment achieved by this product line; the calculation of the return on investment depends on the domain engineering costs, the application engineering costs, the number of applications we envision to sell every year, and the number of years we envision the product line to be active.
- Variability/Commonality Analysis, which consists of deciding what features domain applications have in common (to maximize reuse potential) and how they differ from each other (to broaden the market that can be served by the domain). Variabilities are defined by specifying what features vary from one application to another and what values each feature may take. For example, if we are talking about database applications, then one variability could be the back-end database, and the values on offer could include Oracle, SQL, and Access.
- Reference Architecture, which consists in deriving a common architecture for all the applications in the domain.
- Asset Development, which consists in developing adaptable components that fit in the proposed architecture and support the variabilities that have been selected in the aforementioned analysis.
- Application Modeling Language (AML): For well-designed, well-modeled product lines, it is possible to define a language in which one can specify or uniquely characterize individual products within the application domain. In some simple cases, it is possible to design translators that map a specification written in this AML onto a finished application.
- Application Engineering Process: In addition to producing the necessary assets that the application engineer needs to compose an application, the domain engineering team must deliver a systematic application engineering process that explains how applications are produced from domain engineering assets according to application requirements.
- Application Engineering, which consists in using the assets produced in the domain engineering phase to build an application according to the steps detailed in the application engineering process.
As a simple illustration, consider a product line developed to cater to the IT needs of banks in some jurisdiction (e.g., the state of New Jersey in the United States).
- Domain analysis consists of getting acquainted with the banking domain and with the relevant requirements of an IT application in the selected jurisdiction. This may require that we read relevant documentation and legislation in the jurisdiction of the bank and that we talk to bank managers, bank employees, bank tellers, bank customers, fiscal authorities, state and federal regulators of the banking sector, and so on. At the end of this phase, we ought to become fluent in the banking domain; we also need to record our expertise and domain knowledge in the form of domain models, including relevant abstractions, rules, terminology, and so on.
- Domain scoping consists of deciding what applications are or are not part of our domain. For example, we consider all the types of banks, such as retail banks, investment banks, credit unions, online banks, savings and loans banks, local banks, statewide banks, nationwide banks, offshore banks, and international banks.
- To build an economic rationale for our product line, we must consider the scope that we have defined earlier and evaluate the cost of developing a product line to cater for banks within our scope, then balance this cost against the benefits reaped from selling applications to banks; this, in turn, requires that we estimate the length of our investment cycle, the discount rate that we want to apply from one year to the next, the number of applications that we envision to sell to banks, the price at which we envision to sell the applications, and so on.
- Variability/Commonality Analysis: Once we have defined the scope of our domain, we can analyze the common attributes that the applications of our domain have: for example, if we decide to cater to nationwide retail banks, commonalities include that they are all subject to federal banking laws, federal tax laws, and federal employment laws; other commonalities include that they all maintain bank accounts, customer databases, loan departments, and so on. As for variabilities, banks may be subject to different state laws depending on where they are headquartered, they may have significantly distinct banking policies, they may differ by the range of services that they offer their clients, and so on.
- Reference Architecture: Once we know what kinds of banks we are catering to and what kinds of commonalities and variabilities exist among the needs of these banks, we can draw an architecture that may be shared by all applications of the domain. Such an architecture may include a database of accounts, a database of customers, and a database of loans, along with a customer interface (for online customer transactions), a teller interface (for teller in-branch operations), an automatic teller interface (for ATMs), and so on.
- Once the common architecture is drawn, we can proceed with developing adaptable software components, which can be adjusted to fulfill specific customer needs within the scope of the product line and integrated into the architectural framework to produce a complete application.
Figure 16.1 illustrates the lifecycles of domain engineering and application engineering and how they relate to each other.
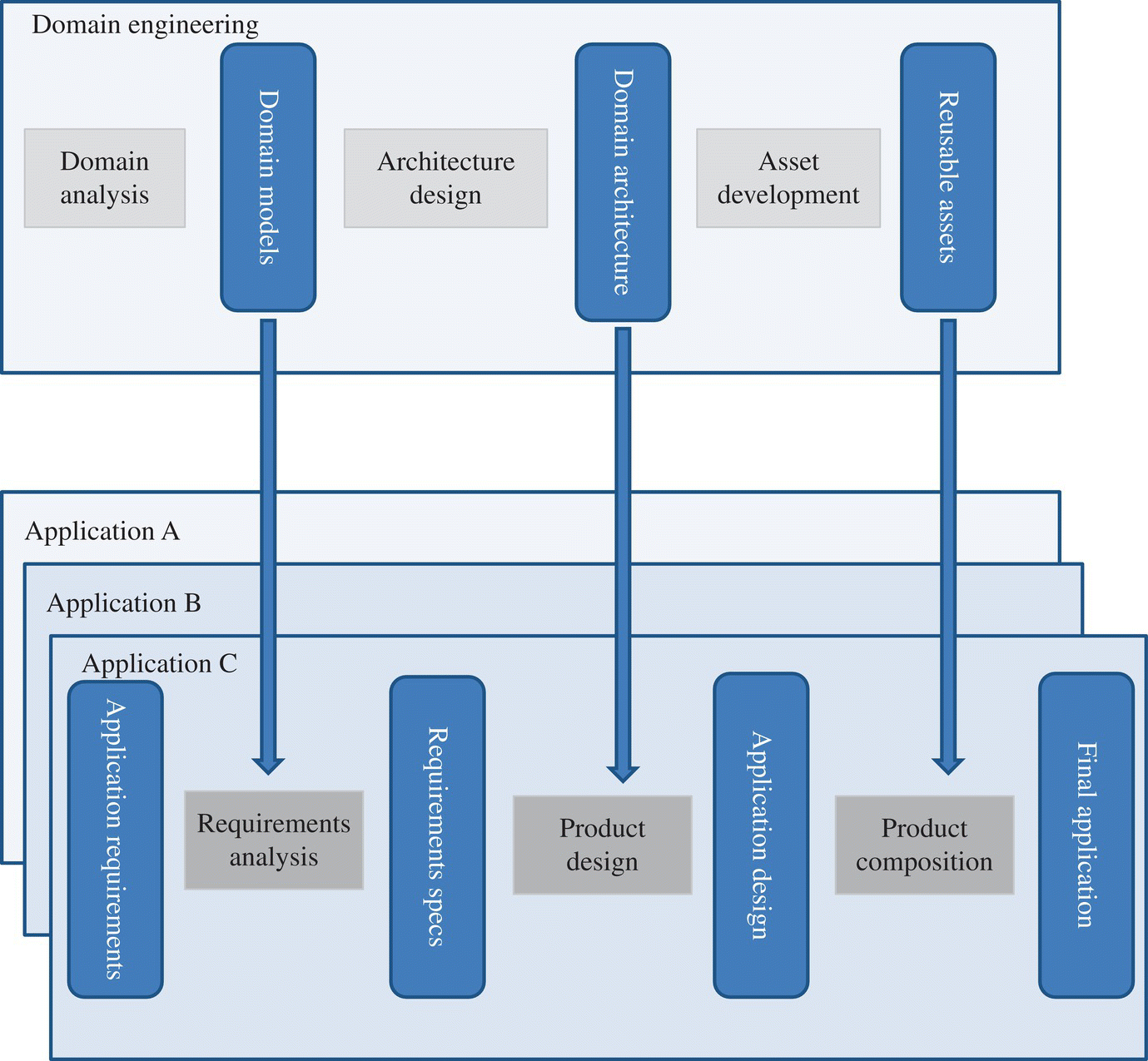
Figure 16.1 Domain engineering and application engineering lifecycles.
16.2 TESTING ISSUES
To get a sense of the issues that arise in testing product lines, we review the traditional lifecycle of software testing then we explore how this lifecycle can be combined with the PLE process discussed earlier (and illustrated in Fig. 16.1). Given a software product P and a specification R, and given that we want to test whether P is correct with respect to R, we proceed through the following phases:
- Test Data Generation, whereby we inspect program P or specification R or both to generate test data T on which we envision to test P.
- Test Oracle Design, whereby we derive a test oracle Ω from specification R, which for any element s of T tells whether the pair (s, P(s)) represents a correct execution of program P on initial state s.
- Test Driver Design, whereby we combine the test data generation criterion with the oracle design to derive a test driver that runs program P on test data T and stores the outcome.
- Test Outcome Analysis, whereby we analyze the outcome of the test and take action according to the goal of the test (fault density estimation, fault removal, reliability estimation, product certification, etc.).
Of course, we can carry out these steps for each application that we develop at the application engineering phase, but this raises the following issues:
- This is extremely inefficient: Indeed, each application is made up of common parts (that stem from commonality analysis) and application-specific parts (that stem from the specific variabilities of the application). The common parts have been tested each time an application is tested; and the variable parts have been tested each time an application with the same variability has been tested. Ideally, we would like to focus the testing effort on those aspects of the application that have not received adequate coverage.
- This is incompatible with the spirit of PLE: The whole paradigm of PLE revolves around streamlined reuse of reuse artifacts and processes; it is only fitting that reuse should extend to testing artifacts (such as test data) and processes (such as testing common features only once, rather than repeatedly for each application).
- This alters the Economics of PLE: The economics of PLE is based on the assumption that a great deal of effort is invested in domain engineering in order to support the rapid, efficient, cost-effective production of applications at application engineering time. If we burden the application engineering phase with the task of testing each application, this may undermine the economic rationale of the product line.
- The application specification is not self-contained: The specification of an application for the purposes of application engineering (written in the AML, for example) is cast in the context of domain engineering and merely specifies the attributes that characterize the application within the scope of the domain; as such, it is not self-contained. To write the specification of the application in a self-contained manner (for the purpose of oracle design), one needs to refer to all the implicit domain requirements that arise in domain engineering.
In light of these issues, it is legitimate to consider shifting the bulk of testing to the domain engineering phase, rather than the application engineering phase. Unfortunately, this option raises a host of issues as well, such as the following:
- Absence of Executable Assets: At the end of domain engineering, we do not have any self-contained executable assets to speak of. What we typically have are adaptable software components that are intended to be used as part of complete applications.
- Absence of Verifiable Specifications: Not only do we not have completely defined operational software products we also do not have precise requirements specifications to test applications against. Instead, we have domain models and feature models that capture domain knowledge and represent domain variabilities.
- Combinatorics of Variabilities: Testing a single software product is already hard enough due to the massive size of typical input spaces. PLE compounds that complexity by adding the extra dimensions of variability: If a product line has five dimensions of variability, and each variability may take four possible values (considered a toy-size example), we have in effect
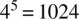 possible configurations to test. If we assume that (some or all of) the variabilities are optional (i.e., a user may opt out of a variability), then the number of application configurations can reach
possible configurations to test. If we assume that (some or all of) the variabilities are optional (i.e., a user may opt out of a variability), then the number of application configurations can reach 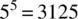 .
. - Feature Interactions: One way to deal with the combinatorial explosion alluded to earlier is to consider the variabilities one at a time, falling back on default options. The trouble with that option is that it fails to uncover problems that arise when variabilities are combined; in particular, it fails to detect feature interactions that may arise.
- Failure to Certify the Composition Step: Testing that takes place at the domain engineering phase precedes, by definition, the application engineering phase, hence it fails to detect issues that may arise at the latter phase. In particular, it fails to ensure that variabilities are bound appropriately according to the specification.
16.3 TESTING APPROACHES
There is no simple, integrated, widely accepted, solution to the problems raised earlier. Rather, there are general guidelines that one ought to pursue in designing a testing policy for any particular product line; we review these guidelines in this section and illustrate them on a simple example in the next section. These guidelines are driven by the following principles:
- All commonalities must be tested at domain engineering time. This principle is intended to save testing effort: commonalities are thoroughly tested at domain engineering time so that we do not need to retest them at application engineering time for each application. We envision two broad methods to optimize commonality testing at domain engineering time:
- Either through the creation of a reference application that may take default variability values or, alternatively, frequently used variability values.
- Or, if we are confident about the validity of the reference architecture and the soundness of component specifications, through individual testing of the various components of the reference architecture.
- Variability-specific test artifacts must be generated at domain engineering time and deployed at application engineering time. This principle is intended to save test data generation effort: For each variability option, the application engineering has a set of test data that she/he must use to test the variability within the application.
- Variability bindings must be tested at application engineering time. Because variability bindings are application-specific, it is fitting that they should be carried out by the application engineer.
- Applications must undergo some degree of integration testing, to make sure the composition of the application was carried out properly and that the components of the application work together as intended.
These principles are illustrated in the next section, through a sample product line, its implementation, and its test.
16.4 ILLUSTRATION
16.4.1 Domain Analysis
We wish to develop a product line of applications that simulate the behavior of waiting queues at service stations. These may represent customers standing in line at checkout counters at a store, travelers standing at airline check-in counters at an airport, arriving passengers standing at immigration stations in an international arrivals terminal, postal customers standing in line for service at a post office, or processes being queued at a shared resource allocation post. The purpose of the applications in this product line is to enable managers to simulate various queuing and servicing policies and analyze their performance in terms of waiting time, fairness, throughput, and so on.
Among the commonalities that we envision between all the applications of this product line, we cite the following:
- The Input Data to the Simulation: The user must enter the following information:
- The duration of the simulation, as a function of a virtual unit of time (e.g., the minute for simulations of customers and the millisecond for simulations of processor allocation).
- The arrival rate, that is, the average length of time between two successive arrivals, expressed in the unit time selected earlier. If there are more than one category of customers, then a rate for each category.
- The service rate, that is, the average length of service time required by each customer. If there are more than one category of customers, then a rate for each category.
- The Format of the Output Data: The user may be interested to collect a variety of statistics pertaining to the simulation. The set of possible functions she/he may be interested in varies from one application to another and is determined at application engineering time, as we discuss later.
- A Standard Record Structure for Customers: We could make the customer record structure a variability, but for the sake of simplicity we choose to adopt a generic structure that will represent most of the relevant data, such as some identification of the customer, his time of arrival, his category (if there are more than one), his requested service time, his priority (if queuing is based on priority), and his time of departure.
- An Illustration of the Simulation: The simulation may be illustrated at run time by showing the evolution of the waiting queues and the service stations throughout the simulation process.
Among the variabilities between applications in this product line, we cite the following:
- Topology of Service Stations: An application may have a single service station or several service stations; if there are several service stations, they may be interchangeable (offering the same service) or not (offering different services, e.g., first-class passengers vs. business-class passengers vs. coach passengers at an airline check-in area; or self check-out counters vs. attended check-out counters vs. check-out counters for small orders at a store’s cash registers; or citizens vs. permanent residents vs. visitors at immigration posts at an international arrivals hall of an airport). Another dimension of variability is whether a service station, if it is available, may serve customers from a different class, if such customers are not being served by their corresponding service station (e.g., if a first-class check-in station is available and there are coach passengers in the coach waiting queue, we may want to have them served at the first-class station).
- Service Time: The service time of a customer may be fixed (the same for all customers) or it may be variable (most typical, in practice). If it is variable, its length may depend solely on the customer (some customers need more service than others) or it may depend on the customer and on the service station (combining the customer needs with the productivity/efficiency of the service station attendant). If the service time is variable, it may be subject to a maximum allocation (as is the case in round-robin allocation of CPU cycles to competing processes in an operating system).
- Topology of Queues: Given a configuration of service stations (one or many, interchangeable or distinct, with or without cross-servicing), we may have one queue per service station or one queue per category of service stations.
- Arrival Distribution: We can imagine a number of probability laws that govern the arrival of new customers. Possible options may include the following:
- A uniform probability distribution
- A Markovian probability distribution
- A Poisson probability distribution
- Queuing Policy: This policy deals with two questions: given an arriving customer, what queue do we put him in, and where in the queue do we place him. In terms of the first question, options include the following:
- Each category of customers is assigned to a particular type of queue, if there is one queue per category.
- Each category of customers is assigned to the shortest queue that corresponds to his category, if there are more than one queue per category.
- Customers are randomly assigned to a queue that corresponds to their category.
As for how to place each customer in the selected queue, we consider two options: an FIFO policy or a priority-based policy.
- Dispatching Policy: Whereas queuing policy deals with where to place an incoming customer in the queue system, the dispatching policy deals with which customers to pick for service whenever a service station becomes available. The simplest situation is to have a queue associated to each service station and not to allow cross-queue transfers. Other options include the situation where several interchangeable service stations take their customers from a shared queue and the situation where an idle service station can take customers from the queue of another service station.
- Measurements: Measurements include any combination of the following:
- Average, median, minimum, or maximum waiting time, that is, time spent in waiting queues.
- Average, median, minimum, or maximum sojourn time, that is, time spent in the system overall.
- Fairness, that is, the extent to which waiting time is proportional to requested service time.
- Occupancy rate of the service stations, that is, the extent to which service stations were busy.
- Throughput of the service stations, that is, the number of customers serviced per unit of time.
- Total duration of the simulation (if the simulation is allowed to proceed until all customers are serviced).
- Total number of customers serviced.
- Wrap Up Policy: When the user of an application determines the length of the experiment, a number of decisions must be made as to how the simulation winds down:
- The simulation is stopped abruptly when the selected time elapses; then all remaining customers are flushed out, possibly taking their statistics.
- When the time of the simulation is exhausted, no new customers are generated but the simulation continues until all the current customers have been serviced and have exited the system.
In the next section, we consider a possible reference architecture for applications in this domain, then we implement some reusable/adaptable components of this architecture and outline how such components are composed to produce an application.
16.4.2 Domain Modeling
We have to make provisions for all possible configurations of the service stations and corresponding queues, namely, variable number of service stations, variable number of queues, variable number of service station types, various mappings from queues to service stations, and so on. In order to cater for all possible configurations, we resolve to introduce a basic building block, which we call the queue-station block; each such a block is made up of a number of interchangeable service stations and a single queue feeding customers to these stations. We represent such a block by the symbol QS(n), where n is the number of service stations and QS stands for queue-service station. We leave it to the reader to check that all possible queue/station configurations can be implemented by a set of such blocks, with varying values of n. For example, if we want to simulate the situation of an airline check in counter that has two stations for first class, three stations for business class, and five stations for coach, we write (in the style of a type-variable declaration) as follows:
QS(2) firstclass; QS(3) businessclass; QS(5) coach.
In addition to specifying the number of service stations in a QS component, we may want to also specify the queuing policy; if we want the first-class and business-class queues to adopt an FIFO policy but want to adopt a priority-based policy for coach queues (e.g., award some privileges to frequent flyers who still fly coach), we may write the following:
QS(FIFO, 2) firstclass; QS(FIFO, 3) businessclass; QS(PRIORITY, 5) coach.
If, for example, we want to simulate the situation of waiting queues at a gas station, where each pump has its own queue of cars and cars are served by order of arrival, then we write the following:
QS(FIFO, 1) pump1, pump2, pump3, pump4, pump5;
In addition to specifying the configuration of queue/station sets, we may also want to specify policies pertaining to how some service station may serve the queues of other service stations; for example, in an airline check-in counter, it is common for first-class stations to serve coach passengers if the station is free and the coach queue is not empty. To this effect, we use the feature CrossStation, and we consider the following options to this feature:
- CrossStation(NONE): no such a possibility is available.
- CrossStation(S,Q): specifies the station that offers the service and the queue to which the service is offered.
For example, in the case of an airline check-in counter, we may write the following:
- CrossStation(firstclass, businessclass);
- CrossStation(firstclass, coach);
- CrossStation(businessclass, coach).
To feed customers to the simulation, we create a component called Arrivals, which generates customers according to the arrival rate provided by the user at run time. This component implements the arrivals distribution of the application and is responsible for the implementation of the queuing policy, at least as far as dispatching arriving customers to QSs, according to their category or to some other criterion. We assume that the Arrivals component takes two parameters, which are as follows:
- The law of probability that determines the arrival of new customers at each unit of clock time: UNI (for uniform), MARKOV (for Markov), or POISSON (for Poisson).
- The rule that determines where each new arriving customer is queued: We assume that we have three options, as discussed earlier, namely, CAT (by category), SHORT (to shortest queue), and ANY (random assignment to queues).
In addition to specifying where incoming customers are placed, we may also want to specify whether the assignment of customers to queues is permanent (until the customer is served) or whether a customer may jump from one queue to another. We use the feature CrossQueue to this effect, and we consider the following options to this feature:
- CrossQueue(NONE): The assignment of customers to queues is permanent.
- CrossQueue(FRONT, n), where n is a natural number: If a queue is of length n or greater and another queue is empty, the front of the first queue is sent to the empty queue.
- CrossQueue(BACK, n), where n is a natural number: if a queue Q1 is longer than a queue Q2 by n elements or more, then the back of queue Q1 is moved to the back of queue Q2.
We assume that CrossQueue transfers take place only within QS sets of the same category.
Also, to collect statistics pertaining to the simulation, we create a component called Statistics, that is called by the QSs whenever a customer is about to leave the system after being serviced; it may also be called by the QSs at each iteration if the user is interested in measuring the rate of occupancy of service stations. This component collects data about individual customers, then computes simulation-wide statistics at the end of the simulation and posts it to the user. We assume that this component lists as parameters all the statistics that are selected at application engineering time, including the following:
- Waiting Time (parameter: WT), including minimum, maximum, average, median
- System Response Time (parameter: SRT), that is, time spent by customers in the system, including minimum, maximum, average, median
- Occupancy rate for each station (parameter: OR)
- Maximum queue length for each queue (parameter: MQL)
- Throughput of the system, that is, number of customers served per unit of time (parameter: TP)
- System Fairness (parameter: FAIR)
It is possible to envision an AML that we use to characterize each application of this domain. In addition to all the details specified earlier, the language may include an indication of whether the simulation ends abruptly when the simulation time runs out or whether it winds down smoothly until all residual customers have been serviced and leave the system. This can be written as follows:
- WrapUp (ABRUPT) or
- WrapUp (SMOOTH)
Hence, for example, if we wanted to specify the simulation of waiting queues in a gas station, we would write the following:
Simulation gasStation
{
QS(FIFO, 1) pump1, pump2, pump3, pump4; // four gas pumps
CrossStation(NONE); // each pump services its own queue
Arrivals (MARKOV, ANY); // arrival law, random assignment to queues
CrossQueue(NONE); // each car stays in its queue
Statistics (WT, OR, MQL); // wait time, occupancy rate, maximum queue length
WrapUp (SMOOTH); // at closing, serve remaining cars
}
Ideally, one may want to define a formal AML, and build a compiler for it, in such a way that an application description such as this could be compiled into a finished application.
16.4.3 A Reference Architecture
The foregoing discussion yields a natural reference architecture for the proposed product line, whose main components include instances of the queue/station structure (QS), an Arrivals component, a Statistics component, and a main program to coordinate all these; this is illustrated in Figure 16.2. This figure describes the dataflow between these components; as for the control flow, it is basically limited to the main component invoking all the others in a sequential manner.
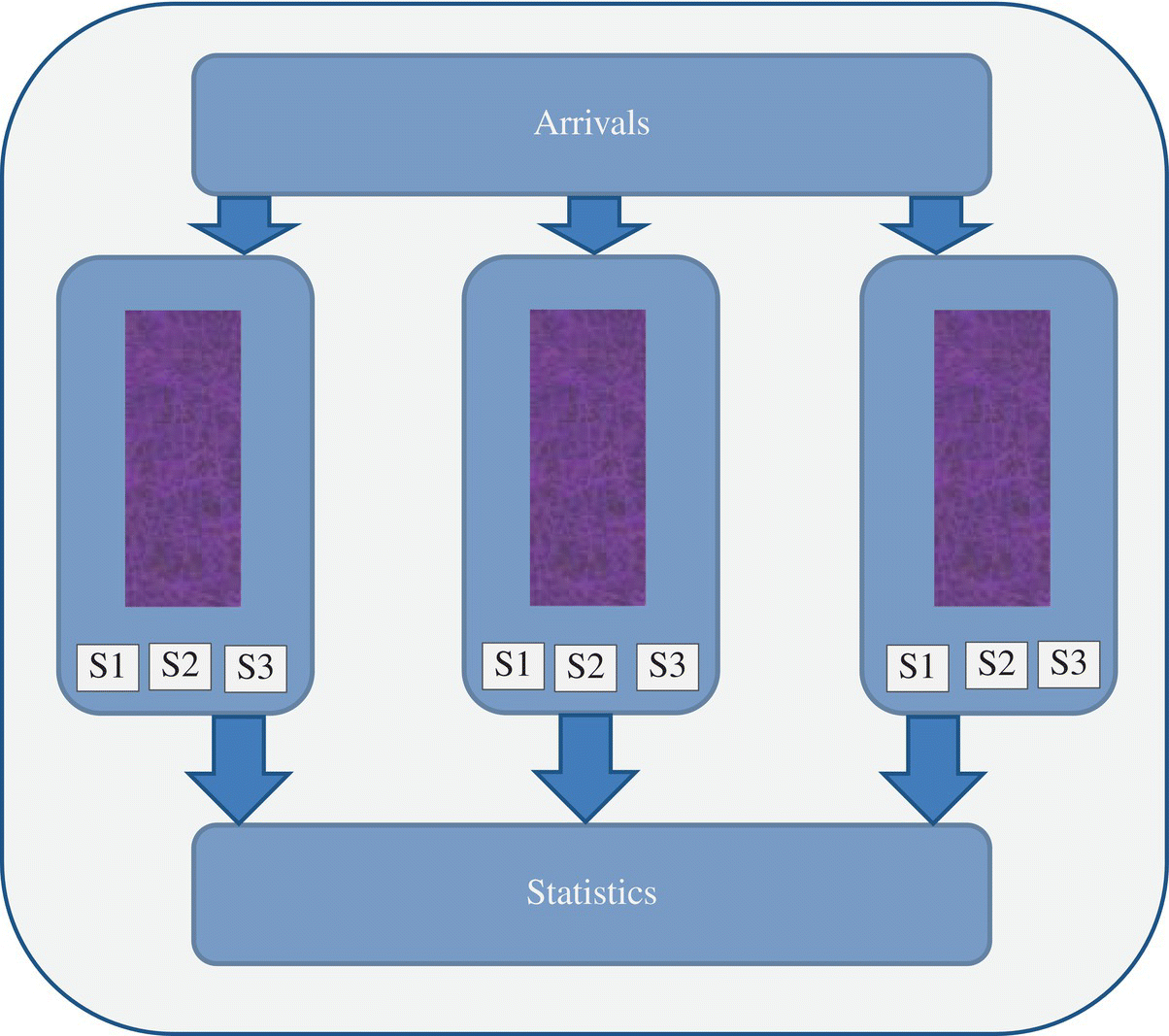
Figure 16.2 Reference architecture of the queue simulation product line.
We review the variabilities that we have listed in Section 16.4.1 and see how these map onto this architecture; in other words, once we decide on the value of a variability, we must determine which components must be modified and how. We consider the variabilities, in turn:
- Topology of Service Stations: This variability affects the main program, as well as the queue/station instances. This variability determines the number of QS instances we create and the number of service stations we declare for each.
- Service Time: This variability affects the Arrivals component as it determines how service requests are computed for incoming customers.
- Topology of Queues: This variability affects the main program, as well as the queue/station instances. This variability determines the number of QS instances we create and how queues are associated with service stations.
- Arrival Distribution: This variability affects the Arrivals component.
- Queuing Policy: This variability affects the declared instances of the QS components, as well as the relationships between them.
- Dispatching Policy: This variability affects the declared instances of the QS components, in the sense that it determines how idle stations determine where their next customer comes from; it also affects whether an idle station may take a customer from another QS component.
- Measurements: This variability affects the Statistics component, by determining what functions to collect data for during the simulation and to summarize at the end of the simulation.
- Wrap Up Policy: This variability affects the main program, in the sense that it determines the main simulation loop of the main program, by dictating the exit condition of the loop: To exit when the end of the simulation is up (abrupt) or when all the customers have cleared the system (smooth).
16.4.4 Domain Implementation
We choose to implement this product line in C++. In this section, we outline the broad structure of the main program, then we implement the main building blocks that are used in this product line. The main program reads as follows:
#include <iostream>line 1#include “qs.cpp”2#include “arrivals.cpp”3#include “statistics.cpp”4using namespace std;5typedef int clocktimetype;6typedef int durationtype;7/* State Objects */8qsclass qs1, qs2;9arclass arrivals;10stclass stats;11/* State Variables */12durationtype expduration;13int arrivalrate1, servicerate1; // for class 114int arrivalrate2, servicerate2; // for class 215int nbcustomers;16/* Working Variables */17clocktimetype clocktime;18customertype customer;19bool newarrival;20int locsum, locmin, locmax;21/* functions */22bool ongoingSimulation();23void elicitParameters();24int main ()25{26elicitParameters();27while (ongoingSimulation())28{29arrivals.drawcustomer(clocktime, expduration,30arrivalrate1, servicerate1, customer, newarrival);31if (newarrival) {nbcustomers++; qs1.enqueue(customer);}32arrivals.drawcustomer(clocktime, expduration,33arrivalrate2, servicerate2, customer, newarrival);34if (newarrival) {nbcustomers++; qs2.enqueue (customer);}35qs1.update(clocktime, locsum, locmin, locmax);36stats.record(locsum,locmin,locmax);37qs2.update(clocktime, locsum, locmin, locmax);38stats.record(locsum,locmin,locmax);39clocktime++;40};41cout << “concluded at time: ” << clocktime << endl;42stats.summary(nbcustomers);43}44bool ongoingSimulation()45{46return ((clocktime<=expduration) ||47(!qs1.done()) || (!qs2.done()));48};49void elicitParameters()50{51nbcustomers=0;52cout << “Length of Simulation” << endl;53cin >> expduration;54cout << “Arrival rate, Service Rate, Station 1” << endl;55cin >> arrivalrate1 >> servicerate1;56cout << “Arrival rate, Service Rate, Station 2” << endl;57cin >> arrivalrate2 >> servicerate2;58};59
As written, this main program refers to two identical QS components; but in general, it may refer to more than one type of QS components (as we recall, QS components may differ by their number of stations and their queuing policy). Also, this main program refers to an arrivals component, that determines the rate of customer arrivals, and a statistics component, that collects statistics. For the sake of simplicity, we have opted for a straightforward (tree-like) #include hierarchy between the various components of this program; the price of this choice is that most data has to transfer through the main program rather than directly between the subordinate components. Hence the decision of whether there is a new arrival and the selection of the new customer parameters transits through the main program (lines 30–31 and 32–34) on its way to the QS component that stores incoming customers (lines 32 and 35); likewise, statistical data is sent from the QS components (lines 36 and 38) to the statistics components (lines 37 and 39) via the main program. Note that while the topology and configuration of the queues and service stations is decided at application engineering time, the actual simulation parameters (experiment duration, arrival rate of each class of customers, service rate of each class of customers) are decided at run-time (line 27).
The QS component is defined by the following header file:
//********************************************************// Header file qs.h////********************************************************const int maxq = 1000; // max size of queueline 1const int nbs = 3; // number of stations for single queue2const int largewait=2000; // used for min wait3typedef int clocktimetype;4typedef int servicetimetype;5typedef int durationtype;6typedef int customeridtype;7typedef int indextype;8typedef struct9{customeridtype cid;10clocktimetype at;11servicetimetype st;12int ccat;13} customertype;14typedef struct15{customertype guest;16durationtype busytime;17int busyrate;18} stationtype;19class qsclass20{public:21qsclass (); // default constructor22bool done ();23void update (clocktimetype clocktime,24int& locsum, int& locmin, int& locmax);25bool emptyq () const; // tells whether q is empty26void enqueue (customertype qitem);27void dequeue ();28void checkfront (customertype& qitem) const;29int queuelength ();3031private:32customertype qarray [maxq];33stationtype sarray [nbs];34indextype front;35indextype back;36int qsize;37};38
The nbs parameter in this header file (line 2) indicates the number of service stations in the QS component; ideally, we would like to define a single QS component for each queuing policy (e.g., FIFO), and let nbs be a parameter (hence, e.g., writing QS(3) or QS(5) depending on the number of stations we want to have for each queue) but we do not believe C++ allows that; hence in practice we write a separate QS class for each different value of nbs and each different value of the queuing policy; in the case of this product line, if we adopt FIFO as the only queuing policy and ![]() as the only viable number of stations per queue, then only one QS class is needed. The state variables of this class include the queue infrastructure (qarray, front, back, qsize) as well as an array of service stations, of size nbs. In addition to the queue methods (emptyq, queuelength, checkfront, enqueue, dequeue), this class has two QS-specific methods, which are (Boolean-valued) done() and (void) update(clocktime, locsum, locmin, locmax). The former indicates that the QS component has no residual customers in its queue or its service stations; the latter updates the queue and service stations on the grounds that a new unit of time (minute, second, millisecond, etc.) has elapsed:
as the only viable number of stations per queue, then only one QS class is needed. The state variables of this class include the queue infrastructure (qarray, front, back, qsize) as well as an array of service stations, of size nbs. In addition to the queue methods (emptyq, queuelength, checkfront, enqueue, dequeue), this class has two QS-specific methods, which are (Boolean-valued) done() and (void) update(clocktime, locsum, locmin, locmax). The former indicates that the QS component has no residual customers in its queue or its service stations; the latter updates the queue and service stations on the grounds that a new unit of time (minute, second, millisecond, etc.) has elapsed:
- If a service station is still busy, it updates the remaining busy time thereof.
- If a service station has just completed serving a customer, it frees the customer and collects statistical data on it.
- If a service station is free and the queue is not empty, then it dequeues the customer at the front of the queue and loads it on the service station.
The arrivals component reads as follows:
****************************************************line 1//2// arrivals component;3// file arrivals.cpp, refers to header file arrivals.h.4//5//******************************************************6#include “arrivals.h” 7#include “rand.cpp”8arclass :: arclass ()9{SetSeed(673); customerid=1001;10};11void arclass :: drawcustomer (clocktimetype clocktime, int expduration,12int arrivalrate, int servicerate,13customertype& customer, bool& newarrival)14{float draw = NextRand();15newarrival = ((clocktime<=expduration) && 16(draw<(1.0/float(arrivalrate))));17if (newarrival)18{customer.cid = customerid; customerid = customerid+3;19customer.at = clocktime;20customer.st = 1+int(NextRand()*servicerate); 21}22}23
This component calls a random number generator using the parameters of arrival time to determine whether or not there is an arrival at time clocktime, and if there is an arrival, it uses the parameter of service time to draw the length of service needed by the new arriving customer, assigns it a customer ID, and timestamps its arrival time. This information is used subsequently for reporting purposes and/ or to compute statistics.
The header of the statistics component reads as follows:
//*********************************************** line 1// Header file statistics.h 2// 3//*********************************************** 4class stclass 5{public: 6stclass (); // default constructor 7void summary (int nbcustomers); 8void record (int locsum, int locmin, int locmax); 9private: 10int totalwait, minwait, maxwait; 11int totalstay, minstay, maxstay; 12}; 13
As written, this component maintains some information about wait times and stay times of customers in the system; it is adequate if all we are interested in are statistics about these two quantities; but it needs to be expanded if we are to support all the variabilities listed in Section 16.4.1. As written, this component has two main functions, which are as follows:
- Collecting data pertaining to wait times and stay times, which transits through the main program (rather than directly from the QS components)
- Summarizing the collected data and printing it to the output at the end of the simulation
16.4.5 Testing at Domain Engineering
In order to test the product line commonalities at domain engineering, we can proceed in one of the following two ways:
- Either we consider the components of the architecture, derive their specification as it emerges from the design of the reference architecture, and test them as self-standing components.
- Or we derive a reference application, that takes default values for the domain variabilities, or adopts frequently used variabilities.
Focusing on the first approach, we propose to consider individual components, pin down their specification as precisely as possible to derive their test oracle, build dedicated test drivers for them, and test them to an arbitrary level of thoroughness, as a way to gain confidence in the correctness and soundness of the product line assets.
As an illustration, we consider, for example, the arrivals components, and write a test driver for it, in such a way that its behavior can be checked easily. For example, if we invoke the arrivals component 10,000 times with an arrival rate of 4 and a service rate of 20, then we expect to generate about 2,500 new customers whose average service rate is about 10 units of time. Note that to write this test driver, we need not see the file arrivals.cpp (in fact it is better not to, for the sake of redundancy); we only need to see the (specification) file arrivals.h. We propose the following test driver:
#include <iostream> line 1#include “qs.cpp” 2#include “arrivals.cpp” 3using namespace std; 4typedef int clocktimetype; 5typedef int durationtype; 6/* State Objects */ 7arclass arrivals; 8/* Working Variables */ 9customertype customer; bool newarrival; 10int nbcustomers; durationtype totalst; 11int main () 12{for (int clocktime=1; clocktime<=10000;clocktime++)13{arrivals.drawcustomer(clocktime,10000,4,20,customer,newarrival); 14if (newarrival) {nbcustomers++;totalst=totalst+customer.st;} 15}; 16cout << “nb customers: ” << nbcustomers << endl; 17cout << “average service time: ” << float(totalst)/nbcustomers << endl;18} 19
Execution of this test driver yields the following output:
nb customers: 2506average service time: 10.7027
which corresponds to our expectation and enhances our faith in the arrivals component.
We could, likewise, test the QS component by generating and storing a number of customers in its queue, then monitoring how it handles the load. For example, we can generate 300 customers that each requires 20 units of service time, and see to it that it schedules them in 2000 minutes. We consider the following test driver:
#include <iostream> line 1#include “qs.cpp” 2#include “statistics.cpp” 3using namespace std; 45typedef int clocktimetype; 6typedef int durationtype; 78/* State Objects */ 9qsclass qs; 10stclass stats; 11/* Working Variables */ 12clocktimetype clocktime; 13customertype customer; 14durationtype expduration; int nbcustomers; 15int locsum, locmin, locmax; 16/* functions */ 17bool ongoingSimulation(); 1819int main () 20{clocktime=0; 21expduration = 0; // terminate whenever qs is empty 22customer.cid=1001; customer.at=0; customer.st=20; 23for (int i=1; i<=300; i++) {qs.enqueue(customer);}; 24nbcustomers=300; 25while (ongoingSimulation()) 26{qs.update(clocktime, locsum, locmin, locmax); 27stats.record(locsum,locmin,locmax); 28clocktime++; 29}; 30cout << “concluded at time: ” << clocktime << endl; 31stats.summary(nbcustomers); 32} 33bool ongoingSimulation() 34{return ((clocktime<=expduration) ||(!qs.done())); 35}; 36
The outcome of the execution of this test driver is the following output, which corresponds to our expectation: The 300 customers kept the 3 stations busy nonstop for a total of 100 × 20 minutes, that is, 2000 minutes. The sum of waiting times is an arithmetic series, of the form
Dividing this sum by the number of customers on each station (100) and replacing the arithmetic series by its closed form expression, we find
The minimum waiting time is 0, of course since the stations were available at the start of the experiment. The maximum waiting time is the waiting time of the last customer in each queue, which had to wait for the 99 customers before it, hence the maximum waiting time is 99 × 20 = 1980. All this is confirmed in the following output, delivered by the test driver (except for the minor detail that the test driver shows the closing time at 2001 rather than 2000, but that is because the main loop increments the clocktime at the bottom of the loop body).
concluded at time: 2001nb customers 300statistics, wait time (total, avg, min, max):297000 990 0 1980
Interestingly, running this test driver enabled us to uncover and remove a fault in the code of the QS component, which was measuring stay time rather than wait time. As far as domain engineering is concerned, we can perform testing under the following conditions:
- We test individual components rather than whole applications. Individual components lend themselves more easily to simple, compact specifications, which can be used as oracles.
- We test preferably components that have the least variability, or whose variabilities are trivial. Ideally, we want any confidence we gain about the correctness of a component to survive as the component is adapted to other applications.
In our case study, we have tested component qs with ![]() ; we can be reasonably confident that changing the value of nbs for the purposes of another application does not alter significantly the confidence we have in its correctness. But changing the queuing policy, however, (e.g., from FIFO to priority) will require a new testing effort. We are able to single out individual components, write test drivers for them, and design targeted test data that will exercise specific functionalities, and for which we know exactly what outcome to expect.
; we can be reasonably confident that changing the value of nbs for the purposes of another application does not alter significantly the confidence we have in its correctness. But changing the queuing policy, however, (e.g., from FIFO to priority) will require a new testing effort. We are able to single out individual components, write test drivers for them, and design targeted test data that will exercise specific functionalities, and for which we know exactly what outcome to expect.
All the testing effort that we carry out at the domain engineering phase is expended once, but will benefit every application that is produced from this product line. While the test we have conducted so far, and other tests focused on system components one at a time, give us confidence in the correctness of the individual components, they give us no confidence in the soundness of the architecture, nor in the integration of the components to form an application.
One way to test the architecture is to run experiments that exercise the interactions between different components of the architecture. Consider, for example, the interaction between two queue-station components in the context of a CrossStation() relation. We assume that the queue-station components are declared by the following AML statements:
QS(3) coach; QS(2) firstclass;CrossStation(firstclass, coach);Wrap-Up(Abrupt);
Then one way to test the interaction between the two queue-station components is to run the simulation with far more coach passengers than the coach service station can serve, and virtually no first passengers at all, and observe that the simulation proceeds as though we had a single coach queue for five coach stations. A sample of data that makes it possible is as follows:
- Coach arrival rate: one every 2 minutes, on average
- Coach service rate: 20 minutes, on average
- First Class arrival rate: 4000 minutes
- First Class service rate: 1 minute
- Duration of the Simulation: 2000 minutes
Then upon termination of the simulation, we may find that all five workstations were busy virtually 100% of the time.
16.4.6 Testing at Application Engineering
In the application engineering phase, we take the domain engineering assets and use them to build an application on the basis of specific requirement specifications. In application engineering, we avail ourselves of an executable product for which we have a product specification; hence we have everything we need to run a test; the issue here is to maximize return on investment by targeting test data to those aspects of the application that have not been adequately tested at domain engineering or have not been adequately covered by the test of other applications within the same domain. Also, we must test that the variabilities are bound correctly with respect to the AML specification.
We consider a sample application in our queue simulation domain, specified by the following AML statements:
Simulation airlineCheckin
{
QS(FIFO, 4) coach;
QS(FIFO, 2) firstClass;
CrossStation(NONE); // each class services its own queue
Arrivals (UNIFORM, CAT); // arrival law, assignment by category
CrossQueue(NONE); // each passenger stays in his/her queue
Statistics (WT); // wait time
WrapUp (SMOOTH); // when check-in ends, take no new
// passengers, but clear lines
}
In light of this specification, we propose to define two QS classes, one with four service stations, and one with two service stations. Also, we envision that the user specifies the arrival rate and service rate of each class of service (coach, first class), and to deliver statistics about wait times. This yields the following simulation program.
#include <iostream>#include “qs2.cpp”#include “qs4.cpp”#include “arrivals.cpp”#include “statistics.cpp”using namespace std;typedef int clocktimetype;typedef int durationtype;/* State Objects */qsclass2 qs2;qsclass4 qs4;arclass arrivals;stclass stats;/* State Variables */durationtype expduration;int arrivalrate2, servicerate2; // for class 2int arrivalrate4, servicerate4; // for class 4int nbcustomers;/* Working Variables */clocktimetype clocktime;customertype customer;bool newarrival, newdeparture;int locsum, locmin, locmax;/* functions */bool ongoingSimulation();void elicitParameters();int main (){elicitParameters();while (ongoingSimulation()){arrivals.drawcustomer(clocktime, expduration,arrivalrate2, servicerate2, customer, newarrival);if (newarrival) {nbcustomers++; qs2.enqueue(customer);}arrivals.drawcustomer(clocktime, expduration,arrivalrate4, servicerate4, customer,newarrival);if (newarrival) {nbcustomers++; qs4.enqueue(customer);}qs2.update(clocktime, locsum, locmin, locmax);stats.record(locsum,locmin,locmax);qs4.update(clocktime, locsum, locmin, locmax);stats.record(locsum,locmin,locmax);clocktime++;};cout << “concluded at time: ” << clocktime << endl;stats.summary(nbcustomers);}bool ongoingSimulation(){return ((clocktime<=expduration)||(!qs2.done())||(!qs4.done()));};void elicitParameters(){nbcustomers=0;cout << “Length of Simulation” << endl;cin >> expduration;cout << “Arrival rate, Service Rate, First Class” << endl;cin >> arrivalrate2 >> servicerate2;cout << “Arrival rate, Service Rate, Coach” << endl;cin >> arrivalrate4 >> servicerate4;};
Successive executions of this program with different arrival rates and service rates give the following results:
| Duration | First class | Coach | Time ended | Customers served | Average wait | Maximum wait | ||
| Arrival rate | Service rate | Arrival rate | Service Rate | |||||
| 900 | 4 | 24 | 3 | 19 | 1573 | 542 | 152 | 665 |
| 900 | 4 | 20 | 3 | 15 | 1321 | 542 | 95 | 415 |
| 900 | 4 | 16 | 3 | 12 | 1076 | 542 | 41 | 173 |
| 900 | 4 | 14 | 2 | 7 | 987 | 688 | 13 | 92 |
| 900 | 4 | 10 | 2 | 5 | 906 | 688 | 0.89 | 13 |
| 1000 | 5 | 20 | 4 | 14 | 1086 | 465 | 21 | 82 |
This Table Shows The Test Data Used For the experiment, as well as the output produced by the simulation. For completeness, we need an oracle that tells us whether the output produced by the simulation is correct; because of the random nature of the simulation, the oracle is not a deterministic function but rather the mean of a random variable. Hence, in terms of an oracle, we need to build an analytical model that shows the expected results of the simulation according to the parameters of the application (decided at application engineering time) and according to the parameters of the simulation (decided at run time). This model would be developed at domain engineering and applied for each application to serve as a test oracle.
16.5 CHAPTER SUMMARY
This chapter highlights the difficulty of testing software product lines, due to unbound specifications and to the combinatorial explosion that stems from multiple variabilities, and proposes some general principles to guide the testing process, which are as follows:
- All commonalities must be tested at domain engineering time.
- Variability-specific test artifacts must be generated at domain engineering time and deployed at application engineering time.
- Variability bindings must be tested at application engineering time.
- Applications must undergo some degree of integration testing, to make sure the composition of the application was carried out properly and that the components of the application work together as intended.
16.6 EXERCISES
- 16.1. Consider the following application specification in the domain of queue simulation, which represents a gas station that has four pumps:
Simulation gasStation
{
QS(FIFO, 1) pump1, pump2, pump3, pump4;
CrossStation(NONE); // each pump services its own queue
Arrivals (UNIFORM); // arrival law
CrossQueue(NONE); // each car stays in its queue
Statistics (WT); // wait time
WrapUp (ABRUPT); // when the station closes, the pumps stop
}
Develop a reference application according to the AML specification and use it to test the commonalities of the product line.
- 16.2. Insert five faults in the code of the queue simulation presented in Section 16.4. Deploy domain engineering tests and application engineering tests and identify which tests uncover the faults and which faults have been uncovered.
16.7 PROBLEMS
- 16.1 Build an analytical statistical model of the queue simulation that can predict, for each configuration and each set of input parameters, what are the expected values of the various statistical functions cited in the queue simulation.
- 16.2 Develop a product line that simulates the behavior of a prey–predator model, develop it, and design a testing policy for the product line. Consider that the model may involve an arbitrary number of species, with an arbitrary network of prey–predator relationships, and an arbitrary array of external factors (drought, disease, floods, etc.) that may affect some or all of the species.
16.8 BIBLIOGRAPHIC REFERENCES
The field of software product line testing is still in its infancy; while many researchers agree on the broad challenges facing the discipline, there is no consensus on a general solution. John McGregor (2001) was the first to draw attention to the unique nature and unique challenges of product line testing. Recent surveys of the field include Machado et al. (2014) and Engstrom and Runeson (2011). The sample example of the queue simulation product line is due to Mili et al. (2002). The domain engineering methodology adopted in this chapter is FAST, which is due to Weiss and Lai (1999). For more on software product lines, consult Weiss and lai (1999), Pohl et al. (2005), or Linden et al. (2007). Another source is the annual Software Product Line Conference(s) (SPLC) conferences at http://www.splc.net/.