
This chapter is about planning a rich-media application from the point of gathering the requirements to testing the implemented system. The application may be a straight forward rich-media application rather like the Family Picture Book (see Chapter 3) with a simple Web user interface connecting to the database. Or as increasingly is the case the rich-media application will be part of a more complex information system where interoperability of the component parts might be a significant requirement.
In this chapter we will introduce various techniques to collect the requirements, plan the stages of the implementation, prototype, and test the system. This is a good point to reflect on what is special about rich-media applications so that we can recognize where there would be problems in development.
The applications are often novel so there may be few or no existing systems that we can learn from.
The collection of rich-media data and its related metadata is a much more significant problem than in text-only applications and will need to be planned.
The data itself may be the product or service being provided to the customer.
Identifying what the users actually want and what will be useful to them is more difficult, particularly where content-based retrieval (see Chapter 13) is a requirement.
Uncertainty about user and technology requirements may increase the risk in terms of time and resources required to develop the system.
The presentation of the rich media could be through a number of different channels—desktop, Web interface, mobile phone, PDA, iPOD, etc.
Information systems (IS) have been getting more complex. There are many reasons for this. Early systems were based on batch processing where data entry and report generation were in the hands of the IT departments themselves. Now end users are responsible for their own IS, and the complexity of the IS tasks has changed to cover not just operational issues but decision making. An organization may have acquired systems from many different vendors that need to be integrated, so that metadata and interoperability are important. The advent of the Internet has meant the public may interact with an organization’s systems remotely using many different channels—interactive TV and mobile and handheld digital devices. Complex and highly interactive organizational systems must be capable of supporting external users such as the public, whose interaction with a system may be remote, infrequent, and nonroutine, as well as internal employees with different and specific training needs. Forecasters suggest this would mean “useable information and services anywhere and anytime” through multichannel access (Dunckley, L. (2006) Practice in Public Sector IT:Usability and Accessibility Performance. Seibel White Paper.). The way the technology is deployed is vital for its success. As Joaquim Roigé, a director at Healthcare Project Management at Indra in Spain, warns, “This is a new challenge to developers—scarce resources ... means we need to be selective when we consider the alternative technologies customers may use to access our systems. We need to match the interface channel to the task. There is a matrix of channels to services deployed that is something I feel is not currently sufficiently analyzed.”
This raises a number of significant questions for IS providers, such as
How can we improve our understanding, analysis, and design of rich media applications to meet future human needs in a resource-effective way?
How do we support the communities of the future in an era of ambient, pervasive, ubiquitous, and mobile computing? Which technology will be useful and acceptable?
How can we achieve quantifiable return on investment by selecting the right tools and effective methodologies, integrating systems, and deploying standards?
There are many excellent books about requirements gathering, IS project management, and software engineering, some of which are included in the references to this chapter. So here we will focus on those techniques that can be particularly useful for rich-media application development. We will also encourage you to explore the employment of some of the newer tools and techniques that can be used for novel application development with uncertain requirements.
In this chapter we also will look at some illustrative cases as well as tools and techniques that are available to address the problems mentioned above.
Hardly a day goes by without some report in the press that a computer system has failed or been shockingly over budget. In 1994, for example, Scientific American reported that three quarters of all large systems were “operating failures” that either did not function as intended, or are not used at all. In this context success can be described as being used effectively for the uses and users for which it was commissioned. Even worse, it also appears that computer systems are now so pervasive in everyday life that they can kill. Unfortunately, it is well known that problems in medical systems can harm patients seriously if not detected and solved in time. Recently, Koppel et al. (2005) conducted a field study of a hospital’s order-entry system where doctors used the software to specify medications for patients. The study reported 22 ways in which the order-entry system caused patients to get the wrong medicine. Most of these issues were identified as usability problems.
One reason that ICT systems appear to fail is because of a lack of effective user engagement. This can be overcome by incorporating user-centered design (UCD) within development. Thomas Landauer (1995) reviewed the value of UCD based on a wide variety of reported studies where “some kind of UCD was intentionally applied.” While the average gains were impressive (50%) individual studies reported gains in performance from 0% (NASA) to 720% (IBM). Landauer claims, based on studies, that without UCD a user interface has typically 40 flaws.
Requirements are often referred to as user needs. We need to know who the users of the information system are and how they carry out their work. Shifting our focus from the input to the design process, how should information systems meet all the needs of different users? Often system developers may merely equate user needs with utility. Landauer (1995, p. 218) has outlined how designers tend to take a system-centered point of view, and programmers, who are involved day and night with a program, cannot put themselves in the place of a new user. Developers who are working on their own do not have sufficient domain knowledge, either to be sure of recognizing all usability problems and consequently the design factors to solve these problems, or to be confident of accurately prioritizing these problems with reference to actual user concerns.
Clearly users require systems to perform functions for which they were devised, but their needs are much wider. Smith (1997) has classified three distinct types of user needs: functional, aspirational, and physical.
Functional needs, which are the requirement of the information system to perform the specific tasks that the users require it to do in the operational situation: media upload, download, searching, indexing, and media-specific operations.
Aspirational needs represent the requirement to support the medium-to long-term personal goals of the user. How does the rich-media functionality fit the user’s work context, ranging from the clear need for job security to the less-tangible desires for interpersonal affiliation in the work place? Does the functional design fit the organizational and national culture? Are we introducing functions that require the user to learn new skills and concepts and perhaps unlearn previous ways of doing things? Database professionals may need to become familiar with image-processing concepts to exploit all the functionality supplied by interMedia.
Physical needs are the needs of the information system to perform its tasks in a manner well suited to the physical characteristics of the user, including workstation ergonomics and interface requirements. Have we considered accessibility to the rich media—how is it presented?
These different classes of user needs lead us to recognize that there are actually a number of different kinds of requirements that we need to identify at the start of the application development.
Functional requirements capture what the product should do. For a rich-media application this will include collection of media, storage, compression, update, formatting, retrieval, classification, and display. However, we also have to decide how the functionality will be distributed between the database and the APIs. At what point do we compress the data and when do we generate thumbnails and carry out feature extraction?
Data requirements capture issues in terms of:
Volatility—. how often is the data changed? In a rich-media application the data will probably be more stable than is something like a transactional database.
Persistence—. how long must the data remain accessible? This is likely to be a longer timespan than for transactional data as the rich media usually has a higher value.
Accuracy—. how accurate must the data be? Compression (lossy and lossless) and resolution.
Aggregation—. what is the need to summarize and filter the information?
Value—. can it be easily replaced?
Metadata—. standards, ownership.
Amounts of data—. rich media will have significant storage requirements.
Environmental requirements capture the circumstances in which the product will be used. This could be the physical or working environment. At one extreme, what would the system need to be operated at a Mt. Everest base camp at 30,000 feet? Will users be wearing protective clothing? Is the working environment noisy and dusty, such as a textile factory?
The social environment is also important particularly for rich-media applications. Is it public or private? Is it shared or single user? Is it synchronous or asynchronous?
What about the organizational and cultural environment? When we introduce a new computer system we may change work patterns and disrupt working practices. When a European ERP system was implemented in Malaysia there were problems because of the disclosure of pricing information to lowly paid staff. This had not been recognized as a problem by the European developers—the concept of privacy and confidentiality is different in Malaysia than in Western societies.
User requirements capture the characteristics of the user group, their abilities, and skills. Computer users are not all the same, so how do we differ?
Age, gender, expertise?
Culture—psychological differences?
Adaptability? Learning ability?
Discretion—can the users choose to use the system or is it essential for their work?
Usability requirements capture the usability goals and measures for the product. In terms of standards this refers to efficiency, effectiveness, and user satisfaction. In addition, recent legislation has added accessibility requirements. The Web Content Accessibility Guidelines 1.0 were developed by the Web Content Accessibility Guidelines Working Group (WCAG WG) and became a W3C Recommendation in 1999.
The following case study demonstrates how requirements can be complex to identify and document.
The U.K. Identity System Case Study
This is interesting because the U.K. identity system has been described as the largest computer system in the world. ID cards will provide legal U.K. residents, including foreign nationals, with an easy and secure way of proving who they are.
The system’s sponsors claim that ID cards will be linked to their owners by unique biometric identifiers (e.g., fingerprints), which means there will be a much stronger way of protecting people’s identities. Background checks will ensure that claimed identities are real and not stolen, and will prevent criminals from using multiple identities.
The exact format of an ID card is not yet decided but it is likely that it will be a credit card–size plastic card featuring the holder’s photograph and a chip storing basic personal information. The ID scheme is more than just issuing a piece of plastic to every adult in the United Kingdom. It is about recording on a central database personal information that will be linked to biometric data. The card should be convenient for the citizens and provide a simple means to check a person against the record in the database. Security in protecting a person’s identity from theft and preventing criminals from creating multiple identities is another key requirement of the database. Public acceptance of the technology for data capture and information retrieval is important.
The U.K. Identity Cards Bill is presently going through Parliament and includes the following proposals:
National identification register
National identity registration number
Collection of biometrics
U.K. citizens must disclose personal data
The identity system will collect the following data for every citizen:
Name
Birth coordinates
Current and previous addresses
Residential status
Biometric details
In addition, it is planned that the database will hold records of all dealings with individuals and an audit trail of access to the records for security and integrity reasons.
Since the act is currently under consideration, the system has not yet been fully specified but the following could happen:
A national registration register would be created to cover:
Every U.K. citizen from 16 years and 3 months and older.
Every U.K. citizen would be assigned an NIRN (national identity registration number).
Every U.K. citizen would be issued an actual ID card with some of this data.
There are a number of rich media issues such as image formats for capture and storage, upload, indexing, and content-based image retrieval (CBIR) requirements that are currently not specified.
The following sections deal with tools and techniques for gathering requirements, the use of scenarios, and user stories.
Participation and cooperation between users and developers needs to be carefully planned. If we skip on the requirements stage we run the risk of developing a system that the users do not want and will not use. If we use too many resources on the requirements stage we will run out of resources or go over budget. This section looks at the different ways in which requirements can be gathered and documented in order.
To understand what techniques are available for gathering requirements.
To appreciate their strengths and weaknesses.
To understand which techniques to choose for specific applications.
The first question we have to answer is, who are the users? In the ID case study there are a number of different stakeholders. The U.K. government has stated it wants to use the system to deal with identity theft, illegal immigration and working, misuse of public services, organized crime, and terrorism. But how can we find out what the users of the system, the public, and the people who will work with the system actually want?
The problem is not that there is a lack of methods; there is a wide range but there is little guidance to choose methods for a particular application and to plan a well-grounded requirements acquisition program. Table 7.1 gives a list of the classical requirements methods, together with their advantages and disadvantages particularly in terms of rich-media applications.
However, the requirement-gathering techniques listed in Table 7.1 vary in terms of:
Objectives—. an investigation to open up the design space, or a confirmation of a design or building consensus.
Cost involved—. time and difficulty of analysis.
Richness of the information—. ethnography can provide rich information but it will involve sifting through lots of low-value observations to find the gold nugget.
Density of the information—. “signal to noise” ratio—can we distinguish the key relevant information easily from the background information?
Reliability of the information collected—. if the technique were repeated would the data be the same?
Objectivity/subjectivity of the process—. how much interpretation does the developer or evaluator have to make?
Possibility of bias—. are we seeing the true picture or has it been slanted in some way that could mislead us in the next stages of design?
Several of the methods in Table 7.1 mention situatedness. This has been described as the context that provides the multiple perspectives needed for the understanding that permits all voices to be heard in good faith. In our terms it usually means seeing the real-world working situation, and has given rise to context-based design methods.
Table 7.1. Requirement-gathering Techniques for Rich-media Applications
Good For | Data Collected | Advantages | Disadvantages | |
|---|---|---|---|---|
Questionnaires and surveys | Specific questions | Quantitative Qualitative | Low cost Many people can be surveyed | Lacks situatedness Relies on recollection and honesty |
Interviews, structured and unstructured | Exploring issues | Mostly qualitative | Designer can meet and understand users | Designer must select representative users carefully Lacks situatedness Relies on recollection and honesty |
Focus groups | Multiple viewpoints | Mostly qualitative | Highlights issues of consensus and conflict | Group must be homogeneous Group must not be dominated by users with specific issues |
Ethnography field methods | Situatedness | Qualitative | Designer can see actual context of use Can use video and audio to support technique | High cost, low information content |
Remote viewing or evaluation | Some Situatedness | Quantitative Qualitative | Designer can see remote context and take measurements | Designer cannot meet users and may not understand what is going on |
Virtual ethnography | Some situatedness | Quantitative Qualitative | Facilitated by some groupware and ERP systems More efficient than traditional ethnography | Designer cannot meet users |
Every requirement-gathering method has disadvantages and errors can occur. Even with a well-established method, if the method is poorly planned and the sources of error are not recognized and managed, then errors can result. Methods can be biased in different ways.
The “principle of triangulation” is a good idea. Basically, this means that more than one method should be applied to be able to look at the system from different perspectives. This is a way of checking which requirements are stable and valid across user groups and should give more reliable results.
Many of these techniques assume there is some kind of existing system that we can study or ask users about. Nokia is a company that has developed many novel rich-media communication products successfully so it is worth noting its development approach, which is summarized as follows:
User-centered design
Contextual approach
Ethnographic approach
Data gathering includes market research
Scenarios and task models
Iterative prototyping: design–build–evaluate
When we are faced with developing completely new systems or concepts, scenarios can be useful.
Scenarios are informal narratives, usually collaboratively constructed by a team in order to describe human work processes. The scenarios should include more than a simple description of the workflow. The term scenario-based design is used to cover a range of tools and techniques that all have a number of common objectives.
Scenarios are useful both for detailed design and also for the design of new concepts and products. In particular they are useful as a basis for overall design to
Identify human goals and motivations.
Identify design alternatives.
Extend and deepen understanding of the problem.
In terms of software development, these contribute to
technical implementation
cooperation within design teams
communication in a multidisciplinary team
evaluation of prototypes at a later stage in development.
Extreme programming (XP) is a popular agile development method that employs user stories to document requirements and engage users in development. User stories are also an important part of the planning process and serve the same purpose as use cases but are not the same. They are used to create time estimates for the release planning meeting. They are also used instead of a large requirements document. User stories are written by the customers as things that the system needs to do for them. They are similar to usage scenarios, except that they are not limited to describing a user interface. They are in the format of about three sentences of text written by the customer in the customer’s terminology without “techno-syntax.”
In Chapter 3 we introduced the Family and Friends Picture Book with some outline user stories:
Matt is interested in astronomy, and his set of photos is mainly focused on the solar system. He captures images from his telescope as well as gets them from various sources, including the Internet. He needs to identify images from the night sky at different locations and times of the year.
User stories also drive the creation of the acceptance tests. In XP one or more automated acceptance tests must be created to verify that the user story has been correctly implemented.
One of the biggest misunderstandings with user stories is how they differ from traditional requirements specifications. The biggest difference is in the level of detail. User stories should only provide enough detail to make a reasonably low-risk estimate of how long the story will take to implement. When the time comes to implement the story, developers will go to the customer and receive a detailed description of the requirements face to face.
As an essential part of the plan, developers estimate how long the stories might take to implement. Each story will be assigned an “ideal development time” as an estimate of completion time in weeks, such as 1, 2, or a maximum of 3 weeks. This ideal development time is how long it would take to implement the story in code if there were no distractions, no other assignments, and the developers knew exactly what to do. An estimate that is longer than 3 weeks means the story needs to be broken down further. Less than 1 week indicates the story is at too detailed a level, therefore, some stories may need to be combined. About 80 user stories (plus or minus 20) are regarded as a perfect number to create a release plan during the planning stage.
Another difference between stories and a requirements document is a focus on user needs. At this stage the developers should try to avoid details of specific technology, database, layout, and algorithms. The developers should try to keep stories focused on user needs and benefits as opposed to specifying GUI layouts.
Much of what we have said would apply to all information systems, but for a rich-media development we will need to plan
Loading large volumes of rich media into the database.
Associating the correct metadata.
Indexing the media content for future search and retrieval.
Delivering the rich-media content efficiently.
There are several possibilities for loading rich-media data into the database, which we covered in detail in Chapter 6:
Database table replication: copying from one Oracle database into another keeps databases, such as those used for production and deployment, synchronized.
SQL*Loader: a high-volume, bulk loader that deals with large quantities of multimedia content very efficiently, using direct path access.
PL/SQL procedures: often used as an alternative to SQL*Loader.
WebDAV: a standard extension to HTTP.
These are covered in detail in the relevant chapters, especially Chapters 4 and 5.
An important issue is the storage of the media as there are several possibilities, including:
Binary large objects, or BLOBS, stored within the database.
File-based large objects, or BFILES, stored in local operating system-specific file systems.
URLs containing image, audio, and video data stored on any HTTP server, such as the Oracle Application Server.
Specialized media storage servers.
The option of storing multimedia content outside the database can be useful for managing large or new multimedia repositories that already reside as flat files on erasable or read-only devices. This data can be conveniently imported and exported between BLOBS and the external BFILE source at any time. However, as these alternative designs involve a tradeoff between security, manageability, and ease of delivery, this is an area where prototyping (section 7.5) can be of benefit.
interMedia facilitates associating metadata with the relevant rich-media objects. This is explained in Chapter 8 where we see how by using the media object types, the metadata is extracted from the media using the appropriate encapsulated methods and loaded into attributes of the object type. Specific application metadata, such as the name of the artist who created the media, can be extracted when required and returned to the application as an XML string. The way metadata issues are supported by interMedia is covered in Chapter 10.
When we have a reasonable concept of the requirements, the next stage is to consider the architecture of the proposed system. It is often not appreciated that the choice of technical architecture has significance for other issues such as interoperability, connectivity, and usability. This is because you cannot add on usability late in the development of complex customer-centric systems. The choice of architecture will enable or restrict the way the system is implemented. When we define the architecture we must consider
Integration necessary between different private and public bodies in order to provide customer centricity seamlessly and cost-effectively.
Significant technological investment in legacy systems.
Many standards that affect IS are set at a national, not international, level but for rich media there are a number of important international standards as well.
Current projects and implementations often do not mandate standards but only suggest them for consideration.
This is a good point to consider enterprise architecture (EA) and whether the proposed rich-media system is intended to fit seamlessly into an existing EA. In the last decade the ability to combine disparate streams of information to improve decision making, develop business innovations, and streamline operations was perceived as giving a company a competitive advantage over others that might be overwhelmed by information overload. The development of the concept of the information architecture also changed the emphasis of software development from using a single development methodology and supplier to supporting diversity within an overarching framework. Now the interconnectivity of the Web is creating the need for organizations’ separate EAs to achieve a level of compatibility and interoperability. The development of EA encountered technical problems, such as interfacing products from different hardware and software vendors, but the primary impediment was the web of organizational factors such as management commitment, data responsibility, data centralization, system design, and staffing. User participation and management commitment are the most significant factors in the success of enterprisewide modeling. End-user managers and their staff must actively engage in defining data elements and relationships among data because they are in the best position to determine the relative importance of data elements to the business. This means negotiating to replace or adapt existing data models.
Table 7.2 presents Zachman’s enterprise architecture. This is a useful way of providing a framework for the planning of application and information systems. The original ISA framework had three columns that represented the data, function, and network representing the what, how, and where of an IS. They relate to columns A, B, and C of the full framework. A later version of the ISA framework (Sowa and Zachman, 1992) consisted of a table of 30 cells, organized in 6 columns of 5 rows, since they recognized the need to add further perspectives relating to people who, motivation why, and events when. As a level-based approach the ISA moves from generalized business objectives progressively to more detailed planning levels from the general to the specific and from the nontechnical to the technical issues. Zachman’s original model was ahead of its time in that it recognized the need for the “planner” row to set the business context of an IS. The planning row provides a predominantly business viewpoint while the lower rows give a technological viewpoint. The framework as it applies to enterprises is simply a logical structure for classifying and organizing the descriptive representations of an enterprise that are significant to the management of the enterprise as well as to the development of the enterprise’s systems. Thus, the data column would require the development of one consistent logical data model for the whole organization.
Table 7.2. Zachman’s Enterprise Architecture
FUNCTION How | NETWORK Where | PEOPLE Who | TIME When | MOTIVATION Why | ||
|---|---|---|---|---|---|---|
SCOPE CONTEXTUAL Planner | List of things important to the business | List of processes the business performs | List of locations where business operates | List of organizations important to the business | List of events/cycles important to the business | List of business goals/strategies Ends/means |
BUSINESS MODEL Owner | e.g., Semantic model | Business process model | Business logistics system | Work-flow model | Master schedule | Business plan Ends = Business objective Means = Business strategy |
SYSTEM MODEL Designer | e.g., Logical data model | Application architecture I/O user views | Distributed systems architecture | Human interface architecture People = Role Work = Deliverable | Processing structure | Business rules model Ends = Structural assertion Means = Action assertion |
TECHNOLOGY MODEL Builder | e.g., Physical data model | System design | Technology architecture | Presentation architecture People = User Deliverable= Screen format | Control structure | Rule design End = Condition Means = Action |
DETAILED REPRESENTATION Subcontractor | e.g., Data definition | Program language statements I/O control block | Network architecture Node = Address Link = Protocol | Security architecture People = Identity Work = Job | Timing definition Time = Interrupt Cycle = Machine cycle | Rule specification End = Subcondition Means = Step |
FUNCTIONING ENTERPRISE | e.g., DATA | e.g., FUNCTION | e.g., NETWORK | e.g., ORGANIZATION | e.g., SCHEDULE | e.g., STRATEGY |
Note: For the ID system, we can start to specify the cells as follows:
DATA, What—. Things important to the business: protecting personal identity, preventing criminals from creating multiple IDs, strengthening homeland security, preventing illegal immigration, controlling access to public services.
FUNCTION, How—. Background checks on identities, collect biometrics, issue ID cards, register adult residents, audit use.
NETWORK, Where—. Locations: all U.K. regions.
PEOPLE, Who—. Important organizations: Interol, NSA, CIA, U.K. Passport Office, U.K. service providers.
The technical architecture selected will depend on requirements for interoperability, connectivity, and usability. Probably the most well-known current architecture is the client-server system but the Oracle interMedia architecture is most easily represented as a three-tier architecture—the data server tier, the application server tier, and the client tier (Figure 7.1). Oracle Application Server and Oracle Database install Oracle HTTP Server powered by the Apache HTTP Server. Oracle HTTP Server serves mainly the static HTML files, images, and so forth that a Web application uses, and is usually located in the file system where Oracle HTTP Server is installed.

The lowest tier, the data server, contains the database. Within this are two important components: the media parser, which takes the rich-media content and parses out the media format, and metadata. The media processor supports the processing of images within the database (see Chapter 8). Both of these run on the Oracle Java Virtual Machine. The delivery servers are special servers connected to plug-ins that get the rich-media content out of the database and deliver this to thin clients. RealNetworks Helix and Microsoft Windows Media are streaming servers that are examples of these. The special indexers are third-party indexers that can perform functions, such as speech recognition and building speech-to-text time base indexers for specialized applications. Also within the data server tier is the XML schema used for loading media content into the XML DB, which makes it easy to manage the media content as part of an XML document.
The application server tier includes the Web server and the interMedia class libraries, such as the JSP tag library for JSP application development. Also in the middle tier is Webdav—a Web distributed authoring and versioning protocol. Webdav is a standard extension to HTTP that makes upload and download of media to remote clients easy. Another middle-tier component is for multimedia delivery over wireless connections. This component provides for media adaptation to suit delivery channel characteristics and output devices.
In this way downloading or delivery of all multimedia content is supported either in batch or as streaming for certain audio and video formats. The data types can always be delivered from the database to the client in batch, synchronous mode. For some data types, more specialized delivery services are available (see Figure 7.2). For certain audio and video formats, the media object types can be delivered in an isochronous or stream fashion, making it possible to play it as it arrives using the RTSP protocol. Oracle interMedia support for these special protocols is through peer-level servers from third-party partners such as RealNetworks and Microsoft.

Using the Java database connectivity (JDBC) interface, you can quickly develop applications for use on any tier (client, application server, or database) to manipulate and modify audio, image, and video data, or heterogeneous media data stored in a database. Oracle interMedia Java Classes makes it possible for JDBC result sets to include both traditional relational data and interMedia columns of object-type media data, to easily select and operate on the result set, to access object attributes, and to invoke object methods. Through Java class libraries, Java clients can retrieve multimedia objects in JDBC result sets and send them to a browser. These same clients can use the Java Advanced Imaging (JAI) package used by Oracle interMedia to perform sophisticated, client-side image processing. Thick clients can also use a Java Media Framework (JMF) player to play, upload, and download audio or video clips from Oracle interMedia. This is described in Chapter 9 on Java application development.
We can also develop interMedia application through PL/SQL. The Oracle HTTP Server contains other modules or plug-ins that extend its functions. One of these modules is the mod_plsql module, also known as the PL/SQL Gateway (Figure 7.2), which serves data dynamically from the database to Web browsers by calling PL/SQL stored procedures. The PL/SQL Gateway receives requests from a Web browser in the form of PL/SQL servlets or PL/SQL server pages that are mapped to PL/SQL stored procedure calls. PL/SQL stored procedures retrieve data from the database and generate an HTTP response containing the data and code from the PL/SQL Web Toolkit to display the generated Web page in a Web browser. The PL/SQL Web Toolkit contains a set of packages that can be used in the stored procedures to get the information required, construct HTML tags, and return header information to the client Web browser.
Oracle HTTP Server contains the PL/SQL Gateway or mod_plsql module, the database access description (DAD) that contains the database connection information, and the file system where static HTML files and images are stored for use by Web applications. From the PL/SQL Gateway, the response is returned to the HTTP Server for hosting as a formatted Web page for the client Web browser. Usually, the returned formatted Web page has one or more additional links, and each link, when selected, sends another request to the database through the PL/SQL Gateway to execute one or more stored procedures. The generated response displays data on the client Web page usually with additional links, which, when selected, execute more stored procedures that return the generated response for display as yet another formatted Web page, and so forth. This is how the PL/SQL application in the PL/SQL development environment is designed to work.
Web application developers who use the PL/SQL development environment create a PL/SQL package specification and body that describe procedures and functions that comprise the application. The package specification defines the procedures and functions used by the application, and the package body is the implementation of each procedure and function. All packages are compiled and stored in the database to perform specific operations for accessing data in the database and formatting HTML output for Web page presentation. To invoke these stored PL/SQL procedures, Web application developers use the request/response PL/SQL servlets and PL/SQL server pages (PSP) to allow Web browser clients to send requests and get back responses using HTTP.
Oracle HTTP Server maps a URL entered in a browser to a specific PL/SQL procedure stored in the database. It does this by storing specific configuration information by means of a DAD for each stored procedure. Thus, each DAD contains the database connection information that is needed by the Web server to translate the URL entered into a database connection in order to call the stored procedure.
A key determinant of successful IS implementation is the technical architecture (shown in Table 7.2). However, currently client-server systems provide limited support for distributed architectures required for complex systems involving rich media. Several alternative technologies have been put forward as solutions:
Grid technology has the potential to allow both competition and interoperability not only among applications and toolkits, but also among implementations of key services. Interoperability could be achieved by both standards in communication and data security, storage, and processing, and by policy initiatives, including organizational protocols, financing procedures, and legal frameworks.
Web services are loosely coupled reusable software components that semantically encapsulate discrete functionality. They provide a distributed computing technology for publishing, discovering, and consuming business services on the Internet or within an intranet using standard XML protocols and formats. Web services standards are giving service definition a structure but challenges remain. If a service could not define its security, availability, integrity, and environment, an acceptable definition of service would not be achieved.
Open grid services architecture (OGSA) is one approach that is suggested as an architecture unifying grid and Web services technology to address flexibility and reliability and to improve the interoperability of grid systems.
Hub-based approaches achieve interoperability by employing a connectivity hub for data exchange that is composed of a common object model and a set of process flows that run across a variety of systems independently of the communication technology and the underlying data models and applications.
If barriers, in terms of legacy systems, silo processes, and heterogeneous connectivity are to be overcome, an innovative approach has to be developed. The hub-based approach provides a technical solution that is compatible with the separation of data, function, and network columns of the EA (see Table 7.2). There are also concerns that service-oriented architectures will not solve interoperability problems alone because of shortcomings especially in the aspects of scalability and interoperability. Peer-based SOA (PSOA) will lead to point-to-point solutions (1:1 interfaces) that are not the best solutions, since they are not scalable or cost-effective—the cost and effort of developing and maintaining such interfaces grows exponentially when new systems are added. Every new system may need as many interfaces as the already existing systems and theoretically, if every system is to be connected with each other, the number of interfaces is N*(N-1)/2, N being the total number of systems. Therefore, the idea of a connectivity hub for data exchange clearly appears to be the solution to the problem of N:N interfaces. In order to integrate consistently different data models, different data definitions and data formats, different semantics and different meanings, a hub would reduce the complexity to a 1:N basis by means of a common object model as a composite of application data models. Discussions and white papers concerning these alternative architectures can be found on the Oracle Technology Network website.
In Table 7.2, for historic reasons, there are two separate columns devoted to data and function although in object-oriented development these are not separated. In the next sections we will look in more detail at the specifications of parts of these columns.
In most organizations, analysis, development, and database teams have tended to work for different managers, business units, and other business organizations. These separate teams are working toward a common goal and need to work together. One of the great potential advantages of adopting UML would be that different IT professionals, who tend to be involved in different stages of the lifecycle, should be able to use a consistent set of modeling techniques and communicate effectively with one another. In the past database designers have tended to use entity models for logical database design while application programmers used a variety of programming design techniques.
This is even more important in incremental development where different parts of the same system may be being changed constantly. As the developers build the applications they uncovers new requirements and the database team also uncover new requirements building the database.
In Figure 7.3 we can see a representation of development from analysis to implementation. At the analysis stage a UML class diagram is used to design the conceptual schema instead of the extended ER model often used in relational database development. UML has the advantage that it permits the design of the entire system, facilitating different system views. The design phase would include a logical design that was independent of any product and a specific design based on Oracle without considering tuning or optimizing at this stage. The logical design (see Table 7.2 SYSTEM MODEL) has an object-relational design that can be used by all the product implementations, forms, Java, etc. and can make migration between products easier. It is useful in the design phase to develop an SQL:1999 schema for interoperability purposes and use an extended UML graphical representation to support documentation and understandability. It also makes the development of the database schema easier as it shows the correct order in which we will need to compile each new object type (or UDT). The implementation phase (see Table 7.2, builder layer) will include some physical design tasks to fine-tune the schema to improve response time and storage space.

The process will require transformations between UML, SQL:1999, and Oracle. Table 7.3 provides some guidelines for transforming a conceptual UML-based schema into SQL:1999 schema and into Oracle object-relational types.
Table 7.3.
UML | SQL:1999 | Oracle Object-Relational Types |
|---|---|---|
Class | Structured type | Object type |
Class extension | Typed table | Table of object type |
Attribute | Attribute | Attribute |
Multivalued | ARRAY | VARRAY/Nested table |
Composed | ROW/Structured type in column | Object type in column |
Calculated | Trigger/Method | Trigger/Method |
Association | Table Constraints | Generalisation row |
One-to-One | REF/[REF] | REF/[REF] |
One-to-Many | [REP]/[ARRAY] | [REF]/[Nested table/VARRAY] |
Many-to-Many | ARRAY/ARRAY | Nested table/Nested table VARRAY/VARRAY |
Aggregation | ARRAY | Nested table/VARRAY of references |
Composition | ARRAY | Nested table/VARRAY of objects |
Generalization | Types/Typed tables | FINAL/INSTATIABLE types |
In UML only persistent classes (marked by the stereotype <<persistent>>) have to be transformed into a class in the database schema. This may mean defining the object type as well as its extension as an object table. Each UML class method is specified in the definition of the object type as the signature of the method so that the method belongs to that type. The body of the method can then be defined separately.
Each attribute of the UML class is transformed into an attribute of the type. Multivalued attributes are represented as collection types. Oracle supports VARRAY and NESTED TABLE collection types. Using a VARRAY is recommended if the maximum number of elements is known and small and the entire collection is to be retrieved. If the number of elements is unknown it is better to use a NESTED TABLE, which can also be queried easily. Composed attributes can be defined as an object type without extension (not defining the object table). Derived attributes should be implemented by means of a trigger or a method.
In the U.K. ID card system, each citizen’s details could be held together with their current and previous addresses. Figure 7.4 represents the transformation using graphical notations. Note the collection type has no methods of its own.

This extension of UML (Table 7.4) defines a set of stereotypes, tagged values, and constraints that enable applications to be modeled in object-relational databases and follows the recommendations of Marcos et al. (2005).
Table 7.4. Stereotypes for Database Design
Database Element | UML Element | Stereotype | Icon | |
|---|---|---|---|---|
Architectural | Database | Component | «Database» | |
Schema | Package | «Schema» | ||
Conceptual | Persistent class | Class | «Persistent» | |
Multivalued attribute | Attribute | «MA» | ||
Calculated attribute | Attribute | «DA» | ||
Composed attribute | Attribute | «CA» | ||
Identifier | Attribute | «ID» | ||
Logical | Table | Class | «Table» | |
View | Class | «View» | ||
Column | Attributes | «Column» | ||
Primary key | Attributes | «PK» | ||
Foreign key | Attributes | «FK» | ||
NOT NULL constraint | Attributes | «NOTNULL» | ||
Unique constraint | Attributes | «Unique» | ||
Trigger | Constraint | «Trigger» | ||
CHECK constraint | Constraint | «Check» | ||
Stored procedure | Class | «Stored Procedure» | ||
Physical | Tablespace | Component | «Tablespace» | |
Index | Class | <<Index>> |
In Table 7.5 we show how the SQL:1999 stereotypes can be implemented.
Table 7.5. SQL:1999 Stereotypes
Typed Table | |
|---|---|
Metamodel class: Class. | Metamodel class: Class. |
Description: A «UDT» allows the representation of new user-defined data types. | Description: It is defined as «Object Type». It represents a class of the database schema that should be defined as a table of a structured data type. |
Icon: None. | Icon:  |
Constraints: Can only be used to define value types. Tagged values: None. | Constraints: A typed table implies the definition of a structured type, which is the type of the table. Tagged values: None. |
Knows | REF Type |
Description: A «Knows» association is a special relationship that joins a class with a user-defined data type «UDT» that is used with the class. It is a unidirectional relationship. The direction of the association is represented by an arrow at the end of the user defined type used by the class. | Description: A «REF» represents a link to some «Object Type» class. |
Icon: None. | Icon: |
Constraints: Can only be used to join an «Object Type» class with a «UDT» class. | Constraints: A «REF» attribute can only refer to an «Object Type» class. |
Tagged values: None. | Tagged values: The «Object Type» class to which it refers. |
ARRAY | ROW Type |
Metamodel class: Attribute. | Metamodel class: Attribute. |
Description: An «Array» represents an indexed and bounded collection type. | Description: A «row» type represents a composed attribute with a fixed number of elements, each of them can be of different data type. |
Icon: | Icon: |
Constraints: The elements of an «Array» can be of any data type except the «Array» type. | Constraints: Has no methods. |
Tagged values: The basic types of the array. The number of elements. | Tagged values: The name for each element and its data type. |
Redefined Method Metamodel class: Method. Description: A «redef» method is an inherited method that is implemented again by the child class. Icon: None. Constraints: None. Tagged values: The list of parameters of the method with their data types. The data type returned by the method. | Deferred Method Metamodel class: Method. Description: A «def» method is a method that defers its implementation to its child classes. Icon: None. Constraints: It has to be defined in a class with children Tagged values: The list of parameters of the method with their data types. The data type returned by the method. |
The aim of ITC development is usefulness, but it is difficult to define, whereas the concept of usability is well established and enshrined in an ISO standard (ISO 9241-11.3). The consequences of poor usability design are evident as
User dissatisfaction and even rejection.
Wasted resources and time as users resort to “working around” the system.
Dangers of incomplete data entry.
Error propagation.
Adverse economic impact.
Investing in usability means planning this into the system development from the earliest stages in the lifecycle, rather than delaying the user input until the final stages of testing. This is because problems of usability can be difficult to solve. When a problem is identified too late in the development there is an inevitable tendency to “quick fix” the problem even if it were clear there could be something fundamentally wrong with the product. We need an early focus on the users to help developers understand how users think about the whole system not just the interface. Introducing a user focus and maintaining it throughout the development makes good economic sense.
As the design process has become more complex, technology has given us some support. This means that we can now create interactive prototypes fairly easily and explore different design options early in the development. We can use online questionnaires to provide users with opportunities to give feedback through our websites so that we can continuously monitor usage and collect information about errors. We can capture information about user behavior and interactions remotely. Although this can generate large amounts of data, it can be difficult to interpret without the use of HCI specialists. This means we should consider the use of multidisciplinary teams with developers, managers, users, and HCI specialists working together. These ideas are built into a number of agile development methods such as dynamic systems design method (DSDM) and extreme programming (XP).
However, some developers are still reluctant to engage directly with users. Too often “user testing” is just letting another developer or someone trusted by the development team use the system. Some organizations also worry about the commercial implications of showing early design concepts to users. But the payoff in terms of the system’s quality and the professional development of software engineers can be considerable. There are also guidelines and heuristics to help designers, although these are less well known than one might expect. Talking informally with a group of U.K. developers recently, we were surprised how few were aware of simple heuristics, such as that displaying text in uppercase makes it less readable and would be inefficient for users. Another problem is that some developers are still not aware of the requirements of accessibility in terms of font, color, animation, and effectively labeling images through metadata. This may partly be the way usability is presented in the literature. HCI books are notoriously wordy and some heuristics are quite vague and deal with slippery concepts such as “naturalness.”
For example, recent changes in legislation in the United States and European Union (EU) place an obligation to make ITC systems accessible for disabled people (WAI initiative). Therefore, we need to design systems with flexibility in mind. Following accessibility guidelines should ensure that all kinds of websites, including multimedia, work well for all users. When we improve usability for disabled users we will automatically improve the system for everybody. Since the Web has a strong visual bias, we need to ensure access for people with vision impairments.
Another problem technological advances pose is that we can no longer design systems with the same degree of predictability. The risk in system development is much higher. It is very easy to cite numerous expensive IT failures. Since both the investment and risk is high, prototyping and piloting these systems is essential. While prototyping is now popular, piloting is less widely used but can be essential when untried technology is being considered, such as the U.K. ID card system. Another key issue is evaluating the prototype user interfaces in a timely and efficient manner.
There are many variations of prototyping but all methods involve the creation of some kind of prototype, even though the prototype itself can range from just a rough sketch to a working prototype the user can interact with. The objective is, however, the same: to anticipate the future use of a product by trialing the prototype with users because the product is not yet available. We can distinguish two basic types of prototyping strategies:
The throwaway approach where the prototype is redeveloped or translated.
The evolutionary approach where the prototypes themselves become delivered systems.
Many different terms are used to describe the product of these processes. Prototypes have been described as external or internal from the viewpoint of the users and can also be said to have horizontal or vertical functionality. This is outlined in Figure 7.5. In horizontal prototyping the whole, albeit limited, version of the required system is prototyped and at each iteration of the evolutionary process more and more detail of the system is added. This is in contrast to vertical prototyping where a full version of one part of the system is developed. Typically horizontal prototypes are mock-ups, however, their influence on the software development is not profound because they do not allow the user to evaluate their requirements fully. Vertical prototypes are of much greater interest because they can exhibit more functionality and would normally be expected to have
A user interface
Supporting data structures and storage
Algorithms or data manipulations
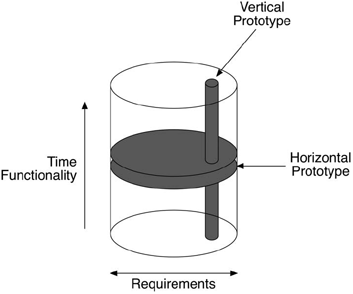
Currently the terms low fidelity and high fidelity are also being used to distinguish two kinds of prototypes that are particularly important for user requirements.
These are used early in the lifecycle and are called low fidelity because they may not resemble the end product very strongly and are created very quickly from low-cost materials. This is usually a rough-cut external user interface that can be paper, whiteboard, flip charts, or a mock-up produced in a software package, such as Microsoft Word or PowerPoint, that has no interactivity. It is useful to provide the “look and feel” of an interface but it lacks the ability to demonstrate effectively how the user interacts with the system because it will have strictly limited functionality. A so-called first-cut prototype should include menus, layout outline, and dialogue to represent how the user would navigate around the system, but this would not be detailed.
A simple technique for developing low-fidelity prototypes that involve users in design sessions is called PICTIVE (plastic interface for collaborative technology initiatives through video exploration). This technique was developed by a team of designers led by Muller working for Sun Microsystems and first published in 1992. Variants of the method are now quite widely used. The method uses low-cost familiar office materials (e.g., colored pens, Post-it® notes, highlighters, colored paper, and tape).
Large sheets of paper represent screens or windows.
Smaller papers or large Post-it notes represent dialog boxes or menus.
Icons are drawn onto the paper or may be produced prior to the sessions.
Colored acetate represents highlighting fields or windows.
Paper widget sets can also be used when a particular target environment is known.
The participants then create a low-fidelity design by building up the structure from a series of Post-it notes layered on a paper screen by users and developers working together. This is particularly useful for rich-media applications where the users may not be able to articulate in words what they want and may suggest requirements that would be technically difficult to realize. The design session can be participative and negotiable. Several alternative designs can be easily explored in detail very quickly. For example, in the case of a Web interface, the design based on a “frame” look and feel can be contrasted with one based on tabs or pull-down menus. The position and size of image and video windows can be explored as well as the way the media would be queried and navigated. One of the advantages of this approach is that participants can explain both the static design of the screen and its dynamic behavior. Several screens will typically be developed and the users and developers can check how to navigate between screens and menus very easily. Obviously, I do not know of its successful use for audio.
It is important that PICTIVE materials can be changeable and extensible by the participants. Once the group has produced a mock-up interface using PICTIVE materials, users can then walk through the mock-up narrating and explaining their work scenarios. Participants can
Annotate the materials by writing and drawing on the design.
Rearrange or replace the materials to explain how work can be done differently.
Reduce social distance between users and designers.

The strongest use for PICTIVE has been in design of visual interfaces based on user-enacted scenarios. In the original method the PICTIVE sessions were videoed. The video records form a way of documenting the design decisions so that developers can check the group discussions that lead to the PICTIVE design. As well as the video the developers have a set of notes from the session and the PICTIVE prototype itself. One of the strongest reasons for using PICTIVE is that it is a low-cost way of carrying out parallel prototyping. This opens out the design space by producing alternatives. One way of doing this is to deliberately plan PICTIVE sessions with different user groups.
This kind of prototype will be much more refined and interactive, capturing essential features of the proposed design in some detail. The key characteristic is that these prototypes are interactive and the user can appear to complete a task and so a much more extensive evaluation is possible. This kind of prototype takes more time and resources to develop and consequently there is a temptation to allow this kind of prototype to develop into the actual product. In evolutionary prototyping these prototypes are not considered to be “throw-away,” although low-fidelity and high-fidelity prototypes could be developed at various stages in both horizontal and vertical prototyping.
Characteristics of high-fidelity prototypes are:
Complete functionality
Extensive interaction
Include navigation and information flow
Prototype responds to user in a way that represents final product
The advantages are:
Usability testing can be conducted early in design–build–evaluate cycles.
Realistic comparisons with competitive products can be made.
Provides a “living” specification for developers.
Can be effective marketing tools.
The disadvantages are:
Expensive and time-consuming
Requires significant programming effort
Difficult to investigate design alternatives because of expense and duplication
Many important design decisions may be made too rapidly to be validated
Oracle provides a suitable application development framework in JDeveloper. Within this system you can set up a number of projects within an application. An application is the highest level of the control structure and serves as a collector for the subparts. This means it is possible to create a high-fidelity prototype for one part of the application that has been identified as suitable while traditional application development continues for other parts of the application. Within JDeveloper we can access the database directly through the SQL worksheet so that DBA functions can be carried out here and the media loaded.


Since JDeveloper supports every stage of the development lifecycle through a single IDE it overcomes many of the disadvantages of prototyping such as version control and refactoring. In this way modeling, coding, debugging, testing, and tuning can be carried out in the same environment. JDeveloper includes UML modelers that can be integrated with creating EJB and simple Java classes. This includes support for the main UML models, such as a Class Modeler, Use Case Modeler, Activity Modeler, and a Sequence Diagram Modeler.
It includes a TopLink Mapper that enables developers to visually map Java objects to databases and other data sources.
At the user interface level JDeveloper provides a visual layout editor for HTML, JSP, and JSF in such a way that it can support interfaces for multichannel applications. A component called the Property Inspector allows the developer to simply specify attributes of visual components. For Web applications Oracle ADF also includes ADF faces. These are a set of JSF components that can be used to define advanced HTML with functionality provided by JSF architecture.

It is often assumed that prototyping ensures the design will be user-centered. This was not part of the original concept and it is still not universal. The characteristics of the users who will interact with the system—their experience, frequency of use, location, equipment, and authority level—are all significant. Experienced users can overlook the obvious and make assumptions that inexperienced users would not. This affects many stages of user-centered design from identification of requirements to evaluation. Users carry out tasks in response to events that occur within their sphere of responsibility. Special attention must be taken of all the objects the user employs so that these can be integrated into the way systems work even if they (objects) are not part of the system.
However, in practice there are several problems with prototyping, particularly
Learning curve
There can be high expectations of high productivity that do not take into account the need for tools and training.
Tool efficiency
Prototyping tools are generally less efficient than conventional programming languages (slow, large memory requirements, larger code).
New roles for people—users must be involved
Prototype itself (what is it—product, representation?)
Ending prototyping—it can be difficult to stop—at each iteration users keep suggesting improvements and so do the developers
Accuracy—this is important in user testing
Acceptance
At the center of a prototyping development is a build-and-test cycle. It is important to evaluate the prototype and identify redesign issues. There are broadly two categories of interface evaluation methods that have been used:
Inspection methods conducted by usability experts that are cheaper and can be deployed in the early stages of the development process. However, the actual context of use is usually missing, hence these methods are often criticized for not addressing a “true picture” and are less reliable with new technological systems;
Field methods (sometimes called ethnography), involving real users in their real context who are able to contextualize the evaluation. This tends to be time-consuming and expensive. Also, it requires the system, or a good robust prototype of it, to be developed and deployed.
On the positive side, newer usability methods are being developed that emphasize the context of use, can be deployed by interdisciplinary teams, and require less training. A realistic factor is that employing social scientists is cheaper than employing software developers so that the payoff from a small ethnographic pilot can be considerable provided the social scientists understand the design objectives and issues, and speak the same language as the developers.
During the build and test stage of prototyping a range of products are generated, some of these are in the form of documentation, for example:
Task specification
System functionality specification
Interface functionality specification
Screen layout and behavior
Design rationale
User feedback
Performance criteria
Reusable code
Given these reservations, prototyping can still be a powerful development tool. In one interview, a developer reflected on a career in which prototyping had played an important part before the introduction of modern tools or RAD and emphasized the prospective nature of user ownership and belief:
This developer emphasizes that crucial factors in whether the system will eventually “work” are the future activities and motivation of the user and that these are influenced strongly by previous prototyping experience, via either direct involvement or as “ambassador” users. However, just chatting with users about a screen can be inefficient and too open so that requirements drift occurs. It can be more efficient to plan a succession of developer–user interactive sessions, which we call DUCE sessions.
A DUCE session could take place in a usability lab but it is intended that the session should be held in the user’s workplace in a realistic context. This method is intended to be used by developers actively involved in design decisions rather than HCI specialists.
The objective of the DUCE session is to make the users explain their normal working practice in relation to the prototype and while they are interacting with it. In order to assist the users to verbalize their experience, the developer is required to ask them a number of open questions as they work through the scenarios. The developer should also make a video and audio recording of the evaluation session for later analysis and takes notes of issues expressed. The question framework is shown in Figure 7.10.
Table 7.10. Eliciting user comments in a DUCE session
For each task/goal: | |||
Ask the user to explain what he/she is attempting | |||
For each subtask: | |||
Ask the user to explain what he/she is attempting | |||
For each stage in Norman’s model of interaction: | |||
Consider asking a question from the checklist | |||
Next stage | |||
Next subtask | |||
Next task | |||
The questioning style we are aiming for is more exploratory and less inquisitorial. For example, questions in the style of “Why did you do that?” are excluded because this would make the designer too dominant in the conversation. A checklist is provided in Figure 7.11 showing the theoretical cognitive stage (Norman, 1986) on the left and corresponding questions to ensure that each stage of cognition involved in completing the task is discussed by the user and developer.
Table 7.6. Checklist of questions
User’s Cognitive Stage | Potential Question |
|---|---|
| a) How does the screen help you select a way of achieving your task? |
| b) How does the screen suggest that what you are about to do is simple or difficult? |
| c) How does the system let you know how you are making progress? |
| d) What is the most important part of the information visible now? e) How has the screen changed in order to show what you have achieved? |
| f) How do you know that what you have done was correct? g) How would you recognize any mistakes? |
The next problem is how to refine the requirements in light of information from data-gathering activities and prototyping. An important issue is prioritizing these. MoSCoW rules (from Dai Clegge of Oracle) is a technique that can help:
The MoSCoW rules are very important as they form the basis of the decisions the developers will make over the whole project and during the time boxes. Time boxing is a technique for making sure prototyping development does not get out of control.
Improving design following user testing is often challenging because attempting to remove one fault can introduce other problems. Therefore, it is important that the designers are presented with actual user comments rather than a reinterpretation of them. This is based on observations that actual comments appear to have more impact motivating designers to change their design than evidence from experts that could be dismissed as merely opinion.
We recommend a meeting to thrash this out, which we call a team evidence analysis (TEA) session. This is because it involves problem solving where a team of developers needs to collaborate. In these days of outsourcing, the team may be distributed geographically and in different time zones, so the session may need technology such as groupware to facilitate it. In general, the way that designers convert data from usability evaluations into design decisions is not clear. One approach is based first on the user importance (the number of users encountering the problem and its importance to the user); secondly on the difficulty to repair the problem; and thirdly in relation to cost-benefit analysis (the relationship between user importance and cost of repair).
What kind of teams are most effective? We have found through experimental study of teams of developers that teams who work together are more effective at resolving design issues than developers working alone, and that having actual users’ comments were more useful than the participation of an HCI specialist.
The ISO standard (ISO/IEC 9126 [1991]) defines six quality characteristics and describes a software product evaluation process model. This standard describes
The external quality manifested by software is the result of internal software attributes. The quality characteristics provide a framework for specifying quality requirements for software and making trade-offs between software product quality characteristics (see Figure 7.11). The objective is to achieve the necessary and sufficient quality to meet the real needs of users. These can be stated and implied needs. User requirements can be specified by quality-in-use metrics, which in turn can be used when a product is evaluated. Achieving a product that satisfies a user’s need normally requires an iterative approach to software development with continual feedback from the user’s perspective.

Quality in use is the user’s view of quality of the software product when it is used in a specific environment and a specific content of use. It measures the extent to which users can achieve their goals in a particular environment. It does not measure the properties of the software itself. The effective testing of the modules requires planning the test, including test data. Use cases form the basis of test cases and scenarios. See Figure 7.12.

Oracle JDeveloper demonstrated the advances in RAD tools. Without tool support testing and debugging user interface code can be challenging as user interface events can be difficult to disentangle. The UI debugger provides an easy way to monitor user interface execution with UI snapshots, event tracking, and graphical object display. We can also integrate with open source testing frameworks.
The ISO standard defines usability as the extent to which the software product can be understood, learned, used, and attractive to the user when used in specified conditions.
Understandability | The capability to enable the user to understand whether the software is suitable and how it can be used for particular tasks and conditions for use. |
Learnability | The capability to enable the user to learn to use its application. |
Operability | The capability to enable the user to operate and control its application (controllability, error tolerance, and conformity to user expectations). |
Usability metrics should be objective, empirical, use a valid scale, and be reproducible. To be classed as empirical, data must be obtained from observation or a psychometrically-valid questionnaire.
The context of use includes the users, tasks, the physical, system, and social environment in which the software product is used. Usability metrics can be obtained by simulating a realistic working environment in a usability laboratory.
Quality in use metrics include:
Table 7.7. Metrics for the Usability of Multimedia Applications (ISO/IEC TR 9126-2)
Metrics | Definition |
|---|---|
Task completion | What proportion of the tasks are completed, x = A/B |
Task effectiveness | What proportion of the tasks are completed correctly, x = A/B |
Error frequency | Number of errors made by users, x = A |
Help frequency | Number of accesses to help, x = A |
Task productivity | M2 = M1/T, where M1 is task effectiveness, T is task time |
Satisfaction scale | x = A, where A is questionnaire responses |
Operational frequency of use | Does the user use the software frequently Actual use/Opportunity of use, x = A/B |
Media device utilization balancing | Degree of synchronization between different media over set period of time – X = ST/T, where ST sync time is time devoted to continuous resource, T = time period for dissimilar media to finish tasks with synchronization |
Effort type is the productive time associated with a specific project task, while individual effort is the productive time needed by the individual to complete a specified task. The task effort is the accumulated value for each individual over the whole project.
Understandability metrics are significant guides for rich-media applications. These include:
Functional understandability: the number of user interface functions where purposes are easily understood by the user, compared with the number of functions, x = A/B.
Location understandability: the number of user interface functions where purposes are easily understood by the user, compared with the number of functions, x = A/B (can the user locate functions by exploring the interface?).
Number of input items that check for valid data, x = A/B
Number of functions that can be cancelled, x = A/B
Number of functions that can be customized for access by users who have accessibility problems, x = A/B
Physical accessibility: number of functions successfully accessed by users with physical handicaps
There are two time behavior metrics that are important for rich media:
Response time—. estimated time to complete task
Throughput time—. number of tasks that can be performed over unit of time
How many users do we need to test our systems? Landauer and Nielsen seem to suggest that with five users we would uncover 80% of the problems, however, ISO/IEC TR 9126-2 suggests that for reliable results a sample of at least eight users is necessary, although useful information can be obtained from smaller groups. Users should carry out the tests without any hints or external assistance.