

CHAPTER
1
Data Integrations Overview
Data is an extremely valuable frontier for the enterprise. Some companies have pulled away from their competition because of their use of data. They understand the value the information brings in making things more efficient, knowing their customers, and advancing their products based on known needs. Data can be a powerful tool in driving business decisions and providing tremendous value. The question is how to harness this data and the power of the information.
There are two ways of approaching the data: a technical one, which will be covered in this book, and a business one. The business approach means that each company has to apply its own expertise of its respective industry and field of business in order to decide how to gain and exploit additional insights from the data. Leveraging the technology will provide a way to harness the data using those insights. Companies that leverage their data and know how to use the information realize that the efforts needed to keep the data updated are well worth it. In this sense, data should be handled as assets. The internal data has to be protected and managed to provide the details across the enterprise, and not just focused on one line of business or product. Depending on the industry, the type of data being collected will require different regulations around the data, which adds complexity to how the data can be used and shared. This adds governance around the data and reasons for business rules to manage and maintain it. The amount of data being collected might even increase questions around what data filters are important. This might also involve the need for analytics and other analysis before the data is used in conjunction with other systems.
The Big Data technologies all over the news these days might give the impression that filtering just some of the data available is a thing of the past. However, the volume of data being generated grows so fast that filtering—at least for analysis of significant data sets—remains an important processing step. This filtering of data provides the data sets needed to integrate with company-specific data for an even more powerful analysis.
The starting point for building systems that utilize the value of data is to begin asking questions. Questions should be formulated to determine the problems the company is trying to solve with the data, and a data strategy can be developed based on these questions. Data strategies are based on business needs and where to get value, and they determine what type of data is collected and integrated. It is amazing what can be done with data—from actually saving lives to anticipating customer needs. As an example, a healthcare company can become more efficient in its processes of gathering medical information and then correlating that data with medical issues to provide a more comprehensive patient history, which leads to better patient care and valuable repository of information about the patients. Another example is an IT department understanding how the various environments, systems, and applications interface within an enterprise; for example, which database supports what applications and on what servers and networks. The support of these systems requires not only issuing upgrades and patches, but also the ability to communicate with the right teams and application owners whenever an issue arises or maintenance needs to be completed. Having an effective data strategy in place helps streamline the communication issues involving maintenance and test plans. These are the types of issues that can be addressed with the analysis of the data.
Internal company data presents excellent information about the enterprise and can be used to answer several questions. Merging data from multiple sets and sources gives new and better insights than just analyzing single-source data sets. Internal systems can be integrated to provide comprehensive data for various departments. Add into that external data sources, and the data can be enriched and probably becomes more complete. The external sources can be standard data sets that are common for industries, governments, regulations, markets, and any other source of data one can think of. It is also possible to subscribe to outside data sources—and with these data sources integrating with the internal sources, the enhanced data and analytics provide more than just an internal picture, but a larger industry picture.
The questions can then be greater and further reaching to provide a deeper look and expand beyond the initial thoughts and research. Now, as the questions are flying and the company is thinking of the possibilities of how to use the data, a plan has to come together—a master plan of the data from master data management, data governance and quality, and of course data integrations.
What Is a Data Integration?
At this point, it might be fine to continue by discussing tools and step-by-step directions for data integrations, but we’ll start with a discussion around what data integrations are. Data can be in various formats as well as different databases and systems. Applications that collect and use data can keep the data contained. It is when the application needs an outside source of information or has valuable information to share with other systems that the data is considered for integrations.
Taking data from one system and combining it with data from another system, based on a common identifier, for use as a data set is the underlying idea of data integrations. Numerous forms of data integration are available. It can be as simple as having a table in an Oracle database and running a query against another table in a different Oracle database. The combined query has to provide the method for the integration. This data can then be loaded into another database or a data warehouse. It can even just be joined in a materialized view (that is, a view that is a snapshot of the data) for reporting.
Data integrations most likely come into the equation when new questions are asked. There is normally an existing system, and answering a question means pulling data from another place and enhancing the data.
Data integrations mean that data can come from almost any platform and format—especially with today’s information being collected from everywhere. Data is being tracked about when we sleep, exercise, and eat. The number of people going into brick-and-mortar stores versus shopping online is counted, and information is gathered about what the weather was on a particular day. Devices and systems collecting high volumes of data in nonrelational data stores can still allow data to be integrated with relational databases.
It all comes back to the data that is available for processing and the information that can be integrated into various data sets. Data warehouses load data from various sources to integrate it into a consolidated location for reporting and as a source of data for other applications to use.
Integrating data can be in done in several steps—from simple statements to complex sources of data that need business rules and controls around them to be able to consume the data for the other purposes. Tools are needed to perform the integrations, a plan is needed to understand the data and the quality of the data, and governance is needed to maintain the system to continuously provide consistent data. More importantly, domain know-how is required to formulate meaningful analysis and interpretations of the data.
History of Data Integration
Data integration used to be simpler. Most of the data would be housed in just a couple of systems. There were not as many options to get data, and not as much information was yet being provided from the Internet. There were fewer sensors and data collection processes in production lines and at consumer sources. Smartphones were not yet around either. Maybe the right questions were not being asked to see the need for different data sources. The applications collecting the data also fed data warehouses to provide the consolidated data.
A data warehouse can have historical and current data, but the main purpose is to centrally store the data. Having this centralized repository allows the business to point to the data warehouse for reporting and analysis. A data mart is a focused and simpler form of a data warehouse; it is used for one subject or functional area. Populating the data warehouses and data marts requires the processes for data integrations, as data warehouses continue to be an important way to store the integrated data.
The amount of data is continuously growing. Today, more sensors and objects provide constant data, and some of these can even talk to smartphones. In addition, the Internet continues to provide more and more information. In other words, there is not going to be any less data going forward. Hopefully, though, it is smarter data—that is, the right information being gathered, along with the right questions being asked.
In the past, it was also typical that data integrations were an integral part of migrations to a new application. Either one company purchased another company or a new system was implemented. This caused a need for the existing systems to be migrated into one for the new entity. Migrations are a whole project in themselves, but they usually have data integration aspects as part of their execution. When combining the two systems, it would make sense for the company to integrate the data as part of the migration plan.
Outside of the data warehouses and migrations, many of the systems were built as stand-alone environments. It was not always expected that another system would ever use the data in these databases. There was no plan or thought given to what would happen if these data sources were combined to provide additional information.
Data integrations have taken on the following forms:
![]() Manual integrations These integrations use queries to pull out the needed information.
Manual integrations These integrations use queries to pull out the needed information.
![]() Common and uniform access The data has the same look and feel and a single access point for the client.
Common and uniform access The data has the same look and feel and a single access point for the client.
![]() Application integrations Applications pull data from different sources to feed the results to the user.
Application integrations Applications pull data from different sources to feed the results to the user.
![]() Common data Provides a single access point for the data that is gathered and pulled together for the user. This involves the use of the following:
Common data Provides a single access point for the data that is gathered and pulled together for the user. This involves the use of the following:
![]() Queries and materialized views
Queries and materialized views
![]() Data warehouses
Data warehouses
![]() Common data stores
Common data stores
Common data can also mean common data storage. Queries, materialized views, and portals are used to provide a common access point for common data. It is a way for the data to be combined, to make the database uniform, and use queries and reporting access. Using a data warehouse is another way to integrate data to a common source. There might also be additional data stores for a common place to access and store data.
A group of databases is an example of a model used for relational databases to be logically joined together for integration. The data can be in different databases, and still a query across databases could join the data because they share a similar query language and structure. This doesn’t necessarily mean bringing the data into one physical location; different sources can be used to create views or reports and provide the integration of the sources of data. This illustrates a simpler method because the data types are similar; it isn’t until NoSQL that unstructured data sources start being added in. Peer-to-peer methods enable a peer application access to another. Again, the databases are dispersed, but access can be consistent and have a single access point.
With these ways of integrating data, there are still several issues with data integrations, and no single way to solve these problems.
Integrations Today
Issues that exist today with data integrations mainly involve large sets of data that keep getting larger and need integrations and automated processes. Performing data integrations is not easy, but the value of the data is worth the effort.
The systems that need the data integration might only require a filter of read-only data to form a new set based on the integration. This filtering process might actually exclude data from the integration because no one knew the right questions to ask or maybe even the wrong questions were being asked. Therefore, data might be missing because of this exclusion if different questions are asked later or other data is required. Missing data or data that’s not provided is something that is seen regularly in technology systems. There are discussions concerning servers, the applications and databases on these servers, what other servers have dependencies, and the owners for all of these items. With constant changes to configurations, applications, and owners, it is difficult to keep the data up to date, so it might be left out of the integration. There might also be other systems that keep part of the data, such as the configurations. This data is not always included in the integration through the filtering because it is not regularly part of the requirements—that is, until a question is asked or new reasons arise to keep the data. The process is just updating information in a system, but even this list of servers, applications, and owners could provide key details for automated systems or operational processes to create efficiencies. These systems might have different sources of data for all of these pieces of information, which are normally integrated from these different systems to pull together a system of record for the server. There seems to be several operational processes and procedures that can be solved by having consistent configuration management data and information. The right filtering or the realization that there are other uses for data needs to be taken into consideration for the data integration process. Filtering data too soon or not asking all of the questions up front can cause sources to be restricted and limited.
This leads into another issue: the fact that systems were not designed for integrations. If there was no initial requirement for another application to need the same information, it was not built into or planned as part of the application. New systems should be designed for others to consume the data. The company should assume that data is not being used for just one thing and that at some point someone is going to want to use that information for another purpose. During the development and data workflow stages, designs should include ways to extract the data and make it usable by others and different applications. Also, APIs should be provided through code, data stores, views, and so on. Quite a few options are available, so including this in the design of the application or just planning for others to use the data will be advantageous for future data integrations.
Figure 1-1 shows the components needed for data integrations to happen at the enterprise level.
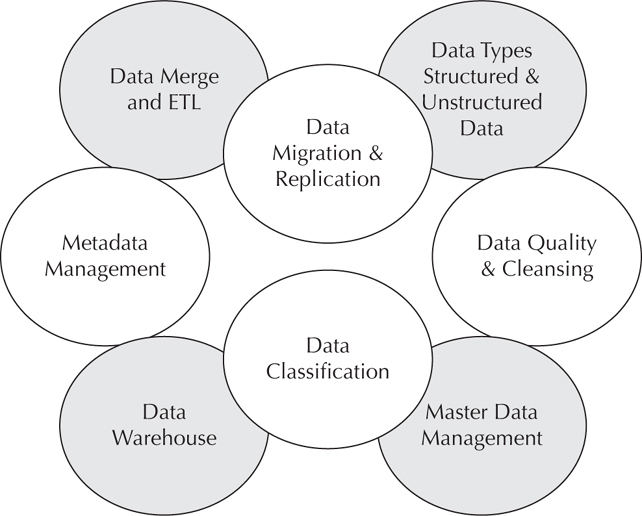
FIGURE 1-1. Data integration components
The components listed in Figure 1-1 will be discussed in more detail throughout the rest of the book. Notice that there are some initial architecture and data governance steps with data classification and master data management that will make the data easier to integrate. Developing these strategies leads to better data and better integrations. Using common formats and understanding what the data is are both keys to being able to consume the completed data set. The business needs can flow into these steps, but it’s still important to ask the right questions.
In order to look into how to perform data integrations, we’ll discuss these topics of the data components first. Understanding how the environment is set up and how data requirements and issues are a part of the development of an integration strategy. The components are shown in no particular order, and some environments are going to have more advanced definitions and processes in these various areas. To have effective processes for the data so that it is providing value, these areas need to be addressed.
To begin, master data management (MDM) provides the specifics about the data and data sources. The sources of data are defined and documented. With external sources of data, the source of the truth and data formats will be part of an MDM strategy. Knowing and understanding the data and where it is coming from allows for reuse in other systems. For proficiency, master data management requires business and upper management support. It also ties into data governance and how the data is used in the company. You can see why this ties into data integrations. Not only can the data integrations be used in the MDM strategy, but the understanding of the data is essential for some of the data integrations.
Data classification is a component that can be used in the data integrations workflow. The data can be sensitive data, a source of truth, or another classification. The sensitivity of the data is important to know if the data needs a certain level of security and therefore might be restricted in use with integrations. The classification of being the true source of data is integral for where to pull data from in order to match it up and use it for mappings. Data classification tags the data with the needed attributes so that the company knows when it can and can’t be used, or with what systems it should be used. This can be part of the development strategy in planning for future integrations or for current processes to use the right source of data.
Data merge and ETL (Extract, Transform, and Load) are processes that use the data source to match and map the needed records and fields. The transformation process can use data integrations for the proper mapping in order to load the data into a data store, data warehouse, or other application. The data merge process is really performing the data integration, in that it merges data sets together. These tools perform the merger or transformation of the data to load the results as needed. Chapters 2 and 3 discuss how queries and other database processes perform these steps.
Data migration and replication can be done in various ways as well. Normally, a mapping of the information is needed to be able to migrate the data to a new system. The migration might involve the same data moving from one system to another to be used by a different application, or it might be two or more applications combining their data to be migrated to a new data store or a whole new application. Nevertheless, these processes perform data migrations to move the data. Replication also duplicates the data to be used in a different place. These components are discussed in more detail as part of Chapter 4.
Because data comes in all shapes and sizes—from external and internal sources—there needs to be a way to bring the data together. Integration of similar types of data provides for more straightforward processes and similar data stores. Unstructured data and data from outside the realm of relational databases require different ways of integrating. Chapter 8 focuses on Big Data and how to pull it. Enhancing existing structured data with unstructured data is where the analytics get interesting and opens up a whole new set of questions and possibilities. These challenges are where the future of data integrations lies because of all the new data coming in now.
Even though data quality and cleansing are really strategies that belong with master data management and data governance, poor quality data will create havoc on any data integration. The testing of the data quality as well as the data cleanup processes is vital to the systems. Because of this, the topics of data quality and cleansing receive a complete chapter: Chapter 7. Not only can data integrations help with the data cleanup, but having the quality of the data tested and confirmed will provide consistent and reliable data integrations. Data quality brings with it a whole set of challenges and needs to be addressed before a data integration for strategic data use is attempted.
Even though the use of a data warehouse is a past way of bringing data together, it is not a dying breed, and will continue to be vital going forward. Data warehouses might transform into different platforms and have different types of data available, but they provide a stable set of data that uses standard processes to have the centralized repository of data. Data integrations are used every step of the way for data warehouses—from loading to reporting. Every data store can be a small part in a bigger data warehouse picture. Simplifying an already complex set of data coming from all over the place to a centralized location can be an asset for several lines of business. They might be pulling data from different sources and integrating it with nonrelational sources on the fly, but for performance in reporting and analytics, having the combined data in a warehouse will provide a way to decrease the access time with the right set of information. The steps along the way might not store the integrated data because of the APIs or the way the data can be pulled, but that doesn’t mean the data can’t end up in a data warehouse.
Metadata management defines the columns and what the data actually means; it allows for proper data mappings. Without the metadata being defined and communicated, different lines of business might be using a certain column or table for something it wasn’t intended for, and thus creating integrations that produce incorrect sources. The characterization of the data is also part of the data cleansing, quality, and master data management efforts. Are you starting to see a pattern here? These components are all tied nicely together; they are integrated just as the data inside of them needs to be integrated. Being lopsided in components or not spending the time to manage the metadata or the quality of the data will lead to bad information. Decisions that are made from poor data will have the opposite effect on the business as using the right information with the right data and asking the right questions.
It is not easy to align all these components. However, if the right questions are being asked now, and the data is available to answer them, it will be well worth the effort to plan, manage, and maintain a system that has integrated data and tools to report and visualize the data, thus resulting in tremendous business value.
Decision Flow Chart
After the discussion of the various components of data integration, decisions need to be made about how to handle the data flow—decisions about the technologies, tools, and how to match the business needs.
These decisions involve what data is needed, frequency, management tools, and how to handle changes. The stakeholders need to be involved in helping make these decisions because they have a vested interest in the data or the processes. Technologists cannot make decisions in isolation about what tools to use because the business and data owners will be the ones using them. Data owners can set the data definitions and the frequency required, but they need help in deciding what tools to use to accomplish what they are looking for.
The problem is that not everyone is communicating. Perhaps the data owners are working in isolation because they don’t believe they need other data and are not sure that the data should be shared. The first decision that actually has to be made is who is going to own the data and if the data, or what parts of the data, are going to be shared.
A lot depends on making good decisions and communicating with the various teams. Successful data integrations have proper data requirements. As shown in Figure 1-2, data requirements comprise the next couple of decisions. Defining the owner of the data will help with what data is accessible because that will provide a responsible party for making the data that should be available and ready for use. Not all data will be available for consumption for data integrations, but as previously discussed, there are steps surrounding metadata information to explain what the data is and what workflows it came from. When planning an application or data system for integrations, the company must build in APIs and other ways to use the data. Also, communication with other teams is necessary for understanding these pieces and learning what the other teams want. You can communicate what is being made available and how to use the data through the workflows. Technology talking with the business will drive the integrations together. These discussions drive the flow of the data and get the necessary data available. Deciding together what data means and working through the needs is definitely a better way to get the right tools in place. This also sets the direction for data quality, reporting, and successful data integrations.

FIGURE 1-2. Decisions for data integrations
The timing of the delivery of the data might be another area where the business wants something that might not be possible technically. There might be different understandings of what the timing of the data delivery is. If the data is only delivered from an external source on a daily or weekly basis, how does that change the timing of the data integration? The timing might change based on when data is available and usable. Real-time data might not even be possible because of workflow processes. If manual checks and processes are in place, these need to be reviewed so they can be automated before data can even be expected any earlier. This can be included as part of the metadata and definitions surrounding the data for timing and details.
Once it is decided what data is needed, the appropriate teams need to be made aware of its timing and what data is available; then the data can be loaded into the consolidated data store or data warehouse. If a federated system is being used, the data can be placed in different areas to be pulled together with processes.
The data can be cleansed at this point. The cleansing of the data will depend on the rules and business logic surrounding it. Data cleansing is discussed more in Chapter 7. At this stage, the data is either corrected or completed, and can now be used for ETL processing or for data integrations.
Data validation is an area that is significant for the entire process because it determines if the data that is delivered is what was expected. Testing against the data will verify that the workflows are working and that the data is defined properly. Data validation is an on-going procedure to confirm several steps in the overall process. Not only does it confirm that the data integrations are working properly, but it also confirms the steps to get to the integrations. There should be checks along the way for data validation, especially when data quality steps and master data management are used. The business rules should be verified against this, and if changes need to be made, the process can circle back through the workflow to validate the data and the changes.
Decisions concerning data integrations start out with communication and having the data owner be responsible for the data. Understanding what the data is currently being used for and the intent of the data will then allow the process for the data validations and data integrations to be designed and created.
Tools for Harnessing Data
Data integrations are more than just technology and mappings of data in a database or environment. There is obviously value in incorporating the data into a common source for analysis. Process work and decisions need to be made with the data owner and applications owners about the data and how to integrate it. Even though some of this process is just data owners discussing the data, there are reasons to pull in tools to make the other work flows with data integrations consistent and repeatable.
Tools such as Oracle Data Integrator and GoldenGate can help with integrations and migrations. In addition, they help automate and track information concerning what has been done and business rules. Oracle Data Integrator is discussed more in Chapter 4. It can be used to set up mappings and business rules and to run through data integrations and data validations.
GoldenGate is for replication and is also discussed in Chapter 4, which provides you with guidance on how to use GoldenGate for data migrations and data integrations. Thinking of replication as part of a data integration strategy is not always intuitive, but using it to provide the source of data in another system and keeping it synchronized without manual intervention is critical for the right data to be replicated over.
Other tools such as SQL*Plus, database features such as materialized views, and external tables can also used for integrating the data. Whether joining tables together or loading an external source through stored procedures, relational databases provide solutions for integrating data. Even though the sources might not be in relational databases, extensions for databases can be used to combine the data in a view or to load the data into a data store. Using features from the database allows for automation and data checking. You’ll find more of a discussion about using queries and these features in Chapters 2 and 3.
The database is a powerful tool, for both structured and unstructured data. Storing and integrating data can be part of the design of the application, which then also provides a way to allow others to access it. The security around data integration can match that of the database as well.
The tools are key to managing and implementing effective data integrations. They provide a way to automate, test, and track what is being done. Integrations are already difficult enough without the tools to maintain the process. The rest of the book will discuss in more detail how to use these tools effectively to have a system for managing data integrations.
Summary
Data used for analytics and reporting is very valuable to companies. This data can give a company a competitive advantage and allow for more efficiencies in improving technology processes and providing cost savings. Combining systems internally as well as with external sources of data can be a very involved effort. A workflow process and checks and validations need to be built in. Applications should be designed with data integrations in mind by providing APIs and other ways to access their data.
There is no easy way to provide all the data integrations needed. The data needs to be reviewed for quality, and it doesn’t work without data owners, governance, and communication. There is not always a technology or tool that can help provide the solution needed. Rather, a decision needs to be made about what data is needed and what that data means.
Questions need to be asked—questions that drive the analytics in figuring out what is needed to move the business forward, provide the right solutions for customers, and result in a competitive edge. Data that is pulled from the various available sources, maintained in a secure system, and available at the right time for those who need it can be used to answer these questions. Tools to help harness the data are available, and the combination of these tools with business processes and workflows will provide the data integrations.
