
This chapter describes a selection of the base technologies related to the implementation of solutions based on the Trivadis Integration Architecture Blueprint. It will:
- Cover transactions and transaction strategies
- Contain a description of Open Grid Services infrastructure (OGSi), a dynamic, hardware-independent software platform
- Consider Java Connector Architecture (JCA), which is a general architecture for connecting heterogeneous systems
- Explain Java Business Integration (JBI) as a standardized description of the functions of an Enterprise Service Bus (ESB)
- Describe Service Component Architecture (SCA) in terms of a model for developing applications and systems based on a Service-Oriented Architecture (SOA)
- Present Service Data Objects (SDO) as a Disconnected Data Architecture
- Cover process modeling, including a description of the most important standards for modeling business processes
The base technologies that currently play a role in the implementation of integration solutions include transactions and standards such as OGSi, JCA, JBI, SCA, and SDO, all of which we will cover in this chapter.
Transactions and transaction strategies have a central function in every type of architecture. Knowledge of the options available, and the differences between the options, is essential when choosing suitable data access strategies. Important aspects include transactional systems, isolation levels, two-phase commit, and global (XA) transactions (a transaction that may span multiple resources, also known as a Distributed Transaction).
Open Grid Services infrastructure (OGSi) is a hardware-independent, dynamic software platform which simplifies the process of modularizing distributed applications and their services, and managing them throughout their entire life cycle. The OSGi platform requires a Java Virtual Machine (JVM) and provides a framework on the basis of the JVM. The most important features of OSGi are the OSGi architecture, the component model (the bundles), and the collaborative model.
Java Connector Architecture (JCA) is a general architecture in the Java Enterprise Edition (JEE) environment used to connect heterogeneous systems, such as legacy applications, through a standardized interface in the form of a resource adapter. Other standardized interfaces defined by the JCA specification allow for collaboration with other system components.
The Java Business Integration (JBI) specification describes the functionality of a standardized ESB. JBI can also be regarded as a service-oriented meta-container that implements a component architecture. JBI uses two types of containers: service engines and binding components. The service engines contain the business logic, while the binding components merely act as a proxy for the service users.
Service Component Architecture (SCA) is a collection of specifications that describe a model for developing applications and systems on the basis of an SOA. SCA models solutions as groups of service components that provide services and include references to other services. Functionality is made available externally as a service in the form of interfaces. Service components have properties that describe the specific characteristics of the components and are used to configure them.
Service Data Objects (SDO) offer a consistent model for managing data, regardless of its source system and source format. SDO makes use of a Disconnected Data Architecture. Although SCA and SDO can be used independently of one another, a combination of the two specifications represents a powerful and flexible tool for developing distributed applications.
One important base technology used in the majority of integration projects consists of business process modeling tools. The modeling process is always done using graphical tools. The Trivadis Integration Architecture Blueprint envisions the usage of graphical tools that support a clearly defined modeling notation. A number of these notations are available. The most important ones are Business Process Modeling Notation (BPMN), Event-Driven Process Chain (EPC), and Business Process Execution Language (BPEL).
Transactions and transaction strategies play a central role in every architecture. A knowledge of the options available and the differences between them is essential when choosing suitable data access strategies. This section covers the aspects relating to integration. These include transactional systems, isolation levels, two-phase commit, and XA transactions.
- Transactional systems: These allow for controlled "all-or-nothing" data manipulation.
- Isolation levels: These levels coordinate data access by parallel transactions and, depending on the level, determine the visibility of the manipulated data. There are four different isolation levels:
- serializable
- repeatable read
- read committed
- read uncommitted
- Two-phase commit: The two-phase commit is the algorithm on which transactions are based. It requires all the systems participating in a transaction to commit to the successful completion of the transaction.
- XA transactions: An XA transaction is a standardized, global transaction that can span several (heterogeneous) resources. XA uses a two-phase commit to ensure that all resources either commit, or rollback, any particular transaction simultaneously.
Transaction processing systems and the theoretical concepts that lie behind them have existed in one form or another since the 1970s and were developed by database guru Jim Gray (Lindsay 2008).
The purpose of transactions and of the infrastructure components that support them is "all-or-nothing" data manipulation within a unit of work (Gray, Reuter 1993).
The following brief example will help to make this clearer:
Say you want to make a bank transfer. This involves debiting the amount from your account and crediting it to another account. The bank transfer process, its sub-activities (debiting and crediting), and the data manipulation involved (deducting the amount from the first account, adding it to the second account) represent a unit of work. This takes place within one transaction to ensure that none of the sub-activities are carried out individually, for example, a debit without a credit or vice versa. The two processes are only valid in combination, even if system errors occur. This consistency is made possible by the use of transactions.
All the operations in a transaction are enclosed within a transaction boundary, as shown in the following figure. It contains all the individual operations, which make up the transaction.

Transactions can be completed in one of two ways:
- Successful—commit
- Unsuccessful—rollback
In the case of a commit, all the changes made during the transaction are reflected in the system. As transactional systems are generally databases or other persistent components, the state changes made in a commit are saved permanently. In the event of a rollback, all the state changes are reversed. Atomic transactions can be nested, but many systems do not support this. In this case, sub-transactions (nested transactions) are provisional, and are only completed when the top-level transaction is completed (commit or abort).

A transaction coordinator is always associated with transactions, as shown in this figure. This infrastructure component manages, monitors, and coordinates the transactions. A coordinator can take the form of an independent component or, for performance reasons, can be part of the application. The coordinator communicates with participants assigned to the transaction (for example, a database and the application which is accessing it) and controls the necessary termination actions, in other words, the commit or the rollback. Different transaction types and mechanisms have different forms of communication and participants (local, remote, distributed, homogeneous, heterogeneous, and so on). The XA protocol for global transactions is often used in distributed environments with several heterogeneous transactional resources (for example, an RDBMS and an XML database).
In many systems, a transaction manager is responsible for managing the transaction coordinators, which coordinate large numbers of transactions. The initiating resource starts the transaction in the transaction manager, and a coordination manager is assigned to the transaction.
Atomic transactions have the following properties, which are also known by the acronym ACID:
- Atomicity: The transaction can be successfully completed (commit) or can be unsuccessful as a result of system errors or program crashes (abort). In the first case, all the changes to the data are implemented as if the changes had taken place in one single (atomic) step. In the event of an abort, all the changes made up to this point in the transaction are reversed (rollback), and the system is returned to its status before the transaction started. Atomic transactions cannot be broken down. If an abort occurs, the system is unchanged. Otherwise, all the changes (not just part of them) are implemented.
- Consistency: Transactions produce consistent results. As a result, they guarantee that the application and the business logic have a well-defined status.
- Isolation: When concurrent transactions are processed, the interim results that occur during the transaction are not visible to other transactions, as long as this transaction is not yet completed. If several transactions are executed simultaneously, they must not influence each other.
- Durability: The system status created by a successful transaction completion (commit) is guaranteed to be durable.
There are four different transaction isolation levels, or, in other words, states that are recognized separately by different parallel transactions. A partial breakup of strict isolation is permitted in many scenarios to improve performance. In order to provide the highest level of process isolation (serializable), data must be blocked. The process that initiates the transaction puts locks on the data. The result is a reduction in the possible process concurrency, in other words, the possible parallelization. Transactions represent a processing bottleneck. The aim of the additional, more relaxed isolation levels is to improve performance compared to strict serialization, by making optimistic assumptions.
In descending order of isolation properties, that is, with increasing visibility and the related possibility of data inconsistencies, the four isolation levels of the ANSI/ISO SQL standard are:
- Serializable
- Repeatable read
- Read committed
- Read uncommitted
All the transactions are completely isolated from each other. They appear to take place serially, one after another. So-called phantom reads, which will be explained later in the chapter, cannot occur, as shown in the following diagram:

Data that has been read (in an RDBMS with a SELECT, for example) cannot be changed. On this isolation level, read locks are required on all data that has been read. However, range locks are not needed, as shown in the following diagram:
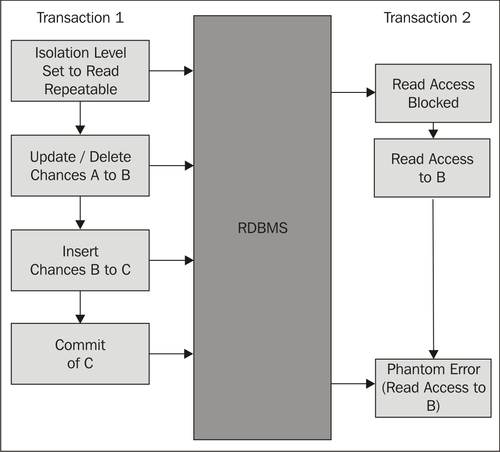


A phantom read occurs when transaction 2 can read data created by transaction 1, but transaction 1 has not yet been completed with a commit. Phantom reads can take place in the following ANSI/ISO SQL standard isolation levels:
- Repeatable read
- Read committed
- Read uncommitted
Phantom reads are not possible in the serializable isolation level. The following table gives an overview of this:
|
Isolation level |
Behavior | ||
|---|---|---|---|
|
Dirty read |
Non-repeatable read |
Phantom read | |
|
Serializable |
No |
No |
No |
|
Repeatable Read |
No |
No |
Yes |
|
Read Committed |
No |
Yes |
Yes |
|
Read Uncommitted |
Yes |
Yes |
Yes |
Different products use the possible isolation levels and the standardized versions in very different ways. In many cases, only a subset of the four options is supported. In some products, additional product-specific syntax must be added to a SELECT to enforce a read lock.
The Two-Phase Commit is the basic mechanism for implementing global transactions. The Two-Phase Commit protocol is a distributed algorithm, which requires all the resources in a distributed system that are participating in a transaction to complete the transaction successfully (commit). The result is that all the resources complete the transaction with a commit, or reverse it with an abort. This is also guaranteed in the event of network errors and/or server failures. A server node takes on the role of coordinator. On each of the participating nodes, there must be the possibility of buffering the local transaction status in order to ensure that, if a server crashes, the transaction can be canceled and the log data is never lost or corrupted (except, of course, in the case of total failures). In addition, the participating nodes must be able to communicate with one another. In particular, where there is a heavy transaction load, the communication latency of the network can be a significant performance factor.
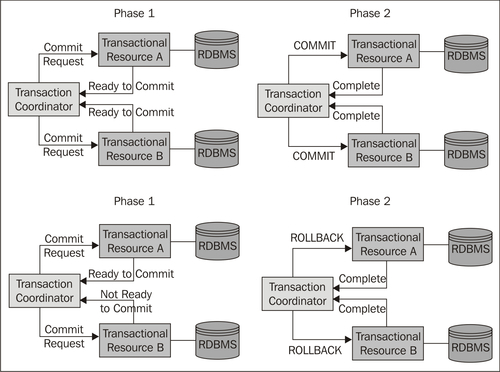
The concept of Two-Phase Commit is the result of implementing the algorithm, which can be divided into the commit request and the commit phases, as shown in this diagram.
- Commit request: The transaction coordinator asks the participating resources if they are prepared to commit. Depending on the local transaction results (commit or abort), the individual resources send a corresponding reply.
- Commit: On the basis of the result of the commit request phase, the transaction coordinator instructs the participating resources to implement a commit or abort locally.
This protocol is shown in the following diagram:

It is initiated by the transaction coordinator when the final step in the transaction is reached. A Two-Phase Commit is made possible by the bidirectional communication of the XA protocol. The Two-Phase Commit is not possible in non-XA transactions, as these protocols are unidirectional and the transaction manager cannot receive any responses from the resource manager. The majority of transaction managers communicate with the resource managers in phase 1 and 2 in parallel in multiple threads, in order to improve performance. By parallelizing communication, the resources can be released at the earliest possible point.
An XA transaction is a global (top-level) transaction, which can span several (heterogeneous) resources, as shown in the next diagram. A non-XA transaction only ever involves a single resource.

The X/Open XA specification describes a bidirectional interface at system level for a communication bridge between several local resource managers on the one hand, and a global transaction manager on the other (OpenGroup 1991). The transaction manager controls the transaction, manages the lifecycle of the transaction, and coordinates one or more resources. The resource manager is responsible for controlling and managing its assigned resource (for example, a database or a message queue).
Because of its bi-directionality, XA uses the Two-Phase Commit protocol. In comparison with atomic transactions, XA has a certain coordination overhead, which can have a negative impact on performance. For this reason, XA should only be chosen when multiple resources are being used simultaneously (in the same transaction context).
Note
XA is only needed if different resources (for example, two databases, not two tables) are accessed in the same transaction. This includes those scenarios where really only one single transaction is needed. As a result, read-only accesses that need no locks can be implemented without XA. (See also the information about transaction isolation levels.) However, XA supports read-only scenarios of this kind by means of optimizations and, therefore, in these cases the use of XA does not normally result in reductions in performance.

The most common scenario in which XA is used is the simultaneous update of a relational database and a message queue (or message topic) in one transaction, as shown in the preceding image. Other prevalent scenarios of this kind include accesses to two or more databases, or several messaging systems (Rahm 1994).
An XA transaction must coordinate all the participating resource types in the event of a rollback, and must isolate the updates from other transactions (see the information on transaction isolation). Without XA, messages that are sent to a queue or a topic may be read before the transaction is completed. If XA is used, the queue (or the topic) is only released when the transaction has been successfully completed, which means that other transactions do not have access to the message.