
The process layer is part of the application level and is responsible for orchestrating component and service calls. It manages the building blocks in the mediation layer (if they cannot act autonomously). This supports and simplifies the implementation of complex integration processes.
The responsibility of the process layer is to manage and control the building blocks in the mediation layer.
The basic requirements for the implementation of the process layer are listed in the following table, along with where in the book to find more information:
|
Requirement |
Section of Chapter 1 |
|---|---|
|
SOA |
Service-oriented integration |
|
Event-driven architecture |
Event-driven architecture |
|
Complex event processing |
Complex event processing XTP and CEP |
The base technologies needed for the implementation of the process layer are listed in the following table.
|
Base technology |
Section of Chapter 2 |
|---|---|
|
Service Component Architecture (SCA) |
Service Component Architecture (SCA) |
|
Process modeling |
Process modeling |
The following building blocks are used in the process layer:
Job schedulers manage, automate, monitor, and plan dependencies between programs. Jobs and programs are started and made dependent on one another across different computers under the control of the scheduler, which allows complex dependencies to be created.
The basic features of a job scheduler are as follows:
- An interface for defining jobs, workflows, and dependencies between jobs
- Automatically starting jobs
- An interface for monitoring and troubleshooting jobs
- Priorities and/or queues to control the execution order of unrelated jobs
Most operating systems provide basic job-scheduling capabilities, such as cron, which runs on Unix. Job schedulers also form part of database, ERP, and business process management systems. However, these often do not meet the complex requirements of enterprise job scheduling. In this case, it is worth installing specific job scheduler software, such as Cronacle, IBM Tivioli Workload Scheduler, Open Source Job Scheduler, or Quartz.
In the IT world, the term portal is used to describe a central point of access which makes customized, internal and external information and services available. The focus is on the provision of cross-application services (in other words, integration) and not on the technical (for example, web-based) implementation.
A workflow, which is an executable process, is by far the most important building block in the process layer. Workflow building blocks form the basis for implementing the technical processes that control an integration solution. They can be implemented, for example, in Business Process Execution Language (BPEL) using a BPEL engine. All the workflow building blocks can be created using BPEL.
The following table gives an overview of the building blocks used to produce workflows:
|
Building block |
Description |
|---|---|
|
Basic control patterns | |
|
Sequence |
Executes one or more activities in sequence. |
|
Parallel split |
Executes two or more activities in sequence or in parallel. |
|
Synchronization |
Synchronizes two or more activities running in sequence or in parallel. Waits to continue until all the previous activities have been completed. Also known as barrier synchronization. |
|
Exclusive choice |
One of several execution paths is selected, on the basis of information which must be available at the time when the exclusive choice activity is executed. |
|
Simple merge |
Waits to complete one of several activities before continuing with processing. The assumption is that only one of these activities is executed. This is generally because these activities are on different paths, based on an exclusive choice or deferred choice. |
|
Advanced branching and synchronization patterns | |
|
Multiple choice |
Selects several execution paths from a number of alternatives. |
|
Synchronizing merge |
Brings together several execution paths and synchronizes them, if several paths were in use. Performs the same role as the simple merge, if only one execution path was in use. |
|
Multiple merge |
A point in a workflow process where two or more paths are merged without being synchronized. If more than one path was activated, then after the merge, one activity is started for each incoming path. |
|
Discriminator |
A point in the workflow process that waits for one of the incoming paths to be completed before activating the next activity. From that moment on, the discriminator waits for all the remaining paths to be completed, but ignores the results. After all the incoming paths have been activated, the pattern is reset and can be reactivated. (This is important, because it could not otherwise be used in a loop.) |
|
Advanced branching and synchronization patterns | |
|
N-out-of-M join |
Similar to the discriminator pattern, but this pattern makes it possible to wait for more than one preceding activity (N) which is to be completed, and then to continue with the next activity. The subsequent activity is only activated when the N paths have been completed. |
|
Structural patterns | |
|
Arbitrary cycles |
A point in the workflow where one or more activities are executed several times. |
|
Implicit termination |
Terminates a process instance when there is no more to be done. |
|
Multiple instances (MI) patterns | |
|
Multiple instances without synchronization |
Several instances of an activity are created for one process instance and each is executed in a separate thread. No synchronization takes place. |
|
Multiple instances with a priori known design time knowledge |
Several instances of an activity are created for one process instance. The number of instances of a given activity is known at design time. |
|
Multiple instances with a priori known runtime time knowledge |
Several instances of an activity are created for one process instance, but the number of instances is not known until runtime. At a specific point during runtime, the number can be determined (as in a FOR loop, but with parallel processing). |
|
Multiple instances without a priori runtime knowledge |
Several instances of an activity are created for one process instance, but the number of instances is not known at design time. Even at runtime it is not clear how many instances will finally be needed until the activities are established. The difference between this and the previous pattern is that after the parallel instances have been completed, or when instances are still being executed, additional, new instances of an activity can be created at any time. |
|
State-based patterns | |
|
Deferred choice |
Executes one of several alternative paths. The alternative to be executed is not selected on the basis of the data available at the time of the deferred choice, but is determined by an event (for example, when an end user chooses a task from a work-list). |
|
Interleaved parallel routing |
Executes a number of activities in random order, possibly depending on the availability of resources. The order is not known until runtime and none of the activities are executed at the same time (in other words, in parallel). |
|
Milestone |
An activity is only executed when the process has a specific status, in other words, a specific milestone has been reached. Otherwise, the activity is not activated. |
|
Cancellation patterns | |
|
Cancel activity |
Stops an active activity that is being executed. |
|
Cancel case |
Stops an entire active process. |
The most commonly used CEP technology patterns are described here to provide support for the implementation of integration solutions based on an event-driven architecture (Coral8 2007).
- Filtering: A simple pattern for filtering events out of one or more event streams. A filter expression is applied to the incoming events and if the condition is
true, the event is published in the output stream.
- In-memory caching: This pattern keeps events in memory, for example for a time-based window covering the last 10 minutes. This forms the basis for many other CEP design patterns.
The cache typically stores two kinds of data:
- Aggregation over windows: Computes statistics over different types of sliding windows (for example, a time-based window covering the last 10 minutes or an event-based window with the last 10 events).

- Database lookups: Accessing databases to compare historical information or references with incoming events.
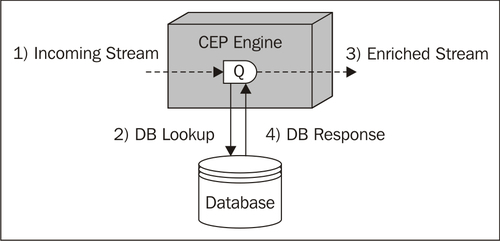
- Database writes: Sending raw or derived events to a database.
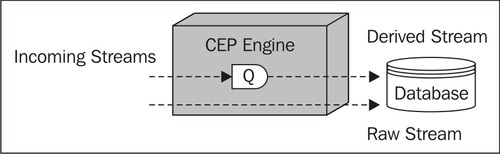
- Correlation (joins): Joining multiple event streams.

- Event pattern matching: Complex time-based patterns of events across multiple streams.

- State machines: Modeling complex behavior and processes through state machines.

- Hierarchical events: Processing, analyzing and composing hierarchical events.

- Dynamic queries: Submitting parameterized queries, requests and subscriptions dynamically.

