

Big Data and the Cloud
WHAT YOU WILL LEARN IN THIS CHAPTER:
- Exploring the Leading Cloud Providers: Amazon and Microsoft
- Using the Amazon Elastic Compute Cloud (EC2) and Microsoft HDInsight Services as Cloud Processing Options
- Hosting and Storing Your Data in the Cloud with Amazon Simple Storage Service (S3) and Microsoft Azure Blob Storage
Although many organizations will inevitably consider an on-premise solution for big data, the broad and ever-expanding appeal of the cloud makes big data approachable to those who would otherwise have neither the resources nor the expertise. The focus of this chapter is threefold. First, we introduce the cloud and look at two of the leading cloud providers: Amazon and Microsoft.
Next, we walk through setting up development or sandbox big data environments to explore the Amazon Elastic Compute Cloud (EC2) service and the Microsoft HDInsight service as cloud processing options.
We then explore two options—Amazon Simple Storage Service (S3) and Microsoft Azure Blob Storage (ASV)—for hosting or storing your data in the cloud. This discussion explains the considerations for cloud storage (pros/cons), reviews best practices for storing your data in the cloud, and identifies proven patterns and tools for loading and managing your data in the cloud.
Defining the Cloud
One of the most overused (and abused) contemporary technology terms is the cloud. You've probably seen or heard it used to describe just about everything from distributed computing to the Internet. So, what is it, really? Well, unfortunately, it is a little bit of everything, which is why we will limit our context to that of applications, services, and (of course) data.
By changing the perspective in which we discuss the cloud, we can easily clarify the definition. For our purposes, we will consider the cloud as the hosted virtualization and abstraction of hardware that provides simple and flexible solutions for capacity and scalability. This is sometimes referred to more simply as infrastructure as a service (IaaS). This definition is succinct, but a simple example can provide elaboration.
Consider a scenario such as setting up a Hadoop cluster. In the on-premise world, you have many things to consider. From hardware and software to configuration, numerous areas require a variety of skills and varying degrees of expertise.
Now, consider Hadoop in the cloud. Your cluster will still function the same as if it were running on real, physical hardware in your data center, with the difference being that now everything from the hardware and the operating system to the Hadoop installation and configuration is being provided as a service. This virtualization service abstracts away hardware from the puzzle and means that your cluster, whether 4 nodes or 32, will be seamlessly available and may be distributed over multiple machines (and potentially even across multiple data centers).
This certainly isn't a new concept, but it is an important one, and if it is not immediately evident, consider some of the other benefits of the cloud:
- Getting the hardware/infrastructure right the first time can be almost completely deemphasized. By virtualizing the hardware and abstracting it away as described previously, scaling either up or down after the fact becomes a trivial exercise that can usually be accomplished by little more than the adjustment of a slider bar in an administrative window.
- Clusters can be stood up (created) and shut down in minutes, meaning that they are available when you need them.
- Common infrastructure concerns such as maintenance and redundancy are managed by the cloud provider, freeing you from the concerns such as hard drive failures, failover for fault-tolerance, and even operating system patches.
Now that you understand the basic value proposition of cloud-based solutions, let's dig deeper into two of the features and offerings of big data cloud providers.
Exploring Big Data Cloud Providers
With the number of cloud service providers offering big data solutions growing at a seemingly endless pace, the environment is dynamic and ever-changing. That notwithstanding, the two market leaders in the space to consider are Amazon and Microsoft.
Amazon
As one of the pioneers with the largest footprint in the big data cloud services space, Amazon offers three relevant services, all of which fall under the Amazon Web Services (http://aws.amazon.com/) umbrella.
Amazon Elastic Compute Cloud (EC2)
The Amazon Elastic Compute Cloud (http://aws.amazon.com/ec2/) is web-based service that provides resizable compute capacity in the cloud. Amazon offers preconfigured Windows and Linux templates that include a variety of preinstalled application systems. Instances from small or micro to large or high memory/processor capacity can be created. You can easily resize your instances as your computing needs change.
Amazon Elastic MapReduce (EMR)
Built on top of the EC2 service, the Elastic MapReduce service (http://aws.amazon.com/elasticmapreduce/) offers businesses a resizable, hosted Hadoop platform for processing large quantities of data. The EMR service supports a number of processing jobs, including MapReduce, MapReduce Streaming (via Java, Ruby, Perl, Python, PHP, R, and C++), Hive, and Pig.
Amazon Simple Storage Service (S3)
The Simple Storage Service (S3) service (http://aws.amazon.com/s3/) provides inexpensive, highly scalable, reliable, secure, and fast data storage in the cloud. Data can easily be backed up or even globally distributed and is accessed and managed via a REST API.
![]() Representational State Transfer (REST) API is a lightweight, stateless web service architectural pattern that is implemented from the HTTP protocol. Commands are generally issued using the HTTP verbs (GET, POST, PUT, and DELETE), making it easier to interact with than traditional SOAP or XML-based web services.
Representational State Transfer (REST) API is a lightweight, stateless web service architectural pattern that is implemented from the HTTP protocol. Commands are generally issued using the HTTP verbs (GET, POST, PUT, and DELETE), making it easier to interact with than traditional SOAP or XML-based web services.
Microsoft
Amazon continues as a leader in this space, but Microsoft (although arriving later) has quickly and dynamically expanded their footprint through innovative and proven solutions in their Windows Azure (http://www.windowsazure.com/) offering. Within the context of big data, the services of interest include HDInsight and Azure Blob Storage.
HDInsight
HDInsight (http://www.windowsazure.com/en-us/services/hdinsight/) is Microsoft's 100% Apache Hadoop implementation available as a cloud service. You can quickly and easily provision an elastic Hadoop cluster ranging from 4 to 32 nodes that allows for seamless scaling.
Azure (ASV) Blob Storage
Like Amazon's S3 service, the Microsoft Azure (ASV) Blob Storage (http://www.windowsazure.com/en-us/services/data-management/) offers a high-performance, reliable, scalable, and secure cloud storage solution that supports backup and global distribution via a content delivery network. In addition to traditional blob storage, the ASV service also supports table-based and queue storage.
Together, both of these service providers offer a first-class storage service and robust, stable processing platform capable of hosting your big data solution. The remainder of this chapter walks you through setting up a sandbox environment for each service provider before demonstrating tools and techniques for getting your data to the cloud and integrating it once it is there.
Setting Up a Big Data Sandbox in the Cloud
Before you dig in and get your hands dirty, both Amazon and Microsoft require that you register or create an account as a condition of service. Amazon will let you create an account using an existing Amazon account, and Microsoft accounts are based on Live IDs.
If you have neither, creating these accounts requires typical information such as name, contact information, an agreement to terms of service, and verification of identity. In addition, both require a credit card for payment and billing purposes.
As mentioned previously, these services are provided on the basis of either compute hours or storage space. Both providers offer a free or preview version that will allow you to try them with little if any out-of-pocket costs, but the payment method you provide will be billed for any overages beyond what's provided as free usage. The tutorials in this chapter assume that you have created accounts for both Amazon and Microsoft.
Getting Started with Amazon EMR
Amazon EMR provides a simple, straightforward method for processing and analyzing large volumes of data by distributing the computation across a virtual cluster of Hadoop servers. The premise is simple and starts with uploading data to a bucket in an Amazon S3 account.
Next, a job is created and uploaded to your S3 account. This job will be responsible for processing your data and can take a number of different forms—such as Hive, Pig, HBase jobs, custom jars, or even a streaming script. (Currently supported languages include Ruby, Perl, Python, PHP, R, Base, and C++.) Your cluster will read the job and data from S3, process your data using a Hadoop cluster running on EC2, and return the output to S3.
![]() Hadoop Streaming functions by streaming data to the standard input (stdin) and output (stdout). Executables that read and write using the standard input/output can be used as either a mapper or reducer. For more information on Hadoop Streaming, please visit: http://hadoop.apache.Org/docs/r0.18.3/streaming.html.
Hadoop Streaming functions by streaming data to the standard input (stdin) and output (stdout). Executables that read and write using the standard input/output can be used as either a mapper or reducer. For more information on Hadoop Streaming, please visit: http://hadoop.apache.Org/docs/r0.18.3/streaming.html.
Before beginning this tutorial, complete the following:
- Create a bucket in your Amazon S3 account, and within your bucket create a folder named input. The bucket name must be unique because the namespace is shared globally. (Amazon S3 and its features and requirements are discussed in greater detail later in this chapter.)
- Locate the wordcount.txt and wordsplitter.py files provided in the Chapter 13 materials (http://www.wiley.com/go/microsoftbigdatasolutions.com) and upload the data file to the input folder and the wordsplitter.py file in the root of your S3 bucket.
Now you are ready to stand up your cluster using the following steps:
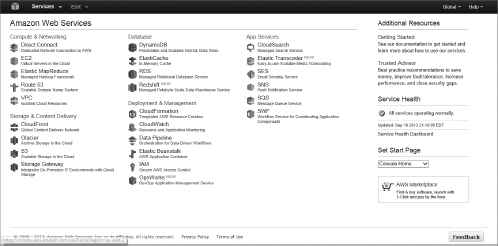
- In a web browser, navigate to the Amazon Web Services portal at https://console.aws.amazon.com/. Find and click the Elastic MapReduce link under the Compute & Networking section (see Figure 13.1).
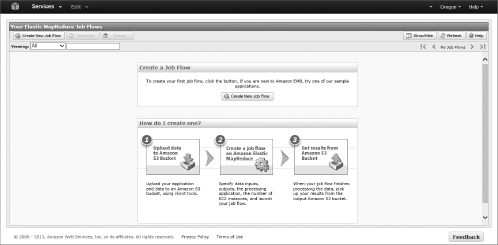
- The Amazon EMR service is built around job flows, which are essential jobs that will process your data. Figure 13.2 shows the Create Job Flow dialog. Begin by clicking the Start Job Flow button.
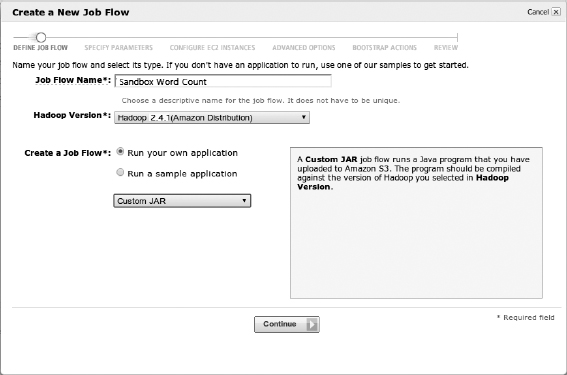
- In the Create a New Job Flow Wizard, define the job settings as described here and illustrated in Figure 13.3, and then click Continue:
- Enter Sandbox Word Count for your job name.
- Keep the default Hadoop distribution, Amazon Distribution.
- Use the latest AMI version. As of this writing, 2.4.1 is the current version.
- Ensure that the Run Your Own Application option is selected.
- Select Streaming as the processing job type.
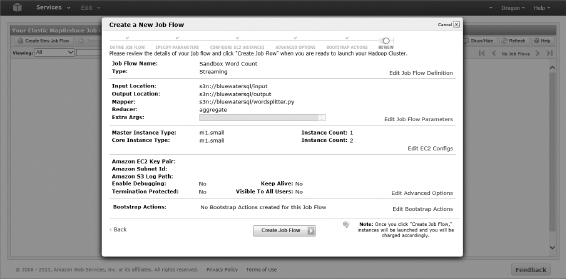
- Specify the parameters needed to execute your job flow. These include input and output location, mapper and reducer jobs, and any additional arguments required for your job, as shown in Figure 13.4. Table 13.1, elaborates on each option, including the values used for this demo. Note that you must substitute your bucket name throughout this demo. Click Continue when you have finished.
Figure 13.4: Amazon EMR job parameters
Table 13.1: Amazon EMR Job Parameters

 For this demo, the built-in org.apache.hadoop.mapreduce.lib.aggregate reducer is used in place of a custom scripted reducer.
For this demo, the built-in org.apache.hadoop.mapreduce.lib.aggregate reducer is used in place of a custom scripted reducer. - Now you are ready to specify the number of EC2 instances that form the nodes within your Hadoop cluster. You need to configure three instance types:
- Master node: The head node is responsible for assigning and coordinating work among core and task nodes. Only a single instance of the master node is created.
- Core node: These are your task and HDFS data nodes. In addition to specifying the size of each number, you can scale the number of nodes from 2 to 20 nodes.
- Task node: These are worker nodes that perform Hadoop tasks but do not store data and can be configured in the same manner as core nodes.
For each of the above node types, you must select the size of the instance and, in the case of core and task nodes, the number of instances you want in your cluster. The size of the instance roughly determines the number of resources (memory, processor, etc.) available for the instance. For this walk-through, small (ml.small) instances are plenty. As you work beyond this demo, the number of instances and their size will be dependent on the volume of your data and the data processing being performed. Use the default settings of 2 core nodes and 0 task nodes, as shown in Figure 13.5, and then click Continue.
 The size you specify for your nodes will affect your pricing. To keep size low, use the smallest instance size possible. For more info on the instance sizes available, visit http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-plan-ec2-instances.html.
The size you specify for your nodes will affect your pricing. To keep size low, use the smallest instance size possible. For more info on the instance sizes available, visit http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-plan-ec2-instances.html.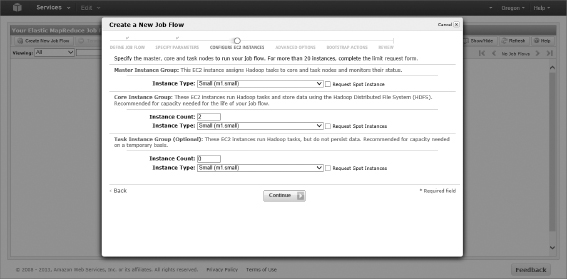
- Accept the defaults for both Advanced Options and Bootstrap Actions by clicking Continue twice.
- Figure 13.6 displays the final review page before your cluster is created. Verify all parameters are correct, and then click the Create Job Flow button.
- After your job kicks off, you can monitor it from the Elastic MapReduce portal (see Figure 13.7). After the job has been completed, you can download and view the results in the output folder found in your S3 bucket (see Figure 13.8).



This tutorial demonstrated only the basics required for creating an Elastic MapReduce streaming job and running it on an Amazon EC2 Hadoop cluster. Other cluster types such as Hive, Jar, Pig, and HBase will vary slightly in their setup.
Getting Started with HDInsight
Whereas the Amazon Elastic MapReduce service approach centers on a processing job flow, the Microsoft HDInsight service is more cluster centric. Instead of specifying a job and cluster configuration, HDInsight starts by provisioning the cluster first. Once the cluster is established, one or more jobs can be submitted before tearing the cluster down. To stand up your first HDInsight sandbox, follow these steps:
- Open your preferred web browser and navigate to https://manage.windowsazure.com/. Then log in with your Windows Live account.
- Before you can begin creating your HDInsight cluster, you must create a storage container. This Azure Blob Storage container will be used to store all the files required for the virtual instances that form your cluster. Click the Storage icon to navigate to the Storage console.
- From the Storage console, click the New button found in the lower left of the screen to access the New Services dialog shown in Figure 13.9.
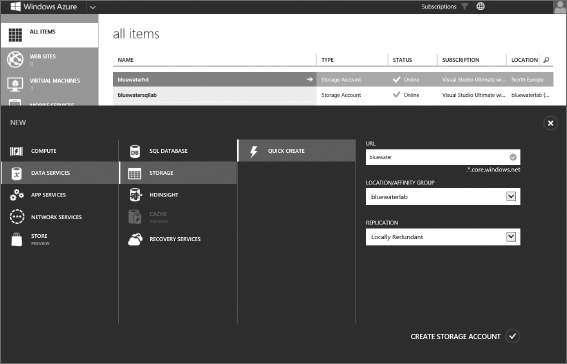
- Click the Quick Create button, and then select a unique container name. Because the container we are creating will be used for an HDInsight instance, select the West US region. (We will be creating our cluster in the West US region later on.) Note that the Enable Geo-Replication option is selected by default. This option can have a pricing impact on your storage. For evaluation and testing purposes, you can uncheck this box. Figure 13.10 shows the resulting container configuration. Click Create Storage Account when finished.
- Now you are ready to begin creating your HDInsight cluster. On the menu bar, click the HDInsight icon to navigate to the HDInsight console, and then click the Create an HDInsight Cluster link.
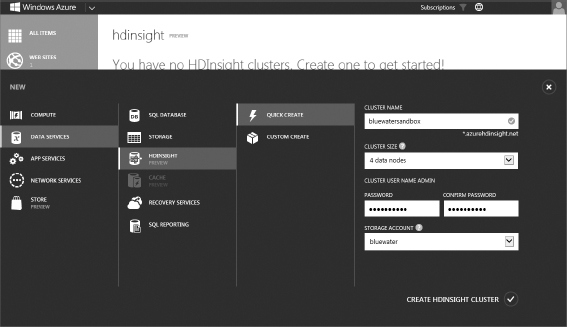
- We will use the Quick Create option to stand up our HDInsight sandbox. Select a unique name for your cluster. For this demonstration, leave the default of 4 data nodes, and then create your administrator password. Note that the administrator username for your instance is Admin when using the Quick Create option. Finally, ensure that the storage account you created previously is selected. The results should look similar to Figure 13.11. Click the Create HDInsight Cluster button.
- After you have submitted your request for an HDInsight cluster, grab a cup of coffee and relax. It takes between 5 and 10 minutes for your Azure virtual machine configuration and nodes to be built out and made available. You can monitor the progress of your request using the HDInsight console/dashboard. When your cluster is ready, the status will read as Started.
Your HDInsight cluster is now available and is ready for a processing job. To access and manage your new cluster, you can use either Remote Desktop or the HDInsight web console.
To open a Remote Desktop session, select your cluster from the HDInsight console and click the Connect button (see Figure 13.12). An *.rdp file is downloaded and contains all the connection information required for the Remote Desktop session. The username mentioned previously is Admin, and the password is the same as you created during setup.

Figure 13.12: HDInsight cluster dashboard
The second option for interacting with your HDInsight sandbox is via the HDInsight web portal. To launch the web portal, click the Manage Cluster link and enter your username and password.
As shown in Figure 13.13, the web portal provides robust access via tiles to key features and functions within your cluster, including the following:
- An interactive console
- Remote Desktop
- A monitor dashboard
- Job history
- Built-in samples
- Downloads and documentation
In addition, you can submit a MapReduce job packaged in a JAR file via the Task tile.
Running a Processing Job on HDInsight
When you set up your sandbox using the Amazon EMR service, your environment centered on a specific processing job. The provision of a cluster was handled in terms of that one specific task. HDInsight takes a different approach from that shown in the preceding demonstration, focusing first on standing up your Hadoop cluster, meaning that to this point, you have not actually processed any data.
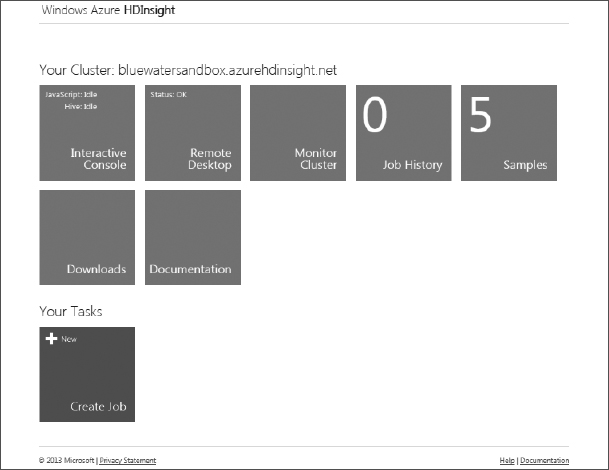
Figure 13.13: HDInsight web portal
To make sure that you understand the differences between the two service providers, create and run a similar word-count job on your HDInsight sandbox by completing the following steps:
- Download the wordcount.js file from the Chapter 13 materials accompanying this book. You also need the wordcount.txt file used in the previous demo.
- From the HDInsight dashboard in the Windows Azure Portal, click your sandbox cluster. Then click the Manage Cluster link at the bottom of the screen.
- When the management portal has launched, enter your username and password to connect to your HDInsight environment.
- For this demonstration, use the JavaScript Interactive console. This console is accessed by clicking the Interactive Console tile.
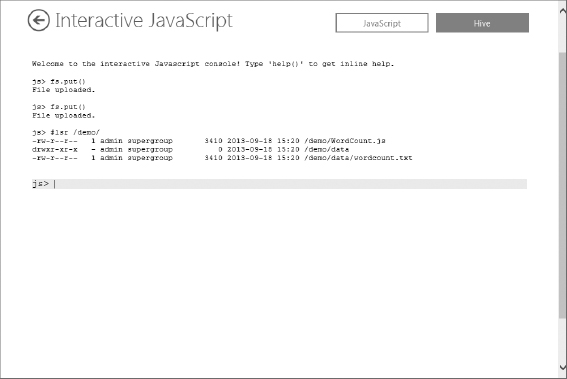
- To prepare for the job, the data and job scripts must first be available within HDInsight. If you recall from the Amazon EMR demo, you uploaded the files separately. In HDInsight, you can upload both the data and job script files using the interactive console. At the console js> prompt, enter or type fs.put(). This launches a file upload dialog as shown in Figure 13.14. Select wordcount.txt from your local file system as the source and enter /demo/data/wordcount.txt for your destination.
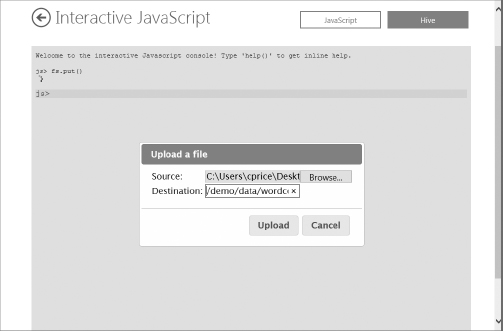
- Repeat Step 5 to upload the Wordcount.js file using /demo/wordCount.js as the destination path. This file contains a streaming JavaScript MapReduce job that will be used to split the words and provide a word count.
- To confirm that the files exist in your ASV storage account and to demonstrate some of the Hadoop Filesystem commands, use the following command, as shown in Figure 13.15, to recursively list the files you uploaded to the demo directory:
#lsr /demo/
- You can also browse the contents of the JavaScript file you uploaded to process your data by entering #cat /demo/wordCount.js. This command reads the file and prints the contents to the Interactive console window.
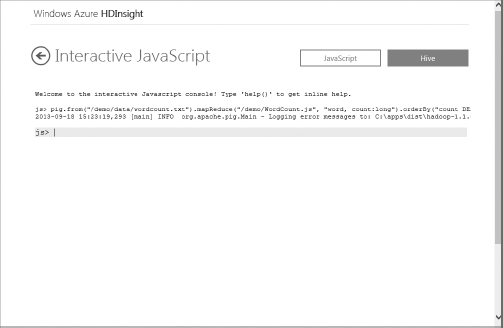
- This demo uses both a Pig and MapReduce job to parse the wordcount.txt file, count the occurrence of words, and return the top 10 most used words. You can create and execute the processing job by entering the following command:
pig.from("/demo/data/wordcount.txt") .mapReduce("/demo/WordCount.js", "word, count:long").orderBy("count DESC") .take(10).to("Top10Words") - Figure 13.16 displays the result when your command is submitted to your HDInsight cluster. The console will continually update the status as processing proceeds. If you prefer to see the entire job output, click the More link displayed in the job status update. If the More link is not visible, you might need to scroll in the console window to the right.
- When your job completes, you can use the Hadoop FileSystem commands to explore the results. The #lsr Top10Words command will display the files output by your processing job, and the #tail Top10Words/part-r-00000 will read and print out the end of your file, as shown in Figure 13.17.
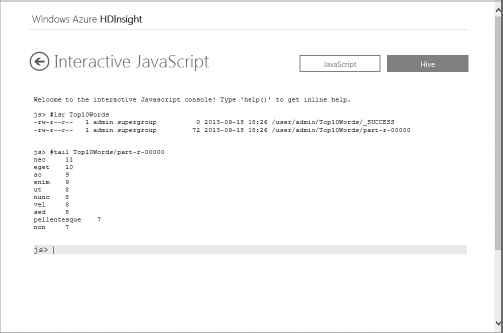
Figure 13.17: HDInsight JavaScript FS command
The Hadoop FileSystem #cat command prints out the entire contents of a file to the console window. If you are working with a very large file, this is probably not a desirable function. Instead, you can use the #tail function to peek or preview the last kilobyte of the file. - Additional functionality beyond the execution of processing jobs is available through your Interactive console. As an example of its flexibility, you could easily chart the top 10 words from the text, as shown in Figure 13.18, using these commands:
file = fs.read(“Top10Words”) data = parse(file.data, “word, count:long”) graph.bar(data)
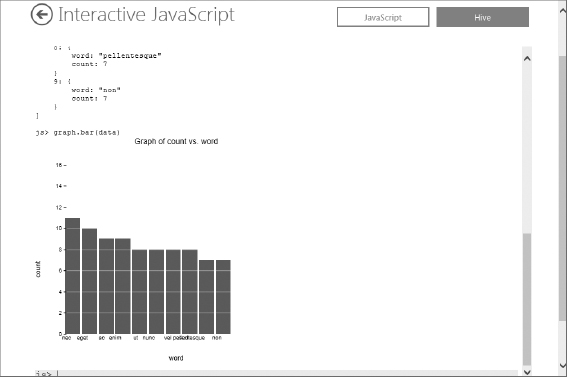
With that, your HDInsight sandbox tour is complete. Unlike the Amazon EMR sandbox, you must manually delete your cluster when you finish. Failure to delete your cluster will result in charges for idle-processing time, which is wasteful and runs counter to the paradigm discussed previously.
Storing Your Data in the Cloud
Previously in this chapter, you worked with cloud storage as you set up and provisioned your Amazon and Microsoft Hadoop clusters. This section looks more closely at cloud storage and some of the common features and rationalizations as they relate to big data.
Storing Data
Storing your big data in the cloud is a more natural fit than it might appear at first glance. Cloud data storage works best when the “write once, read many” or WORM principle is applied. This principle implies that data is written once and read many times from many different sources. This is one of the core principles of big data and Hadoop data systems in general.
Cloud service providers offer cheap, scalable, and redundant data storage that is highly and even globally available when necessary, making it an ideal storage solution for many big data implementations. Regardless of the service provider, the feature set among cloud storage providers is similar, including advanced features such as advanced security options, backup or snapshot capabilities, and content-delivery networks.
Both Amazon S3 and Microsoft Azure Blob Storage are centered on a top-level root directory or container (called a bucket in S3). These containers can contain an unlimited number of files and folders and can scale to any size you require. Likewise, these containers allow you to apply general security and access policies to prevent or allow access as required.
To better illustrate how these containers work, we will use the following example:
- Account: mycorp
- Container/bucket: demo
- Folder: weblogs
- File: server1.csv
When using Amazon S3, the URL of your bucket is a globally unique name. This results in the URL for your file follows:
http://demo.s3.amazonaws.com/weblogs/server1.csv
On the Azure Blob Storage service, both your account name and container name are included resulting in a URL that looks like this:
http://mycorp.blob.core.windows.net/demo/weblogs/server1.csv
Access to both containers is provided via REST web APIs that allow for creating, modifying, and deleting folders and files within the containers. Each API also supports the creation and deletion of containers/buckets on the fly.
Uploading Your Data
Big data presents challenges in terms of how data is processed and managed. If you are going to host your data in the cloud, you are also confronted with the task of efficiently moving your data into the cloud in a timely manner. To assist in the process, you want to consider several best practices, as discussed next.
Location Matters
When you are configuring your containers and buckets, the geographic location that you select during provisioning has a large impact on the file upload latency. If your data center and the servers that are producing the data are located in the southeast United States and the storage container you provision is in the western United States (or worse yet northern Europe), there is additional latency introduced because your data now has to physically travel farther. Make sure that your storage is provisioned correctly by ensuring geographic proximity.
Size Matters
Anytime you move data over any network, especially the Internet, size matters. The bigger the file, the more latency and the greater the likelihood that something will go wrong. This reinforces the obvious, which is why you want to make the files you move to the cloud as small as possible using compression.
You have multiple compression formats and techniques (LZ, zip, deflate, rar) from which to choose. The most popular and widely used in the big data realm is GZip. GZip is a lossless compression technique, which means that statistical redundancies in the data are exploited to shrink the data with no data loss. Libraries to compress and decompress files using the GZip format are available on almost every platform, and most importantly the tools within the Hadoop ecosystem can read directly from a file compressed with the GZip format.
Data Movements
When data is moved, it is usually loaded sequentially (that is, one file after another). This pattern does not scale well when you consider the data volumes typically associated with big data. To provide the scale and throughput required, data movements are usually handled in a multithreaded or parallel fashion. Luckily, the distributed nature of cloud storage lends itself to handling parallel operations.
When planning how your data will move to the cloud, consider the following:
- If your data is being created across many servers, do not create a central collection point. This point will eventually create a bottleneck for your loads. Instead, distribute the responsibility for publishing the data to the cloud to the data producers.
- Consider your tooling. Most modern cloud storage tools support uploading and downloading files in parallel.
- There is a tendency or desire to bundle multiple files into a single compressed file before publishing to the cloud. This process will tax the system responsible for packaging files and slow down your uploads. Multiple small files will always upload faster than a single large or monolithic file.
Exploring Big Data Storage Tools
Amazon S3 and Microsoft Azure Blob Storage provide a robust REST API for integration with their cloud data services. In addition, a number of wrappers function as a layer of abstraction and provide easy access within code; these are available in just about every development language. If you are a developer (or even a closet developer), this may excite you and be exactly what you are looking for. For most of you, however, you will prefer tools that provide the same management and administration capabilities with no coding required.
This section briefly introduces some of the more popular commercial tools available and discusses the AzCopy project. The intent is not to endorse any one tool over another, but instead to make you aware of the current state of the marketplace.
Azure Management Studio
Developed by a company called Cerebata, Azure Management Studio (http://www.cerebrata.com/products/azure-management-studio/introduction) is a tool geared toward Microsoft Azure. It is a full-feature product that not only allows for complete administration over your blob storage but also includes other features such as pulling diagnostic and miscellaneous analytical information associated with your account. It also has a number of features built in to enable you to manage your other Azure services. A demo version is available for evaluation, but you have to purchase a license to use this product.
CloudXplorer
Developed by ClumsyLeaf, CloudXplorer (http://clumsyleaf.com/products/cloudxplorer) is a lightweight explorer tool for Windows Azure. It is widely used and capable of supporting all needed administrative and management tasks. CloudXplorer offers two versions: one freeware and a Pro version.
CloudBerry Explorer
CloudBerry Explorer (http://www.cloudberrylab.com/) by CloudBerry Labs offers versions that work with both Windows Azure and Amazon S3. This tool is also a full-feature product that comes in two versions: freeware and Pro.
AzCopy
Beyond tools offered by third-party providers, within the Windows Azure realm there is an open source, console-based project called AzCopy that enables quick and convenient parallel data transfers (http://go.microsoft.com/fwlink/?LinkId=287086). Unlike the tools discussed previously, the sole purpose of this tool is the upload and/or download files to and from your Azure blob storage account. Because it is implemented as a console application, it can easily be scripted for the purpose of automation into your big data movement processing.
Working with AzCopy is easy, and it lends itself nicely to being embedded in jobs or even SQL Server Integration Services packages. The following command format will recursively copy (the /s switch) all files from the c:logs directory to the target container:
AzCopy C:logs https://demo.blob.core.windows.net/logs/ /destkey:key /S
The process has built-in parallelism that uses multithreading to simultaneously initiate network connections eight times the number of cores on your server or workstation. This means that for a 4-core machine, 32 simultaneous file transfers to your Azure Blob Storage account would be initiated.
Regardless of the tool you select, the principles for efficiently and effectively transferring data to the cloud remain the same, and all the tools discussed do a good job in helping you effectively and efficiently get your data into the cloud.
Integrating Cloud Data
Once your data is stored in the cloud, integrating it into your Hadoop cluster is a trivial task. Vendors have a done a lot of work to ensure that the links between their cloud storage and cloud computing services are not only seamless but also high performance.
Both S3 and Azure Blob data can be referenced natively within each vendor's respective service using a path that starts with either s3:// or asv:// as the path prefix.
Within Microsoft HDInsight, there are three use cases to consider when integrating cloud data stored in Azure Blob Storage, as described next.
Local Container and Containers on the Same Storage Account
Data can be created and read from both the same container and other containers on the same storage account that is used to run your HDInsight cluster. In this scenario, the key required to read from the storage account is already stored in the core-site.xml. This allows for full access to the data within these containers.
Public Container
When a container (and the blobs it contains) is marked as public, you can access data directly by specifying a URI path to the blob. The path required varies slightly from the one introduced previously. When accessing a file from a URI, the path format looks like the following:
http://<Account>.blob.core.windows.net/<Container>/<Path>
The URI required for access to the same file from HDInsight would translate to the following:
asv://<Container>@<Account>.blob.core.windows.net/<Path>
Private Container on a Separate Account
To connect to a private container on a separate storage account, you must configure Hadoop for access to the container. To make this configuration change, complete the following steps:
- Use Remote Desktop to connect to your HDInsight cluster by clicking the Configure button on your HDInsight dashboard.
- In Windows Explorer, navigate to the c:appsdisthadoop-1.1.0-SNAPSHOTconf directory and open the core-site.xml file in Notepad.
- Add the following snippet of XML, ensuring that you substitute the storage account name and storage account key:
<property> <name>fs.azure.account.key.<ACCOUNT>.blob.core.microsoft.com </name> <value><KEY></value> </property> - Save the changes and close the file.
After you define the account and security key required for access to the container, HDInsight will treat the container as a local container.
![]() You can easily use the Hadoop FileSystem API to manage containers from your HDInsight cluster. A few of the common commands are included here:
You can easily use the Hadoop FileSystem API to manage containers from your HDInsight cluster. A few of the common commands are included here:
- Create a new container
hadoop fs -mkdir asvs://<container>@<account>.blob.core .windows.net/ <path>
- List container contents
hadoop fs -ls asvs://<container>@<account>.blob.core .windows.net/<path>
- Permanently delete file
Hadoop fs -rmr -skipTrash asvs://<container>@<account>.blob.core. windows.net/<path>
Other Cloud Data Sources
Beyond your cloud data, many other cloud data sources may provide value in your big data infrastructure.
Amazon hosts a number of different public data sets, ranging from U.S. census databases to data from the Human Genome project. You can get more information on this data at http://aws.amazon.com/publicdatasets/.
Microsoft also hosts a number of different data sources and services through the Windows Azure Data Marketplace. A variety of data is available, ranging from demographic and weather data to business and economic data for banking, finance, and manufacturing. Some data is offered either free of charge or with a free trial; other data is offered via a paid subscription service.
Summary
Getting started with big data does not require a large investment in either time or resources. By leveraging the cloud service providers like Amazon and Microsoft for both storage and computer power, you can easily get started with Hadoop and big data.
Using these services is quick and easy and allows for virtualizing away the hardware and infrastructure while providing a reliable, scalable, cloud-based big data solution.