
In this section, we will extend our Chicago crime example and will perform some real-time analysis using Spark SQL on the streaming crime data.
All Spark extensions extend a core architecture component of Spark: RDD. Now whether it is DStreams in Spark Streaming or DataFrame in Spark SQL, they are interoperable with each other. We can easily convert DStreams into DataFrames and vice versa. Let's move ahead and understand the integration architecture of Spark Streaming and Spark SQL. We will also materialize the same and develop an application for querying streaming data in real time. Let's refer to this job as SQL Streaming Crime Analyzer.
The high-level architecture of our SQL Streaming Crime Analyzer will essentially consist of the following three components:
- Crime producer: This is a producer that will randomly read the crime records from the file and push the data to a socket. This is same crime record file which we downloaded and configured in the Creating Kinesis stream producers section in Chapter 5, Getting Acquainted with Kinesis.
- Stream consumer: This reads the data from the socket and converts it into RDD.
- Stream to DataFrame transformer: This consumes the RDD provided by the stream consumer and further transforms it into a DataFrame using dynamic schema mapping.
Once we have the DataFrame, we can execute our regular Spark SQL operations. The following diagram represents the interaction between all three components in realization of the overall use case:
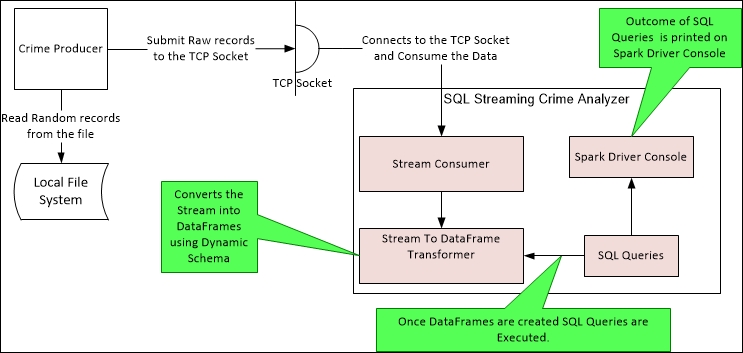
Let's move forward towards the next section and code our SQL Streaming Crime Analyzer.
Perform the following steps to code our crime producer that will read the crimes from a predefined file and submit the data to a socket:
- Open and edit the
Spark-Examplesproject and add a new Java file namedchapter.nine.CrimeProducer.java. - Edit
CrimeProducer.javaand add the following code in it:package chapter.nine; import java.io.*; import java.net.*; import java.util.Random; public class CrimeProducer { public static void main(String[] args) { if (args == null || args.length < 1) { System.out .println("Usage - java chapter.nine.StreamProducer <port#>"); System.exit(0); } System.out.println("Defining new Socket on " + args[0]); try (ServerSocket soc = new ServerSocket(Integer.parseInt(args[0]))) { System.out.println("Waiting for Incoming Connection on - " + args[0]); Socket clientSocket = soc.accept(); System.out.println("Connection Received"); OutputStream outputStream = clientSocket.getOutputStream(); // Path of the file from where we need to read crime records. String filePath = "/home/ec2-user/softwares/crime-data/Crimes_-Aug-2015.csv"; PrintWriter out = new PrintWriter(outputStream, true); BufferedReader brReader = new BufferedReader(new FileReader( filePath)); // Defining Random number to read different number of records each // time. Random number = new Random(); // Keep Reading the data in a Infinite loop and send it over to the // Socket. while (true) { System.out.println("Reading Crime Records"); StringBuilder dataBuilder = new StringBuilder(); // Getting new Random Integer between 0 and 60 int recordsToRead = number.nextInt(60); System.out.println("Records to Read = " + recordsToRead); for (int i = 0; i < recordsToRead; i++) { String dataLine = brReader.readLine() + " "; dataBuilder.append(dataLine); } System.out .println("Data received and now writing it to Socket"); out.println(dataBuilder); out.flush(); // Sleep for 6 Seconds before reading again Thread.sleep(6000); } } catch (Exception e) { e.printStackTrace(); } } }
And we are done with our crime producer. Let's develop our stream consumer and transformer, and then we will deploy and execute all components and analyze the results on the Spark driver console.
Perform the following steps for coding the stream consumer and transformer in Scala:
- Open and edit the
Spark-Examplesproject and add a new Scala object namedchapter.nine.SQLStreamingCrimeAnalyzer.scala. - Edit
SQLStreamingCrimeAnalyzer.scalaand add the following code:package chapter.nine import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.sql._ import org.apache.spark.storage.StorageLevel._ import org.apache.spark.rdd._ import org.apache.spark.streaming.dstream._ object SQLStreamingCrimeAnalyzer { def main(args: Array[String]) { val conf = new SparkConf() conf.setAppName("Our SQL Streaming Crime Analyzer in Scala") val streamCtx = new StreamingContext(conf, Seconds(6)) val lines = streamCtx.socketTextStream("localhost", args(0).toInt, MEMORY_AND_DISK_SER_2) lines.foreachRDD { x => //Splitting, flattening and finally filtering to exclude any Empty Rows val rawCrimeRDD = x.map(_.split(" ")).flatMap { x => x }.filter { x => x.length()>2 } println("Data Received = "+rawCrimeRDD.collect().length) //Splitting again for each Distinct value in the Row val splitCrimeRDD = rawCrimeRDD.map { x => x.split(",") } //Finally mapping/ creating/ populating the Crime Object with the values val crimeRDD = splitCrimeRDD.map(c => Crime(c(0), c(1),c(2),c(3),c(4),c(5),c(6))) //Getting instance of SQLContext and also importing implicits for dynamically creating Data Frames val sqlCtx = getInstance(streamCtx.sparkContext) import sqlCtx.implicits._ //Converting RDD to DataFrame val dataFrame = crimeRDD.toDF() //Perform few operations on DataFrames println("Number of Rows in Table = "+dataFrame.count()) println("Printing All Rows") dataFrame.show(dataFrame.count().toInt) //Now Printing Crimes Grouped by "Primary Type" println("Printing Crimes, Grouped by Primary Type") dataFrame.groupBy("primaryType").count().sort($"count".desc).show(5) //Now registering it as Table and Invoking few SQL Operations val tableName ="ChicagoCrimeData"+System.nanoTime() dataFrame.registerTempTable(tableName) invokeSQLOperation(streamCtx.sparkContext,tableName) } streamCtx.start(); streamCtx.awaitTermination(); } def invokeSQLOperation(sparkCtx:SparkContext,tableName:String){ println("Now executing SQL Queries.....") val sqlCtx = getInstance(sparkCtx) println("Printing the Schema...") sqlCtx.sql("describe "+tableName).collect().foreach { println } println("Printing Total Number of records.....") sqlCtx.sql("select count(1) from "+tableName).collect().foreach { println } } //Defining Singleton SQLContext variable @transient private var instance: SQLContext = null //Lazy initialization of SQL Context def getInstance(sparkContext: SparkContext): SQLContext = synchronized { if (instance == null) { instance = new SQLContext(sparkContext) } instance } } // Define the schema using a case class. case class Crime(id: String, caseNumber:String, date:String, block:String, IUCR:String, primaryType:String, desc:String)
And we are done with our stream consumer and transformer. Let's move forward and execute our producers, consumers, and transformers and analyze the results.
Perform the following steps to execute the SQL Streaming Crime Analyzer:
- Assuming that your Spark cluster is up and running, export your Eclipse project as
spark-examples.jar. - The first task is to bring up our crime producer, so open a new Linux console and execute the following command from the same location where we exported
spark-examples.jar:java -classpath spark-examples.jar chapter.nine.CrimeProducer 9047The argument to
CrimeProduceris the port number on which our producer will open a new TCP socket (which is9047in our case) for listening to the clients that want to receive the data. As soon as we execute the command, the producer will wait for an incoming connection before it starts reading and submitting the crime data. - Next, we will open a new Linux console and execute the following command from the same location where we exported
spark-examples.jar:$SPARK_HOME/bin/spark-submit --class chapter.nine.SQLStreamingCrimeAnalyzer --master spark://ip-10-234-208-221:7077 spark-examples.jar 9047We also provided the port number in the last argument of our
spark-submitcommand. This port number should be same as the one we provided while executingCrimeProducer(in our case, it is9047). Our job will connect to the provided port and start receiving the data available and submitted by our producer.
And we are done! Awesome, isn't it ?
The outcome of this execution would be similar to what's shown in the following screenshot:

The preceding screenshot shows the output produced on the console. It shows the number of records read and submitted by the crime producer.
The following screenshot shows the output produced by the consumer and transformer on the Spark driver console. It shows the results of the analysis performed by Spark SQL:

In this section, we discussed the integration of two different Spark extensions: Spark Streaming and Spark SQL. We also developed/executed a Spark Streaming job that receives the data in near real-time and then further leverages Spark SQL for performing analysis over streaming data.
Let's move forward and look at the deployment and monitoring aspects of Spark Streaming.