
This chapter describes the fundamental concepts of integration, and is intended as an introduction to integration technology and terminology. You will:
- Learn the basic concepts, which are often used in the context of integration architecture
- Grasp an overview of the different architecture variants, such as point-to-point, hub-and-spoke, pipeline, and service-oriented architecture (SOA)
- Learn about service-oriented integration with an explanation of both the process and the workflow integration patterns
- Understand the different types of data integration and the accompanying patterns
- Gain an understanding of Enterprise Application Integration (EAI) and Enterprise Information Integration (EII), and an indication of how direct connection, broker, and router patterns should be used
- Understand developments in SOA resulting from the introduction of enterprise-wide events
- Understand the integration technologies of the future: grid computing and extreme transaction processing (XTP)
The term integration has a number of different meanings. A fundamental knowledge of the terms and concepts of integration is an essential part of an integration architect's toolkit. There are many ways of classifying the different types of integration. From an enterprise-wide perspective, a distinction is made between application-to-application (A2A), business-to-business (B2B), and business-to-consumer (B2C) integration. Portal, function, and data integration can be classified on the basis of tiers. Another possible grouping consists of integration based on semantics.
Fundamental integration concepts include Enterprise Application Integration (EAI), Enterprise Service Bus (ESB), middleware, and messaging. These were used to define the subject before the introduction of SOA, and still form the basis of many integration projects today. EAI is, in fact, a synonym of integration. In David Linthicum's original definition of EAI, it means the unrestricted sharing of data and business processes among any connected applications. The technological implementation of EAI systems is, in most cases, based on middleware. The main base technology of EAI is messaging, giving the option of implementing an integration architecture through asynchronous communication, using messages which are exchanged across a distributed infrastructure and a central message broker.
The fundamental integration architecture variants are:
- point-to-point
- hub-and-spoke
- pipeline
- service-oriented architecture
A point-to-point architecture is a collection of independent systems, which are connected through a network.
Hub-and-spoke architecture represents a further stage in the evolution of application and system integration, in which a central hub takes over responsibility for communications.
In pipeline architecture, independent systems along the value-added chain are integrated using a message bus. The bus capability is the result of interfaces to the central bus being installed in a distributed manner through the communication network, which gives applications local access to a bus interface. Different applications are integrated to form a functioning whole by means of distributed and independent service calls that are orchestrated through an ESB and, if necessary, a process engine.
A fundamental technique for integration is the usage of design patterns. These include process and workflow patterns in a service-oriented integration, federation, population, and synchronization of patterns in a data integration, and direct connection, broker, and router patterns, which form part of EAI and EII. It is important to be familiar with all of these patterns, in order to be able to use them correctly.
The most recent integration architectures are based on concepts such as event-driven architecture, grid computing, or extreme transaction processing (XTP). These technologies have yet to be tested in practice, but they are highly promising and of great interest for a number of applications, in particular, for corporate companies and large organizations.
The Trivadis Integration Architecture Blueprint applies a clear and simple naming to each of the individual layers. However, in the context of integration, a wide range of different definitions and terms are used, which we will explain in this chapter.
- Application to Application (A2A): A2A refers to the integration of applications and systems with each another.
- Business to Business (B2B): B2B means the external integration of business partners', customers', and suppliers' processes and applications.
- Business to Consumer (B2C): B2C describes the direct integration of end customers into internal corporate processes, for example, by means of Internet technologies.
- Integration types: Integration projects are generally broken down into integration portals, shared data integration, and shared function integration. Portals integrate applications at a user interface level. Shared data integration involves implementing integration architectures at a data level, and shared function integration at a function level.
- Semantic integration: One example of a semantic integration approach is the use of model-based semantic repositories for integrating data, using different types of contextual information.
- Enterprise Application Integration (EAI): EAI allows for the unrestricted sharing of data and business processes among any connected applications.
- Messaging, publish/subscribe, message brokers, and messaging infrastructures: These are integration mechanisms involving asynchronous communication using messages, which are exchanged across a distributed infrastructure and a central message broker.
- Enterprise Service Bus (ESB): An ESB is an integration infrastructure used to implement an EAI. The role of the ESB is to decouple client applications from services.
- Middleware: The technological implementation of EAI systems is, in most cases, based on middleware. Middleware is also described as communication infrastructure.
- Routing schemes: Information can be routed in different ways within a network. Depending on the type of routing used, routing schemes can be broken down into unicast (1:1 relationship), broadcast (all destinations), multicast (1:N), and anycast (1:N—most accessible).
Nowadays, business information systems in the majority of organizations consist of an application and system landscape, which has grown gradually over time. The increasing use of standard software (packaged applications) means that information silos will continue to exist. IT, however, should provide end-to-end support for business processes. This support cannot, and must not, stop at the boundaries of new or existing applications. For this reason, integration mechanisms are needed, which bring together individual island solutions to form a functioning whole. This happens not only at the level of an individual enterprise or organization, but also across different enterprises, and between enterprises and their customers. At an organizational level, a distinction is made between A2A, B2B, and B2C integration (Pape 2006). This distinction is shown in the image below. Each type of integration places specific requirements on the methods, technologies, products, and tools used to carry out the integration tasks. For example, the security requirements of B2B and B2C integrations are different from those of an A2A integration.

Modern concepts such as the Extended Enterprise integration across organizational boundaries, (Konsynski 1993) and the Virtual Enterprise (Hardwick, Bolton 1997) can be described using a combination of the different integration terms.
Integration projects are generally broken down into information portals, shared data integration, and shared function integration. Portals integrate applications at a user interface level. Shared data integration involves implementing integration architectures at a data level, and shared function integration at a function level.
The majority of business users need access to a range of systems in order to be able to run their business processes. They may need to be able to answer specific questions (that is, a call center taking incoming customer calls must be able to access the latest customer data) or to initiate or implement certain business functions (that is, updating customer data). In these circumstances, employees often have to use several business systems at the same time. An employee may need to access an order system (on a host) in order to verify the status of a customer order and, at the same time, may also have to open a web-based order system to see the data entered by the customer. Information portals bring together information from multiple sources. They display it in one place so that users do not have to access several different systems (which might also require separate authentication) and can work as efficiently as possible (Kirchhof et al. 2003). Simple information portals divide the user's screen into individual areas, each of which displays the data from one backend system independently, without interacting with the others. More sophisticated systems allow for limited interaction between the individual areas, which makes it possible to synchronize the different areas. For example, if the user selects a record in one area, the other areas are updated. Other portals use such advanced integration technology that the boundaries between the portal application and the integrated application become blurred (Nussdorfer, Martin 2006).
Shared databases, file replication, and data transfers fall in the category of integration using shared data (Gorton 2006).
- Shared databases: Many different business systems need to access the same data. For example, customer addresses may be required in an order system, a CRM system, and a sales system. This kind of data can be stored in a shared database in order to reduce redundancy and synchronization problems.
- File replication: Systems often have their own local data storage. This means that any centrally managed data (in a top-level system) has to be replicated in the relevant target databases, and updated and synchronized regularly.
- Data transfers: Data transfers are a special form of data replication in which the data is transferred in files.
In the same way that different business systems store redundant data, they also have a tendency to implement redundant business logic. This makes maintenance and adapting to new situations both difficult and costly. For example, different systems must be able to validate data using predefined, centrally managed business rules. It makes sense to manage such logic in a central place.
- EAI: The term EAI is generally used to describe all the methods which attempt to simplify the process of making a connection between different systems, in order to avoid a type of "spaghetti architecture" which results from the uncontrolled use of proprietary point-to-point connections. The systems are linked together with EAI solutions, instead of a single proprietary application programming interface (API).
- SOA: Service-oriented architecture is a term used to describe one way of implementing an enterprise architecture. SOA begins with an analysis of the business, in order to identify and structure the individual business areas and processes. This allows for the definition of services, which implement individual areas of business functionality. In an SOA, technical services are the equivalent of the specialist business areas, or functionality, in the business processes. This represents a major conceptual difference when compared with classic EAI solutions, which have a quite different focus. Their approach involves the simple exchange of data between systems, regardless of the technical semantics, and independently of any technical analysis of the processes.
In many cases, EAI solutions have only been able to fulfill the expectations placed on them to either a limited extent, or in an unsatisfactory way. This is, among other things, due to the following factors (Rotem-Gal-Oz 2007):
- EAI solutions are generally data oriented and not process oriented.
- EAI solutions do not address business processes. Instead, they are defined independently.
- EAI solutions are highly complex, and because of their use of proprietary technologies, do not allow for long-term protection of investments, which is possible when using open standards.
- EAI solutions need product-specific knowledge, which is only relevant in an EAI context, and cannot be reused in other projects.
- In the long term, EAI solutions are almost as costly to operate as the previously mentioned "home-made" spaghetti architectures.
If EAI solutions are used in combination with web services to link systems together, this is still not the equivalent of an SOA. Although the number of proprietary connection components between the systems being linked are reduced by the use of open WS-* standards, a "real" SOA involves a more extensive architectural approach, based on a (business) process-oriented perspective on integration problems.
While EAI is data driven and puts the emphasis on application interface integration, SOA is a (business) process-driven concept, which focuses on integrating service interfaces in compliance with open standards encapsulating the differences in individual integration approaches. As a result, it removes the barrier between the data integration and application integration approaches. However, SOA has one significant problem, which is that of semantic integration. Existing web services do not provide a satisfactory answer to this problem, but they do allow us to formulate the right questions in order to identify future solutions.
The challenge represented by semantic integration is based on the following problem:
- The representation of the data and the information contained in the data are often closely interlinked, and not separated into user data and metadata.
- The information suffers from the missing data context; there is no meta information defining how the data needs to be interpreted.
This means that the data structure and data information (its meaning) are often not the same thing and, therefore, have to be interpreted (Inmon, Nesavich 2008).
The following example will help to make this clearer:
A date, such as "7 August 1973," forms part of the data. It is not clear whether this information is a text string or in a date format. It may even be in another format and will have to be calculated on the basis of reference data before runtime. This information is of no relevance to the user.
However, it might be important to know what this date refers to, in other words, its semantic meaning in its reference context. Is it a customer's birthday, or the date on which a record was created? This example can even be more complex.
Another example that can be interpreted differently in different contexts is the term Caesar, for instance. Depending on the context, it could be the name of a pet or the name of pet food, a well-known salad, a gambling casino, or the name of a Roman emperor.
It is clear that data without a frame of reference is lacking any semantic information, causing the data to be ambiguous and possibly useless. Ontologically-oriented interfaces, as well as adaptive interfaces, can help to create such semantic reference and will become increasingly important in the field of autonomous B2B or B2C marketplaces in the future.
One semantic integration approach is, for example, the use of model-based semantic repositories (Casanave 2007). These repositories store and maintain implementation and integration designs for applications and processes (Yuan et al. 2006). They access existing vocabularies and reference models, which enable a standardized modeling process to be used. Vocabularies create a semantic coupling between data and specific business processes, and it is through these vocabularies that the services and applications involved are supplied with semantic information in the surrounding technical context. The primary objective of future architectures must be to maintain the glossary and the vocabularies, in order to create a common language and, therefore, a common understanding of all the systems and partners involved. Semantic gaps must be avoided or bridged wherever possible, for example transforming input and output data by using canonical models and standardized formats for business documents. These models and formats can be predefined for different industries as reference models [EDI (FIPS 1993), RosettaNet (Damodaran 2004), and so on]. Transformation rules can be generated and stored on the basis of reference models, in the form of data cards and transformation cards. In the future, there will be a greater focus on the declarative description (what?) and less emphasis on describing the concrete software logic (how?) when defining integration architectures. In other words, the work involved in integration projects will move away from implementation, and towards a conceptual description in the form of a generative approach, where the necessary runtime logic is generated automatically.
The term Enterprise Application Integration (EAI) has become popular with the increased importance of integration, and with more extensive integration projects. EAI is not a product or a specific integration framework, but can be defined as a combination of processes, software, standards, and hardware that allow for the end-to-end integration of several enterprise systems, and enable them to appear as a single system (Lam, Shankararaman 2007).
Tip
Definition of EAI
The use of EAI means the unrestricted sharing of data and business processes among any connected applications (Linthicum 2000).
From a business perspective, EAI can be seen as the competitive advantage that a company acquires when all its applications are integrated into one consistent information system. From a technical perspective, EAI is a process in which heterogeneous applications, functions, and data are integrated, in order to allow the shared use of data and the integration of business processes across all applications. The aim is to achieve this level of integration without major changes to the existing applications and databases, by using efficient methods that are cost and time effective.
In EAI, the focus is primarily on the technical integration of an application and system landscape. Middleware products are used as the integration tools, but, wherever possible, the design and implementation of the applications are left unchanged. Adapters enable information and data to be moved across the technologically heterogeneous structures and boundaries. The service concept is lacking, as well as the reduction of complexity and avoidance of redundancy offered by open standards. The service concept and the standardization only came later with the emergence of service-oriented architectures (SOA), which highlighted the importance of focusing on the functional levels within a company, and its business processes.
Nowadays, software products which support EAI are often capable of providing the technical basis for infrastructure components within an SOA. As they also support the relevant interfaces of an SOA, they can be used as the controlling instance for the orchestration, and help to bring heterogeneous subsystems together to form a whole. Depending on its strategic definition, EAI can be seen as a preliminary stage of SOA, or as a concept that competes with SOA.
SOA is now moving the concept of integration into a new dimension. Alongside the classic "horizontal" integration, involving the integration of applications and systems in the context of an EAI, which is also of importance in an SOA, SOA also focuses more closely on a "vertical" integration of the representation of business processes at an IT level (Fröschle, Reinheimer 2007).
SOAs are already a characteristic feature of the application landscape. It is advisable when implementing new solutions to ensure that they are SOA-compliant, even if there are no immediate plans to introduce an integration architecture, or an orchestration layer. This allows the transition to an SOA to be made in small, controllable steps, in parallel with the existing architecture and on the basis of the existing integration infrastructure.
Integration architectures are based on at least three or four integration levels (after Puschmann, Alt 2004 and Ring, Ward-Dutton 1999):
- Integration on data level: Data is exchanged between different systems. The technology most frequently used for integration at data level is File Transfer Protocol (FTP). Another widespread form of data exchange is the direct connection of two databases. Oracle databases, for example, exchange data via database links or external tables.
- Integration on object level: Integration on object level is based on data-level integration. It allows systems to communicate by calling objects from outside the applications involved.
- Integration on process level: Integration on process level uses workflow management systems. At this level, communication between the different applications takes place through the workflows, which make up a business process.
Message queues were introduced in the 1970s as a mechanism for synchronizing processes (Brinch Hansen 1970). Message queues allow for persistent messages and, therefore, for asynchronous communication and the guaranteed delivery of messages. Messaging decouples the producer and the consumer with the only common denominator being the queue.

The most important properties of messaging, quality attributes of messaging, are shown in the following table:
|
Attribute |
Comment |
|---|---|
|
Availability |
Physical queues with the same logical name can be replicated across several server instances. In the case of a failure of one server, the clients can send the message to another. |
|
Failure handling |
If communication between a client and a server fails, the client can send the message via failover mechanisms to another server instance. |
|
Modifiability |
Clients and servers are loosely coupled by the messaging concept, which means that they do not know each other. This makes it possible for both clients and servers to be modified without influencing the system as a whole. Another dependency between producer and consumer is the message format. This dependency can be reduced or removed altogether by introducing a self-descriptive general message format (canonical message format). |
|
Performance |
Messaging can handle several thousands of messages per second, depending on the size of the messages and the complexity of the necessary transformations. The quality of service also has a major influence on the overall performance. Non-reliable messaging, which involves no buffering provides better performance than reliable messaging, where the messages are stored (persisted) in the filesystem or in databases (local or remote), to ensure that they are not lost if a server fails. |
|
Scalability |
Replication and clustering make messaging a highly scalable solution. |
Publish/subscribe represents an evolution of messaging (Quema et al. 2002). A subscriber indicates, in a suitable form, its interest in a specific message or message type. The persistent queue guarantees secure delivery. The publisher simply puts its message in the message queue, and the queue distributes the message itself. This allows for many-to-many messaging:

The most important properties of publish/subscribe, quality attributes of publish/subscribe, are listed in the following table:
|
Attribute |
Comment |
|---|---|
|
Availability |
Physical topics with the same logical name can be replicated across several server instances. In the case of the failure of one server, the clients can send the message to another. |
|
Failure handling |
In the case of the failure of one server, the clients can send the message to another replicated server. |
|
Modifiability |
The publisher and the subscriber are loosely coupled by the messaging concept, which means that they do not know each other. This makes it possible for both publisher and subscriber to be modified without influencing the system as a whole. Another dependency is the message format. This can be reduced or removed altogether by introducing a self-descriptive, general message format (canonical message format). |
|
Performance |
Publish/subscribe can process thousands of messages per second. Non-reliable messaging is faster than reliable messaging, because reliable messages have to be stored locally. If a publish/subscribe broker supports multicast/broadcast protocols, several messages can be transmitted to the subscriber simultaneously, but not serially. |
|
Scalability |
Topics can be replicated across server clusters. This provides the necessary scalability for very large message throughputs. Multicast/broadcast protocols can also be scaled more effectively than point-to-point protocols. |
A message broker is a central component, which is responsible for the secure delivery of messages (Linthicum 1999). The broker has logical ports for receiving and sending messages. It transports messages between the sender and the subscriber, and transforms them where necessary.
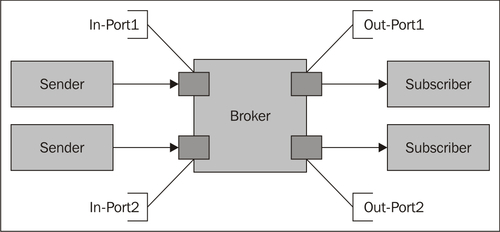
The most important tasks of a message broker, as shown in the preceding diagram, are implementing a hub-and-spoke architecture, the routing, and the transformation of messages.
- Hub-and-spoke architecture: The broker acts as a central message hub with the senders and receivers arranged like spokes around it. Connections to the broker are done through adapter ports that support the relevant message format.
- Message routing: The broker uses processing logic to route the messages. Routing decisions can be hardcoded, or can be specified in a declarative way. They are often based on the content of the message (content-based routing) or on specific values or attributes in the message header (attribute-based routing).
- Message transformation: The broker logic transforms the message input format into the necessary message output format.
The most important properties of a message broker, quality attributes of a message broker, are listed in the following table:
|
Attribute |
Comment |
|---|---|
|
Availability |
To provide high availability, brokers must be replicated and operate in a clusters. |
|
Failure handling |
Brokers have different types of input ports that validate incoming messages to ensure that they have the correct format, and reject those with the wrong format. If one broker fails, the clients can send the message to another replicated broker. |
|
Modifiability |
Brokers separate transformation logic and routing logic from one another and from senders and receivers. This improves modifiability, as the logic has no influence on senders and receivers. |
|
Performance |
Because of the hub-and-spoke approach, brokers can potentially be a bottleneck. This applies in particular in the case of a high volume of messages, large messages and complex transformations. The throughput is typically lower than with simple reliable messaging. |
|
Scalability |
Broker clusters allow for high levels of scalability. |
A messaging infrastructure provides mechanisms for sending, routing, and converting data, between different applications running on different operating systems with different technologies, as shown in the following diagram (Eugster et al. 2003):
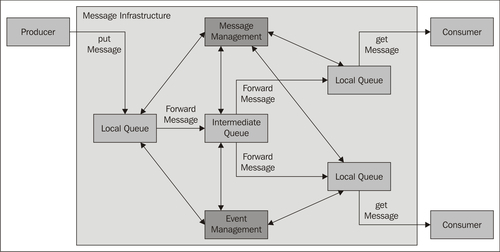
A messaging infrastructure involves the following parties/components:
- Producer: An application which sends messages to a local queue.
- Consumer: An application which is interested in specific messages.
- Local queue: The local interface of the messaging infrastructure. Each message sent to a local queue is received by the infrastructure and routed to one or more receivers.
- Intermediate queue: In order to ensure that messages are delivered, the infrastructure uses intermediate queues, in case a message cannot be delivered, or has to be copied for several receivers.
- Message management: Message management includes sending, routing, and converting data, together with special functions, such as guaranteed delivery, message monitoring, tracing individual messages, and error management.
- Event management: The subscription mechanism is controlled through special events.
An Enterprise Service Bus is an infrastructure that can be used to implement an EAI. The primary role of the ESB is to decouple client applications from services, as shown in the following diagram (Chappell 2004):

The encapsulation of services by the ESB means that the client application does not need to know anything about the location of the services, or the different communication protocols used to call them. The ESB enables the shared, enterprise-wide, and even intra-enterprise use of services and separate business processes from the relevant service implementations (Lee et al. 2003).
The major SOA vendors now offer specific Enterprise Service Bus products, which provide a series of core functions in one or another form, shown in the following diagram:

The following diagram shows the basic structure of an ESB in a vendor-neutral way:
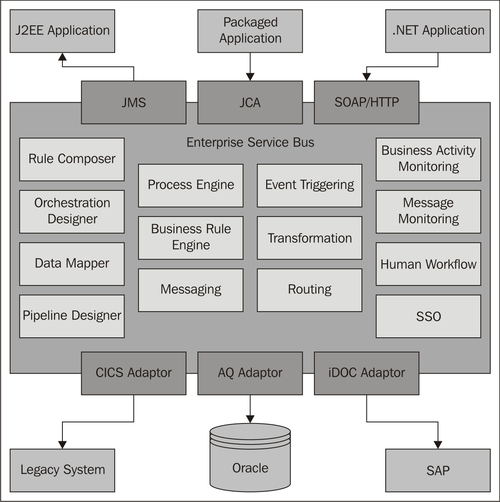
The naming for the single components used by the different vendors of SOA products will vary from those shown in the above diagram, but the products provide the following functions as a minimum (Craggs 2003):
- Routing and messaging as base services
- A communication bus, which enables a wide variety of systems to be integrated using predefined adapters
- Transformation and mapping services for a range of different conversions and transformations
- Mechanisms for executing processes and rules
- Monitoring functions for a selection of components
- Development tools for modeling processes, mapping rules, and message transfers
- A series of standardized interfaces, such as JMS (Java Messaging Specification (Hapner et al. 2002)), JCA (Java Connector Architecture (JCASpec 2003)), and SOAP/HTTP
In most cases the technological realization of EAI systems is done through what is commonly termed middleware. Middleware is also described as a communication infrastructure. It allows communication between software components, regardless of the programming language in which the components were created, the protocols used for communication, and the platform on which the components are running (Thomson 1997). A distinction is made between the different types of middleware according to the methods of communication used, and the base technology.
Communication methods for middleware can be broken down into five categories:
- Conversational (Dialog-Oriented): The components interact synchronously with one another. They always react instantly to the information being exchanged. This type of communication is generally used in real-time systems.
- Request/reply: This is used when an application needs to call functions from another application. It corresponds to a call to a subroutine, with the important difference that the communication can take place over a network.
- Message passing: This enables information to be exchanged in a simple and well-directed way using messages. Communication takes place in one direction only. If an application wants to react to an incoming message, its response must be placed in another message.
- Message queuing: Information is exchanged in the form of messages which are sent through a queue, in other words, indirectly. Queuing allows the secure, planned, and prioritized delivery of messages. It is often used for the near real-time exchange of information between loosely coupled systems.
- Publish/subscribe: Two roles are involved in non-directed communication: the publisher of a message sends the message only to the middleware. The subscriber subscribes to all the types of message that are of interest to him or her. The middleware ensures that all subscribers receive the corresponding messages from a publisher.
|
Middleware type |
Communication |
Relationship |
Synchronous/ asynchronous |
Interaction |
|---|---|---|---|---|
|
Peer-to-peer, API |
Conversational |
1:1 |
Synchronous |
Blocking |
|
Database gateways |
Request/reply |
1:1 |
Synchronous |
Blocking |
|
Database replication |
Request/reply/ Message queue |
1:N 1:N |
Synchronous Asynchronous |
Blocking Non-blocking |
|
Remote procedure calls |
Request/reply |
1:1 |
Mostly synchronous |
Mostly blocking |
|
Object request brokers |
Request/reply |
1:1 |
Mostly synchronous |
Mostly blocking |
|
Direct messaging |
Message passing |
1:1 |
Asynchronous |
Non-blocking |
|
Message queue systems |
Message queue |
M:N |
Asynchronous |
Non-blocking |
|
Message infrastructure |
Publish/subscribe |
M:N |
Asynchronous |
Non-blocking |
Middleware can be broken down into the following base technologies:
- Data-oriented middleware: The integration or distribution of data to different RDBMS using the appropriate synchronization mechanisms.
- Remote procedure call: The implementation of the classic client/server approach.
- Transaction-oriented middleware: The transaction concept (ACID—Atomicity, Consistency, Isolation, Durability) is put into effect using this type of middleware. A transaction is a finite series of atomic operations which have either read or write access to a database.
- Message-oriented middleware: The information is exchanged by means of messages, which are transported by the middleware from one application to the next. Message queues are used in most cases.
- Component-oriented middleware: This represents different applications and their components as a complete system.
Information can be routed in different ways within a network. Depending on the type of routing used, routing schemes can be broken down into the following four categories:
- Unicast (1:1 relationship)
- Broadcast (all destinations)
- Multicast (1:N)
- Anycast (1:N, most accessible)
The unicast routing scheme sends data packages to a single destination. There is a 1:1 relationship between the network address and the network end point:

The broadcast routing scheme sends data packets in parallel to all the possible destinations in the network. If there is no support for this process, the data packets can be sent serially to all possible destinations. This produces the same results, but the performance is reduced. There is a 1:N relationship between the network address and the network end point.

The multicast routing scheme sends data packets to a specific selection of destinations. The destination set is a subset of all the possible destinations. There is a 1:N relationship between the network address and the network end point:

