
Chapter 6. Composing Methods
A large part of my refactoring is composing methods to package code properly. Almost all the time the problems come from methods that are too long. Long methods are troublesome because they often contain a lot of information, which gets buried by the complex logic that usually gets dragged in. The key refactoring is Extract Method, which takes a clump of code and turns it into its own method. Inline Method is essentially the opposite. You take a method call and replace it with the body of the code. I need Inline Method when I’ve done multiple extractions and realize some of the resulting methods are no longer pulling their weight or if I need to reorganize the way I’ve broken down methods.
The biggest problem with Extract Method is dealing with local variables, and temps are one of the main sources of this issue. When I’m working on a method, I like Replace Temp with Query to get rid of any temporary variables that I can remove. If the temp is used for many things, I use Split Temporary Variable first to make the temp easier to replace.
Sometimes, however, the temporary variables are just too tangled to replace. I need Replace Method with Method Object. This allows me to break up even the most tangled method, at the cost of introducing a new class for the job.
Parameters are less of a problem than temps, provided you don’t assign to them. If you do, you need Remove Assignments to Parameters.
Once the method is broken down, I can understand how it works much better. I may also find that the algorithm can be improved to make it clearer. I then use Substitute Algorithm to introduce the clearer algorithm.
To improve the fluency of code I use Introduce Named Parameter. If I find later that the fluency the named parameter brings is no longer worth the complexity on the receiver, I can remove it with Remove Named Parameter.
When a default parameter becomes unused, I need to remove it using Remove Unused Default Parameter.
Extract Method
You have a code fragment that can be grouped together.
Turn the fragment into a method whose name explains the purpose of the method.
Motivation
Extract Method is one of the most common refactorings I do. I look at a method that is too long or look at code that needs a comment to understand its purpose. I then turn that fragment of code into its own method.
I prefer short, well-named methods for several reasons. First, it increases the chances that other methods can use a method when the method is finely grained. Second, it allows the higher-level methods to read more like a series of comments. Overriding also is easier when the methods are finely grained.
It does take a little getting used to if you are used to seeing larger methods. And small methods really work only when you have good names, so you need to pay attention to naming. People sometimes ask me what length I look for in a method. To me length is not the issue. The key is the semantic distance between the method name and the method body. If extracting improves clarity, do it, even if the name is longer than the code you have extracted.
Mechanics
1. Create a new method, and name it after the intention of the method (name it by what it does, not by how it does it).
![]() If the code you want to extract is very simple, such as a single message or function call, you should extract it if the name of the new method reveals the intention of the code in a better way. If you can’t come up with a more meaningful name, don’t extract the code.
If the code you want to extract is very simple, such as a single message or function call, you should extract it if the name of the new method reveals the intention of the code in a better way. If you can’t come up with a more meaningful name, don’t extract the code.
2. Copy the extracted code from the source method into the new target method.
3. Scan the extracted code for references to any variables that are local in scope to the source method. These are local variables and parameters to the method.
4. See whether any temporary variables are used only within this extracted code. If so, declare them in the target method as temporary variables.
5. Look to see whether any of these local-scope variables are modified by the extracted code. If one variable is modified, see whether you can treat the extracted code as a query and assign the result to the variable concerned. If this is awkward, or if there is more than one such variable, you can’t extract the method as it stands. You may need to use Split Temporary Variable and try again. You can eliminate temporary variables with Replace Temp with Query (see the discussion in the examples).
6. Pass into the target method as parameters local-scope variables that are read from the extracted code.
7. Replace the extracted code in the source method with a call to the target method.
![]() If you moved any temporary variables over to the target method, look to see whether they were declared outside the extracted code. If so, you can now remove the declaration.
If you moved any temporary variables over to the target method, look to see whether they were declared outside the extracted code. If so, you can now remove the declaration.
8. Test.
Example: No Local Variables
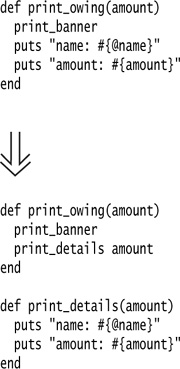
In the simplest case, Extract Method is trivially easy. Take the following method:

Tip
Comments often identify pieces of a method that can be extracted. Additionally, the comment itself can be a potential name for the extracted method. For example, in the preceding code the print banner functionality is a primary candidate for extraction.
It is easy to extract the code that prints the banner. I just cut, paste, and put in a call:

Example: Using Local Variables
So what’s the problem? The problem is local variables: parameters passed into the original method and temporaries declared within the original method. Local variables are only in scope in that method, so when I use Extract Method, these variables cause me extra work. In some cases they even prevent me from doing the refactoring at all.
The easiest case with local variables is when the variables are read but not changed. In this case I can just pass them in as a parameter. So if I have the following method:

I can extract the printing of details with a method with one parameter:

Example: Reassigning a Local Variable
It’s the assignment to local variables that becomes complicated. In this case we’re only talking about temps. If you see an assignment to a parameter, you should immediately use Remove Assignments to Parameters.
For temps that are assigned to, there are two cases. The simpler case is that in which the variable is a temporary variable used only within the extracted code. When that happens, you can move the temp into the extracted code. The other case is use of the variable outside the code. If the variable is not used after the code is extracted, you can make the change in just the extracted code. If it is used afterward, you need to make the extracted code return the changed value of the variable. I can illustrate this with the following method:

Now I extract the calculation:

Once I’ve tested for the extraction, I use the inject Collection Closure Method on Array:

In this case the outstanding variable is initialized only to an obvious initial value, so I can initialize it only within the extracted method. If something more involved happens to the variable, I have to pass in the previous value as a parameter. The initial code for this variation might look like this:

In this case the extraction would look like this:

After I test this, I clear up the way the outstanding variable is initialized:

At this point you may be wondering, “What happens if more than one variable needs to be returned?”
Though parallel assignment can be used to return multiple values, I prefer to use single return values as much as possible. In this case, I try to do multiple extractions with each extraction only returning one value.
Temporary variables often are so plentiful that they make extraction very awkward. In these cases I try to reduce the temps by using Replace Temp with Query. If whatever I do things are still awkward, I resort to Replace Method with Method Object. This refactoring doesn’t care how many temporaries you have or what you do with them.
Inline Method
A method’s body is just as clear as its name.
Put the method’s body into the body of its callers and remove the method.


Motivation
A theme of this book is to use short methods named to show their intention, because these methods lead to clearer and easier to read code. But sometimes you do come across a method in which the body is as clear as the name. Or you refactor the body of the code into something that is just as clear as the name. When this happens, you should then get rid of the method. Indirection can be helpful, but needless indirection is irritating.
Another time to use Inline Method is when you have a group of methods that seem badly factored. You can inline them all into one big method and then re-extract the methods. Kent Beck finds it is often good to do this before using Replace Method with Method Object. You inline the various calls made by the method that have behavior you want to have in the method object. It’s easier to move one method than to move the method and its called methods.
I commonly use Inline Method when someone is using too much indirection, and it seems that every method does simple delegation to another method, and I get lost in all the delegation. In these cases some of the indirection is worthwhile, but not all of it. By trying to inline I can flush out the useful ones and eliminate the rest.
Mechanics
1. Check that the method is not polymorphic.
![]() Don’t inline if subclasses override the method; they cannot override a method that isn’t there.
Don’t inline if subclasses override the method; they cannot override a method that isn’t there.
2. Find all calls to the method.
3. Replace each call with the method body.
4. Test.
5. Remove the method definition.
Written this way, Inline Method is simple. In general it isn’t. I could write pages on how to handle recursion, multiple return points, inlining into another object when you don’t have accessors, and the like. The reason I don’t is that if you encounter these complexities, you shouldn’t do this refactoring.
Inline Temp
You have a temp that is assigned to once with a simple expression, and the temp is getting in the way of other refactorings.
Replace all references to that temp with the expression.
base_price = an_order.base_price
return (base_price > 1000)
![]()
![]()
Motivation
Most of the time Inline Temp is used as part of Replace Temp with Query, so the real motivation is there. The only time Inline Temp is used on its own is when you find a temp that is assigned the value of a method call. Often this temp isn’t doing any harm and you can safely leave it there. If the temp is getting in the way of other refactorings, such as Extract Method, it’s time to inline it.
Mechanics
1. Find all references to the temp and replace them with the right-hand side of the assignment.
2. Test after each change.
3. Remove the declaration and the assignment of the temp.
4. Test.
Replace Temp with Query
You are using a temporary variable to hold the result of an expression.
Extract the expression into a method. Replace all references to the temp with the expression. The new method can then be used in other methods.

Motivation
The problem with temps is that they are temporary and local. Because they can be seen only in the context of the method in which they are used, temps tend to encourage longer methods, because that’s the only way you can reach the temp. By replacing the temp with a query method, any method in the class can get at the information. That helps a lot in coming up with cleaner code for the class.
Replace Temp with Query often is a vital step before Extract Method. Local variables make it difficult to extract, so replace as many variables as you can with queries.
The straightforward cases of this refactoring are those in which temps are assigned only to once and those in which the expression that generates the assignment is free of side effects. Other cases are trickier but possible. You may need to use Split Temporary Variable or Separate Query from Modifier first to make things easier. If the temp is used to collect a result (such as summing over a loop), you need to copy some logic into the query method.
Mechanics
Here is the simple case:
1. Extract the right-hand side of the assignment into a method.
![]() Initially mark the method as private. You may find more use for it later, but you can easily relax the protection then.
Initially mark the method as private. You may find more use for it later, but you can easily relax the protection then.
![]() Ensure the extracted method is free of side effects—that is, it does not modify any object. If it is not free of side effects, use Separate Query from Modifier.
Ensure the extracted method is free of side effects—that is, it does not modify any object. If it is not free of side effects, use Separate Query from Modifier.
2. Test.
3. Inline Temp on the temp.
Temps often are used to store summary information in loops. The entire loop can be extracted into a method; this removes several lines of noisy code. Sometimes a loop may be used to sum up multiple values, as in the total_charge method in the Decomposing and Redistributing the Statement Method section in Chapter 1. When this is the case, duplicate the loop for each temp so that you can replace each temp with a query. The loop should be simple, so there is little danger in duplicating the code.
You may be concerned about performance in this case. As with other performance issues, let it slide for the moment. Nine times out of ten, it won’t matter. When it does matter, you will fix the problem during optimization. With your code better factored, you often find more powerful optimizations that you would have missed without refactoring. If worse comes to worst, it’s easy to put the temp back.
Example
I start with a simple method:

I replace the temps one at a time. First I extract the right-hand side of the assignment:

I test; then I begin with Inline Temp. First I replace the first reference to the temp:

Test and do the next (sounds like a caller at a line dance). Because it’s the last, I also remove the temp assignment:


With that gone I can extract discount_factor in a similar way:
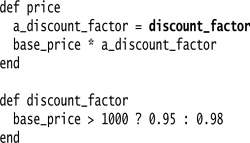
See how it would have been difficult to extract discount_factor if I had not replaced base_price with a query?
The price method ends up as follows:
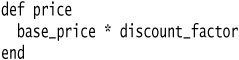
Replace Temp with Chain
You are using a temporary variable to hold the result of an expression.
Change the methods to support chaining, thus removing the need for a temp.

Motivation
Calling methods on different lines gets the job done, but at times it makes sense to chain method calls together and provide a more fluent interface. In the previous example, assigning an expectation to a local variable is only necessary so that the arguments and return value can be specified. The solution utilizing Method Chaining removes the need for the local variable. Method Chaining can also improve maintainability by providing an interface that allows you to compose code that reads naturally.
At first glance, Replace Temp With Chain might seem to be in direct contrast to Hide Delegate. The important difference is that Hide Delegate should be used to hide the fact that an object of one type needs to delegate to an object of another type. It is about encapsulation—the calling object should not reach down through a series of subordinate objects to request information—it should tell the nearest object to do a job for it. Replace Temp With Chain, on the other hand, involves only one object. It’s about improving the fluency of one object by allowing chaining of its method calls.
Mechanics
1. Return self from methods that you want to allow chaining from.
2. Test.
3. Remove the local variable and chain the method calls.
4. Test.
Example
Suppose you were designing a library for creating HTML elements. This library would likely contain a method that created a select drop-down and allowed you to add options to the select. The following code contains the Select class that could enable creating the example HTML and an example usage of the Select class.

The first step in creating a Method Chained solution is to create a method that creates the Select instance and adds an option.

Next, change the method that adds options to return self so that it can be chained.

Finally, rename the add_option method to something that reads more fluently, such as “and”.

Introduce Explaining Variable
You have a complicated expression.
Put the result of the expression, or parts of the expression, in a temporary variable with a name that explains the purpose.


Motivation
Expressions can become complex and hard to read. In such situations temporary variables can be helpful to break down the expression into something more manageable.
Introduce Explaining Variable is particularly valuable with conditional logic in which it is useful to take each clause of a condition and explain what the condition means with a well-named temp. Another case is a long algorithm, in which each step in the computation can be explained with a temp.
Note
In this, and the two refactorings that follow, we introduce temporary variables. It should be stated that temps should not be introduced lightly. Extraneous temporary variables are not a good thing: They can clutter method bodies and distract the reader, hindering their understanding of the code. So why do we introduce them? It turns out that in some circumstances, temporary variables can make code a little less ugly. But whenever I’m tempted to introduce a temporary variable, I ask myself if there’s another option. In the case of Introduce Explaining Variable, I almost always prefer to use Extract Method if I can. A temp can only be used within the context of one method. A method is useful throughout the object and to other objects. There are times, however, when other local variables make it difficult to use Extract Method. That’s when I bite the bullet and use a temp.
Mechanics
1. Assign a temporary variable to the result of part of the complex expression.
2. Replace the result part of the expression with the value of the temp.
![]() If the result part of the expression is repeated, you can replace the repeats one at a time.
If the result part of the expression is repeated, you can replace the repeats one at a time.
3. Test.
4. Repeat for other parts of the expression.
Example
I start with a simple calculation:

Simple it may be, but I can make it easier to follow. First I identify the base price as the quantity times the item price. I can turn that part of the calculation into a temp:

Quantity times item price is also used later, so I can substitute with the temp there as well:

Next I take the quantity discount:

Finally, I finish with the shipping. As I do that, I can remove the comment, too, because now it doesn’t say anything the code doesn’t say:

Example with Extract Method
For this example I usually wouldn’t have done the explaining temps; I would prefer to do that with Extract Method. I start again with

but this time I extract a method for the base price:

I continue one at a time. When I’m finished I get:

Split Temporary Variable
You have a temporary variable assigned to more than once, but it is not a loop variable nor a collecting temporary variable.
Make a separate temporary variable for each assignment.


Motivation
Temporary variables are made for various uses. Some of these uses naturally lead to the temps being assigned to several times. Loop variables [Beck] change for each run around a loop. Collecting temporary variables [Beck] collect together some value that is built up during the method.
Many other temporaries are used to hold the result of a long-winded bit of code for easy reference later. These kinds of variables should be set only once. That they are set more than once is a sign that they have more than one responsibility within the method. Any variable with more than one responsibility should be replaced with a temp for each responsibility. Using a temp for two different things is confusing for the reader.
Mechanics
1. Change the name of a temp at its first assignment.
![]() If the later assignments are of the form
If the later assignments are of the form i = i + some_expression, that indicates that it is a collecting temporary variable, so don’t split it. The operator for a collecting temporary variable usually is addition, string concatenation, writing to a stream, or adding to a collection.
2. Change all references of the temp up to its second assignment.
3. Test.
4. Repeat in stages, each stage renaming at the assignment, and changing references until the next assignment.
Example
For this example I compute the distance traveled by a haggis. From a standing start, a haggis experiences an initial force. After a delayed period a secondary force kicks in to further accelerate the haggis. Using the common laws of motion, I can compute the distance traveled as follows:
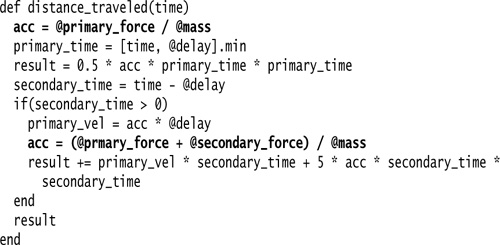
A nice awkward little function. The interesting thing for our example is the way the variable acc is set twice. It has two responsibilities: one to hold the initial acceleration caused by the first force and another later to hold the acceleration with both forces. This I want to split.
I start at the beginning by changing the name of the temp. Then I change all references to the temp from that point up to the next assignment:
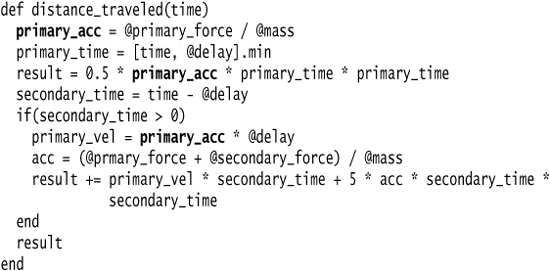
I choose the new name to represent only the first use of the temp. My tests should pass.
I continue on the second assignment of the temp. This removes the original temp name completely, replacing it with a new temp named for the second use.


I’m sure you can think of a lot more refactoring to be done here. Enjoy it. (I’m sure it’s better than eating the haggis—do you know what they put in those things?)
Remove Assignments to Parameters
The code assigns to a parameter.
Use a temporary variable instead.
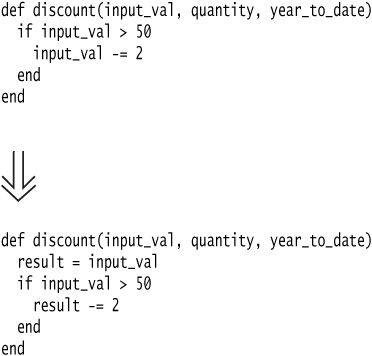
Motivation
First let me make sure we are clear on the phrase “assigns to a parameter.” If you pass an object named foo as a parameter to a method, assigning to the parameter means to change foo to refer to a different object. I have no problems with doing something to the object that was passed in; I do that all the time. I just object to changing foo to refer to another object entirely:

The reason I don’t like this comes down to lack of clarity and to confusion between pass by value and pass by reference. Ruby uses pass by value exclusively (see later), and this discussion is based on that usage.
With pass by value, any change to the parameter is not reflected in the calling routine. Those who have used pass by reference will probably find this confusing.
The other area of confusion is within the body of the code itself. It is much clearer if you use only the parameter to represent what has been passed in, because that is a consistent usage.
In Ruby, don’t assign to parameters, and if you see code that does, apply Remove Assignments to Parameters.
Of course this rule does not necessarily apply to other languages that use output parameters, although even with these languages I prefer to use output parameters as little as possible.
Mechanics
1. Create a temporary variable for the parameter.
2. Replace all references to the parameter, made after the assignment, to the temporary variable.
3. Change the assignment to assign to the temporary variable.
4. Test.
Example
I start with the following simple routine:
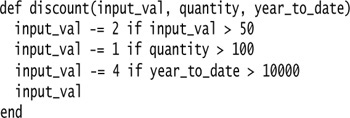
Replacing with a temp leads to:

Use of pass by value often is a source of confusion in Ruby. Ruby strictly uses pass by value in all places, thus the following program:

produces the following output:
arg in triple: 15
x after triple 5
The confusion arises because I can call methods on the object that modify its state:

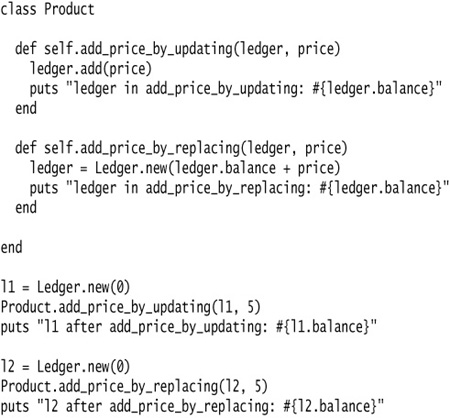
It produces this output:

Essentially the object reference is passed by value. I can use the reference to call methods and make changes to the state that will be reflected further up the call stack. But if I assign to the reference, the fact that this reference has been passed by value means that this new assignment will not be reflected outside the scope of the method body.
Replace Method with Method Object
You have a long method that uses local variables in such a way that you cannot apply Extract Method.
Turn the method into its own object so that all the local variables become instance variables on that object. You can then decompose the method into other methods on the same object.

Motivation
In this book I emphasize the beauty of small methods. By extracting pieces out of a large method, you make things much more comprehensible.
The difficulty in decomposing a method lies in local variables. If they are rampant, decomposition can be difficult. Using Replace Temp with Query helps to reduce this burden, but occasionally you may find you cannot break down a method that needs breaking. In this case you reach deep into the tool bag and get out your Method Object [Beck].
Applying Replace Method with Method Object turns all these local variables into attributes on the method object. You can then use Extract Method on this new object to create additional methods that break down the original method.
Mechanics
Stolen shamelessly from Kent Beck’s Smalltalk Best Practices.
1. Create a new class, name it after the method.
2. Give the new class an attribute for the object that hosted the original method (the source object) and an attribute for each temporary variable and each parameter in the method.
3. Give the new class a constructor that takes the source object and each parameter.
4. Give the new class a method named “compute”
5. Copy the body of the original method into compute. Use the source object instance variable for any invocations of methods on the original object.
6. Test.
7. Replace the old method with one that creates the new object and calls compute.
Now comes the fun part. Because all the local variables are now attributes, you can freely decompose the method without having to pass any parameters.
Example
A proper example of this requires a long chapter, so I’m showing this refactoring for a method that doesn’t need it. (Don’t ask what the logic of this method is, I made it up as I went along.)
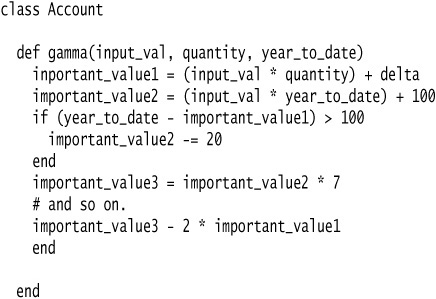
To turn this into a method object, I begin by declaring a new class. I provide an attribute for the original object and an attribute for each parameter and temporary variable in the method.

I add a constructor:

Now I can move the original method over. I need to modify any calls of features of account to use the @account instance variable.

I then modify the old method to delegate to the method object:
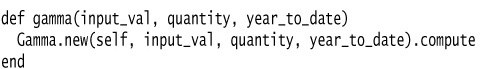
That’s the essential refactoring. The benefit is that I can now easily use Extract Method on the compute method without ever worrying about the argument’s passing:

Substitute Algorithm
You want to replace an algorithm with one that is clearer.
Replace the body of the method with the new algorithm.


Motivation
I’ve never tried to skin a cat. I’m told there are several ways to do it. I’m sure some are easier than others. So it is with algorithms. If you find a clearer way to do something, you should replace the complicated way with the clearer way. Refactoring can break down something complex into simpler pieces, but sometimes you just reach the point at which you have to remove the whole algorithm and replace it with something simpler. This occurs as you learn more about the problem and realize that there’s an easier way to do it. It also happens if you start using a library that supplies features that duplicate your code.
Sometimes when you want to change the algorithm to do something slightly different, it is easier to substitute the algorithm first into something easier for the change you need to make.
When you have to take this step, make sure you have decomposed the method as much as you can. Substituting a large, complex algorithm is difficult; only by making it simple can you make the substitution tractable.
Mechanics
1. Prepare your alternative algorithm.
2. Run the new algorithm against your tests. If the results are the same, you’re finished.
3. If the results aren’t the same, use the old algorithm for comparison in testing and debugging.
![]() Run each test case with old and new algorithms and watch both results. That helps you see which test cases are causing trouble, and how.
Run each test case with old and new algorithms and watch both results. That helps you see which test cases are causing trouble, and how.
Replace Loop with Collection Closure Method
You are processing the elements of a collection in a loop.
Replace the loop with a collection closure method.
Motivation
In most mainstream programming languages you operate on collections using loops, grabbing each element one at a time and processing it. It turns out there are common patterns of processing that you do in loops, but these are difficult to extract into libraries unless your programming language has closures.
Two of Ruby’s mentor languages are Lisp and Smalltalk, both of which have closures and library code to manipulate collections easily. Ruby has followed their lead and offers a really nice set of methods. The Enumberable module, included in Array and Hash, is a perfect example.
By replacing loops with the relevant collection closure methods you can make the code easier to follow. The collection closure method hides away the infrastructure code used to traverse the collection and create derived collections, allowing us to focus on business logic.
There are times when a more complex task requires a sequence of collection closure methods chained together.
Mechanics
1. Identify what the basic pattern of the loop is.
2. Replace the loop with the appropriate collection closure methods.
3. Test.
Examples
There are quite a few common cases when different collection closure methods are useful. Here I show the most common transformations.


The reject method reverses the test of the filter. In both cases the original collection isn’t touched unless you use the destructive form (select! or reject!).
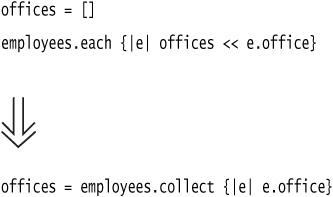
collect is aliased as “map”. collect is the Smalltalk word, and map is the Lisp word, so the choice depends on whether you like parentheses or square brackets.
Often you’ll find loops that include more than one task going on. In this case you can often replace them with a sequence of collection closure methods.

It might be useful to think of this chaining as a series of pipes and filters. Here, we’ve piped the original collection through the select filter and onto the collect filter. Also note the way I’ve laid out the code here—listing each filter on its own line makes the transformations a little clearer. If you finish a line with a period, Ruby knows not to treat the end of line as a statement terminator.
When the series of pipes and filters becomes so complex that it’s no longer easy to understand, you might want to consider writing a custom traversal method whose name explains the purpose of the traversal.
If you need to do something in a loop that produces a single value, such as a sum, consider using the inject method. This can take a bit more getting used to.

Extract Surrounding Method
You have two methods that contain nearly identical code. The variance is in the middle of the method.
Extract the duplication into a method that accepts a block and yields back to the caller to execute the unique code.
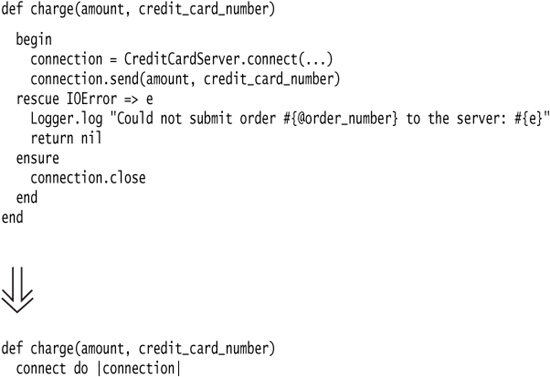
Motivation
It’s not hard to remove duplication when the offending code is at the top or bottom of a method: Just use Extract Method to move the duplication out of the way. But what happens when the unique code is in the middle of the method? You can use Form Template Method, but that involves introducing an inheritance hierarchy, which isn’t always ideal.
Conveniently, Ruby’s blocks allow us to extract the surrounding duplication and have the extracted method yield back to the calling code to execute the unique logic. As well as removing duplication, this refactoring can be used to hide away infrastructure code (for example, code for iterating over a collection or connecting to an external service), so that the business logic becomes more prominent.
Mechanics
1. Use Extract Method on one piece of duplication. Name it after the duplicated behavior.
![]() This will become our surrounding method.
This will become our surrounding method.
![]() For now the surrounding method will still perform the unique behavior.
For now the surrounding method will still perform the unique behavior.
2. Test.
3. Modify the calling method to pass a block to the surrounding method. Copy the unique logic from the surrounding method into the block.
4. Replace the unique logic in the extracted method with the yield keyword.
5. Identify any variables in the surrounding method that are needed by the unique logic and pass them as parameters in the call to yield.
6. Test.
7. Modify any other methods that can use the new surrounding method.
Example
Let’s say that we are modeling family trees, and we have a person class that has a self-referential one-to-many relationship to itself, called children (see Figure 6.1).
Figure 6.1 A mother can have many children.

For now, we only need to capture the mother of each child. Our person class looks like this:

The person class has two methods that we’re interested in: one for counting the number of living descendants, and one for counting the number of descendants with a particular name.

Both of these methods iterate over the collection of children, recursively down the family tree. Recursion isn’t trivial, and once I get it correct, I try to avoid duplication of the recursive logic. But the means to remove this duplication isn’t always obvious. Extract Method can reduce duplication if you can parameterize the method in a way that allows its use in different situations. But in this case, the duplication is in the decision about whether to increment the count or not—and this decision can’t be made without context as to the state of the person object that you are examining at each step of the iteration.
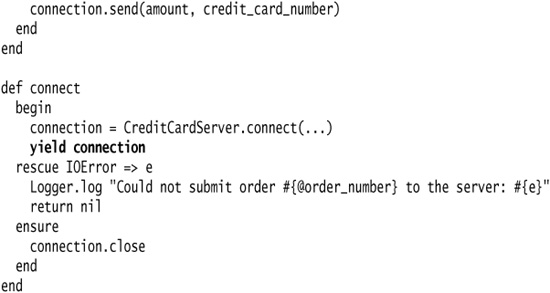
Fortunately, Ruby’s blocks allow us to provide this context. We can yield the person object back to the caller at each iteration step, and the caller can decide whether we should count. The first step is to perform Extract Method on one of the duplicates. I start with the number_of_descendants_named method. I name the extracted method after the common behavior—the counting of descendants matching a certain criteria. This will become the surrounding method.


Next, I make the calling method pass a block to the surrounding method, and push the logic that checks for a matching name up into the block. I need to yield the child back to the caller so that it can perform the check:
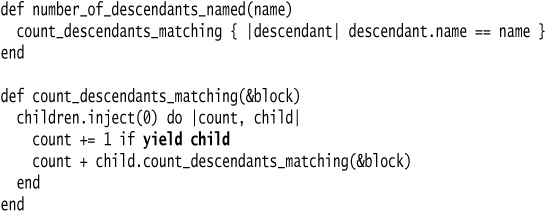
And finally, I can modify the number_of_living_descendants method to use our new surrounding method.

The duplication has been removed, and I have the added benefit of having kept the business logic (the logic determining whether to count the descendant) up in the public method. I’ve separated this business logic from the infrastructure logic required to iterate over the collection, which helps during maintenance.
Introduce Class Annotation
You have a method whose implementation steps are so common that they can safely be hidden away.
Declare the behavior by calling a class method from the class definition.

Motivation
Attribute readers and writers are so common in Object-Oriented programming languages that the author of Ruby decided to provide a succinct way to declare them. The attr_accessor, attr_reader, and attr_writer methods can be called from the definition of a class or module with a list of names of attributes. The implementation of an attribute accessor is so easy to understand that it can be hidden away and replaced with a class annotation. Most code isn’t this simple, and hiding it away would serve only to obfuscate the solution. But when the purpose of the code can be captured clearly in a declarative statement, Introduce Class Annotation can clarify the intention of your code.
Mechanics
1. Decide on the signature of your class annotation. Declare it in the appropriate class.
2. Convert the original method to a class method. Make the appropriate changes so that the method works at class scope.
![]() Make sure the class method is declared before the class annotation is called; otherwise, you’ll get an exception when the parser tries to execute the annotation.
Make sure the class method is declared before the class annotation is called; otherwise, you’ll get an exception when the parser tries to execute the annotation.
3. Test.
4. Consider using Extract Module on the class method to make the annotation more prominent in your class definition.
Example
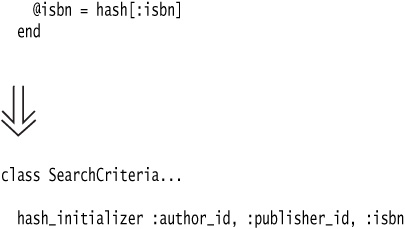
For this example, we have a SearchCriteria class that takes a Hash of parameters and assigns them to instance variables.

Since we’re dealing with initialize here, we’ll use Rename Method as well as change the method to class scope, just to make things a little clearer. We want to define the initialize method dynamically so that we can handle any list of key-names.

The unfortunate thing here is that we’re not really taking advantage of our succinct class annotation with the ugliness of the hash_initializer standing above it. Since we’ll probably use hash_initializer in a lot of classes, it makes sense to extract it to a module and move it to class Class.

Introduce Named Parameter
The parameters in a method call cannot easily be deduced from the name of the method you are calling.
Convert the parameter list into a Hash, and use the keys of the Hash as names for the parameters.

Motivation
So much of object-oriented design depends on the effectiveness of the abstractions that you create. Let’s say you have object A that delegates to object B, which in turn delegates to object C. It is much easier to understand the algorithm if each object can be synthesized in isolation by the reader. To provide for this, the clarity of the public interface of the object being delegated to is important. If object B’s public interface represents a cohesive piece of behavior with a well-named class, well-named methods, and parameter lists that make sense given the name of the method, a reader is less likely to have to delve into the details of object B to understand object A. Without this clear abstraction around the behavior of object B, the reader will have to move back and forth between object A and object B (and perhaps object C as well), and understanding of the algorithm will be much more difficult.
Ruby’s Hash object provides another way to improve the readability of a method. By replacing a list of parameters with a Hash of key-value pairs, with the key representing the name of the parameter and the value representing the parameter itself, the fluency of the calling code can be improved significantly. The reader of the calling code can see how the parameters might relate to one another and deduce how the method might use them. It’s particularly useful for optional parameters—parameters that are only used in some of the calls can be extra hard to understand.
Mechanics
1. Choose the parameters that you want to name. If you are not naming all of the parameters, move the parameters that you want to name to the end of the parameter list.
![]() That way your calling code does not need to wrap the named parameters in curly braces.
That way your calling code does not need to wrap the named parameters in curly braces.
2. Test
3. Replace the parameters in the calling code with name/value pairs
4. Replace the parameters with a Hash object in the receiving method. Modify the receiving method to use the new Hash.
5. Test.
Example 1: Naming All of the Parameters
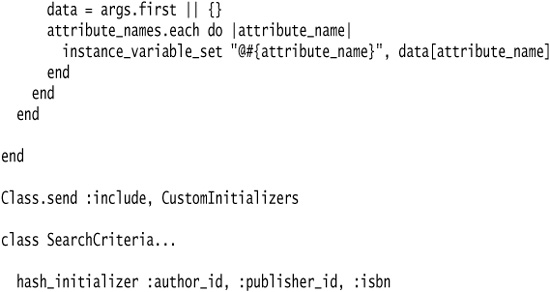
We start with a SearchCriteria object that is responsible for finding books. Its constructor takes an author_id, publisher_id, and isbn.
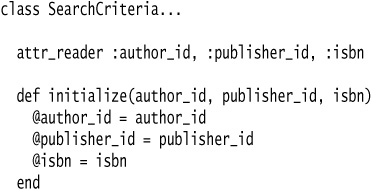
Some client code might look like this:
![]()
Without looking at the class definition, it’s hard to know what the parameters are. And without knowing what the parameters are, it’s hard to infer how the SearchCriteria object might behave.
First we change the calling code to pass key-value pairs to the constructor.
![]()
Next we change the initialize method to take a Hash, and initialize the instance variables with the values from the Hash.
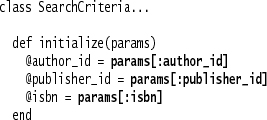
Our calling code is a lot cleaner, but if a developer is looking at the class definition and wants to know the required parameters for the method, she needs to examine the method definition to find all that are used. For initialize methods such as this that simply assign instance variables of the same name as the keys in the Hash, I like to use Introduce Class Annotation to declare the initialize method.
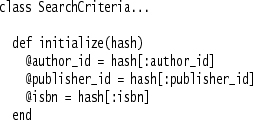
becomes

To do this, we add a method to the Class class:
module CustomInitializers

And then we can use our hash_initializer method in any class definition.
Example 2: Naming Only the Optional Parameters
It can be useful to distinguish between optional and required parameters to better communicate the method’s use to the developer trying to call the method. Take for example the following SQL-building code:

Both the conditions and joins parameters are optional, but the selector is required. The selector can be either :all, or :first. The former brings back all records that meet the given criteria, and the latter brings back only the first record that meets the criteria. Here are some clients of this code:

While the conditions parameter might be reasonably intuitive to a developer who understands SQL, the joins parameter is not as clear. The following syntax better communicates the use of the parameters:

Since the parameters we want to name are already at the end of the parameter list, we don’t need to move them.
We convert the conditions and joins parameters to a Hash, and modify the method definition accordingly.

Our calling code is more fluent, but if we are looking at the class definition, we have to look through the entire method to know the parameters that we need to pass in. We can improve this by using Introduce Assertion. We’ll add the assertion to the Hash object itself.


This has two advantages: We get quick feedback on misspelled keys that we pass to the method, and the assertion serves as a declarative statement to communicate to any reader the expected parameters.
Remove Named Parameter
The fluency that the named parameter brings is no longer worth the complexity on the receiver.
Convert the named parameter Hash to a standard parameter list.

Motivation
Introduce Named Parameter brings a fluency to the calling code that can be beneficial. But named parameters do come at a price—they add complexity to the receiving method. The parameters are clumped together into one Hash, which can rarely have a better name than “params” or “options”, because the parameters contained within the Hash are not cohesive enough to have a domain-related name. Even if they are named well, it is impossible to tell exactly the contents of the Hash, without examining the method body or the calling code. Most of the time, this added complexity is worth the increased readability on the calling side, but sometimes the receiver changes in such a way that the added complexity is no longer justified. Perhaps the number of parameters has reduced, or one of the optional parameters becomes required, so we remove the required parameter from the named parameter Hash. Or perhaps we perform Extract Method or Extract Class and take only one of the parameters with us. The newly created method or class might now be able to be named in such a way that the parameter is obvious. In these cases, you want to remove the named parameter.
Mechanics
1. Choose the parameter that you want to remove from the named parameter Hash. In the receiving method, replace the named parameter with a standard parameter in the parameter list.
![]() If you have other named parameters that you don’t want to remove, place the unnamed parameter earlier in the parameter list than the named parameters, so that you can still call the method without curly braces for your named parameter
If you have other named parameters that you don’t want to remove, place the unnamed parameter earlier in the parameter list than the named parameters, so that you can still call the method without curly braces for your named parameter Hash.
2. Replace the named parameter in the calling code with a standard parameter.
3. Test.
Example
Let’s go back to our books example, but this time suppose that all of the parameters have been implemented as named parameters. They are all optional. This means that the calling code can call the method in many different ways:

This code has a couple of problems. For starters, without looking at the implementation of the find method, it is difficult to predict the result of calling Books.find without any parameters. Does it return one result? Does it return all results? For this, I need to go to the implementation:

After sifting through the entire method, I see that if I don’t provide any parameters, all books will be returned. So we’ve introduced named parameters, but haven’t removed the need to switch to the implementation to understand the calling code.
The second problem is the name of the :selector parameter. “:selector” doesn’t mean anything in the domain of SQL. “:limit” would perhaps be a better name, but :limit => :all is a little strange. Changing the selector parameter to be required will solve both problems. The name “selector” will be removed, and if we want to return all books we will use the syntax Books.find(:all).
The first step is to introduce the selector parameter into the find method:

The next step is to modify the calling code:
Books.find
becomes

becomes
![]()
and

becomes
![]()
Remove Unused Default Parameter
A parameter has a default value, but the method is never called without the parameter.
Remove the default value.
![]()

Motivation
Adding a default value to a parameter can improve the fluency of calling code. Without the default, callers that don’t require the parameter will have to explicitly pass nil or an empty collection to the method when they don’t require it, and the fluency of the calling code is reduced. When required, default values are a good thing. But sometimes, as code evolves over time, fewer and fewer callers require the default value, until finally the default value is unused. Unused flexibility in software is a bad thing. Maintenance of this flexibility takes time, allows opportunities for bugs, and makes refactoring more difficult. Unused default parameters should be removed.
Mechanics
1. Remove the default from the parameter in the method signature.
2. Test.
3. Remove any code within the method that checks for the default value.
4. Test.
Example
In this example, search_criteria defaults to nil in the parameter list, but then performs some conditional logic to use the @search_criteria instance variable if search_criteria isn’t explicitly passed in:
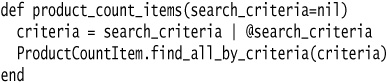
If we never call product_count_items without a parameter, then the use of @search_criteria is misleading. If this is the only use of the instance variable within the class, then our default value is preventing us from removing the instance variable entirely.
First, we remove the default value:

Our tests should still pass since no one calls the method without a parameter.
All going well, we should now be able to remove the conditional logic:

We now have the option to perform Inline Method, which could remove a layer of indirection and simplify our code.
Dynamic Method Definition
You have methods that can be defined more concisely if defined dynamically.
Define the methods dynamically.

Motivation
I use Dynamic Method Definition frequently. Of course, I default to defining methods explicitly, but at the point when duplication begins to appear I quickly move to the dynamic definitions.
Dynamically defined methods can help guard against method definition mistakes, since adding another method usually means adding one more argument; however, this is not the primary reason for Dynamic Method Definition.
The primary goal for Dynamic Method Definition is to more concisely express the method definition in a readable and maintainable format.
Mechanics
1. Dynamically define one of the similar methods.
2. Test.
3. Convert the additional similar methods to use the dynamic definition.
4. Test.
Example: Using def_each to Define Similar Methods
Defining several similar methods is verbose and often unnecessary. For example, each of the following methods is simply calling the state method.
The preceding code executes perfectly well, but it’s too similar to justify 11 lines in our source file. The following example could be a first step to removing the duplication.

Dynamically defining methods in a loop creates a more concise definition, but it’s not a particularly readable one. To address this issue I define the def_each method. The motivation for defining a def_each method is that it is easy to notice and understand while scanning a source file.

The instance_exec Method
Ruby 1.9 includes instance_exec by default; however, Ruby 1.8 has no such feature. To address this limitation I generally include the following code created by Mauricio Fernandez.

With def_each now available I can define the methods like so:

Example: Defining Instance Methods with a Class Annotation
The def_each method is a great tool for defining several similar methods, but often the similar methods represent a concept that can be used within code to make the code itself more descriptive.
For example, the previous method definitions were all about setting the state of the class. Instead of using def_each you could use Introduce Class Annotation to generate the state setting methods. Defining a states class annotation helps create more expressive code.


Example: Defining Methods By Extending a Dynamically Defined Module
Sometimes you have an object and you simply want to delegate method calls to another object. For example, you might want your object to decorate a Hash so that you can get values by calling methods that match keys of that Hash.
As long as you know what keys to expect, you could define the decorator explicitly.

While this works, it’s truly unnecessary in Ruby. Additionally, it’s a headache if you want to add new delegation methods. You could define method_missing to delegate directly to the Hash, but I find debugging method_missing problematic and avoid it whenever possible. I’m going to skip straight to defining the methods dynamically from the keys of the Hash. Let’s also assume that the PostData instances can be passed different Hashes, thus we’ll need to define the methods on individual instances of PostData instead of defining the methods on the class itself.

The preceding code works perfectly well, but it suffers from readability pain. In cases like these I like to take a step back and look at what I’m trying to accomplish.
What I’m looking for is the keys of the Hash to become methods and the values of the Hash to be returned by those respective methods. The two ways to add methods to an instance are to define methods on the metaclass and to extend a module.
Fortunately, Ruby allows me to define anonymous modules. I have a Hash and a decorator, but what I want is a way to define methods of the decorator by extending a Hash, so I simply need to convert the Hash to a module.
The following code converts a Hash to a module with a method for each key that returns the associated value.

With the preceding code in place, it’s possible to define the PostData class like the following example.

Replace Dynamic Receptor with Dynamic Method Definition
You have methods you want to handle dynamically without the pain of debugging method_missing.
Use dynamic method definition to define the necessary methods.
Motivation
Debugging classes that use method_missing can often be painful. At best you often get a NoMethodError on an object that you didn’t expect, and at worst you get stack level too deep (SystemStackError).
There are times that method_missing is required. If the object must support unexpected method calls you may not be able to avoid the use of method_missing. However, often you know how an object will be used and using Dynamic Method Definition you can achieve the same behavior without relying on method_missing.
Mechanics
1. Dynamically define the necessary methods.
2. Test.
3. Remove method_missing.
4. Test.
Example: Dynamic Delegation Without method_missing
Delegation is a common task while developing software. Delegation can be handled explicitly by defining methods yourself or by utilizing something from the Ruby Standard Library such as Forwardable. (See the Hide Delegate section in Chapter 7 for an explanation of Forwardable.) Using these techniques gives you control over what methods you want to delegate to the subject object; however, sometimes you want to delegate all methods without specifying them. Ruby’s Standard Library also provides this capability with the delegate library, but we’ll assume we need to implement our own for this example.
The simple way to handle delegation (ignoring the fact that you would want to undefine all the standard methods a class gets by default) is to use method_missing to pass any method calls straight to the subject.

This solution does work, but it can be problematic when mistakes are made. For example, calling a method that does not exist on the subject results in the subject raising a NoMethodError. Since the method call is being called on the decorator but the subject is raising the error, it may be painful to track down where the problem resides.
The wrong object raising a NoMethodError is significantly better than the dreaded stack level too deep (SystemStackError). This can be caused by something as simple as forgetting to use the subject instance variable and trying to use a nonexistent subject method or any misspelled method. When this happens the only feedback you have is that something went wrong, but Ruby isn’t sure exactly what it was.
These problems can be avoided entirely by using the available data to dynamically define methods at runtime. The following example defines an instance method on the decorator for each public method of the subject.

Using this technique any invalid method calls will be correctly reported as NoMethodErrors on the decorator. Additionally, there’s no method_missing definition, which should help avoid the stack level too deep problem entirely.
Example: Using User-Defined Data to Define Methods
Often you can use the information from a class definition to define methods instead of relying on method_missing. For example, the following code relies on method_missing to determine whether any of the attributes are nil.

The code works, but it suffers from the same debugging issues that the previous example does. Utilizing Dynamic Method Definition and Introduce Class Annotation the issue can be avoided by defining the attributes and creating the empty_attribute? methods at the same time.

Isolate Dynamic Receptor
A class utilizing method_missing has become painful to alter.
Introduce a new class and move the method_missing logic to that class.

![]()
Motivation
As I mentioned in the section “Replace Dynamic Receptor with Dynamic Method Definition” earlier in the chapter, objects that use method_missing often raise NoMethodError errors unexpectedly. Even worse is when you get no more information than stack level too deep (SystemStackError).
Despite the added complexity, method_missing is a powerful tool that needs to be used when the interface of a class cannot be predetermined. On those occasions I like to use Isolate Dynamic Receptor to move the method_missing behavior to a new class: a class whose sole responsibility is to handle the method_missing cases.
The ActiveRecord::Base (AR::B) class defines method_missing to handle dynamic find messages. The implementation of method_missing allows you to send find messages that use attributes of a class as limiting conditions for the results that will be returned by the dynamic find messages. For example, given a Person subclass of AR::B that has both a first name and a ssn attribute, it’s possible to send the messages Person.find_by_first_name, Person.find_by_ssn, and Person.find_by_first_name_and_ssn.
It’s possible, though not realistic, to dynamically define methods for all possible combinations of the attributes of an AR::B subclass. Utilizing method_missing is a good alternative. However, by defining method_missing on the AR::B class itself the complexity of the class is increased significantly. AR::B would benefit from a maintainability perspective if instead the dynamic finder logic were defined on a class whose single responsibility was to handle dynamic find messages. For example, the previous Person class could support find with the following syntax: Person.find.by_first_name, Person.find.by_ssn, or Person.find.by_first_name_and_ssn.
Tip
Very often it’s possible to know all valid method calls ahead of time, in which case I prefer Replace Dynamic Receptor with Dynamic Method Definition.
Mechanics
1. Create a new class whose sole responsibility is to handle the dynamic method calls.
2. Copy the logic from method_missing on the original class to the method_missing of the focused class.
3. Create a method on the original class to return an instance of the focused class.
4. Change all client code that previously called the dynamic methods on the original object to call the new method first.
5. Remove the method_missing from the original object.
6. Test.
Example
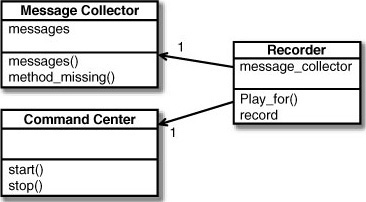
The following example is a Recorder class that records all calls to method_missing.


The Recorder class may need additional behavior such as the ability to play back all the messages on an object and the ability to represent all the calls as Strings.

It might be used like this:

As the behavior of Recorder grows it becomes harder to identify the messages that are dynamically handled from those that are actually explicitly defined. By design the functionality of method_missing should handle any unknown message, but how do you know if you’ve broken something by adding an explicitly defined method?
The solution to this problem is to introduce an additional class that has the single responsibility of handling the dynamic method calls. In this case we have a class Recorder that handles recording unknown messages as well as playing back the messages or printing them. To reduce complexity we will introduce the MesageCollector class that handles the method_missing calls.

The record method of Recorder will create a new instance of the MessageCollector class and each additional chained call will be recorded. The play back and printing capabilities will remain on the Recorder object.


And now our usage will change to call the record method:

Move Eval from Runtime to Parse Time
You need to use eval but want to limit the number of times eval is necessary.
Move the use of eval from within the method definition to defining the method itself.


Motivation
As Donald Knuth once said, “Premature optimization is the root of all evil”. I’ll never advocate for premature optimization, but this refactoring can be helpful when you determine that eval is a source of performance pain. The Kernel#eval method can be the right solution in some cases, but it is almost always more expensive (in terms of performance) than its alternatives. In the cases where eval is necessary, it’s often better to move an eval call from runtime to parse time.
Mechanics
1. Expand the scope of the string being eval’d.
2. Test.
It’s also worth noting that evaluating the entire method definition allows you to change the define_method to def in this example. All current versions of Ruby execute methods defined with def significantly faster than methods defined using define_method; therefore, this refactoring could yield benefits for multiple reasons. Of course, you should always measure to ensure that you’ve actually refactored in the right direction.